【Spring AI】Java实现类似langchain的向量数据库RAG_原理与具体实践
介绍一下RAG:
检索增强生成(RAG)是一种技术,它结合了检索模型和生成模型来提高文本生成的质量。通过从企业私有或专有的数据源中检索相关信息,并将这些信息与大型语言模型相结合,RAG能够显著减少模型产生幻觉的情况,同时使回答更加精确、相关。这解决了大模型在缺乏特定上下文或最新数据时提供的答案不够准确的问题。
向量数据库在Rag中的具体作用说明:
在检索增强生成(RAG)过程中,向量数据库起着核心作用。首先,原始文档或数据通过Embedding模型转化为高维向量,随后这些向量被存储于向量数据库中。当有新的查询请求时,系统将该查询也转换为相应的向量,并在向量数据库中查找最相似的向量以获取相关上下文信息。使用向量数据库的原因在于其能高效地处理大规模高维向量的存储与检索问题,支持快速精确匹配,这对于提高RAG系统的响应速度及准确性至关重要。此外,向量数据库还能够很好地支持非结构化数据的管理,使得从大量文本或其他类型的内容中提取有价值的信息成为可能。
Spring AI alibaba 是什么:
Spring AI Alibaba 是基于 Spring Boot 的应用框架,专为 Java 开发者设计,用于集成和利用阿里云的通义大模型等AI服务。其核心优势在于提供了标准化接口,使得开发者能够以一致的方式访问不同AI供应商(如OpenAI、Azure、阿里云)的服务,只需更改配置即可切换不同的AI实现。这极大简化了开发流程,减少了因适配不同API而带来的工作量。此外,Spring AI Alibaba 还支持多种生成式任务,如对话、文生图、语音合成,并且与 Flux 流输出兼容,方便构建复杂的AI应用。通过Spring Boot的自动装配机制,可以轻松地在现有项目中添加强大的AI能力。
详细实践:
检索增强的后端代码编写
为了实现基于检索增强生成 (RAG) 的功能,以读取阿里巴巴财务报表PDF并提供相应的服务,我们首先需要理解如何配置Spring AI Alibaba来支持RAG能力。根据提供的我了解的信息,这涉及到一系列的准备工作和具体的代码实现步骤。
1. 环境准备
- JDK版本:确保你的开发环境使用的是JDK 17或更高版本。
- Spring Boot版本:项目需基于Spring Boot 3.3.x及以上版本构建。
- 阿里云账号与API Key获取:
-
- 登录阿里云百炼平台,开通“百炼大模型推理”服务。
-
- 服务开通后,在用户中心创建一个新的API Key,并妥善保存用于后续配置。
2. 配置阿里云通义千问 API Key
在你的应用程序环境中设置AI_DASHSCOPE_API_KEY环境变量:
export AI_DASHSCOPE_API_KEY=您的实际API密钥并在application.properties文件中添加如下配置项来引用这个环境变量:
spring.ai.dashscope.api-key: ${AI_DASHSCOPE_API_KEY}3. 添加必要的依赖库
由于Spring AI Alibaba目前处于早期阶段,其Maven仓库尚未正式发布所有相关组件,因此我们需要指定额外的仓库地址以便能够下载所需的库。请将以下仓库配置加入到你的pom.xml文件内:
<repositories><repository><id>sonatype-snapshots</id><url>https://oss.sonatype.org/content/repositories/snapshots</url><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases></repository></repositories><dependencies><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>1.0.0-M2</version></dependency><!-- 其他必要的依赖 -->
</dependencies>4. RAG服务实现
接下来是核心的服务逻辑实现,包括向量存储、文档检索等关键组件的定义。我们将创建一个名为RagService的服务类,它负责处理从PDF提取内容、建立索引以及最终基于查询条件进行响应的过程。
创建RagService类
public class RagService {// ...省略了构造器和其他成员变量声明...public String buildIndex() {String filePath = "阿里巴巴财报.pdf";DocumentReader reader = new DashScopeDocumentCloudReader(filePath, dashscopeApi, null);List<Document> documentList = reader.get();vectorStore.add(documentList);return "索引构建完成";}public StreamResponseSpec queryWithDocumentRetrieval(String message) {StreamResponseSpec response = chatClient.prompt().user(message).advisors(new DocumentRetrievalAdvisor(retriever, DEFAULT_USER_TEXT_ADVISE)).stream();return response;}
}提供REST接口
最后一步是在Controller层暴露两个端点,一个是用来初始化索引的/buildIndex,另一个则是实际对外提供查询服务的/ragChat:
@RestController
@RequestMapping("/ai")
public class RagController {@Autowiredprivate RagService ragService;@GetMapping("/buildIndex")public String buildIndex() {return ragService.buildIndex();}@GetMapping("/ragChat")public Flux<String> generate(@RequestParam("input") String input, HttpServletResponse httpResponse) {StreamResponseSpec chatResponse = ragService.queryWithDocumentRetrieval(input);httpResponse.setCharacterEncoding("UTF-8");return chatResponse.content();}
}以上就是通过检索增强技术实现读取PDF文件并提供问答服务的整体流程。此方案利用了Spring AI Alibaba提供的RAG框架,并结合阿里云的大规模语言模型能力,实现了高效的知识检索与自然语言处理。在实际部署前,请确保所有依赖均已被正确添加至项目,并且已按照要求设置了正确的环境变量及属性配置。
检索增强的前端代码编写
检索增强的前端代码编写
根据我了解的信息中提供的关于基于React构建支持流输出的前端项目的内容,我们可以按照类似的步骤来构建一个能够与后端http://localhost:8080/ai/ragChat?input=…接口交互,并处理返回的flux<String>数据流的前端应用。下面将具体阐述如何搭建这样的项目。
构建项目并填写代码
首先,我们需要创建一个新的React应用,并确保安装所有必需的依赖项。这可以通过运行以下命令实现:
npx create-react-app ragchat-frontend
cd ragchat-frontend
npm install接下来,我们将依次设置或修改几个关键文件以满足项目需求。
public/index.html
无需特别改动此文件,保持默认内容即可。
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>RAG Chat App</title></head><body><div id="root"></div></body></html>
src/index.js
同样地,这个文件基本可以保持原样,仅用于渲染应用入口组件App。
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';ReactDOM.render(<React.StrictMode><App /></React.StrictMode>,document.getElementById('root')
);src/App.js
这里是主应用程序组件,我们将其简单指向我们的聊天组件RAGChatComponent。
import React from 'react';
import RAGChatComponent from './components/RAGChatComponent';function App() {return (<div className="App"><RAGChatComponent /></div>);
}export default App;src/components/RAGChatComponent.js
这是核心功能所在的地方。我们需要在此处添加逻辑来发送请求到指定的URL,并且处理从服务器接收到的数据流。
import React, { useState } from 'react';function RAGChatComponent() {const [input, setInput] = useState('');const [messages, setMessages] = useState('');const handleInputChange = (event) => {setInput(event.target.value);};const handleSendMessage = async () => {try {const response = await fetch(`http://localhost:8080/ai/ragChat?input=${input}`);if (!response.ok) throw new Error("Network response was not ok");const reader = response.body.getReader();const decoder = new TextDecoder('utf-8');let done = false;while (!done) {const { value, done: readerDone } = await reader.read();done = readerDone;const chunk = decoder.decode(value, { stream: true });setMessages((prevMessages) => prevMessages + chunk);}// 请求完成后添加换行符setMessages((prevMessages) => prevMessages + '\n\n=============================\n\n');} catch (error) {console.error('Failed to fetch', error);}};const handleClearMessages = () => {setMessages('');};return (<div><inputtype="text"value={input}onChange={handleInputChange}placeholder="Enter your message"/><button onClick={handleSendMessage}>Send</button><button onClick={handleClearMessages}>Clear</button><div><h3>Messages:</h3><pre>{messages}</pre></div></div>);
}export default RAGChatComponent;通过以上步骤,你已经成功配置了一个简单的React应用,该应用能够向给定的后端服务发送请求,并实时显示返回的文本流。请确保你的后端服务正在本地运行于http://localhost:8080,并且允许来自前端的跨域请求(CORS)。如果需要进一步定制样式或其他功能,可以根据实际需求调整上述代码。

相关文章:
【Spring AI】Java实现类似langchain的向量数据库RAG_原理与具体实践
介绍一下RAG: 检索增强生成(RAG)是一种技术,它结合了检索模型和生成模型来提高文本生成的质量。通过从企业私有或专有的数据源中检索相关信息,并将这些信息与大型语言模型相结合,RAG能够显著减少模型产生幻…...

linux下使用systemctl设置开机自动运行程序
本文介绍在Linux下,使用systemctl设置开机自动运行程序,实现创建一个systemd服务单元文件,并启用该服务的方法。 1、创建.service文件 在/etc/systemd/system/目录下创建一个以.service结尾的文件,例如myapp.service:…...

复位电路的亚稳态
复位导致亚稳态的概念: 同步电路中,输入数据需要与时钟满足setup time和hold time才能进行数据的正常传输(数据在这个时间段内必须保持不变:1不能变为0,0也不能变为1),防止亚稳态; …...

针对考研的C语言学习(循环队列-链表版本以及2019循环队列大题)
题目 【注】此版本严格按照数字版循环队列的写法,rear所代表的永远是空数据 图解 1.初始化部分和插入部分 2出队 3.分部代码解析 初始化 void init_cir_link_que(CirLinkQue& q) {q.rear q.front (LinkList)malloc(sizeof(LNode));q.front->next NULL…...

系统架构设计师教程 第12章 12.4 信息系统架构案例分析 笔记
12.4 信息系统架构案例分析 ★★★★☆ 12.4.1 价值驱动的体系结构——连接产品策略与体系结构 1.价值模型概述 价值模型核心的特征可以简化为三种基本形式。 (1)价值期望值:表示对某一特定功能的需求,包括功能、质量和不同 级别质量的实用性。 (2)…...

web1.0,web2.0,web3.0 有什么区别 详解
Web 的发展经历了多个阶段,每个阶段都有其独特的特点和技术进步。下面是 Web 1.0、Web 2.0 和 Web 3.0 之间的主要区别和详细解释: Web 1.0 时间范围:大约在 1991 年至 1995 年。 Web 1.0 是互联网的最初形态,也被称为静态 Web…...
将图片添加到 PDF 的 5 种方法
需要一种称为 PDF 编辑器的特定工具才能将图片添加到 PDF。尽管大多数浏览器在查看和注释 PDF 文件方面都非常出色,但如果您使用图像到 PDF 技术,则只能将照片放入 PDF 中。无需修改即可将 PDF 文件恢复为原始格式的能力是使用此类软件程序甚至在线服务的…...

TiDB 优化器丨执行计划和 SQL 算子解读最佳实践
导读 在数据库系统中,查询优化器是数据库管理系统的核心组成部分,负责将用户的 SQL 查询转化为高效的执行计划,因而会直接影响用户体感的性能与稳定性。优化器的设计与实现过程充满挑战,有人比喻称这是数据库技术要持续攀登的珠穆…...

初学51单片机之I2C总线与E2PROM以及UART简单实例应用
这是I2C的系列的第三篇,这篇主要是写一个简单的程序来实践一下相关的内容。前面博主写过一个电子密码锁的程序初学51单片机之简易电子密码锁及PWM应用扩展_51单片机设计电子密码锁-CSDN博客 本篇主要是在此基础上修改下程序,让密码存储在E2PROM中&#…...

软考高级软件架构师论文——论Web系统的测试技术及其应用
【摘要】 本人于2023年8月参与了某地级市的市级机关电子政务信息系统的建设工作,该项目是该市机关的电子政务网建设计划的一部分,笔者在该项目中担任项目经理和系统分析师一职,主要负责项目的日常全面管理和质量保证与质量控制工作。该项目是基于WEB系统的,由于WEB系统具有…...
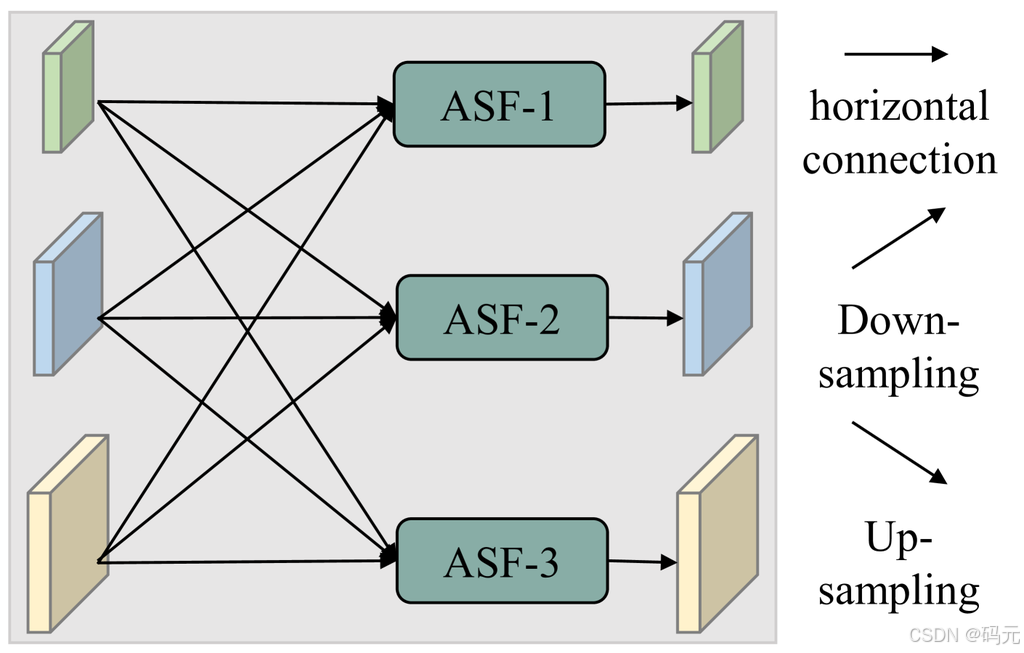
快速总结AFPN
AFPN: Asymptotic Feature Pyramid Network for Object Detection 解决的问题 特征金字塔架构的提出是为了解决尺度变化的问题,图像中物体真正有用的特征在顶部最高层需要通过多个中间尺度传播,并与这些尺度的特征交互,才能与底部的低层特征…...

Linux 内核中USB鼠标枚举失败问题总结
一、环境: 机器平台:linux 内核版本:linux-3.4 二、问题: USB鼠标接入后报错,log显示设备无法枚举 usb 1-1: new low-speed USB device number 10 using musb-hdrc hub 1-0:1.0: unable to enumerate USB device o…...

十六进制转二进制
128 64 32 16 8 4 2 1 十六进制:0~9ABCDEF(A是10、B是11、C是12、D是13、E是14、F是15) 每一个十六进制位转换成4个二进制位,左边不足4个补0 示例: 109CBE:0001 0000 1001 1100 1011 1110 8 4 2 1 1 …...

Python保存CSV文件,Excel打开后中文乱码
情况描述 在做多语言文件处理时, 使用 pandas, 并且指定了encoding为 UTF-8, 在 IDE, Sublime等编辑器上查看都显示正常,使用Excel打开非英文字符, 例如汉字, 阿拉伯文, 希伯来文等显…...
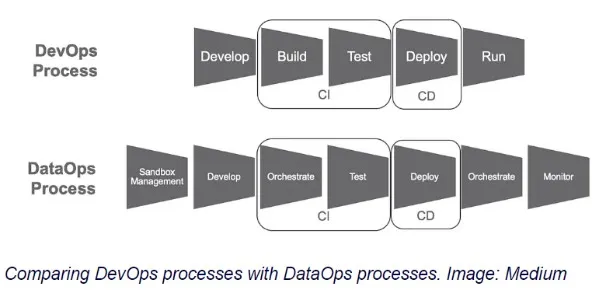
数据湖数据仓库数据集市数据清理以及DataOps
一提到大数据我们就知道是海量数据,但是我们并不了解需要从哪些维度去考虑这些数据的存储。比如 数据湖、数据仓库、数据集市,以及数据自动化应用DataOps有哪些实现方式和实际应用,这篇文章将浅显的做一次介绍。 数据湖 数据湖是一种以自然…...

「Ubuntu」文件权限说明(drwxr-xr-x)
我们在使用Ubuntu 查看文件信息时,常常使用 ll 命令查看,但是输出的详细信息有些复杂,特别是 类似与 drwxr-xr-x 的字符串,在此进行详细解释下 属主:所属用户 属组:文件所属组别 drwxr-xr-x 7 apps root 4…...
)
JS-学生管理系统(功能实现)
基础知识点掌握: 1.DOM节点 首先DOM树当做一颗到着生长的树,DOM树里面的每一个内容称为节点 节点类型: 属性节点元素节点文本节点其他 2.查找节点: 查找节点分为3个类型: 父节点子节点兄弟节点 (1&…...

C# 屏幕录制工具
屏幕录制工具 开发语音:C# vb.net 下载地址:https://download.csdn.net/download/polloo2012/89879996 功能:屏幕录制,声卡采集,麦克风采集。 屏幕录制:录制屏幕所有操作,并转换视频格式&…...

前端开发攻略---前端ocr图片文字提取功能
1、引入资源 通过链接引用 <script src"https://cdn.bootcdn.net/ajax/libs/tesseract.js/5.1.0/tesseract.min.js"></script> npm或其他方式下载 npm i tesseract 2、示例 <!DOCTYPE html> <html lang"en"><head><meta…...

平凯星辰亮相 2024开放原子开源生态大会,分享开源教育及社区治理经验
9 月 25-27 日,2024 开放原子开源生态大会在北京成功举办,本次大会以“开源赋能产业,生态共筑未来”为主题,由开放原子开源基金会主办,聚焦地方开源实践、企业开源建设思路,围绕开源生态建设,突…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

STM32CubeIDE实战指南:从代码编译到一键下载的完整流程解析
1. STM32CubeIDE开发环境概述 对于刚接触STM32开发的工程师来说,选择一款合适的集成开发环境(IDE)至关重要。STM32CubeIDE是ST官方推出的免费开发工具,它集成了代码编辑、编译、调试和下载功能于一体,特别适合新手快速上手。我在实际项目中使…...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...

NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导?
NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导? 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: ht…...

Path of Building:3个步骤从Build小白到规划大师的完整指南
Path of Building:3个步骤从Build小白到规划大师的完整指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building作为流放之路玩家最信赖的Build规…...

基于RAG的电影智能体构建:从向量检索到Agentic设计
1. 项目概述:一个能聊电影的智能体最近在GitHub上看到一个挺有意思的项目,叫tomasonjo/llm-movieagent。光看名字,你大概能猜到,这是一个和电影、和大型语言模型(LLM)相关的智能体。简单来说,它…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...