【机器学习(十三)】机器学习回归案例之股票价格预测分析—Sentosa_DSML社区版
文章目录
- 一、背景描述
- 二、Python代码和Sentosa_DSML社区版算法实现对比
- (一) 数据读入
- (二) 特征工程
- (三) 样本分区
- (四) 模型训练和评估
- (五) 模型可视化
- 三、总结
一、背景描述
股票价格是一种不稳定的时间序列,受多种因素的影响。影响股市的外部因素很多,主要有经济因素、政治因素和公司自身因素三个方面的情况。自股票市场出现以来,研究人员采用各种方法研究股票价格的波动。随着数理统计方法和机器学习的广泛应用,越来越多的人将机器学习等预测方法应用于股票预测中,如神经网络预测、决策树预测、支持向量机预测、逻辑回归预测等。
XGBoost是由TianqiChen在2016年提出来,并证明了其模型的计算复杂度低、运行速度快、准确度高等特点。XGBoost是GBDT的高效实现。在分析时间序列数据时,GBDT虽然能有效提高股票预测结果,但由于检测速率相对较慢,为寻求快速且精确度较高的预测方法,采用XGBoost模型进行股票预测,在提高预测精度同时也提高预测速率。可以利用XGBoost网络模型对股票历史数据的收盘价进行分析预测,将真实值和预测值进行对比,最后通过评估算子来评判XGBoost模型对股价预测的效果。
数据集通过爬虫获取从2005年开始到2020年的股票(代码为 510050.SH)历史数据,下表展示了股票在多个交易日内的市场表现,主要字段包括:
| 字段 | 含义 |
|---|---|
| ts_code | 股票代码 |
| trade_date | 交易日期 |
| pre_close | 前一个交易日的收盘价 |
| open | 开盘价 |
| high | 当日最高价 |
| low | 当日最低价 |
| close | 当日收盘价 |
| change | 收盘价变化值(与前一日相比的差值) |
| pct_chg | 收盘价变化百分比 |
| vol | 成交量 |
| amount | 成交金额 |
| label | 标记某日涨跌情况 |
这些字段全面记录了股票每天的价格波动和交易情况,用于后续分析和预测股票趋势。
二、Python代码和Sentosa_DSML社区版算法实现对比
(一) 数据读入
1、python代码实现
导入需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rcParams
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import xgboost as xgb
数据读入
dataset = pd.read_csv('20_year_FD.csv')
print(dataset.head())
2、Sentosa_DSML社区版实现、
首先,利用文本算子从本地文件读入股票数据集。

(二) 特征工程
1、python代码实现
def calculate_moving_averages(dataset, windows):for window in windows:column_name = f'MA{window}'dataset[column_name] = dataset['close'].rolling(window=window).mean()dataset[['close'] + [f'MA{window}' for window in windows]] = dataset[['close'] + [f'MA{window}' for window in windows]].round(3)return datasetwindows = [5, 7, 30]
dataset = calculate_moving_averages(dataset, windows)print(dataset[['close', 'MA5', 'MA7', 'MA30']].head())plt.figure(figsize=(14, 7))
plt.plot(dataset['close'], label='Close Price', color='blue')
plt.plot(dataset['MA5'], label='5-Day Moving Average', color='red', linestyle='--')
plt.plot(dataset['MA7'], label='7-Day Moving Average', color='green', linestyle='--')
plt.plot(dataset['MA30'], label='30-Day Moving Average', color='orange', linestyle='--')
plt.title('Close Price and Moving Averages')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()

得到实际股价与平均股价的差值的绝对值,观察偏离水平。
def calculate_deviation(dataset, ma_column):deviation_column = f'deviation_{ma_column}'dataset[deviation_column] = abs(dataset['close'] - dataset[ma_column])return datasetdataset = calculate_deviation(dataset, 'MA5')
dataset = calculate_deviation(dataset, 'MA7')
dataset = calculate_deviation(dataset, 'MA30')plt.figure(figsize=(10, 6))
plt.plot(dataset['deviation_MA5'], label='Deviation from MA5')
plt.plot(dataset['deviation_MA7'], label='Deviation from MA7')
plt.plot(dataset['deviation_MA30'], label='Deviation from MA30')
plt.legend(loc='upper left')
plt.title('Deviation from Moving Averages')
plt.show()

def calculate_vwap(df, close_col='close', vol_col='vol'):if close_col not in df.columns or vol_col not in df.columns:raise ValueError(f"DataFrame must contain '{close_col}' and '{vol_col}' columns.")try:cumulative_price_volume = (df[close_col] * df[vol_col]).cumsum()cumulative_volume = df[vol_col].cumsum()vwap = np.where(cumulative_volume == 0, np.nan, cumulative_price_volume / cumulative_volume)except Exception as e:print(f"Error in VWAP calculation: {e}")vwap = pd.Series(np.nan, index=df.index)return pd.Series(vwap, index=df.index)
dataset['VWAP'] = calculate_vwap(dataset)
def generate_signals(df, close_col='close', vwap_col='VWAP'):if close_col not in df.columns or vwap_col not in df.columns:raise ValueError(f"DataFrame must contain '{close_col}' and '{vwap_col}' columns.")signals = pd.Series(0, index=df.index)signals[(df[close_col] > df[vwap_col]) & (df[close_col].shift(1) <= df[vwap_col].shift(1))] = 1 # 买入信号signals[(df[close_col] < df[vwap_col]) & (df[close_col].shift(1) >= df[vwap_col].shift(1))] = -1 # 卖出信号return signalsdataset['signal'] = generate_signals(dataset)
print(dataset[['close', 'VWAP', 'signal']].head())
2、Sentosa_DSML社区版实现
移动平均线是一种常用的技术指标,通过计算移动平均来分析股票的价格走势,帮助识别市场趋势,并为交易决策提供参考。根据不同的窗口大小(5天、7天、30天)来计算股票的收盘价的移动平均线,移动平均线可以平滑股价的短期波动,从而更好地识别股票的长期趋势。短期的 5 日、7 日移动平均线通常用来捕捉股票的短期趋势,帮助交易者快速做出买入或卖出的决策。30 日移动平均线则代表中长期趋势,帮助识别更广泛的市场方向。通过绘制图表,可以直观地看到收盘价格及其对应的移动平均线,方便观察价格变化和趋势。
利用生成列算子,通过设定的生成列表达式计算的新列的值,并设置列名,这里生成列分别为 moving_avg_5d、 moving_avg_7d、 moving_avg_30d,分别表示不同周期(5天、7天、30天)的移动平均线。

表达式为SQL窗口函数,
AVG(`close`) OVER ( ROWS BETWEEN 4 PRECEDING AND CURRENT ROW)
AVG(`close`) OVER ( ROWS BETWEEN 4 PRECEDING AND CURRENT ROW)
AVG(`close`) OVER ( ROWS BETWEEN 4 PRECEDING AND CURRENT ROW)

连接折线图算子,选择收盘价实际值和移动平均线,进行图表展示。

得到结果如下,可以直观地看到收盘价格及其对应的移动平均线,方便观察价格变化和趋势。

再利用生成列算子,计算股票价格与不同周期的移动平均线的偏差的绝对值,得出当前价格偏离移动平均线的程度,观察偏离水平。偏差值越大,意味着价格波动越剧烈,可能处于较强的上涨或下跌趋势中。偏差值越小,意味着价格与均值靠近,波动较小,市场可能处于震荡或横盘阶段。
如果偏差持续扩大,说明价格远离均值,可能面临较大的回调风险或即将突破某个方向。
如果偏差开始收窄,说明价格回归均值,可能表明市场趋势趋于稳定或发生反转。
这里设置生成列列名分别为deviation_MA5、 deviation_MA7、deviation_MA30,分别表示不同周期得偏差。
生成列值得表达式如下:
abs(`close`-` moving_avg_5d`)
abs(`close`-` moving_avg_7d`)
abs(`close`-` moving_avg_29d`)

右键生成列算子预览可以得到数据展示。

或者利用图表算子对偏差值进行可视化图表展示,通过对偏差值进行可视化展示,绘制偏差曲线,可以直观呈现实际收盘价格与移动平均线之间的偏离趋势,不仅有助于揭示市场波动的幅度,还能为识别潜在的价格反转或趋势变化提供重要依据,能够更精准地判断市场的动向,从而优化决策流程并降低交易风险。

然后,基于交易量计算加权平均价格,反映特定时间段内股票的平均成交价格,考虑成交量的影响。计算公式是用股票的收盘价(close)乘以交易量(vol),然后计算加权收盘价的累积和,除以交易量的累积和。
利用生成列算子设置列名,并构造生成列表达式计算成交量加权平均值。

当股票的收盘价(close)大于成交量加权平均值时,signal 设置为 1,表示一个买入信号,股票价格处于强势。
当股票的收盘价小于等于成交量加权平均值时,signal 为 0,表示弱势,可以用于做空或保持观望。这个信号可以作为简单的策略来指导交易决策。
利用选择算子,对数据按照表达式trade_date;close>成交量加权平均对数据进行选择。

并连接删除和重命名算子将进行条件判断后得列修改列名为signal,表示交易决策的指导信号。

再连接合并算子,将数据利用关键字trade_date将特征列进行合并。

右键预览,可观察合并后的数据情况,也可以连接表格算子对数据进行表格输出。

(三) 样本分区
1、python代码实现
对数据进行预处理和顺序分区。
def preprocess_data(dataset, columns_to_exclude, label_column):if label_column not in dataset.columns:raise ValueError(f"Label column '{label_column}' not found in dataset.")dataset[columns_to_exclude] = Nonefor column in columns_to_convert:if column in dataset.columns:dataset[column] = pd.to_numeric(dataset[column], errors='coerce')else:print(f"Warning: Column '{column}' not found in dataset.")dataset.fillna(0, inplace=True)return dataset
def split_data(dataset, label_column, train_ratio=0.8):dataset.sort_values(by='trade_date', ascending=True, inplace=True)split_index = int(len(dataset) * train_ratio)train_set = dataset.iloc[:split_index]test_set = dataset.iloc[split_index:]return train_set, test_set
def prepare_dmatrix(train_set, test_set, label_column):if label_column not in train_set.columns or label_column not in test_set.columns:raise ValueError(f"Label column '{label_column}' must be in both training and testing sets.")dtrain = xgb.DMatrix(train_set.drop(columns=[label_column]), label=train_set[label_column])dtest = xgb.DMatrix(test_set.drop(columns=[label_column]), label=test_set[label_column])return dtrain, dtest
columns_to_exclude = ['trade_date', 'ts_code', 'label', 'VWAP', 'signal','MA5', 'MA7', 'deviation_MA5', 'deviation_MA7'
]
columns_to_convert = ['close', 'MA5', 'MA7', 'deviation_MA5','deviation_MA7', 'MA30', 'deviation_MA30','VWAP', 'signal'
]label_column = 'close'
dataset = preprocess_data(dataset, columns_to_exclude, label_column)
train_set, test_set = split_data(dataset, label_column)
dtrain, dtest = prepare_dmatrix(train_set, test_set, label_column)
2、Sentosa_DSML社区版实现
在处理数据时,将trade_date列从int类型转换为datetime 类型,可以连接两个格式算子完成,首先将int类型的日期转换为字符串,然后再将字符串转换为datetime类型。


对数据输出类型进行格式化后,连接类型算子,设置数据的测量类型和模型类型。这里修改模型类型,设置建模算子输入数据需要的标签列和特征列等属性。

然后,连接样本分区算子,利用时间序列对数据进行分区,训练集和测试集比例为8:2。
(四) 模型训练和评估
1、python代码实现
params = {'objective': 'reg:squarederror','eval_metric': 'rmse','learning_rate': 1,'max_depth': 6,'min_child_weight': 1,'subsample': 1,'colsample_bytree': 0.8,'lambda': 1,'alpha': 0
}
model = xgb.train(params, dtrain, num_boost_round=100, evals=[(dtest, 'test')])
y_train_pred = model.predict(dtrain)
y_test_pred = model.predict(dtest)
def calculate_metrics(y_true, y_pred):r2 = r2_score(y_true, y_pred)mae = mean_absolute_error(y_true, y_pred)rmse = np.sqrt(mean_squared_error(y_true, y_pred))mape = np.mean(np.abs((y_true - y_pred) / y_true)) * 100smape = np.mean(2 * np.abs(y_true - y_pred) / (np.abs(y_true) + np.abs(y_pred))) * 100mse = mean_squared_error(y_true, y_pred)return {'R2': r2,'MAE': mae,'RMSE': rmse,'MAPE': mape,'SMAPE': smape,'MSE': mse}
train_metrics = calculate_metrics(train_set[label_column], y_train_pred)
test_metrics = calculate_metrics(test_set[label_column], y_test_pred)
print("训练集评估结果:")
print(train_metrics)
print("测试集评估结果:")
print(test_metrics)
2、Sentosa_DSML社区版实现
首先,选择XGBoost回归算子,并设置了相关参数用于模型训练,使用均方根误差(RMSE)作为评估模型表现的指标。构建了一个XGBoost预测模型,并将其应用于股票收盘价预测。也可以连接其他回归模型进行训练,将XGBoost模型的预测结果与其他模型的预测结果进行比较,并通过模型评价指标(如R²、MAE、RMSE等)对各个模型的表现进行验证和评估。

执行后可以得到训练完成的XGBoost回归模型,右键可进行查看模型信息和预览结果等操作。

连接评估算子对XGBoost模型进行评估。股票预测模型的预测性能评价指标采用R²、MAE、RMSE、MAPE、SMAPE和MSE,分别用于评估模型的拟合优度、预测误差的平均绝对值、均方根误差、绝对百分比误差、对称百分比误差和均方误差,用于衡量预测的准确性和稳定性。

得到训练集和测试集的评估结果如下所示:


该XGBoost股票预测模型在训练集上表现优异,误差较小,表明模型能够很好地拟合训练数据。在测试集上的评估结果也较为理想,MAE为0.054,RMSE为0.093,MAPE和SMAPE分别为1.8%和1.7%,说明模型在测试集上的预测误差较小,具有良好的泛化能力,能够较为准确地预测股票收盘价,该模型在平衡训练集拟合和测试集泛化上表现稳定。
(五) 模型可视化
1、python代码实现
rcParams['font.family'] = 'sans-serif'
rcParams['font.sans-serif'] = ['SimHei']train_residuals = train_set[label_column] - y_train_predplt.figure(figsize=(10, 6))
xgb.plot_importance(model, importance_type='weight', title='特征重要性图', xlabel='重要性', ylabel='特征')
plt.show()plt.figure(figsize=(10, 6))
sns.histplot(train_residuals, bins=30, kde=True, color='blue')
plt.title('残差分布', fontsize=16)
plt.xlabel('残差', fontsize=14)
plt.ylabel('频率', fontsize=14)
plt.axvline(x=0, color='red', linestyle='--')
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()`if '预测值' in test_set.columns:test_data = pd.DataFrame(test_set.drop(columns=[label_column, '预测值']))
else:test_data = pd.DataFrame(test_set.drop(columns=[label_column]))test_data['实际值'] = test_set[label_column].values
test_data['预测值'] = y_test_pred
test_data_subset = test_data.head(400)original_values = test_data_subset['实际值'].values
predicted_values = test_data_subset['预测值'].values
x_axis = range(1, 401)plt.figure(figsize=(12, 6))
plt.plot(x_axis, original_values, label='实际值', color='orange')
plt.plot(x_axis, predicted_values, label='预测值', color='green')
plt.title('实际值与预测值比较', fontsize=16)
plt.xlabel('样本编号', fontsize=14)
plt.ylabel('收盘价', fontsize=14)
plt.legend()
plt.grid()
plt.show()`


2、Sentosa_DSML社区版实现
右键模型信息可以查看特征重要性图、残差直方图等信息。


连接时序图算子,用于将XGBoost模型预测的股票收盘价与实际收盘价进行可视化对比,将每个序列单独显示,生成时序对比曲线图,通过这种方式可以直观地看到模型预测与实际数据的差异,从而评估模型的性能和可靠性。这在数据预测中非常重要,因为它有助于识别模型是否能够准确捕捉市场趋势。

得到时序图算子的执行结果如下所示:

这张图包含两条时间序列曲线,分别展示了模型预测值(Predicted_close)和实际值(close)在一段时间内的走势对比,显示的是模型预测的股票收盘价随时间变化的趋势。两条曲线的整体趋势相似,尤其是在大的波动区域(如2008年左右的高峰期和之后的下降期),表明模型的预测效果与实际值接近。这张图直观地展示了模型预测值与实际值的时间序列对比,帮助评估模型的表现是否符合实际市场走势。
三、总结
相比传统代码方式,利用Sentosa_DSML社区版完成机器学习算法的流程更加高效和自动化,传统方式需要手动编写大量代码来处理数据清洗、特征工程、模型训练与评估,而在Sentosa_DSML社区版中,这些步骤可以通过可视化界面、预构建模块和自动化流程来简化,有效的降低了技术门槛,非专业开发者也能通过拖拽和配置的方式开发应用,减少了对专业开发人员的依赖。
Sentosa_DSML社区版提供了易于配置的算子流,减少了编写和调试代码的时间,并提升了模型开发和部署的效率,由于应用的结构更清晰,维护和更新变得更加容易,且平台通常会提供版本控制和更新功能,使得应用的持续改进更为便捷。
为了回馈社会,矢志推动全民AI普惠的实现,不遗余力地降低AI实践的门槛,让AI的福祉惠及每一个人,共创智慧未来。为广大师生学者、科研工作者及开发者提供学习、交流及实践机器学习技术,我们推出了一款轻量化安装且完全免费的Sentosa_DSML社区版软件,该软件包含了Sentosa数据科学与机器学习平台(Sentosa_DSML)中机器学习平台(Sentosa_ML)的大部分功能,以轻量化一键安装、永久免费使用、视频教学服务和社区论坛交流为主要特点,同样支持“拖拉拽”开发,旨在通过零代码方式帮助客户解决学习、生产和生活中的实际痛点问题。
该软件为基于通用人工智能的数据分析工具,可以赋能各行各业。应用范围非常广泛,以下是一些主要应用领域:
金融风控:用于信用评分、欺诈检测、风险预警等,降低投资风险;
股票分析:预测股票价格走势,提供投资决策支持;
医疗诊断:辅助医生进行疾病诊断,如癌症检测、疾病预测等;
药物研发:进行分子结构的分析和药物效果预测,帮助加速药物研发过程;
质量控制:检测产品缺陷,提高产品质量;
故障预测:预测设备故障,减少停机时间;
设备维护:通过分析机器的传感器数据,检测设备的异常行为;
环境保护:用于气象预测、大气污染监测等。
欢迎访问官网https://sentosa.znv.com/,下载体验Sentosa_DSML社区版。同时,我们在B站、CSDN、知乎、博客园等平台也有技术讨论博客和文章,欢迎广大数据分析爱好者前往交流讨论。
Sentosa_DSML社区版,重塑数据分析新纪元,以可视化拖拽方式指尖轻触解锁数据深层价值,让数据挖掘与分析跃升至艺术境界,释放思维潜能,专注洞察未来。
https://sentosa.znv.com/

相关文章:
【机器学习(十三)】机器学习回归案例之股票价格预测分析—Sentosa_DSML社区版
文章目录 一、背景描述二、Python代码和Sentosa_DSML社区版算法实现对比(一) 数据读入(二) 特征工程(三) 样本分区(四) 模型训练和评估(五) 模型可视化 三、总结 一、背景描述 股票价格是一种不稳定的时间序列,受多种因素的影响。影响股市的外部因素很多,主要有经济因素、政治因…...

大模型微调
概述 什么是模型微调? 模型微调是通过微调工具,使用独特的场景数据对平台的基础模型进行调整,帮助你快速定制一个更符合业务需求的大型模型。其优势在于对基础模型进行小幅调整以满足特定需求,相比于训练一个新模型,…...

240607 继承
面向对象三大特性:封装、继承、多态 RE: 封装 C把数据和方法封装在类里面迭代器和适配器 继承 1 基类 & 派生类 一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。定义一个派生类,我们使用一个类派生列表…...

轻松应对意外丢失:高效电脑数据恢复指南!
有时候由于误操作、硬件故障、病毒攻击等原因,电脑里的重要文件可能会突然消失不见。面对这样的情况,很多人会感到手足无措。其实,借助专业的电脑数据恢复软件,我们可以较为轻松地找回丢失的数据。今天,我们就来介绍几…...

vue项目中播放rtsp视频流
一、下载webrtc-streamer 下载地址:https://github.com/mpromonet/webrtc-streamer/releases 根据设备型号下载对应的版本到本地直接解压就行,我下载的是webrtc-streamer-v0.8.6-dirty-Windows-AMD64-Release.tar版本。 双击webrtc-streamer.exe可执行文…...

tomcat部署web配置环境变量
在Tomcat中设置环境变量通常涉及以下步骤: 找到Tomcat的启动脚本(如catalina.sh或catalina.bat)。 在启动脚本中设置环境变量。 对于catalina.sh(Linux/Unix系统),你可以在文件顶部添加环境变量…...
)
数据仓库技术及应用(练习1)
1.创表 (1)customers.csv CREATE EXTERNAL TABLE IF NOT EXISTS customers ( customer_id int, customer_fname varchar(45), customer_lname varchar(45), customer_email varchar(45), customer_password varchar(45), customer_street …...

老板的“神助攻”:公司电脑监控软件
在当今的商业世界中,企业管理者都希望员工能全身心投入工作,为企业创造更多价值。然而,员工上班摸鱼的现象却让许多老板头疼不已。公司电脑监控软件的出现,为解决这一问题提供了可能。接下来,我们将详细介绍几款优质的…...

前端vue部署网站
这里讲解一下前端vue框架部署网站,使用工具是 xshell 和 xftp (大家去官网安装免费版的就行了) 服务器 我使用的阿里云服务器,买的是 99 一年的,淘宝有新手9.9 一个月服务器。可以去用,学生的话是有免费三…...

Unity3D 动画回调函数详解
在Unity3D中,动画回调函数是实现精细动画效果的重要工具。通过动画回调函数,我们可以在动画的特定时刻执行自定义代码,从而实现更加灵活和复杂的动画效果。本文将详细解释Unity3D中的动画回调函数,并提供相应的代码实现。 对惹&a…...

el-table表格表尾合计行,指定合计某几列,自定义合计方法
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回&#…...
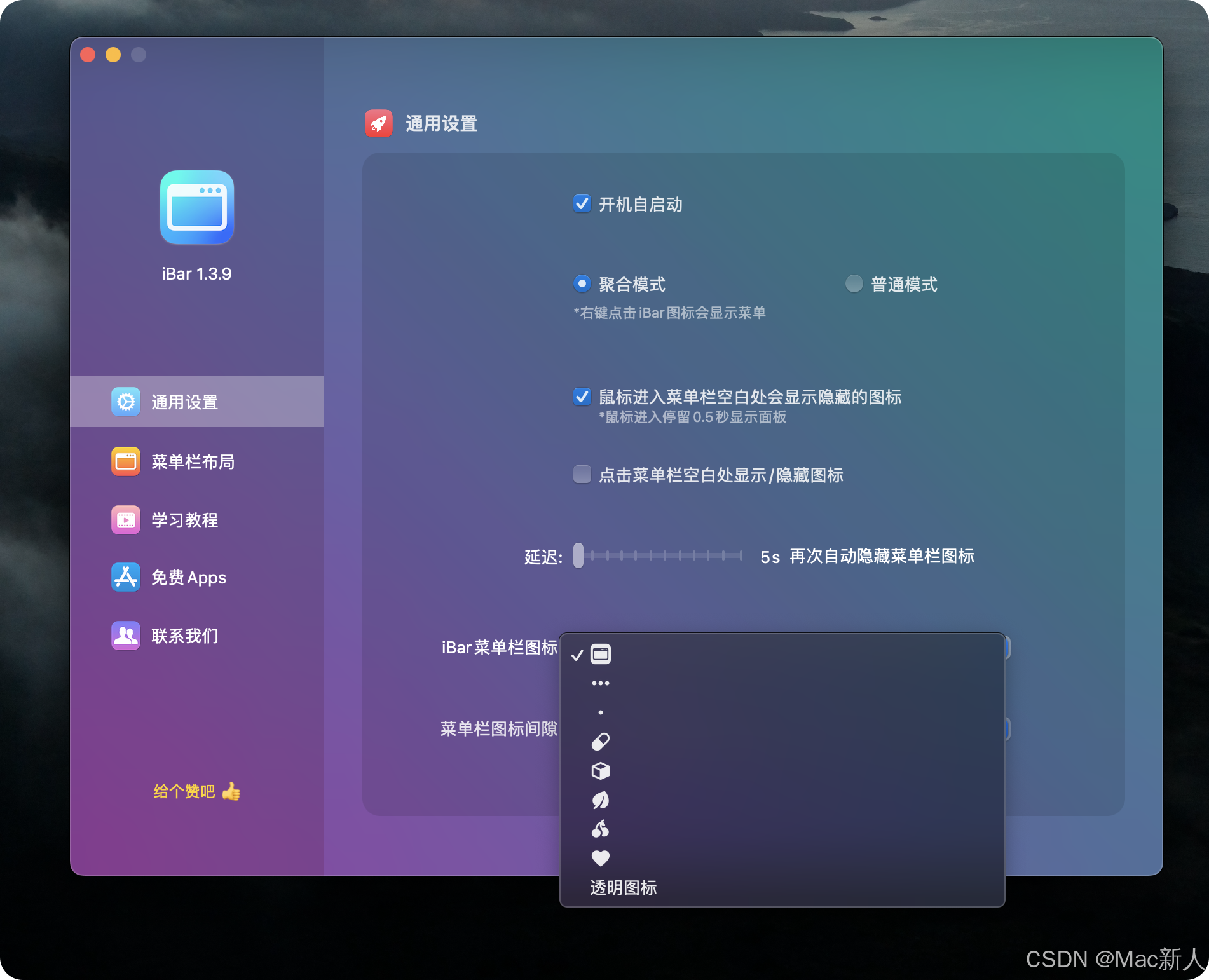
一款工具替你解决Mac电脑菜单栏图标杂乱问题
你的菜单栏是不是各种图标挤在一起?图标过多显得杂乱?刘海屏遮挡菜单栏图标?教你如何让你的菜单栏变的简洁美观 iBar,一款Mac上优秀的菜单栏管理工具,可以自主选择菜单栏图标隐藏,单独窗口聚合展示&#x…...

MySQL 基础入门教程
参考视频地址:一小时MySQL教程 bilibili SQL 基础 数据库分为关系型数据库和非关系型数据库 常见的关系型数据库: MySQL、PostgreSQL、Oracle、SQL Server等。 非关系型数据库: MongoDB(文档型数据库)、Redis&am…...

俏生元将传统膳食智慧融入现代生活,自然成分绽放健康光彩
近年来,当代女性健康食品市场正经历快速发展和显著变化。随着女性健康意识的提升,市场对专门针对女性健康的产品需求快速上升。女性消费者对健康的关注不再局限于表面,而是越来越注重内在健康和生活质量的提升。此外,中式养生文化…...

腾讯云推流播放相关
直播的在线人数是否有上限? 腾讯云直播默认不限制观看直播的在线人数,只要网络等条件允许都可以观看直播。如果用户配置了带宽限制,当观看人数过多、超出了限制带宽时新的用户无法观看,此情况下在线人数是有限制的。 如何使用播…...

UE5运行时动态加载场景角色动画任意搭配-相机及运镜(二)
通过《MMD模型及动作一键完美导入UE5》系列文章,我们可以把外部场景、角色、动画资产导入UE5,接下来我们将实现运行时动态加载这些资产,并任意组合搭配。 1、运行时播放相机动画 1、创建1个BlueprintActor,通过这个蓝图动态创建1个LevelSequence,并Play 2、将这个Bluep…...

@JsonAlias和@JSONField序列化和反序列化
com.fasterxml.jackson.annotation.JsonAlias("expressCode") com.alibaba.fastjson.annotation.JSONField(name "expressCode") 这两个注解分别属于不同的JSON序列化框架:Jackson 和 Fastjson,它们的用途是处理JSON字段的名称映射…...

k8s1.27部署ingress 1.11.2
k8s1.27部署ingress 1.11.2 要求: 1、使用主机网络。 2、多节点部署,以来标签:isingressistrue ingress1.11.2支持版本 官方参考链接: https://github.com/kubernetes/ingress-nginx/ 官网yaml https://raw.githubuserconten…...

【运维】自动化运维详解
目录 引言一、什么是自动化运维?二、自动化运维的优势三、自动化运维的关键组成部分详解3.1 监控与告警3.2 部署与配置管理3.3 备份与恢复3.4 安全管理 总结 引言 在当今信息技术飞速发展的时代,企业对IT基础设施的依赖日益增强,传统的人工运…...

线控底盘技术介绍
随着汽车工业的不断发展,传统的机械控制系统逐渐向电子控制系统转变。线控底盘(Drive-by-Wire Chassis)作为这一转变的重要组成部分,正在改变汽车的操控方式和驾驶体验。本文将全面介绍线控底盘的概念、组成、工作原理、优缺点、应…...

Fast-GitHub:智能网络优化架构解析与分布式加速方案
Fast-GitHub:智能网络优化架构解析与分布式加速方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 在国内开发者面临G…...

手把手教你用Vivado配置Xilinx SEM IP 3.1:从IP Catalog到Tera Term串口调试全流程
手把手教你用Vivado配置Xilinx SEM IP 3.1:从IP Catalog到Tera Term串口调试全流程 在FPGA开发中,软错误缓解(SEM)IP核是确保设计可靠性的关键组件。对于使用Xilinx Artix-7系列芯片的工程师来说,掌握SEM IP的完整配置…...

10分钟带你完成:Claude Code CC Switch 接入DeepSeek-V4
文章目录概要环境要求整体流程概要 本项目在 Windows 环境下,如何让强大的 AI 编程助手 Claude Code 成功“变身”,接入国产顶尖大模型 DeepSeek-V4。通过利用 DeepSeek 的 API 兼容性,不仅保留了 Claude Code 极致的终端交互体验…...

显卡驱动彻底清理指南:DDU工具拯救你的显示问题![特殊字符]
显卡驱动彻底清理指南:DDU工具拯救你的显示问题!🚀 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-d…...

NY345固态MT29F32T08GWLBHD6-24T:B
NY345固态MT29F32T08GWLBHD6-24T:B在智能制造、交通控制、能源监测等关键领域,每一次写入与读取都决定着系统运行的可靠性。美光(Micron)MT29F32T08GWLBHD6-24T:B,以其32Tb大容量、工业级封装和多模式灵活切换,成为嵌入…...

HNU 计算机系统 bomblab:从GDB断点到链表重构的逆向实战
1. 逆向工程实战:从零开始拆解二进制炸弹 第一次接触bomblab时,我盯着终端里那个名为"bomb"的可执行文件发呆了十分钟。这个看似普通的Linux程序就像个黑盒子,里面藏着六个需要密码才能解除的"炸弹"。作为计算机系统课程…...

QGIS工程文件.QGZ与.QGS到底怎么选?从团队协作到版本控制的完整避坑指南
QGIS工程文件.QGZ与.QGS深度对比:团队协作与版本控制的最佳实践 当你在QGIS中完成一天的工作,点击保存按钮时,系统默认会生成.QGZ格式的文件。但你是否想过,这个看似简单的选择可能会影响未来团队协作的效率?在GIS项目…...

告别光流计算!用PyTorch复现MotionNet,5分钟搞定视频动作识别
5分钟实现视频动作识别:PyTorch版MotionNet实战指南 在咖啡还没凉透的间隙里,让AI看懂视频动作——这曾是计算机视觉领域最耗时的任务之一。传统双流网络需要预计算光流,像手工制作意大利面般繁琐;而2017年问世的MotionNet就像发…...

TLV320AIC3254音频编解码器:从DSP算法到低功耗设计的嵌入式开发全解析
1. 项目概述:从一颗音频编解码器芯片说起最近在做一个需要高保真音频采集与播放的项目,选型时又一次把目光投向了德州仪器(TI)的音频编解码器产品线。这次的主角是TLV320AIC3254,一颗在专业音频、消费电子和工业领域都…...

第11篇 安全配置实战:SASL_SSL + SCRAM-SHA-512
第11篇:安全配置实战 —— SASL_SSL + SCRAM-SHA-512 生产落地 系列:Kafka Spring Boot:参数精讲与生产落地实战 本篇关键词:security.protocol SASL SCRAM-SHA-512 SSL TrustStore 生产安全配置 📌 本篇导读 内网开发环境用 PLAINTEXT 完全没问题。但一旦涉及: 云…...