如何将数据从 AWS S3 导入到 Elastic Cloud - 第 1 部分:Elastic Serverless Forwarder
作者:来自 Elastic Hemendra Singh Lodhi

这是多部分博客系列的第一部分,探讨了将数据从 AWS S3 导入 Elastic Cloud 的不同选项。
Elasticsearch 提供了多种从 AWS S3 存储桶导入数据的选项,允许客户根据其特定需求和架构策略选择最合适的方法。
这些是从 AWS S3 导入数据的主要选项:
- Elastic Serverless Forwarder (ESF) - 我们在本博客中的重点
- Elastic Agent - 第 2 部分
- Elastic S3 Native Connector - 第 3 部分
选项比较
| Features | ESF | Elastic Agent | S3 Connector |
|---|---|---|---|
| Logs | ✅ | ✅ | ✅[[^1]] |
| Metrics | ❌ | ✅ | ✅[[^2]] |
| Cost | Medium-Lambda,SQS | Low-EC2,SQS | Low-Elastic Enterprise Search |
| Scaling | Auto - Unlimited | EC2 instance size | Enterprise Search Node size |
| Operation | Low - Monitor Lambda function | High - Manage Agents | Low |
| PrivateLink | ✅ | ✅ | NA (Pull from S3) |
| Primary Use Case | Logs |
注 1:由于 AWS 对可触发 Lambda 函数的服务有限制,并且你无法使用 CloudWatch 指标上的订阅过滤器调用 Lambda,因此 ESF 不支持指标收集。但是,考虑到成本,可以将指标存储在 S3 中,并通过 SQS 触发提取到 Elastic。
注 2:虽然 S3 连接器可以从 S3 存储桶中提取日志和指标,但它最适合提取内容、文件、图像和其他数据类型
在本博客中,我们将重点介绍如何使用 Elastic Serverless Forwarder (ESF) 从 AWS S3 中提取数据。在接下来的部分中,我们将探索 Elastic Agent 和 Elastic S3 Native Connector 方法。
让我们开始吧。
按照以下步骤启动 Elastic Cloud 部署:
Elastic Cloud
1)如果尚未创建,请创建一个帐户,并在 AWS 中创建 Elastic 部署。

2)创建部署后,请记下 Elasticsearch 端点。可以在 Elastic Cloud 控制台的-> Manage -> Deployments 下找到它。

Elastic Serverless Forwarder
Elastic Serverless Forwarder 是一个 AWS Lambda 函数,可将 VPC Flow 日志、WAF、Cloud Trail 等日志从 AWS 环境转发到 Elastic。它可用于将数据发送到 Elastic Cloud 以及进行自我管理部署。
功能
- 支持多个输入
- S3(通过 SQS 事件通知)
- Kinesis 数据流
- CloudWatch Logs 订阅过滤器
- SQS 消息负载
- 使用 “continuing queue” 和 “replay queue”(由无服务器转发器自动创建)至少传递一次
- 支持通过 PrivateLink 进行数据传输,允许在 AWS 虚拟私有云(或 VPC)内而不是在公共网络上传输数据。
- Lambda 函数是一种 AWS 无服务器计算托管服务,可根据代码执行请求自动扩展
- 函数执行时间经过优化,并根据需要分配最佳内存大小
- 按使用量付费定价,只需为 Lambda 函数执行期间的计算时间和 SQS 事件通知付费
数据流
我们将使用 S3 输入和 SQS 通知将 VPC 流日志发送到 Elastic Cloud:

- VPC 流日志配置为写入 S3 存储桶
- 将日志写入 S3 存储桶后,S3 事件通知 (S3:ObjectCreated) 将发送到 SQS
- 包含事件元数据的 SQS 事件通知触发 Lambda 函数,该函数从存储桶中读取日志
- 部署转发器时会创建连续队列(Continuing queue),并确保至少交付一次。转发器会跟踪上次发送的事件,并在转发器函数超过 15 分钟的运行时间(Lambda 最大默认值)时帮助处理待处理事件
- 部署转发器时也会创建重放队列(Replay queue),并处理日志提取异常。转发器会跟踪失败的事件并将其写入重放队列以供以后提取。例如,在我的测试中,我输入了错误的 Elastic API 密钥,导致身份验证失败,从而填满了重放队列。你可以启用重播队列作为 ESF lambda 函数的触发器,以再次使用来自 S3 存储桶的消息。首先解决交付失败很重要;否则消息将在重放队列中累积。你可以永久设置此触发器,但可能需要根据消息失败问题删除/重新启用。要启用触发器,请转到 SQS -> elastic-serverless-forwarder-replay-queue- -> under Lambda triggers -> Configure Lambda function trigger -> Select the ESF lamnda function
设置
1)创建 S3 存储桶 s3-vpc-flow-logs-elastic 来存储 VPC 流日志
AWS Console -> S3 -> Create bucket.。你可以将其他设置保留为默认设置,也可以根据要求进行更改:

复制存储桶 ARN,下一步配置流日志时需要此 ARN:

2)启用 VPC Flow 日志并发送到 S3 bucket s3-vpc-flow-logs-elastic
AWS Console -> VPC -> Select VPC -> Flow logs。保留其他设置或根据要求进行更改:

提供流日志的名称,选择要应用的过滤器、聚合间隔和流日志存储的目标:

完成后,它将如下所示,以 S3 为目的地。今后,通过此 VPC 的所有流量都将存储在存储桶 s3-vpc-flow-logs-elastic 中:

3)创建 SQS 队列
注 1:在与 S3 存储桶相同的区域中创建 SQS 队列
注 2:将可 visiblity timeout 设置为 910 秒,比 AWS Lambda 函数最大运行时间 900 秒多 10 秒。
AWS Console -> Amazon SQS -> Create queue
提供队列名称并将可见性超时更新为 910 秒。Lambda 函数最多运行 900 秒(15 分钟),为可见性超时设置更高的值允许消费者 Elastic Serverless Forwarder(ESF)处理并从队列中删除消息:

更新 SQS 访问策略(高级)以允许 S3 存储桶向 SQS 队列发送通知。将 account-id 替换为你的 AWS 帐户 ID。保留其他选项的默认设置。
在这里,我们指定 S3 从 S3 存储桶向 SQS 队列 (ARN) 发送消息:
{"Version": "2012-10-17","Id": "example-ID","Statement": [{"Sid": "example-statement-ID","Effect": "Allow","Principal": {"Service": "s3.amazonaws.com"},"Action": "SQS:SendMessage","Resource": "arn:aws:sqs:ap-southeast-2:<account-id>:sqs-vpc-flow-logs-elastic-serverless-forwarder","Condition": {"StringEquals": {"aws:SourceAccount": "<account-id>"},"ArnLike": {"aws:SourceArn": "arn:aws:s3:::s3-vpc-flow-logs-elastic"}}}]
}
有关 AWS 集成的权限要求(IAM 用户)的更多详细信息,请参见此处。
在“详细信息”下的队列设置中复制 SQS ARN:

4)在 S3 存储桶中启用 VPC 流日志事件通知
AWS Console > S3. Select bucket s3-vpc-flow-logs-elastic -> Properties and Create event notification
提供名称以及你想要触发 SQS 的事件类型。我们已选择在将任何对象添加到存储桶时创建对象:

选择 destination 为 SQS queue 并选择 sqs-vpc-flow-logs-elastic-serverless-forwarder:

保存后,配置将如下所示:

创建另一个 S3 存储桶来存储 Elastic Serverless Forwarder 的配置文件:

创建一个名为 config.yaml 的文件并使用以下配置进行更新。完整选项集在此处:
inputs:- type: "s3-sqs"id: "arn:aws:sqs:ap-southeast-2:xxxxxxxxxx:sqs-vpc-flow-logs-elastic-serverless-forwarder"outputs:- type: "elasticsearch"args:# either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are includedelasticsearch_url: "https://e286410s58ae4ad6a446c10596ked613.ap-southeast-2.aws.found.io:443"#cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA=="# either api_key or username/password, username/password takes precedence if both are includedapi_key: "LlVqN3Q1RUi3TThuexxxxxxxxxx9RlJRdjniY0JubktEdm9oOUtaNU9mdw=="#username: "username"#password: "password"#es_datastream_name: "aws.vpcflow"es_dead_letter_index: "esf-dead-letter-index" # optionalbatch_max_actions: 500 # optional: default value is 500batch_max_bytes: 10485760 # optional: default value is 10485760
输入类型:s3-sqs。我们使用带有 SQS 通知选项的 S3
输出:
- elasticsearch_url:来自上述 Elastic Cloud 部署创建部分的 elasticsearch 端点
- api_key:使用此处的说明创建 Elasticsearch API 密钥(用户 API 密钥)
- es_datastream_name:转发器支持自动路由 aws.cloudtrail、aws.cloudwatch_logs、aws.elb_logs、aws.firewall_logs、aws.vpcflow 和 aws.waf 日志。对于其他日志类型,你可以将其设置为所需的命名约定。
将其他选项保留为默认值。
将 config.yaml 上传到 s3 存储桶 s3-vpc-flow-logs-serverless-forwarder-config 中:

6)安装 AWS 集成资产
Elastic 集成预先打包了资产,可简化收集、解析、索引和可视化。集成使用具有特定索引命名约定的数据流,这有助于入门。转发器也可以写入任何其他流名称。
按照步骤安装 Elastic AWS 集成。
Kibana -> Management -> Integrations,搜索 AWS:

7)部署 Elastic Serverless Forwarder
有几种方法可以从 SAR(Serverless Application Repository)部署 Elastic Serverless Forwarder:
- 使用 AWS 控制台
- 使用 AWS Cloudformation
- 使用 Terraform
- 直接部署可提供更多自定义选项
我们将使用 AWS 控制台选项来部署 ESF。
注意:直接使用 AWS 控制台时,每个区域只允许部署一次。
AWS Console -> Lambda -> Application -> Create Application,搜索 elastic-serverless-forwarder:

在应用程序设置下提供以下详细信息:
- Application name -
elastic-serverless-forwarder - ElasticServerlessForwarderS3Buckets -
s3-vpc-flow-logs-elastic - ElasticServerlessForwarderS3ConfigFile -
s3://s3-vpc-flow-logs-serverless-forwarder-config/config.yaml - ElasticServerlessForwarderS3SQSEvent -
arn:aws:sqs:ap-southeast-2:xxxxxxxxxxx:sqs-vpc-flow-logs-elastic-serverless-forwarder

部署成功后,Lambda 部署的状态应为 “Create Complete”:

以下是成功部署 ESF 后自动创建的 SQS 队列:

一切设置正确后,S3 存储桶 s3-vpc-flow-logs-elastic 中发布的流日志将向 SQS 发送通知,你将看到队列 sqs-vpc-flow-logs-elastic-serverless-forwarder 中可供 ESF 使用的消息。
如果出现诸如 SQS 消息数持续增加等问题,请检查 Lambda 执行日志 Lambda -> Application -> serverlessrepo-elastic-serverless-forwarder-ElasticServerlessForwarderApplication* -> Monitoring -> Cloudwatch Log Insights。单击 LogStream 获取详细信息:

有关故障排除的更多信息,请参见此处。
8)在 Kibana Discover 和仪表板中验证 VPC 流日志
Kibana -> Discover 。这将显示 VPC 流日志:

Kibana -> Dashboards。查找 VPC VPC Flow log Overview 表板:

更多仪表板!
如前所述,除了其他资产外,AWS 集成还提供预构建的仪表板。我们可以使用 Elastic 代理提取方法监控我们设置中涉及的 AWS 服务,我们将在本系列的第 2 部分中介绍该方法。这将有助于跟踪使用情况并有助于优化。
结论
Elasticsearch 提供了多种选项来将数据从 AWS S3 同步到 Elasticsearch 部署中。在本演练中,我们证明了实现 Elastic Serverless Forwarder (ESF) 提取选项以从 AWS S3 提取数据并利用 Elastic 业界领先的搜索和分析功能相对容易。
在本系列的第 2 部分中,我们将深入研究使用 Elastic Agent 作为提取 AWS S3 数据的另一种选择。
你可以使用来自任何来源的数据构建搜索。查看此网络研讨会以了解 Elasticsearch 支持的不同连接器和来源。
准备好自己尝试一下了吗?开始免费试用。
原文:https://www.elastic.co/search-labs/blog/ingest-aws-s3-data-elastic-cloud-elastic-serverless-forwarder
相关文章:
如何将数据从 AWS S3 导入到 Elastic Cloud - 第 1 部分:Elastic Serverless Forwarder
作者:来自 Elastic Hemendra Singh Lodhi 这是多部分博客系列的第一部分,探讨了将数据从 AWS S3 导入 Elastic Cloud 的不同选项。 Elasticsearch 提供了多种从 AWS S3 存储桶导入数据的选项,允许客户根据其特定需求和架构策略选择最合适的方…...

Linux基础-正则表达式
正则表达式概述 正则表达式是处理字符串的一种工具,可以用于查找、删除、替换特定的字符串,主要用于文件内容的处理。与之不同的是,通配符则用于文件名称的匹配。正则表达式通过使用特殊符号,帮助用户轻松实现对文本的操作。 一…...

【HTML格式PPT离线到本地浏览】
文章目录 概要实现细节小结 概要 最近在上课时总是出现网络不稳定导致的PPT无法浏览的情况出现,就想到下载到电脑上。但是PPT是一个HTML的网页,无法通过保存网页(右键另存为mhtml只能保存当前页)的形式全部下载下来,试…...

如何在Vue项目中封装axios
文章目录 一、axios简介基本使用 二、封装axios的原因三、封装axios的方法1. 设置接口请求前缀2. 设置请求头和超时时间3. 封装请求方法4. 添加请求拦截器5. 添加响应拦截器小结 一、axios简介 axios 是一个基于 XMLHttpRequest 的轻量级HTTP客户端,适用于浏览器和…...

linux 配置ssh免密登录
一、 cd /root/.ssh/ #不存在就创建mkdir /root/.ssh ssh-keygen #连续按4个回车 ll二、将公钥发送到目标服务器下 #公钥上传到目标服务器 ssh-copy-id root192.168.31.142 #回车完也是要输入密码的 #测试一下免密登录: ssh root192.168.31.142 成功...

【AI绘画】Midjourney进阶:三分线构图详解
博客主页: [小ᶻZ࿆] 本文专栏: AI绘画 | Midjourney 文章目录 💯前言💯什么是构图为什么Midjourney要使用构图 💯三分线构图特点使用场景提示词书写技巧测试 💯小结 💯前言 【AI绘画】Midjourney进阶&a…...
)
享元模式(C++)
定义:享元模式是一种结构型设计模式,它使用共享对象,用以尽可能减少内存使用和提高性能。享元模式通过共享已经存在的对象实例,而不是每次需要时都创建新对象实例,从而避免大量重复对象的开销。 对比: 与单…...

开发一个UniApp需要多长时间
开发一个UniApp所需的时间因项目的规模、复杂度、开发团队的经验水平以及开发过程中的需求变更等多种因素而异。因此,很难给出一个确切的时间范围。然而,我们可以从以下几个方面来大致估算开发时间: 项目规划与需求分析: 在项目开…...

服务器源IP暴露后的安全风险及防御措施
在互联网安全领域,服务器的源IP地址泄露可能成为黑客攻击的切入点。本文将列举十种常见的攻击类型,并提供相应的防御建议,帮助管理员们更好地保护服务器免受潜在威胁。 一、引言 服务器源IP地址的暴露意味着攻击者可以直接针对服务器发起攻击…...

YoloV8改进策略:BackBone改进|CAFormer在YoloV8中的创新应用,显著提升目标检测性能
摘要 在目标检测领域,模型性能的提升一直是研究者和开发者们关注的重点。近期,我们尝试将CAFormer模块引入YoloV8模型中,以替换其原有的主干网络,这一创新性的改进带来了显著的性能提升。 CAFormer,作为MetaFormer框架下的一个变体,结合了深度可分离卷积和普通自注意力…...

网络编程(19)——C++使用asio协程实现并发服务器
十九、day19 上一节学习了如果通过asio协程实现一个简单的并发服务器demo(官方案例),今天学习如何通过asio协程搭建一个比较完整的并发服务器。 主要实现了AsioIOServicePool线程池、逻辑层LogicSystem、粘包处理、接收协程、发送队列、网络…...

【SQL】深入了解 SQL 索引:数据库性能优化的利器
目录 引言1. 什么是 SQL 索引?1.1 索引的基本概念1.2 索引的优缺点 2. 索引的工作原理2.1 B 树索引2.2 哈希索引2.3 全文索引 3. 索引创建方式3.1 单列索引示意图3.2 复合索引示意图3.3 唯一索引示意图 4. 如何创建索引4.1 创建单列索引4.2 创建唯一索引4.3 创建全文…...

河道垃圾数据集 水污染数据集——无人机视角数据集 共3000张图片,可直接用于河道垃圾、水污染功能检测 已标注yolo格式、voc格式,可直接训练;
河道垃圾数据集 水污染数据集——无人机视角数据集 共3000张图片,可直接用于河道垃圾、水污染功能检测 已标注yolo格式、voc格式,可直接训练; 河道垃圾与水污染检测数据集(无人机视角) 项目概述 本数据集是一个专门用…...

[棋牌源码] 2023情怀棋牌全套源代码含多套大厅UI及600+子游源码下载
降维打击带来的优势 这种架构不仅极大提升了运营效率,还降低了多端维护的复杂性和成本。运营商无需投入大量资源维护多套代码,即可实现产品的全终端覆盖和快速更新,这就是产品层面的降维打击。 丰富的游戏内容与多样化大厅风格 类型&#…...
详解)
深度学习:预训练模型(基础模型)详解
预训练模型(基础模型)详解 预训练模型(有时也称为基础模型或基准模型)是机器学习和深度学习领域中一个非常重要的概念,特别是在自然语言处理(NLP)、计算机视觉等领域。这些模型通过在大规模数据…...

欧科云链研究院深掘链上数据:洞察未来Web3的隐秘价值
目前链上数据正处于迈向下一个爆发的重要时刻。 随着Web3行业发展,公链数量呈现爆发式的增长,链上积聚的财富效应,特别是由行业热点话题引领的链上交互行为爆发式增长带来了巨量的链上数据,这些数据构筑了一个行为透明但与物理世…...
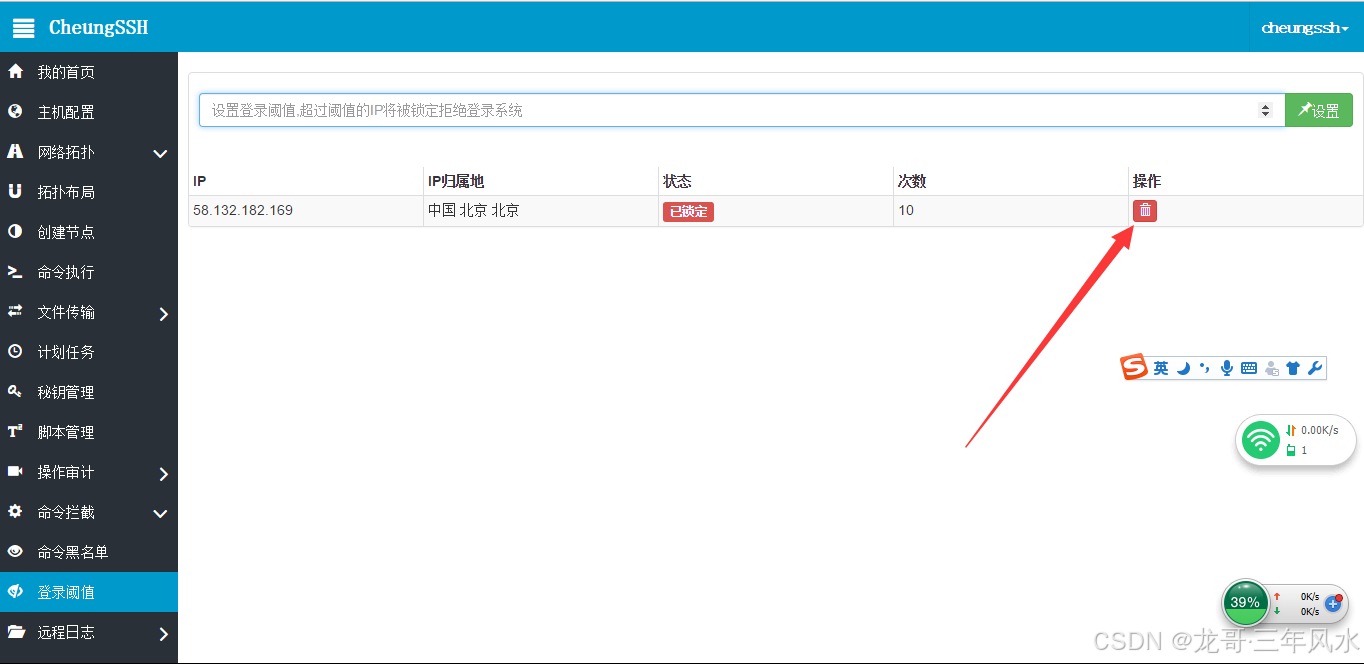
国外电商系统开发-运维系统登录阈值
为了登录安全,在登录验证的时候,如果一个IP连续登录的次数超过5次,那么系统则会拒绝这个IP的所有登录,而不管密码是否正确,就像是银行卡一样。 设置登录阈值: 注意:如果您的IP不幸被系统锁定&am…...

设备台账管理是什么
设备管理对企业至关重要。比如在电子加工企业,高效的设备管理能减少设备故障,提升生产效率,为企业赢得市场竞争优势。设备台账管理作为设备管理的一个核心部分,起着重要的作用。 让我们一起从本篇文章中探索设备台账管理是什么&a…...

操作教程|基于DataEase用RFM分析法分析零售交易数据
DataEase开源BI工具可以在店铺运营的数据分析及可视化方面提供非常大的帮助。同样,在用于客户评估的RFM(即Recency、Frequency和Monetary的简称)分析中,DataEase也可以发挥出积极的价值,通过数据可视化大屏的方式实时展…...

使用Go语言的gorm框架查询数据库并分页导出到Excel实例
文章目录 基本配置配置文件管理命令行工具: Cobra快速入门基本用法 生成mock数据SQL准备gorm自动生成结构体代码生成mock数据 查询数据导出Excel使用 excelize实现思路完整代码参考 入口文件效果演示分页导出多个Excel文件合并为一个完整的Excel文件 完整代码 基本配置 配置文…...

HunyuanVideo-Foley环境音生成挑战赛:最佳提示词与生成作品赏析
HunyuanVideo-Foley环境音生成挑战赛:最佳提示词与生成作品赏析 1. 挑战赛背景与规则 最近,一场以"城市夜晚"为主题的HunyuanVideo-Foley环境音生成挑战赛吸引了众多音频创作者参与。这场赛事要求参赛者使用HunyuanVideo-Foley系统ÿ…...

如何评价目前主流的AI论文生成软件?哪一款最好用?
目前主流 AI 论文工具已形成清晰的中文全流程、英文国际、文献 / 润色专项三大阵营,PaperRed、毕业之家是中文论文全流程首选,ChatGPT-4o、Claude 3.7适合英文与深度逻辑,Kimi、Elicit专攻文献处理。没有绝对 “最好”,只有最适配…...

别再傻傻分不清!Word里‘分页符’和‘分节符’到底怎么用?一个表格横竖混排的实战案例讲透
别再傻傻分不清!Word里‘分页符’和‘分节符’到底怎么用?一个表格横竖混排的实战案例讲透 每次做季度报告时,最让我头疼的就是那些超宽的表格——明明数据很重要,却因为页面宽度不够,硬生生被挤成密密麻麻的小字&…...
)
FPGA开发实战——常见错误排查与优化技巧(持续更新)
1. Vivado仿真与PR Flow冲突问题实战解析 第一次用Vivado做PR(Partial Reconfiguration)项目时,我兴冲冲地点开仿真按钮,结果弹出一个让人崩溃的报错:"ERROR [Common 17-69] Command failed. Simulation for PR F…...

Qwen-Image-2512-SDNQ使用心得:如何写出更有效的中文Prompt获得理想图片
Qwen-Image-2512-SDNQ使用心得:如何写出更有效的中文Prompt获得理想图片 1. 为什么中文Prompt需要特别优化? 在AI绘画领域,Prompt(提示词)的质量直接影响生成结果。对于中文用户而言,使用母语描述想象中的…...

Nunchaku-FLUX.1-dev镜像安全加固:非root运行/最小权限/网络策略限制
Nunchaku-FLUX.1-dev镜像安全加固:非root运行/最小权限/网络策略限制 1. 为什么需要安全加固? 当你把Nunchaku-FLUX.1-dev这个强大的文生图模型部署在自己的服务器上时,可能更多关注的是它能生成多么精美的图片,或者处理中文提示…...
 failed错误(含GitHub镜像加速))
手把手教你解决winget的InternetOpenUrl() failed错误(含GitHub镜像加速)
深度解析winget的InternetOpenUrl() failed错误及高效解决方案 当你满怀期待地打开终端,准备用winget快速安装一个开发工具时,突然跳出的"InternetOpenUrl() failed. 0x80072efd"错误提示无疑是一盆冷水。这个看似简单的网络连接问题背后&…...

Tesla Dashcam:3步搞定特斯拉行车记录视频合并的专业工具
Tesla Dashcam:3步搞定特斯拉行车记录视频合并的专业工具 【免费下载链接】tesla_dashcam Convert Tesla dash cam movie files into one movie 项目地址: https://gitcode.com/gh_mirrors/te/tesla_dashcam 还在为特斯拉行车记录仪生成的零散视频文件而烦恼…...

Wan2.2-I2V-A14B镜像应用案例:快速生成高质量短视频,助力内容创作
Wan2.2-I2V-A14B镜像应用案例:快速生成高质量短视频,助力内容创作 1. 引言:短视频创作的新范式 在数字内容爆炸式增长的今天,短视频已成为最主流的内容形式之一。无论是电商平台的商品展示、社交媒体上的创意内容,还…...

**用Python打造高保真语音合成系统:从原理到实战部署**在人工智能飞速发展的今天,语音合成(TTS,Text-to-Speech
用Python打造高保真语音合成系统:从原理到实战部署 在人工智能飞速发展的今天,语音合成(TTS, Text-to-Speech)已不再是实验室里的“玩具”,而是广泛应用于智能客服、有声读物、无障碍交互等多个场景的核心技术。本文将…...