LLM - 使用 ModelScope SWIFT 测试 Qwen2-VL 的 LoRA 指令微调 教程(2)
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/142827217
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。

SWIFT 即 Scalable lightWeight Infrastructure for FineTuning (可扩展轻量级微调基础设施),是高效、轻量级的模型微调和推理框架,支持大语言模型(LLM) 和 多模态大型模型(MLLM) 的训练、推理、评估和部署。可以将 SWIFT 框架直接应用到研究和生产环境中,实现从模型训练和评估到应用的完整工作流程。
1. 数据集
测试 OCR 数据集:
- 已整理 (Parquet格式):https://modelscope.cn/datasets/AI-ModelScope/LaTeX_OCR
- 原始:https://github.com/LinXueyuanStdio/Data-for-LaTeX_OCR
数据集 缓存( MODELSCOPE_CACHE) 位置:modelscope_models/AI-ModelScope/LaTeX_OCR
测试数据效果:
[your path]/llm/vision_test_data/latex-print.png
[your path]/llm/vision_test_data/latex-fullhand.png
测试 qwen2-vl-7b-instruct 的 OCR 识别能力,即:
CUDA_VISIBLE_DEVICES=0 swift infer --model_type qwen2-vl-7b-instruct<<< <image>使用OCR识别图像中的Latex公式
Input an image path or URL <<< [your path]/llm/vision_test_data/latex-print.png
ds^2 = (1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}} \{dr^2 + r^2 d\theta^2 + r^2 sin^2\theta d\phi^2 \} - \frac{dt^2}{(1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}}}.
原始图像:

识别结果(印刷):
d s 2 = ( 1 − q c o s θ r ) 2 1 + α 2 { d r 2 + r 2 d θ 2 + r 2 s i n 2 θ d ϕ 2 } − d t 2 ( 1 − q c o s θ r ) 2 1 + α 2 ds^2 = (1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}} \{dr^2 + r^2 d\theta^2 + r^2 sin^2\theta d\phi^2 \} - \frac{dt^2}{(1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}}} ds2=(1−rqcosθ)1+α22{dr2+r2dθ2+r2sin2θdϕ2}−(1−rqcosθ)1+α22dt2
原始图像:

识别结果(手写):
d s 2 = ( 1 − q c o s θ r ) 2 1 + α 2 { d δ 2 + r 2 d θ 2 + n 2 s / n 2 d ϕ 2 } − d t 2 ( 1 − q c o s θ r ) 2 1 + α 2 . ds^2 = (1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}} \{d\delta^2 + r^2 d\theta^2 + n^2 s/n^2 d\phi^2 \} - \frac{dt^2}{(1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}}}. ds2=(1−rqcosθ)1+α22{dδ2+r2dθ2+n2s/n2dϕ2}−(1−rqcosθ)1+α22dt2.
其中,数据集 latex-ocr-print 的 preprocess_func() 函数,如下:
def _preprocess_latex_ocr_dataset(dataset: DATASET_TYPE) -> DATASET_TYPE:from datasets import Imageprompt = 'Using LaTeX to perform OCR on the image.'def _process(d):return {'query': prompt, 'response': d['text']}kwargs = {}if not isinstance(dataset, HfIterableDataset):kwargs['load_from_cache_file'] = dataset_enable_cachereturn dataset.map(_process, **kwargs).rename_column('image', 'images')
使用 ModelScope 下载的数据集,位于 modelscope_models/hub/datasets,数据集是 arrow 格式,与默认格式不兼容,即:
├── [4.0K] AI-ModelScope___la_te_x_ocr
│ └── [4.0K] synthetic_handwrite-eb02dd1cc52afa40
│ └── [4.0K] 0.0.0
│ ├── [4.0K] master
│ │ ├── [752K] cache-8f28bc5f38ad58b9-fa2020342a21.arrow
│ │ ├── [6.3M] cache-a7c7e67013e13072-fa2020342a21.arrow
│ │ ├── [606M] cache-c67a1e1eba314afd-fa2020342a21.arrow
│ │ ├── [7.9K] cache-e9fb6f7ceeaa8304-fa2020342a21.arrow
│ │ ├── [1.2K] dataset_info.json
│ │ ├── [ 59M] la_te_x_ocr-test.arrow
│ │ ├── [474M] la_te_x_ocr-train.arrow
│ │ └── [ 59M] la_te_x_ocr-validation.arrow
│ ├── [ 0] master.incomplete_info.lock
│ └── [ 0] master_builder.lock
2. 有监督微调训练
有监督微调(Supervised Fine-Tuning, SFT),参数说明:
python [your path]/llm/ms-swift/swift/cli/sft.py --help
在运行过程中,自动下载数据集,至 MODELSCOPE_CACHE,并且转换成 SWIFT 支持的 Arrow 格式,无法使用默认数据集,即:
MAX_STEPS=2000 SIZE_FACTOR=8 MAX_PIXELS=602112 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7,8 nohup swift sft \
--model_type qwen2-vl-7b-instruct \
--model_id_or_path qwen/Qwen2-VL-7B-Instruct \
--sft_type lora \
--num_train_epochs 2 \
--batch_size 4 \
--eval_steps 1000 \
--save_steps 1000 \
--dataset latex-ocr-handwrite \
> nohup.latex-ocr-handwrite.out &tail -f nohup.latex-ocr-handwrite.out
如果使用,自定义数据集格式,参考 Swift - 自定义数据集,需要转换成标准的 json 或 jsonl 格式。
训练完成,输出日志,累计训练 11808 steps,如下:
[INFO:swift] Saving model checkpoint to [your folder]/output/qwen2-vl-7b-instruct/v0-20241011-205638/checkpoint-11808
Train: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11808/11808 [6:16:15<00:00, 1.91s/it]
[INFO:swift] last_model_checkpoint: [your folder]/output/qwen2-vl-7b-instruct/v0-20241011-205638/checkpoint-11808
[INFO:swift] best_model_checkpoint: [your folder]/output/qwen2-vl-7b-instruct/v0-20241011-205638/checkpoint-11000
[INFO:swift] images_dir: [your folder]/output/qwen2-vl-7b-instruct/v0-20241011-205638/images
[INFO:swift] End time of running main: 2024-10-12 03:17:31.020443
{'eval_loss': 0.12784964, 'eval_acc': 0.96368307, 'eval_runtime': 44.673, 'eval_samples_per_second': 21.355, 'eval_steps_per_second': 5.35, 'epoch': 2.0, 'global_step/max_steps': '11808/11808', 'percentage': '100.00%', 'elapsed_time': '6h 16m 14s', 'remaining_time': '0s'}
{'train_runtime': 22574.9994, 'train_samples_per_second': 8.369, 'train_steps_per_second': 0.523, 'train_loss': 0.14006881, 'epoch': 2.0, 'global_step/max_steps': '11808/11808', 'percentage': '100.00%', 'elapsed_time': '6h 16m 15s', 'remaining_time': '0s'}
输出如下,其中 images 保存训练过程的绘制图像,即:
[your folder]/output/qwen2-vl-7b-instruct/v0-20241011-205638
├── [4.0K] checkpoint-11000
├── [4.0K] checkpoint-11808
├── [4.0K] images
├── [1.1M] logging.jsonl
├── [4.0K] runs
├── [ 11K] sft_args.json
└── [4.8K] training_args.json
使用 TensorBoard 读取训练日志,即:
# http://127.0.0.1:6006/
tensorboard --logdir=[your folder]/output/qwen2-vl-7b-instruct/v0-20241011-205638/runs/ --host=0.0.0.0 --port=6006
训练 Loss,Smooth=0.9,如下:

学习率,如下:

验证集 Loss,eval_steps=1000,如下:

显存占用 (BatchSize=4),如下:

其他,如果使用 Matplotlib 和 TensorBoard 数据绘制 Loss 曲线,平滑度设置成 0.9,参考:
import os
from typing import Dict, List, Tupleimport matplotlib.pyplot as plt
from tensorboard.backend.event_processing.event_accumulator import EventAccumulatorItem = Dict[str, float]
TB_COLOR, TB_COLOR_SMOOTH = '#FFE2D9', '#FF7043'def read_tensorboard_file(fpath: str) -> Dict[str, List[Item]]:if not os.path.isfile(fpath):raise FileNotFoundError(f'fpath: {fpath}')ea = EventAccumulator(fpath)ea.Reload()res: Dict[str, List[Item]] = {}tags = ea.Tags()['scalars']print(f"[Info] tags: {tags}")for tag in tags:values = ea.Scalars(tag)r: List[Item] = []for v in values:r.append({'step': v.step, 'value': v.value})res[tag] = rreturn resdef tensorboard_smoothing(values: List[float], smooth: float = 0.9) -> List[float]:norm_factor = 0x = 0res: List[float] = []for i in range(len(values)):x = x * smooth + values[i] # Exponential decaynorm_factor *= smoothnorm_factor += 1res.append(x / norm_factor)return resdef plot_images(images_dir: str,tb_dir: str,smooth_key: List[str],smooth_val: float = 0.9,figsize: Tuple[int, int] = (8, 5),dpi: int = 100) -> None:"""Using tensorboard's data content to plot images"""os.makedirs(images_dir, exist_ok=True)fname = [fname for fname in os.listdir(tb_dir) if os.path.isfile(os.path.join(tb_dir, fname))][0]tb_path = os.path.join(tb_dir, fname)data = read_tensorboard_file(tb_path)for k in data.keys():_data = data[k]steps = [d['step'] for d in _data]values = [d['value'] for d in _data]if len(values) == 0:continue_, ax = plt.subplots(1, 1, squeeze=True, figsize=figsize, dpi=dpi)ax.set_title(k)if len(values) == 1:ax.scatter(steps, values, color=TB_COLOR_SMOOTH)elif k in smooth_key:ax.plot(steps, values, color=TB_COLOR)values_s = tensorboard_smoothing(values, smooth_val)ax.plot(steps, values_s, color=TB_COLOR_SMOOTH)else:ax.plot(steps, values, color=TB_COLOR_SMOOTH)# fpath = os.path.join(images_dir, k.replace('/', '_'))# plt.savefig(fpath, dpi=dpi, bbox_inches='tight')# plt.close()plt.show()plt.close()breakckpt_dir="[your path]/llm/ms-swift/output"
images_dir = os.path.join(ckpt_dir, 'images')
tb_dir = "[your path]/run_cuda/output/qwen2-vl-7b-instruct/v0-20241011-205638/runs/"
plot_images(images_dir, tb_dir, ['train/loss'], 0.9)
3. 合并 LoRA 模型
训练完成,输出的 LoRA 模型,如下:
(rag) output/qwen2-vl-7b-instruct/v0-20241011-205638/checkpoint-11808# tree -L 1 -h .
.
├── [5.0K] README.md
├── [ 712] adapter_config.json
├── [ 39M] adapter_model.safetensors
├── [ 67] additional_config.json
├── [ 383] configuration.json
├── [ 219] generation_config.json
├── [ 77M] optimizer.pt
├── [ 14K] rng_state.pth
├── [1.0K] scheduler.pt
├── [ 11K] sft_args.json
├── [608K] trainer_state.json
└── [7.2K] training_args.bin
将 LoRA 合并至源模型,同时,评估模型,即:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir [your path]/run_cuda/output/qwen2-vl-7b-instruct/v0-20241011-205638/checkpoint-11808/ \
--load_dataset_config true \
--merge_lora true
# 直接评估模型
使用合并之后的模型,进行推理:
# [your path]/run_cuda/output/qwen2-vl-7b-instruct/v0-20241011-205638/checkpoint-11808-merged
# CUDA_VISIBLE_DEVICES=0 swift infer --model_type qwen2-vl-7b-instruct
CUDA_VISIBLE_DEVICES=0 swift infer --ckpt_dir [your path]/run_cuda/output/qwen2-vl-7b-instruct/v0-20241011-205638/checkpoint-11808-merged
测试输出差异,即:
<<< <image>使用OCR识别图像中的Latex公式
Input an image path or URL <<< [your path]/llm/vision_test_data/latex-fullhand.png
d s ^ { 2 } = ( 1 - \frac { q c o s \theta } { r } ) ^ { \frac { 2 } { 1 + \kappa ^ { 2 } } } \{ d r ^ { 2 } + r ^ { 2 } d \theta ^ { 2 } + r ^ { 2 } s i n ^ { 2 } \theta d \varphi ^ { 2 } \} - \frac { d t ^ { 2 } } { ( 1 - \frac { q c o s \theta } { r } ) ^ { \frac { 2 } { 1 + \kappa ^ { 2 } } } } .# 之前格式
# ds^2 = (1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}} \{d\delta^2 + r^2 d\theta^2 + n^2 s/n^2 d\phi^2 \} - \frac{dt^2}{(1 - \frac{qcos\theta}{r})^{\frac{2}{1 + \alpha^2}}}.
注意:格式与之前差异较大,模型已经学会新的 OCR 输出格式,之前的输出格式没有空格,新的输出格式包括空格,与微调数据一致。
测试微调的训练数据格式,与 LoRA 输出保持一致,训练成功,如下:
d s ^ { 2 } = ( 1 - { \frac { q c o s \theta } { r } } ) ^ { \frac { 2 } { 1 + \alpha ^ { 2 } } } \lbrace d r ^ { 2 } + r ^ { 2 } d \theta ^ { 2 } + r ^ { 2 } s i n ^ { 2 } \theta d \varphi ^ { 2 } \rbrace - { \frac { d t ^ { 2 } } { ( 1 - { \frac { q c o s \theta } { r } } ) ^ { \frac { 2 } { 1 + \alpha ^ { 2 } } } } } \, .
\widetilde \gamma _ { \mathrm { h o p f } } \simeq \sum _ { n > 0 } \widetilde { G } _ { n } { \frac { ( - a ) ^ { n } } { 2 ^ { 2 n - 1 } } }
4. 训练参数 --dataset 调用逻辑
数据集的声明位于 swift/llm/utils/dataset.py,参考:
latex_ocr_print = 'latex-ocr-print'register_dataset(DatasetName.latex_ocr_print, # dataset_name'AI-ModelScope/LaTeX_OCR', # dataset_id_or_path['full'], # subsets_preprocess_latex_ocr_dataset,# preprocess_funcget_dataset_from_repo, # get_functionsplit=['validation', 'test'], # There are some problems in the training dataset.hf_dataset_id='linxy/LaTeX_OCR',tags=['chat', 'ocr', 'multi-modal', 'vision'])
其中 register_dataset 函数的作用是,把 dataset_info 注册进入 DATASET_MAPPING 中:
dataset_info = {'dataset_id_or_path': dataset_id_or_path,'subsets': subsets,'preprocess_func': preprocess_func,'split': split,'hf_dataset_id': hf_dataset_id,'is_local': is_local,**kwargs
}
DATASET_MAPPING[dataset_name] = dataset_info
其中 args.dataset 参数是位于 _get_train_val_dataset 函数中:
sft_main = get_sft_main(SftArguments, llm_sft)def llm_sft(args: SftArguments) -> Dict[str, Any]:# ...train_dataset, val_dataset = prepare_dataset(args, template, msg) # 调用def prepare_dataset(args, template: Template, msg: Optional[Dict[str, Any]] = None):# ...train_dataset, val_dataset = _get_train_val_dataset(args) # 调用def _get_train_val_dataset(args: SftArguments) -> Tuple[HfDataset, Optional[HfDataset]]:# ...train_dataset, val_dataset = get_dataset(args.dataset,args.dataset_test_ratio,args.dataset_seed,check_dataset_strategy=args.check_dataset_strategy,model_name=args.model_name,model_author=args.model_author,streaming=args.streaming,streaming_val_size=args.streaming_val_size,streaming_buffer_size=args.streaming_buffer_size)
即 swift/llm/sft.py#llm_sft() -> prepare_dataset() -> _get_train_val_dataset() -> get_dataset()
在 swift/llm/utils/dataset.py 中,即:
def get_dataset(dataset_name_list: Union[List[str], str],dataset_test_ratio: float = 0.,dataset_seed: Union[int, RandomState] = 42,check_dataset_strategy: Literal['none', 'discard', 'error', 'warning'] = 'none',*,# for self-cognitionmodel_name: Union[Tuple[str, str], List[str], None] = None,model_author: Union[Tuple[str, str], List[str], None] = None,**kwargs) -> Tuple[DATASET_TYPE, Optional[DATASET_TYPE]]:"""Returns train_dataset and val_dataset"""# ...if isinstance(dataset_name_list, str):dataset_name_list = [dataset_name_list]# ...# dataset_id_or_path -> dataset_namedataset_name_list = _dataset_id_to_name(dataset_name_list)
调用 _dataset_id_to_name() 函数:
- 调用
register_dataset_info()函数 - 调用
register_local_dataset()函数 - 调用
register_dataset()函数 - 调用
get_local_dataset()函数 - 调用
load_dataset_from_local()函数 - 处理
.jsonl、.json、.csv文件 - 或者调用
preprocess_func()函数
即:
if dataset_path.endswith('.csv'):dataset = HfDataset.from_csv(dataset_path, na_filter=False)
elif dataset_path.endswith('.jsonl') or dataset_path.endswith('.json'):dataset = HfDataset.from_json(dataset_path)
else:raise ValueError('The custom dataset only supports CSV, JSONL or JSON format.')
dataset = preprocess_func(dataset)
相关文章:
LLM - 使用 ModelScope SWIFT 测试 Qwen2-VL 的 LoRA 指令微调 教程(2)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/142827217 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 SWIFT …...

2024 年热门前端框架对比及选择指南
在前端开发的世界里,框架的选择对于项目的成功至关重要。不同的框架有着不同的设计理念、生态系统和适用场景,因此,开发者在选框架时需要权衡多个因素。本文将对当前最流行的前端框架——React、Vue、Angular、Svelte 和 Solid——进行详细对…...

map_server
地图格式 此软件包中的工具处理的地图以两个文件的形式存储。YAML 文件描述地图的元数据,并命名图像文件。图像文件编码了占用数据。 图像格式 图像文件描述世界中每个单元格的占用状态,并使用相应像素的颜色表示。在标准配置中,较白的像素…...

无人机航拍视频帧处理与图像拼接算法
无人机航拍视频帧处理与图像拼接算法 1. 视频帧截取与缩放 在图像预处理阶段,算法首先逐帧地从视频中提取出各个帧。 对于每一帧图像,算法会执行缩放操作,以确保所有帧都具有一致的尺寸,便于后续处理。 2. 图像配准 在图像配准阶段,算法采用SIFT(尺度不变特征变换)算…...

搬砖11、Python 文件和异常
文件和异常 实际开发中常常会遇到对数据进行持久化操作的场景,而实现数据持久化最直接简单的方式就是将数据保存到文件中。说到“文件”这个词,可能需要先科普一下关于文件系统的知识,但是这里我们并不浪费笔墨介绍这个概念,请大…...
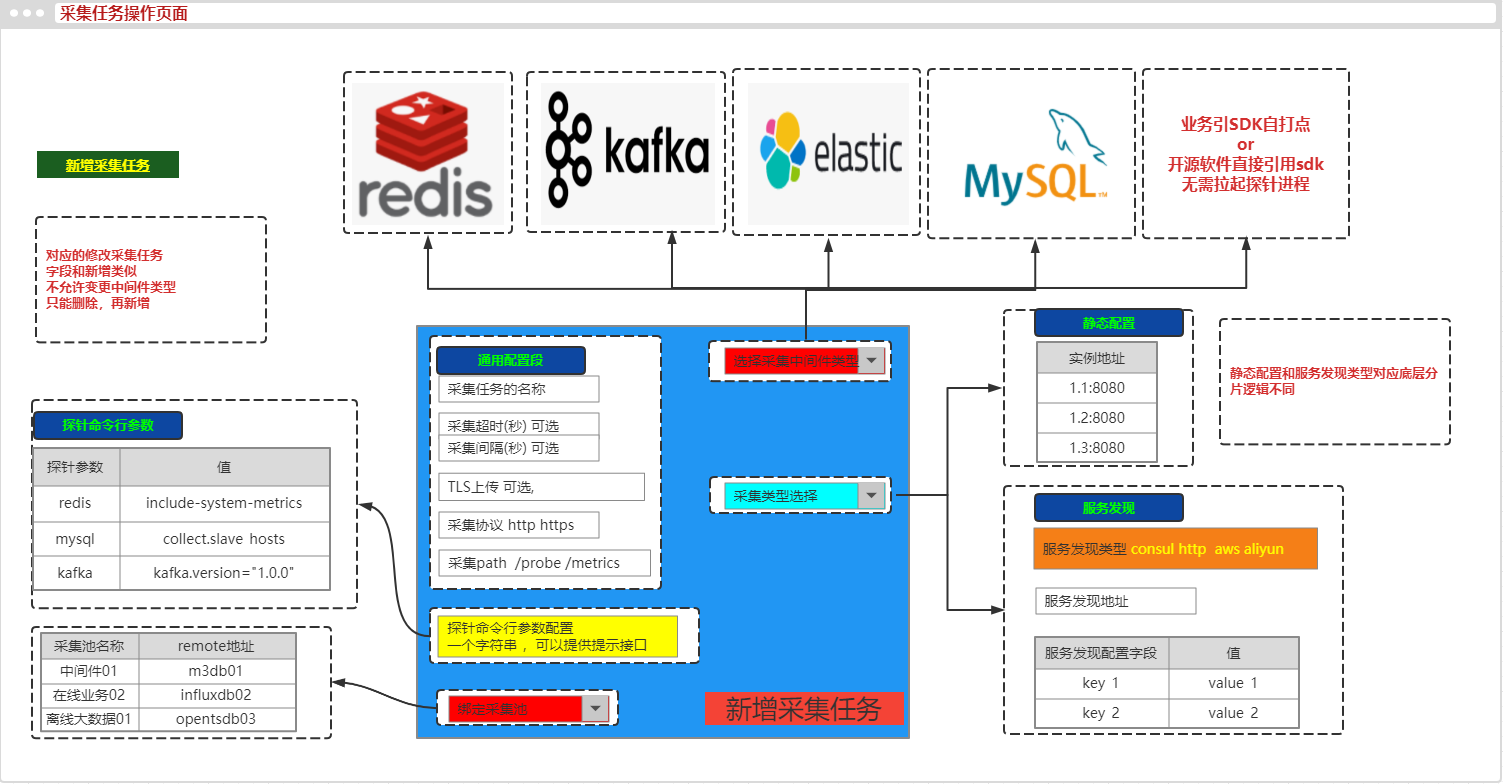
24.6 监控系统在采集侧对接运维平台
本节重点介绍 : 监控系统在采集侧对接运维平台 服务树充当监控系统的上游数据提供者在运维平台上 可以配置采集任务 exporter改造成探针型将给exporter传参和修改prometheus scrape配置等操作页面化 监控系统在采集侧对接运维平台 服务树充当监控系统的上游数据提供者在运…...

refresh-1
如果设置了刷新标志(refreshFlag): - 如果CAT(配置文件管理代理)未初始化,eUICC应返回一个错误代码commandError。 - 对于MEP-A2,eUICC可以返回一个错误代码commandError。 - 如果目标端口上正…...
如何写好一篇计算机应用的论文?
计算机应用是一个广泛的领域,涵盖了从软件开发到数据分析、人工智能、网络安全等多个方向。选择一个合适的毕业设计题目,不仅要考虑个人兴趣和专业技能,还要考虑项目的可行性、创新性以及对未来职业发展的帮助。以下是一些建议,帮…...

工业 5.0 时代的数字孪生:迈向高效和可持续的智能工厂
数字孪生(物理机器或流程的虚拟代表)正在彻底改变工业物联网和流程监控。这项新兴技术可实现实时模拟,提高效率、可持续性并降低成本。航空航天和汽车等行业已经从这些创新系统中获益匪浅 数字孪生是数字模拟器的演变,因此&#x…...

Python脚本之获取Splunk数据发送到第三方UDP端口
原文地址:https://www.program-park.top/2024/10/12/python_21/ 在 Linux 环境执行脚本,Python需要引入对应依赖: pip install splunk-sdk离线环境下,可手动执行python进入 Python 解释器的交互式界面,输入以下命令&a…...

Protobuf:复杂类型接口
Protobuf:复杂类型接口 package字段规则复杂类型enumAnyoneofmap 本博客基于proto3语法,讲解protobuf中的复杂类型。 package 在.proto文件中,支持导入其它.proto文件的内容,例如: test.proto: syntax …...

Git Push 深度解析:命令的区别与实践
目录 命令一:git push origin <branch-name>命令二:git push Factory_sound_detection_tool test工作流程:两者的主要区别实践中的应用总结 Git 是一种分布式版本控制系统,它允许用户对代码进行版本管理。在 Git 中…...
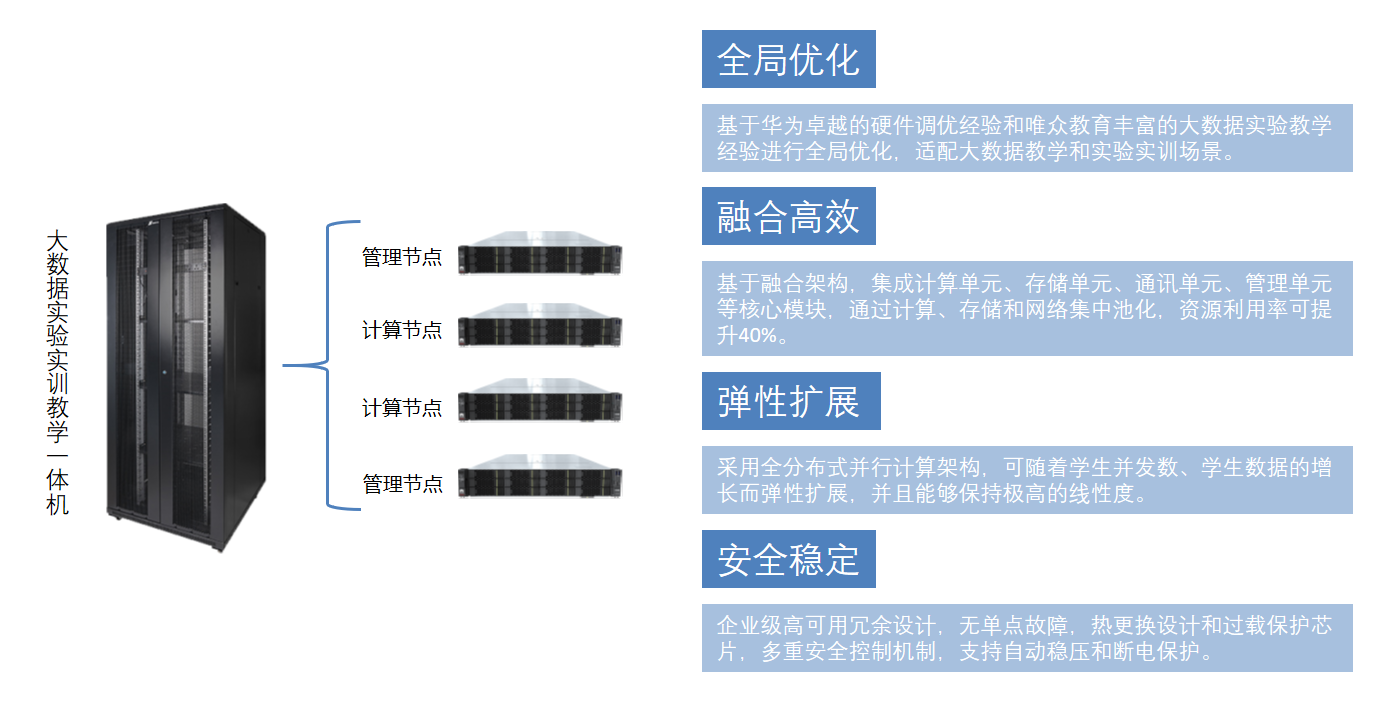
大数据开发基础实训室设备
大数据实验实训一体机 大数据实验教学一体机是一种专为大数据教育设计的软硬件融合产品,其基于华为机架服务器进行了调优设计,从而提供了卓越的性能和稳定性。这一产品将企业级虚拟化管理系统与实验实训教学信息化平台内置于一体,通过软硬件…...
)
【数据结构】string(C++模拟实现)
string构造 string::string(const char* str):_size(strlen(str)) {_str new char[_size 1];_capacity _size;strcpy(_str, str); }// s2(s1) string::string(const string& s) {_str new char[s._capacity 1];strcpy(_str, s._str);_size s._size;_capacity s._cap…...

【笔记】I/O总结王道强化视频笔记
文章目录 从中断控制器的角度来理解整个中断处理的过程复习 处理器的中断处理机制**中断驱动I/O方式** printf——从系统调用到I/O控制方式的具体实现1轮询方式下输出一个字符串(程序查询)中断驱动方式下输出一个字符串中断服务程序中断服务程序与设备驱动程序之间的关系 DMA方…...

XML XSLT:转换与呈现数据的力量
XML XSLT:转换与呈现数据的力量 XML(可扩展标记语言)和XSLT(XML样式表转换语言)是现代信息技术中不可或缺的工具,它们在数据交换、存储和呈现方面发挥着重要作用。本文将深入探讨XML和XSLT的概念、应用及其在信息技术领域的重要性。 XML:数据交换的标准 XML是一种用于…...

ES6总结
1.let和const以及与var区别 1.1 作用域 var: 变量提升(Hoisting):var 声明的变量会被提升到其作用域的顶部,但赋值不会提升。这意味着你可以在声明之前引用该变量(但会得到 undefined)。 con…...

晶体匹配测试介绍
一、晶体参数介绍 晶体的电气规格相对比较简单,如下: 我们逐一看看每个参数, FL就是晶体的振动频率,这个晶体是24.576MHz的。 CL就是负载电容,决定了晶体频率是否准确,包括外接的实际电容、芯片的等效电容以及PCB走线的寄生电容等,核心参数。 Frequency Tolerance是…...

超声波清洗机靠谱吗?适合学生党入手的四款眼镜清洗机品牌推荐!
有没有学生党还不知道双十一买什么?其实可以去看看超声波清洗机,说实话它的实用性真的很高,对于日常用于清洗眼镜真的非常合适,不仅可以帮助大家节约时间而且还能把眼镜清洗的干净透亮,接下来我就来为大家带来四款好用…...

Java生成图片_基于Spring AI
Spring AI 优势 过去,使用Java编写AI应用时面临的主要困境是没有统一且标准的封装库,开发者需自行对接各个AI服务提供商的接口,导致代码复杂度高、迁移成本大。如今,Spring AI Alibaba的出现极大地缓解了这一问题,它提…...

[2026最新版] 保姆级 Burp Suite 安装教程
在Windows上安装教程如下: 文件下载:点我下载(NAS分享链接,若链接过期或无法下载,请联系作者:zeyun4699gmail.com) 步骤一:下载来自我上传的文件(你会得到步骤二的图片…...

重复内容误标率高达37%?NotebookLM检测逻辑漏洞全曝光,立即修复这6个隐藏开关
更多请点击: https://intelliparadigm.com 第一章:重复内容误标率高达37%?NotebookLM检测逻辑漏洞全曝光,立即修复这6个隐藏开关 NotebookLM 的“重复内容检测”功能并非基于端到端语义比对,而是依赖于分块哈希&#…...

现代Web全栈技术栈实践:从Next.js到PostgreSQL的标准化开发方案
1. 项目概述:一个现代Web应用的技术栈实践最近在技术社区里看到一个挺有意思的项目,叫stack-wuh/x.wuh.site。光看这个名字,可能有点摸不着头脑,但拆解一下就能明白,这本质上是一个关于“技术栈”的实践项目。stack-wu…...

创业公司如何利用taotoken的token plan套餐控制ai研发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业公司如何利用Taotoken的Token Plan套餐控制AI研发成本 对于早期科技创业公司而言,产品创新与成本控制是两条必须并…...

终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位
终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款…...

终极指南:如何用ROFL-Player永久解决英雄联盟回放版本兼容性问题
终极指南:如何用ROFL-Player永久解决英雄联盟回放版本兼容性问题 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄…...

告别商业收费与审核枷锁:深度拆解 Open-Generative-AI,构建 MIT 开源、零过滤的私有化视频生成工作站
发布日期: 2026-05-18标签: #Open-Generative-AI #Sora #Flux #Veo #AI视频生成 #私有化部署一、 引言在 2026 年,大模型生成图像与视频(Text-to-Video)的技术已经炉火纯青,但创作者们依然面临着三大难以言…...
)
NotebookLM大纲自动生成正在淘汰传统笔记法(内部白皮书泄露:Google Labs 2024 Q2 A/B测试结果首次公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM大纲自动生成正在淘汰传统笔记法(内部白皮书泄露:Google Labs 2024 Q2 A/B测试结果首次公开) Google Labs 2024年第二季度A/B测试数据显示,启用…...

Crucible:基于Docker Compose的轻量级容器化部署框架实践
1. 项目概述:一个轻量级的容器化应用部署框架最近在折腾个人项目和小型团队应用的部署时,我一直在寻找一个介于“裸跑Docker命令”和“上全套Kubernetes”之间的解决方案。前者太琐碎,后者又太重,对于非核心业务或者资源有限的场景…...

StreamFX终极指南:5个简单技巧打造专业级OBS直播画面
StreamFX终极指南:5个简单技巧打造专业级OBS直播画面 【免费下载链接】obs-StreamFX StreamFX is a plugin for OBS Studio which adds many new effects, filters, sources, transitions and encoders! Be it 3D Transform, Blur, complex Masking, or even custom…...