Fastgpt本地化部署 - 以MAC为例
1.认识fastgpt

2.私有化部署

- MongoDB:用于存储除了向量外的各类数据
- PostgreSQL/Milvus:存储向量数据
- OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
(1)前置工作
Docker环境、网络
(2)开始部署
本地创建文件夹命名为fastgpt,在该文件夹下创建config.json 和 docker-compose.yml 文件。
内容如下:
// 已使用 json5 进行解析,会自动去掉注释,无需手动去除
{"feConfigs": {"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。},"systemEnv": {"vectorMaxProcess": 15,"qaMaxProcess": 15,"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。},"llmModels": [{"model": "gpt-4o-mini", // 模型名(对应OneAPI中渠道的模型名)"name": "gpt-4o-mini", // 模型别名"avatar": "/imgs/model/openai.svg", // 模型的logo"maxContext": 125000, // 最大上下文"maxResponse": 16000, // 最大回复"quoteMaxToken": 120000, // 最大引用内容"maxTemperature": 1.2, // 最大温度"charsPointsPrice": 0, // n积分/1k token(商业版)"censor": false, // 是否开启敏感校验(商业版)"vision": true, // 是否支持图片输入"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型"customExtractPrompt": "", // 自定义内容提取提示词"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)},{"model": "gpt-4o","name": "gpt-4o","avatar": "/imgs/model/openai.svg","maxContext": 125000,"maxResponse": 4000,"quoteMaxToken": 120000,"maxTemperature": 1.2,"charsPointsPrice": 0,"censor": false,"vision": true,"datasetProcess": true,"usedInClassify": true,"usedInExtractFields": true,"usedInToolCall": true,"usedInQueryExtension": true,"toolChoice": true,"functionCall": false,"customCQPrompt": "","customExtractPrompt": "","defaultSystemChatPrompt": "","defaultConfig": {},"fieldMap": {}},{"model": "o1-mini","name": "o1-mini","avatar": "/imgs/model/openai.svg","maxContext": 125000,"maxResponse": 4000,"quoteMaxToken": 120000,"maxTemperature": 1.2,"charsPointsPrice": 0,"censor": false,"vision": false,"datasetProcess": true,"usedInClassify": true,"usedInExtractFields": true,"usedInToolCall": true,"usedInQueryExtension": true,"toolChoice": false,"functionCall": false,"customCQPrompt": "","customExtractPrompt": "","defaultSystemChatPrompt": "","defaultConfig": {"temperature": 1,"stream": false},"fieldMap": {"max_tokens": "max_completion_tokens"}},{"model": "o1-preview","name": "o1-preview","avatar": "/imgs/model/openai.svg","maxContext": 125000,"maxResponse": 4000,"quoteMaxToken": 120000,"maxTemperature": 1.2,"charsPointsPrice": 0,"censor": false,"vision": false,"datasetProcess": true,"usedInClassify": true,"usedInExtractFields": true,"usedInToolCall": true,"usedInQueryExtension": true,"toolChoice": false,"functionCall": false,"customCQPrompt": "","customExtractPrompt": "","defaultSystemChatPrompt": "","defaultConfig": {"temperature": 1,"stream": false},"fieldMap": {"max_tokens": "max_completion_tokens"}}],"vectorModels": [{"model": "text-embedding-ada-002", // 模型名(与OneAPI对应)"name": "Embedding-2", // 模型展示名"avatar": "/imgs/model/openai.svg", // logo"charsPointsPrice": 0, // n积分/1k token"defaultToken": 700, // 默认文本分割时候的 token"maxToken": 3000, // 最大 token"weight": 100, // 优先训练权重"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)"queryConfig": {} // 参训时的额外参数},{"model": "text-embedding-3-large","name": "text-embedding-3-large","avatar": "/imgs/model/openai.svg","charsPointsPrice": 0,"defaultToken": 512,"maxToken": 3000,"weight": 100,"defaultConfig": {"dimensions": 1024}},{"model": "text-embedding-3-small","name": "text-embedding-3-small","avatar": "/imgs/model/openai.svg","charsPointsPrice": 0,"defaultToken": 512,"maxToken": 3000,"weight": 100}],"reRankModels": [],"audioSpeechModels": [{"model": "tts-1","name": "OpenAI TTS1","charsPointsPrice": 0,"voices": [{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }]}],"whisperModel": {"model": "whisper-1","name": "Whisper1","charsPointsPrice": 0}
}# 数据库的默认账号和密码仅首次运行时设置有效
# 如果修改了账号密码,记得改数据库和项目连接参数,别只改一处~
# 该配置文件只是给快速启动,测试使用。正式使用,记得务必修改账号密码,以及调整合适的知识库参数,共享内存等。
# 如何无法访问 dockerhub 和 git,可以用阿里云(阿里云没有arm包)version: '3.3'
services:# dbpg:image: pgvector/pgvector:0.7.0-pg15 # docker hub# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.7.0 # 阿里云container_name: pgrestart: alwaysports: # 生产环境建议不要暴露- 5432:5432networks:- fastgptenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- POSTGRES_USER=username- POSTGRES_PASSWORD=password- POSTGRES_DB=postgresvolumes:- ./pg/data:/var/lib/postgresql/datamongo:image: mongo:5.0.18 # dockerhub# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云# image: mongo:4.4.29 # cpu不支持AVX时候使用container_name: mongorestart: alwaysports:- 27017:27017networks:- fastgptcommand: mongod --keyFile /data/mongodb.key --replSet rs0environment:- MONGO_INITDB_ROOT_USERNAME=myusername- MONGO_INITDB_ROOT_PASSWORD=mypasswordvolumes:- ./mongo/data:/data/dbentrypoint:- bash- -c- |openssl rand -base64 128 > /data/mongodb.keychmod 400 /data/mongodb.keychown 999:999 /data/mongodb.keyecho 'const isInited = rs.status().ok === 1if(!isInited){rs.initiate({_id: "rs0",members: [{ _id: 0, host: "mongo:27017" }]})}' > /data/initReplicaSet.js# 启动MongoDB服务exec docker-entrypoint.sh "$$@" &# 等待MongoDB服务启动until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; doecho "Waiting for MongoDB to start..."sleep 2done# 执行初始化副本集的脚本mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程wait $$!# fastgptsandbox:container_name: sandboximage: ghcr.io/labring/fastgpt-sandbox:latest # git# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:latest # 阿里云networks:- fastgptrestart: alwaysfastgpt:container_name: fastgptimage: ghcr.io/labring/fastgpt:v4.8.9 # git# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.9 # 阿里云ports:- 3020:3000networks:- fastgptdepends_on:- mongo- pg- sandboxrestart: alwaysenvironment:# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。- DEFAULT_ROOT_PSW=1234# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。- OPENAI_BASE_URL=http://oneapi:3000/v1# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)- CHAT_API_KEY=sk-fastgpt# 数据库最大连接数- DB_MAX_LINK=30# 登录凭证密钥- TOKEN_KEY=any# root的密钥,常用于升级时候的初始化请求- ROOT_KEY=root_key# 文件阅读加密- FILE_TOKEN_KEY=filetoken# MongoDB 连接参数. 用户名myusername,密码mypassword。- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin# pg 连接参数- PG_URL=postgresql://username:password@pg:5432/postgres# sandbox 地址- SANDBOX_URL=http://sandbox:3000# 日志等级: debug, info, warn, error- LOG_LEVEL=info- STORE_LOG_LEVEL=warnvolumes:- ./config.json:/app/data/config.json# oneapimysql:# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36 # 阿里云image: mysql:8.0.36container_name: mysqlrestart: alwaysports:- 3306:3306networks:- fastgptcommand: --default-authentication-plugin=mysql_native_passwordenvironment:# 默认root密码,仅首次运行有效MYSQL_ROOT_PASSWORD: oneapimmysqlMYSQL_DATABASE: oneapivolumes:- ./mysql:/var/lib/mysqloneapi:container_name: oneapiimage: ghcr.io/songquanpeng/one-api:v0.6.7# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6 # 阿里云ports:- 3001:3000depends_on:- mysqlnetworks:- fastgptrestart: alwaysenvironment:# mysql 连接参数- SQL_DSN=root:oneapimmysql@tcp(mysql:3306)/oneapi# 登录凭证加密密钥- SESSION_SECRET=oneapikey# 内存缓存- MEMORY_CACHE_ENABLED=true# 启动聚合更新,减少数据交互频率- BATCH_UPDATE_ENABLED=true# 聚合更新时长- BATCH_UPDATE_INTERVAL=10# 初始化的 root 密钥(建议部署完后更改,否则容易泄露)- INITIAL_ROOT_TOKEN=fastgptvolumes:- ./oneapi:/data
networks:fastgpt:(将fastgpt的ports修改为3020:3000)
对于该配置文件下载时存在三个版本,如何选择依据下图:

(3)下载镜像
docker-compose up -d # 一次性启动所有服务,若本地没有该服务镜像则会先下载(4)安装ollama
Ollama是管理和运行大型语言模型的开源工具。其功能特点包括:可在本地运行大型语言模型,保障数据隐私与安全;支持多种模型管理,方便用户按需拉取切换;轻量级,对系统资源要求相对合理,能在多种设备运行;具有简单的命令行界面,易于使用。在应用场景方面,对开发者而言,能在本地快速搭建测试环境,提高开发效率;对普通用户来说,可用于个人创作任务并确保数据安全,是一款功能实用且易用的工具。
ollama安装地址 | ollama仓库地址
ollama常用命令:
ollama pull <model - name>:用于从 Ollama 的模型库中拉取指定名称的模型到本地ollama list:该命令会列出已经下载到本地的所有模型ollama run <model - name>:启动指定名称的模型
(5)安装M3E
# 1.拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest# 2.启动镜像(2种方式根据实际情况选择)
# 使用CPU运行
docker run -d --name m3e -p 6100:6008 registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
# nvida-docker 使用GPU
docker run -d --name m3e -p 6100:6008 --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api测试是否安装成功:
curl --location 'http://localhost:6100/v1/embeddings' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
--data '{
"model": "m3e",
"input": [
"laf是什么"
]
}'(6)通过one-api配置国内大模型(以qwen)
根据设定的端口,在浏览器内输入localhost:3001,默认账号为root密码为123456
(端口号在docker-compose.yml文件中查看)
在渠道中配置 通义千问和M3E。
a. 通义千问配置
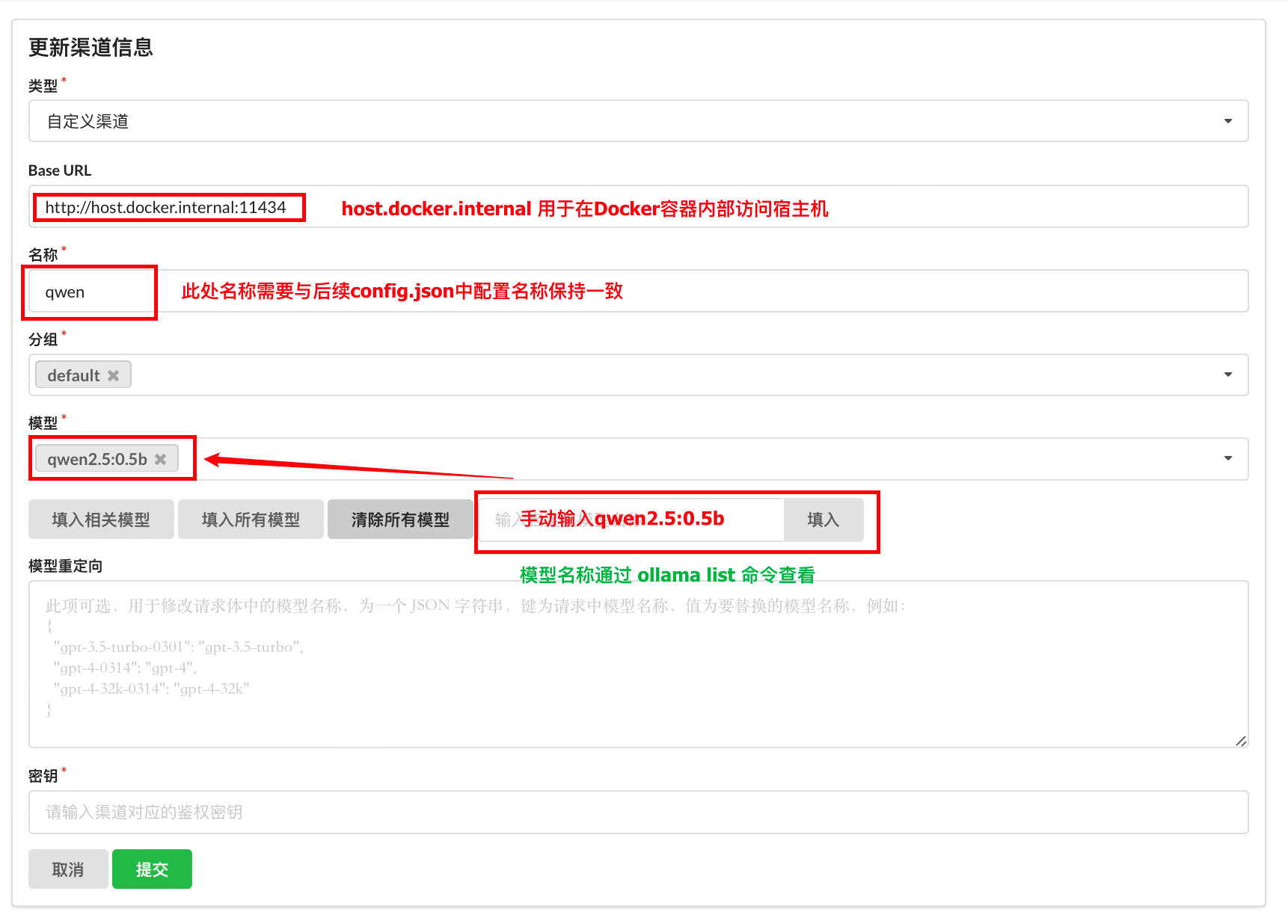

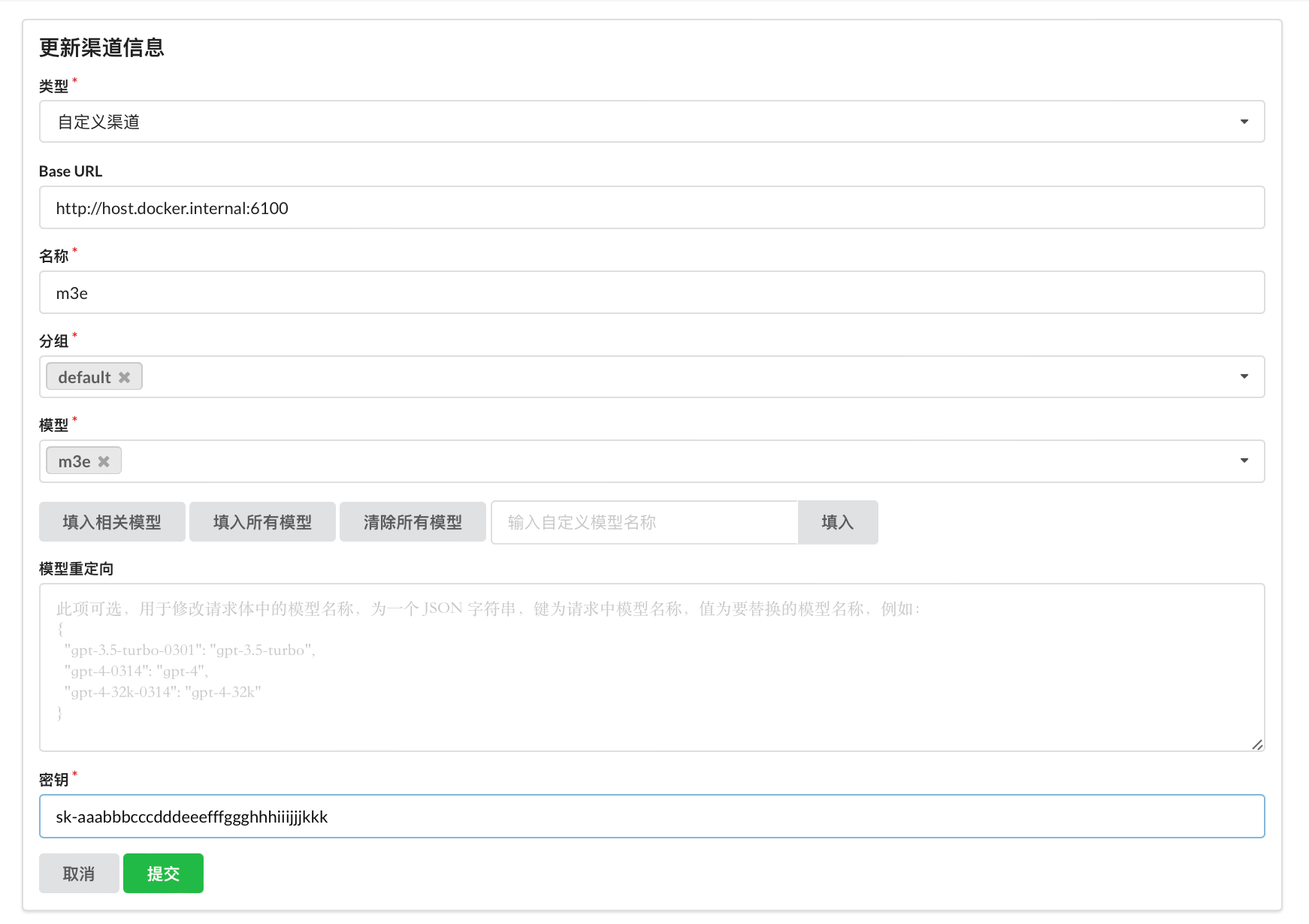
b. M3E配置
密钥默认设置为: sk-aaabbbcccdddeeefffggghhhiiijjjkkk
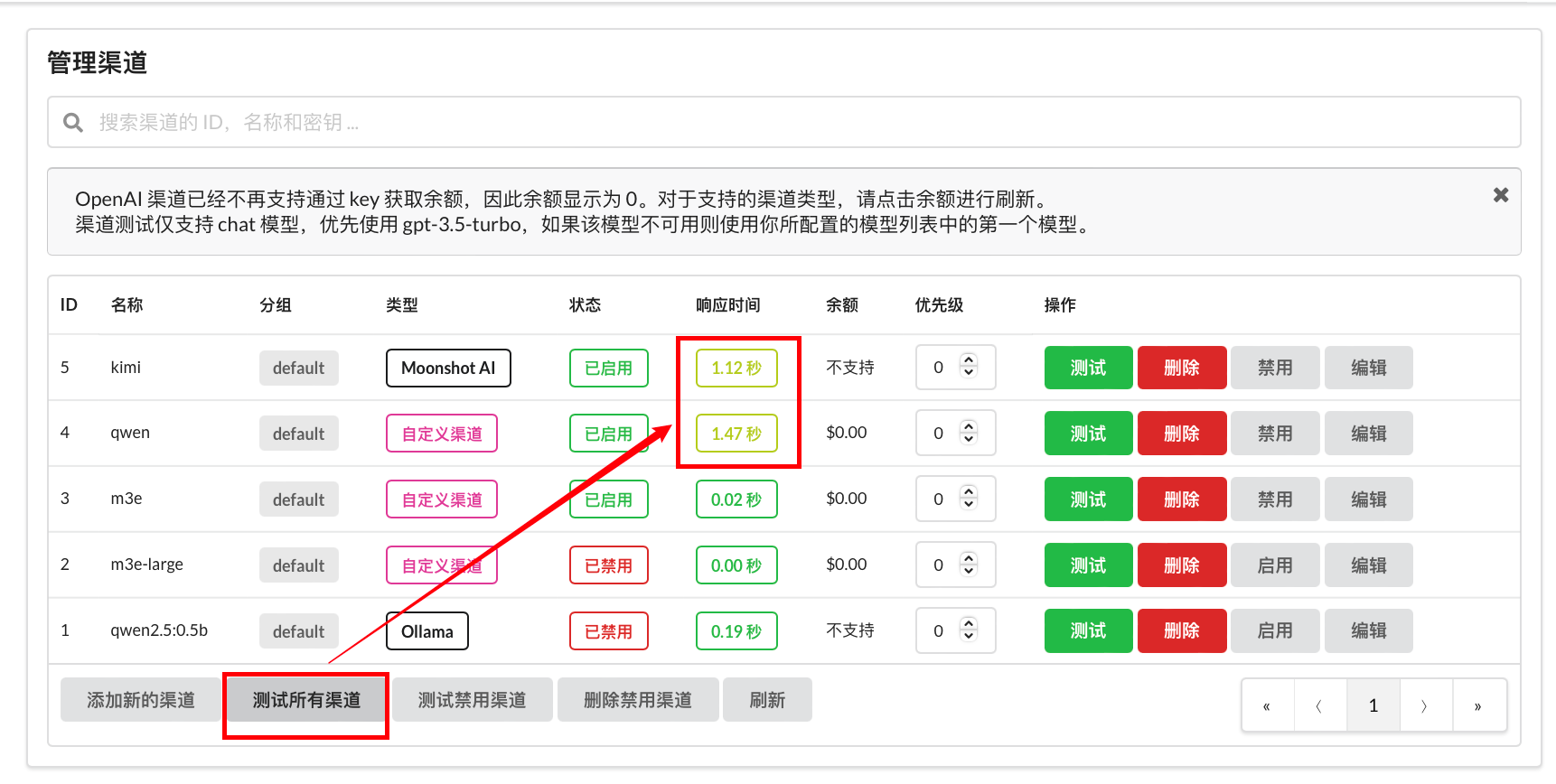
c.测试所有渠道
(7)将模型集成进fastgpt
修改config.json文件
"chatModels": [...#新增一个模型配置{"model": "qwen2.5:0.5b", // 模型名(对应OneAPI中渠道的模型名)"name": "qwen", // 模型别名"avatar": "/imgs/model/openai.svg", // 模型的logo"maxContext": 8000, // 最大上下文"maxResponse": 8000, // 最大回复"quoteMaxToken": 8000, // 最大引用内容"maxTemperature": 1.2, // 最大温度"charsPointsPrice": 0, // n积分/1k token(商业版)"censor": false, // 是否开启敏感校验(商业版)"vision": true, // 是否支持图片输入"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型"customExtractPrompt": "", // 自定义内容提取提示词"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)},...
]# 添加m3e向量模型
"vectorModels": [......{"model": "m3e","name": "m3e","avatar": "/imgs/model/openai.svg","charsPointsPrice": 0,"defaultToken": 700,"maxToken": 3000,"weight": 100},......
](其中name的值需要与one-api渠道配置中的名称保持一致,model的值需要与模型名称保持一致)
docker-compose down
docker-compose up -d(8) 测试
访问fastgpt:http://localhost:3020
知识库 - 新建知识库
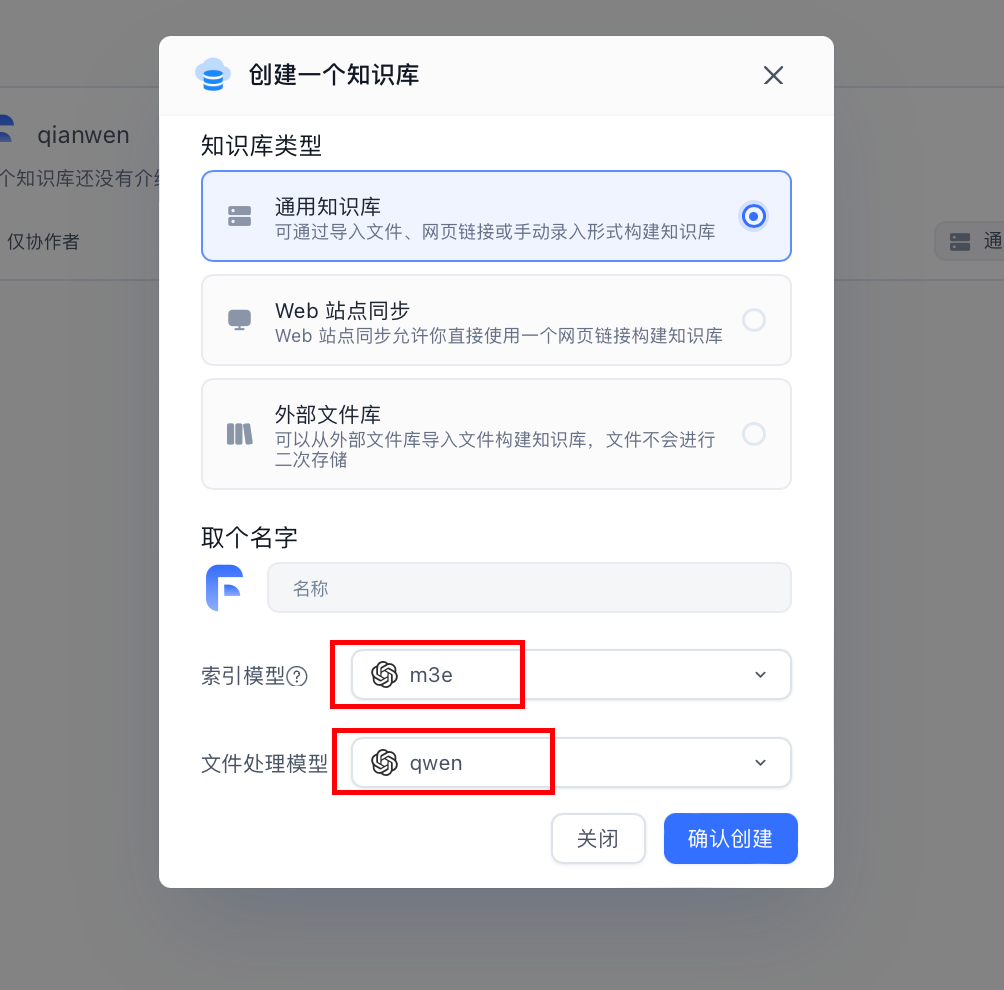
成功!!
相关文章:
Fastgpt本地化部署 - 以MAC为例
1.认识fastgpt 2.私有化部署 MongoDB:用于存储除了向量外的各类数据PostgreSQL/Milvus:存储向量数据OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验) (1&a…...

SpringBoot框架下购物推荐网站的设计模式与实现
3系统分析 3.1可行性分析 通过对本东大每日推购物推荐网站实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本东大每日推购物推荐网站采用JAVA作为开发语言&…...

Apache Flink 和 Apache Kafka
Apache Flink 和 Apache Kafka 都是大数据生态系统中非常重要的工具,但它们的作用和应用场景有所不同。下面将分别介绍两者的主要特性和它们之间的异同点。 Apache Kafka 作用: 消息队列:Kafka 主要作为消息队列使用,用于解耦生…...

Excel中Ctrl+e的用法
重点:想要使用ctrle,前提是整合或拆分后的结果放置的单元格必须和被提取信息的单元格相邻,且被提取信息的单元格也必须相连。 下图为错误示例 这样则可以使用ctrle 1、信息整合 2、提取信息 3、添加符号 4、信息顺序调换 5、数字提取 crtle还…...

07-Cesium动态处理线条闪烁材质的属性
这段代码定义了 LineFlickerMaterialProperty 类,用于管理线条闪烁材质的属性。构造函数接收颜色和速度作为选项,类包含动态属性 isConstant 和 definitionChanged,以及获取材质类型和当前属性值的方法。getValue 方法返回颜色和速度的当前值,equals 方法用于比较两个实例是…...

postgresql16分区表解析
PostgreSQL 16 引入了对分区表的多项改进,增强了其性能和可用性。本文介绍PostgreSQL 16 中分区表功能,包括基本概念、创建方法、管理技巧以及一些最佳实践。 分区表的基本概念 分区表是一种将大表物理分割成更小、更易管理的部分的技术。每个部分称为…...

文字识别解决方案-OCR识别应用场景解析
光学字符识别(Optical Character Recognition, OCR)技术是一种将图像中的文字转换为可编辑和可搜索的数据的技术。随着人工智能和机器学习的发展,OCR技术的应用场景越来越广泛,为文字录入场景带来了革命性的变革,下面以…...

Qt 每日面试题 -9
81、请写一个调用消息对话框提示报错的程序 QMessageBox::waring(this,tr("警告"), tr("用户名或密码错误!"),QMessageBox::Yes)82、Qt都提供哪些标准对话框以供使用,他们实现什么功能? Qt提供9个标准对话框: QColorDialog 颜色对话框&…...

K8s环境下使用sidecar模式对EMQX的exhook.proto 进行流量代理
背景 在使用emqx作为mqtt时需要我们需要拦截client的各种行为,如连接,发送消息,认证等。除了使用emqx自带的插件机制。我们也可以用多语言-钩子扩展来实现这个功能,但是目前emqx仅仅支持单个grpc服务端的设置,所以会有…...

Dirble:一款高性能目录扫描与爬取工具
今天给大家介绍的是一款名叫Dirble工具,它是一款易于使用的高性能网站目录扫描工具。该工具针对Windows和Linux平台设计,在Dirble的帮助下,广大安全研究人员可以快速对目标站点进行目录扫描和资源爬取。 工具安装 广大研究人员可以使用下列…...

C#语言基础
GitHub - babbittry/Csharp-notes: C# 课程笔记https://github.com/babbittry/Csharp-notes?tabreadme-ov-file#net%E6%98%AF%E4%BB%80%E4%B9%88 C# 数据类型 | 菜鸟教程 (runoob.com)https://www.runoob.com/csharp/csharp-data-types.html 语法基础 一、命名空间、类、方…...

网络分析仪——提升网络性能的关键工具
目录 什么是网络分析仪? 1. 实时流量监控 2. 历史数据回溯分析 3. 网络性能关键指标监测 4. 可视化界面与报告生成 总结 在当今的数字化世界,网络的稳定性和性能直接影响企业的运营效率。网络拥堵、延迟和丢包等问题会导致用户体验的下降ÿ…...

简单认识Maven 1
1.基本概念 Maven 是一个开源的项目管理和构建工具,主要用于 Java 项目,但也支持其他基于 JVM(Java Virtual Machine)的项目,如 Scala、Groovy 等。它基于项目对象模型(Project Object Model,P…...

鼠标右键删除使用Visual Studio 打开(v)以及恢复【超详细】
鼠标右键删除使用Visual Studio 打开(v) 1. 引言2. 打开注册表3. 进入对应的注册表地址4. 右键删除 AnyCode 项5. 效果6. 备份注册表文件——恢复菜单 1. 引言 安装完 Visual Studio 鼠标右键总有 “使用Visual Studio 打开(v)”,让右键菜单…...

如何缩短微商城系统推广周期
前言 微商城系统的推广周期是企业关注的重点之一。为了缩短推广周期,企业需要采取一系列有效的策略和措施。以下是对如何缩短微商城系统推广周期的详细介绍: 一、明确目标用户群体 在推广之前,企业需要明确自己的目标用户群体是谁…...

电脑如何清理重复文件?方法很简单!
清理重复文件能够有效释放存储空间,提高系统运行效率。长期堆积的重复文件会导致硬盘空间不足,从而影响系统性能。此外,清理文件还能帮助用户更好地管理和组织文件,避免因文件混乱而浪费时间。 常见的重复文件类型 重复文件可以是…...

【Linux】ioctl分析
简介 一个字符设备驱动通常会实现常规的open、release、read和write接口,但是如果需要扩展新的功能,通常以ioctl接口的方式实现。 #mermaid-svg-uY8EyPklf5e4ZMQo {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill…...

物联网通信会给人们的生活带来什么样的变化
物联网(IoT)通信的崛起正以前所未有的速度改变着人们的生活方式。从智能家居、智能交通到远程医疗、工业自动化,物联网技术的应用已经渗透到我们日常生活的方方面面。以下是对物联网通信如何具体影响并改变人们生活的详细探讨。 一、智能家居…...

Android 中获取当前 CPU 频率和占用率
最近在优化 App 的性能,需要获取当前 CPU视频频率和占用率,通过查询资料,大致思路如下: 目前没有标准的 API 来获取 CPU 的使用频率,只能通过读取指定 CPU 文件获取当前 CPU 频率,在某些机器或者特定版本中…...

pymobiledevice3使用介绍(安装、常用命令、访问iOS沙盒目录)
项目地址:https://github.com/doronz88/pymobiledevice3 首先先介绍一下pymobiledevice3, pymobiledevice3是用Python3 实现的,用于处理 iDevices(iPhone 等)。它可以跨平台使用,支持:windows…...

【JAVA基础面经】深拷贝与浅拷贝
文章目录基本概念浅拷贝深拷贝重写 clone() 方法实现深拷贝使用序列化实现深拷贝使用复制构造函数或工厂方法基本概念 浅拷贝:创建一个新对象,然后将原对象的非静态字段(基本类型和引用类型)直接复制到新对象中。对于引用类型字段…...

S2-Pro+C语言教学系统:代码逻辑讲解与典型错误自动纠正
S2-ProC语言教学系统:代码逻辑讲解与典型错误自动纠正 1. 智能编程助教初体验 第一次看到S2-Pro在C语言教学中的应用效果时,确实让人眼前一亮。想象一下,当学生提交一段指针运算代码后,系统不仅能指出错误,还能像经验…...
)
OpenCompass本地评测大模型实战指南(2025最新版)
1. 为什么你需要OpenCompass本地评测 最近两年大模型发展太快了,各种新模型层出不穷。作为开发者,你是不是经常遇到这样的困惑:这个新发布的模型到底效果如何?和之前用的模型相比优势在哪里?官方公布的benchmark数据靠…...

[Android] 鲁迅全集 7.2.0
[Android] 鲁迅全集 7.2.0 链接:https://pan.xunlei.com/s/VOp2ylhHGYlTTbQ2rTOhsk3RA1?pwdh6tu# 鲁迅作品全集!!!...

Python与OPC UA实战:高效读写PLC数据
1. 为什么选择Python操作OPC UA? 在工业自动化领域,PLC(可编程逻辑控制器)就像工厂的"大脑",而OPC UA则是让这个大脑与其他系统对话的"普通话"。作为Python开发者,我们经常需要从PLC读…...

Docker 容器技术 第一节---定义、概念、安装CentOS 7 Linux系统、MobaXterm中安装docker-ce
一、Docker的定义Docker是一款开源的容器化平台,它能将应用及其依赖的环境、配置、库等打包成轻量可移植的容器,既保证了不同环境下应用运行的一致性,又以共享宿主机内核的方式实现了比传统虚拟机更高效的资源利用和秒级启动速度,…...

5分钟零代码部署:Live2D AI虚拟助手让你的网站活起来
5分钟零代码部署:Live2D AI虚拟助手让你的网站活起来 【免费下载链接】live2d_ai 基于live2d.js实现的动画小人ai,拥有聊天功能,还有图片识别功能,可以嵌入到网页里 项目地址: https://gitcode.com/gh_mirrors/li/live2d_ai …...

Phi-4-mini-reasoning实操手册:针对数学题优化的token长度设置技巧
Phi-4-mini-reasoning实操手册:针对数学题优化的token长度设置技巧 1. 模型特点与适用场景 Phi-4-mini-reasoning是一个专为推理任务优化的文本生成模型,特别适合处理需要多步分析的数学题和逻辑题。与通用聊天模型不同,它被设计为直接输出…...

从零到一:AI工程开源资源全栈指南与实战应用
从零到一:AI工程开源资源全栈指南与实战应用 【免费下载链接】aie-book [WIP] Resources for AI engineers. Also contains supporting materials for the book AI Engineering (Chip Huyen, 2025) 项目地址: https://gitcode.com/GitHub_Trending/ai/aie-book …...

Allegro 17.4约束管理器实战:从基础规则到高速PCB设计优化
1. Allegro约束管理器入门指南 刚接触Allegro 17.4的工程师经常会问:为什么我的PCB设计总是出现DRC报错?为什么高速信号总是不稳定?其实问题的关键往往在于约束管理器的使用。作为Cadence Allegro的核心功能模块,约束管理器就像PC…...