InternVid:用于多模态视频理解与生成的大规模视频-文本数据集 | ICLR Spotlight
InternVid 是一个开源的大规模视频-文本数据集,旨在促进视频理解和生成任务的发展,由上海人工智能实验室与南京大学、中国科学院等单位联合发布,相关的工作已经被ICLR2024接收。它包含超过 700 万个视频,总时长近 76 万小时,并附带详细的文本描述。InternVid 的发布将推动文本-视频的多模态理解和生成的进步,并为相关研究和应用提供新的机遇,包含以下特点:
-
规模庞大:InternVid 是目前公开的最大的视频-文本数据集之一,包含超过 700 万个视频,总时长近 76 万小时。
-
内容丰富: 视频内容涵盖日常生活、体育运动、娱乐、教育等多个领域,能够满足不同研究和应用的需求。
-
高质量: 视频和文本都经过精心挑选和处理,保证了数据集的高质量,提供了丰富的描述,CLIP-SIM,视频美学分数。
InternVid 可用于以下任务:
-
视频理解: 视频分类、视频检索、视频描述生成、视频摘要生成等。
-
视频生成: 视频编辑、视频合成、视频特效等。
-
多模态学习: 视频-文本语义匹配、视频-文本检索、视频-文本生成等。

论文:
https://arxiv.org/abs/2307.06942
开源链接:
https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid
HuggingFace:
https://huggingface.co/datasets/OpenGVLab/InternVid
InternVid的出发点
学习可迁移的视频-文本表示对于视频理解至关重要,尤其是在自动驾驶、智能监控、人机交互和视觉搜索等实际应用中。近期,OpenAI发布的Sora模型在文生视频领域取得了显著进展。Sora不仅打破了视频连贯性的局限,还在多角度镜头切换中保持一致性,并展示出对现实世界逻辑的深刻理解。这一突破为视频-语言领域的多模态对比学习提供了新的可能性,尽管目前Sora尚未开放给公众使用,但其在视频生成领域的GPT-3时刻,预示着通用人工智能的实现可能比预期来得更快。
但是限制住目前探索的一个关键原因是缺乏用于大规模预训练的高质量视频-语言数据集。当前的研究依赖于如HowTo100M [1]、HD-VILA [2] 和 YT-Temporal [3, 4] 等数据集,其文本是使用自动语音识别(ASR)生成的。尽管这些数据集规模庞大,但它们在视频和相应文本描述之间的语义相关性通常较低。这类的数据一方面不太符合文生视频等生成任务的需要,另一方面提高这种相关性(例如,通过将视频与描述对齐以改善它们的匹配度)显著有利于下游任务,如视频检索和视频问答。
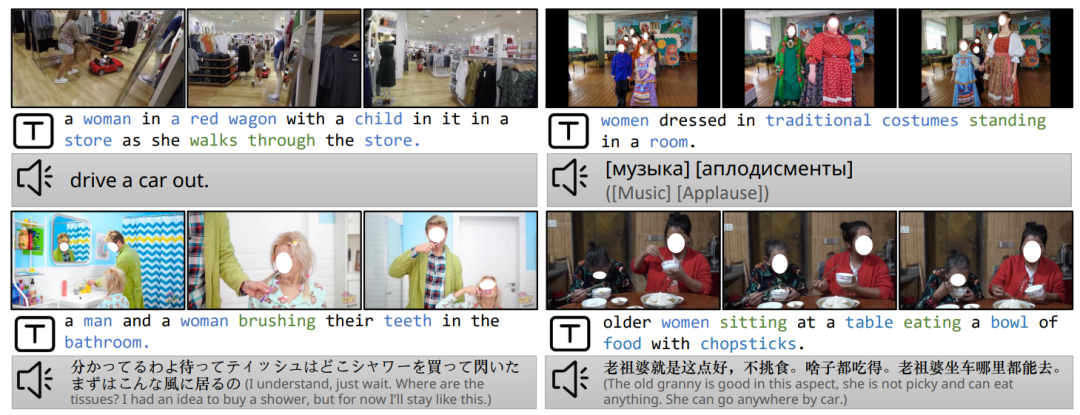
为了解决扩大视频语言建模规模的挑战,同时保持高视频-文本对应性,我们提出了一个大规模的以视频为中心的数据集InternVid,见图1。ASR转录几乎没有描述视频中的视觉元素,而生成的描述则涵盖有更多的视觉内容。该数据集包含高度相关的视频-文本对,包括超过700万视频,总计760,000小时,产生234M个视频片段,涵盖16种场景和约6,000个动作描述。为了提高视频-文本匹配度,我们采用了多尺度方法生成描述。在粗略尺度上,我们对每个视频的中间帧进行描述,并使用描述作为视频描述。在精细尺度上,我们生成逐帧描述,并用语言模型对它们进行总结。
通过InternVid,我们学习了一个视频表示模型ViCLIP,实现了较强的零样本性能。对于文生视频,我们筛选了一个具有美学的子集InternVid-Aes,并涵盖1800万个视频片段。与WebVid-10M[5]一起,InternVid可以显著提高基于diffusion的视频生成模型的生成能力。
数据集收集
我们确定了构建此数据集的三个关键因素:显著的时序信息、丰富多样的语义以及很强的视频-文本相关性。为了确保高时序性,我们基于action和activity的查询词来收集原始视频。为了丰富和多样的语义,我们不仅爬取了各个类别中的流行视频,还故意增加了从不同国家和语言的数据比例。为了加强视频-文本相关性,我们使用图像描述和语言模型从特定帧的注释生成视频描述。接下来,我们将详细阐述数据集构建过程,并讨论其统计数据和特征。
#01-数据集的多样性描述
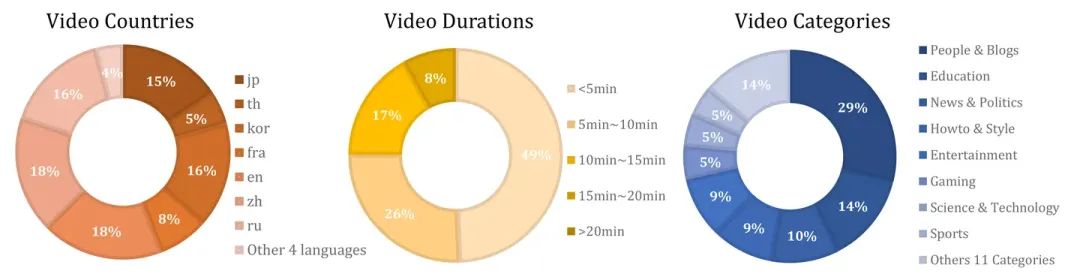
16个流行类别中收集了各种百分比的视频。为了确保多样性,我们选择了来自不同语言的国家的视频,而非依赖于一个主导语言环境。我们采样的国家包括英国、美国、澳大利亚、日本、韩国、中国、俄罗斯和法国等。在时长方面,每个视频平均持续351.9秒。几乎一半(49%)的视频时长不超过五分钟,而四分之一(26%)的视频时长在五到十分钟之间。只有8%的视频超过20分钟。在策划的视频中,85%是高分辨率(720P),其余15%的分辨率从360P至720P不等。虽然低分辨率的视频在内容生成任务中可能表现不如高分辨率的视频,但只要配有适当的描述,它们仍可用于视频-语言表示学习。
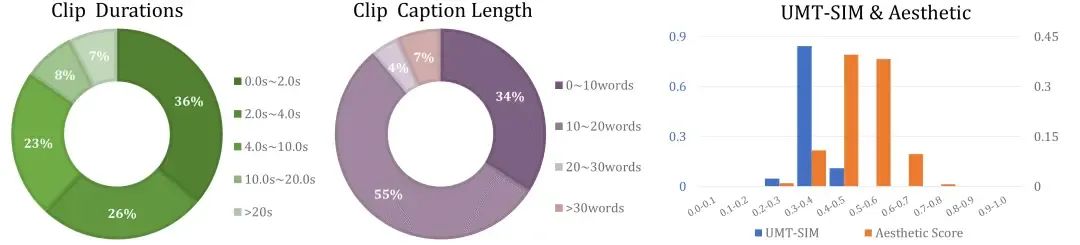
InternVid展示了在分割剪辑级别上具有不同剪辑时长和描述长度的多样性。美学分数和剪辑-描述相似度均匀分布。大部分剪辑的长度在0-10秒之间,占所有剪辑的85%。大约一半的剪辑描述含有10-20个单词,而三分之一的剪辑描述含有少于10个单词。大约11%的剪辑具有超过20个单词的长描述。
#02-原始数据收集
我们从互联网收集视频,考虑到其数据的多样性和丰富性,以及其对学术使用。总共,我们获得了700万个视频链接,平均时长为6.4分钟。我们通过创建视频ID的数据库,并排除在2023年4月之前公开可用的数据集中已存在的任何视频,来确保我们数据集的独特性。一方面,我们选择了流行频道及其相应的热门或高评分视频,从新闻、游戏等类别中,共获得200万视频。另一方面,我们创建了与动作/活动相关的动词列表。有了这个列表,我们也通过选择检索结果顶部的视频,获得了510万视频。
#03-定义动作和视频检索词
我们从ATUS[6]、公共视频数据集和文本语料库中定义了大约6.1K个动作短语。然后它们经过模型的精炼和手动的剔除。我们利用2017年至2022年的ATUS动作,将它们合并并去除重复项。对于参考的公共视频数据,我们利用了Kinetics [7]、SomethingSomething系列 [8,9]、UCF101 [10]等。这为我们提供了1103个动作标签。此外,我们还访问了几个grounding的数据集。我们使用语言模型从语料库中提取动作及其相应的目标(如果存在),形成短语,经过人工检查后共有5001个动作。总共,我们收集了6104个视频查询词,用于在网络上搜索视频。
#04-收集策略
为了确保我们数据集的质量,我们建立了特定的爬取规则。我们只收集时长在10秒到30分钟之间,分辨率从360P到720P的视频。在这个过程中,我们优先考虑可用的最高分辨率。为了提供一个全面的多模态数据集,我们收集了视频及其音频、描述、标题和摘要。
#05-多尺度视频描述生成
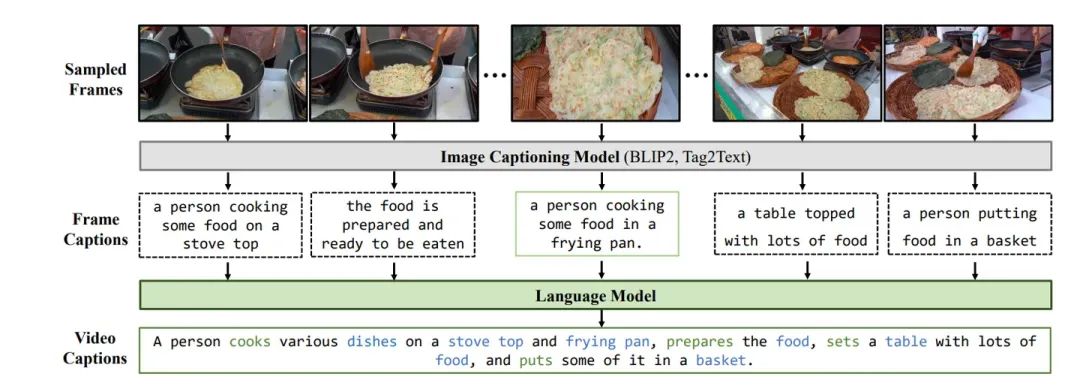
为了生成可扩展、丰富和多样化的视频描述,我们采用了多尺度方法,包含两种不同的描述策略,如图4所示。在更细的尺度上,我们通过专注于视频片段中常见的对象、动作和场景描述来简化视频描述过程。我们故意忽略了复杂细节,如微妙的面部表情和动作,以及其他细微元素。在更粗的尺度上,仅对视频的中心帧进行描述。鉴于我们关注的是通过场景分割过滤的短视频片段(大约10秒),大多数视频主要显示一致的对象,没有显著的外观变化。这避免了在处理视频时从图像角度处理身份保留问题。技术上,我们使用轻量级图像描述模型Tag2Text[11]进行更细的尺度描述,它以低fps逐帧描述视频。在更粗的尺度上,我们使用BLIP2 [12]对片段的中间帧进行描述。然后,这些描述被合成成一个综合视频描述,使用预训练的语言模型[13, 14]。
多模态视频表征模型 ViCLIP
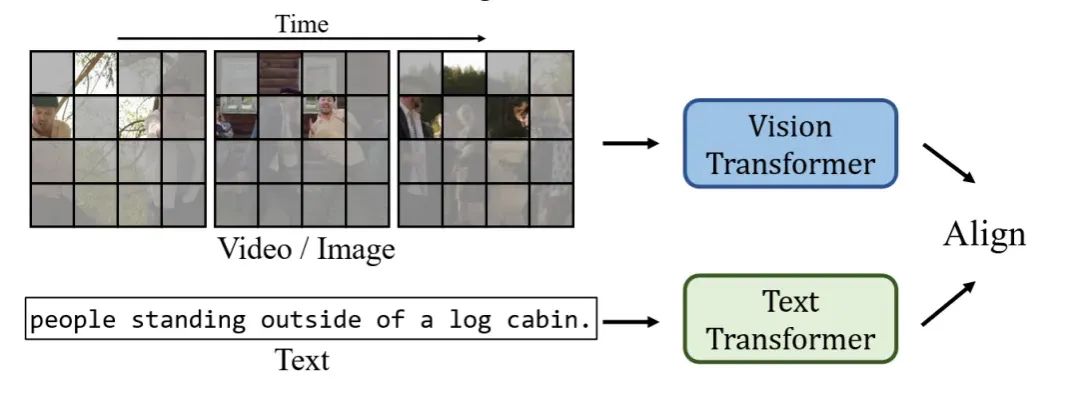
基于InternVid和CLIP[15],我们还提出了ViCLIP,一个视频-文本对比学习的模型,它基于ViT-L,并采用了视频遮盖和对比损失的方法,来学习可迁移的视频-文本表示,如图5所示。通过引入 DeepSpeed 和 FlashAttention,ViCLIP 在 64 个 NVIDIA A100 GPU 上训练了 3 天。与之前的Video CLIP变体相比,ViCLIP在零样本设置下表现出显著的性能提升。
我们在InternVid的五个子集上学习ViCLIP,并在多个流行的视频相关基准测试中评估其性能,包括零样本和全微调设置。这五个子集分别是:随机采样的InternVid-10M、InternVid-50M,InternVid-200M,假设训练视频片段的多样性比数量更重要的InternVid-10M-DIV和假设文本-视频匹配度更重要的InternVid-10M-FLT。我们将InternVid-10M和InternVid-10M-DIV/-FLT与WebVid10M进行比较,同时使用InternVid-50M和InternVid-200M进一步验证视频-语言对比学习的数据显示性。具体性能表格可以参考原文,图6列出了检索任务的性能。
文生视频的探索
此外,我们还提供了一个经过特定的视频-文本关系和视觉美学过滤的子集,InternVid-Aes,它有助于生成高分辨率、无水印的视频。利用InternVid-Aes,一个简单的文本到视频的基线模型的视觉和定量的结果都可以明显提升。这些提供的资源为有兴趣进行多模态视频理解和生成的研究者和从业者提供了一个有力的工具。

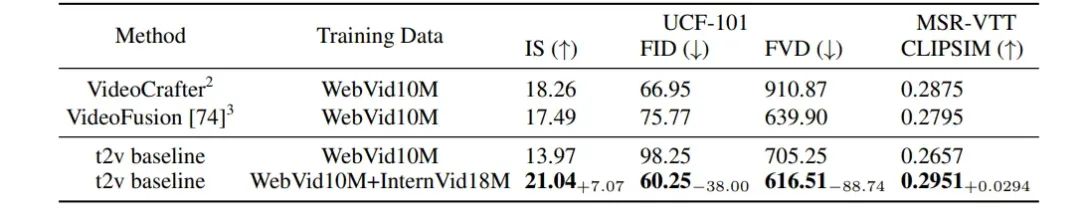
为了定量评估我们的模型,我们进行了零样本文本到视频的实验,并随机从UCF-101数据集中抽取了2020个视频,从MSRVTT数据集中抽取了2990个视频,并在图8中测试了CLIPSIM、IS、FID和FVD指标。
下载
InternVid 数据集可通过以下方式获取:
Hugging Face
·数据集metainfo:
https://huggingface.co/datasets/OpenGVLab/InternVid
·ViCLIP权重:
https://huggingface.co/OpenGVLab/ViCLIP
目前HuggingFace上已经开源了有InternVid-10M-FLT(默认)、InternVid-10M-DIV、InternVid-18M-Aes,通过选择不同的subset即可进行预览,这里提供了视频的id,开始和结束的时间戳,视频描述,美学分数和视频文本匹配度。您可以通过配合yt-dlp或video2dataset进行下载。
下载meta文件,您也可以通过以下指令(请第一次先登录网页获取权限后操作):
pip install -U huggingface_hubhuggingface-cli download --repo-type dataset --token hf_***(请注意替换成您的token) --resume-download --local-dir-use-symlinks False OpenGVLab/InternVid --local-dir InternVid_metainfo
同时,我们也提供了涵盖了来源语种的信息您可以通过https://huggingface.co/datasets/OpenGVLab/InternVid-10M-FLT-INFO/下载
OpenDataLab (国内访问更加友好)
·InternVid-10M-FLT:
https://opendatalab.com/shepshep/InternVid
·InternVid-Aes: h
https://opendatalab.com/yinanhe/InternVid-14M-Aes
Github
·数据集信息及Model Zoo:
https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid
·ViCLIP训练代码:
https://github.com/OpenGVLab/InternVideo/tree/main/Pretrain/ViCLIP
InternVid 的发布将推动视频理解和生成领域的研究和发展。未来,通用视频团队将继续对 InternVid 进行更新和完善,并致力于为研究人员和开发者提供更加优质的数据集和工具。
引用信息
如果您在研究或应用中使用了 InternVid 数据集或ViCLIP,欢迎您引用以下文献:
@inproceedings{wang2023internvid,title={InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation},author={Wang, Yi and He, Yinan and Li, Yizhuo and Li, Kunchang and Yu, Jiashuo and Ma, Xin and Chen, Xinyuan and Wang, Yaohui and Luo, Ping and Liu, Ziwei and Wang, Yali and Wang, Limin and Qiao, Yu},booktitle={The Twelfth International Conference on Learning Representations},year={2023}
}
相关文章:
InternVid:用于多模态视频理解与生成的大规模视频-文本数据集 | ICLR Spotlight
InternVid 是一个开源的大规模视频-文本数据集,旨在促进视频理解和生成任务的发展,由上海人工智能实验室与南京大学、中国科学院等单位联合发布,相关的工作已经被ICLR2024接收。它包含超过 700 万个视频,总时长近 76 万小时&#…...
)
Hive数仓操作(十)
一、Hive 分页查询 在大数据处理中,分页查询是非常常见的需求。Hive 提供了 LIMIT 和 OFFSET 关键字来方便地进行分页操作。本文将详细介绍它们的用法。 1. 基本用法 LIMIT:用于限制查询结果的行数。OFFSET:用于指定从哪一行开始检索。 2…...

Android 扩大View的点击区域
文章目录 Android 扩大View的点击区域使用padding属性使用TouchDelegate使用getLocationOnScreen监听 Android 扩大View的点击区域 使用padding属性 通过设置 padding 属性扩大点击区域。 使用: <?xml version"1.0" encoding"utf-8"?&…...

[Qt学习笔记] 解决QTextEdit数据过多UI卡死问题
背景问题 在项目中使用QTextEdit显示软件的日志信息,由于在连续输出日志信息,刚开始QTextEdit显示没什么问题,长时间就会出现UI界面卡死,内存占用变高。晚上查了说QTextEdit的append函数如果不释放会累计增加内存,包括…...

OgreNext高级材质中增加线宽,点大小,虚线模式绘制支持
修改Ogre高级材质系统,增加线宽,点大小,虚线模式,虚线参数的支持,效果如下: 需要修改的代码文件如下: 修改如下 代码文本: //范围[0.2 - 51] 0.2 * [0,255];Ogre::uint8 mLineWidth;//范围[…...

STM32中的DMA数据转运——下篇
STM32中的DMA数据转运——上篇-CSDN博客 在上篇文章中,我们讨论了STM32中的DMA(直接存储器访问)及其工作原理、存储器类型和总线设计。接下来,我们将更深入地探讨DMA的具体配置方法、常见应用场景以及一些实际设计中的注意事项。…...

51单片机的智能小区安防系统【proteus仿真+程序+报告+原理图+演示视频】
1、主要功能 该系统由AT89C51/STC89C52单片机LCD1602显示模块时钟模块温度传感器烟雾传感器CO传感器红外感应传感器IC卡蓝牙继电器按键、蜂鸣器、LED等模块构成。适用于智能小区安防、智能家居安防等相似项目。 可实现功能: 1、LCD1602实时显示北京时间、温度、烟雾浓度和CO浓…...
数仓建模流程
数仓建模简介 一句话总结 数仓建模中的“建模”是一个将数据有序组织和存储起来的过程,旨在提高数据的使用效率和降低使用成本。 详细描述 在数仓建模中,“建模”指的是构建数据模型,也就是数据的组织和存储方法。数据模型强调从业务、数…...

Neo4j CQL语句 使用教程
CREATE命令 : CREATE (<node-name>:<label-name>{ <Property1-name>:<Property1-Value>........<Propertyn-name>:<Propertyn-Value>} )字段说明 CREATE (dept:Dept { deptno:10,dname:“Accounting”,location:“Hyderabad” })&#…...

STM32-HAL库 驱动DS18B20温度传感器 -- 2024.10.8
目录 一、教程简介 二、驱动理论讲解 三、CubeMX生成底层代码 四、Keil5编写代码 五、实验结果 一、教程简介 本教程面向初学者,只介绍DS18B20的常用功能,但也能满足大部分的运用需求。跟着本教程操作,可在10分钟内解决DS18b20通信难题。…...

HTML 符号
HTML 符号 HTML(超文本标记语言)是一种用于创建网页的标准标记语言。它使用一系列的标签来描述网页的结构和内容。HTML 符号,通常指的是 HTML 标签,是构成 HTML 文档的基础。本文将详细介绍 HTML 符号的概念、种类、用途以及如何在网页设计中正确使用它们。 HTML 符号的概…...

编译后的MySQL安装
MySQL安装 1.下载网址2.下载方式3.配置配置环境变量修改配置文件初始化安装服务启动服务测试修改 Mysql 默认密码 1.下载网址 https://dev.mysql.com/downloads/mysql/2.下载方式 选择对应版本下载 mysql-xxx-winx64.zip,该压缩包为编译后文件,并非源码…...

Ubuntu安装Apache教程
系统版本:Ubuntu版本 23.04 Ubuntu是一款功能强大且用户友好的操作系统,而Apache是一款广泛使用的Web服务器软件。在Ubuntu上安装Apache可以帮助用户搭建自己的网站或者进行Web开发。为大家介绍如何在Ubuntu上安装Apache,并提供详细的教程和操…...

Nginx跳转模块之location与rewrite
目录 一、location模块与rewrite模块区别 二、location模块的基本介绍 1. location模块是什么? 2. 三种匹配类别 3. 常用的匹配规则 4. 匹配优先级 三、location模块使用实例 1.精准匹配优先级小于一般匹配的特殊情况 2 .解决方法 3. 实际网站使用中的三个匹配…...

oracle col命令
oracle col命令可以对列进行进行格式化,格式:col 列名 for(mat) 格式 例如: col owner for a100 设置owner列格式 col 列名:显示当前列的格式 SQL> col owner COLUMN owner ON FORMAT a100 SQL> clear column:清除所有列的格式 SQL> col o…...

ESP32接入扣子(Coze) API使用自定义智能体
使用ESP32接入Coze API实现聊天机器人的教程 本示例将使用ESP32开发板通过WiFi接入 Coze API,实现一个简单的聊天机器人功能。用户可以通过串口向机器人输入问题,ESP32将通过Coze API与智能体进行通信,并返回对应的回复。本文将详细介绍了如…...

【JVM】如何判断对象是否可以被回收
引用计数法: 在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。 优点:实现简单,判…...
)
CloseableHttpResponse 类(代表一个可关闭的 HTTP 响应)
CloseableHttpResponse 类是 Apache HttpClient 库中的一个类,代表一个可关闭的 HTTP 响应。当你使用 HttpClient 发送请求时,你会得到一个 CloseableHttpResponse 实例,它包含了服务器的响应数据和状态。处理完响应后,你应该关闭…...

C语言编程规范及命名规则
C语言编程规范及命名规则 编码规范总原则:清晰、简洁、一致头文件函数标识符命名与定义变量宏、常量表达式注释排版与格式代码编辑编译其他设置 命名规则类型命名: 其他编译器配色 参考 编码规范 总原则:清晰、简洁、一致 清晰第一 清晰性是…...

Pika 1.5 - Pika Labs最新推出的AI视频生成工具
Pika 1.5是由Pika Labs最新推出的AI视频生成工具。通过简单易用的界面和强大的”Pikaffects”特效库,用户能通过上传图片或输入文本,快速生成具有专业质感和创意效果的视频内容。新版本强调低门槛创作,让普通用户能轻松制作出有趣、抽象、易于…...

为内部工具集成 AI 能力时如何借助 Taotoken 简化运维
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成 AI 能力时如何借助 Taotoken 简化运维 在开发内部效率工具或数据分析脚本时,集成文本生成、代码补全等…...

使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回 在开发或调试过程中,有时你可能需要绕过高级 SDK…...

思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析
思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版烦恼吗?字体选择困…...

DIY红外遥控电视关机器:从ATTINY85到晶体管驱动的硬件实践
1. 项目概述:从“关不掉”的烦恼到“一键清静”的实践不知道你有没有过这样的经历:在餐厅吃饭,墙上挂着的电视正播放着吵闹的广告;在候车室,多台电视同时播放着不同的节目,让人心烦意乱。你只想安安静静地待…...

Android Studio中文插件终极指南:3分钟告别英文开发环境
Android Studio中文插件终极指南:3分钟告别英文开发环境 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Androi…...

质子CT技术:原理、系统设计与临床应用
1. 质子CT技术概述:从原理到临床需求在放射治疗领域,质子治疗因其独特的布拉格峰(Bragg Peak)特性而备受关注。与传统X射线治疗相比,质子束在组织中沉积的能量分布具有明显的物理优势——在射程末端释放最大剂量后迅速衰减。这一特性使得肿瘤…...

QML数据驱动UI:从ListModel与ListElement入门到实战
1. 为什么需要数据驱动UI? 第一次接触QML开发时,我习惯直接在UI组件里写死数据。比如要显示一个水果列表,可能会这样写: Column {Text { text: "Apple - $2.45" }Text { text: "Orange - $3.25" }Text { text…...

别再乱写RS485协议了!基于STM32F103C8T6,聊聊工业通讯中帧结构的那些坑
工业级RS485通讯协议设计:从基础到实战的避坑指南 在嘈杂的工厂车间里,一排STM32F103C8T6控制器通过RS485总线连接着二十多台设备。突然,3号节点的温度传感器数据开始随机跳变,而工程师小王发现每当隔壁车间的变频器启动时&#x…...

第二章:Compose入门—声明式UI编程
第二章:Compose 入门 — 声明式 UI 编程 Compose 的核心理念:用 Kotlin 代码声明 UI,而不是用 XML 布局文件。 2.1 传统 View 系统 vs Compose 对比项传统 View 系统Jetpack ComposeUI 描述XML 布局文件Kotlin 代码状态更新findViewById 手…...

基于MCP协议构建AI智能体实时加密资讯数据源实战
1. 项目概述:一个为AI智能体打造的实时加密资讯“雷达”如果你正在开发一个需要实时了解加密货币市场动态的AI智能体,比如一个自动交易机器人、一个市场分析助手,或者一个社区内容生成器,那么你肯定遇到过这样的痛点:如…...