sklearn pipeline
示例代码
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
import numpy as np
import scipy.linalg
from sklearn.preprocessing import LabelEncoder, StandardScaler
import optuna
import scipy.linalg
from sklearn.linear_model import BayesianRidge
import pandas as pd
from sklearn.model_selection import LeaveOneOut, cross_val_scoreclass EmscScaler(object):def __init__(self, order=1):self.order = orderself._mx = Nonedef mlr(self, x, y):"""Multiple linear regression fit of the columns of matrix x(dependent variables) to constituent vector y (independent variables)order - order of a smoothing polynomial, which can be includedin the set of independent variables. If order isnot specified, no background will be included.b - fit coeffsf - fit result (m x 1 column vector)r - residual (m x 1 column vector)"""if self.order > 0:s = np.ones((len(y), 1))for j in range(self.order):s = np.concatenate((s, (np.arange(0, 1 + (1.0 / (len(y) - 1)), 1.0 / (len(y) - 1)) ** j).reshape(-1,1)[0:len(y)]),1)X = np.concatenate((x.reshape(-1,1), s), 1)else:X = x# calc fit b=fit coefficientsb = np.dot(np.dot(scipy.linalg.pinv(np.dot(X.T, X)), X.T), y)f = np.dot(X, b)r = y - freturn b, f, rdef fit(self, X, y=None):"""fit to X (get average spectrum), y is a passthrough for pipeline compatibility"""self._mx = np.mean(X, axis=0)def transform(self, X, y=None, copy=None):if type(self._mx) == type(None):print("EMSC not fit yet. run .fit method on reference spectra")else:# do fittingcorr = np.zeros(X.shape)for i in range(len(X)):b, f, r = self.mlr(self._mx, X[i, :])corr[i, :] = np.reshape((r / b[0]) + self._mx, (corr.shape[1],))return corrdef fit_transform(self, X, y=None):self.fit(X)return self.transform(X)from sklearn.base import BaseEstimator, TransformerMixin
class SpectraPreprocessor(BaseEstimator, TransformerMixin):def __init__(self, emsc_order=3,X_ref=None):self.emsc_order = emsc_orderself.emsc_scalers = [EmscScaler(order=emsc_order) for _ in range(4)]self.X_ref = X_refdef fit(self, X, y=None):X_ref = self.X_refif X_ref is None:X_ref = X.copy()# Define the column ranges for each segmentranges = [(0, 251), (281, 482), (482, 683), (683, 854)]# Fit EmscScaler for each segmentfor i, (start, end) in enumerate(ranges):self.emsc_scalers[i].fit(X_ref[:, start:end])return selfdef transform(self, X, y=None):# Define the column ranges for each segmentranges = [(0, 251), (281, 482), (482, 683), (683, 854)]# Transform each segmenttransformed_segments = []for i, (start, end) in enumerate(ranges):segment = X[:, start:end]transformed_segment = self.emsc_scalers[i].transform(segment)transformed_segments.append(transformed_segment)# Concatenate all transformed segmentsreturn np.concatenate(transformed_segments, axis=1)def fit_transform(self, X, y=None):self.fit(X)return self.transform(X)def bayesian_ridge_optuna_for_emsc_data(x_train, y_train, pipeline_):def objective(trial):try:alpha_1 = trial.suggest_float('alpha_1', 0.001, 1, log=True)alpha_2 = trial.suggest_float('alpha_2', 0.001, 1, log=True)lambda_1 = trial.suggest_float('lambda_1', 0.001, 1, log=True)lambda_2 = trial.suggest_float('lambda_2', 0.001, 1, log=True)model = pipeline_.set_params(bayesian_ridge__alpha_1=alpha_1,bayesian_ridge__alpha_2=alpha_2,bayesian_ridge__lambda_1=lambda_1,bayesian_ridge__lambda_2=lambda_2)model.fit(x_train, y_train)score = cross_val_score(model, x_train, y_train, cv=10, n_jobs=-1, scoring='r2')return np.mean(score)except ValueError as e:return -np.infoptuna.logging.set_verbosity(optuna.logging.WARNING)pruner = optuna.pruners.MedianPruner()study = optuna.create_study(direction="maximize", pruner=pruner)study.optimize(objective, n_trials=500, show_progress_bar=True, n_jobs=1)return study.best_paramsdef getdata(filenamex, filenamey):x = pd.read_csv(filenamex, header=None)y = pd.read_csv(filenamey)data = pd.concat([x, y], axis=1)return dataname = 'test'
x, y = np.random.rand(100,884), np.random.rand(100)
x_ref = np.random.rand(30,884)
pipeline = Pipeline([('preprocessor', SpectraPreprocessor(emsc_order=3, X_ref=None)),('scaler', StandardScaler()),('bayesian_ridge', BayesianRidge())
])pipeline.set_params(preprocessor__X_ref=x_ref)############################################################################################################################################################
best_params = bayesian_ridge_optuna_for_emsc_data(x, y, pipeline)
############################################################################################################################################################pipeline.set_params(bayesian_ridge__alpha_1=best_params['alpha_1'],bayesian_ridge__alpha_2=best_params['alpha_2'],bayesian_ridge__lambda_1=best_params['lambda_1'],bayesian_ridge__lambda_2=best_params['lambda_2']
)
pipeline.fit(x, y)
y_pred = pipeline.predict(x)
print(y_pred)
相关文章:

sklearn pipeline
示例代码 from sklearn.pipeline import Pipeline from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB import numpy as np import scipy.linalg from sklearn.preprocessing import LabelEncoder, StandardScaler …...

springboot实现服务注册与发现
在Spring Boot应用中实现服务注册与发现通常使用Spring Cloud框架,其中Eureka和Consul是两个常用的服务注册与发现组件。以下是使用Eureka来实现服务注册与发现的基本步骤。 准备工作 添加依赖:在你的Spring Boot项目的pom.xml文件中添加Eureka相关的依…...

美格智能亮相2024中国移动全球合作伙伴大会,共赢AI+时代
2024年10月11日至13日,主题为“智焕新生 共创AI时代”的2024中国移动全球合作伙伴大会,在广州琶洲保利世贸博览馆召开,作为中国移动重要的战略合作伙伴,美格智能亮相4号馆E22展位,与上百家知名企业共同展示最新数智化创…...

【LeetCode】动态规划—309. 买卖股票的最佳时机含冷冻期(附完整Python/C++代码)
动态规划—309. 买卖股票的最佳时机含冷冻期 题目描述前言基本思路1. 问题定义2. 理解问题和递推关系状态定义:状态转移公式:初始条件: 3. 解决方法动态规划方法伪代码: 4. 进一步优化5. 小总结 Python代码Python代码解释总结 C代…...
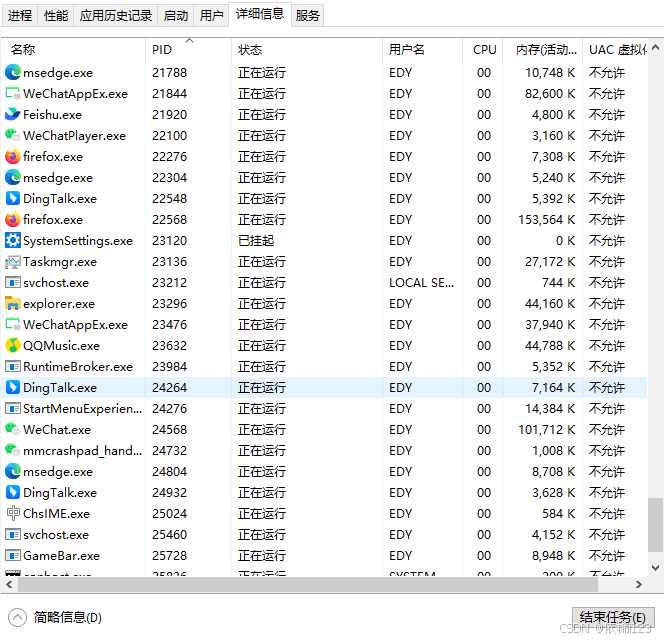
IDE启动失败
报错:Cannot connect to already running IDE instance. Exception: Process 24,264 is still running 翻译:无法连接到已运行的IDE实例。异常:进程24,264仍在运行 打开任务管理器,找到PID为24264的CPU线程,强行结束即可。 【Ct…...
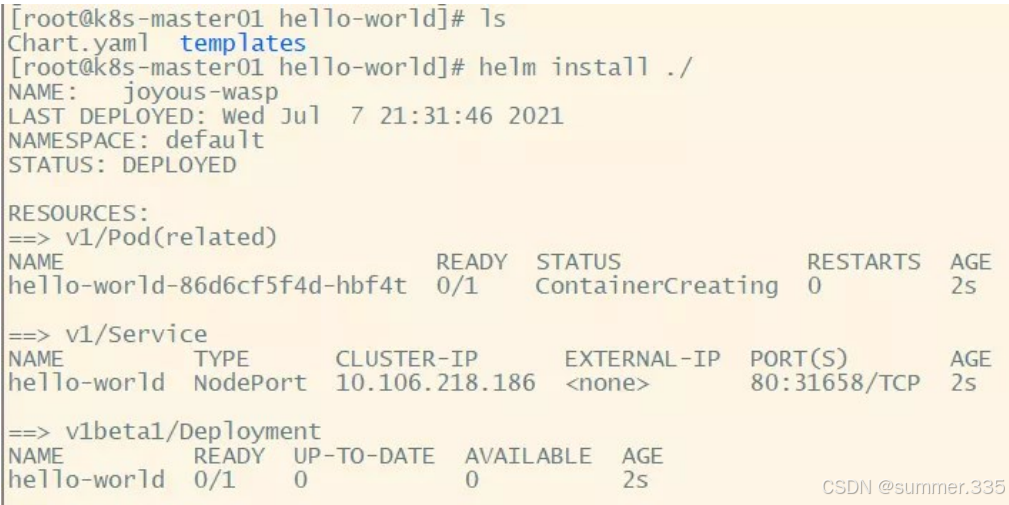
【Kubernetes】常见面试题汇总(六十)
目录 131. pod 一直处于 pending 状态? 132. helm 安装组件失败? 特别说明: 题目 1-68 属于【Kubernetes】的常规概念题,即 “ 汇总(一)~(二十二)” 。 题目 69-113 属于…...

maven dependency中scope的取值类型
在 Maven 中,<scope> 标签用于定义依赖项的范围,以指定依赖在不同阶段的可见性和生命周期。以下是 Maven 中常见的 <scope> 取值类型的详细介绍: 1. **compile**: - 默认的依赖范围,适用于编译、测试和…...
线性代数在大一计算机课程中的重要性
线性代数在大一计算机课程中的重要性 线性代数是一门研究向量空间、矩阵运算和线性变换的数学学科,在计算机科学中有着广泛的应用。大一的计算机课程中,线性代数的学习为学生们掌握许多计算机领域的关键概念打下了坚实的基础。本文将介绍线性代数的基本…...

笔记本电脑按住电源键强行关机,对电脑有伤害吗?
电脑卡住了,我们习惯性地按住电源键或者直接拔掉电源强制关机,但这种做法真的安全吗?会不会对电脑造成伤害呢? 其实,按住电源键关机和直接拔掉电源关机是不一样的。它们在硬件层面有着本质区别。 按住电源键关机 当…...

如何将 cryptopp库移植到UE5内
cryptopp是一个开源免费的算法库,这个库的用途非常多,我常常用这个库来做加解密的运算。这段时间在折腾UE5.4.4,学习的过程中,准备把cryptopp移植到游戏的工程内,但UE的编译环境和VS的编译环境完全不同,能在…...

SpringBoot 集成GPT实战,超简单详细
Spring AI 介绍 在当前的AI应用开发中,像OpenAI这样的GPT服务提供商主要通过HTTP接口提供服务,这导致大部分Java开发者缺乏一种标准化的方式来接入这些强大的语言模型。Spring AI Alibaba应运而生,它作为Spring团队提供的一个解决方案&…...

基于Langchain框架下Prompt工程调教大模型(LLM)[输入输出接口、提示词模板与例子选择器的协同应用
大家好,我是微学AI,今天给大家介绍一下基于Langchain框架下Prompt工程调教大模型(LLM)[输入输出接口、提示词模板与例子选择器的协同应用。本文深入探讨了Langchain框架下的Prompt工程在调教LLM(大语言模型)方面的应用,…...

Vue基于vue-office实现docx、xlsx、pdf文件的在线预览
文章目录 1、vue-office概述2、效果3、实现3.1 安装3.2 使用示例3.2.1 docx文档的预览3.2.2 excel文档预览3.2.3 pdf文档预览1、vue-office概述 vue-office是一个支持多种文件(docx、.xlsx、pdf)预览的vue组件库,支持vue2和vue3。 功能特色: 一站式:提供docx、.xlsx、pdf多…...
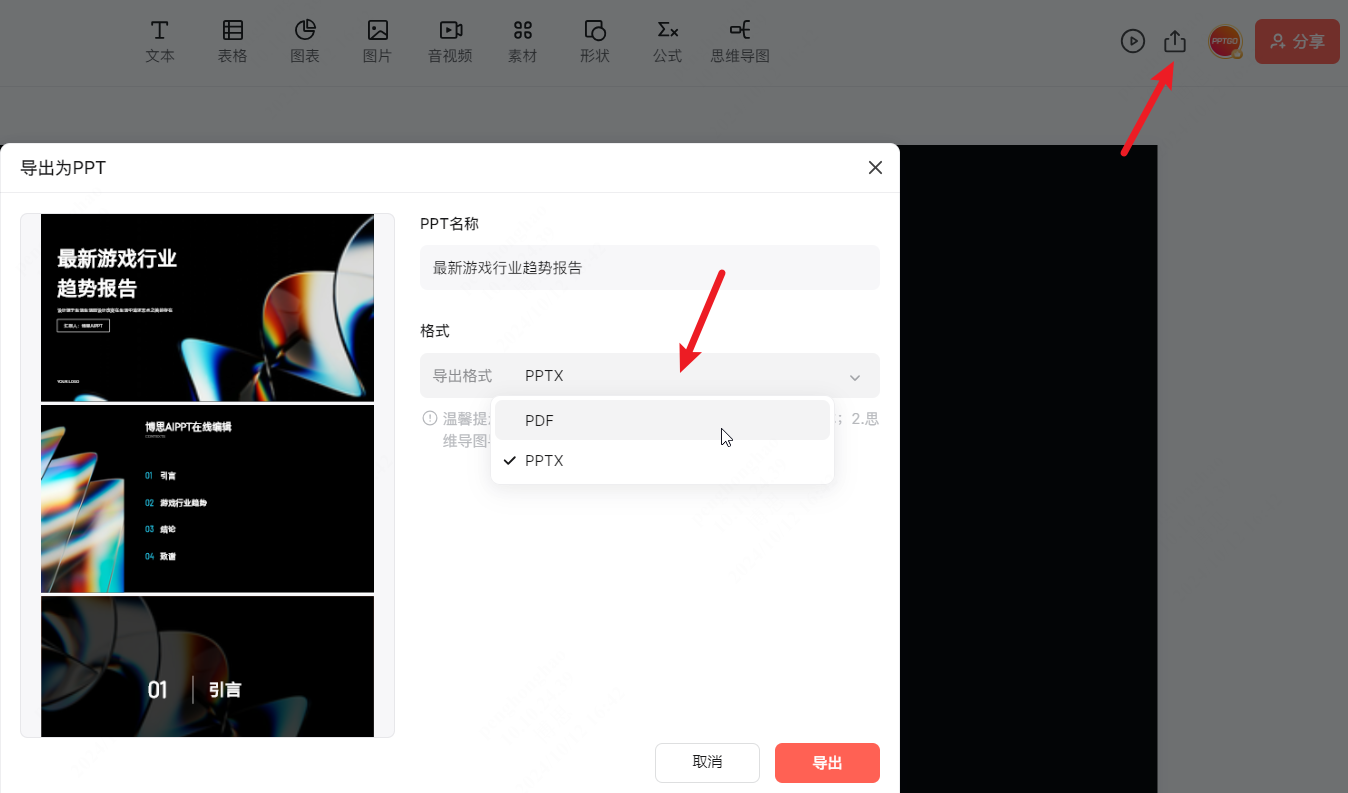
哪个软件可以在线编辑ppt? 一口气推荐5个做ppt的得力助手!
日常在制作ppt时,你是否经常遇到这些问题,ppt做到一半,电脑突然死机,来不及保存的ppt付之一炬,分分钟让人原地崩溃…… 好在许多团队也在持续跟进这个问题,给出了一个一劳永逸的最佳方案——PPT在线编辑&a…...

Django学习笔记九:Django中间件Middleware
Django中间件(Middleware)是一段在Django的请求/响应处理过程中,可以介入并改变请求或响应的代码。中间件是Django框架中一个非常强大的功能,它允许你在Django的视图函数之前或之后执行自定义代码。 中间件可以用于: …...

原来自媒体高手都是这样选话题的,活该人家赚大钱,真后悔知道晚了
做自媒体,话题是战略,内容是战术。 战略是要做正确的事情,战术是如何正确地做事。 如果战略上错误,战术上再勤奋努力都无济于事。 《孙子兵法》有云:“胜者先胜而后求战,败者先战而后求胜。” 相信很多…...

胤娲科技:AI绘梦师——一键复刻梵高《星空》
想象一下,你手中握有一张梵高的《星空》原图,只需轻轻一点,AI便能化身绘画大师,一步步在画布上重现那璀璨星河。 这不是科幻电影中的桥段,而是华盛顿大学科研团队带来的“Inverse Painting”项目,正悄然改变…...

第18课-C++继承:探索面向对象编程的复用之道
一、引言 C 作为一种强大的编程语言,继承机制在面向对象编程中扮演着至关重要的角色。它允许开发者基于已有的类创建新的类,从而实现代码的复用和功能的扩展。然而,继承的概念和使用方法并非一目了然,特别是在处理复杂的继承关系时…...

麒麟V10系统下的调试工具(网络和串口调试助手)
麒麟V10系统下的调试工具(网络和串口调试助手) 1.安装网络调试助手mnetassist arm64-main ①在linux下新建一个文件夹 mkdir /home/${USER}/NetAssist②将mnetassist arm64-main.zip拷贝到上面文件夹中,并解压给权限 cd /home/${USER}/Ne…...

ssh封装上传下载
pip install paramiko import paramikoclass SSHClient:def __init__(self, host, port, username, password):self.host = hostself.port = portself.username = usernameself.password = passwordself.ssh = Noneself.sftp = Nonedef connect(self):"""连接到…...

【HarmonyOS6.1全场景实战】基线版本:我用了15篇文章,造出了一个能登录、能推荐、带后台的鸿蒙全栈App
我用了15篇文章,造出了一个能登录、能推荐、带后台的鸿蒙全栈App 摘要:从开篇词到第15篇,《灵犀厨房》的第一个里程碑版本 v2.0 正式发布。它不再是一个前端Demo,而是一个拥有用户认证系统、Python Flask后台、MySQL数据库、AI智能…...

中国500万医生的新AI:顶刊独家联手,卷的就是证据源
金磊 发自 杭州量子位 | 公众号 QbitAI很反差。明明是一场AI的发布会,台下却坐满了医学界的大佬们:有北大、清华的,有浙江、上海的,甚至医学顶刊BMJ集团的主编都来围观了……△图片由AI生成为啥会这样?因为阿里健康正式…...

091、力控制:阻抗控制与导纳控制
091 力控制:阻抗控制与导纳控制 从一次机器人撞坏夹具说起 去年调试一台六轴协作机器人,做精密装配。力控参数调了一周,结果在某个姿态下,机器人突然“发疯”,直接把气动夹具怼变形了。事后复盘,发现是阻抗控制里的刚度矩阵设错了——不是数值大小的问题,是坐标系搞反…...

别让电流倒灌毁了你的MCU!手把手教你用肖特基二极管和MOS管搞定电平转换电路
嵌入式系统电平转换电路设计实战:阻断电流倒灌的5种硬件方案 当3.3V单片机需要驱动5V传感器时,或者5V逻辑器件要与1.8V处理器通信时,电平转换电路就成了系统稳定的关键屏障。去年我在工业控制器项目中就曾遇到一个典型问题:当5V外…...
)
别只装AlexNet了!手把手教你在MATLAB里玩转更多预训练模型(VGG, ResNet, MobileNet安装指南)
别只装AlexNet了!手把手教你在MATLAB里玩转更多预训练模型(VGG, ResNet, MobileNet安装指南) 当你第一次在MATLAB中调用alexnet函数时,那种"开箱即用"的体验确实令人惊艳。但就像一位米其林大厨不会只满足于使用基础厨具…...

反激变压器优化设计实战:从磁芯选型到绕制工艺的工程指南
1. 项目概述:为什么反激变压器设计是开关电源的“心脏手术”? 在开关电源的世界里,反激拓扑(Flyback)就像一位“全能型选手”,从手机充电器到家电辅助电源,再到工业控制模块,几乎无处…...

回溯算法:暴力枚举最优解
一、上期回顾 吃透二分查找三大模板:基础查找、左边界、右边界,掌握二分答案解题思维,有序数组最优解法全部拿下。今天正式攻克回溯算法,暴力枚举最优写法,解决排列、组合、子集、棋盘类所有搜索题。二、递归与回溯核心…...

RT-Thread实战:AB32VG1驱动I2C OLED屏实现上电自启动
1. 项目概述与核心思路最近在折腾中科蓝讯的AB32VG1开发板,想用它来驱动一块I2C接口的OLED屏幕。在网上搜了一圈,发现大部分教程都停留在“官方例程”的层面——也就是在RT-Thread的msh(类似shell的命令行)里输入指令来测试驱动。…...

抖音批量下载神器:三步搞定无水印视频下载,告别手动烦恼
抖音批量下载神器:三步搞定无水印视频下载,告别手动烦恼 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser f…...

Claude技能库开发指南:工具调用原理与模块化实践
1. 项目概述:一个为Claude模型量身定制的技能库最近在探索如何让Claude这类大型语言模型更好地融入我的日常工作流时,我遇到了一个非常有意思的项目——DhanushNehru/claude-skills。简单来说,这是一个专门为Anthropic的Claude模型设计的“技…...