河道垃圾数据集 水污染数据集——无人机视角数据集 共3000张图片,可直接用于河道垃圾、水污染功能检测 已标注yolo格式、voc格式,可直接训练;

河道垃圾数据集 水污染数据集——无人机视角数据集 共3000张图片,可直接用于河道垃圾、水污染功能检测 已标注yolo格式、voc格式,可直接训练;


河道垃圾与水污染检测数据集(无人机视角)
项目概述
本数据集是一个专门用于河道垃圾和水污染检测的数据集,包含3000张由无人机拍摄的图像。这些图像经过人工检查并标注,确保了标注的质量。数据集提供了YOLO格式和VOC格式的标注文件,可以直接用于训练深度学习模型,以实现对河道中的水污染、漂浮物、废弃船、捕鱼养殖设施以及废弃物的自动检测。
数据集特点
- 高质量标注:所有标注数据至少经过一次人工检查,确保标注质量。
- 多样化类别:涵盖五类常见的河道污染物和设施。
- 多用途:适用于多种目标检测任务,特别是涉及河道管理和环境保护的应用。
- 易于使用:提供了详细的说明文档和预处理好的标注文件,方便用户快速上手。
- 无人机视角:所有图像均从无人机视角拍摄,具有较高的分辨率和广角视野。
数据集结构
River_Pollution_Dataset/
├── images/ # 图像文件夹
│ ├── train/ # 训练集图像
│ ├── val/ # 验证集图像
│ └── test/ # 测试集图像
├── labels/ # 标注文件夹
│ ├── train/ # 训练集标注 (YOLO 和 VOC 格式)
│ ├── val/ # 验证集标注 (YOLO 和 VOC 格式)
│ └── test/ # 测试集标注 (YOLO 和 VOC 格式)
├── README.md # 项目说明文档
└── data.yaml # 数据集配置文件数据集内容
- 总数据量:3000张图像。
- 标注格式:YOLO格式和VOC格式。
- 标注对象:各类河道污染物和设施的位置。
- 类别及数量:
| 类别名 | 标注个数 |
|---|---|
| 水污染 (Water Pollution) | 488 |
| 漂浮物 (Floating Debris) | 5495 |
| 废弃船 (Abandoned Boats) | 1215 |
| 捕鱼养殖 (Fishing and Aquaculture) | 710 |
| 废弃物 (Waste) | 156 |
- 总计:
- 图像总数:3000张
- 标注总数:7064个
- 总类别数 (nc):5类
使用说明
-
环境准备:
- 确保安装了Python及其相关库(如
torch、opencv-python、matplotlib等)。 - 下载并解压数据集到本地目录。
- 安装YOLOv5所需的依赖项: bash
深色版本
git clone https://github.com/ultralytics/yolov5 cd yolov5 pip install -r requirements.txt
- 确保安装了Python及其相关库(如
-
加载数据集:
- 可以使用常见的编程语言(如Python)来加载和处理数据集。
- 示例代码如下:
import os
import json
import pandas as pd
from pathlib import Path
from yolov5.utils.datasets import LoadImages, LoadImagesAndLabels
from yolov5.models.experimental import attempt_load
from yolov5.utils.general import non_max_suppression, scale_coords
from yolov5.utils.torch_utils import select_device
import cv2
import numpy as np# 定义数据集路径
dataset_path = 'River_Pollution_Dataset'# 加载图像和标注
def load_dataset(folder):images_folder = os.path.join(dataset_path, 'images', folder)labels_folder = os.path.join(dataset_path, 'labels', folder)dataset = []for image_file in os.listdir(images_folder):if image_file.endswith('.jpg') or image_file.endswith('.png'):image_path = os.path.join(images_folder, image_file)label_path = os.path.join(labels_folder, image_file.replace('.jpg', '.txt').replace('.png', '.txt'))with open(label_path, 'r') as f:labels = [line.strip().split() for line in f.readlines()]dataset.append({'image_path': image_path,'labels': labels})return dataset# 示例:加载训练集
train_dataset = load_dataset('train')
print(f"Number of training images: {len(train_dataset)}")- 模型训练:
- 使用预训练的YOLOv5模型进行微调,或者从头开始训练。
- 示例代码如下:
# 设置设备
device = select_device('')# 加载预训练模型或从头开始训练
model = attempt_load('yolov5s.pt', map_location=device) # 或者 'path/to/custom_model.pt'
model.train()# 数据集配置文件
data_yaml = 'River_Pollution_Dataset/data.yaml'# 训练参数
hyp = 'yolov5/data/hyps/hyp.scratch.yaml' # 超参数配置文件
epochs = 100
batch_size = 16
img_size = 640# 开始训练
%cd yolov5
!python train.py --img {img_size} --batch {batch_size} --epochs {epochs} --data {data_yaml} --weights yolov5s.pt- 模型推理:
- 使用训练好的模型进行推理,并在图像上绘制检测结果。
- 示例代码如下:
python
深色版本
def detect(image_path, model, device, img_size=640):img0 = cv2.imread(image_path)img = letterbox(img0, new_shape=img_size)[0]img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416img = np.ascontiguousarray(img)img = torch.from_numpy(img).to(device)img = img.half() if half else img.float() # uint8 to fp16/32img /= 255.0 # 0 - 255 to 0.0 - 1.0if img.ndimension() == 3:img = img.unsqueeze(0)# 推理with torch.no_grad():pred = model(img, augment=False)[0]# NMSpred = non_max_suppression(pred, 0.4, 0.5, classes=None, agnostic=False)for i, det in enumerate(pred): # 每个图像的检测结果if det is not None and len(det):det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()for *xyxy, conf, cls in reversed(det):label = f'{model.names[int(cls)]} {conf:.2f}'plot_one_box(xyxy, img0, label=label, color=(0, 255, 0), line_thickness=3)return img0# 示例:检测单张图像
result_img = detect('path/to/image.jpg', model, device)
cv2.imshow('Detection Result', result_img)
cv2.waitKey(0)
cv2.destroyAllWindows()- 性能评估:
- 使用测试集进行性能评估,计算mAP、召回率、精确率等指标。
- 可以使用YOLOv5自带的评估脚本: bash
深色版本
python val.py --data River_Pollution_Dataset/data.yaml --weights best.pt --img 640
注意事项
- 数据格式:确保图像文件和标注文件的命名一致,以便正确匹配。
- 硬件要求:建议使用GPU进行训练和推理,以加快处理速度。如果没有足够的计算资源,可以考虑使用云服务提供商的GPU实例。
- 超参数调整:根据实际情况调整网络架构、学习率、批次大小等超参数,以获得更好的性能。
应用场景
- 河道管理:自动检测河道中的污染物和设施,帮助管理部门及时清理和维护。
- 环境保护:监测河流水质和污染情况,支持环保部门制定治理措施。
- 智能监控:结合无人机巡检系统,实现对河道的实时监控和预警。
- 科研教育:用于水污染研究和教学,提高公众对环境保护的认识。
希望这个数据集能帮助你更好地理解和应用深度学习技术在河道垃圾和水污染检测中的应用。
相关文章:
河道垃圾数据集 水污染数据集——无人机视角数据集 共3000张图片,可直接用于河道垃圾、水污染功能检测 已标注yolo格式、voc格式,可直接训练;
河道垃圾数据集 水污染数据集——无人机视角数据集 共3000张图片,可直接用于河道垃圾、水污染功能检测 已标注yolo格式、voc格式,可直接训练; 河道垃圾与水污染检测数据集(无人机视角) 项目概述 本数据集是一个专门用…...

[棋牌源码] 2023情怀棋牌全套源代码含多套大厅UI及600+子游源码下载
降维打击带来的优势 这种架构不仅极大提升了运营效率,还降低了多端维护的复杂性和成本。运营商无需投入大量资源维护多套代码,即可实现产品的全终端覆盖和快速更新,这就是产品层面的降维打击。 丰富的游戏内容与多样化大厅风格 类型&#…...
详解)
深度学习:预训练模型(基础模型)详解
预训练模型(基础模型)详解 预训练模型(有时也称为基础模型或基准模型)是机器学习和深度学习领域中一个非常重要的概念,特别是在自然语言处理(NLP)、计算机视觉等领域。这些模型通过在大规模数据…...

欧科云链研究院深掘链上数据:洞察未来Web3的隐秘价值
目前链上数据正处于迈向下一个爆发的重要时刻。 随着Web3行业发展,公链数量呈现爆发式的增长,链上积聚的财富效应,特别是由行业热点话题引领的链上交互行为爆发式增长带来了巨量的链上数据,这些数据构筑了一个行为透明但与物理世…...
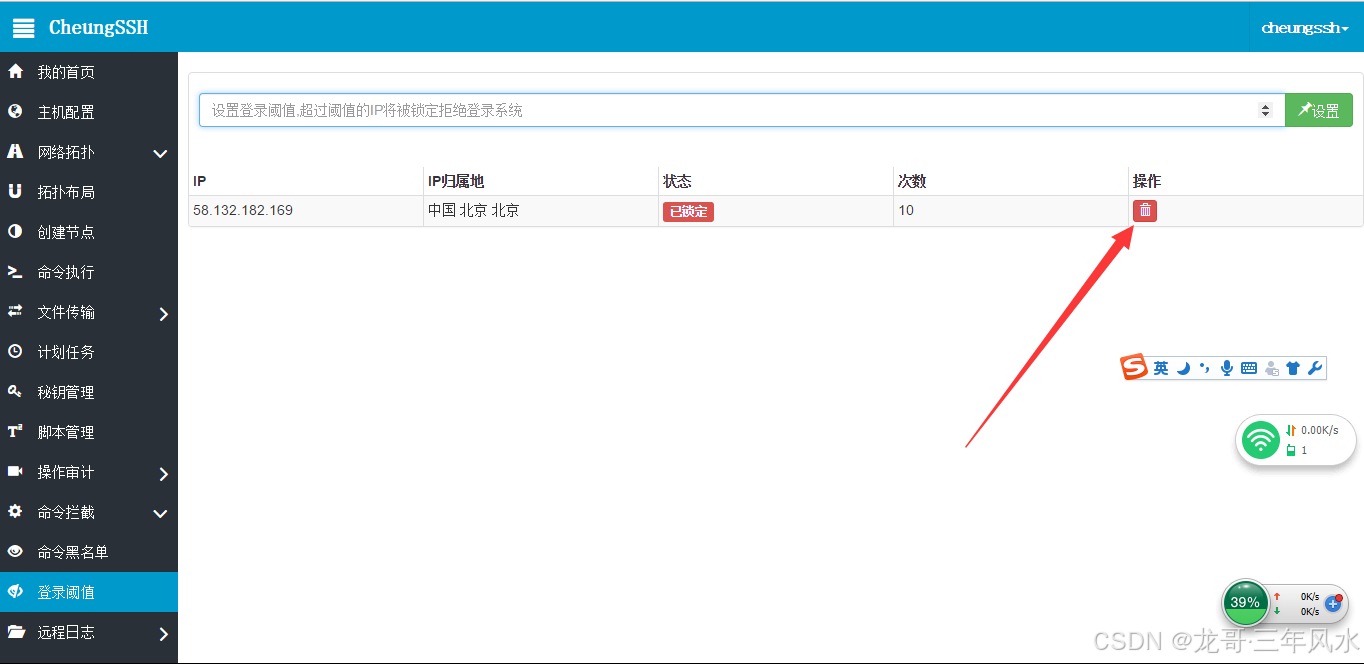
国外电商系统开发-运维系统登录阈值
为了登录安全,在登录验证的时候,如果一个IP连续登录的次数超过5次,那么系统则会拒绝这个IP的所有登录,而不管密码是否正确,就像是银行卡一样。 设置登录阈值: 注意:如果您的IP不幸被系统锁定&am…...

设备台账管理是什么
设备管理对企业至关重要。比如在电子加工企业,高效的设备管理能减少设备故障,提升生产效率,为企业赢得市场竞争优势。设备台账管理作为设备管理的一个核心部分,起着重要的作用。 让我们一起从本篇文章中探索设备台账管理是什么&a…...

操作教程|基于DataEase用RFM分析法分析零售交易数据
DataEase开源BI工具可以在店铺运营的数据分析及可视化方面提供非常大的帮助。同样,在用于客户评估的RFM(即Recency、Frequency和Monetary的简称)分析中,DataEase也可以发挥出积极的价值,通过数据可视化大屏的方式实时展…...

使用Go语言的gorm框架查询数据库并分页导出到Excel实例
文章目录 基本配置配置文件管理命令行工具: Cobra快速入门基本用法 生成mock数据SQL准备gorm自动生成结构体代码生成mock数据 查询数据导出Excel使用 excelize实现思路完整代码参考 入口文件效果演示分页导出多个Excel文件合并为一个完整的Excel文件 完整代码 基本配置 配置文…...
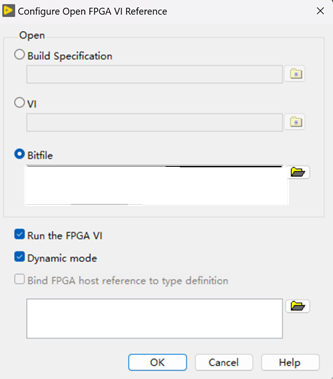
Run the FPGA VI 选项的作用
Run the FPGA VI 选项的作用是决定当主机 VI 运行时,FPGA VI 是否会自动运行。 具体作用: 勾选 “Run the FPGA VI”: 当主机 VI 执行时,如果 FPGA VI 没有正在运行,系统将自动启动并运行该 FPGA VI。 这可以确保 FPG…...

新手入门怎么炒股,新手炒股入门需要做哪些准备?
炒股自动化:申请官方API接口,散户也可以 python炒股自动化(0),申请券商API接口 python炒股自动化(1),量化交易接口区别 Python炒股自动化(2):获取…...

Fetch 与 Axios:JavaScript HTTP 请求库的详细比较
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...

记录一个Ajax发送JSON数据的坑,后端RequestBody接收参数小细节?JSON对象和JSON字符串的区别?
上半部分主要介绍我实际出现的问题,最终下面会有总结。 起因:我想发送post请求的data,但是在浏览器中竟然被搞成了地址栏编码 如图前端发送的ajax请求数据 如图发送的请求体: 很明显是keyvalue这种形式,根本就不是…...

【智能算法应用】长鼻浣熊优化算法求解二维路径规划问题
摘要 本文采用长鼻浣熊优化算法 (Coati Optimization Algorithm, COA) 求解二维路径规划问题。COA 是一种基于长鼻浣熊的觅食和社群行为的智能优化算法,具有快速收敛性和较强的全局搜索能力。通过仿真实验,本文验证了 COA 在复杂环境下的路径规划性能&a…...

微服务中的负载均衡算法与策略深度解析
在微服务架构中,负载均衡是保证系统高可用性和高性能的关键技术。通过合理地将请求分配给多个服务实例,负载均衡策略可以优化资源利用,实现请求的均衡处理。本文将深入探讨微服务中的负载均衡算法及其配置策略,帮助读者更好地理解…...

初知C++:AVL树
文章目录 初知C:AVL树1.AVL树的概念2.AVL树的是实现2.1.AVL树的结构2.2.AVL树的插入2.3.旋转2.4.AVL树的查找2.5.AVL树平衡检测 初知C:AVL树 1.AVL树的概念 • AVL树是最先发明的自平衡⼆叉查找树,AVL是⼀颗空树,或者具备下列性…...

[LeetCode] 67. 二进制求和
题目描述: 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a "11", b "1" 输出:"100" 示例 2: 输入:a "1010", b "…...

工业物联网关-ModbusTCP
Modbus-TCP模式把网关视作Modbus从端设备,主端设备可以通过Modbus-TCP协议访问网关上所有终端设备。用户可以自定义多条通道,每条通道可以配置为TCP Server或者TCP Slave。注意,该模式需要指定采集通道,采集通道可以是串口和网口通…...

子组件向父组件传值$emit
点击子组件的按钮,将子组件的值传递给父组件,并进行提示。 子组件 <template><div><button click"emitIndex">clickme</button></div> </template> <script> export default {methods: {emitInde…...

校车购票微信小程序的设计与实现(lw+演示+源码+运行)
摘 要 由于APP软件在开发以及运营上面所需成本较高,而用户手机需要安装各种APP软件,因此占用用户过多的手机存储空间,导致用户手机运行缓慢,体验度比较差,进而导致用户会卸载非必要的APP,倒逼管理者必须改…...

【Golang】关于Go语言中的定时器原理与实战应用
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

Python try...except ImportError 语句详解
在Python编程中,ImportError 是与模块导入相关的核心异常。优雅地处理它,是编写健壮、可维护和跨平台代码的关键。try...except ImportError 结构正是实现这一目标的标准工具。本文将为你抽丝剥茧,从基础概念到高级实践,全面解析这…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...

Ruby LLM框架:为Ruby开发者打造的大语言模型应用开发工具包
1. 项目概述:一个为Ruby语言量身打造的LLM应用框架如果你是一名Ruby开发者,最近被各种大语言模型(LLM)的应用搞得心痒痒,但看着满世界的Python库和框架感到无从下手,那么crmne/ruby_llm这个项目可能就是你在…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

桌面CNC木质游戏手柄外壳制作:从Fusion 360设计到实战加工全流程
1. 项目概述:从数字模型到木质手柄的旅程如果你和我一样,既痴迷于复古游戏的怀旧情怀,又享受亲手将数字设计变为实体物件的成就感,那么这个项目绝对能点燃你的热情。我们这次要做的,不是一个简单的3D打印外壳ÿ…...

LoRA模型合并实战:多技能大模型融合指南与vLLM+Copaw工具链解析
1. 项目概述:LoRA模型合并的“瑞士军刀” 在AIGC(人工智能生成内容)领域,模型微调是让大语言模型(LLM)或扩散模型适配特定任务、风格或知识库的核心手段。而LoRA(Low-Rank Adaptation࿰…...