自监督学习:引领机器学习的新革命
引言
自监督学习(Self-Supervised Learning)近年来在机器学习领域取得了显著进展,成为人工智能研究的热门话题。不同于传统的监督学习和无监督学习,自监督学习通过利用未标注数据生成标签,从而大幅降低对人工标注数据的依赖。这种方法在图像、文本和音频等多个领域都展现出了优异的性能和广泛的应用前景。本文将深入探讨自监督学习的核心概念、先进方法及其在实际应用中的表现,并提供一些代码示例,帮助读者更好地理解这一引领新革命的技术。

一、什么是自监督学习?
自监督学习是一种无监督学习的特殊形式,它通过从数据本身生成标签来训练模型。这个过程通常包括以下几个步骤:
- 生成预文本:从未标注数据中提取信息,生成伪标签或预文本。
- 模型训练:利用生成的标签对模型进行训练。
- 特征提取:训练好的模型可以用于特征提取,进一步应用于下游任务(如分类、检测等)。
这种方法能够有效地利用大规模未标注数据,为深度学习模型提供丰富的特征表示。
自监督学习的历史背景
自监督学习的思想可以追溯到几年前,最早是在图像处理领域被提出。随着深度学习的快速发展,研究者们逐渐认识到未标注数据的巨大潜力。尤其是在大规模数据集的爆炸式增长下,获取标注数据的成本越来越高,而利用自监督学习的方法来减少对标注数据的依赖变得越来越重要。
二、自监督学习的先进方法
自监督学习的技术和方法不断演进,以下是一些当前先进的方法:
1. 对比学习(Contrastive Learning)
对比学习是一种流行的自监督学习方法,旨在通过比较样本间的相似性和差异性来学习有效的特征表示。它通过将相似的样本拉近,将不相似的样本推远,从而增强模型的判别能力。
代码示例:SimCLR
下面是使用TensorFlow实现简单的SimCLR的示例:
import tensorflow as tf
from tensorflow.keras import layers, Modeldef create_base_network(input_shape):base_model = tf.keras.applications.ResNet50(include_top=False, weights='imagenet', input_shape=input_shape)return Model(inputs=base_model.input, outputs=base_model.output)def contrastive_loss(y_true, y_pred):return tf.reduce_mean(tf.square(y_true - y_pred))input_shape = (224, 224, 3)
base_network = create_base_network(input_shape)# 示例输入
anchor = layers.Input(shape=input_shape)
positive = layers.Input(shape=input_shape)anchor_output = base_network(anchor)
positive_output = base_network(positive)# 计算对比损失
loss = contrastive_loss(anchor_output, positive_output)model = Model(inputs=[anchor, positive], outputs=loss)
model.compile(optimizer='adam', loss=contrastive_loss)
2. 生成式模型(Generative Models)
生成式模型如GAN(生成对抗网络)和VAE(变分自编码器)可以通过生成样本来进行自监督学习。这些模型通过学习数据分布生成新样本,同时优化生成样本的质量。
代码示例:变分自编码器(VAE)
以下是一个简单的VAE实现示例:
from tensorflow.keras import layers, Model
from tensorflow.keras import backend as K# VAE参数
original_dim = 784 # 例如MNIST图像大小
latent_dim = 2# 编码器
inputs = layers.Input(shape=(original_dim,))
h = layers.Dense(256, activation='relu')(inputs)
z_mean = layers.Dense(latent_dim)(h)
z_log_var = layers.Dense(latent_dim)(h)# 重参数化技巧
def sampling(args):z_mean, z_log_var = argsepsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim))return z_mean + K.exp(0.5 * z_log_var) * epsilonz = layers.Lambda(sampling)([z_mean, z_log_var])# 解码器
decoder_h = layers.Dense(256, activation='relu')
decoder_mean = layers.Dense(original_dim, activation='sigmoid')h_decoded = decoder_h(z)
outputs = decoder_mean(h_decoded)vae = Model(inputs, outputs)# VAE损失
def vae_loss(original, reconstructed):reconstruction_loss = K.binary_crossentropy(original, reconstructed) * original_dimkl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)return K.mean(reconstruction_loss + kl_loss)vae.compile(optimizer='adam', loss=vae_loss)
3. 预测性模型(Predictive Models)
预测性模型通过训练模型预测输入数据的一部分,从而实现自监督学习。例如,BERT(Bidirectional Encoder Representations from Transformers)通过随机遮盖部分单词并训练模型预测这些单词,取得了优异的自然语言处理效果。
代码示例:BERT简化实现
以下是使用Hugging Face的Transformers库进行BERT预训练的示例:
from transformers import BertTokenizer, BertForMaskedLM
import torch# 初始化BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')# 输入句子
input_text = "The capital of France is [MASK]."
inputs = tokenizer(input_text, return_tensors='pt')# 预测被遮盖的单词
with torch.no_grad():outputs = model(**inputs)predictions = outputs.logits# 获取遮盖位置的预测结果
masked_index = torch.where(inputs['input_ids'] == tokenizer.mask_token_id)[1]
predicted_token_id = predictions[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)print(f"Predicted token: {predicted_token}")
4. 数据增强(Data Augmentation)
数据增强在自监督学习中发挥着重要作用,通过对原始数据进行变换(如旋转、裁剪等),生成多个不同的样本,从而增强模型的鲁棒性和泛化能力。自监督学习中的数据增强不仅能够生成新的训练样本,还能在模型训练时增加样本的多样性。
三、自监督学习的应用案例
1. 图像识别
自监督学习在图像识别中的应用十分广泛。例如,利用对比学习的方法,模型可以在未标注的图像数据上进行训练,进而在有标注的图像分类任务中取得优异表现。
实际应用
在实际应用中,许多公司和研究机构开始采用自监督学习来训练图像分类模型。例如,Facebook的研究团队利用自监督学习训练了一个图像分类模型,成功地在ImageNet数据集上取得了领先的结果。这种方法减少了对手动标注数据的依赖,同时保持了高水平的模型性能。
2. 自然语言处理
在自然语言处理领域,BERT等模型采用自监督学习的方法,利用大量未标注文本数据进行预训练,然后在特定任务上进行微调。这种方式显著提升了模型在各类下游任务中的表现,包括文本分类、情感分析和问答系统等。
实际应用
自监督学习在搜索引擎和社交媒体平台中的应用也越来越广泛。例如,Google利用BERT模型在其搜索引擎中实现了更准确的自然语言查询理解,提升了用户体验。此外,社交媒体平台利用自监督学习来增强内容推荐系统的精准度,从而提高用户粘性。
3. 推荐系统
自监督学习也在推荐系统中得到了广泛应用。通过分析用户的行为数据,模型可以自我生成用户偏好标签,从而在推荐算法中提供更精准的推荐结果。
实际应用
许多电商平台和视频流媒体服务采用自监督学习来优化推荐算法。例如,Netflix通过分析用户观看历史数据,使用自监督学习模型来预测用户未来可能感兴趣的电影和电视剧,显著提高了用户的观看满意度和留存率。
4. 音频处理
自监督学习在音频处理中的应用也越来越受到关注。研究者们利用未标注的音频数据进行特征提取,以提升语音识别和音乐生成等任务的性能。
实际应用
例如,Spotify和其他流媒体服务利用自监督学习来分析用户的音乐偏好,生成个性化的播放列表。同时,语音助手如Siri和Alexa也在持续优化其语音识别能力,采用自监督学习来改进用户的语音交互体验。
四、自监督学习面临的挑战
虽然自监督学习在许多领域取得了显著进展,但它仍面临一些挑战:
-
生成伪标签的有效性:如何生成高质量的伪标签是自监督学习的关键。如果生成的标签不准确,可能会导致模型的学习效果下降。
-
模型复杂度:自监督学习模型通常复杂,训练过程需要大量计算资源,特别是在处理大规模数据集时。
-
数据选择:选择哪些数据进行自监督学习也非常重要。若数据的代表性不足,模型的泛化能力会受到影响。
-
对抗性攻击:自监督学习模型可能对输入数据的微小变化敏感,容易受到对抗性攻击的影响。
五、未来的研究方向
自监督学习作为一个快速发展的领域,未来有几个值得关注的研究方向:
-
提高生成伪标签的质量:研究者们可以探索更高效的伪标签生成方法,以提高模型的学习效果。
-
多模态自监督学习:结合不同模态(如图像、文本、音频)进行自监督学习,有助于模型更全面地理解数据。
-
模型压缩和加速:为了在资源有限的设备上实现自监督学习,研究模型压缩和加速的方法将是一个重要的方向。
-
增强模型的可解释性:随着自监督学习应用的扩大,增强模型的可解释性将帮助人们理解模型的决策过程。
六、结论
自监督学习正在改变机器学习的研究和应用格局。通过有效利用未标注数据,这一方法不仅提高了模型的性能,还减少了对标注数据的依赖。本文简要介绍了自监督学习的基本概念、先进方法及其实际应用,并提供了一些代码示例,希望为读者提供一个清晰的理解框架。
随着技术的不断进步,自监督学习将继续引领人工智能领域的发展,开启更多未知的可能性。未来的研究将集中于如何进一步提升模型的学习能力和泛化能力,为各个行业带来创新的解决方案。欢迎大家深入探索自监督学习的无限魅力!
相关文章:
自监督学习:引领机器学习的新革命
引言 自监督学习(Self-Supervised Learning)近年来在机器学习领域取得了显著进展,成为人工智能研究的热门话题。不同于传统的监督学习和无监督学习,自监督学习通过利用未标注数据生成标签,从而大幅降低对人工标注数据…...

Web安全常用工具 (持续更新)
前言 本文虽然是讲web相关工具,但在在安全领域,没有人是先精通工具,再上手做事的。鉴于web领域繁杂戎多的知识点(工具是学不完的,哭),如果你在本文的学习过程中遇到没有学过的知识点࿰…...

不踩坑,青龙面板小问题解决方案~
好久没写了,随手记录一下。 1. 新建目录 很多人跟我一样入坑的手机免root青龙面板,一般用的都是2.10.13版本。这个版本比较早,似乎没有新建目录的功能(也可能是我不会用哈哈),以下是对比图: 大家…...

2025秋招倒计时---招联金融
【投递方式】 直接扫下方二维码,或点击内推官网https://wecruit.hotjob.cn/SU61025e262f9d247b98e0a2c2/mc/position/campus,使用内推码 igcefb 投递) 【招聘岗位】 后台开发 前端开发 数据开发 数据运营 算法开发 技术运维 软件测试 产品策…...

基于yolov8、yolov5的果蔬检测系统(含UI界面、数据集、训练好的模型、Python代码)
项目介绍 项目中所用到的算法模型和数据集等信息如下: 算法模型: yolov8、yolov8 SE注意力机制 或 yolov5、yolov5 SE注意力机制 , 直接提供最少两个训练好的模型。模型十分重要,因为有些同学的电脑没有 GPU࿰…...

出海快报 | “三消+短剧”手游横空出世,黄油相机“出圈”日本市场,从Q1看日本手游市场趋势和机会
编者按:TopOn出海快报栏目为互联网出海从业者梳理出海热点,供大家了解行业最新发展态势。 1.“三消短剧”横空出世,融合创新手游表现亮眼 随着竞争的加剧,新产品想要突出重围,只能在游戏中加入额外的元素。第一次打开…...
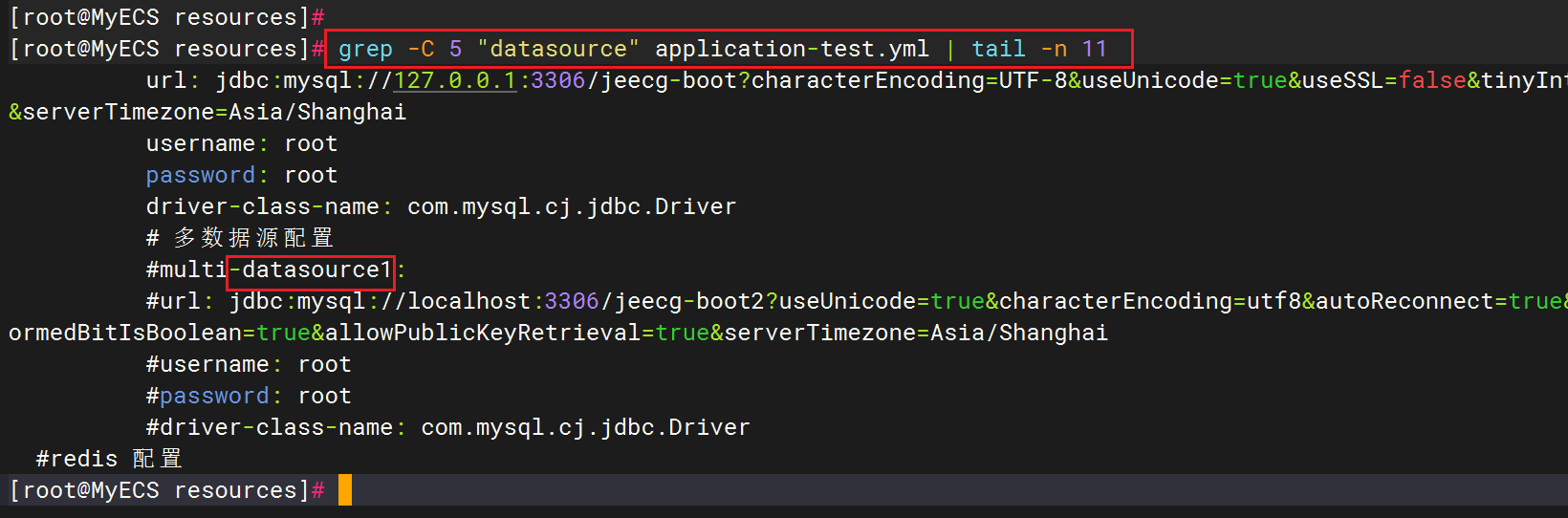
Linux高效查日志命令介绍
说明:之前介绍Linux补充命令时,有介绍使用tail、grep命令查日志; Linux命令补充 今天发现仅凭这两条命令不够,本文扩展介绍一下。 命令一:查看日志开头 head -n 行数 日志路径如下,可以查看程序启动是否…...

非线性关卡设计
【GDC】如何设计完全非线性的单人关卡_DOOM (bilibili.com) 本文章算是此视频的简单笔记,更详细还请看视频 设计完全非线性关卡强调自由移动和沙盒式玩法,鼓励玩家进行不可预测的移动和空间探索。讲解者分享了设计此类关卡的具体步骤,包括明…...

Qt-链接数据库可视化操作
1. 概述 Qt 能够支持对常见数据库的操作,例如: MySQL、Oracle、SqlServer 等等。 Qt SQL模块中的API分为三层:驱动层、SQL接口层、用户接口层。 驱动层为数据库和SQL接口层之间提供了底层的桥梁。 SQL接口层提供了对数据库的访问࿰…...

萤火php端: 查询数据的时候报错: “message“: “Undefined index: pay_status“,
代码:getGoodsFromHistory <?php // ---------------------------------------------------------------------- // | 萤火商城系统 [ 致力于通过产品和服务,帮助商家高效化开拓市场 ] // -----------------------------------------------------…...

程序人生-2024我的个人总结
可能现在写个人总结比较早,但是眼看着还有三个月,今年就过去了,所以决定提前写写,今年对于我来说是不平凡的一年,先是加薪,之后求婚,以为快要走上人生巅峰的时候,被裁员,…...

SQL自学:什么是联结,如何编写使用联结的SELECT语句
在 SQL(Structured Query Language,结构化查询语言)的世界里,联结(JOIN)是一个强大且至关重要的概念。它允许我们从多个表中检索数据,从而实现更复杂的查询和数据分析。本文将深入探讨联结的概念…...

【C++】函数重载+引用
大家好,我是苏貝,本篇博客带大家了解C的函数重载和引用,如果你觉得我写的还不错的话,可以给我一个赞👍吗,感谢❤️ 目录 一. 预处理、编译、汇编、链接二. 函数重载1 概念2 C支持函数重载的原理—名字修饰…...

华为S5735交换机console密码重置和恢复出厂设置
比较简单,简单说就是进入bootload清除密码,然后进入default mode下重置密码。 1.开机按CtrlB,进入启动加载菜单(BootLoad menu) 拨电源重启交换机,大约开机10多秒的时候会出现提示按CtrlB可以进入BootLoa…...

Spring Security无脑使用
步骤1:添加Spring Security依赖 在你的Spring Boot项目的pom.xml文件中,添加Spring Security的依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</art…...

学习 PostgreSQL + Spring Boot 3 +mybatisplus整合过程中的报错记录
今天计划学习 PostgreSQL,并顺便尝试使用 Spring Boot 3.x 框架,打算整合 Spring Boot 3、PostgreSQL 和 MyBatis-Plus。整合后一直出现以下报错: 去AI上面搜了讲的是sqlSessionFactory 或 sqlSessionTemplate 没有正确配置 初始分析&#…...

立仪光谱共焦传感器在玻璃测量技术上的突破
近年来,随着科技的不断发展,光谱共焦传感器逐渐成为了工业检测领域的重要工具。尤其是在玻璃这种透明材质的厚度测量中,光谱共焦传感器展现出了其独特的优势。立仪科技小编将围绕光谱共焦传感器在玻璃行业中的应用,从问题、分析到…...

Llama系列上新多模态!3.2版本开源超闭源,还和Arm联手搞了手机优化版,Meta首款多模态Llama 3.2开源!1B羊驼宝宝,跑在手机上了
Llama系列上新多模态!3.2版本开源超闭源,还和Arm联手搞了手机优化版,Meta首款多模态Llama 3.2开源!1B羊驼宝宝,跑在手机上了! 在多模态领域,开源模型也超闭源了! 就在刚刚结束的Met…...
系统缺失mfc140.dll的修复方法,有效修复错误mfc140.dll详细步骤
mfc140.dll丢失原因分析 1 系统文件损坏或病毒感染 系统文件损坏或被病毒感染是导致mfc140.dll丢失的常见原因之一。根据用户反馈和安全研究报告,大约有30%的mfc140.dll丢失案例与系统文件损坏或病毒感染有关。病毒、木马或其他恶意软件可能会破坏或删除系统中的m…...

移动app的UI和接口自动化测试怎么进行?
标题:从0到1:移动App的UI和接口自动化测试 导语:移动App的快速发展使得UI和接口自动化测试成为了确保应用质量的重要环节。本文将从零开始介绍移动App的UI和接口自动化测试的基本概念以及如何进行测试。 第一部分:了解移动App自动…...

3种智能解析技术:VideoDownloadHelper如何突破网页视频下载限制
3种智能解析技术:VideoDownloadHelper如何突破网页视频下载限制 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 在当今数字内容爆…...

用ArcGIS做快餐店选址分析:手把手教你用OD方法分析KFC和麦当劳的聚集关系
用ArcGIS解码快餐店选址密码:OD方法揭示KFC与麦当劳的区位博弈 当你在商业区看到KFC和麦当劳总是比邻而居,是否好奇这背后隐藏着怎样的商业逻辑?本文将以空间分析的视角,带你用ArcGIS工具揭示两大快餐巨头的选址策略。不同于传统的…...
本地AI:从创建应用到配置AppID/Secret全流程)
飞书机器人+OpenClaw(小龙虾)本地AI:从创建应用到配置AppID/Secret全流程
OpenClaw 连接飞书完整图文教程 本文结合当前飞书开放平台页面、本目录里的截图素材,以及 OpenClaw Windows 现有飞书配置方式整理。 适用于“先在飞书开放平台创建企业自建应用,再把 App ID 和 App Secret 填回 OpenClaw”的接入流程。 先说结论&…...

OpenClaw用户如何快速接入Taotoken并开始使用Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始使用Agent工作流 对于已经在使用OpenClaw进行Agent开发的用户来说,接入Taotok…...

终极AMD Ryzen处理器调试指南:如何用SMUDebugTool解锁隐藏性能潜力
终极AMD Ryzen处理器调试指南:如何用SMUDebugTool解锁隐藏性能潜力 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

【亲测有效】DeepSeek极简入门与应用_156.[第6章 高级应用技巧] 场景描述型框架:用情境设定让AI进入最佳状态
别再让AI"猜谜"了!一个场景设定,让DeepSeek从"人工智障"秒变"懂王"——这可能是你用过最被低估的Prompt技巧 #mermaid-svg-7MQcGN4wm4OXCgus{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:1…...

OpenClaw企业微信渠道配置教程|API模式+长连接+全部授权
OpenClaw 连接企业微信完整图文教程 前置准备 下载小龙虾open claw一键装机包(www.totom.top)并安装 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已安装并登录企业微信客户端。 当前企业微信账号具备创建和管理…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...

实战指南:如何为nvm-windows项目配置专业级持续集成流水线
实战指南:如何为nvm-windows项目配置专业级持续集成流水线 【免费下载链接】nvm-windows A node.js version management utility for Windows. Ironically written in Go. 项目地址: https://gitcode.com/gh_mirrors/nv/nvm-windows nvm-windows作为Windows平…...

瑞萨RL78/G16开发板与EZ-CUBE3仿真器连接调试全攻略
1. 项目概述与核心价值 最近在折腾瑞萨的RL78系列MCU,手头正好有一块RL78/G16的快速原型开发板和一个EZ-CUBE3仿真器。对于刚接触瑞萨生态的朋友来说,如何把这套硬件正确地连接起来,并成功跑通第一个LED闪烁程序,往往是入门路上的…...