使用Go语言的gorm框架查询数据库并分页导出到Excel实例
文章目录
- 基本配置
- 配置文件管理
- 命令行工具: Cobra
- 快速入门
- 基本用法
- 生成mock数据
- SQL准备
- gorm自动生成结构体代码
- 生成mock数据
- 查询数据
- 导出Excel
- 使用 excelize
- 实现思路
- 完整代码参考
- 入口文件
- 效果演示
- 分页导出多个Excel文件
- 合并为一个完整的Excel文件
- 完整代码
基本配置
配置文件管理
添加依赖 go get github.com/spf13/viper,支持 JSON, TOML, YAML, HCL 等格式的配置文件。
在项目根目录下面新建 conf 目录,然后新建 application.yml 文件,此文件需要忽略版本控制。每次修改后,记得同步修改 conf/application.yml.demo 文件,让别人也知道你添加或修改了哪些内容。
server:port: 8080
datasource:driverName: mysqlhost: "127.0.0.1"port: "3306"database: go-demo-2025username: rootpassword: "123456"charset: utf8loc: Asia/Shanghai
配置初始化: common/initialization.go
// 配置初始化
func InitConfig() {workDir, _ := os.Getwd() //获取目录对应的路径viper.SetConfigName("application") //配置文件名viper.SetConfigType("yml") //配置文件类型(后缀名)viper.AddConfigPath(workDir + "/conf") //执行go run对应的路径配置fmt.Println(workDir)err := viper.ReadInConfig()if err != nil {panic(err)}
}
数据库配置: 使用 gorm 初始化数据库配置,参考 common/database.go 文件
var DB *gorm.DB// https://gorm.io/zh_CN/docs/index.html
func InitDB() *gorm.DB {//从配置文件中读取数据库配置信息host := viper.GetString("datasource.host")port := viper.Get("datasource.port")database := viper.GetString("datasource.database")username := viper.GetString("datasource.username")password := viper.GetString("datasource.password")charset := viper.GetString("datasource.charset")loc := viper.GetString("datasource.loc")args := fmt.Sprintf("%s:%s@tcp(%s:%s)/%s?charset=%s&parseTime=true&loc=%s",username,password,host,port,database,charset,url.QueryEscape(loc))//fmt.Println(args)db, err := gorm.Open(mysql.Open(args), &gorm.Config{Logger: logger.Default.LogMode(logger.Info), //配置日志级别,打印出所有的sql})if err != nil {fmt.Println(err)panic("failed to connect database, err: " + err.Error())}DB = dbreturn db
}
命令行工具: Cobra
Cobra是Go的CLI框架。它包含一个用于创建强大的现代CLI应用程序的库和一个用于快速生成基于Cobra的应用程序和命令文件的工具。
简单理解, 类似于 thinkphp 封装的
php think xxx的命令行工具.
Cobra 官网: https://cobra.dev
快速入门
- 安装:
go get github.com/spf13/cobra - 入口文件:
command.go - 核心文件:
cmd/cobra.go
基本用法
测试Demo: command/testCmd.go
执行: go run command.go testCmd --paramA 100 --paramB 200 hello your name
输出:
--- test 运行 ---
参数个数: 3
100
200
0=>hello
1=>your
2=>name
更多参考: https://www.cnblogs.com/niuben/p/13886555.html
生成mock数据
SQL准备
CREATE TABLE `user` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',`user_id` bigint(20) unsigned NOT NULL COMMENT '用户编号',`name` varchar(255) NOT NULL DEFAULT '' COMMENT '用户姓名',`age` tinyint(4) unsigned NOT NULL DEFAULT '0' COMMENT '用户年龄',`address` varchar(255) NOT NULL DEFAULT '' COMMENT '地址',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '添加时间',`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`),UNIQUE KEY `key_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
gorm自动生成结构体代码
需要引入gorm.io/gen扩展,参考代码:gorm_generate_db_struct.go
package mainimport ("gorm.io/driver/mysql""gorm.io/gen""gorm.io/gorm""strings"
)func main() {// 初始化配置common.InitConfig()// 连接数据库db := common.InitDB()// 生成实例g := gen.NewGenerator(gen.Config{// 相对执行`go run`时的路径, 会自动创建目录OutPath: "old_crm_models/query",// WithDefaultQuery 生成默认查询结构体(作为全局变量使用), 即`Q`结构体和其字段(各表模型)// WithoutContext 生成没有context调用限制的代码供查询// WithQueryInterface 生成interface形式的查询代码(可导出), 如`Where()`方法返回的就是一个可导出的接口类型Mode: gen.WithDefaultQuery | gen.WithQueryInterface,// 表字段可为 null 值时, 对应结体字段使用指针类型//FieldNullable: true, // generate pointer when field is nullable// 表字段默认值与模型结构体字段零值不一致的字段, 在插入数据时需要赋值该字段值为零值的, 结构体字段须是指针类型才能成功, 即`FieldCoverable:true`配置下生成的结构体字段.// 因为在插入时遇到字段为零值的会被GORM赋予默认值. 如字段`age`表默认值为10, 即使你显式设置为0最后也会被GORM设为10提交.// 如果该字段没有上面提到的插入时赋零值的特殊需要, 则字段为非指针类型使用起来会比较方便.FieldCoverable: false, // generate pointer when field has default value, to fix problem zero value cannot be assign: https://gorm.io/docs/create.html#Default-Values// 模型结构体字段的数字类型的符号表示是否与表字段的一致, `false`指示都用有符号类型FieldSignable: false, // detect integer field's unsigned type, adjust generated data type// 生成 gorm 标签的字段索引属性FieldWithIndexTag: false, // generate with gorm index tag// 生成 gorm 标签的字段类型属性FieldWithTypeTag: true, // generate with gorm column type tag})// 设置目标 dbg.UseDB(db)// 自定义字段的数据类型// 统一数字类型为int64,兼容protobufdataMap := map[string]func(detailType string) (dataType string){"tinyint": func(detailType string) (dataType string) { return "int64" },"smallint": func(detailType string) (dataType string) { return "int64" },"mediumint": func(detailType string) (dataType string) { return "int64" },"bigint": func(detailType string) (dataType string) { return "int64" },"int": func(detailType string) (dataType string) { return "int64" },}// 要先于`ApplyBasic`执行g.WithDataTypeMap(dataMap)// 自定义模型结体字段的标签// 将特定字段名的 json 标签加上`string`属性,即 MarshalJSON 时该字段由数字类型转成字符串类型jsonField := gen.FieldJSONTagWithNS(func(columnName string) (tagContent string) {//toStringField := `balance, `toStringField := ``if strings.Contains(toStringField, columnName) {return columnName + ",string"}return columnName})// 将非默认字段名的字段定义为自动时间戳和软删除字段;// 自动时间戳默认字段名为:`updated_at`、`created_at, 表字段数据类型为: INT 或 DATETIME// 软删除默认字段名为:`deleted_at`, 表字段数据类型为: DATETIME//autoUpdateTimeField := gen.FieldGORMTag("update_time", "column:update_time;type:int unsigned;autoUpdateTime")//autoCreateTimeField := gen.FieldGORMTag("create_time", "column:create_time;type:int unsigned;autoCreateTime")// 模型自定义选项组//fieldOpts := []gen.ModelOpt{jsonField, autoCreateTimeField, autoUpdateTimeField}fieldOpts := []gen.ModelOpt{jsonField}// 创建模型的结构体,生成文件在 model 目录; 先创建的结果会被后面创建的覆盖// 创建全部模型文件, 并覆盖前面创建的同名模型allModel := g.GenerateAllTable(fieldOpts...)// 创建模型的方法,生成文件在 query 目录; 先创建结果不会被后创建的覆盖g.ApplyBasic(allModel...)g.Execute()
}
参考: https://segmentfault.com/a/1190000042502370
生成的结构体代码如下:
type User struct {ID int64 `gorm:"column:id;type:int(11) unsigned;primaryKey;autoIncrement:true;comment:ID" json:"id"` // IDUserID int64 `gorm:"column:user_id;type:bigint(20) unsigned;not null;comment:用户编号" json:"user_id"` // 用户编号Name string `gorm:"column:name;type:varchar(255);not null;comment:用户姓名" json:"name"` // 用户姓名Age int64 `gorm:"column:age;type:tinyint(4) unsigned;not null;comment:用户年龄" json:"age"` // 用户年龄Address string `gorm:"column:address;type:varchar(255);not null;comment:地址" json:"address"` // 地址CreateTime time.Time `gorm:"column:create_time;type:datetime;not null;default:CURRENT_TIMESTAMP;comment:添加时间" json:"create_time"` // 添加时间UpdateTime time.Time `gorm:"column:update_time;type:datetime;not null;default:CURRENT_TIMESTAMP;comment:更新时间" json:"update_time"` // 更新时间
}
生成mock数据
代码路径:service/users/userService.go
// 批量添加mock数据
func (ctx *UserService) BatchCreateMockData() {for i := 1; i <= 82; i++ { //循环操作82次var users []*model.Userfor j := 1; j <= 100; j++ { //一次添加100条数据userid := "1" + fmt.Sprintf("%03d", i) + fmt.Sprintf("%03d", j)useridInt, _ := strconv.Atoi(userid)users = append(users, &model.User{UserID: int64(useridInt),Name: funcUtils.GenerateRandomChineseName(),Age: int64(common.GenerateRandomNumber()),Address: funcUtils.GenerateRandomChinaAddress(),})}err := ctx.GormDB.Create(users).Errorif err != nil {fmt.Println(fmt.Sprintf("第 %d 页添加失败,错误原因:%s", i, err))} else {fmt.Println(fmt.Sprintf("第 %d 页添加成功", i))}}
}
备注:以上代码中关于测试数据生成的工具:
- 中国地址生成器 https://github.com/GoFinalPack/chinese-address-generator
- 随机生成中国人姓名 https://www.jianshu.com/p/bab0994647b3

生成的测试数据效果如下:

查询数据
gorm 查询方法文档: https://gorm.io/zh_CN/docs/query.html
定义查询总数和查询列表的方法,代码路径:service/users/userService.go
// 查询总数
func (ctx *UserService) GetUserCount() int64 {var count int64err := ctx.GormDB.Model(&model.User{}).Where("1=1").Count(&count).Errorif err != nil {fmt.Println(fmt.Sprintf("查询总数错误:%s", err))return 0}//fmt.Println(fmt.Sprintf("总条数:%d", count))return count
}func (ctx *UserService) GetUserList(page int, pageSize int) []model.User {var dataList []model.Useroffset := (page - 1) * pageSize //偏移量err2 := ctx.GormDB.Select("*").Where("1=1").Order("id asc").Limit(pageSize).Offset(offset).Find(&dataList).Errorif err2 != nil {fmt.Println(fmt.Sprintf("查询列表错误:%s", err2))return nil}return dataList
}
导出Excel
使用 excelize
使用率高的几个扩展
excelize (github.com/xuri/excelize/v2)excelize (github.com/360EntSecGroup-Skylar/excelize)xlsx (github.com/tealeg/xlsx/v3)xxhash (github.com/OneOfOne/xxhash)
相关 Excel 开源类库性能对比: https://xuri.me/excelize/zh-hans/performance.html
此处以 github.com/xuri/excelize/v2 为例演示常用的Excel操作方法. 官方中文文档: https://xuri.me/excelize/zh-hans/
安装excelize go get github.com/xuri/excelize/v2
导出 Excel 文档参考代码:
var filePath stringfunc init() {filePath = fmt.Sprintf("files/%s", time.Now().Format("2006/01/02/"))
}// WriteExcel 导出 Excel 文档
// data: 要导出的数据
// return: 文件名, error
func WriteExcel(data [][]string, relativePath string, fileName string) (string, error) {//创建存放目录relativeFilePath := filePath + relativePath + "/"_, err := os.ReadDir(relativeFilePath)if err != nil {// 不存在就创建err = os.MkdirAll(relativeFilePath, fs.ModePerm)if err != nil {fmt.Println(err)}}//创建表格file := excelize.NewFile()sheetName := "Sheet1"index, _ := file.NewSheet(sheetName)for i, row := range data {for j, val := range row {// 列和行 数字索引转excel坐标索引cellName, _ := excelize.CoordinatesToCellName(j+1, i+1)//fmt.Println("cellName:", cellName)// 写入sheetfile.SetCellValue(sheetName, cellName, val)}}file.SetActiveSheet(index)//导出文件filePathName := relativeFilePath + fileName + "_" + common.GetMicroTimestamp() + ".xlsx"err = file.SaveAs(filePathName)if err != nil {return "", err}return filePathName, nil
}
实现思路
导出数据部分,考虑到数据量可能较大,如果一次性查询全量数据,可能造成内存或CPU爆满,因此不建议一次性全部导出,而是采用分页导出到多个文件,然后再将多个文件合并为一个Excel表格文件。
这里需要注意一个细节,就是正常导出的表格数据一般都是按照id(或者添加时间)倒序排列,最新的在前面。但是由于使用了分页导出,如果我们采用 order by id desc limit xxx offset xxx 有可能在分页查询的过程中产生新的数据,那么分页的偏移量(offset)可能导致出现重复数据,就是第一页的某一条数据有可能在第二页重复出现(应该很好理解吧?)。所以查询数据的时候需要 order by id asc 按照 id 从小到大的顺序导出数据就可以避免这个问题。
分页导出后,需要对整体顺序再次反转,最后合并的表格数据才能是按照 由新到旧 的顺序的结果。
// 二维数组/切片 反转
func ReverseTwoDimSlice(slice [][]string) {// 按照子切片的第0个元素进行倒序排列sort.Slice(slice, func(i, j int) bool {return slice[i][0] > slice[j][0] // 返回true表示i在j之前})
}
导出的表头,可以考虑使用上面 gorm 生成的 struct 部分,通过反射可以获取,核心代码如下:
func GetStructTag(data any) []string {t := reflect.TypeOf(data)var result []stringfor i := 0; i < t.NumField(); i++ {field := t.Field(i)jsonTag := field.Tag.Get("json")//fmt.Printf("Field: %s, Tag: %s\n", field.Name, jsonTag)result = append(result, jsonTag)}return result
}
上面代码传入的 data参数为 model 结构体的 tag 的 json 部分:

如果需要指定导出的表头字段,可以如下定义:
dataKeySlice = [][]string{{"id", "ID"},{"user_id", "用户ID"},{"name", "用户姓名"},{"age", "年龄"},{"address", "地址"},{"create_time", "添加时间"},{"update_time", "修改时间"},
}
dataKeys, dataKeysTitle := excelUtils.GetDataKeyAndTitle(dataKeySlice)// 根据自定义的二维切片,封装导出的表头字段的key和title
func GetDataKeyAndTitle(dataKeySlice [][]string) ([]string, []string) {//自定义导出的字段var dataKeys []stringvar dataKeysTitle []stringif len(dataKeySlice) > 0 { //如果定义了key对应的字段值for _, v := range dataKeySlice {if len(v[1]) > 0 {dataKeysTitle = append(dataKeysTitle, v[1])} else if len(v[0]) > 0 {dataKeysTitle = append(dataKeysTitle, v[0])}if len(v[0]) > 0 {dataKeys = append(dataKeys, v[0])}}}return dataKeys, dataKeysTitle
}导出多个Excel文件后,再对它们进行合并为一个Excel文件:
// 合并一个目录下的所有Excel文件
func MergeExcel(dirPath string, outputFileName string, isDeleteOriginFiles bool) string {dir, err := ioutil.ReadDir(dirPath)if err != nil {fmt.Printf("open dir failed: %s\n", err.Error())}//设置路径,文件夹放在main的同级目录下PathSeperator := string(os.PathSeparator)outputdir := dirPath + "/../" + outputFileName//合并后的文件var new_file *xlsx.Filevar new_sheet *xlsx.Sheetnew_file = xlsx.NewFile()var new_err errornew_sheet, new_err = new_file.AddSheet("Sheet1")for _, fi := range dir {//fmt.Printf("open success: %s\n", Pthdir + PthSep+fi.Name())if new_err != nil {fmt.Printf(new_err.Error())}//读取文件xlFile, err := xlsx.OpenFile(dirPath + PathSeperator + fi.Name())if err != nil {fmt.Printf("open failed: %s\n", err)}for _, sheet := range xlFile.Sheets {//fmt.Printf("Sheet Name: %s\n", sheet.Name)num := 0for _, row := range sheet.Rows {num++//跳过前5行,将后面的行写入新的文件//if(num > 5){new_row := new_sheet.AddRow()//new_row.SetHeightCM(1)for _, cell := range row.Cells {text := cell.String()//fmt.Printf("%s\n", text)new_cell := new_row.AddCell()new_cell.Value = text}//}}}}//写入文件new_err = new_file.Save(outputdir)if new_err != nil {fmt.Printf(new_err.Error())}//是否删除原文件if isDeleteOriginFiles {os.RemoveAll(dirPath)}outputFilePath, _ := filepath.Abs(outputdir)return outputFilePath
}
完整代码参考
代码路径: service/users/userDataExportService.go
package usersimport ("fmt""go-demo-2025/common""go-demo-2025/utils/excelUtils""go-demo-2025/utils/funcUtils""math""os""path/filepath""strconv"
)// 通过反射直接获取结构体中的所有数据字段,并转换为map,再根据key的顺序逐一映射到新的切片
func (ctx *UserService) ExportUserList() {requestKey := common.GetYmdHis() + "_" + common.RandomString(10)count := ctx.GetUserCount()count = 1300 //调试数据//分页查询列表pageSize := 1000 //每页查询多少条pageCount := math.Ceil(float64(count) / float64(pageSize)) //总页数//fmt.Println("总页数:", pageCount)//自定义导出的字段var dataKeySlice [][]string//如果需要导出数据表的所有字段,则注释下面的二维切片dataKeySlice = [][]string{{"id", "ID"},{"user_id", "用户ID"},{"name", "用户姓名"},{"age", "年龄"},{"address", "地址"},{"create_time", "添加时间"},{"update_time", "修改时间"},}dataKeys, dataKeysTitle := excelUtils.GetDataKeyAndTitle(dataKeySlice)for page := 1; page <= int(pageCount); page++ {dataList := ctx.GetUserList(page, pageSize)var excelData [][]stringfor key, item := range dataList {//如果没有定义指定要导出的字段,则获取数据表的所有字段if len(dataKeys) == 0 { //dataKeys切片(model结构体的tag的json部分)dataKeys = funcUtils.GetStructTag(item)}//结构体转为mapitemMap, _ := funcUtils.StructToMap(item, "json")//fmt.Println(itemMap)//os.Exit(1)//按照顺序将map中的数据填充到key的切片中var itemSlice []string//第一列使用key,下一步排序用itemSlice = append(itemSlice, fmt.Sprintf("%03d", key)) //key前面补两个0,要不然反转的时候会按照字符串顺序排序,导致"2>10".这样改后就是"10>02")for _, keys := range dataKeys { //按照dataKeys设定的字段,逐一插入到切片中itemSlice = append(itemSlice, itemMap[keys])}excelData = append(excelData, itemSlice)}funcUtils.ReverseTwoDimSlice(excelData) //倒序排列,必须保证第0个元素是 key 值excelData = funcUtils.DeleteTwoDimSliceFirstChar(excelData) //删除第0个元素(key值)pageDiff := int(pageCount) - page + 1//导出Excel文件_, err1 := excelUtils.WriteExcel(excelData, requestKey, fmt.Sprintf("用户数据导出_page_%s", fmt.Sprintf("%04d", pageDiff)))if err1 != nil {fmt.Println("Write excel error: ", err1)os.Exit(1)}//fmt.Println("Write excel success, file name is: ", fileName)}//导出表头var excelDataTitle [][]stringif len(dataKeysTitle) == 0 {dataKeysTitle = dataKeys}excelDataTitle = append(excelDataTitle, dataKeysTitle)fileName, _ := excelUtils.WriteExcel(excelDataTitle, requestKey, "用户数据导出_page_0000")//合并多个文件为一个absPath, _ := filepath.Abs(fileName) // 获取文件的绝对路径dirPath := filepath.Dir(absPath) //获取文件所在目录的绝对路径//fmt.Println(dirPath)outputFileName := fmt.Sprintf("用户数据导出_%v.xlsx", requestKey)outputFilePath := excelUtils.MergeExcel(dirPath, outputFileName, true)fmt.Println("最终导出的文件:", outputFilePath)
}
入口文件
新增命令行脚本: command/userCmd.go
package commandimport ("fmt""github.com/spf13/cobra""go-demo-2025/service/users""os""time"
)// go run command.go userCmd --operate exportData
func init() {RootCmd.AddCommand(userCmd)
}var userCmd = &cobra.Command{Use: "userCmd",Short: "关于用户相关的命令行操作",Long: ``,Run: func(cmd *cobra.Command, args []string) {fmt.Println("--- userCmd 运行 ---")userCmdRun(args)},
}func userCmdRun(args []string) {if operate == "" {fmt.Println("缺少参数operate")os.Exit(1)}if operate == "createMockData" { //生成mock数据fmt.Println("执行createMockData...")service := users.NewUserService()service.BatchCreateMockData()} else if operate == "exportData" { //导出用户数据fmt.Println("执行exportData...")service := users.NewUserService()startTime := time.Now()service.ExportUserList()endTime := time.Now()timeCost := endTime.Sub(startTime)fmt.Println("总耗时: ", timeCost)} else {fmt.Println("暂未定义此operate的业务逻辑")os.Exit(1)}
}
效果演示
分页导出多个Excel文件
合并多个文件前的效果演示,在合并多个Excel部分的代码暂时终止一下,看看效果。

在项目根目录下执行命令 go run command.go userCmd --operate exportData

生成的文件在:项目根目录下面的 /files/年/月/日/xxx 下面:

其中 用户数据导出_page_0000_xxx 是表头数据:

合并为一个完整的Excel文件
接下来, 去掉刚才的 os.Exit(1) 再试一次直接导出一个完整的Excel文件,还是执行命令 go run command.go userCmd --operate exportData

这次直接合并为多个文件,并且删除之前的多个小文件。

完整代码
源代码:https://gitee.com/rxbook/go-demo-2025
下载后,解压到自定义目录,配置好 Go 环境,创建数据库go-demo-2025,导入 data/go-demo-2025.sql 的SQL语句,复制 conf/application.yml.demo 为 conf/application.yml 修改对应的数据为你自己的数据库连接信息。
- 执行
go run command.go userCmd --operate createMockData生成测试用的mock数据; - 执行
go run command.go userCmd --operate exportData即可导出Excel文件; - 执行
go run quick_start_demo/gin_http_get.go快速入门Gin框架http服务; - 执行
go run main.go启动HTTP服务,进入router/router.go查看具体测试的路由信息。
相关文章:
使用Go语言的gorm框架查询数据库并分页导出到Excel实例
文章目录 基本配置配置文件管理命令行工具: Cobra快速入门基本用法 生成mock数据SQL准备gorm自动生成结构体代码生成mock数据 查询数据导出Excel使用 excelize实现思路完整代码参考 入口文件效果演示分页导出多个Excel文件合并为一个完整的Excel文件 完整代码 基本配置 配置文…...
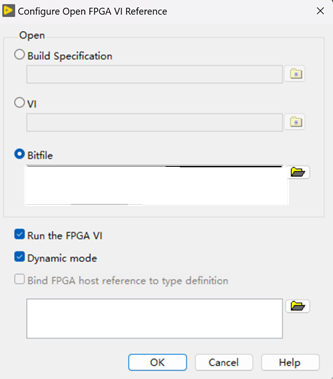
Run the FPGA VI 选项的作用
Run the FPGA VI 选项的作用是决定当主机 VI 运行时,FPGA VI 是否会自动运行。 具体作用: 勾选 “Run the FPGA VI”: 当主机 VI 执行时,如果 FPGA VI 没有正在运行,系统将自动启动并运行该 FPGA VI。 这可以确保 FPG…...

新手入门怎么炒股,新手炒股入门需要做哪些准备?
炒股自动化:申请官方API接口,散户也可以 python炒股自动化(0),申请券商API接口 python炒股自动化(1),量化交易接口区别 Python炒股自动化(2):获取…...

Fetch 与 Axios:JavaScript HTTP 请求库的详细比较
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...

记录一个Ajax发送JSON数据的坑,后端RequestBody接收参数小细节?JSON对象和JSON字符串的区别?
上半部分主要介绍我实际出现的问题,最终下面会有总结。 起因:我想发送post请求的data,但是在浏览器中竟然被搞成了地址栏编码 如图前端发送的ajax请求数据 如图发送的请求体: 很明显是keyvalue这种形式,根本就不是…...

【智能算法应用】长鼻浣熊优化算法求解二维路径规划问题
摘要 本文采用长鼻浣熊优化算法 (Coati Optimization Algorithm, COA) 求解二维路径规划问题。COA 是一种基于长鼻浣熊的觅食和社群行为的智能优化算法,具有快速收敛性和较强的全局搜索能力。通过仿真实验,本文验证了 COA 在复杂环境下的路径规划性能&a…...

微服务中的负载均衡算法与策略深度解析
在微服务架构中,负载均衡是保证系统高可用性和高性能的关键技术。通过合理地将请求分配给多个服务实例,负载均衡策略可以优化资源利用,实现请求的均衡处理。本文将深入探讨微服务中的负载均衡算法及其配置策略,帮助读者更好地理解…...

初知C++:AVL树
文章目录 初知C:AVL树1.AVL树的概念2.AVL树的是实现2.1.AVL树的结构2.2.AVL树的插入2.3.旋转2.4.AVL树的查找2.5.AVL树平衡检测 初知C:AVL树 1.AVL树的概念 • AVL树是最先发明的自平衡⼆叉查找树,AVL是⼀颗空树,或者具备下列性…...

[LeetCode] 67. 二进制求和
题目描述: 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a "11", b "1" 输出:"100" 示例 2: 输入:a "1010", b "…...

工业物联网关-ModbusTCP
Modbus-TCP模式把网关视作Modbus从端设备,主端设备可以通过Modbus-TCP协议访问网关上所有终端设备。用户可以自定义多条通道,每条通道可以配置为TCP Server或者TCP Slave。注意,该模式需要指定采集通道,采集通道可以是串口和网口通…...

子组件向父组件传值$emit
点击子组件的按钮,将子组件的值传递给父组件,并进行提示。 子组件 <template><div><button click"emitIndex">clickme</button></div> </template> <script> export default {methods: {emitInde…...

校车购票微信小程序的设计与实现(lw+演示+源码+运行)
摘 要 由于APP软件在开发以及运营上面所需成本较高,而用户手机需要安装各种APP软件,因此占用用户过多的手机存储空间,导致用户手机运行缓慢,体验度比较差,进而导致用户会卸载非必要的APP,倒逼管理者必须改…...

【Golang】关于Go语言中的定时器原理与实战应用
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

matlab不小心删除怎么撤回
预设项——>删除文件——>移动至临时文件夹 tem临时文件夹下...

云原生、云计算、虚拟化概念概述
(带着批评阅读,不对的请评论区补充) 1、出现年代前后顺序 虚拟化------>云计算------>云原生 2、虚拟化 虚拟化侧重描述实现,最开始的技术是模拟、hook指令执行软件程序,后续出现了半虚拟化、CPU硬件提供虚拟化…...
【Trulens框架】用TruLens 自动化 RAG 应用项目评估测试
前言: 什么是Trulens TruLens是面向神经网络应用的质量评估工具,它可以帮助你使用反馈函数来客观地评估你的基于LLM(语言模型)的应用的质量和效果。反馈函数可以帮助你以编程的方式评估输入、输出和中间结果的质量,从而…...

互联网线上融合上门洗衣洗鞋小程序,让洗衣洗鞋像点外卖一样简单
随着服务创新的风潮,众多商家已巧妙融入预约上门洗鞋新风尚,并携手洗鞋小程序,开辟线上蓝海。那么,这不仅仅是一个小程序,它究竟蕴含着哪些诱人好处呢? 1. 无缝融合,双线共赢:小程序…...

R语言绘制三维散点图
之前我们绘制的属于二维散点图,具有两个维度通常是 x 轴和 y 轴)上展示数据点的分布。只能呈现两个变量之间的关系。而三维散点图则具有三个维度(x 轴、y 轴和 z 轴)上展示数据点的分布。可以同时呈现三个变量之间的关系ÿ…...

2014年国赛高教杯数学建模A题嫦娥三号软着陆轨道设计与控制策略解题全过程文档及程序
2014年国赛高教杯数学建模 A题 嫦娥三号软着陆轨道设计与控制策略 嫦娥三号于2013年12月2日1时30分成功发射,12月6日抵达月球轨道。嫦娥三号在着陆准备轨道上的运行质量为2.4t,其安装在下部的主减速发动机能够产生1500N到7500N的可调节推力,…...

QD1-P25 CSS 背景
本节学习:CSS 背景属性 本节视频 https://www.bilibili.com/video/BV1n64y1U7oj?p25 背景颜色 背景图片 不重复 横向重复 纵向重复 双向重复 背景图片大小 400px 600px 原图大小 显示器宽度不够时&…...

ChatGPT资源宝库:从提示工程到项目实践的完整指南
1. 项目概述:一份关于ChatGPT的“Awesome”清单意味着什么?如果你最近在GitHub上搜索过任何与ChatGPT、AI或提示工程相关的内容,那么你大概率见过一个以“awesome-”开头的仓库。而sindresorhus/awesome-chatgpt无疑是这个领域里最知名、最常…...

NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南
NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡优化工具,专为…...

Linuxbonding链路稳定性治理方法
Linuxbonding链路稳定性治理方法这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限…...

终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼
终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中疯狂上跳的枪口而…...

从零构建本地化AI代码助手:架构、微调与工程实践
1. 项目概述:从零构建你自己的Claude代码助手最近在开发者社区里,一个名为“build-your-claude-code-from-scratch”的项目引起了我的注意。这个标题本身就充满了吸引力——它暗示着一种可能性:我们是否能够不依赖任何现成的、闭源的商业API&…...

本地化AI代码助手LLMDog:模块化框架与开源模型集成实践
1. 项目概述:一个为开发者设计的本地化AI代码助手最近在GitHub上闲逛,发现了一个挺有意思的项目叫“LLMDog”,作者是doganarif。乍一看这个名字,可能会联想到“AI狗”或者某种宠物,但它的全称其实是“Large Language M…...
)
【2026年阿里巴巴集团暑期实习- 5月16日-算法岗-第二题- 坏掉的键盘】(题目+思路+JavaC++Python解析+在线测试)
题目内容 小明准备输入一个仅由小写英文字母组成的字符串,但他的键盘在一开始就有且仅有一个按键失灵,导致该字母在原串中的所有出现都没有被输入,最终得到的字符串为 sss。小明还告诉你:原本要输入的完整字符串中任意相邻两个字符都不相同。 请你计算,对于每一个可能的…...

从二维到三维:DIY LED视频立方体构建全攻略
1. 项目概述:从平面到立体的视觉革命几年前,当我第一次成功点亮一整面由32x32 RGB LED面板组成的视频墙时,那种由1024个像素点共同编织出的动态画面所带来的震撼,至今记忆犹新。但作为一个热衷于将技术推向边界的创作者࿰…...

量子退火与经典优化结合的金融投资组合优化实践
1. 量子退火与经典优化结合的金融投资组合优化实践在金融投资领域,如何构建最优投资组合一直是核心挑战。传统方法如现代投资组合理论(MPT)和均值-方差优化(MVO)虽然奠定了理论基础,但在处理大规模资产配置时往往面临计算效率瓶颈。近年来,量…...

【Clickhouse从入门到精通】第03篇:ClickHouse适用场景深度剖析
上一篇【第02篇】ClickHouse横空出世——天下武功唯快不破 下一篇【第04篇】ClickHouse生态全景与生产实践者巡礼 摘要 技术选型是数据架构设计的核心命题。再优秀的工具,若用错了场景,也会事倍功半。ClickHouse 以"极速分析查询"著称&#x…...