Hive数仓操作(十七)
一、Hive的存储
一、Hive 四种存储格式
在 Hive 中,支持四种主要的数据存储格式,每种格式有其特点和适用场景,不过一般只会使用Text 和 ORC :
1. Text
- 说明:Hive 的默认存储格式。
- 存储方式:行存储。
- 优点:简单易用,可以通过
LOAD DATA直接加载数据。 - 缺点:占用空间较大,读取和解析速度较慢。
2. Sequence
- 说明:以序列格式存储数据。
- 存储方式:行存储,使用键值对(key-value)方式存储数据。
- 优点:在某些情况下支持高效的压缩。
- 缺点:占用空间比 Text 格式要大。
3. RC (Record Columnar)
- 说明:由 Facebook 创建的一种列存储格式。
- 存储方式:列存储,采用懒加载存储和管理数据。
- 优点:对每一行的数据进行单独压缩;查询时只读取需要的数据,提高查询速度。
- 缺点:相较于 Text 格式,导入数据不够方便。
4. ORC (Optimized Row Columnar)
- 说明:在公司工作中使用最广泛的存储格式,是 RC 的优化版本。
- 存储方式:列存储,具备懒加载特点。
- 优点:优化了文件的压缩和存储,查询性能非常高。
- 缺点:同样不支持直接使用
LOAD DATA导入。
注意事项
- 对于 Sequence、RC 和 ORC 格式,不能直接使用
LOAD DATA命令导入数据。需要先将数据导入到一个 Text 格式的表中,再使用INSERT OVERWRITE TABLE的方式将数据复制到目标表中。
二、Hive 行列存储

1. 行存储的特点(TEXT)
- 查询性能:
- 当查询需要满足条件的一整行数据时,行存储具有优势。只需找到一个值,其余的值都存储在相邻的位置,可以快速访问。
2. 列存储的特点(ORC)
- 数据读取效率:
- 在查询仅需要少数几个字段时,列存储能显著减少读取的数据量,因为每个字段的数据聚集存储。
- 数据类型一致性:
- 每个字段的数据类型相同,这使得列式存储能够针对性地设计更高效的压缩算法,优化存储空间。
三、Hive 压缩格式
1. TEXTFILE
- 压缩算法:可使用 Gzip、Bzip2 等压缩算法。
- 适用场景:适合需要频繁导入和导出的小数据量表格,压缩时一般使用 Gzip 在上传HDFS前压缩。
2. ORC
- 默认压缩:ORC 格式通常使用 Zlib 压缩。如果使用其他压缩格式,可能会导致 ORC 文件实际存储空间增大。
- 适用场景:适合处理非常大的数据集。ORC 格式的读取速度通常较快,默认使用 Zlib 进行压缩,效果优于 Snappy,一般建表时进行压缩。
压缩示例
以下是一个使用 ORC 格式创建 Hive 表的示例:
CREATE TABLE IF NOT EXISTS emp_orc_ys (empno INT,ename STRING,job STRING,mgr INT,hiredate STRING,sal FLOAT,comm FLOAT,deptno INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' -- 使用制表符作为字段分隔符
STORED AS ORC
TBLPROPERTIES ("orc.compress" = "SNAPPY"); -- 改变默认压缩方式,使用 Snappy 压缩
四、Hive 建表手册
创建表的基本语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name (col1 type1,col2 type2,col3 type3,...colN typeN
)
[PARTITIONED BY (part_col1 part_type1, part_col2 part_type2, ...)]
[CLUSTERED BY (col_name1, col_name2, ...)]
[ROW FORMAT DELIMITED row_format]
[ROW FORMAT SERDE 'serde_name']
[FIELDS TERMINATED BY 'delimiter'] -- 指定字段分隔符
[COLLECTION ITEMS TERMINATED BY 'delimiter'] -- 用于数组、映射等
[MAP KEYS TERMINATED BY 'delimiter'] -- 用于映射
[STORED AS file_format]
[LOCATION 'hdfs_path']
[TBLPROPERTIES (compress)];
参数说明
-
EXTERNAL:可选,表示创建外部表。数据存储在外部位置,删除表时不会删除数据。 -
IF NOT EXISTS:可选,若表已经存在则不执行创建。
-
db_name.:可选,指定数据库名称。
-
table_name:表的名称。
-
col1, col2, … colN:列的名称和数据类型。
-
PARTITIONED BY:用于指定分区列及其数据类型。 -
CLUSTERED BY:指定分桶列,通常和分桶数量一起使用。 -
ROW FORMAT DELIMITED:指定行格式,通常用于定义分隔符等。 -
FIELDS TERMINATED BY:指定字段分隔符,例如FIELDS TERMINATED BY ','表示使用逗号作为分隔符。 -
COLLECTION ITEMS TERMINATED BY:如果表中包含数组或映射,指定集合项的分隔符。
-
MAP KEYS TERMINATED BY:指定映射键的分隔符。
-
ROW FORMAT SERDE:可以使用自定义的序列化和反序列化方法。
-
STORED AS:指定存储文件的格式(加TEXTFILE、ORC、SEQUENCEFILE等)。 -
LOCATION:指定表在 HDFS 上的存储路径。 -
TBLPROPERTIES:指定表在 HDFS 上的压缩方式。
示例
以下是多元复杂建表示例,创建一个包含数组和映射的 Hive 表:
CREATE EXTERNAL TABLE IF NOT EXISTS my_database.my_table (id INT,name STRING,age INT,scores ARRAY<INT>, -- 数组类型attributes MAP<STRING, STRING> -- 映射类型
)
PARTITIONED BY (country STRING)
CLUSTERED BY (id) INTO 10 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '|'
MAP KEYS TERMINATED BY ':'
STORED AS ORC
LOCATION 'hdfs://hdfs_path/my_table/'
TBLPROPERTIES ("orc.compress" = "SNAPPY");
相关文章:
Hive数仓操作(十七)
一、Hive的存储 一、Hive 四种存储格式 在 Hive 中,支持四种主要的数据存储格式,每种格式有其特点和适用场景,不过一般只会使用Text 和 ORC : 1. Text 说明:Hive 的默认存储格式。存储方式:行存储。优点…...

工业和自动化领域常见的通信协议
在工业和自动化领域,有多种常见的通信协议,主要用于设备间的通信、数据传输和控制。 Modbus: 类型:串行通信协议用途:广泛用于工业自动化设备间的通信,如PLC、传感器和执行器。优点:简单、开放且…...

连夜爆肝收藏各大云服务新老用户优惠活动入口地址(内含免费试用1个月的地址),适用于小白,大学生,开发者,小企业老板....
具体请前往:云服务器优惠活动入口大全--收藏各主流云厂商的云服务器等系列产品的优惠活动入口,免费试用1个月活动入口,让新老用户都能根据使用场景和身份快速锁定优惠权益 经济下滑,被优化增多,大学生就业难࿰…...

SpringBoot+Redis+RabbitMQ完成增删改查
各部分分工职责 RabbitMQ负责添加、修改、删除的异步操作 Redis负责数据的缓存 RabbitMQ里面角色职责简单描述 RabbitMQ里面有几个角色要先分清以及他们的对应关系: 交换机、队列、路由键 交换机和队列是一对多 队列和路由键是多对多 然后就是消息的发送者&…...

【系统集成中级】线上直播平台开发项目质量管理案例分析
【系统集成中级】线上直播平台开发项目质量管理案例分析 一、案例二、小林在项目质量管理中存在的问题(一)计划阶段缺失(二)测试用例编制与执行问题(三)质量管理流程问题(四)质量保证…...

浪潮信息领航边缘计算,推动AI与各行业深度融合
在9月20日于安徽盛大召开的浪潮信息边缘计算合作伙伴大会上,浪潮信息指出,未来的计算领域将全面融入AI技术,特别是在企业边缘侧,智能应用特别是生成式人工智能应用正在迅速普及,这一趋势正引领边缘计算向边缘智算的方向…...

Koa2项目实战3 (koa-body,用于处理 HTTP 请求中的请求体)
以用户注册接口为例,需要在请求里携带2个参数:用户名(user_name)和密码(password)。 开发者需要在接口端,解析出user_name 、password。 在使用Koa开发的接口中,如何解析出请求携带…...

复盘20241012
1、 classpath "com.android.tools.build:gradle:8.5.1" 的版本 与distributionUrlhttps\://services.gradle.org/distributions/gradle-8.9-bin.zip的对应规则: Execution failed for task :app:compileDebugKotlin. 解决方案 切换 setting --> ot…...

泊松流负载均衡控制
目录 泊松流负载均衡控制 一、到达率λ 二、服务率μ 三、泊松流负载均衡控制 泊松流负载均衡控制 在探讨泊松流负载均衡控制时,我们主要关注的是到达率λ和服务率μ这两个核心参数。以下是对这两个参数及其在泊松流负载均衡控制中作用的详细解释: 一、到达率λ 定义:…...

3D打印矫形器市场报告:未来几年年复合增长率CAGR为10.8%
3D 打印矫形器是指使用 3D 打印技术制作的定制外部支撑装置。它们有助于稳定、引导、缓解或纠正肌肉骨骼状况,并根据个体患者的解剖结构进行设计,通常使用 3D 扫描和建模技术。3D 打印在矫形器方面的主要优势是能够生产精确适合患者解剖结构的定制装置&a…...
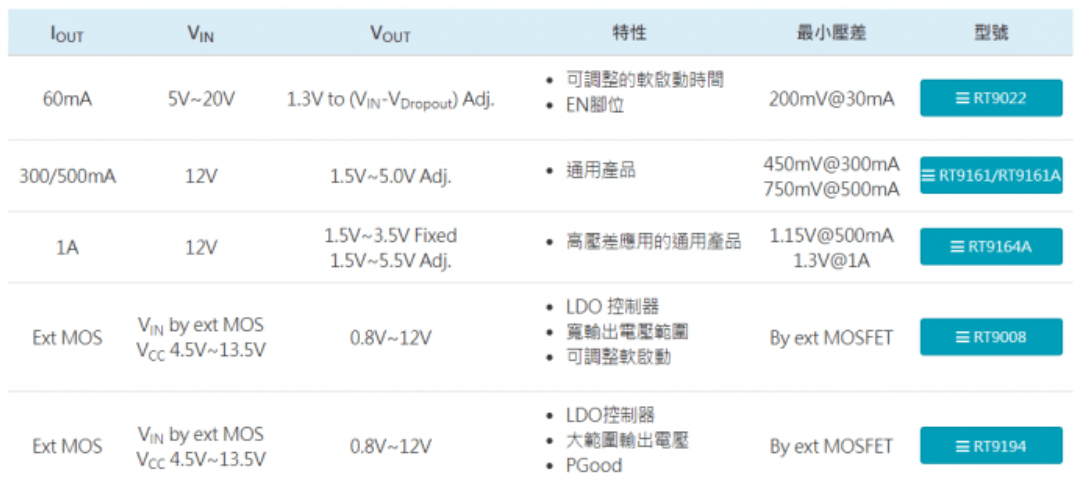
Richtek立锜科技线性稳压器 (LDO) 选型
一、什么是LDO? LDO也可称为低压差线性稳压器,适合从较高的输入电压转换成较低输出电压的应用,这种应用的功率消耗通常不是很大,尤其适用于要求低杂讯、低电流和输入、输出电压差很小的应用环境。 二、LDO的特性 LDO透过控制线性区调整管…...

Leetcode 前 k 个高频元素
使用最小堆算法来解决这道题目:相当于有一个容量固定为K的教室,只能容纳 K 个人,学生们逐个逐个进入该教室,当教室容量达到K人之后,每次进入一个新的学生后,我们将分数最低的学生(类似本题中的频率最低元素…...

[LeetCode] 面试题01.02 判定是否互为字符重拍
题目描述: 给定两个由小写字母组成的字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。 示例 1: 输入: s1 "abc", s2 "bca" 输出: true 示例 2&am…...

数据结构-4.5.KMP算法(旧版上)-朴素模式匹配算法的优化
朴素模式匹配算法最坏的情况: 一.实例: 第一轮匹配失败,开始下一轮的匹配: 不断的操作,最终匹配成功: 如上述图片所述,朴素模式匹配算法会导致时间开销增加, 优化思路:主…...

STM32 QSPI接口驱动GD/W25Qxx配置简要
STM32 QSPI接口GD/W25Qxx配置简要 📝本篇会具体涉及介绍Winbond(华邦)和GD(兆易创新) NOR flash相关型号指令差异。由于网络上可以搜索到很多相关QSPI相关知识内容,不对QSPI通讯协议做深度解析。 🔖首先确保所使用的ST…...
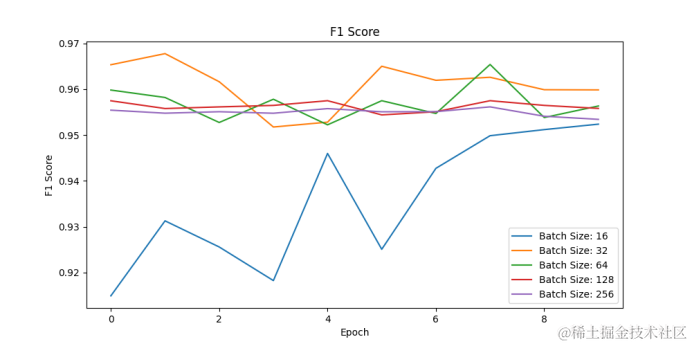
UCI-HAR数据集深度剖析:训练仿真与可视化解读
在本篇文章中,我们将深入探讨如何使用Python对UCI人类活动识别(HAR)数据集进行分割和预处理,以及运用模型网络CNN对数据集进行训练仿真和可视化解读。 一、UCI-HAR数据集分析及介绍 UCI-HAR数据集是一个公开的数据集,…...

牛客SQL练习详解 06:综合练习
牛客SQL练习详解 06:综合练习 SQL34 统计复旦用户8月练题情况SQL35 浙大不同难度题目的正确率SQL39 21年8月份练题总数 叮嘟!这里是小啊呜的学习课程资料整理。好记性不如烂笔头,今天也是努力进步的一天。一起加油进阶吧! SQL34 统…...

k8s apiserver高可用方案
目前官方推荐有 2 种方式部署k8s apiserver 高可用 keepalived and haproxy 部署有2种方式,一种是systemd管理的,另一种是pod形式,使用那种可以根据实际情况选择 服务部署 systemd方式 可以通过包管理工具安装,正常启动之后&…...

服务器数据恢复—硬盘坏扇区导致Linux系统服务器数据丢失的数据恢复案例
服务器数据恢复环境: 一台linux操作系统网站服务器,该服务器上部署了几十个网站,使用一块SATA硬盘。 服务器故障&原因: 服务器在工作过程中突然宕机。管理员尝试重新启动服务器失败,于是将服务器上的硬盘拆下检测…...

【多线程】多线程(12):多线程环境下使用哈希表
【多线程环境下使用哈希表(重点掌握)】 可以使用类:“ConcurrentHashMap” ★ConcurrentHashMap对比HashMap和Hashtable的优化点 1.优化了锁的粒度【最核心】 //Hashtable的加锁,就是直接给put,get等方法加上synch…...

MIMO AONN架构:量子干涉实现超低功耗光学神经网络
1. MIMO AONN架构的核心价值光学神经网络(AONN)正在突破传统电子计算的物理极限。在传统电子神经网络中,非线性激活函数需要消耗大量能量进行电子-光子转换,而基于量子干涉的光学非线性机制可以直接在光域实现这一关键操作。我们实…...

Linux服务器文件传输服务搭建:从FTP协议到vsftpd实战部署
1. 项目概述:为什么要在Linux上搭建FTP服务器?很多刚接触Linux的朋友,尤其是从Windows转过来的,一提到搭建服务器,特别是像FTP这种“古老”但依然实用的文件传输服务,第一反应可能就是“头大”。在Windows上…...

【文学研究者的AI分身已上线】:NotebookLM定制知识图谱构建指南——仅限高校人文实验室内部流通的8项参数配置
更多请点击: https://codechina.net 第一章:【文学研究者的AI分身已上线】:NotebookLM定制知识图谱构建指南——仅限高校人文实验室内部流通的8项参数配置 NotebookLM 的「自定义知识图谱」功能并非通用型索引,而是面向人文学科深…...

STM32 SPI协议深度解析:从硬件连接到时序模式与实战配置
1. SPI协议:从硬件连接到时序模式的深度解析 搞嵌入式开发,尤其是用STM32这类MCU,SPI(Serial Peripheral Interface)总线是绕不开的一道坎。它不像I2C那样需要上拉电阻和复杂的地址协议,也不像UART那样需要…...

从零到一:基于STM32CubeMX与FSMC高效点亮TFT LCD屏的实战指南
1. 硬件准备与环境搭建 第一次接触STM32和TFT LCD屏时,我完全被各种接线和术语搞晕了。后来才发现,只要选对硬件组合,事情就成功了一半。我用的STM32F103ZET6开发板(俗称大容量版)和正点原子2.8寸LCD屏,这套…...

Pearcleaner深度清理工具:为你的Mac找回丢失的存储空间
Pearcleaner深度清理工具:为你的Mac找回丢失的存储空间 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经计算过,那些看似已…...

AI赋能Git提交:aicommit2如何用LLM自动生成规范提交信息
1. 项目概述:从命令行到智能提交的进化在团队协作开发中,提交信息(Commit Message)的质量直接关系到项目的可维护性。一条清晰、规范的提交信息,就像给代码变更打上了一个精准的标签,能让团队成员ÿ…...

AWS实战|从零搭建高可用Web应用网络架构
1. 为什么需要高可用Web应用架构? 最近帮朋友公司迁移电商平台到AWS时,他们最担心的就是大促期间服务器挂掉。这让我想起三年前自己踩过的坑——当时用单可用区部署的官网,因为一次区域级故障直接宕机8小时。现在回头看,其实只要在…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

proxy-doctor:自动化诊断与修复开发工具代理配置的利器
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的项目时,遇到了一个老生常谈但又极其恼人的问题:代理配置。无论是开发环境里的包管理工具,还是日常使用的命令行工具,一旦涉及到网络请求,代理设置不对ÿ…...