权重衰减与暂退法——pytorch与paddle实现模型正则化
权重衰减与暂退法——pytorch与paddle实现模型正则化
在深度学习中,模型正则化是一种至关重要的技术,它有助于防止模型过拟合,提高泛化能力。过拟合是指在训练数据上表现良好,但在测试数据或新数据上表现不佳的现象。为了缓解这一问题,研究者们提出了多种正则化方法,其中权重衰减和暂退法(Dropout)是两种常用的技术。
权重衰减,也称为L2正则化,通过在损失函数中加入权重的平方和来惩罚大的权重,从而防止模型过度复杂。这种方法鼓励模型使用更小的权重,以减少对训练数据的依赖,增强模型的泛化能力。
暂退法则是一种通过随机丢弃神经网络中的部分神经元来防止过拟合的方法。在训练过程中,暂退法会随机将部分神经元的输出设置为0,这有助于减少神经元之间的复杂共适应性,使得模型更加健壮。
在本文中,我们将深入探讨权重衰减和暂退法这两种正则化技术,并通过PyTorch和PaddlePaddle两个流行的深度学习框架来展示如何实现这些技术。无论你是PyTorch的拥趸,还是PaddlePaddle的忠实用户,本文都将为你提供详尽的实现指南,助你更好地理解和应用这两种重要的正则化方法。让我们一同踏上这场探索之旅,共同提升深度学习模型的性能与泛化能力。
本文部分为torch框架以及部分理论分析,paddle框架对应代码可见权重衰减与暂退法paddle
import torch
print("pytorch version:",torch.__version__)
pytorch version: 2.3.0+cu118
当我们谈论机器学习模型的性能时,经常会提到两个关键指标:训练误差和泛化误差。这两个误差度量有助于我们了解模型的学习效果和预测未知数据的能力。下面,我将结合一个简单的例子来详细介绍这两个概念。
训练误差
训练误差是模型在训练数据集上的表现。它衡量了模型对于已经见过的数据的拟合程度。训练误差低意味着模型能够很好地学习和复现训练集中的数据规律和特征。
假设我们有一个简单的线性回归模型,用于预测房屋的价格。训练数据集包含了100套房屋的面积和价格。我们使用这个数据集来训练模型,使其能够根据房屋面积预测价格。
训练完成后,我们在同样的训练数据集上评估模型的性能。如果模型预测的价格与真实价格相差很小,那么训练误差就低。反之,如果预测价格与真实价格相差较大,则训练误差高。
泛化误差
泛化误差是模型在未见过的数据(即测试数据)上的表现。它衡量了模型对于新数据的预测能力,是评估模型泛化性能的重要指标。一个具有良好泛化能力的模型能够在未见过的数据上做出准确的预测。
接着训练误差中的例子,在训练完线性回归模型后,我们获得了一个新的、独立的数据集,其中包含了另外20套房屋的面积和价格。这些数据在训练过程中模型是未见过的。
当我们在这个新数据集上评估模型时,模型根据房屋面积预测出的价格与实际价格的差距,就反映了模型的泛化误差。如果预测价格与真实价格相差很小,说明模型的泛化误差低,泛化能力强。相反,如果预测价格与真实价格相差较大,则说明模型的泛化误差高。
训练误差和泛化误差都是评估机器学习模型性能的重要指标。训练误差低表明模型能够很好地拟合训练数据,而泛化误差低则表明模型能够很好地预测未见过的数据。理想情况下,我们希望模型既有较低的训练误差,也有较低的泛化误差,这通常需要在模型的复杂度和泛化能力之间找到平衡。
然而,在实际应用中,过度追求训练误差的最小化可能导致模型过度拟合训练数据,从而损害了其在新数据上的预测能力(即增加了泛化误差)。因此,我们通常需要使用正则化技术(如L1、L2正则化、暂退法等)来防止过拟合,以提高模型的泛化性能。
在比较训练和验证误差时,需留意两种典型状况。首先,应警惕训练误差与验证误差均处于较高水平,但两者间差距甚微的情形。若模型无法有效降低训练误差,这可能表明模型复杂度不足,难以捕捉数据的内在模式。同时,由于训练和验证误差间的差距较小,意味着模型的泛化误差并不大。因此,我们可以考虑采用更复杂的模型来尝试降低训练误差。这种情况通常被称为欠拟合。
反之,当训练误差显著低于验证误差时,则需警惕过拟合的风险。值得注意的是,过拟合并非总是负面的。在深度学习领域,表现最佳的预测模型通常在训练数据上的表现会明显优于在验证数据上的表现。归根结底,我们更加关注的是验证误差本身,而非训练误差与验证误差之间的差异。
模型是否出现过拟合或欠拟合,可能受到模型复杂度以及可用训练数据集规模的影响。
权重衰减
权重衰减,也称为L2正则化,是一种常用的正则化技术,用于防止过拟合。它通过在损失函数中加入权重的平方和来惩罚大的权重,从而减少模型对训练数据的依赖。权重衰减的核心思想是在原损失函数的基础上,根据权值的大小加入一个惩罚项。具体而言,假设原损失函数为 L ( w ) L(\mathbf{w}) L(w),其中 w \mathbf{w} w代表模型的权值,则加入权重衰减后的损失函数可表示为:
L ′ ( w ) = L ( w ) + λ R ( w ) L'(\mathbf{w}) = L(\mathbf{w}) + \lambda R(\mathbf{w}) L′(w)=L(w)+λR(w)
其中, L ′ ( w ) L'(\mathbf{w}) L′(w)是正则化后的损失函数, λ \lambda λ是权重衰减参数(超参数), R ( w ) R(\mathbf{w}) R(w)是正则化项。在实际应用中,最常用的正则化项是L2范数(亦称Ridge正则化),即权值平方和的一半:
R ( w ) = 1 2 ∑ i w i 2 R(\mathbf{w}) = \frac{1}{2} \sum_{i} w_i^2 R(w)=21i∑wi2
因此,正则化后的损失函数可进一步表示为:
L ′ ( w ) = L ( w ) + λ 2 ∑ i w i 2 L'(\mathbf{w}) = L(\mathbf{w}) + \frac{\lambda}{2} \sum_{i} w_i^2 L′(w)=L(w)+2λi∑wi2
在利用梯度下降法最小化正则化后的损失函数时,权值更新规则会发生相应变化。标准梯度下降的权值更新规则为:
w ← w − η ∇ L ( w ) \mathbf{w} \leftarrow \mathbf{w} - \eta \nabla L(\mathbf{w}) w←w−η∇L(w)
其中, η \eta η是学习率, ∇ L ( w ) \nabla L(\mathbf{w}) ∇L(w)是损失函数关于权值的梯度。而在引入权重衰减后,更新规则变为:
w ← w − η ( ∇ L ( w ) + λ w ) \mathbf{w} \leftarrow \mathbf{w} - \eta (\nabla L(\mathbf{w}) + \lambda \mathbf{w}) w←w−η(∇L(w)+λw)
这表明,在每次更新时,除了考虑损失函数的梯度外,还会根据权值大小施加一个收缩项,使权值向零收缩。权重衰减作为一种有效的正则化技术,通过向损失函数中加入基于权值大小的惩罚项,有助于防止机器学习模型过拟合。它鼓励模型保持较小的权值,从而倾向于生成更简单的模型,这些模型通常对未见数据具有更好的泛化能力。通过调整权重衰减参数 λ \lambda λ,可以控制惩罚项的力度,进而影响模型的复杂度和泛化性能。
接下来,我们设计一段代码,来测试一下权重衰减的效果。
# 首先我们生成一些具有线性关系的数据
def synthetic_data_linear(w, b, num_examples):"""生成y=Xw+b+噪声"""X = torch.normal(-1, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(-0.01, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([-0.1, -0.2, -0.3, -0.4, -0.5, -1.0, 1, 0.5, 0.4, 0.3, 0.2, 0.1]) # 参数这样设置是为了让数据期望变为0
true_b = torch.tensor(0.6)
features_train, labels_train = synthetic_data_linear(true_w, true_b, 500)
features_test, labels_test = synthetic_data_linear(true_w, true_b, 100)
接下来,我们设计一个多层感知机用来拟合数据,并加入权重衰减。
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader # 设定超参数
learning_rate = 0.005 # 学习率
batch_size = 32 # 批大小
epochs = 20 # 迭代轮数
weight_decay = 0.01 # 权重衰减系数 # 将生成的数据放入DataLoader中
train_dataset = torch.utils.data.TensorDataset(features_train, labels_train)
test_dataset = torch.utils.data.TensorDataset(features_test, labels_test)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 定义模型架构
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(12, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 1) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 实例化模型,定义损失函数和优化器
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay) # 使用权重衰减 # 训练模型
for epoch in range(epochs): for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() # 清空梯度 outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新权重 print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.item()}') Epoch 1/20, Loss: 0.8894861340522766
Epoch 2/20, Loss: 0.3511538803577423
Epoch 3/20, Loss: 0.0896303802728653
Epoch 4/20, Loss: 0.02197984606027603
Epoch 5/20, Loss: 0.029118452221155167
Epoch 6/20, Loss: 0.017600927501916885
Epoch 7/20, Loss: 0.0046103657223284245
Epoch 8/20, Loss: 0.008393934927880764
Epoch 9/20, Loss: 0.018870992586016655
Epoch 10/20, Loss: 0.018793821334838867
Epoch 11/20, Loss: 0.0025365424808114767
Epoch 12/20, Loss: 0.0068980855867266655
Epoch 13/20, Loss: 0.006183989811688662
Epoch 14/20, Loss: 0.014932369813323021
Epoch 15/20, Loss: 0.01221642829477787
Epoch 16/20, Loss: 0.007736223749816418
Epoch 17/20, Loss: 0.002323838649317622
Epoch 18/20, Loss: 0.0014630617806687951
Epoch 19/20, Loss: 0.0037388321943581104
Epoch 20/20, Loss: 0.0044212075881659985
接下来让我们在训练集和测试集上分别测试模型损失。
# 测试模型在训练集上精度
model.eval()
with torch.no_grad(): for inputs, labels in train_loader: outputs = model(inputs) loss = criterion(outputs, labels)print(f'loss of the network on the train dataset: {loss}')break # 测试模型在测试集上精度
model.eval()
with torch.no_grad(): correct = 0 total = 0 for inputs, labels in test_loader: outputs = model(inputs) loss = criterion(outputs, labels)print(f'loss of the network on the test dataset: {loss}')break
loss of the network on the train dataset: 0.0036835460923612118
loss of the network on the test dataset: 0.003596331924200058
可以看到此时训练集和测试集上模型准确率基本接近,且模型未出现过拟合,接下来我们将取消权重衰减这一过程看看。
# 实例化模型,定义损失函数和优化器
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=0) # 权重衰减为0 # 训练模型
for epoch in range(epochs): for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() # 清空梯度 outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新权重 print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.item()}') # 测试模型在训练集上精度
model.eval()
with torch.no_grad(): for inputs, labels in train_loader: outputs = model(inputs) loss = criterion(outputs, labels)print(f'loss of the network on the train dataset: {loss}')break # 测试模型在测试集上精度
model.eval()
with torch.no_grad(): correct = 0 total = 0 for inputs, labels in test_loader: outputs = model(inputs) loss = criterion(outputs, labels)print(f'loss of the network on the test dataset: {loss}')break
Epoch 1/20, Loss: 0.3804636001586914
Epoch 2/20, Loss: 0.10201512277126312
Epoch 3/20, Loss: 0.05300257354974747
Epoch 4/20, Loss: 0.022839698940515518
Epoch 5/20, Loss: 0.06588203459978104
Epoch 6/20, Loss: 0.03117508627474308
Epoch 7/20, Loss: 0.008893032558262348
Epoch 8/20, Loss: 0.005567398853600025
Epoch 9/20, Loss: 0.003931932616978884
Epoch 10/20, Loss: 0.0034582510124891996
Epoch 11/20, Loss: 0.008027699775993824
Epoch 12/20, Loss: 0.0031271420884877443
Epoch 13/20, Loss: 0.003611028892919421
Epoch 14/20, Loss: 0.0010798544390127063
Epoch 15/20, Loss: 0.0021747848950326443
Epoch 16/20, Loss: 0.0023846726398915052
Epoch 17/20, Loss: 0.003580381628125906
Epoch 18/20, Loss: 0.0025739886332303286
Epoch 19/20, Loss: 0.0016739631537348032
Epoch 20/20, Loss: 0.002029286464676261
loss of the network on the train dataset: 0.002409562701359391
loss of the network on the test dataset: 0.007698399946093559
可以看到此时模型过拟合程度明显加深。
实际上,当模型训练的数据量足够大时,过拟合问题并不明显,此时权重衰减几乎不会起到作用。
暂退法(Dropout)
暂退法(Dropout)是一种常用的正则化方法,它通过在训练过程中随机丢弃部分神经元来减少模型参数间的关联性,从而达到减少过拟合的效果。暂退法在训练过程中,每次前向传播时,随机丢弃一部分神经元,并将其输出置为0。在测试过程中,不进行暂退操作。
在训练过程中,对于神经网络中的每一层,每个神经元以概率( p )保留,以概率( 1-p )丢弃。这可以用数学公式表示为:
z ( l ) = r ( l ) ⊙ a ( l − 1 ) \mathbf{z}^{(l)} = \mathbf{r}^{(l)} \odot \mathbf{a}^{(l-1)} z(l)=r(l)⊙a(l−1)
其中:
- z ( l ) \mathbf{z}^{(l)} z(l) 是应用Dropout后第 l l l层的输入。
- a ( l − 1 ) \mathbf{a}^{(l-1)} a(l−1)是前一层的激活。
- r ( l ) \mathbf{r}^{(l)} r(l) 是一个二元掩码向量,其中每个元素都是从参数为 p p p的伯努利分布中抽取的。 ⊙ \odot ⊙表示元素乘法。
(伯努利分布(Bernoulli Distribution)也被称为0-1分布或两点分布,是一种离散概率分布,用于描述一个只有两种可能结果的随机试验,通常用来表示成功或失败、是或否等二选一的情况。
具体来说,如果随机变量X只有两个可能的取值0和1:
事件发生、成功的概率为p(0<p<1);
事件不发生、失败的概率则为q=1-p。)
让我们用代码演示一下暂退法的过程:
# 定义一个测试网络
class Net_Isdropout(nn.Module):def __init__(self):super(Net_Isdropout, self).__init__()self.fc1 = nn.Linear(12, 5)self.dropout = nn.Dropout(p=0.5) # 丢弃概率为0.5def forward(self, x):# 随机丢弃一部分神经元,并将其输出置为0x = self.fc1(x)x = self.dropout(x)return xdef forward_withoutdropout(self, x):# 不丢弃任何神经元x = self.fc1(x)return x# 让我们测试一下
model = Net_Isdropout()
x_test = torch.randn(1, 12)
print(model.forward(x_test))
print(model.forward_withoutdropout(x_test))
tensor([[-1.5135, 2.2347, -0.3080, 0.7851, -1.0136]], grad_fn=<MulBackward0>)
tensor([[-0.7567, 1.1173, -0.1540, 0.3926, -0.5068]],grad_fn=<AddmmBackward0>)
可以看到,经过dropout层输出后,部分神经元的输出被置为0,即被丢弃了。接下来让我们继续使用上方的数据集,重新设计网络看一下dropout的效果吧。
# 定义模型架构
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(12, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 1) self.dropout = nn.Dropout(p=0.3) # 丢弃概率为0.3def forward(self, x): x = torch.relu(self.fc1(x)) x = self.dropout(x) # 随机丢弃一部分神经元,并将其输出置为0x = torch.relu(self.fc2(x)) x = self.fc3(x) return x def forward_withoutdropout(self, x):# 不丢弃任何神经元x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return x# 实例化模型,定义损失函数和优化器
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=0) # 使用权重衰减 # 训练模型
for epoch in range(epochs): for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() # 清空梯度 outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新权重 print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.item()}') # 测试模型在训练集上精度
model.eval()
with torch.no_grad(): for inputs, labels in train_loader: outputs = model.forward_withoutdropout(inputs) loss = criterion(outputs, labels)print(f'loss of the network on the train dataset: {loss}')break # 测试模型在测试集上精度
model.eval()
with torch.no_grad(): correct = 0 total = 0 for inputs, labels in test_loader: outputs = model.forward_withoutdropout(inputs) loss = criterion(outputs, labels)print(f'loss of the network on the test dataset: {loss}')break
Epoch 1/20, Loss: 1.4576040506362915
Epoch 2/20, Loss: 0.36066704988479614
Epoch 3/20, Loss: 0.2595958709716797
Epoch 4/20, Loss: 0.18967191874980927
Epoch 5/20, Loss: 0.30267801880836487
Epoch 6/20, Loss: 0.1744869500398636
Epoch 7/20, Loss: 0.14163830876350403
Epoch 8/20, Loss: 0.15505251288414001
Epoch 9/20, Loss: 0.1287088841199875
Epoch 10/20, Loss: 0.13843272626399994
Epoch 11/20, Loss: 0.136577308177948
Epoch 12/20, Loss: 0.09528158605098724
Epoch 13/20, Loss: 0.11676064878702164
Epoch 14/20, Loss: 0.07942278683185577
Epoch 15/20, Loss: 0.0655207484960556
Epoch 16/20, Loss: 0.049338024109601974
Epoch 17/20, Loss: 0.09166398644447327
Epoch 18/20, Loss: 0.05438005179166794
Epoch 19/20, Loss: 0.08748330175876617
Epoch 20/20, Loss: 0.12238947302103043
loss of the network on the train dataset: 0.021074801683425903
loss of the network on the test dataset: 0.02531733736395836
此时模型并没有过拟合或过拟合程度减轻,与之前权重衰减为0的情况做对比,可以发现暂退法具有一定的正则化效果。
除了权重衰减(也称为L2正则化)和暂退法(Dropout)之外,还有其他几种常见的正则化方法,用于防止模型过拟合:
-
L1正则化:与L2正则化类似,L1正则化是在损失函数中添加一个与模型参数(权重)绝对值之和成正比的项。L1正则化有助于产生稀疏权重矩阵,即使得模型中的很多参数变为零,从而简化模型并防止过拟合。
-
数据增强:虽然数据增强不直接作用于模型参数,但它是一种有效的正则化技术,通过增加训练数据的多样性来提高模型的泛化能力。例如,在图像识别任务中,可以通过旋转、平移、缩放、颜色变换等方式对原始图像进行变换,生成新的训练样本。
-
提前终止:这是一种简单而有效的正则化策略。在训练过程中,我们会监控模型在验证集上的性能。当验证集上的误差开始上升时(即模型开始出现过拟合迹象),我们就提前终止训练。这样可以防止模型在训练数据上过度优化,从而提高其在未知数据上的泛化能力。
-
集成方法:集成方法,如Bagging和Boosting,也可以通过结合多个模型的预测结果来提高泛化能力。虽然这些方法本身并不直接对模型进行正则化,但它们通过组合多个可能过度拟合的模型来减少过拟合的风险。
-
批量归一化(Batch Normalization):虽然批量归一化主要用于加速神经网络的训练和提高模型性能,但它也有助于减少内部协变量偏移,从而间接起到正则化的作用。通过规范化每一层的输入,批量归一化可以使模型更加稳定,并减少过拟合的风险。
-
对抗训练:对抗训练是一种通过向输入数据添加微小扰动来增强模型鲁棒性的方法。这些扰动被设计为最大化模型的损失函数,从而使模型在面对轻微变化的数据时仍然能够保持稳定的性能。对抗训练可以视为一种正则化技术,因为它有助于减少模型对训练数据的依赖性,并提高其泛化能力。
-
混合正则化:有时可以将多种正则化方法结合使用,例如同时应用L1和L2正则化(也称为Elastic Net正则化),以结合两者的优点。这种方法可以帮助模型在稀疏性和稳定性之间找到平衡。
选择哪种正则化方法取决于具体的应用场景和数据集特性。在实际应用中,可能需要通过实验来确定最佳的正则化策略。
相关文章:

权重衰减与暂退法——pytorch与paddle实现模型正则化
权重衰减与暂退法——pytorch与paddle实现模型正则化 在深度学习中,模型正则化是一种至关重要的技术,它有助于防止模型过拟合,提高泛化能力。过拟合是指在训练数据上表现良好,但在测试数据或新数据上表现不佳的现象。为了缓解这一…...
MYSQL-windows安装配置两个或多个版本MYSQL
安装第一个mysql很简单,这里不再赘述。主要说说第二个怎么安装,服务怎么配置。 1. 从官网下载第二个MySQL并安装 一般都是免安装版了,下载解压到某个文件目录下(路径中尽量不要带空格或中文),再新建一个my.ini文件(或…...

6、Spring Boot 3.x集成RabbitMQ动态交换机、队列
一、前言 本篇主要是围绕着 Spring Boot 3.x 与 RabbitMQ 的动态配置集成,比如动态新增 RabbitMQ 交换机、队列等操作。二、默认RabbitMQ中的exchange、queue动态新增及监听 1、新增RabbitMQ配置 RabbitMQConfig.java import org.springframework.amqp.rabbit.a…...

【分布式微服务云原生】 探索SOAP协议:简单对象访问协议的深度解析与实践
探索SOAP协议:简单对象访问协议的深度解析与实践 摘要: 在现代分布式系统中,SOAP(简单对象访问协议)扮演着至关重要的角色,提供了一种标准化的方式来实现不同系统间的通信。本文深入探讨了SOAP的工作原理、…...

C语言题目练习2
前面我们知道了单链表的结构及其一些数据操作,今天我们来看看有关于单链表的题目~ 移除链表元素 移除链表元素: https://leetcode.cn/problems/remove-linked-list-elements/description/ 这个题目要求我们删除链表中是指定数据的结点,最终返…...
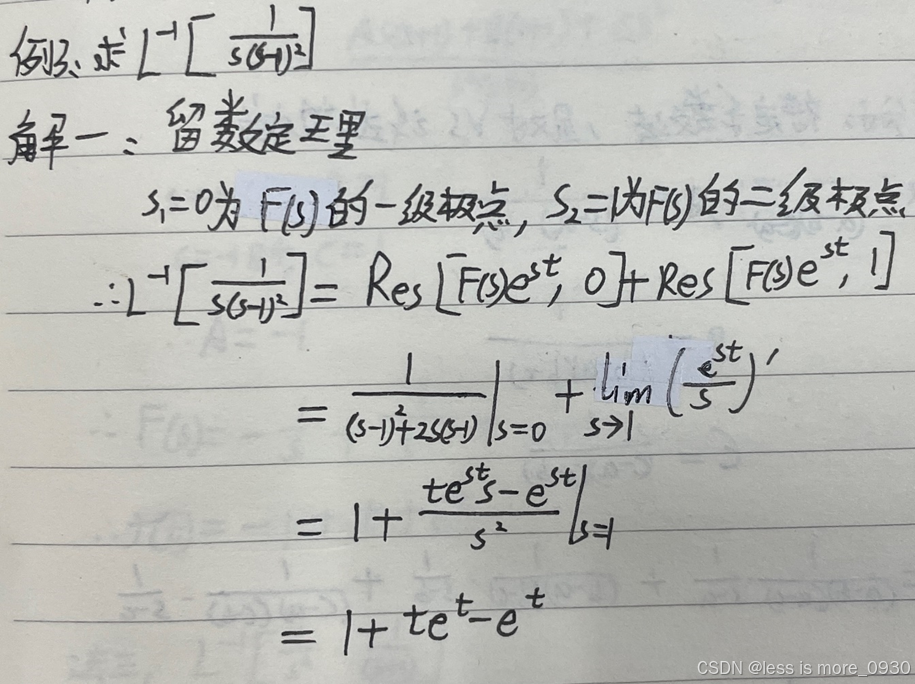
复变函数与积分变换——留数定理求拉氏逆变换
1.留数定理 若s1,s2,…,sn是F(s)的所有奇点(函数在某个点上的取值无定义或者无限大),且当s→∞时,F(s)→0,则有: 一般地: s1是一级极点,则&#…...

RabbitMQ事务模块
目录 消息分发 负载均衡 幂等性保障 顺序性保障 顺序性保障方案 二号策略:分区消费 三号策略:消息确认机制 四号策略: 消息积压 RabbitMQ集群 选举过程 RabbitMQ是基于AMQP协议实现的,该协议实现了事务机制,要么全部成功,要么全…...

Android终端GB28181音视频实时回传设计探讨
技术背景 好多开发者,在调研Android平台GB28181实时回传的时候,对这块整体的流程,没有个整体的了解,本文以大牛直播SDK的SmartGBD设计开发为例,聊下如何在Android终端实现GB28181音视频数据实时回传。 技术实现 Andr…...

AI金融攻防赛:金融场景凭证篡改检测(DataWhale组队学习)
引言 大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年10月学习赛的AI金融攻防赛学习总结文档。本文主要讲解如何解决 金融场景凭证篡改检测的核心问题,以及解决思路和代码实现过程。希望…...

华为OD机试真题---喊7的次数重排
题目描述 喊7是一个传统的聚会游戏。N个人围成一圈,按顺时针从1到N编号。编号为1的人从1开始喊数,下一个人喊的数字为上一个人的数字加1。但是,当将要喊出来的数字是7的倍数或者数字本身含有7时,不能把这个数字直接喊出来&#x…...

使用阿里巴巴的图
参考链接1 引用彩色图标可参考以下链接 (到第三步 测试图标效果 的时候 还是可以保持之前的写法:<i/sapn class“iconfont icon-xxx”>也会出现彩色的) 参考链接2 阿里巴巴字体使用 也可以直接将官网的代码复制过来到页面的css区域...

【hot100-java】排序链表
链表题。 使用归并排序法。 一图解决。 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val val; }* ListNode(int val, ListNode next) { this.val val; thi…...
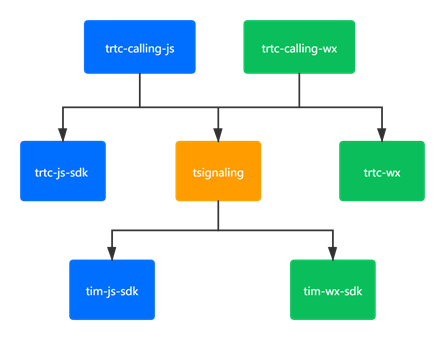
腾讯云视立方TRTCCalling Web 相关
基础问题 什么是 TRTCCalling? TRTCCalling 是在 TRTC 和 TIM 的基础上诞生的一款快速集成的音视频的解决方案。支持1v1和多人视频/语音通话。 TRTCCalling 是否支持接受 roomID 为字符串? roomID 可以 string,但只限于数字字符串。 环境问题 Web …...

使用argparse库实现命令行参数解析的实用指南
使用argparse库实现命令行参数解析的实用指南 在现代软件开发中,命令行工具的使用越来越普遍。无论是自动化脚本、数据处理工具,还是系统管理工具,命令行参数解析都是一个不可或缺的功能。Python的argparse库提供了一种简单而强大的方式来处理命令行参数,使得开发者能够轻…...

kafka消息队列核心内容及常见问题
目录 1. 使用消息队列的目的(优点与缺点) 2. 常见各消息队列对比 3. kafka介绍 3.1 kafka简介 3.2 kafka特点 3.3 kafka系统架构 3.4 设置数据可靠性 3.4.1 Topic 分区副本 3.4.2 消息确认机制 4. 常见问题(面试题) 4.…...

电脑无线网wifi和有线网同时使用(内网+外网同时使用)
一、要求 我这里以无线网wifi为外网,有线网卡为内网为例: 一、基本信息 无线wifi(外网):ip是192.168.179.235,网关是192.168.179.95有线网(内网):ip是192.168.10.25&…...

Ubuntu22.04阿里云服务器 Gitlab搭建CICD
gitlab搭建cicd流水线教程 1、阿里云申请免费云盘 申请免费云盘用于创建gitlab 申请方法百度 2、安装gitlab-ce 更新系统: sudo apt update sudo apt upgrade -y 安装必要的依赖: sudo apt install -y curl openssh-server ca-certificates pos…...

2024最新全流程ChatGPT深度科研应用、论文与项目撰写、数据分析、机器学习、深度学习及AI绘图
2022年11月30日,可能将成为一个改变人类历史的日子——美国人工智能开发机构OpenAI推出了聊天机器人ChatGPT3.5,将人工智能的发展推向了一个新的高度。 2023年4月,更强版本的ChatGPT4.0上线,文本、语音、图像等多模态交互方式使其…...

网络流C++
网络流问题及其应用 网络流问题是图论中的一个经典问题,应用于交通调度、物流配送、计算机网络等领域。它通过模型化图中的流量传递过程,解决从源点传递流量到汇点的最优流量分配问题。本文将介绍网络流的基本概念、几种经典算法,并通过一个…...
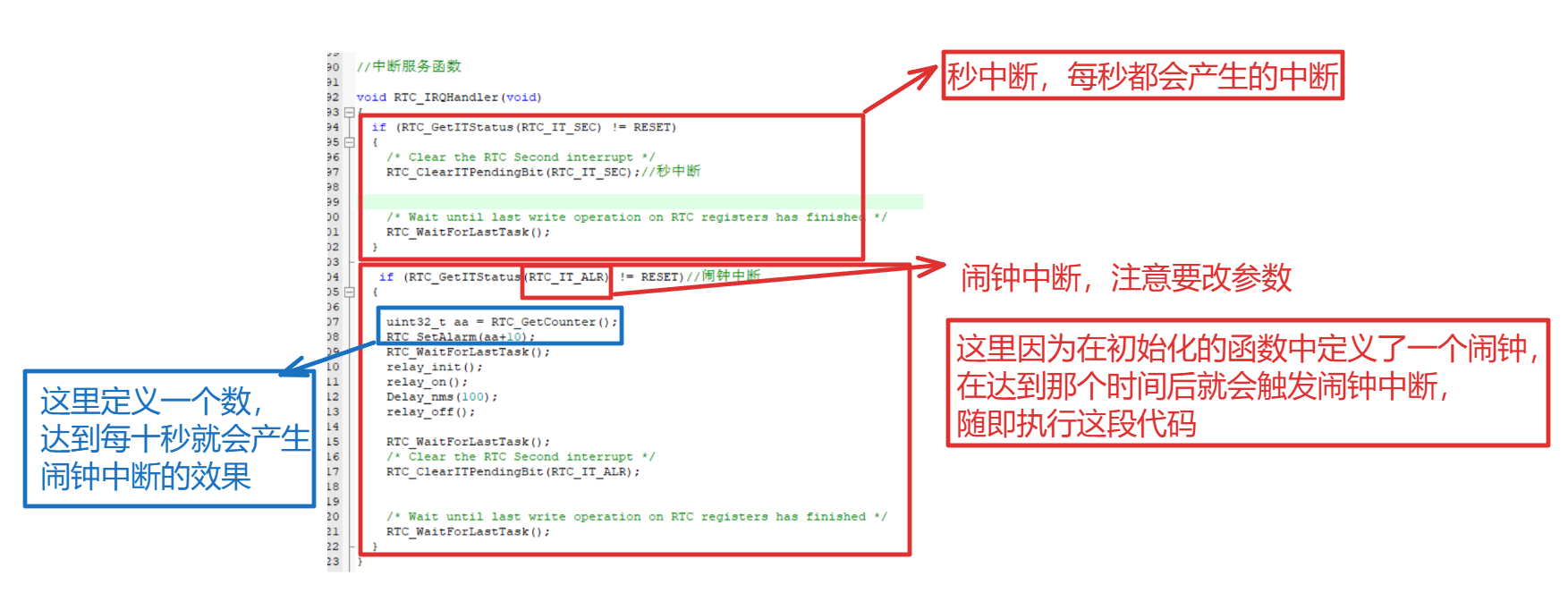
RTC -
RTC 目录 RTC 回顾 RTC 如何实现RTC制作一个时钟日历 代码编写 rtc.c完整代码 模块开发的步骤: 1、找文档 2、 在文档里面找通信方式,通信过程(协议) 3、代码> -- 前面学的是模块的开发,串口类,I…...

避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战
避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战 在医疗AI领域,癫痫脑电信号分析一直是个充满挑战的课题。许多开发者满怀信心地构建模型,却在验证阶段遭遇性能瓶颈——准确率停滞不前,误报率居…...

AI智能体密钥安全管理:AgentVault架构解析与实战指南
1. 项目概述:一个为AI智能体打造的“保险箱”最近在折腾AI智能体(Agent)应用开发的朋友,估计都绕不开一个核心痛点:如何安全、可靠地管理智能体运行过程中需要用到的各种密钥、凭证和敏感数据?无论是调用Op…...

NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导?
NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导? 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: ht…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

Copaw_dev:AI编程助手增强框架,提升代码生成与自动化开发效率
1. 项目概述:Copaw_dev 是什么,以及它为何值得关注如果你是一名开发者,尤其是对自动化、代码生成或者AI辅助编程感兴趣,那么“Copaw_dev”这个项目标题很可能已经引起了你的注意。乍一看,这个由“G-Divine”维护的项目…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

轻量级服务器监控面板:从原理到部署实战
1. 项目概述:一个开源监控面板的诞生最近在折腾服务器和容器化应用,发现一个挺普遍的需求:当你手头有几台服务器,上面跑着几个Docker容器,或者一些自己写的服务,你总想知道它们现在“活”得怎么样。CPU是不…...
从零构建大语言模型:Transformer架构、训练技巧与实战指南
1. 项目概述:从零构建你自己的大语言模型最近几年,大语言模型(LLM)的热度居高不下,从ChatGPT到Claude,再到国内外的各种开源模型,它们展现出的理解和生成能力让人惊叹。但你是否也和我一样&…...

基于意图与技能解耦的智能对话系统构建指南
1. 项目概述:一个意图与技能驱动的AI对话引擎最近在折腾AI应用开发,特别是对话型AI助手时,发现一个核心痛点:如何让AI不仅能理解用户说了什么(意图识别),还能精准地调用相应的功能(技…...

AI增强型写作工具Hermes-Writer:为开发者打造的智能写作助手
1. 项目概述:一个面向开发者的智能写作助手最近在GitHub上看到一个挺有意思的项目,叫dav-niu474/Hermes-Writer。乍一看标题,你可能会觉得这又是一个普通的Markdown编辑器或者写作工具。但如果你点进去,仔细研究一下它的README、代…...