深入理解 Parquet 文件格式
深入理解 Parquet 文件格式
- 深入理解 Parquet 文件格式
- 一、引言
- 二、为什么采用 Parquet 格式
- 1. 行式存储的局限性
- 2. 列式存储的优势
- 三、Parquet 的工作原理
- 1. 文件结构
- 2. 列块和页面
- 3. 编码和压缩
- 四、具体数据实例
- 1. 数据示例
- 2. 行式存储 vs 列式存储
- 3. 查询性能对比
- 4. 压缩效果对比
- 五、Parquet 的高级特性
- 1. 列的元数据
- 2. 支持复杂数据类型
- 3. 与大数据生态系统的集成
- 六、如何在 Python 中使用 Parquet
- 1. 安装依赖库
- 2. 写入 Parquet 文件
- 3. 读取 Parquet 文件
- 4. 使用 pyarrow 直接操作 Parquet
- 5. 优化读取性能
- 七、Parquet 格式为了解决什么问题而生
深入理解 Parquet 文件格式
一、引言
随着大数据技术的发展,数据的存储和处理方式也在不断演进。传统的行式存储格式(如 CSV、JSON)在处理大规模数据时效率较低,无法满足现代数据分析的需求。为了解决这些问题,Parquet 作为一种高效的列式存储格式应运而生。本文将深入解析 Parquet 格式,探讨其设计初衷、解决的问题,并通过具体的数据实例和表格来阐述其优势。
二、为什么采用 Parquet 格式
1. 行式存储的局限性
行式存储将数据按行存储,每一行包含所有的列字段。这种存储方式在以下场景中存在问题:
- 读取效率低:当只需要查询部分列的数据时,仍然需要扫描整个行,导致不必要的 I/O 开销。
- 压缩效果差:不同类型的数据混合在一起,难以实现高效的压缩算法。
- 数据类型不一致:同一列的数据类型可能不一致,增加了数据处理的复杂性。
2. 列式存储的优势
列式存储将同一列的数据存储在一起,具有以下优势:
- 高效的列读取:只需读取所需的列,减少了磁盘 I/O,提高了查询性能。
- 优秀的压缩率:同一列的数据类型和取值范围相似,更容易进行高效压缩。
- 矢量化处理:便于 CPU 的指令级并行和矢量化计算,提高了处理速度。
因此,Parquet 格式采用列式存储方式,旨在解决行式存储的局限性,提升大数据处理的效率。
三、Parquet 的工作原理
1. 文件结构
Parquet 文件由以下三个主要部分组成:
- 文件头(Header):包含魔数(Magic Number)和格式版本信息。
- 数据块(Row Group):实际存储数据的地方,每个数据块包含一定数量的行。
- 文件尾(Footer):包含元数据,如列的统计信息、索引等,便于快速定位数据。
2. 列块和页面
在数据块(Row Group)中,数据按照列存储,每一列被称为列块(Column Chunk),进一步细分为多个页面(Page),便于数据的读取和缓存。
3. 编码和压缩
Parquet 支持多种编码和压缩算法:
- 编码方式:如变长整数编码、位包编码(Bit-Packing)、运行长度编码(RLE)等。
- 压缩算法:如 Snappy、GZIP、LZO 等。
这些技术结合,使得 Parquet 在保持高效读取的同时,显著减少了存储空间。
四、具体数据实例
1. 数据示例
假设有一个员工信息的数据集:
| 员工ID | 姓名 | 年龄 | 部门 |
|---|---|---|---|
| 1 | 张三 | 28 | 市场部 |
| 2 | 李四 | 35 | 技术部 |
| 3 | 王五 | 42 | 财务部 |
| 4 | 赵六 | 29 | 人事部 |
2. 行式存储 vs 列式存储
行式存储(如 CSV 格式):
1,张三,28,市场部
2,李四,35,技术部
3,王五,42,财务部
4,赵六,29,人事部
列式存储(Parquet 格式):
- 员工ID列:[1, 2, 3, 4]
- 姓名列:[张三, 李四, 王五, 赵六]
- 年龄列:[28, 35, 42, 29]
- 部门列:[市场部, 技术部, 财务部, 人事部]
3. 查询性能对比
查询场景:统计所有员工的年龄平均值。
- 行式存储:需要读取每一行的所有字段,然后提取年龄列,I/O 开销大。
- 列式存储:只需读取年龄列的数据,I/O 开销小,速度快。
4. 压缩效果对比
由于列式存储的同一列数据类型相同,取值范围集中,可以采用更高效的压缩算法。
-
年龄列(数值型):可以使用位包编码(Bit-Packing),这种编码方式通过将数据按位压缩来减少存储空间。例如,如果年龄列中的值都在0到63之间,可以使用6位而不是标准的32位来表示每个值,从而显著降低数据存储的大小。
-
部门列(字符串型):由于重复值较多,可以使用字典编码(Dictionary Encoding)。这种编码方法通过为每个唯一值创建一个字典,然后使用引用来代替原始值,从而减少重复存储。例如,部门列中"市场部"和"技术部"重复多次,字典编码只需存储这些值一次,然后在实际数据中使用索引引用,大大提高了压缩效率。
具体实例流程如下:
假设部门列包含如下数据:
市场部, 技术部, 财务部, 技术部, 市场部, 人事部, 技术部, 财务部
在字典编码的过程中,首先为每个唯一值分配一个索引:
| 部门 | 索引 |
|---|---|
| 市场部 | 0 |
| 技术部 | 1 |
| 财务部 | 2 |
| 人事部 | 3 |
然后将原始数据替换为索引:
0, 1, 2, 1, 0, 3, 1, 2
这样通过使用索引引用,可以显著减少存储空间,尤其是在数据中存在大量重复值时。
压缩前后的数据示意表:
| 列名 | 原始大小 | 压缩后大小 | 压缩率 |
|---|---|---|---|
| 员工ID | 32字节 | 16字节 | 50% |
| 姓名 | 64字节 | 40字节 | 62.5% |
| 年龄 | 32字节 | 8字节 | 25% |
| 部门 | 64字节 | 24字节 | 37.5% |
五、Parquet 的高级特性
1. 列的元数据
Parquet 在文件尾部存储了丰富的元数据,包括:
- 统计信息:如最小值、最大值、空值数量等。
- 索引信息:便于快速定位特定的数据块。
这些元数据有助于查询优化,如在过滤条件下跳过不必要的列块。
2. 支持复杂数据类型
Parquet 支持嵌套的复杂数据类型,如结构体、列表和映射,适用于更广泛的数据场景。
3. 与大数据生态系统的集成
Parquet 被广泛支持于各大数据处理框架,如:
- Apache Hadoop
- Apache Spark
- Apache Hive
- Apache Impala
六、如何在 Python 中使用 Parquet
在 Python 中,我们通常使用 pandas 和 pyarrow 库来读取和写入 Parquet 文件。以下是一些具体的代码示例,帮助理解如何使用 Parquet 格式。
1. 安装依赖库
首先,确保安装了 pandas 和 pyarrow 库,可以通过以下命令安装:
pip install pandas pyarrow
2. 写入 Parquet 文件
使用 pandas 和 pyarrow 可以方便地将 DataFrame 写入 Parquet 文件:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq# 创建一个 DataFrame
data = {"员工ID": [1, 2, 3, 4],"姓名": ["张三", "李四", "王五", "赵六"],"年龄": [28, 35, 42, 29],"部门": ["市场部", "技术部", "财务部", "人事部"]
}
df = pd.DataFrame(data)# 将 DataFrame 写入 Parquet 文件
df.to_parquet("employees.parquet", engine="pyarrow", index=False)
3. 读取 Parquet 文件
读取 Parquet 文件同样非常简单:
# 读取 Parquet 文件
df_from_parquet = pd.read_parquet("employees.parquet", engine="pyarrow")
print(df_from_parquet)
4. 使用 pyarrow 直接操作 Parquet
除了 pandas,还可以使用 pyarrow 直接操作 Parquet 文件:
# 创建一个表(Table)
table = pa.Table.from_pandas(df)# 将表写入 Parquet 文件
pq.write_table(table, "employees_pyarrow.parquet")# 从 Parquet 文件读取表
table_from_parquet = pq.read_table("employees_pyarrow.parquet")
print(table_from_parquet.to_pandas())
5. 优化读取性能
在读取大型 Parquet 文件时,可以通过设置 columns 参数只读取所需的列,从而优化性能:
# 只读取年龄和部门列
df_selected_columns = pd.read_parquet("employees.parquet", engine="pyarrow", columns=["年龄", "部门"])
print(df_selected_columns)
pandas 通过 read_parquet 方法直接读取 Parquet 文件的数据,并将其加载为 DataFrame 对象,而不会涉及中间的 CSV 转换步骤。这使得数据读取更为高效,特别是在处理大规模数据时。
七、Parquet 格式为了解决什么问题而生
综上所述,Parquet 格式主要为了解决以下问题:
- 提高大数据查询的读取效率:通过列式存储,减少不必要的磁盘 I/O。
- 降低存储空间占用:采用高效的编码和压缩算法,节省存储成本。
- 增强数据分析能力:丰富的元数据支持,使得查询优化和数据统计更为高效。
相关文章:

深入理解 Parquet 文件格式
深入理解 Parquet 文件格式 深入理解 Parquet 文件格式一、引言二、为什么采用 Parquet 格式1. 行式存储的局限性2. 列式存储的优势 三、Parquet 的工作原理1. 文件结构2. 列块和页面3. 编码和压缩 四、具体数据实例1. 数据示例2. 行式存储 vs 列式存储3. 查询性能对比4. 压缩效…...

计算机挑战赛3
老式的计算机只能按照固定次序进行运算,华安大学就有这样一台老式计算机,计算模式为AB#C,和#为输入的运算符(可能是、-或*,运算符优先级与C一致),现给出A,B,C的数值以及和#对应的运算符…...

深度学习:循环神经网络—RNN的原理
传统神经网络存在的问题? 无法训练出具有顺序的数据。模型搭建时没有考虑数据上下之间的关系。 RNN神经网络 RNN(Recurrent Neural Network,循环神经网络)是一种专门用于处理序列数据的神经网络。在处理序列输入时具有记忆性…...

蓝桥杯刷题--幸运数字
幸运数字 题目: 解析: 我们由题目可以知道,某个进制的哈沙德数就是该数和各个位的和取整为0.然后一个幸运数字就是满足所有进制的哈沙德数之和.然后具体就是分为以下几个步骤 1. 我们先写一个方法,里面主要是用来判断,这个数在该进制下是否是哈沙德数 2. 我们在main方法里面调用…...

Node.js入门——fs、path模块、URL端口号、模块化导入导出、包、npm软件包管理器
Node.js入门 1.介绍 定义:跨平台的JS运行环境,使开发者可以搭建服务器端的JS应用程序作用:使用Node.Js编写服务器端代码Node.js是基于Chrome V8引擎进行封装,Node中没有BOM和DOM 2.fs模块-读写文件 定义:封装了与…...

多元线性回归:机器学习中的经典模型探讨
引言 多元线性回归是统计学和机器学习中广泛应用的一种回归分析方法。它通过分析多个自变量与因变量之间的关系,帮助我们理解和预测数据的行为。本文将深入探讨多元线性回归的理论背景、数学原理、模型构建、技术细节及其实际应用。 一、多元线性回归的背景与发展…...

域1:安全与风险管理 第1章实现安全治理的原则和策略
---包括OSG 1、2、3、4 章--- 第1章、实现安全治理的原则和策略 1、由保密性、完整性和可用性组成的 CIA 三元组。 保密性原则是指客体不会被泄露给 未经授权的主体。完整性原则是指客体保持真实性且只被经过授权的主体进行有目的的修改。 可用性原则指被授权的主体能实时和…...

【大数据】学习大数据开发应该从哪些技术栈开始学习?
学习大数据开发可以从以下几个技术栈和阶段入手。以下内容按学习顺序和重要性列出,帮助你逐步掌握大数据开发的核心技能: 1. 编程基础 Java:Hadoop 和许多大数据工具(如 Spark、Flink)的核心代码都是用 Java 编写的&…...

CentOS快速配置网络Docker快速部署
CentOS快速配置网络&&Docker快速部署 CentOS裸机Docker部署1.联通外网2.配置CentOS镜像源3.安装Docker4.启动Docker5.CentOS7安装DockerCompose Bug合集ERROR [internal] load metadata for docker.io/library/java:8-alpineError: Could not find or load main class …...

Grounded-SAM Demo部署搭建
目录 1 环境部署 2 Grounded-SAM Demo安装 3 运行Demo 3.1 运行Gradio APP 3.2 Gradio APP操作 1 环境部署 由于SAM建议使用CUDA 11.3及以上版本,这里使用CUDA 11.4版本。 另外,由于整个SAM使用的是Pytorch开发,因此需要Python环境&…...
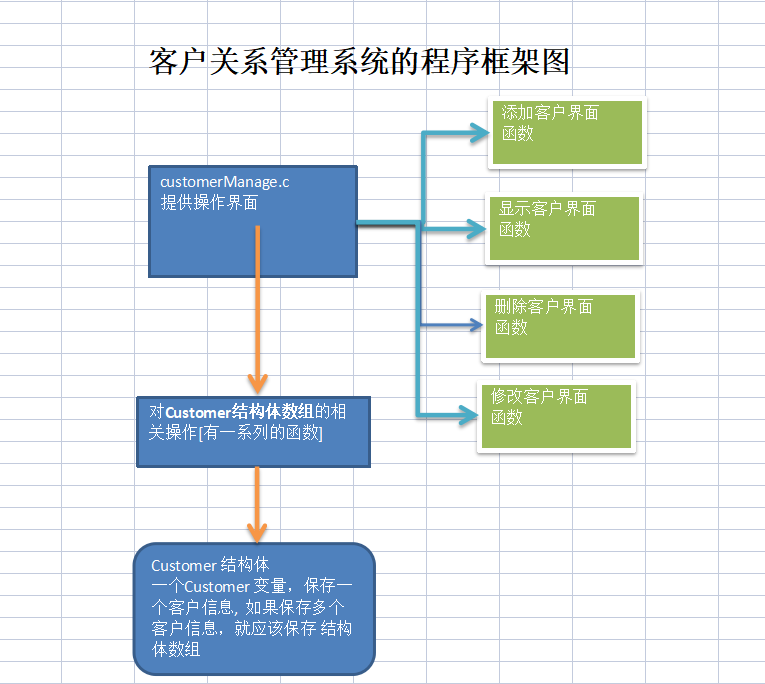
C语言 | 第十六章 | 共用体 家庭收支软件-1
P 151 结构体定义三种形式 2023/3/15 一、创建结构体和结构体变量 方式1-先定义结构体,然后再创建结构体变量。 struct Stu{ char *name; //姓名 int num; //学号 int age; //年龄 char group; //所在学习小组 float score; //成绩 }; struct Stu stu1, stu2; //…...

【论文阅读】Learning a Few-shot Embedding Model with Contrastive Learning
使用对比学习来学习小样本嵌入模型 引用:Liu, Chen, et al. “Learning a few-shot embedding model with contrastive learning.” Proceedings of the AAAI conference on artificial intelligence. Vol. 35. No. 10. 2021. 论文地址:下载地址 论文代码…...

OKHTTP 如何处理请求超时和重连机制
😄作者简介: 小曾同学.com,一个致力于测试开发的博主⛽️,主要职责:测试开发、CI/CD 如果文章知识点有错误的地方,还请大家指正,让我们一起学习,一起进步。 😊 座右铭:不…...

基于Springboot vue的流浪狗领养管理系统设计与实现
博主介绍:专注于Java(springboot ssm 等开发框架) vue .net php python(flask Django) 小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不然下次找…...

爬虫案例——网易新闻数据的爬取
案例需求: 1.爬取该新闻网站——(网易新闻)的数据,包括标题和链接 2.爬取所有数据(翻页参数) 3.利用jsonpath解析数据 分析: 该网站属于异步加载网站——直接网页中拿不到,需要…...

SpringCloud 2023 Gateway的Filter配置介绍、类型、内置过滤器、自定义全局和单一内置过滤器
目录 1. Filter介绍2. Filter类型3. 内置过滤器3.1 请求头(RequestHeader)相关GatewayFilter Factory3.2 请求参数(RequestParameter)相关GatewayFilter Factory3.3 回应头(ResponseHeader)相关GatewayFilter Factory3.4 前缀和路径相关GatewayFilter Factory3.5 Default Filte…...

从银幕到现实:擎天柱机器人即将改变我们的生活
擎天柱(Optimus)是《变形金刚》系列电影中的主角,如今也成为特斯拉正在开发的通用机器人。2022年10月,特斯拉展示了这一机器人的初始版本,创始人埃隆马斯克表示,希望到2023年能够启动生产。他指出ÿ…...

408算法题leetcode--第33天
509. 斐波那契数 题目地址:509. 斐波那契数 - 力扣(LeetCode) 题解思路:dp 时间复杂度:O(n) 空间复杂度:O(n) 代码: class Solution { public:int fib(int n) {// dp数组含义:dp[i]即i位置…...

OCR模型调研及详细安装
OCR模型调研及详细安装 1 搭建 Tesseract-OCR 环境。 1.1 注意需先手动安装Tesseract-OCR, 下载地址:https://digi.bib.uni-mannheim.de/tesseract/?CM;OD 注意:安装的时候选中中文包(安装时把所有选项都勾上)。 安装磁盘选择…...

C++第六讲:STL--vector的使用及模拟实现
C第六讲:STL--vector的使用及模拟实现 1.vector简介2.vector的常见接口介绍2.1constructor -- 构造2.2destructor -- 析构2.3begin、end2.3.1vector和string的区别、vector<string> 2.4rbegin、rend2.5cbegin、cend2.6crbegin、crend2.7size、max_size、resiz…...
嵌入式LED色彩校正:Gamma原理与Arduino NeoPixel实战
1. 项目概述:为什么你的NeoPixel灯带颜色总是不对劲?如果你玩过像NeoPixel、WS2812B这类可编程LED灯带,并且尝试过自己调色,大概率遇到过这样的困惑:你在代码里设定了一个“橙色”——比如红色满值255,绿色…...

PPO 原理与应用
1. PPO 在 RLHF 里到底是干什么的? 在 RLHF 里,我们通常已经有了一个经过 SFT 的模型。这个模型已经比较会回答问题了,但还不一定最符合人类偏好。 于是我们再训练一个 奖励模型 Reward Model,让它模仿人类判断: 这个回…...
)
【独家首发】ElevenLabs马拉雅拉姆文支持状态实测报告(含ISO 639-2代码验证、音素对齐误差率<0.8%)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs马拉雅拉姆文支持的现状与战略意义 ElevenLabs 作为全球领先的语音合成平台,自2023年11月起正式将马拉雅拉姆语(Malayalam,ISO 639-1: ml)纳入…...

电商运营数字密码解析:0.01、50、0、8.8背后的用户增长与转化逻辑
1. 项目概述:一次电商运营的“数字密码”破译最近在复盘一些头部品牌的电商运营案例时,CYPRESS天猫旗舰店的一组数字引起了我的注意:0.01、50、0、8.8。乍一看,这像是几个毫无关联的随机数,但当你把它们放在电商运营的…...

为Claude Code配置Taotoken密钥以解决访问限制与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken密钥以解决访问限制与token不足问题 对于经常使用Claude Code作为编程助手的开发者而言,直接…...

终极英雄联盟换肤工具:R3nzSkin国服特供版完整使用教程
终极英雄联盟换肤工具:R3nzSkin国服特供版完整使用教程 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服免费体验所有皮肤…...

书匠策AI毕业论文功能全拆解:一个教论文写作的博主,居然被它种草了
你还在对着空白文档发呆?这个AI工具让我"真香"了 各位同学,我是你们的论文写作科普博主。 说句大实话,这几年我教过上千个学生怎么写毕业论文,从选题到开题、从大纲到终稿,每个环节我都能给你掰碎了讲。但…...

Win11Debloat终极指南:如何轻松优化Windows 11系统性能
Win11Debloat终极指南:如何轻松优化Windows 11系统性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and c…...
如何用二维图像实现三维物体识别?)
多视角卷积神经网络(MVCNN)如何用二维图像实现三维物体识别?
多视角卷积神经网络(MVCNN)如何用二维图像实现三维物体识别? 【免费下载链接】mvcnn_pytorch MVCNN on PyTorch 项目地址: https://gitcode.com/gh_mirrors/mv/mvcnn_pytorch 在计算机视觉领域,三维物体识别一直是一个具有…...

如何永久保存微信聊天记录?WeChatMsg终极解决方案完全指南
如何永久保存微信聊天记录?WeChatMsg终极解决方案完全指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...