生信分析流程:从数据准备到结果解释的完整指南

介绍
生物信息学(生信)分析是一个复杂的过程,涉及从数据准备到结果解释的多个步骤。随着高通量测序技术的发展和生物数据的迅猛增长,了解和掌握生信分析的标准流程变得尤为重要。这不仅有助于提高分析的准确性,还能优化数据处理的效率。本文将详细介绍生信分析的标准流程,包括每个步骤的关键操作和最佳实践。
生信分析的标准流程


马上体验少走弯路,高效分析;了解生信云,访问 【生信圆桌x生信专用云服务器】 : www.tebteb.cc
- 数据获取与存储:
-
- 数据来源:生信分析通常从获取生物数据开始,包括基因组测序、转录组测序、蛋白质组测序等。数据可以来自实验室生成的原始数据,或是公开数据库如NCBI、Ensembl等。
- 数据存储:确保数据的安全性和完整性,使用高效的数据存储方案如SSD硬盘或云存储服务,定期备份数据以防丢失。
- 数据预处理:
-
- 质量控制:使用工具如FastQC对原始数据进行质量评估,识别数据中的噪声和低质量序列。质量控制是确保数据分析结果可靠的关键步骤。
- 去除低质量序列:利用工具如Trimmomatic、Cutadapt去除低质量序列和接头序列,提高数据的整体质量。
- 数据归一化:对于表达数据,应用归一化方法(如TPM、RPKM、FPKM)来调整不同样本之间的测序深度和表达量差异。
- 数据比对与对齐:
-
- 基因组比对:将测序数据比对到参考基因组上。使用比对工具如BWA、Bowtie2进行比对,以识别序列的具体位置。
- 序列对齐:对于转录组数据,进行序列对齐以确定每个转录本的位置和丰度。常用工具包括STAR、HISAT2等。
- 变异检测与注释:
-
- 变异检测:识别基因组中的变异,包括单核苷酸多态性(SNPs)和插入缺失(INDELs)。常用的变异检测工具有GATK、Samtools等。
- 变异注释:将检测到的变异注释到基因功能上,评估其生物学意义。使用工具如ANNOVAR、SnpEff为变异添加注释信息。
- 差异表达分析:
-
- 差异表达检测:分析不同条件或样本组之间的基因表达差异。工具如DESeq2、edgeR用于差异表达分析,生成不同条件下的显著性表达基因列表。
- 结果可视化:使用火山图、热图等可视化工具展示差异表达基因的结果,帮助理解和解释数据。
- 功能富集分析:
-
- GO和KEGG分析:利用Gene Ontology(GO)和Kyoto Encyclopedia of Genes and Genomes(KEGG)等数据库,对差异表达基因进行功能富集分析,识别相关的生物过程、分子功能和细胞组分。
- 通路分析:分析差异表达基因在生物学通路中的作用,帮助揭示潜在的生物学机制。
- 结果解释与验证:
-
- 结果解释:综合分析结果,解释生物学意义和潜在的生物学机制。通过文献调研和已知的生物学知识进行结果的解读。
- 实验验证:使用实验技术如qPCR、Western Blot等对分析结果进行验证,以确保结果的准确性和可靠性。
- 数据报告与分享:
-
- 报告生成:撰写详细的数据分析报告,包括分析流程、方法、结果和结论。报告应清晰、准确,并符合科研出版的标准。
- 数据分享:将数据和结果共享到公共数据库或研究平台,促进科学交流和后续研究。遵循数据共享和开放获取的相关政策。
生信分析流程的最佳实践
- 严格的数据质量控制:确保每一步都进行严格的质量控制,以获得高质量的数据和可靠的分析结果。
- 选择合适的工具和方法:根据具体的研究需求选择合适的工具和分析方法,避免使用不适当的工具影响结果。
- 文档化和记录:记录每一步的操作细节和参数设置,以便于结果的复现和结果的解释。
- 进行充分的验证:对分析结果进行实验验证和多角度的验证,以提高结果的可信度。
- 与团队合作:与其他生物信息学专家和领域专家合作,获取专业建议和意见,提高分析的全面性和准确性。
推荐使用生信圆桌平台进行分析
为了提高生信分析的效率,我们推荐使用生信圆桌平台。生信圆桌平台提供了集成的生信分析工具和预配置的计算资源,支持从数据预处理到结果解释的完整分析流程。使用生信圆桌平台可以简化分析过程,提高工作效率,并确保结果的可靠性。
生信圆桌平台 的主要优势包括:
- 集成分析工具:预装常用的生信分析工具,如DESeq2、STAR、GATK等,方便用户快速启动分析任务。
- 高性能计算资源:提供强大的计算资源,支持大规模数据处理和复杂计算任务。
- 用户友好的界面:简化操作流程,降低学习曲线,提高分析效率。
使用生信圆桌平台,你可以更高效地完成生信分析流程,获取准确的研究结果,为生物信息学研究提供有力支持。
相关文章:
生信分析流程:从数据准备到结果解释的完整指南
介绍 生物信息学(生信)分析是一个复杂的过程,涉及从数据准备到结果解释的多个步骤。随着高通量测序技术的发展和生物数据的迅猛增长,了解和掌握生信分析的标准流程变得尤为重要。这不仅有助于提高分析的准确性,还能优…...

golang语法
参考链接:https://www.runoob.com/go/ 创建变量 // 3种方法 var a int a : 10 // 类型推断 a : make() // 复合类型循环 // 3种循环 for i : 0; i < 10; i {// 循环体} // 传统for循环 for index, num : range nums {// 循环体} // nums是可迭代的复合类型…...

【fisco学习记录2】多群组搭建
说明 文档参考: 多群组部署 — FISCO BCOS 2.0 v2.11.0 文档 (fisco-bcos-documentation.readthedocs.io) 多群组搭建之前,先暂停之前的单群组,并删除: cd fisco bash nodes/127.0.0.1/stop_all.sh rm -rf nodes/ 实现图&…...

深度解读:路由交换、负载均衡与防火墙的网络交响
一、路由交换:网络流动的“大动脉” 1. 路由:决定命运的“路径规划师” 路由技术如同现代交通网络中的导航系统,决定了数据从起点到终点的最佳路径。路由器基于网络层IP地址,对每个数据包进行精确的路径选择,并确保其…...

linux线程 | 线程的控制(二)
前言: 本节内容是线程的控制部分的第二个小节。 主要是列出我们的线程控制部分的几个细节性问题以及我们的线程分离。这些都是需要大量的代码去进行实验的。所以, 准备好接受新知识的友友们请耐心观看。 现在开始我们的学习吧。 ps:本节内容适合了解线程…...

npm install报错一堆sass gyp ERR!
执行npm install ,出现一堆gyp含有sass错误的情况下。 解决办法: 首页可能是node版本问题,太高或者太低,也会导致npm install安装错误(不会自动生成node_modules文件),本次试验,刚开…...

微知-BlueField DPU在lspci中显示Flash Recovery是什么意思?
效果: lspci |grep BlueField10:00.0 Memory controller: Mellanox Technologies MT42822 Family [BlueField-2 SoC Flash Recovery] (rev 01)*原因: 表示此时flash是empty空的,或者在flash中的FW是无法工作的。比如烧录错误。 这里指的一提…...

【前端知识点】前端笔记
css 引入css文件的文件路径 <!-- 引入外部 CSS 文件 --> <!-- 当前文件所在文件夹目录 --> <link rel"stylesheet" href"./"> <!-- 当前文件所在父文件夹目录 --> <link rel"stylesheet" href"../">j…...

Sping Cache 使用详解
缓存是提升应用性能的常用手段。它通过将耗时的操作结果存储起来,下次请求可以直接从缓存中获取,从而避免重复计算或查询数据库,显著减少响应时间和服务器负载。Spring 框架提供了强大的缓存抽象 Spring Cache,它简化了缓存的使用…...

动手学深度学习60 机器翻译与数据集
1. 机器翻译与数据集 import os import torch from d2l import torch as d2l#save d2l.DATA_HUB[fra-eng] (d2l.DATA_URL fra-eng.zip,94646ad1522d915e7b0f9296181140edcf86a4f5)#save def read_data_nmt():"""载入“英语-法语”数据集"&qu…...

Python网络爬虫技术
Python网络爬虫技术详解 引言 网络爬虫(Web Crawler),又称网络蜘蛛(Web Spider)或网络机器人(Web Robot),是一种按照一定规则自动抓取互联网信息的程序或脚本。它们通过遍历网页链…...

黑马程序员-redis项目实践笔记1
目录 一、 基于Session实现登录 发送验证码 验证用户输入验证码 校验登录状态 Redis代替Session登录 发送验证码修改 验证用户输入验证码 登录拦截器的优化 二、 商铺查询缓存 缓存更新策略 数据库和缓存不一致解决方案 缓存更新策略的最佳实践方案 实现商铺缓…...

ES-入门聚合查询
url 请求地址 http://192.168.1.108:9200/shopping/_search {"aggs": { //聚合操作"price_group":{ //名称,随意起名"terms":{ //分组"field": "price" //分组字段}}} } 查询出来的结果是 查询结果中价格的平均值 {&q…...

七维大脑: 探索人类认知的未来之路
七维大脑: 探索人类认知的未来之路 随着科技的不断发展,人们对于大脑的认知也在不断扩展。近年来,科学家们提出了一个名为“七维大脑”的概念,试图通过七个维度来理解人类的认知过程。这个概念的提出,让人们开始思考&…...

spring |Spring Security安全框架 —— 认证流程实现
文章目录 开头简介环境搭建入门使用1、认证1、实体类2、Controller层3、Service层3.1、接口3.2、实现类3.3、实现类:UserDetailsServiceImpl 4、Mapper层3、自定义token认证filter 注意事项小结 开头 Spring Security 官方网址:Spring Security官网 开…...

Django+vue自动化测试平台---正式开源!!!
自动化测试:接口、Web UI 与 App 的全面探索 在此郑重声明:本文内容未经本人同意,不得随意转载。若有违者,必将追究其法律责任。同时,禁止对相关源码进行任何形式的售卖行为,本内容仅供学习使用。 Git 地…...

电子电气架构 --- 智能网联汽车未来是什么样子?
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

docker安装elasticsearch(es)+kibana
目录 docker安装elasticsearch 一.准备工作 1.打开docker目录 2.创建elasticsearch目录 3.打开elasticsearch目录 4.拉取elasticsearch镜像 5.检查镜像 二.挂载目录 1.创建数据挂载目录 2.创建配置挂载目录 3.创建插件挂载目录 4.权限授权 三.编辑配置 1.打开con…...

大厂面试真题-说说redis的雪崩、击穿和穿透
缓存雪崩、击穿、穿透是缓存系统中常见的三种问题,它们都会对系统的性能和稳定性造成严重影响。以下是对这三种问题的详细解释以及相应的解决方案: 一、缓存雪崩 问题解释: 缓存雪崩指的是因为某些原因导致缓存中大量的数据同时失效或过期…...
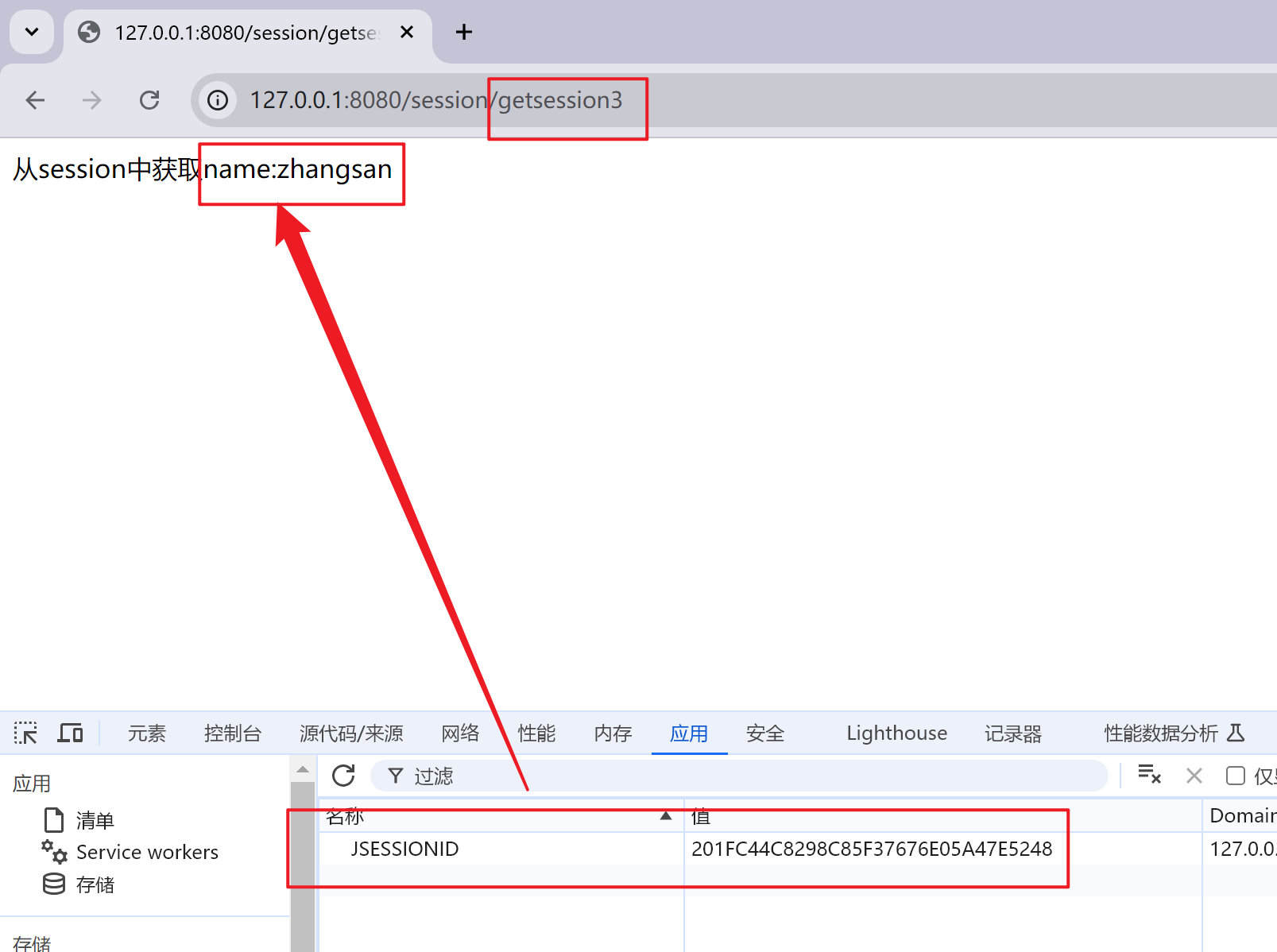
【Spring】获取Cookie和Session(@CookieValue()和@SessionAttribute())
获取 Cookie 传统获取 Cookie 这是没有 Spring 的时候,用 Servlet 来获取(获取所有的 Cookie) Spring MVC 是基于 Servlet API 构建的原始 Web 框架,也是在 Servlet 的基础上实现的 RequestMapping("/getcookie") …...

RP2040内置温度传感器:零成本实现精准温度监测与校准
1. 项目概述:为什么要在Pico上折腾内置温度传感器?如果你手头有一块树莓派Pico,或者任何基于RP2040芯片的开发板,你可能已经用它点亮过LED、驱动过电机,甚至玩过一些简单的通信协议。但你是否知道,就在这块…...

淘金币自动化脚本:5分钟完成淘宝全任务,每天节省20分钟宝贵时间
淘金币自动化脚本:5分钟完成淘宝全任务,每天节省20分钟宝贵时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/t…...

构建高可用代理池:开源工具agentpull的架构解析与实战部署
1. 项目概述:一个轻量级、可编程的代理拉取工具最近在折腾一些自动化任务和分布式爬虫时,经常遇到一个头疼的问题:如何高效、稳定地管理海量的代理IP资源。无论是数据采集、社交媒体运营还是安全测试,一个可靠的代理池都是基础设施…...

SAP屏幕导航:从SET到LEAVE,实战解析六大跳转策略
1. SAP屏幕导航的核心逻辑 在SAP ABAP开发中,屏幕导航就像是在迷宫中寻找出口。想象你手里有六把不同的钥匙(六种跳转策略),每把钥匙对应不同的门锁(业务场景)。选错钥匙要么打不开门,要么可能把…...

MATLAB解DAE踩坑实录:ode15i求解完全隐式方程,初始条件怎么设才不报错?
MATLAB解DAE踩坑实录:ode15i求解完全隐式方程,初始条件怎么设才不报错? 在工程仿真和科学计算领域,微分代数方程(DAE)的求解一直是令人头疼的问题。特别是当面对完全隐式形式的DAE时,传统的半显…...

基于ChatGPT的Twitter机器人开发实战:从架构设计到部署优化
1. 项目概述与核心价值最近在社交媒体上,尤其是技术社区,经常能看到一些“智能”的推特机器人账号。它们不仅能自动回复评论,还能根据上下文进行看似有逻辑的对话,甚至参与话题讨论。这背后,往往就是像transitive-bull…...

Attention Is All You Need:一篇论文,改变了整个世界
先讲一个场景。 2017年,谷歌大脑的一间办公室。 八个研究员,围坐在一起。 他们在讨论一个问题: 现有的翻译模型,为什么总是翻译得不够好? 长句子,翻译到后面,前面的意思就丢了。 复杂的语法结构…...

基于RT-Thread与PSoC 6的智能环境监测系统设计与实现
1. 项目概述:当嵌入式RTOS遇上混合信号MCU最近在捣鼓一个智能环境监测的小玩意儿,核心需求很简单:实时采集环境的温湿度数据,一旦超过预设的阈值,就通过声光或者网络的方式发出警报。听起来像是毕业设计的经典题目&…...

WeChatMsg:5分钟轻松掌握微信聊天记录的终极管理方案
WeChatMsg:5分钟轻松掌握微信聊天记录的终极管理方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChat…...

awesome-clothed-human安全指南:在数字人体建模中保护用户隐私的5个最佳实践
awesome-clothed-human安全指南:在数字人体建模中保护用户隐私的5个最佳实践 【免费下载链接】awesome-digital-human Digital Human Resource: 2D/3D/4D Human Modeling, Avatar Generation & Animation, Clothed People Digitalization, Virtual Try-On, etc.…...