L1练习-鸢尾花数据集处理(分类/聚类)
背景
前文(《AI 自学 Lesson1 - Sklearn(开源Python机器学习包)》)以鸢尾花数据集的处理为例,本文将完善其代码,在使用 sklearn 的部分工具包基础上,增加部分数据预处理、数据分析和数据可视化。
由于鸢尾花数据集适用于进行分类和聚类的练习,这里使用多种分类和聚类方式,并验证其准确性。同时在概念部分对分类和聚类的种类、库、用法等进行补充介绍。
并在文首附上跑通资源,便于直接查看处理结果。
一、补充概念
1. 分类
在 sklearn 中,常见的分类算法涵盖了从简单的线性模型到复杂的非线性模型。以下是一些常见的分类算法及其对应的库名称:
| 算法名称 | 库名称 | 描述 | 适用场景 | |
|---|---|---|---|---|
| 1 | 逻辑回归(Logistic Regression) | sklearn.linear_model.LogisticRegression | 基于逻辑函数的线性分类模型,用于二分类或多分类问题。 | 线性可分的二分类或多分类任务。 |
| 2 | 支持向量机(SVM) | sklearn.svm.SVC, sklearn.svm.LinearSVC | 高效的分类算法,适用于处理高维空间和非线性分类问题。 | 高维数据、复杂的非线性分类任务。 |
| 3 | K近邻(KNN) | sklearn.neighbors.KNeighborsClassifier | 基于距离测量进行分类,适用于小型数据集。 | 小数据集、特征空间维度较低的分类任务。 |
| 4 | 决策树(Decision Tree) | sklearn.tree.DecisionTreeClassifier | 基于树状结构的分类模型,能够处理非线性分类任务。 | 非线性数据的分类,易于解释和可视化。 |
| 5 | 随机森林(Random Forest) | sklearn.ensemble.RandomForestClassifier | 集成多个决策树,提升分类的准确性和鲁棒性。 | 处理大规模、高维数据,减少过拟合。 |
| 6 | 朴素贝叶斯(Naive Bayes) | sklearn.naive_bayes.GaussianNB, sklearn.naive_bayes.MultinomialNB | 基于贝叶斯定理的概率分类模型,假设特征之间相互独立。 | 文本分类、特征独立的分类任务。 |
| 7 | 梯度提升树(Gradient Boosting) | sklearn.ensemble.GradientBoostingClassifier | 通过多个弱分类器的组合逐步提升分类性能,适用于复杂数据。 | 非线性、高维数据的复杂分类任务。 |
| 8 | 极限梯度提升(XGBoost) | xgboost.XGBClassifier | 高效的梯度提升算法实现,适合处理大规模数据,性能优异。 | 高性能分类任务,常用于竞赛和大数据处理。 |
| 9 | 多层感知器(MLP) | sklearn.neural_network.MLPClassifier | 基于神经网络的多层感知器模型,能够处理复杂的非线性分类问题。 | 深度学习相关的分类任务,非线性数据的分类。 |
2. 聚类
在 sklearn 中,常见的聚类算法涵盖了从基本的距离度量方法到更复杂的层次聚类和密度聚类。以下是常用的聚类算法及其对应的库名称:
| 算法名称 | 库名称 | 描述 | 适用场景 | |
|---|---|---|---|---|
| 1 | K均值聚类(K-Means Clustering) | sklearn.cluster.KMeans | 基于质心的聚类算法,通过质心划分数据,适用于线性可分数据。 | 线性可分的数据,聚类数已知的情况下。 |
| 2 | 层次聚类(Hierarchical Clustering) | sklearn.cluster.AgglomerativeClustering | 通过构建层次树对数据进行聚类,能够发现数据的层次结构。 | 需要构建层次结构的聚类任务。 |
| 3 | DBSCAN(密度聚类) | sklearn.cluster.DBSCAN | 基于密度的聚类算法,能够发现任意形状的簇,适合带噪声数据。 | 发现任意形状的簇,处理噪声数据。 |
| 4 | 均值漂移(Mean Shift Clustering) | sklearn.cluster.MeanShift | 基于核密度估计的非参数聚类算法,能够自动找到簇的数量。 | 高密度区域的聚类,适合未知簇数的情况。 |
| 5 | 谱聚类(Spectral Clustering) | sklearn.cluster.SpectralClustering | 基于图论的聚类算法,适合非线性或高维数据。 | 非线性数据或高维空间的聚类任务。 |
| 6 | 高斯混合模型(Gaussian Mixture Model, GMM) | sklearn.mixture.GaussianMixture | 基于概率模型的聚类算法,假设数据来自多个高斯分布的混合。 | 处理复杂分布的聚类任务,适合有重叠的簇。 |
| 7 | Birch(平衡迭代减少与聚类) | sklearn.cluster.Birch | 高效的层次聚类算法,适合处理大规模数据集。 | 大规模数据的层次聚类任务。 |
| 8 | 亲和传播(Affinity Propagation) | sklearn.cluster.AffinityPropagation | 通过消息传递进行聚类,适用于自动确定簇数。 | 自动发现簇数,适合不需要预设簇数的聚类任务。 |
| 9 | MiniBatch K-Means | sklearn.cluster.MiniBatchKMeans | KMeans 的小批量变体,适合处理大规模数据。 | 大规模数据集的聚类任务,提升计算效率。 |
在后续代码部分,将使用【分类】中的 逻辑回归、k近邻、支持向量机、朴素贝叶斯、决策树 分别对鸢尾花数据集进行处理,并判断各模型算法的准确性;【聚类】中的 K均值聚类、层次聚类、DBSCAN 分别对鸢尾花数据集进行聚类处理,,并判断各模型算法的准确性。
3. 交叉验证
交叉验证是用于评估模型泛化能力的技术,它通过多次划分数据集来减少偶然性,常见的是 K折交叉验证(K-Fold Cross-Validation),即将数据分成K份,每次用其中的一份作为验证集,剩下的作为训练集,重复K次,最后取平均准确率作为模型的性能评估。
通过多次划分数据集,减少模型在某一特定训练集上表现过好的风险,保证模型在未知数据上的性能稳定。
作用
- 稳定性:通过多次分割数据,确保模型在不同数据集上的表现一致。
- 评估泛化能力:避免模型过拟合到某一个特定的训练集。
- 综合评估模型性能:通过平均和标准差的计算,得到模型在多次验证下的表现。
4. F1得分(F1 Score)
- F1得分 是用于分类任务中的一种综合指标,它是 精确率(Precision) 和 召回率(Recall) 的调和平均数,主要用于不平衡数据集(即某些类别出现的频率较高,另一些类别则较低)。
- 精确率(Precision):模型预测为正类的样本中,真正为正类的比例。
- 召回率(Recall):真实为正类的样本中,模型正确预测为正类的比例。
5. 超参数调优
KNN 的一个关键超参数是 K值(近邻个数),不同的 K 值会影响模型的性能。为了找到最合适的 K 值,我们可以使用 网格搜索(Grid Search) 结合交叉验证来进行超参数调优。此外,还可以调优距离度量方法(如 p 值,决定使用欧几里得距离或曼哈顿距离等)。
通过网格搜索或随机搜索选择最优的超参数组合,能够显著提升模型性能,避免欠拟合或过拟合。
作用
- 优化模型性能:通过选择合适的超参数,可以显著提升模型的表现。
- 避免过拟合:调整参数如正则化强度、树的深度等,可以防止模型过度拟合训练数据。
- 增强泛化能力:经过调优后的模型在未知数据上能有更好的预测能力。
二、代码
1. 准备阶段
#导入内置的鸢尾花数据
from sklearn.datasets import load_iris
import pandas as pd
import numpy as npiris = load_iris()
print(iris)#导入所需包
import seaborn as sns #数据可视化
import matplotlib.pyplot as plt #绘图
import pandas as pd #数据分析from sklearn.model_selection import train_test_split #数据划分
from sklearn.preprocessing import StandardScaler #数据标准化from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.neighbors import KNeighborsClassifier #K近邻分类
from sklearn.svm import SVC #支持向量机
from sklearn.naive_bayes import GaussianNB #朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.metrics import accuracy_score from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN #聚类库
from sklearn.metrics import adjusted_rand_score, silhouette_score
from sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import cross_val_score #K折交叉验证
from sklearn.model_selection import GridSearchCV #超参数调优-网格搜索#数据集属性描述
print("特征值:\n",iris.data)
print("目标值:\n",iris["target"])
print("特征值名字:\n",iris.feature_names)
print("目标值名字:\n",iris.target_names)
print("数据集描述:\n",iris.DESCR)iris_d = pd.DataFrame(data=iris.data,columns=['sepal length', 'sepal width', 'petal length', 'petal width'])iris_d#查看数据类型信息
iris_d.info()2. 数据可视化
iris_d["target"] = iris.target#定义函数iris_plot,定义三个变量
#使用seaborn进行数据可视化,对应函数变量第一位为数据,第二位为横轴名,第三位为纵轴名
def iris_plot(data,col1,col2):sns.lmplot(x=col1,y=col2,data=data,hue="target",fit_reg=False)plt.show()#显示可视化图表#使用数据为iris_d,横轴为名为sepal width,纵轴名为petal length
iris_plot(iris_d,'sepal width','petal length')3. 数据预处理
分为数据划分和数据转换。
#定义数据、标签
X = iris.data
y = iris.target#进行数据划分
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=42#,stratify=y,test_size=0.3#,shuffle=True)
#将完整数据集的70%作为训练集,30%作为测试集,
#可通过使得设置 stratify=y 测试集和训练集中各类别数据的比例与原始数据集比例一致(stratify分层策略)
#可通过设置 shuffle=True 提前打乱数据print("训练集的目标值形状:\n",y_train.shape)
print("测试集的目标值形状:\n",y_test.shape)#构建转换器实例
scaler = StandardScaler( )#拟合及转换
scaler.fit_transform(X_train)
X_scaled = scaler.fit_transform(X)4. 分类
# 1. 逻辑回归
logistic_model = LogisticRegression(max_iter=200)
logistic_model.fit(X_train, y_train)
y_pred_logistic = logistic_model.predict(X_test)
accuracy_logistic = accuracy_score(y_test, y_pred_logistic)
print(f"逻辑回归分类准确率: {accuracy_logistic:.2f}")# 2. K近邻(KNN)
knn_model = KNeighborsClassifier(n_neighbors=5)
knn_model.fit(X_train, y_train)
y_pred_knn = knn_model.predict(X_test)
accuracy_knn = accuracy_score(y_test, y_pred_knn)
print(f"K近邻分类准确率: {accuracy_knn:.2f}")# 3. 支持向量机
svm_model = SVC()
svm_model.fit(X_train, y_train)
y_pred_svm = svm_model.predict(X_test)
accuracy_svm = accuracy_score(y_test, y_pred_svm)
print(f"支持向量机分类准确率: {accuracy_svm:.2f}")# 4. 朴素贝叶斯
nb_model = GaussianNB()
nb_model.fit(X_train, y_train)
y_pred_nb = nb_model.predict(X_test)
accuracy_nb = accuracy_score(y_test, y_pred_nb)
print(f"朴素贝叶斯分类准确率: {accuracy_nb:.2f}")# 5. 决策树
tree_model = DecisionTreeClassifier()
tree_model.fit(X_train, y_train)
y_pred_tree = tree_model.predict(X_test)
accuracy_tree = accuracy_score(y_test, y_pred_tree)
print(f"决策树分类准确率: {accuracy_tree:.2f}")输出结果
逻辑回归分类准确率: 1.00
K近邻分类准确率: 1.00
支持向量机分类准确率: 1.00
朴素贝叶斯分类准确率: 0.98
决策树分类准确率: 1.00
分析
- 在鸢尾花数据集上,逻辑回归、K近邻、支持向量机 和 决策树 都能达到 100% 的分类准确率,这说明这些模型在处理这个简单的三分类问题时表现非常好。
- 朴素贝叶斯 的准确率稍微低一点,约为 98%,这可能是由于鸢尾花数据集中的特征分布并非完全符合朴素贝叶斯的独立性假设,但仍然是一个较好的结果。
5. 聚类
# 1. K均值聚类
kmeans = KMeans(n_clusters=3, random_state=42)
y_pred_kmeans = kmeans.fit_predict(X_scaled)
ari_kmeans = adjusted_rand_score(y, y_pred_kmeans)
silhouette_kmeans = silhouette_score(X_scaled, y_pred_kmeans)
print(f"K均值 - Adjusted Rand Index: {ari_kmeans:.2f}, Silhouette Score: {silhouette_kmeans:.2f}")# 2. 层次聚类
hierarchical = AgglomerativeClustering(n_clusters=3)
y_pred_hierarchical = hierarchical.fit_predict(X_scaled)
ari_hierarchical = adjusted_rand_score(y, y_pred_hierarchical)
silhouette_hierarchical = silhouette_score(X_scaled, y_pred_hierarchical)
print(f"层次聚类 - Adjusted Rand Index: {ari_hierarchical:.2f}, Silhouette Score: {silhouette_hierarchical:.2f}")# 3. DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=5)
y_pred_dbscan = dbscan.fit_predict(X_scaled)
# 由于DBSCAN的标签中可能有-1(表示噪声),需过滤掉噪声点计算ARI和轮廓系数
ari_dbscan = adjusted_rand_score(y, y_pred_dbscan)
if len(set(y_pred_dbscan)) > 1: # 如果存在多个簇silhouette_dbscan = silhouette_score(X_scaled, y_pred_dbscan)
else:silhouette_dbscan = -1 # 如果只有一个簇或噪声
print(f"DBSCAN - Adjusted Rand Index: {ari_dbscan:.2f}, Silhouette Score: {silhouette_dbscan:.2f}")代码说明
- K均值:我们设置簇的数量为3(因为鸢尾花数据集包含3类标签),并使用
Adjusted Rand Index (ARI)和Silhouette Score来评估聚类效果。 - 层次聚类:我们同样设定簇数量为3,使用凝聚层次聚类(自底向上)。
- DBSCAN:使用基于密度的聚类方法,不需要指定簇的数量,但我们设置
eps=0.5,min_samples=5来控制聚类的密度参数。该方法对噪声点(标记为-1)进行自动处理。
输出结果
K均值 - Adjusted Rand Index: 0.62, Silhouette Score: 0.46
层次聚类 - Adjusted Rand Index: 0.62, Silhouette Score: 0.45
DBSCAN - Adjusted Rand Index: 0.44, Silhouette Score: 0.36
分析:
- K均值聚类 和 层次聚类 在鸢尾花数据集上的表现相似,ARI 均为 0.62,Silhouette Score 也接近,这表明它们能够较好地将数据聚成三类,且与真实标签有较高的一致性。
- DBSCAN 的 ARI 和 Silhouette Score 较低(如 0.44 和 0.36),这表明它在该数据集上的效果不如前两种算法。由于鸢尾花数据集的分布较为规则,DBSCAN 的密度聚类特性并不适合这个数据集。
6. 交叉验证
# 使用准确率作为评估标准
scores = cross_val_score(knn_model, X, y, cv=5, scoring='accuracy')# 输出交叉验证的平均准确率和标准差
print(f"KNN - 交叉验证准确率: {scores.mean():.2f} ± {scores.std():.2f}")# 使用加权F1得分作为评估标准
scores = cross_val_score(knn_model, X, y, cv=5, scoring='f1_weighted')# 输出加权F1得分的平均值和标准差
print(f"KNN - 加权F1得分: {scores.mean():.2f} ± {scores.std():.2f}")代码说明
scores.mean():计算5次交叉验证的平均准确率。- 交叉验证返回的是5次验证的准确率数组,
scores.mean()对这些值取平均,作为模型在不同划分下的总体表现。均值代表模型的总体准确率水平。
- 交叉验证返回的是5次验证的准确率数组,
scores.std():计算5次交叉验证准确率的标准差。- 标准差用于衡量模型准确率的波动程度。标准差越小,说明模型在不同数据划分下的表现越稳定;反之,如果标准差较大,表示模型的性能在不同数据集划分上差异较大,可能不够稳定。
7. 超参数调优
# 定义需要调优的超参数范围
param_grid = {'n_neighbors': [3, 5, 7, 9, 11], # K值(邻居数)'weights': ['uniform', 'distance'], # 权重'p': [1, 2] # p=1 曼哈顿距离, p=2 欧几里得距离
}# 使用网格搜索与K折交叉验证结合
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X, y)# 输出最佳参数和对应的交叉验证得分
print(f"最佳超参数组合: {grid_search.best_params_}")
print(f"最佳交叉验证准确率: {grid_search.best_score_:.2f}")简单来说就是通过字典给超参数不同维度的设置选择,使用搜索即是将所有组合的正确率都进行验证,并通过 grid_search.best_params_ 返回出最优组合。
相关文章:
L1练习-鸢尾花数据集处理(分类/聚类)
背景 前文(《AI 自学 Lesson1 - Sklearn(开源Python机器学习包)》)以鸢尾花数据集的处理为例,本文将完善其代码,在使用 sklearn 的部分工具包基础上,增加部分数据预处理、数据分析和数据可视化…...

javaweb以html方式集成富文本编辑器TinyMce
前言: 单一的批量图片上传按钮,禁用tinymce编辑器,但是还可以操作图片编辑; 多元化格式的富文本编辑要求; 采用tinymce实现。 附: tinymce中文手册网站: http://tinymce.ax-z.cn/download-all.…...

大学生福音!用GPT-4o几分钟内轻松读懂一篇论文!
文章目录 一、读论文智能体:PDFAI操作指导阅读论文上传论文并分析进一步研究导出可用代码 二、感受 一、读论文智能体:PDFAI 操作指导 ChatGPT 4o国内直接访问地址:https://share.xuzhugpt.cloud/ 上plus的车 输入购买的授权码即可。 默认…...

微信小程序昵称获取
<view class"shouquan_list"> <label>昵称</label> <input type"nickname" value"{{nichengshoudong}}" bindinput"bindKeyInputnicheng" placeholder"请输入昵称" placeholder-style"color:r…...

SQL进阶技巧:如何找出开会时间有重叠的会议室?| 时间区间重叠问题
目录 0 场景描述 1 数据准备 2 问题分析 方法1:利用 lateral view posexplode()函数将表展开成时间明细表 方法2:利用数学区间讨论思想求解 3 小结 如果觉得本文对你有帮助,想进一步学习SQL语言这门艺术的,那么不妨也可以选…...
 D 题解)
Educational Codeforces Round 170 (Rated for Div. 2) D 题解
to sum of:前三题都是究极水题,补补D题吧,dp太钛肽弱了.. Problem - D - Codeforces--Attribute Checks 思路:首先得坚定地确定m^2,然后剩下的复杂度思考怎么优化.. key:每一个0只考虑影响到下一个0之间的数字!! 定义dp[i][j]为,在有i个能力点时.点了…...

NeRS: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild
阅读记录: 1. 2.优点1:我们的方法仅依赖于近似的相机位姿估计和粗略的类别级形状模板。 3.我们的关键见解是,我们可以强制执行基于表面的 3D 表示,而不是允许广泛用于体积表示的无约束密度。重要的是,这允许依赖于视…...

【Linux】su 命令的运行原理以及su切换用户默认继承环境配置
一、su 命令的运行原理 原理解释: su(switch user)命令用于在Linux和Unix系统中切换用户身份。 当你执行 su 命令时,系统会创建一个新的进程,通常是一个新的 shell 实例。这个新进程会以目标用户的身份运行&#…...

libtorch环境配置
环境配置 建议在linux上配置对应环境 可以在autoDL上租一个服务器来搭建,带有pytorch的环境 https://www.autodl.com/home 我自己的win电脑上安装了pytorch,但是配置时会报错,于是到ubuntu上配置 电脑上装有pytorch的就不需要再下载libtorc…...
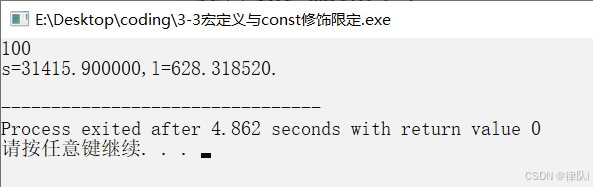
【C语言】define宏定义与const修饰限定
两者都是将字符替换为相应的数值。 区别在于: #define宏定义纸进行字符串替换,无类型检查 const修饰符限定变量为只读变量 #include <stdio.h> #define PI 3.14159 //符号常量 /* 功能:宏定义与const修饰符限定 时间:20…...

基于深度学习的基于视觉的机器人导航
基于深度学习的视觉机器人导航是一种通过深度学习算法结合视觉感知系统(如摄像头、LiDAR等)实现机器人在复杂环境中的自主导航的技术。这种方法使机器人能够像人类一样使用视觉信息感知环境、规划路径,并避开障碍物。与传统的导航方法相比&am…...
)
苍穹外卖学习笔记(二十三)
拒单 OrderController /*** 拒单*/PutMapping("/rejection")ApiOperation("拒单")public Result rejection(RequestBody OrdersRejectionDTO ordersRejectionDTO) throws Exception {orderService.rejection(ordersRejectionDTO);return Result.success(…...

vLLM 推理引擎性能分析基准测试
文章目录 分析步骤案例案例描述测试数据集 原始数据〇轮测试(enable-64)一轮测试(enable-128)二轮测试(enable-256)三轮测试(enable-512)四轮测试(enable-2048࿰…...

图像增强论文精读笔记-Kindling the Darkness: A Practical Low-light Image Enhancer(KinD)
1. 论文基本信息 论文标题:Kindling the Darkness: A Practical Low-light Image Enhancer 作者:Yonghua Zhang等 发表时间和期刊:2019;ACM MM 论文链接:https://arxiv.org/abs/1905.04161 2. 研究背景和动机 现有…...

HALCON数据结构之字符串
1.1 String字符串的基本操作 *将数字转换为字符串或修改字符串 *tuple_string (T, Format, String) //HALCON语句 *String: T $ Format //赋值操作*Format string 由以下四个部分组成: *<flags><field width>.<precision><conversion 字符&g…...

string模拟优化和vector使用
1.简单介绍编码 utf_8变长编码,常用英文字母使用1个字节,对于其它语言可能2到14,大部分编码是utf_8,char_16是编码为utf_16, char_32是编码为utf_32, wchar_t是宽字符的, utf_16是大小为俩个字节&a…...

Go-知识依赖GOPATH
Go-知识依赖GOPATH 1. 介绍2. GOROOT 是什么3. GOPATH 是什么4. 依赖查找5. GOPATH 的缺点1. 介绍 早期Go语言单纯地使用GOPATH管理依赖,但是GOPATH不方便管理依赖的多个版本,后来增加了vendor,允许把项目依赖 连同项目源码一同管理。Go 1.11 引入了全新的依赖管理工具 Go …...

PyTorch 中 reshape 函数用法示例
PyTorch 中 reshape 函数用法示例 在 PyTorch 中,reshape 函数用于改变张量的形状,而不改变其中的数据。下面是一些关于 reshape 函数的常见用法示例。 基本语法 torch.reshape(input, shape) # input: 要重塑的张量。 # shape: 目标形状࿰…...

安全光幕的工作原理及应用场景
安全光幕是一种利用光电传感技术来检测和响应危险情况的先进设备。其工作原理基于红外线传感器,通过发射红外光束并接收反射或透射光束来形成一道无形的屏障。以下是对安全光幕工作原理和应用场景的介绍: 工作原理 发射器与接收器:安全光幕通…...

《深度学习》OpenCV LBPH算法人脸识别 原理及案例解析
目录 一、LBPH算法 1、概念 2、实现步骤 3、方法 1)步骤1 • 缩放 • 旋转和平移 2)步骤2 二、案例实现 1、完整代码 1)图像内容: 2)运行结果: 一、LBPH算法 1、概念 在OpenCV中,L…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

使用libusb-win32驱动复活老旧USB硬件:以Elektor Magic Eye为例
1. 项目概述:让老硬件在新时代焕发新生手头有一台十多年前的《Elektor》杂志上刊登的“Magic Eye EM84”复古VFD显示屏项目,想把它接到Windows 10电脑上当个酷炫的CPU占用率显示器,却发现官方提供的“AVR309”USB驱动在新系统上彻底罢工了。这…...

AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程
AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要让你的…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...
)
DeepSeek代码审查能力白皮书(2024企业级实测报告)
更多请点击: https://kaifayun.com 第一章:DeepSeek代码审查能力白皮书(2024企业级实测报告)概述 本报告基于2024年Q1至Q3期间,面向金融、电信与云原生三大垂直行业的17家头部企业客户开展的深度实测,覆盖…...
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Window…...