C语言中缓冲区底层实现以及数据输入的处理
C语言中缓冲区底层实现以及数据输入的处理
一、缓冲区的概念
在C语言的标准输入输出操作中,缓冲区(Buffer) 扮演着至关重要的角色。在计算机系统中,缓冲区是一块用于暂存数据的内存区域。在输入输出(I/O)操作中,缓冲区的作用是提高效率,减少系统调用的次数。C语言的标准I/O库为每个打开的流(FILE对象)都分配了一个缓冲区,用于暂存输入或输出的数据。
二、为什么需要缓冲区
1. 系统调用的开销
在现代操作系统中,系统调用(System Call) 是程序从用户空间与内核空间交互的唯一途径。系统调用会涉及:
- 用户态与内核态的切换:CPU从用户态切换到内核态需要保存和恢复上下文,影响程序性能。
- 参数验证与复制:数据从用户空间传递到内核空间,需要进行参数检查和内存复制。
- 系统资源占用:每次调用都会消耗系统资源,频繁调用会显著降低性能。
2. I/O设备的低速性
与CPU、内存相比,I/O设备(如磁盘、网络)速度较慢。如果每次输入或输出都等待设备响应,会导致CPU等待,降低程序的效率。缓冲区通过合并多次I/O操作,减少了与设备的直接交互,从而提高性能。
3. 提高程序的运行效率
通过缓冲区,程序可以批量传递数据,将多次小操作合并为一次大操作。这减少了系统调用的次数,从而优化CPU和I/O设备之间的协同工作。
三、缓冲区的类型
1. 全缓冲(Fully Buffered)
- 特性:只有在缓冲区被完全填满时,才会触发一次I/O操作。
- 应用场景:通常用于文件I/O操作,因为文件的写入不需要即时性输出。
示例场景:文件写入
在文件写入中,多次fprintf操作不会立即写入文件,而是先写入缓冲区。当缓冲区满或文件关闭时,数据才会写入磁盘。
代码示例:全缓冲模式
#include <stdio.h>int main() {FILE *fp = fopen("example.txt", "w");if (fp == NULL) {perror("文件打开失败");return 1;}// 多次写入,但未满缓冲区,不会立即写入磁盘for (int i = 0; i < 3; i++) {fprintf(fp, "Line %d\n", i);}// 手动刷新缓冲区,将缓冲内容写入文件fflush(fp);fclose(fp); // 关闭文件时也会自动刷新缓冲区return 0;
}
输出:
- 文件
example.txt中将写入内容。 - 如果不调用
fflush或不关闭文件,则可能看不到写入的内容,因为数据会停留在缓冲区中。
注意:全缓冲模式适合文件操作,不需要即时查看输出的场景。
2. 行缓冲(Line Buffered)
- 特性:缓冲区在遇到换行符(
'\n')或缓冲区满时才会刷新,将内容输出。 - 应用场景:常用于标准输出
stdout,如终端打印信息,适合与用户交互的程序。
示例场景:控制台输出
在控制台打印时,如果不输出换行符,缓冲区中的内容可能不会立即显示。
代码示例:行缓冲模式
#include <stdio.h>
#include <unistd.h> // for sleep()int main() {printf("正在处理中..."); // 没有换行符,不会立即输出sleep(2); // 模拟处理延迟printf("完成!\n"); // 加上换行符,立即刷新缓冲区return 0;
}
输出:
- 如果程序运行时未添加换行符,可能在2秒后才会看到“正在处理中…”和“完成!”一起输出。
- 添加换行符
'\n'后,“正在处理中…”会立即显示。
总结:stdout默认是行缓冲模式,适用于需要即时反馈的控制台程序。
3. 无缓冲(Unbuffered)
- 特性:数据不经过缓冲区,每次调用都会直接进行I/O操作。
- 应用场景:适用于标准错误输出
stderr,确保错误信息能即时显示。
示例场景:错误信息输出
在某些情况下,需要立即显示错误信息,因此stderr是无缓冲的。
代码示例:无缓冲模式
#include <stdio.h>
#include <unistd.h> // for sleep()int main() {fprintf(stderr, "发生错误:连接超时\n"); // 无缓冲,立即显示sleep(2); // 模拟延迟fprintf(stderr, "尝试重新连接...\n"); // 也会立即显示return 0;
}
输出:
- 错误信息会立即显示在终端中,不会等到程序结束或缓冲区满时才输出。
总结:stderr采用无缓冲模式,确保关键的错误信息不会因程序异常退出而丢失。
4. 手动设置缓冲模式
C语言允许手动设置缓冲模式,通过setvbuf函数可以为文件或标准流指定缓冲模式。
代码示例:手动设置缓冲模式
#include <stdio.h>int main() {// 设置stdout为无缓冲模式setvbuf(stdout, NULL, _IONBF, 0);printf("这是无缓冲输出\n"); // 立即输出,不经过缓冲区// 设置stdout为行缓冲模式setvbuf(stdout, NULL, _IOLBF, 0);printf("行缓冲模式:"); // 不会立即输出,等待换行符printf("现在换行了\n"); // 立即输出return 0;
}
输出:
- 无缓冲模式:立即显示“这是无缓冲输出”。
- 行缓冲模式:直到输出换行符,才会显示“行缓冲模式:现在换行了”。
四、缓冲区的实现及工作原理
C语言标准库的输入输出功能是通过**FILE结构体及其管理的缓冲区实现的。缓冲区的核心目的是减少系统调用的次数,并提高I/O效率。接下来,我们更详细地探讨FILE结构体的组成、缓冲区的工作流程、刷新机制及输入缓冲区的特殊处理**。
1. FILE结构体与缓冲机制
FILE结构体是C标准库定义的,用来表示一个输入或输出流。FILE结构体不仅是程序员与文件、标准输入输出之间的接口,还负责管理缓冲区和底层系统调用。不同编译器和系统的FILE结构体实现可能略有不同,但通常包含以下核心信息:
FILE结构体的主要成员:
char *buffer:指向用于临时存储数据的缓冲区。size_t buffer_size:缓冲区的大小。int fd:文件描述符(file descriptor),用于标识底层系统调用的目标文件或设备。char *buffer_pos:指向缓冲区当前读写的位置。int mode:当前流的缓冲模式(全缓冲、行缓冲、无缓冲)。int flags:标志流的状态(如是否出错、是否到达文件末尾)。
2. 缓冲区如何减少系统调用次数
底层实现概述
系统调用如read、write会切换用户态与内核态,带来额外开销。如果每次输出一个字符都需要调用write,性能会严重受影响。通过将多个I/O请求合并为一次调用,缓冲区大大减少了系统调用的次数。
缓冲区的优化工作流程
- 全缓冲模式:将多个写入操作存放在缓冲区中,当缓冲区满或文件关闭时,才触发系统调用,将所有数据一次性写入文件。
- 行缓冲模式:每当检测到换行符(
'\n'),或者缓冲区满时,系统调用会将缓冲区的数据写出。 - 无缓冲模式:不使用缓冲区,每次写入或读取都会直接触发系统调用。
3. 缓冲区刷新(Buffer Flush)
刷新时机:
- 缓冲区满时:当写入数据填满缓冲区时,系统会自动触发刷新,将数据写入文件或输出设备。
- 遇到换行符时:在行缓冲模式下,输出换行符(
'\n')会触发缓冲区刷新。 - 显式调用
fflush时:程序员可以通过fflush函数手动刷新缓冲区。 - 程序正常结束时:标准库会在程序正常结束时自动刷新所有未刷新的缓冲区。
- 读取输入时触发:某些情况下,输入操作会触发输出缓冲区刷新,确保输入和输出顺序正确。
4. 输入缓冲区的行为
输入缓冲区的特点
- 缓冲区存储用户输入:当用户在控制台输入数据时,数据会先被缓存在输入缓冲区中,直到按下回车键(
Enter)为止,才会将缓冲区内容传递给程序。 - 残留字符问题:某些输入函数(如
scanf)会留下未处理的换行符在缓冲区中,可能影响后续的输入。
清除输入缓冲区的代码示例
#include <stdio.h>int main() {char name[20];int age;printf("请输入姓名:");scanf("%19s", name); // 输入姓名,但换行符仍留在缓冲区中printf("请输入年龄:");// 为避免缓冲区残留问题,清除缓冲区int ch;while ((ch = getchar()) != '\n' && ch != EOF);scanf("%d", &age); // 正确读取年龄printf("姓名:%s,年龄:%d\n", name, age);return 0;
}
解释:
- 在第一次输入后,换行符会留在缓冲区中。如果不清理缓冲区,后续的
scanf可能会直接读取换行符,导致程序行为不正确。
要理解C语言中缓冲区的底层实现,我们需要深入探讨从用户空间和内核空间的交互、系统调用的优化、文件描述符(File Descriptor)的使用,到C标准库(stdio.h)的具体实现。以下内容将从操作系统的角度和系统层面详细解释缓冲区的原理和实现机制。
五、缓冲区的底层实现
1. 用户空间与内核空间的交互
现代操作系统将内存分为用户空间和内核空间:
- 用户空间:运行普通用户程序,不能直接访问硬件设备。
- 内核空间:负责管理资源和硬件设备,提供系统调用(如
read、write)给用户空间程序使用。
I/O的核心开销
- 每次系统调用需要用户态与内核态的切换,这是一个昂贵的操作,因为CPU需要保存当前上下文,并切换到内核模式。
- 使用缓冲区的目标是减少系统调用的频率,将多次I/O请求合并为一次操作,减少上下文切换的成本。
2. 文件描述符(File Descriptor)
每个文件或设备在打开时,操作系统会分配一个文件描述符(File Descriptor,FD)。这是一个整数,用于标识当前进程打开的文件或I/O设备。标准输入、标准输出和标准错误分别对应文件描述符0、1、2。
stdin:描述符0stdout:描述符1stderr:描述符2
示例一:标准输出(stdout,文件描述符1)
我们可以使用 系统调用write,直接向文件描述符1(标准输出)写入数据。
代码示例:使用write向标准输出打印信息
#include <unistd.h> // 提供write系统调用int main() {const char *message = "Hello from stdout!\n";write(1, message, 19); // 使用文件描述符1直接输出return 0;
}
解释:
- 使用
write(1, ...)将消息直接写入标准输出。 write的第一个参数为1,表示写入标准输出。- 你会在控制台上看到输出:
Hello from stdout!
示例二:标准错误(stderr,文件描述符2)
标准错误(stderr)是无缓冲的,任何错误信息都应该立即显示。我们可以直接向文件描述符2写入错误消息。
代码示例:使用write向标准错误输出信息
#include <unistd.h> // 提供write系统调用int main() {const char *error_message = "An error occurred!\n";write(2, error_message, 18); // 使用文件描述符2输出错误信息return 0;
}
解释:
- 使用
write(2, ...)直接将错误信息写入标准错误流。 - 这条错误信息会立即输出,而不会经过缓冲。
示例三:标准输入(stdin,文件描述符0)
可以通过**read系统调用**从标准输入读取用户输入。
代码示例:使用read从标准输入读取数据
#include <unistd.h> // 提供read系统调用
#include <stdio.h> // 提供printfint main() {char buffer[100]; // 缓存用户输入printf("请输入内容:");ssize_t n = read(0, buffer, sizeof(buffer) - 1); // 从标准输入读取if (n > 0) {buffer[n] = '\0'; // 将读取的内容转成字符串printf("你输入了:%s", buffer);} else {printf("读取失败或输入为空\n");}return 0;
}
解释:
- 使用
read(0, ...)从标准输入读取用户的输入。 - **文件描述符
0**表示读取来自标准输入的数据。 - 输入的内容会被存储在
buffer中,然后打印出:“你输入了:…”的内容。
示例四:重定向文件描述符
我们可以通过重定向文件描述符,让标准输出或标准错误指向文件,而不是默认的终端。
代码示例:重定向标准输出到文件
#include <unistd.h> // 提供write、dup2系统调用
#include <fcntl.h> // 提供open系统调用int main() {// 打开文件 "output.txt",以写入模式创建(如果不存在则创建)int file_fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);if (file_fd < 0) {write(2, "无法打开文件\n", 18); // 使用标准错误输出错误信息return 1;}// 将标准输出重定向到文件dup2(file_fd, 1); // 将文件描述符file_fd复制到标准输出(1)// 使用标准输出打印内容(实际上写入了文件)write(1, "Hello, file!\n", 13);close(file_fd); // 关闭文件return 0;
}
解释:
open打开文件output.txt并返回文件描述符。dup2(file_fd, 1)将文件描述符复制到标准输出(1),因此所有标准输出的内容会被写入文件。- 在文件
output.txt中可以看到:Hello, file!。
示例五:同时输出到标准输出和标准错误
在某些情况下,我们可能希望将一部分信息输出到标准输出,而错误信息则输出到标准错误。
代码示例:同时输出到标准输出和标准错误
#include <unistd.h> // 提供write系统调用int main() {// 输出普通信息到标准输出write(1, "This is stdout message\n", 23);// 输出错误信息到标准错误write(2, "This is stderr message\n", 23);return 0;
}
解释:
- 使用
write(1, ...)输出普通信息到标准输出。 - 使用
write(2, ...)输出错误信息到标准错误。
在控制台上:
- 普通信息和错误信息都会显示在终端中,但可以通过重定向将它们分别输出到不同的地方。
3. FILE结构体与缓冲区管理
C语言标准库的FILE结构体用于管理每个打开的文件或输入/输出流。这个结构体并不是直接对系统调用进行操作,而是通过**缓冲区(Buffer)**优化输入输出操作。具体而言,C标准库会在合适的时机调用底层系统调用(如read或write),从而减少系统调用的次数,提高I/O性能。
FILE结构体的成员详解
struct FILE {char *buffer; // 指向缓冲区的指针size_t buffer_size; // 缓冲区的大小int fd; // 文件描述符(底层I/O目标:stdin、stdout等)size_t buffer_pos; // 当前缓冲区中的位置(用于追踪读写进度)int mode; // 缓冲模式:全缓冲(_IOFBF)、行缓冲(_IOLBF)、无缓冲(_IONBF)int error; // 错误状态(非0表示发生了错误)int eof; // 文件结束状态(非0表示EOF)int flags; // 额外的状态标志(如是否可读、是否可写)
};
a.缓冲区的作用与机制
buffer:指向缓冲区的内存位置。缓冲区用于存储临时数据,例如未写入文件的数据,或者从文件读取但未使用的数据。buffer_size:缓冲区的大小,一般为**BUFSIZ**。BUFSIZ的大小通常为4KB或8KB,具体取决于系统。
缓冲区的主要目的是将多次小的I/O操作合并为少量的系统调用。比如,当用户多次调用printf写入字符时,数据会先存入缓冲区,只有缓冲区满时才调用write系统调用写入文件或显示到终端。
b. FILE结构体与文件描述符(fd)的关系
fd:每个打开的文件或I/O流(如stdin、stdout、文件)都会有一个文件描述符(整数)。这是C标准库与操作系统之间的桥梁。
当缓冲区需要刷新或读取新数据时,FILE结构体会调用系统调用,如:
read(fd, buffer, size)从输入流读取数据填充缓冲区。write(fd, buffer, size)将缓冲区中的数据写入文件或输出流。
c. 缓冲区指针与进度
buffer_pos:用于记录缓冲区当前的读写位置。如果缓冲区满了(写操作),或缓冲区耗尽(读操作),会触发系统调用。
示例:读操作中的缓冲区管理流程
- 当用户调用
fgetc或fgets读取字符时,标准库首先检查缓冲区是否有数据。 - 如果缓冲区为空,则调用
read(fd, buffer, BUFSIZ)将数据批量读取到缓冲区。 - 用户继续读取时,
buffer_pos会增加,直到缓冲区耗尽。
d. 缓冲模式的实现
- 全缓冲(
_IOFBF):数据在缓冲区填满时才进行I/O操作(适合文件I/O)。 - 行缓冲(
_IOLBF):遇到换行符或缓冲区满时触发I/O操作(适合标准输出)。 - 无缓冲(
_IONBF):每次fputc或fprintf都会直接调用write系统调用(适合stderr)。
e. FILE结构体的错误管理
error:用于标识流中的错误状态。例如,如果写入操作失败,error会被设置为非零值。用户可以通过ferror()函数检查错误。eof:用于标识文件是否到达文件末尾(EOF),可以通过feof()函数检查。
错误检查示例:
#include <stdio.h>int main() {FILE *fp = fopen("nonexistent.txt", "r");if (fp == NULL) {perror("无法打开文件");return 1;}// 执行一些读取操作if (ferror(fp)) {printf("读取过程中发生错误\n");}fclose(fp);return 0;
}
f. 缓冲区的刷新
缓冲区的数据会在以下情况下被刷新:
- 缓冲区满时自动刷新。
- 遇到换行符时,在行缓冲模式下刷新。
- **调用
fflush()**时手动刷新。 - 关闭文件时自动刷新。
- 程序结束时,C库会自动刷新所有缓冲区。
手动刷新示例:
#include <stdio.h>int main() {printf("这条信息在刷新之前不会显示");fflush(stdout); // 手动刷新缓冲区,立即显示输出return 0;
}
g. 系统调用与缓冲区的协作(完整流程)
- 用户调用I/O函数:例如
fprintf或fgets。 - 数据写入缓冲区:数据被存入
FILE结构体的缓冲区,并更新buffer_pos。 - 检查缓冲区状态:
- 写缓冲区:如果缓冲区满,则调用
write(fd, buffer, size)。 - 读缓冲区:如果缓冲区为空,则调用
read(fd, buffer, size)。
- 写缓冲区:如果缓冲区满,则调用
- 错误处理:如果系统调用失败,
FILE结构体的error标志会被设置。 - 结束时刷新缓冲区:当文件被关闭或程序结束时,剩余数据会写入目标文件。
4. 缓冲区的工作流程
-
写操作时的流程:
- 调用
printf等输出函数时,数据首先存储在FILE结构体的缓冲区中。 - 当缓冲区填满或满足刷新条件时,调用系统调用
write,将缓冲区内容写入文件或标准输出。
- 调用
-
读操作时的流程:
- 当调用
fgets或scanf时,标准库会先检查缓冲区是否为空。 - 如果缓冲区为空,标准库会调用系统调用
read,从输入源中读取一大块数据(通常是BUFSIZ大小),并将其存储在缓冲区中,以备后续读取。
- 当调用
5. 系统调用与缓冲区的协作
write系统调用(写入数据)
ssize_t write(int fd, const void *buf, size_t count);
write将用户空间的缓冲区数据传递给内核空间,再由内核写入设备或文件。- 每次调用都涉及上下文切换,因此减少
write调用可以显著提高性能。
read系统调用(读取数据)
ssize_t read(int fd, void *buf, size_t count);
read从内核读取数据,并存放在用户空间的缓冲区中。- 缓冲区机制减少了系统调用次数,使得程序无需频繁调用
read读取每个字符。
6. 缓冲区的刷新机制实现
全缓冲实现(Full Buffering)
在全缓冲模式下,FILE结构体分配了一个缓冲区。当程序调用fprintf或fwrite时,数据会写入缓冲区中,只有当缓冲区填满或文件关闭时,才会调用write系统调用将数据写入目标文件。
伪代码:全缓冲写入逻辑
void fwrite(const char *data, size_t size, FILE *fp) {size_t remaining_space = fp->buffer_size - fp->buffer_pos;if (size > remaining_space) {flush(fp); // 缓冲区已满,调用系统调用write()}memcpy(fp->buffer + fp->buffer_pos, data, size);fp->buffer_pos += size;
}
行缓冲实现(Line Buffering)
在行缓冲模式下,每当检测到换行符('\n')时,缓冲区会立即刷新,即调用write将数据写入输出流。
伪代码:行缓冲逻辑
void fputs(const char *str, FILE *fp) {while (*str) {if (*str == '\n' || fp->buffer_pos >= fp->buffer_size) {flush(fp); // 遇到换行符或缓冲区满时刷新}fp->buffer[fp->buffer_pos++] = *str++;}
}
无缓冲实现(Unbuffered I/O)
在无缓冲模式下,fprintf、fwrite等函数直接调用系统调用write,数据不会经过缓冲区。
伪代码:无缓冲逻辑
void fputc_unbuffered(char c, FILE *fp) {write(fp->fd, &c, 1); // 每次输出一个字符都直接调用write
}
7. 输入缓冲区的处理
- 输入缓冲区会暂存用户在终端输入的数据,直到按下回车键(
Enter)为止。此时,缓冲区中的数据才会传递给程序。 - 残留问题:使用
scanf读取时,未消耗的换行符会留在缓冲区,可能影响后续输入。
伪代码:缓冲区清理逻辑
void clear_input_buffer() {int c;while ((c = getchar()) != '\n' && c != EOF); // 清除缓冲区中的所有字符
}
六、标准库中的缓冲函数(详细讲解)
C语言标准库提供了多种缓冲相关的函数,帮助开发者设置流的缓冲模式、管理缓冲区,以及检查流的状态。下面我们详细介绍 setbuf、setvbuf、perror 等函数的使用场景、参数、以及它们如何优化输入输出。
1. setbuf函数
setbuf 用于设置流的缓冲区。它是一个较为简单的接口,允许我们设置 缓冲区 或将流设置为 无缓冲模式。
函数原型
void setbuf(FILE *stream, char *buffer);
stream:需要设置缓冲区的流(如stdin、stdout)。buffer:指向自定义缓冲区的指针。如果为NULL,则将流设为 无缓冲模式。
使用示例:设置自定义缓冲区
#include <stdio.h>int main() {char buf[BUFSIZ]; // 定义一个自定义缓冲区// 为stdout设置自定义缓冲区setbuf(stdout, buf);printf("Hello, buffered world!"); // 暂时存入缓冲区,不立即输出fflush(stdout); // 手动刷新缓冲区,立即输出return 0;
}
说明
- 设置自定义缓冲区可以优化性能,将多个小的I/O操作合并为一次系统调用。
- 如果传入的
buffer为NULL,则流会变成 无缓冲 模式,所有输出操作会立即执行。
2. setvbuf函数
setvbuf 是一个更加灵活的接口,允许设置流的缓冲模式和缓冲区大小。与setbuf相比,它支持 多种缓冲模式。
函数原型
int setvbuf(FILE *stream, char *buffer, int mode, size_t size);
stream:目标流(如stdout、stderr)。buffer:指向自定义缓冲区。如果为NULL,则使用系统默认的缓冲区。mode:缓冲模式:_IOFBF:全缓冲(只有缓冲区满时才执行I/O)。_IOLBF:行缓冲(遇到换行符或缓冲区满时执行I/O)。_IONBF:无缓冲(每次I/O操作都立即执行)。
size:缓冲区的大小。
使用示例:设置全缓冲模式
#include <stdio.h>int main() {char buf[BUFSIZ]; // 自定义缓冲区// 设置stdout为全缓冲模式,并使用自定义缓冲区if (setvbuf(stdout, buf, _IOFBF, BUFSIZ) != 0) {perror("Failed to set buffer");return 1;}printf("This message is buffered."); // 存入缓冲区,不立即输出fflush(stdout); // 手动刷新缓冲区,确保输出return 0;
}
说明
_IOFBF:适用于需要高效批量处理的文件操作。_IOLBF:常用于控制台输出,保证交互信息及时显示。_IONBF:适用于错误信息输出,确保错误立即显示。
3. perror函数
perror 是一个实用函数,用于根据全局变量 errno 的值,输出错误信息。errno 在系统调用失败时会被设置为错误代码,perror 可以将错误代码转为对应的 人类可读信息 并输出。
函数原型
void perror(const char *message);
message:用户自定义的前缀信息,用于描述错误的上下文。
使用示例:打开文件时错误处理
#include <stdio.h>int main() {FILE *fp = fopen("nonexistent.txt", "r"); // 尝试打开一个不存在的文件if (fp == NULL) {perror("Error opening file"); // 输出错误信息return 1;}fclose(fp);return 0;
}
输出示例
Error opening file: No such file or directory
说明
perror会将用户自定义的前缀信息和strerror(errno)的输出信息拼接在一起。errno是线程安全的,全局错误码反映了上一次系统调用的错误状态。
缓冲函数对比
| 函数名 | 功能 | 参数 | 使用场景 |
|---|---|---|---|
setbuf | 为流设置自定义缓冲区或无缓冲 | 流指针、缓冲区指针 | 简单设置缓冲区 |
setvbuf | 设置流的缓冲模式和缓冲区大小 | 流指针、缓冲区指针、模式、大小 | 灵活控制缓冲模式和大小 |
perror | 根据errno输出错误信息 | 错误描述字符串 | 检测并报告系统调用的错误 |
七、日常编程以及算法竞赛中数据输入的处理
在日常编程和算法题中,高效的输入输出方法可以显著提升程序的性能和稳定性。不同的场景有不同的需求,如:
- 日常开发需要注重可维护性和清晰的代码结构;
- 算法竞赛或刷题则要求极致的速度和高效的I/O操作。
接下来我们将详细讨论如何选择合适的输入输出方法,并针对 算法题 解决常见的输入问题。
1. 常见的输入输出方法及其选择
a. scanf 和 printf
适用场景:
scanf:用于从标准输入读取格式化数据。printf:用于将格式化数据输出到标准输出。- 适合场景:小规模数据输入输出、数据格式稳定的情况。
优点:
- 格式控制灵活,支持多种数据类型。
- 内置缓冲机制,自动跳过空白符(如空格和换行符)。
缺点:
scanf在处理 字符串和多行输入 时容易出错。- 性能比
getchar和fgets略低,对于大规模输入不够高效。
代码示例:
#include <stdio.h>int main() {int a, b;printf("请输入两个整数:");scanf("%d %d", &a, &b);printf("它们的和是:%d\n", a + b);return 0;
}
适用建议:
- 小规模数据输入:如日常开发中的输入输出功能。
- 数据格式稳定:如整型、浮点型等常规输入。
b. getchar 和 putchar
适用场景:
getchar:逐字符读取输入。putchar:逐字符输出到标准输出。- 适合场景:处理逐字符输入(如读取文件中的每个字符)或清除输入缓冲区。
优点:
- 直接读取和输出字符,非常简单。
- 比
scanf更适合处理未知格式的输入流。
缺点:
- 逐字符处理效率较低,不适合大规模数据输入。
代码示例:读取用户输入的字符并逐个输出。
#include <stdio.h>int main() {char c;printf("请输入一个字符:");c = getchar();printf("你输入的字符是:");putchar(c);putchar('\n');return 0;
}
适用建议:
- 用于清理输入缓冲区:避免换行符等残留字符影响后续输入。
- 适用于逐字符读取的特殊场景,如文本处理。
c. fgets 和 fputs
适用场景:
fgets:从输入流中读取一行数据。fputs:将字符串输出到指定的输出流。- 适合场景:需要安全读取字符串、处理换行符的情况。
优点:
- 安全性高,避免缓冲区溢出问题(相比
gets)。 - 支持多行读取,适合较复杂的输入。
缺点:
fgets会将换行符读入,需要手动处理。- 性能略逊于
scanf。
代码示例:读取一行用户输入并输出。
#include <stdio.h>int main() {char buffer[100];printf("请输入一行文本:");fgets(buffer, sizeof(buffer), stdin);printf("你输入的文本是:%s", buffer);return 0;
}
适用建议:
- 适合处理 多行输入 或 字符串数据,如读取配置文件或文本数据。
- 算法题中,如果输入包含大量文本,可以优先使用
fgets。
d. read 和 write(系统调用)
适用场景:
- 适合处理极大规模数据输入输出,如 算法竞赛 和 文件处理。
优点:
- 性能高,没有多余的格式化处理。
- 直接调用底层系统 I/O 操作。
缺点:
- 使用不够方便,需要自行管理缓冲区。
- 不支持格式化数据的直接读取。
代码示例:从标准输入读取数据并写入标准输出。
#include <unistd.h>int main() {char buffer[100];ssize_t n = read(0, buffer, sizeof(buffer)); // 从标准输入读取write(1, buffer, n); // 输出到标准输出return 0;
}
适用建议:
- 算法竞赛中需要极致性能时,使用
read和write。 - 不需要格式化处理的批量数据读写。
2. 算法题中的数据输入问题及解决方案
在算法题中,输入数据量可能非常大,直接使用 scanf 或 printf 会导致 TLE(超时)。因此,我们需要选择更高效的 I/O 方法,并避免常见的输入错误。
a. 如何高效读取大规模数据
- 首选方法:
fgets+ 自行解析数据 - 避免使用:逐字符读取(如
getchar)
示例:高效读取整数数组
#include <stdio.h>
#include <stdlib.h>int main() {char buffer[1000000]; // 假设数据量非常大fgets(buffer, sizeof(buffer), stdin); // 一次性读取整行数据int sum = 0, num;char *ptr = buffer;// 逐个解析整数并累加while (sscanf(ptr, "%d", &num) == 1) {sum += num;while (*ptr != ' ' && *ptr != '\n') ptr++; // 跳过当前整数ptr++;}printf("总和为:%d\n", sum);return 0;
}
分析:
- 使用
fgets读取整行数据,然后使用sscanf从字符串中解析整数。 - 这种方法比多次调用
scanf快得多,因为减少了系统调用的次数。
b. 避免缓冲区残留问题
在使用 scanf 读取数据时,缓冲区可能会留下多余的换行符,影响后续的输入。解决办法是手动清理缓冲区。
示例:清理输入缓冲区
#include <stdio.h>int main() {int a;printf("请输入一个整数:");scanf("%d", &a);// 清理缓冲区,避免换行符影响后续输入while (getchar() != '\n');printf("输入的整数是:%d\n", a);return 0;
}
c. 如何避免EOF问题
在算法题中,可能会遇到未知输入行数的情况。我们可以通过**fgets** 或 scanf 的返回值检测是否到达输入末尾。
示例:检测EOF
#include <stdio.h>int main() {int num;while (scanf("%d", &num) != EOF) { // 读取直到EOFprintf("读取到的数:%d\n", num);}return 0;
}
3. 总结:如何选择输入输出方法
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
scanf/printf | 小规模数据,格式稳定的输入 | 使用方便,格式化灵活 | 大数据输入时效率低 |
getchar/putchar | 逐字符输入或缓冲区处理 | 简单直接 | 效率低 |
fgets/fputs | 多行输入、字符串处理 | 安全,不易出错 | 需要手动处理换行符 |
read/write | 大规模数据,高效I/O | 性能极高 | 需要手动解析数据 |
选择建议:
- 日常开发:
scanf/printf足够应对大部分场景。 - 大规模数据处理:使用
fgets+sscanf或read+ 自行解析。 - 算法竞赛:优先使用
fgets或read处理大量输入数据,避免逐字符读取。
通过合理选择输入输出方法,我们可以编写出性能优秀且健壮性强的代码,应对不同的编程场景和挑战。
相关文章:

C语言中缓冲区底层实现以及数据输入的处理
C语言中缓冲区底层实现以及数据输入的处理 一、缓冲区的概念 在C语言的标准输入输出操作中,缓冲区(Buffer) 扮演着至关重要的角色。在计算机系统中,缓冲区是一块用于暂存数据的内存区域。在输入输出(I/O)…...

RocketMQ事务消息原理
一、RocketMQ事务消息原理: RocketMQ 在 4.3 版本之后实现了完整的事务消息,基于MQ的分布式事务方案,本质上是对本地消息表的一个封装,整体流程与本地消息表一致,唯一不同的就是将本地消息表存在了MQ内部&…...

【Java】IntelliJ IDEA开发环境安装
一、下载 官方地址:https://www.jetbrains.com/idea/ 点击Download直接下载 二、安装 双击安装包,点击Next 选择安装路径,点击Next 勾选安装内容 安装完成。 三、创建项目 打开IDEA,填写项目名称,选择项目安装路径…...
 实践:Goroutine之间的通信)
Go语言中的通道 (Channel) 实践:Goroutine之间的通信
1. 引言 在Go语言中,并发编程是其核心优势之一。与其他编程语言不同,Go语言推荐使用通道 (Channel) 来进行多线程或并发任务的协调与通信,而非使用锁机制。本文将介绍如何通过通道在多个goroutine之间进行通信,避免竞争条件和复杂…...
常用类(二)--String类的简单总结
文章目录 1.基本介绍1.1创建对象1.2找到对应下标的字符1.3找到对应字符的下标1.4指定位置开始遍历1.5反向进行遍历1.6大小写之间的转换1.7字符串转换为数组1.8元素的替换1.9字符串的分割1.10字符串的截取 2.StringBuilder和StringBuffer2.1 StringBuilder的引入2.2面试题目 1.基…...

Spring Boot开发:从入门到精通
Spring Boot开发:从入门到精通 当你在开发一个新的Java应用时,是否曾经感到苦恼于繁琐的配置和重复的代码?Spring Boot就像一位友好的助手,向你伸出援手,让开发变得轻松愉快。从这一单一框架中,你可以快速…...

《数据结构》--队列【各种实现,算法推荐】
一、认识队列 队列是一种常见的数据结构,按照先进先出(FIFO,First In First Out)的原则排列数据。也就是说,最早进入队列的元素最先被移除。队列主要支持两种基本操作: 入队(enqueue࿰…...

面试八股文对校招的用处有多大?--GDB篇
前言 1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。 2.本系列发布内容分为12篇…...

Unity用VS打开FGUI脚本变成杂项怎么处理?
在Unity中使用Visual Studio(VS)打开FGUI脚本时,如果脚本显示为杂项文件,这通常意味着VS没有正确识别或关联这些脚本文件。以下是一些解决此问题的步骤: 对惹,这里有一个游戏开发交流小组,大家…...
解释说明)
交叉熵损失函数(Cross-Entropy Loss Function)解释说明
公式 8-11 的内容如下: L ( y , a ) − [ y log a ( 1 − y ) log ( 1 − a ) ] L(y, a) -[y \log a (1 - y) \log (1 - a)] L(y,a)−[yloga(1−y)log(1−a)] 这个公式表示的是交叉熵损失函数(Cross-Entropy Loss Function)&#…...

和外部机构API交互如何防止外部机构服务不可用拖垮调用服务
引言 在现代的分布式系统和微服务架构中,服务之间的通信往往通过API进行,尤其是在与外部机构或第三方服务进行交互时,更需要通过API实现功能的集成。然而,由于外部服务的可控性较差,其服务的不可用性(如响…...

自动猫砂盆真的有必要吗?买自动猫砂盆不看这四点小心害死猫。
现在越来越多铲屎官选择购买自动猫砂盆来代替自己给猫咪铲屎,可是自动猫砂盆真的有必要吗?要知道,在现在忙碌的生活中,有很多人因为工作上的忙碌而不小心忽视了猫咪,猫咪的猫砂盆堆满粪便,要知道猫砂盆一天…...

国外解压视频素材哪里找?五个海外解压视频素材网站推荐
国外解压视频素材哪里找?五个海外解压视频素材网站推荐 如果你正在寻找国外的解压视频素材,那么今天这篇文章一定能帮助你。无论是修牛蹄、洗地毯,还是切肥皂、玩解压游戏等,下面分享的几个网站都是你找到高质量海外解压视频素材…...
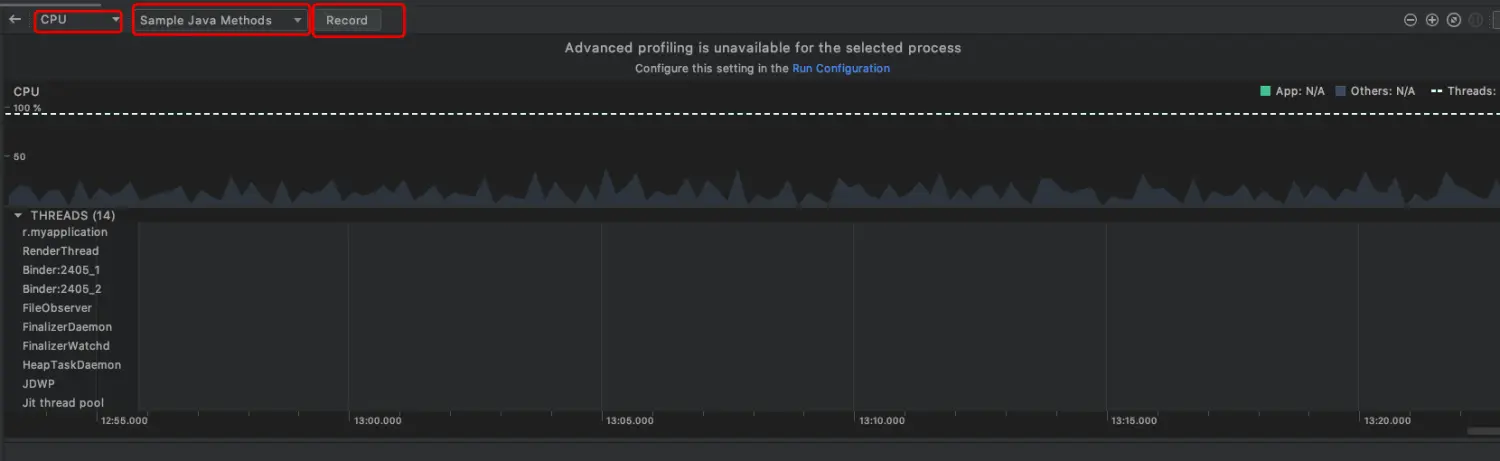
Android一个APP里面最少有几个线程
Android一个APP里面最少有几个线程 参考 https://www.jianshu.com/p/92bff8d6282f https://www.jianshu.com/p/8a820d93c6aa 线程查看 Android一个进程里面最少包含5个线程,分别为: main线程(主线程)FinalizerDaemon线程 终结者守护线程…...

位操作解决数组的花样遍历
文章目录 题目 一、思路: 二、代码 总结 题目 leetcodeT289 https://leetcode.cn/problems/game-of-life/description/ 一、思路: 这题思路很简单,对每个位置按照题目所给规则进行遍历,判断周围网格的活细胞数即可。但是题目要求…...

【面试宝典】深入Python高级:直戳痛点的题目演示(下)
目录 🍔 Python下多线程的限制以及多进程中传递参数的⽅式 🍔 Python是如何进⾏内存管理的? 🍔 Python⾥⾯如何拷⻉⼀个对象? 🍔 Python⾥⾯search()和match()的区别? 🍔 lambd…...

Hive数仓操作(十七)
一、Hive的存储 一、Hive 四种存储格式 在 Hive 中,支持四种主要的数据存储格式,每种格式有其特点和适用场景,不过一般只会使用Text 和 ORC : 1. Text 说明:Hive 的默认存储格式。存储方式:行存储。优点…...

工业和自动化领域常见的通信协议
在工业和自动化领域,有多种常见的通信协议,主要用于设备间的通信、数据传输和控制。 Modbus: 类型:串行通信协议用途:广泛用于工业自动化设备间的通信,如PLC、传感器和执行器。优点:简单、开放且…...

连夜爆肝收藏各大云服务新老用户优惠活动入口地址(内含免费试用1个月的地址),适用于小白,大学生,开发者,小企业老板....
具体请前往:云服务器优惠活动入口大全--收藏各主流云厂商的云服务器等系列产品的优惠活动入口,免费试用1个月活动入口,让新老用户都能根据使用场景和身份快速锁定优惠权益 经济下滑,被优化增多,大学生就业难࿰…...

SpringBoot+Redis+RabbitMQ完成增删改查
各部分分工职责 RabbitMQ负责添加、修改、删除的异步操作 Redis负责数据的缓存 RabbitMQ里面角色职责简单描述 RabbitMQ里面有几个角色要先分清以及他们的对应关系: 交换机、队列、路由键 交换机和队列是一对多 队列和路由键是多对多 然后就是消息的发送者&…...

FFXIV TexTools:终极《最终幻想14》模组管理完全指南
FFXIV TexTools:终极《最终幻想14》模组管理完全指南 【免费下载链接】FFXIV_TexTools_UI 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_TexTools_UI FFXIV TexTools 是一款为《最终幻想14》玩家量身打造的开源模组管理框架,让游戏外观定…...
别再只调XGBoost参数了!试试阿里PAI这篇AAAI 2024新作AMFormer,用Transformer做表格数据效果真香
突破表格数据建模瓶颈:AMFormer如何用算术特征交互重塑深度学习方法 在金融风控、医疗诊断和推荐系统等实际业务场景中,结构化表格数据始终占据着核心地位。传统树模型如XGBoost和LightGBM凭借对特征缺失和噪声的鲁棒性,长期统治着这一领域。…...

RStudio 2026最新版下载:一键直达官网,解锁数据分析新体验
RStudio免费版安装包下载地址:RStudio安装包 RStudio 是 R 语言专用的集成开发环境,简单说就是 R 语言的 “超级工作台”。它不替代 R 语言,而是必须搭配 R 语言使用,负责把 R 语言的能力可视化、流程化、高效化。 RStudio 的核心…...

CNN在卷什么:五大组件详解,一文讲透卷积神经网络,从LeNet到ResNet,为什么这5个组件是CNN的标配
CNN在卷什么:五大组件详解,一文讲透卷积神经网络 副标题: 从LeNet到ResNet,为什么这5个组件是CNN的标配 痛点:CNN的五大组件是什么? 学CNN的时候,你是不是分不清这些概念? 卷积层 vs 池化层:都是"滑动",有什么区别? BatchNorm 到底在做什么?为什么需要它…...

你的边缘AI盒子为什么烫手?——散热设计的最后一道物理防线
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 211、985硕士,从业16年 从事结构设计、热设计、售前、产品设计、项目管理等工作,涉足消费电子、新能源、医疗设备、制药信息化、核工业等…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界
UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA(Unity Asset Bundle Extractor Avalonia&#…...

ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在
ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的nc…...
)
低多边形≠简陋!掌握这7个结构化Prompt技巧,3分钟产出可商用IP形象(附Figma网格对齐校验表)
更多请点击: https://intelliparadigm.com 第一章:低多边形设计的认知革命:从“简陋感”到“结构化美学” 低多边形(Low-Poly)设计曾长期被误读为建模能力不足的妥协产物,但其本质是一场对数字视觉语法的系…...