linux线程 | 线程的控制(二)
前言: 本节内容是线程的控制部分的第二个小节。 主要是列出我们的线程控制部分的几个细节性问题以及我们的线程分离。这些都是需要大量的代码去进行实验的。所以, 准备好接受新知识的友友们请耐心观看。 现在开始我们的学习吧。
ps:本节内容适合了解线程的基本控制(创建, 等待, 终止)的友友们进行观看哦。
目录
线程的栈
准备文件
makefile
核心代码
创建test_i栈区变量
利用全局变量拿到别的执行流数据
局部性存储
线程分离
主线程分离
自己分离自己
首先我们的系统之中,有下面四种情况。

左上角是只有一个线程一个进程的情况, 右上角是一个进程多个线程的情况。 左下角是多个进程里面有一个线程的情况。 右下角是多个进程里面有多个进程的情况。
那么, 其实我们的linux当中, 其实是分为用户级线程和内核LWP。 这两个加起来, 才是我们的linux下真正的线程。 其中, 我们的linux其实是属于用户级线程。 里面的用户级线程与内核LWP的比率为 1 : 1。
线程的栈
现在我们谈一谈这个栈, 这个栈并不是简简单单的用来入栈出栈, 定义变量。 实际上, 我们的每一条执行流的本质就是一条调用链, 从main函数开始从上往下执行, 我们会依次执行各种函数, 当我们进行调用函数时, 本质上就是在栈当中先为该函数形成一个独立的栈帧结构。 所以这个栈其实就是被整体使用的, 依次把一个一个地调用链所对应的栈帧结构宏观上在栈上依次开辟。 然后我们每一次定义变量, 都是在栈帧结构里面去定义的, 这个栈结构, 本质是为了支持我们在应用层来完成我们的整个的调用链所对应的临时空间的开辟和释放。 所以, 这些线程为了能够拥有独立的调用链, 就必须拥有属于自己的调用栈!
现在我们利用代码来测试一下:
准备文件
准备好两个文件

makefile
再将makefile准备出来
mythread.exe:mythread.cppg++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:rm -rf mythread.exe核心代码
这串代码分为几个板块: 定义线程的信息的结构体、线程信息的初始化、将整形转化为字符串类型、线程的执行代码、主函数
#include<iostream>
using namespace std;
#include<pthread.h>
#include<vector>
#include<unistd.h>#define NUM 5 //创建多个执行流, NUM为执行流个数using namespace std;//线程的数据信息。
struct threadData
{string threadname;
};//将整形以十六进制转化为字符串类型
string toHex(pthread_t tid)
{char buffer[128];snprintf(buffer, sizeof(buffer), "0x%x", tid);return buffer;
}//线程信息的初始化
void InitthreadData(threadData* td, int number)
{td->threadname = "thread-" + to_string(number);
}//新线程的执行代码
void* threadRuntine(void* args)
{threadData* td = static_cast<threadData*>(args);int i = 0;while (i < 5){cout << "pid: " << getpid() << ", tid: " << toHex(pthread_self()) << ", name: " << td->threadname << endl;i++;sleep(2);}delete td;return nullptr;
}int main()
{ vector<threadData*> tids;//我们创建多个执行流, 为了能够验证每个线程都有一个独立的栈结构for (int i = 0; i < NUM; i++){//每一个线程都要有一个线程的信息, 并且这个线程的信息我们在堆区开辟, 那么所有的线程其实都能够看到这个线程的信息, 因为堆区是共享的。threadData* td = new threadData();pthread_t tid;InitthreadData(td, i); //初始化线程的信息。pthread_create(&tid, nullptr, threadRuntine, td);tids.push_back(tid);sleep(2);}for (int i = 0; i < tids.size(); i++){pthread_join(tids[i], nullptr);}return 0;
}然后我们就能看到这种情况。

创建test_i栈区变量
在线程的执行代码块里面添加一个test_i变量, 然后打印这个变量。
//新线程的执行代码
void* threadRuntine(void* args)
{threadData* td = static_cast<threadData*>(args);int test_i = 0;int i = 0;while (i < 5){cout << "pid: " << getpid() << ", tid: " << toHex(pthread_self()) << ", name: " << td->threadname << ", test_i: " << test_i << ", &test_i: " << &test_i << endl;i++;test_i++;sleep(2);}delete td;return nullptr;
}
下面就是运行结果, 从图中我们可以看到, 每一个执行流都有自己的独有的一份test_i, 并且他们的值都是从零开始, 一直加到4。而且, 每个变量的地址都不一样, 所以每个线程都会有自己独立的栈结构。当我们的线程执行到threadRuntine, 就会在自己的栈结构里面开辟自己的栈帧, 然后创建test_i也是在自己刚刚创建的栈帧中创建。

利用全局变量拿到别的执行流数据
创建一个全局变量p

然后在线程执行的代码里面, 写上要拿哪一个线程的什么数据:

为了确认真正的拿到了这个数据, 在程序的最后打印这个数据:

下面是运行结果:

由上面的结果我们其实就能够知道:在线程中根本没有秘密, 只不过要求线程有独立的栈, 但是这个独立的栈本质上还是在地址空间的共享区中。 所以, 我们每个线程叫做都有一个独立的栈结构, 而不是一个私有的栈结构。 就是因为这个栈结构能够被别人访问到, 而私有的意思是别人看不到。 ——所以, 线程与线程之间没有秘密。 线程的栈上的数据,也是可以被其他线程看到并访问的。
局部性存储
我们之前说过, 全局变量是可以被所有线程看到并访问的。但是如果线程想要一个私有的全局变量呢? 那么我们就需要在全局变量前面加一个__thread。 下面用代码来进行验证:
我们的核心代码还是上面写的代码。
并且为了方便观察, 将创建线程每隔1000微秒(使用usleep函数)创建一个线程。 然后每隔2秒打印一次数据:
#include<iostream>
using namespace std;
#include<pthread.h>
#include<vector>
#include<unistd.h>#define NUM 5 //创建多个执行流, NUM为执行流个数using namespace std;int* p = nullptr;
__thread int g_val = 0;//线程的数据信息。
struct threadData
{string threadname;
};string toHex(pthread_t tid)
{char buffer[128];snprintf(buffer, sizeof(buffer), "0x%x", tid);return buffer;
}void InitthreadData(threadData* td, int number)
{td->threadname = "thread-" + to_string(number);
}//新线程的执行代码
void* threadRuntine(void* args)
{threadData* td = static_cast<threadData*>(args);int i = 0;while (i < 5){cout << "pid: " << getpid() << ", tid: " << toHex(pthread_self()) << ", name: " << td->threadname<< ", g_val: " << g_val << ", &g_val: " << &g_val << endl;i++;g_val++;sleep(2);}delete td;return nullptr;
}int main()
{ vector<pthread_t> tids;//我们创建多个执行流, 为了能够验证每个线程都有一个独立的栈结构for (int i = 0; i < NUM; i++){threadData* td = new threadData();pthread_t tid;InitthreadData(td, i);pthread_create(&tid, nullptr, threadRuntine, td);tids.push_back(tid);usleep(1000);}//for (int i = 0; i < tids.size(); i++){pthread_join(tids[i], nullptr);}return 0;
}下面是运行结果, 运行结果中g_val都是从0开始, 然后各自加各自的,互不影响。 而且每个g_val的地址也不相同。这里的这个__thread, 叫做编译选项。每一个线程都访问同一个全局变量, 但是在访问的时候, 每一个全局变量对于每一个线程来说, 都是各自私有一份的。 这种技术叫做线程的局部性存储!

另外, 我们需要知道的一点就是__thread只能修饰内置类型, 不能修饰自定义类型。
那么, 这个局部性存储有什么作用呢? 就比如我们的线程要进行多次函数调用并且函数都要用到它,而且又不想和别的线程共享这份资源的时候, 我们就可以使用线程的局部性存储。
线程分离
在我们的默认情况下, 新创建的线程是joinable的, 线程退出后, 需要对其进行pthread_join操作, 否则无法释放资源造成内存泄露。 但是我们可以告诉操作系统, 当进程退出的时候, 不需要主线程等待, 而是自动释放资源, 这个操作就是线程分离。
接口如下:

参数就是线程的tid。 返回值和之前一样,就是成功零被返回, 失败返回错误码。
主线程分离
然后我们测试一下线程分离, 代码只改变main函数里面的就可以。 主要就是在进行线程等待之前先将线程分离。 然后等待的时候就会等待错误, 返回错误码。同时我们也可以打印一下错误码观察错误信息。
int main()
{ vector<pthread_t> tids;//我们创建多个执行流, 为了能够验证每个线程都有一个独立的栈结构for (int i = 0; i < NUM; i++){threadData* td = new threadData();pthread_t tid;InitthreadData(td, i);pthread_create(&tid, nullptr, threadRuntine, td);tids.push_back(tid);usleep(1000);}//for (auto e : tids){pthread_detach(e);}for (int i = 0; i < tids.size(); i++){int n = pthread_join(tids[i], nullptr);cout << "n = " << n << ", who: " << toHex(tids[i]) << ", " << strerror(n) << endl;}return 0;
}运行结果如下, 可以发现运行结果如同我们的猜测, 都是返回错误码。 然后我们可以打印一下

自己分离自己
上面的情况是在主线程分离新线程。 我们也可以在新线程里面自己分离自己。
//新线程的执行代码
void* threadRuntine(void* args)
{pthread_detach(pthread_self());//threadData* td = static_cast<threadData*>(args);number = pthread_self();int i = 0;while (i < 5){cout << "pid: " << getpid() << ", tid: " << toHex(number) << ", name: " << td->threadname<< ", g_val: " << g_val << ", &g_val: " << &g_val << endl;i++;g_val++;sleep(2);}delete td;return nullptr;
}然后我们的结果其实和上面的是一样的:

其实线程的分离, 线程是否分离其实是一种属性状态。 一开始默认线程是不分离的,是joinable的。本质上就是线程库里面的线程数据结构里有一个是否可分离的标记位, 开始默认是joinable的,一旦设置由零变一, 就是线程分离。 而线程分离呢, 说是分离, 但是其实和原本的进程还是在共享一份资源, 只是这个线程处于分离状态, 线程退出和进程没有关系了!
——————以上就是本节全部内容哦, 如果对友友们有帮助的话可以关注博主, 方便学习更多知识哦!!!
相关文章:
linux线程 | 线程的控制(二)
前言: 本节内容是线程的控制部分的第二个小节。 主要是列出我们的线程控制部分的几个细节性问题以及我们的线程分离。这些都是需要大量的代码去进行实验的。所以, 准备好接受新知识的友友们请耐心观看。 现在开始我们的学习吧。 ps:本节内容适合了解线程…...

npm install报错一堆sass gyp ERR!
执行npm install ,出现一堆gyp含有sass错误的情况下。 解决办法: 首页可能是node版本问题,太高或者太低,也会导致npm install安装错误(不会自动生成node_modules文件),本次试验,刚开…...

微知-BlueField DPU在lspci中显示Flash Recovery是什么意思?
效果: lspci |grep BlueField10:00.0 Memory controller: Mellanox Technologies MT42822 Family [BlueField-2 SoC Flash Recovery] (rev 01)*原因: 表示此时flash是empty空的,或者在flash中的FW是无法工作的。比如烧录错误。 这里指的一提…...

【前端知识点】前端笔记
css 引入css文件的文件路径 <!-- 引入外部 CSS 文件 --> <!-- 当前文件所在文件夹目录 --> <link rel"stylesheet" href"./"> <!-- 当前文件所在父文件夹目录 --> <link rel"stylesheet" href"../">j…...

Sping Cache 使用详解
缓存是提升应用性能的常用手段。它通过将耗时的操作结果存储起来,下次请求可以直接从缓存中获取,从而避免重复计算或查询数据库,显著减少响应时间和服务器负载。Spring 框架提供了强大的缓存抽象 Spring Cache,它简化了缓存的使用…...

动手学深度学习60 机器翻译与数据集
1. 机器翻译与数据集 import os import torch from d2l import torch as d2l#save d2l.DATA_HUB[fra-eng] (d2l.DATA_URL fra-eng.zip,94646ad1522d915e7b0f9296181140edcf86a4f5)#save def read_data_nmt():"""载入“英语-法语”数据集"&qu…...

Python网络爬虫技术
Python网络爬虫技术详解 引言 网络爬虫(Web Crawler),又称网络蜘蛛(Web Spider)或网络机器人(Web Robot),是一种按照一定规则自动抓取互联网信息的程序或脚本。它们通过遍历网页链…...

黑马程序员-redis项目实践笔记1
目录 一、 基于Session实现登录 发送验证码 验证用户输入验证码 校验登录状态 Redis代替Session登录 发送验证码修改 验证用户输入验证码 登录拦截器的优化 二、 商铺查询缓存 缓存更新策略 数据库和缓存不一致解决方案 缓存更新策略的最佳实践方案 实现商铺缓…...

ES-入门聚合查询
url 请求地址 http://192.168.1.108:9200/shopping/_search {"aggs": { //聚合操作"price_group":{ //名称,随意起名"terms":{ //分组"field": "price" //分组字段}}} } 查询出来的结果是 查询结果中价格的平均值 {&q…...

七维大脑: 探索人类认知的未来之路
七维大脑: 探索人类认知的未来之路 随着科技的不断发展,人们对于大脑的认知也在不断扩展。近年来,科学家们提出了一个名为“七维大脑”的概念,试图通过七个维度来理解人类的认知过程。这个概念的提出,让人们开始思考&…...

spring |Spring Security安全框架 —— 认证流程实现
文章目录 开头简介环境搭建入门使用1、认证1、实体类2、Controller层3、Service层3.1、接口3.2、实现类3.3、实现类:UserDetailsServiceImpl 4、Mapper层3、自定义token认证filter 注意事项小结 开头 Spring Security 官方网址:Spring Security官网 开…...

Django+vue自动化测试平台---正式开源!!!
自动化测试:接口、Web UI 与 App 的全面探索 在此郑重声明:本文内容未经本人同意,不得随意转载。若有违者,必将追究其法律责任。同时,禁止对相关源码进行任何形式的售卖行为,本内容仅供学习使用。 Git 地…...

电子电气架构 --- 智能网联汽车未来是什么样子?
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

docker安装elasticsearch(es)+kibana
目录 docker安装elasticsearch 一.准备工作 1.打开docker目录 2.创建elasticsearch目录 3.打开elasticsearch目录 4.拉取elasticsearch镜像 5.检查镜像 二.挂载目录 1.创建数据挂载目录 2.创建配置挂载目录 3.创建插件挂载目录 4.权限授权 三.编辑配置 1.打开con…...

大厂面试真题-说说redis的雪崩、击穿和穿透
缓存雪崩、击穿、穿透是缓存系统中常见的三种问题,它们都会对系统的性能和稳定性造成严重影响。以下是对这三种问题的详细解释以及相应的解决方案: 一、缓存雪崩 问题解释: 缓存雪崩指的是因为某些原因导致缓存中大量的数据同时失效或过期…...
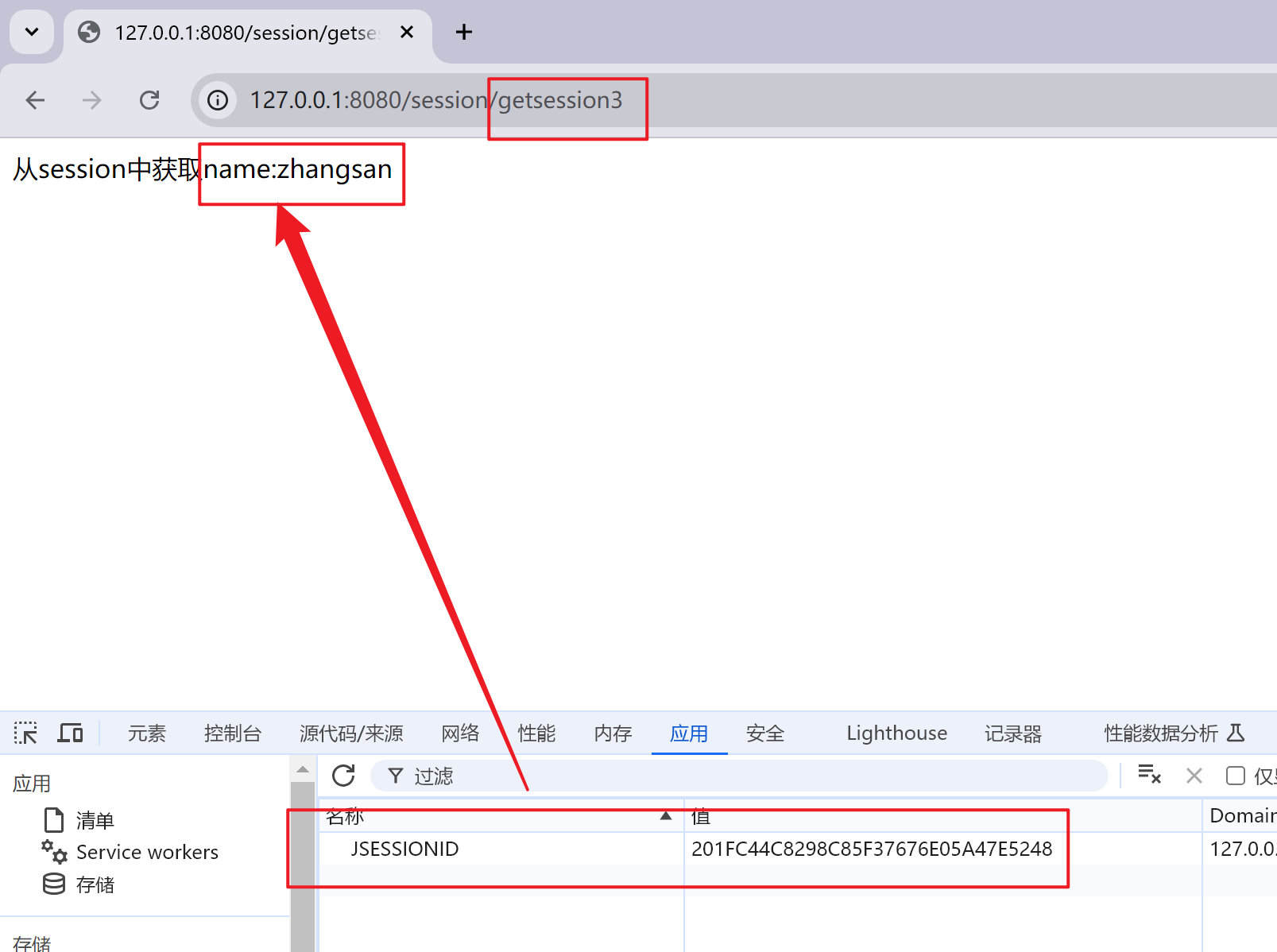
【Spring】获取Cookie和Session(@CookieValue()和@SessionAttribute())
获取 Cookie 传统获取 Cookie 这是没有 Spring 的时候,用 Servlet 来获取(获取所有的 Cookie) Spring MVC 是基于 Servlet API 构建的原始 Web 框架,也是在 Servlet 的基础上实现的 RequestMapping("/getcookie") …...

【C++打怪之路Lv8】-- string类
🌈 个人主页:白子寰 🔥 分类专栏:重生之我在学Linux,C打怪之路,python从入门到精通,数据结构,C语言,C语言题集👈 希望得到您的订阅和支持~ 💡 坚持…...

【JS】node.js压缩文件的方式
在 Node.js 中,有多种方法可以压缩文件。以下是几种常见的压缩方式及其对应的代码示例: 使用 archiver 压缩成 ZIP 文件使用 zlib 压缩成 GZIP 文件使用 tar 压缩成 TAR 文件 1. 使用 archiver 压缩成 ZIP 文件 archiver 是一个功能强大的库ÿ…...
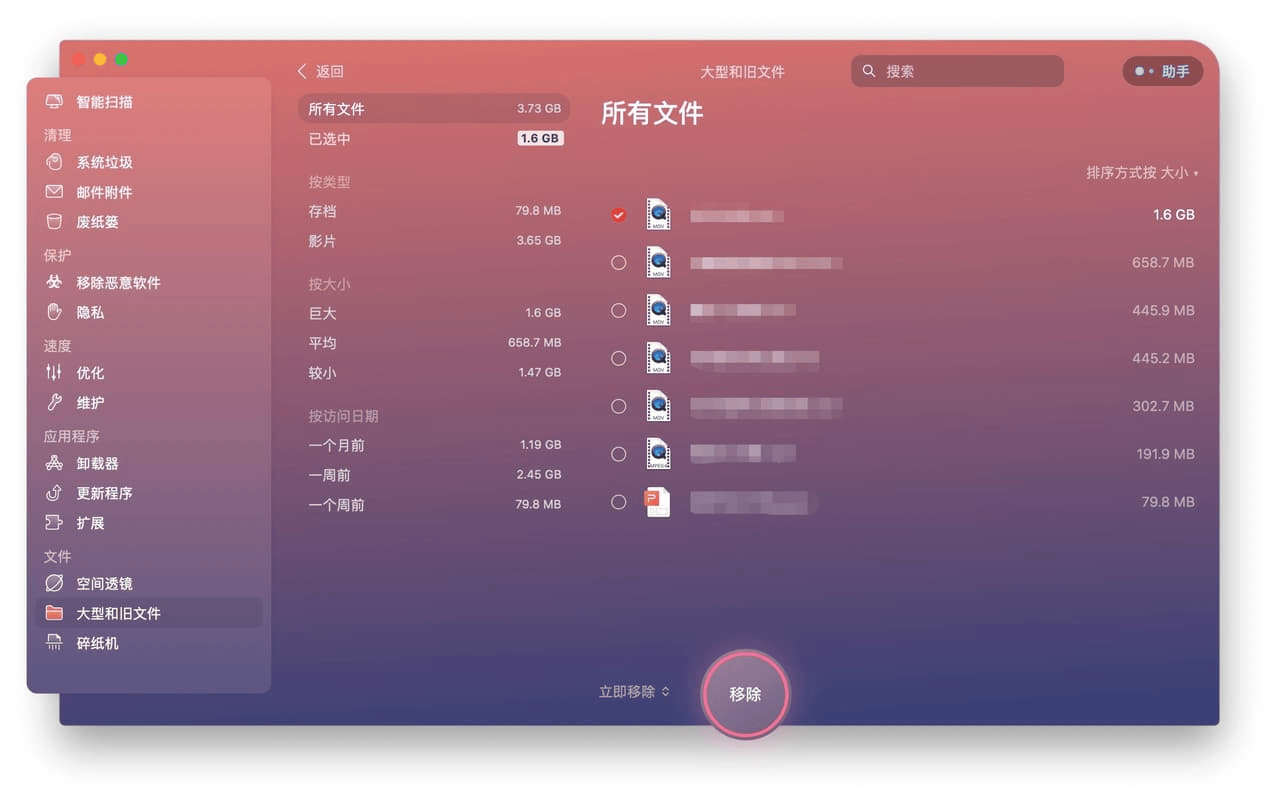
2024免费mac苹果电脑清理垃圾软件CleanMyMac X4.15.8
对于苹果电脑用户来说,设备上积累的垃圾文件可能会导致存储空间变得紧张,影响电脑的性能和使用体验。尤其是那些经常下载和安装新应用、编辑视频或处理大量照片的用户,更容易感受到存储空间的压力。面对这种情况,寻找一种有效的苹…...

MPA-SVM多变量回归预测|海洋捕食者优化算法-支持向量机|Matalb
目录 一、程序及算法内容介绍: 基本内容: 亮点与优势: 二、实际运行效果: 三、算法介绍: 四、完整程序下载: 一、程序及算法内容介绍: 基本内容: 本代码基于Matlab平台编译&am…...

GitHub中文界面极速解锁指南:5分钟告别英文困扰的终极方案
GitHub中文界面极速解锁指南:5分钟告别英文困扰的终极方案 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经面对…...
)
【限时技术白皮书】ElevenLabs尼泊尔文语音质量评估体系(含MOS打分标准、基线数据集、及与Google Cloud Text-to-Speech Nepali v1.3对比)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs尼泊尔文语音质量评估体系概述 ElevenLabs 对尼泊尔文(नेपाली)语音合成的支持虽属新兴能力,但其质量评估需兼顾语言学特性、声学保真度与文化适配性…...
【限时技术白皮书】ElevenLabs藏文模型权重结构首度曝光:Transformer Decoder层中Tibetan Syllable Tokenization模块详解
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs藏文语音生成技术全景概览 ElevenLabs 作为全球领先的文本到语音(TTS)平台,目前尚未官方支持藏文(བོད་སྐད་)语音合成。其公…...

5个技巧打造个性化Obsidian笔记界面:AnuPpuccin主题美化指南
5个技巧打造个性化Obsidian笔记界面:AnuPpuccin主题美化指南 【免费下载链接】AnuPpuccin Personal theme for Obsidian 项目地址: https://gitcode.com/gh_mirrors/an/AnuPpuccin 还在为单调的笔记界面而烦恼吗?想要让你的Obsidian笔记软件焕然一…...

ROFL-Player:基于C的多版本英雄联盟回放文件解析技术实现
ROFL-Player:基于C#的多版本英雄联盟回放文件解析技术实现 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款…...

构建自主可控安全自动化平台:从开源情报到自动化响应实践
1. 项目概述:从开源代码到安全实践的桥梁最近在梳理一些开源安全项目时,我注意到了mattijsmoens/openclaw-sovereign-shield这个仓库。单从名字看,“Sovereign Shield”(主权之盾)就透着一股强烈的防御和自主掌控的意味…...

装机解惑:Bios中的Secure Boot与CSM,为何相爱相杀?
1. Secure Boot与CSM:现代PC的引导之争 刚装好的新电脑突然黑屏,这种经历估计不少DIY玩家都遇到过。上周我就帮朋友处理了这么个案例:他为了省钱继续用老显卡GTX650ti,结果在新配的13代酷睿主机上死活点不亮屏幕。这背后其实是UEF…...

MoviePilot媒体元数据服务连接异常的技术诊断与系统解决方案
MoviePilot媒体元数据服务连接异常的技术诊断与系统解决方案 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot MoviePilot作为专业的NAS媒体库自动化管理工具,其核心功能依赖于TheMovieDb&…...
)
LM567锁相环芯片实测:手把手教你搭建10kHz音频信号检测电路(附面包板接线图)
LM567锁相环芯片实战:从零构建10kHz音频检测电路全流程解析 在电子设计领域,频率检测一直是个既基础又关键的课题。无论是红外遥控信号解码、超声波测距,还是电磁导航系统,精准的频率识别都是实现功能的前提。而LM567这款经典的锁…...

别再手动配置时钟树了!用STM32CubeMX 6.10 + Keil MDK 5分钟搞定LED闪烁工程
5分钟极速开发:STM32CubeMX图形化工具颠覆传统嵌入式开发模式 第一次接触STM32开发时,面对密密麻麻的寄存器手册和复杂的时钟树配置,我花了整整三天才让一个LED灯闪烁起来。直到发现STM32CubeMX这个神器——它彻底改变了嵌入式开发的入门门槛…...