毕设分享 大数据用户画像分析系统(源码分享)
文章目录
- 0 前言
- 2 用户画像分析概述
- 2.1 用户画像构建的相关技术
- 2.2 标签体系
- 2.3 标签优先级
- 3 实站 - 百货商场用户画像描述与价值分析
- 3.1 数据格式
- 3.2 数据预处理
- 3.3 会员年龄构成
- 3.4 订单占比 消费画像
- 3.5 季度偏好画像
- 3.6 会员用户画像与特征
- 3.6.1 构建会员用户业务特征标签
- 3.6.2 会员用户词云分析
- 4 最后
0 前言
Hi,大家好,这里是丹成学长,今天做一个电商销售预测分析,这只是一个demo,尝试对电影数据进行分析,并可视化系统
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 大数据用户画像分析系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 项目分享:见文末!
实现效果
毕业设计 大数据用户行为分析
https://www.bilibili.com/video/BV1Hc41187N3
2 用户画像分析概述
用户画像是指根据用户的属性、用户偏好、生活习惯、用户行为等信息而抽象出来的标签化用户模型。通俗说就是给用户打标签,而标签是通过对用户信息分析而来的高度精炼的特征标识。通过打标签可以利用一些高度概括、容易理解的特征来描述用户,可以让人更容易理解用户,并且可以方便计算机处理。

标签化就是数据的抽象能力
- 互联网下半场精细化运营将是长久的主题
- 用户是根本,也是数据分析的出发点
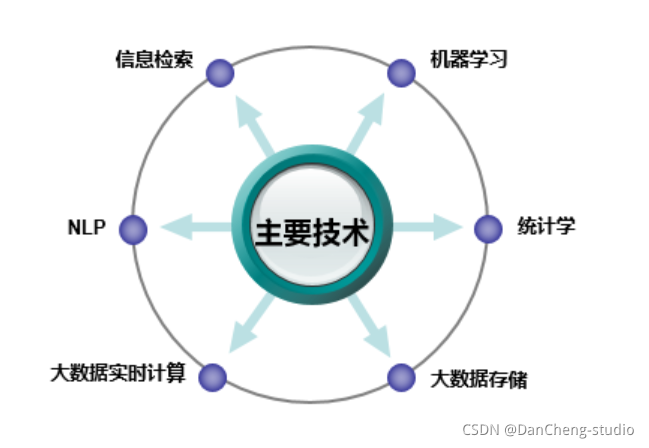
2.1 用户画像构建的相关技术
我们对构建用户画像的方法进行总结归纳,发现用户画像的构建一般可以分为目标分析、体系构建、画像建立三步。
画像构建中用到的技术有数据统计、机器学习和自然语言处理技术(NLP)等,下如图所示。具体的画像构建方法学长会在后面的部分详细介绍。
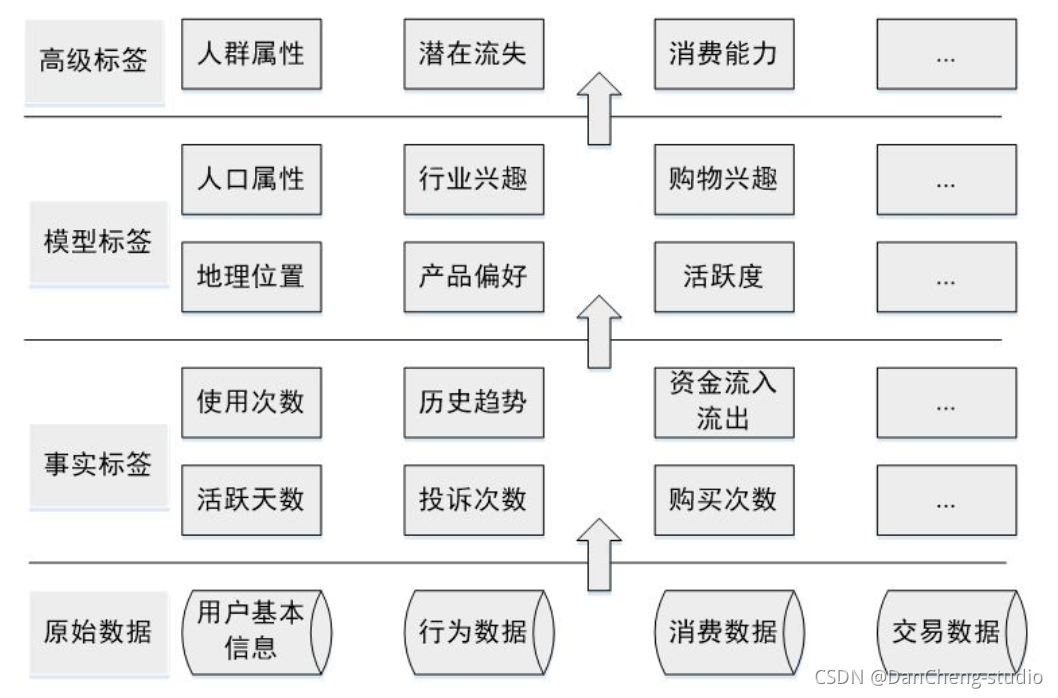
按照数据流处理阶段划分用户画像建模的过程,分为三个层,每一层次,都需要打上不同的标签。
- 数据层:用户消费行为的标签。打上事实标签,作为数据客观的记录
- 算法层:透过行为算出的用户建模。打上模型标签,作为用户画像的分类
- 业务层:指的是获客、粘客、留客的手段。打上预测标签,作为业务关联的结果
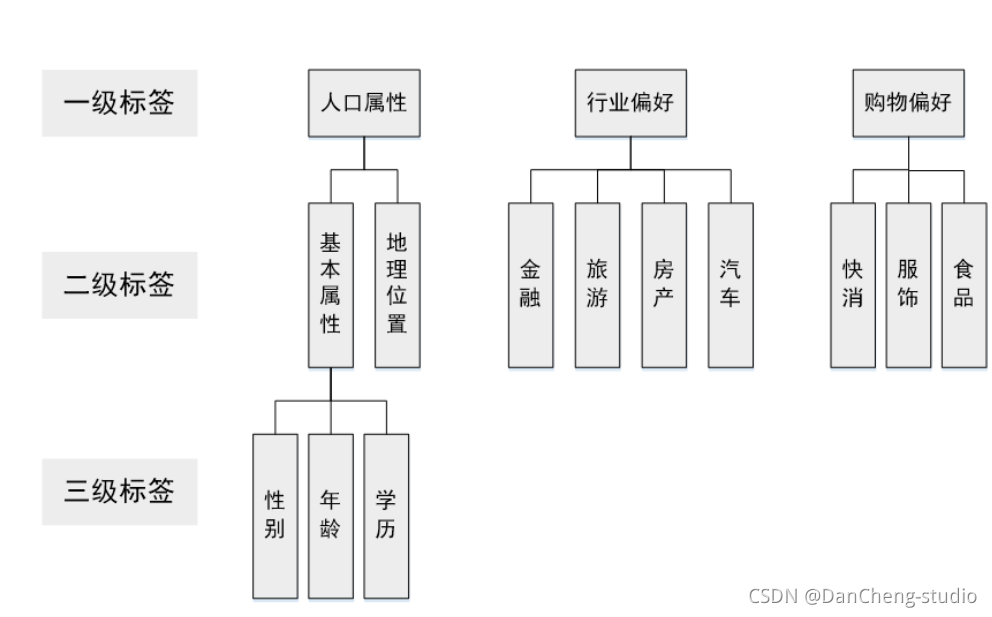
2.2 标签体系
目前主流的标签体系都是层次化的,如下图所示。首先标签分为几个大类,每个大类下进行逐层细分。在构建标签时,我们只需要构建最下层的标签,就能够映射到上面两级标签。
上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例如我们可以统计有人口属性标签的用户比例,但用户有人口属性标签本身对广告投放没有任何意义。
2.3 标签优先级
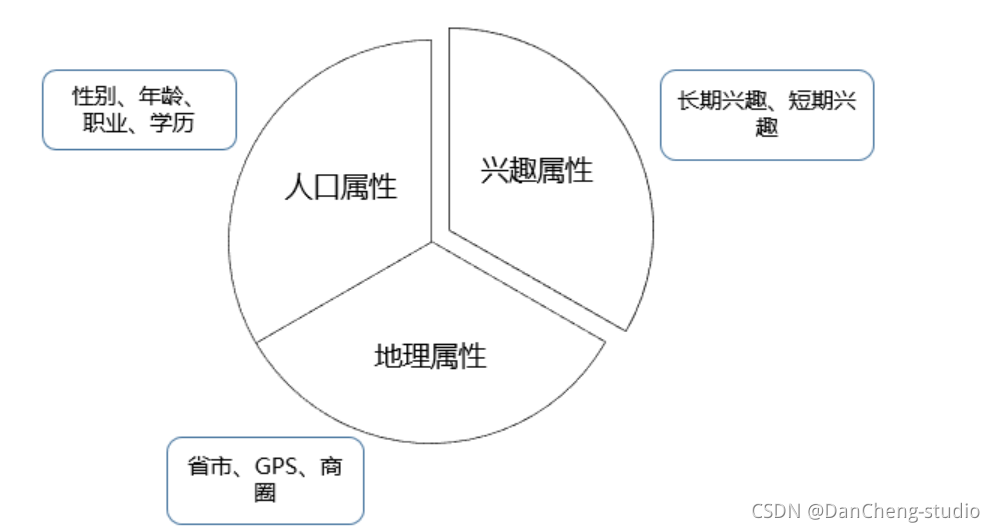
构建的优先级需要综合考虑业务需求、构建难易程度等,业务需求各有不同,这里介绍的优先级排序方法主要依据构建的难易程度和各类标签的依存关系,优先级如下图所示:
我们把标签分为三类,这三类标签有较大的差异,构建时用到的技术差别也很大。第一类是人口属性,这一类标签比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定;第二类是兴趣属性,这类标签随时间变化很快,标签有很强的时效性,标签体系也不固定;第三类是地理属性,这一类标签的时效性跨度很大,如GPS轨迹标签需要做到实时更新,而常住地标签一般可以几个月不用更新,挖掘的方法和前面两类也大有不同,如图所示:
3 实站 - 百货商场用户画像描述与价值分析
3.1 数据格式
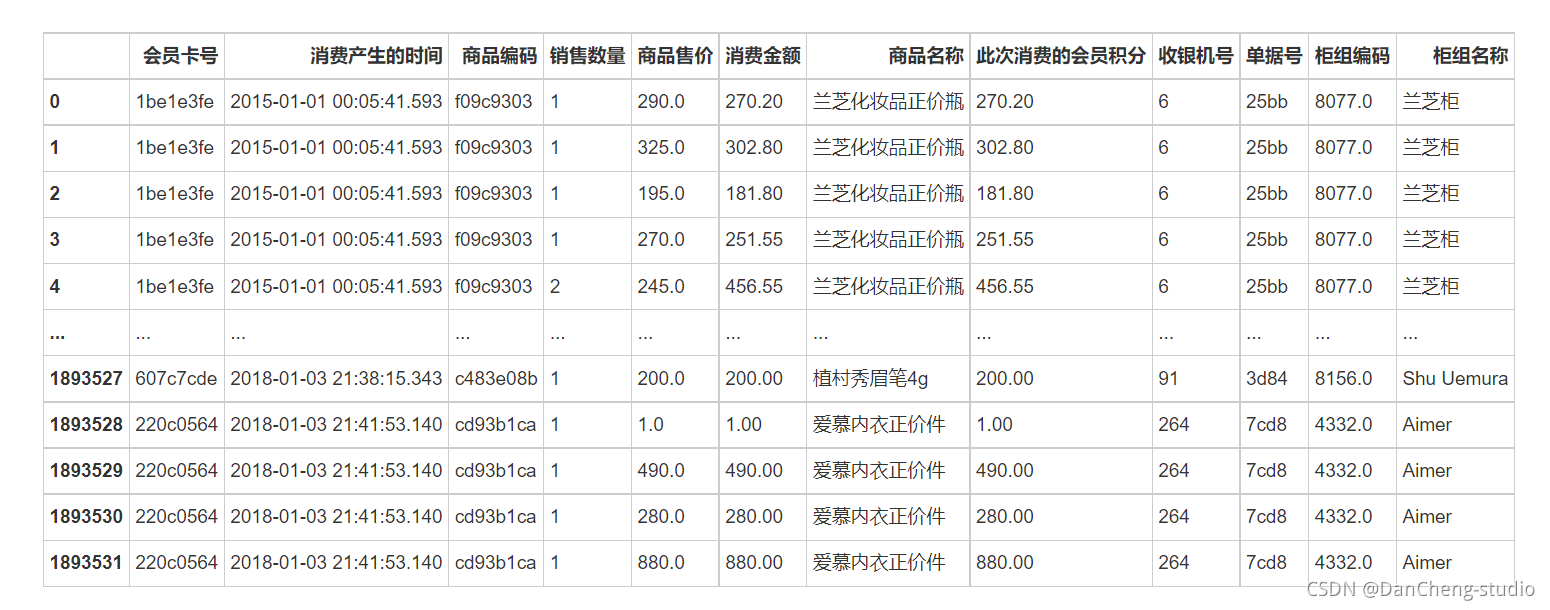
3.2 数据预处理
部分代码
# 作者:丹成学长 Q746876041
import matplotlib
import warnings
import re
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as pltfrom sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler, MinMaxScaler%matplotlib inline
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
matplotlib.rcParams.update({'font.size' : 16})
plt.style.use('ggplot')
warnings.filterwarnings('ignore')df_cum = pd.read_excel('./cumcm2018c1.xlsx')
df_cum
# 先来对会员信息表进行分析
print('会员信息表一共有{}行记录,{}列字段'.format(df_cum.shape[0], df_cum.shape[1]))
print('数据缺失的情况为:\n{}'.format(df_cum.isnull().mean()))
print('会员卡号(不重复)有{}条记录'.format(len(df_cum['会员卡号'].unique())))# 会员信息表去重
df_cum.drop_duplicates(subset = '会员卡号', inplace = True)
print('会员卡号(去重)有{}条记录'.format(len(df_cum['会员卡号'].unique())))# 去除登记时间的缺失值,不能直接dropna,因为我们需要保留一定的数据集进行后续的LRFM建模操作
df_cum.dropna(subset = ['登记时间'], inplace = True)
print('df_cum(去重和去缺失)有{}条记录'.format(df_cum.shape[0]))# 性别上缺失的比例较少,所以下面采用众数填充的方法
df_cum['性别'].fillna(df_cum['性别'].mode().values[0], inplace = True)
df_cum.info()# 由于出生日期这一列的缺失值过多,且存在较多的异常值,不能贸然删除
# 故下面另建一个数据集L来保存“出生日期”和“性别”信息,方便下面对会员的性别和年龄信息进行统计
L = pd.DataFrame(df_cum.loc[df_cum['出生日期'].notnull(), ['出生日期', '性别']])
L['年龄'] = L['出生日期'].astype(str).apply(lambda x: x[:3] + '0')
L.drop('出生日期', axis = 1, inplace = True)
L['年龄'].value_counts()
...(略)....
3.3 会员年龄构成
# 使用上述预处理后的数据集L,包含两个字段,分别是“年龄”和“性别”,先画出年龄的条形图
fig, axs = plt.subplots(1, 2, figsize = (16, 7), dpi = 100)
# 绘制条形图
ax = sns.countplot(x = '年龄', data = L, ax = axs[0])
# 设置数字标签
for p in ax.patches:height = p.get_height()ax.text(x = p.get_x() + (p.get_width() / 2), y = height + 500, s = '{:.0f}'.format(height), ha = 'center')
axs[0].set_title('会员的出生年代')
# 绘制饼图
axs[1].pie(sex_sort, labels = sex_sort.index, wedgeprops = {'width': 0.4}, counterclock = False, autopct = '%.2f%%', pctdistance = 0.8)
axs[1].set_title('会员的男女比例')
plt.savefig('./会员出生年代及男女比例情况.png')

# 绘制各个年龄段的饼图
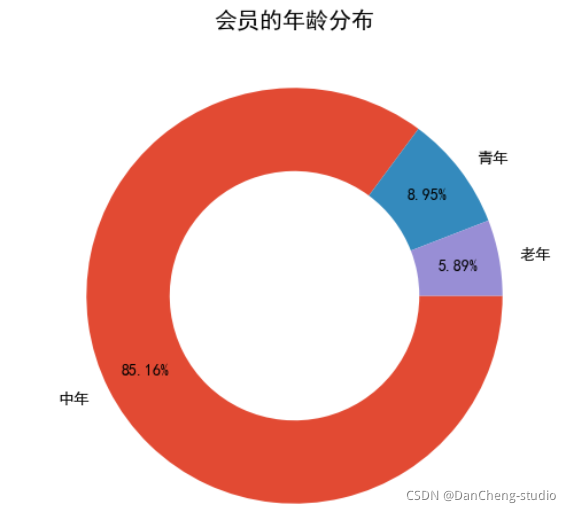
plt.figure(figsize = (8, 6), dpi = 100)
plt.pie(res.values, labels = ['中年', '青年', '老年'], autopct = '%.2f%%', pctdistance = 0.8, counterclock = False, wedgeprops = {'width': 0.4})
plt.title('会员的年龄分布')
plt.savefig('./会员的年龄分布.png')
3.4 订单占比 消费画像
# 由于相同的单据号可能不是同一笔消费,以“消费产生的时间”为分组依据,我们可以知道有多少个不同的消费时间,即消费的订单数
fig, axs = plt.subplots(1, 2, figsize = (12, 7), dpi = 100)
axs[0].pie([len(df1.loc[df1['会员'] == 1, '消费产生的时间'].unique()), len(df1.loc[df1['会员'] == 0, '消费产生的时间'].unique())],labels = ['会员', '非会员'], wedgeprops = {'width': 0.4}, counterclock = False, autopct = '%.2f%%', pctdistance = 0.8)
axs[0].set_title('总订单占比')
axs[1].pie([df1.loc[df1['会员'] == 1, '消费金额'].sum(), df1.loc[df1['会员'] == 0, '消费金额'].sum()], labels = ['会员', '非会员'], wedgeprops = {'width': 0.4}, counterclock = False, autopct = '%.2f%%', pctdistance = 0.8)
axs[1].set_title('总消费金额占比')
plt.savefig('./总订单和总消费占比情况.png')
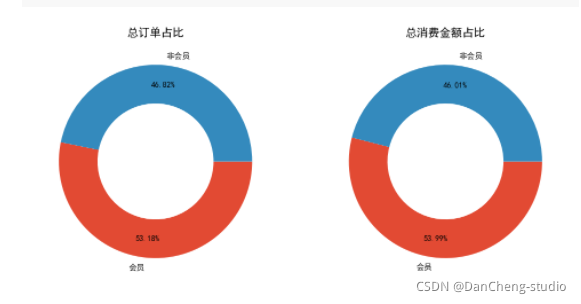
消费偏好:
我觉得会稍微偏向与消费的频次,相当于消费的订单数,因为每笔消费订单其中所包含的消费商品和金额都是不太一样的,有的订单所消费的商品很少,但金额却很大,有的消费的商品很多,但金额却特别少。如果单纯以总金额来衡量的话,会员下次消费时间可能会很长,消费频次估计也会相对变小(因为这次所购买的商品已经足够用了)。所以我会偏向于认为一个用户消费频次(订单数)越多,就越能带来更多的价值,从另一方面上来讲,用户也不可能一直都是消费低端产品,消费频次越多用户的粘性也会相对比较大
3.5 季度偏好画像
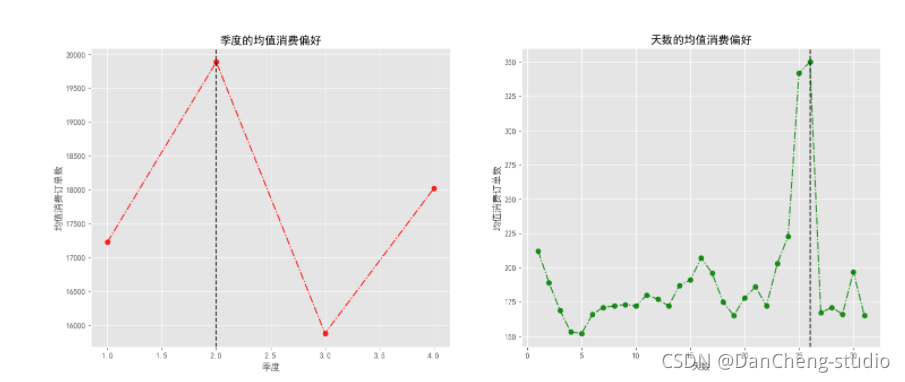
# 前提假设:2015-2018年之间,消费者偏好在时间上不会发生太大的变化(均值),消费偏好——>以不同时间的订单数来衡量
quarters_list, quarters_order = orders(df_vip, '季度', 3)
days_list, days_order = orders(df_vip, '天', 36)
time_list = [quarters_list, days_list]
order_list = [quarters_order, days_order]
maxindex_list = [quarters_order.index(max(quarters_order)), days_order.index(max(days_order))]
fig, axs = plt.subplots(1, 2, figsize = (18, 7), dpi = 100)
colors = np.random.choice(['r', 'g', 'b', 'orange', 'y'], replace = False, size = len(axs))
titles = ['季度的均值消费偏好', '天数的均值消费偏好']
labels = ['季度', '天数']
for i in range(len(axs)):ax = axs[i]ax.plot(time_list[i], order_list[i], linestyle = '-.', c = colors[i], marker = 'o', alpha = 0.85)ax.axvline(x = time_list[i][maxindex_list[i]], linestyle = '--', c = 'k', alpha = 0.8)ax.set_title(titles[i])ax.set_xlabel(labels[i])ax.set_ylabel('均值消费订单数')print(f'{titles[i]}最优的时间为: {time_list[i][maxindex_list[i]]}\t 对应的均值消费订单数为: {order_list[i][maxindex_list[i]]}')
plt.savefig('./季度和天数的均值消费偏好情况.png')
# 自定义函数来绘制不同年份之间的的季度或天数的消费订单差异
def plot_qd(df, label_y, label_m, nrow, ncol):"""df: 为DataFrame的数据集label_y: 为年份的字段标签label_m: 为标签的一个列表n_row: 图的行数n_col: 图的列数"""# 必须去掉最后一年的数据,只能对2015-2017之间的数据进行分析y_list = np.sort(df[label_y].unique().tolist())[:-1]colors = np.random.choice(['r', 'g', 'b', 'orange', 'y', 'k', 'c', 'm'], replace = False, size = len(y_list))markers = ['o', '^', 'v']plt.figure(figsize = (8, 6), dpi = 100)fig, axs = plt.subplots(nrow, ncol, figsize = (16, 7), dpi = 100)for k in range(len(label_m)):m_list = np.sort(df[label_m[k]].unique().tolist())for i in range(len(y_list)):order_m = []index1 = df[label_y] == y_list[i]for j in range(len(m_list)):index2 = df[label_m[k]] == m_list[j]order_m.append(len(df.loc[index1 & index2, '消费产生的时间'].unique()))axs[k].plot(m_list, order_m, linestyle ='-.', c = colors[i], alpha = 0.8, marker = markers[i], label = y_list[i], markersize = 4)axs[k].set_xlabel(f'{label_m[k]}')axs[k].set_ylabel('消费订单数')axs[k].set_title(f'2015-2018年会员的{label_m[k]}消费订单差异')axs[k].legend()plt.savefig(f'./2015-2018年会员的{"和".join(label_m)}消费订单差异.png')
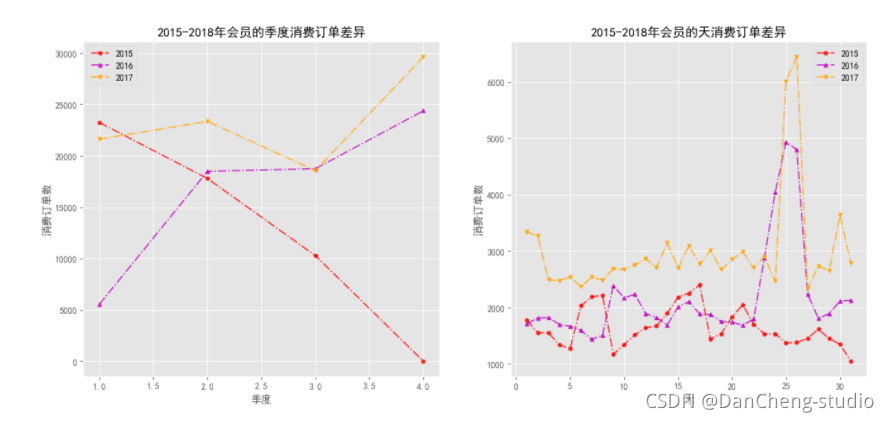
# 自定义函数来绘制不同年份之间的月份消费订单差异
def plot_ym(df, label_y, label_m):"""df: 为DataFrame的数据集label_y: 为年份的字段标签label_m: 为月份的字段标签"""# 必须去掉最后一年的数据,只能对2015-2017之间的数据进行分析y_list = np.sort(df[label_y].unique().tolist())[:-1]m_list = np.sort(df[label_m].unique().tolist())colors = np.random.choice(['r', 'g', 'b', 'orange', 'y'], replace = False, size = len(y_list))markers = ['o', '^', 'v']fig, axs = plt.subplots(1, 2, figsize = (18, 8), dpi = 100)for i in range(len(y_list)):order_m = []money_m = []index1 = df[label_y] == y_list[i]for j in range(len(m_list)):index2 = df[label_m] == m_list[j]order_m.append(len(df.loc[index1 & index2, '消费产生的时间'].unique()))money_m.append(df.loc[index1 & index2, '消费金额'].sum())axs[0].plot(m_list, order_m, linestyle ='-.', c = colors[i], alpha = 0.8, marker = markers[i], label = y_list[i])axs[1].plot(m_list, money_m, linestyle ='-.', c = colors[i], alpha = 0.8, marker = markers[i], label = y_list[i])axs[0].set_xlabel('月份')axs[0].set_ylabel('消费订单数')axs[0].set_title('2015-2018年会员的消费订单差异')axs[1].set_xlabel('月份')axs[1].set_ylabel('消费金额总数')axs[1].set_title('2015-2018年会员的消费金额差异')axs[0].legend()axs[1].legend()plt.savefig('./2015-2018年会员的消费订单和金额差异.png')
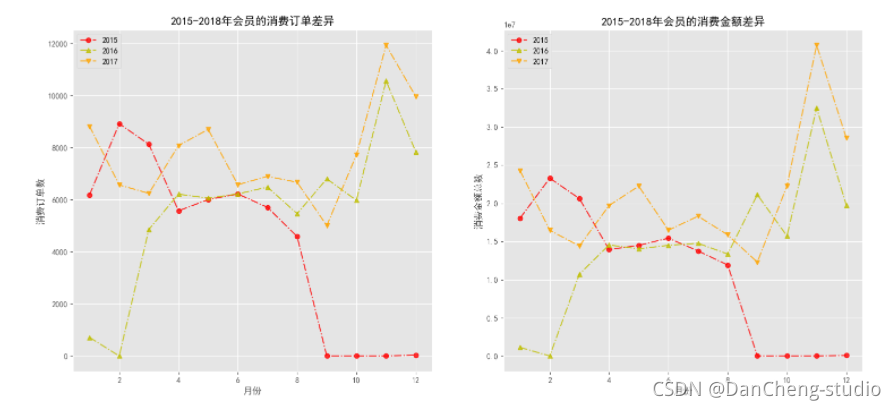
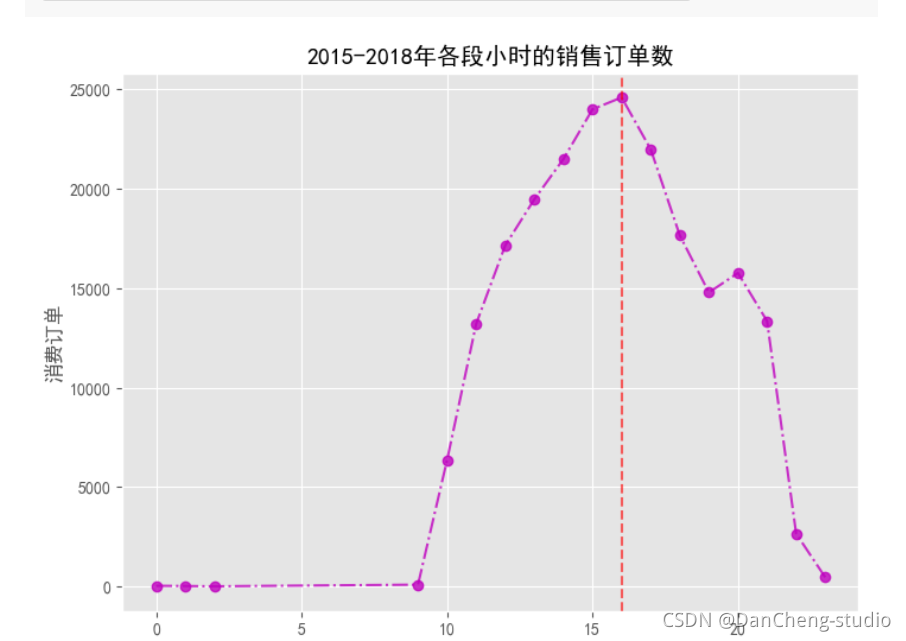
maxindex = order_nums.index(max(order_nums))
plt.figure(figsize = (8, 6), dpi = 100)
plt.plot(x_list, order_nums, linestyle = '-.', marker = 'o', c = 'm', alpha = 0.8)
plt.xlabel('小时')
plt.ylabel('消费订单')
plt.axvline(x = x_list[maxindex], linestyle = '--', c = 'r', alpha = 0.6)
plt.title('2015-2018年各段小时的销售订单数')
plt.savefig('./2015-2018年各段小时的销售订单数.png')
3.6 会员用户画像与特征
3.6.1 构建会员用户业务特征标签
# 取DataFrame之后转置取values得到一个列表,再绘制对应的词云,可以自定义一个绘制词云的函数,输入参数为df和会员卡号
"""
L: 入会程度(新用户、中等用户、老用户)
R: 最近购买的时间(月)
F: 消费频数(低频、中频、高频)
M: 消费总金额(高消费、中消费、低消费)
P: 积分(高、中、低)
S: 消费时间偏好(凌晨、上午、中午、下午、晚上)
X:性别
"""# 开始对数据进行分组
"""
L(入会程度):3个月以下为新用户,4-12个月为中等用户,13个月以上为老用户
R(最近购买的时间)
F(消费频次):次数20次以上的为高频消费,6-19次为中频消费,5次以下为低频消费
M(消费金额):10万以上为高等消费,1万-10万为中等消费,1万以下为低等消费
P(消费积分):10万以上为高等积分用户,1万-10万为中等积分用户,1万以下为低等积分用户
"""
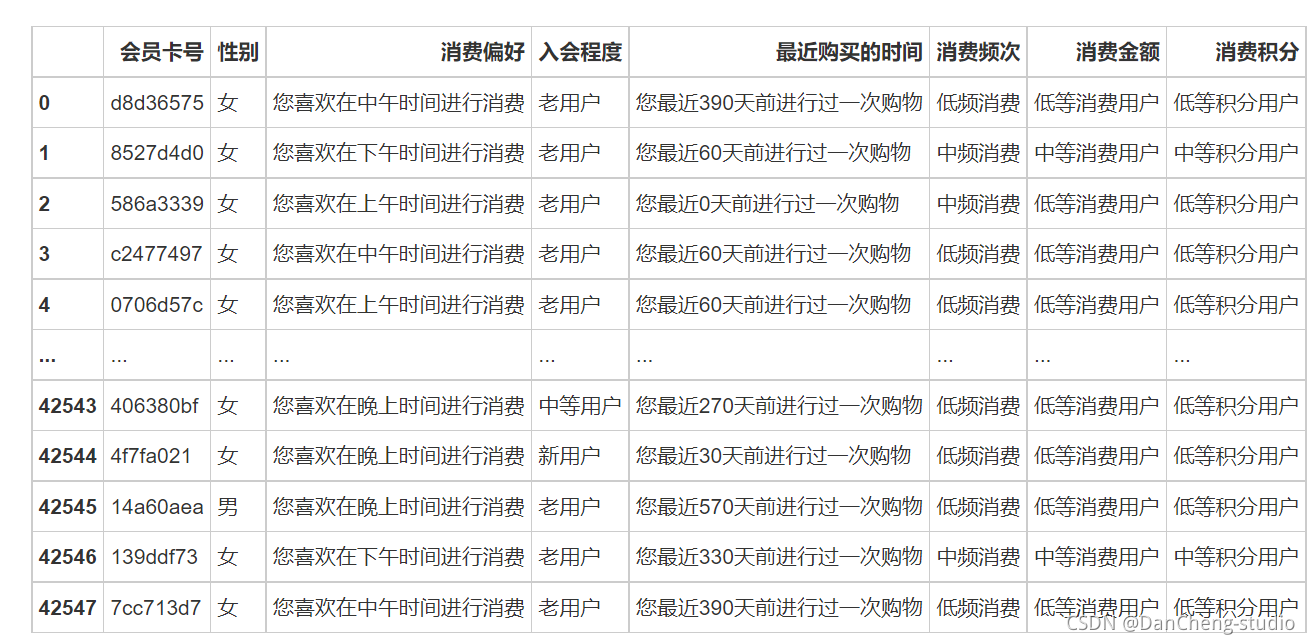
df_profile = pd.DataFrame()
df_profile['会员卡号'] = df['id']
df_profile['性别'] = df['X']
df_profile['消费偏好'] = df['S'].apply(lambda x: '您喜欢在' + str(x) + '时间进行消费')
df_profile['入会程度'] = df['L'].apply(lambda x: '老用户' if int(x) >= 13 else '中等用户' if int(x) >= 4 else '新用户')
df_profile['最近购买的时间'] = df['R'].apply(lambda x: '您最近' + str(int(x) * 30) + '天前进行过一次购物')
df_profile['消费频次'] = df['F'].apply(lambda x: '高频消费' if x >= 20 else '中频消费' if x >= 6 else '低频消费')
df_profile['消费金额'] = df['M'].apply(lambda x: '高等消费用户' if int(x) >= 1e+05 else '中等消费用户' if int(x) >= 1e+04 else '低等消费用户')
df_profile['消费积分'] = df['P'].apply(lambda x: '高等积分用户' if int(x) >= 1e+05 else '中等积分用户' if int(x) >= 1e+04 else '低等积分用户')
df_profile
3.6.2 会员用户词云分析
# 开始绘制用户词云,封装成一个函数来直接显示词云
def wc_plot(df, id_label = None):"""df: 为DataFrame的数据集id_label: 为输入用户的会员卡号,默认为随机取一个会员进行展示"""myfont = 'C:/Windows/Fonts/simkai.ttf'if id_label == None:id_label = df.loc[np.random.choice(range(df.shape[0])), '会员卡号']text = df[df['会员卡号'] == id_label].T.iloc[:, 0].values.tolist()plt.figure(dpi = 100)wc = WordCloud(font_path = myfont, background_color = 'white', width = 500, height = 400).generate_from_text(' '.join(text))plt.imshow(wc)plt.axis('off')plt.savefig(f'./会员卡号为{id_label}的用户画像.png')plt.show()


4 最后
🧿 项目分享:见文末!
相关文章:
毕设分享 大数据用户画像分析系统(源码分享)
文章目录 0 前言2 用户画像分析概述2.1 用户画像构建的相关技术2.2 标签体系2.3 标签优先级 3 实站 - 百货商场用户画像描述与价值分析3.1 数据格式3.2 数据预处理3.3 会员年龄构成3.4 订单占比 消费画像3.5 季度偏好画像3.6 会员用户画像与特征3.6.1 构建会员用户业务特征标签…...

使用 Redis 实现分布式锁:原理、实现与优化
在分布式系统中,分布式锁是确保多个进程或线程在同一时间内对共享资源进行互斥访问的重要机制。Redis 作为一个高性能的内存数据库,提供了多种实现分布式锁的方式。本文将详细介绍如何使用 Redis 实现分布式锁,包括基本原理、实现方法、示例代…...

Android常用C++特性之std::make_pair
声明:本文内容生成自ChatGPT,目的是为方便大家了解学习作为引用到作者的其他文章中。 std::make_pair 是 C 标准库中的一个函数模板,用于创建一个 std::pair 对象。std::pair 是一种可以存储两个不同类型值的简单数据结构,类似于二…...

Kafka-参数详解
一、上下文 从《Kafka-初识》中可以看到运行kafka-console-producer和 kafka-console-consumer来生产和消费数据时会打印很多参数,这些参数给我们应对多种场景提供了遍历,除了producer和consumer的提供了参数外,Kafka服务器集群中的broker也…...

Docker Overlay2 空间优化
目录 分析优化数据路径规划日志大小限制overlay2 大小限制清理冗余数据 总结 分析 overlay2 目录占用磁盘空间较大的原因通常与 Docker 容器和镜像的存储机制以及它们的长期累积相关,其实我之前在 Docker 原理那里已经提到过了。 通常时以下几种原因导致ÿ…...

第 3 章:使用 Vue 脚手架
1. 初始化脚手架 1.1 说明 Vue 脚手架是 Vue 官方提供的标准化开发工具(开发平台)。最新的版本是 5.x。文档: https://cli.vuejs.org/zh/ 1.2 具体步骤 第一步(仅第一次执行):全局安装vue/cli。 npm install -g vu…...

Spring 循环依赖详解:问题分析与三级缓存解决方案
在Spring框架中,循环依赖(Circular Dependency)是指多个Bean相互依赖,形成一个循环引用。例如,Bean A依赖于Bean B,而Bean B又依赖于Bean A。这种情况在Bean创建时可能导致Spring容器无法正常完成初始化&am…...

爬虫prc技术----小红书爬取解决xs
知识星球:知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具知识星球是创作者连接铁杆粉丝,实现知识变现的工具。任何从事创作或艺术的人,例如艺术家、工匠、教师、学术研究、科普等,只要能获得一…...

uni-app之旅-day06-加入购物车
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言8.0 创建 cart 分支8.1 配置 vuex8.2 创建购物车的 store 模块8.3 在商品详情页中使用 Store 中的数据8.4 实现加入购物车的功能8.5 动态统计购物车中商品的总数…...

【Kubernetes】常见面试题汇总(五十六)
目录 123. pod 创建失败? 124. kube-flannel-ds-amd64-ndsf7 插件 pod 的 status 为 Init:0/1 ? 特别说明: 题目 1-68 属于【Kubernetes】的常规概念题,即 “ 汇总(一)~(二十二&#x…...
LabVIEW激光诱导击穿光谱识别与分析系统
LabVIEW激光诱导击穿光谱(LIBS)分析系统利用高能量脉冲激光产生高温等离子体,通过分析等离子体发出的光谱来定性分析样品中的元素种类。该系统的开发集成了软件与硬件的设计,实现了自动识别和定性分析功能,适用于环境监…...

Redis的基础篇
Redis的基础篇 1.在CentOs7上安装Redis(最好不要在windows上装,版本少) 1.安装gcc --> yum install gcc tcl(可能会报错,重新安装yum就行了) 2.下载redis --> 最好是6.2上的版本 3.解压redis --> tar -zxvf redis-6.2.…...

java和python哪个好
Java和Python各有优缺点,适合不同的应用场景,具体看你需要在哪种情况下使用编程语言。以下是Java和Python的一些对比,帮助你决定哪种更适合你的需求: 性能 Java:编译型语言,编译成字节码运行在Java虚拟机&…...

Electron + ts + vue3 + vite
正常搭建脚手架:npm create vitelatest 项目名称 安装electron的相关依赖:注:安装时终端url要项目名那一层 安装npm install electron -D安装打包工具:npm install electron-builder -D开发工具:npm install electron-…...

《大规模语言模型从理论到实践》第一轮学习--分布式训练
基础知识 5分钟看懂电脑硬件配置 - 知乎 (zhihu.com) 显存 定义:显存是显卡上的专用高速缓存,用于存储图形处理器(GPU)在处理图像和视频数据时所需的临时数据。 功能:显存的主要作用是提供GPU快速访问的数据存储&a…...

多模态智能
研究背景: 深度学习从1.0的端到端走向2.0的预训练,通过大规模预训练来记忆多模态数据中共性知识,增强对下游任务的学习能力。 深度学习1.0:特定任务有标注训练数据->随机初始化训练->最终模型 深度学习2.0:大规…...

【机器学习(十三)】机器学习回归案例之股票价格预测分析—Sentosa_DSML社区版
文章目录 一、背景描述二、Python代码和Sentosa_DSML社区版算法实现对比(一) 数据读入(二) 特征工程(三) 样本分区(四) 模型训练和评估(五) 模型可视化 三、总结 一、背景描述 股票价格是一种不稳定的时间序列,受多种因素的影响。影响股市的外部因素很多,主要有经济因素、政治因…...

大模型微调
概述 什么是模型微调? 模型微调是通过微调工具,使用独特的场景数据对平台的基础模型进行调整,帮助你快速定制一个更符合业务需求的大型模型。其优势在于对基础模型进行小幅调整以满足特定需求,相比于训练一个新模型,…...

240607 继承
面向对象三大特性:封装、继承、多态 RE: 封装 C把数据和方法封装在类里面迭代器和适配器 继承 1 基类 & 派生类 一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。定义一个派生类,我们使用一个类派生列表…...

轻松应对意外丢失:高效电脑数据恢复指南!
有时候由于误操作、硬件故障、病毒攻击等原因,电脑里的重要文件可能会突然消失不见。面对这样的情况,很多人会感到手足无措。其实,借助专业的电脑数据恢复软件,我们可以较为轻松地找回丢失的数据。今天,我们就来介绍几…...

OpenClaw 环境搭建|可视化操作零门槛
📌 OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版) ⭐ 核心优势 全程可视化操作,无需命令行、无需手动配置 Python/Node…...

屹晶微优势代理 600V/0.3A/0.6A 半桥栅极驱动器 SOP8 技术解析
在吹风筒、无线充电、变频水泵、DC-DC电源及无刷电机驱动等应用中,需要一款高耐压、低成本的半桥栅极驱动芯片。EG2304L是一款高性价比的MOS管、IGBT管栅极驱动专用芯片,采用SOP8封装,内置高端悬浮自举电源设计,耐压高达600V&…...

数据库备份与恢复策略
数据库备份与恢复策略 1. 技术分析 1.1 备份概述 备份是数据安全的基石: 备份类型完全备份: 全部数据增量备份: 变化数据差异备份: 上次完全备份后的变化备份策略:定期完全备份增量备份补充实时备份1.2 恢复策略 恢复类型完全恢复: 恢复到最新状态时间点恢复: 恢复到…...

【普中 51-Ai8051 开发攻略】-- 第 30 章 OLED 液晶显示实验-硬件 IIC
(1)实验平台: 普中 51-Ai8051 开发板https://item.taobao.com/item.htm?abbucket17&id1026052331067(2)资料下载 :普中科技-各型号产品资料下载链接 前面已经使用 IO 口软件模拟 IIC 时序与 OLED 通信实现字符汉字的显示。 本章学习使用 AI805…...

京沪高铁涨价了,传说中的“牛马专列”要坐不起了?
一直以来,京沪高铁因为其连通北京上海这两大重要城市,成为了最受关注的高铁线路,然而就在最近京沪高铁的涨价引发了市场的热议,让人不禁想问传说中的“牛马专列”要坐不起了? 一、京沪高铁涨价了? 据南方都…...

政企级无人机管理系统,如何用一套方案搞定多行业巡检?
一、为什么政企客户越来越倾向私有化无人机平台?在低空经济政策收紧、数据安全要求趋严的今天,很多单位在采购无人机管理系统时,已经不再满足于 “能用就行”。公有云平台无法部署在政务内网,数据出网存在合规风险;通用…...

K210+STM32F103C8T6低成本送药小车全流程:从硬件选型到代码调试避坑
K210STM32F103C8T6低成本送药小车全流程:从硬件选型到代码调试避坑 当电子竞赛遇上嵌入式开发,一个融合视觉识别与运动控制的送药小车项目,往往成为检验技术实力的试金石。本文将带你从零开始,用K210视觉模块与STM32F103C8T6主控芯…...

别再只看功率了!用LRS-200-24开关电源给电机供电,我踩过的这个坑你得知道
电机供电实战:LRS-200-24电源选型中那些教科书不会告诉你的细节 深夜的厂房里,两台24V直流电机突然像哮喘发作般间歇性抽搐,伴随开关电源指示灯疯狂闪烁——这个场景让现场工程师血压飙升。当教科书上的功率计算公式遭遇真实世界的电机启动电…...

死信队列与补偿作业
Skeyevss FAQ:死信队列与补偿作业 试用安装包下载 | SMS | 在线演示 项目地址:https://github.com/openskeye/go-vss 1. 什么是死信(DLQ) 消息在 最大重试次数 后仍失败,进入 死信队列 或 失败表,避免无…...

AI英语智能体的开发
构建一个专门用于英语学习的AI智能体(AI Agent),核心在于如何将大语言模型(LLM)的通用能力,转化为符合二语习得(SLA)理论的教学逻辑。这类智能体不仅需要“懂英语”,更需…...