51 | 适配器模式:代理、适配器、桥接、装饰,这四个模式有何区别?
前面几篇文章我们学习了代理模式、桥接模式、装饰器模式,今天,我们再来学习一个比较常用的结构型模式:适配器模式。这个模式相对来说还是比较简单、好理解的,应用场景也很具体,总体上来讲比较好掌握。
关于适配器模式,今天我们主要学习它的两种实现方式,类适配器和对象适配器,以及 5 种常见的应用场景。同时,我还会通过剖析 slf4j 日志框架,来给你展示这个模式在真实项目中的应用。除此之外,在文章的最后,我还对代理、桥接、装饰器、适配器,这 4 种代码结构非常相似的设计模式做简单的对比,对这几篇内容做一个简单的总结。
话不多说,让我们正式开始今天的学习吧!
适配器模式的原理与实现
适配器模式的英文翻译是 Adapter Design Pattern。顾名思义,这个模式就是用来做适配的,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作。对于这个模式,有一个经常被拿来解释它的例子,就是 USB 转接头充当适配器,把两种不兼容的接口,通过转接变得可以一起工作。
原理很简单,我们再来看下它的代码实现。适配器模式有两种实现方式:类适配器和对象适配器。其中,类适配器使用继承关系来实现,对象适配器使用组合关系来实现。具体的代码实现如下所示。其中,ITarget 表示要转化成的接口定义。Adaptee 是一组不兼容 ITarget 接口定义的接口,Adaptor 将 Adaptee 转化成一组符合 ITarget 接口定义的接口。
// 类适配器: 基于继承
public interface ITarget {void f1();void f2();void fc();
}public class Adaptee {public void fa() { //... }public void fb() { //... }public void fc() { //... }
}public class Adaptor extends Adaptee implements ITarget {public void f1() {super.fa();}public void f2() {//...重新实现f2()...}// 这里fc()不需要实现,直接继承自Adaptee,这是跟对象适配器最大的不同点
}// 对象适配器:基于组合
public interface ITarget {void f1();void f2();void fc();
}public class Adaptee {public void fa() { //... }public void fb() { //... }public void fc() { //... }
}public class Adaptor implements ITarget {private Adaptee adaptee;public Adaptor(Adaptee adaptee) {this.adaptee = adaptee;}public void f1() {adaptee.fa(); //委托给Adaptee}public void f2() {//...重新实现f2()...}public void fc() {adaptee.fc();}
}
针对这两种实现方式,在实际的开发中,到底该如何选择使用哪一种呢?判断的标准主要有两个,一个是 Adaptee 接口的个数,另一个是 Adaptee 和 ITarget 的契合程度。
- 如果 Adaptee 接口并不多,那两种实现方式都可以。
- 如果 Adaptee 接口很多,而且 Adaptee 和 ITarget 接口定义大部分都相同,那我们推荐使用类适配器,因为 Adaptor 复用父类 Adaptee 的接口,比起对象适配器的实现方式,Adaptor 的代码量要少一些。
- 如果 Adaptee 接口很多,而且 Adaptee 和 ITarget 接口定义大部分都不相同,那我们推荐使用对象适配器,因为组合结构相对于继承更加灵活。
适配器模式应用场景总结
原理和实现讲完了,都不复杂。我们再来看,到底什么时候会用到适配器模式呢?
一般来说,适配器模式可以看作一种“补偿模式”,用来补救设计上的缺陷。应用这种模式算是“无奈之举”。如果在设计初期,我们就能协调规避接口不兼容的问题,那这种模式就没有应用的机会了。
前面我们反复提到,适配器模式的应用场景是“接口不兼容”。那在实际的开发中,什么情况下才会出现接口不兼容呢?我建议你先自己思考一下这个问题,然后再来看我下面的总结 。
1. 封装有缺陷的接口设计
假设我们依赖的外部系统在接口设计方面有缺陷(比如包含大量静态方法),引入之后会影响到我们自身代码的可测试性。为了隔离设计上的缺陷,我们希望对外部系统提供的接口进行二次封装,抽象出更好的接口设计,这个时候就可以使用适配器模式了。
具体我还是举个例子来解释一下,你直接看代码应该会更清晰。具体代码如下所示:
public class CD { //这个类来自外部sdk,我们无权修改它的代码//...public static void staticFunction1() { //... }public void uglyNamingFunction2() { //... }public void tooManyParamsFunction3(int paramA, int paramB, ...) { //... }public void lowPerformanceFunction4() { //... }
}// 使用适配器模式进行重构
public interface ITarget {void function1();void function2();void fucntion3(ParamsWrapperDefinition paramsWrapper);void function4();//...
}
// 注意:适配器类的命名不一定非得末尾带Adaptor
public class CDAdaptor extends CD implements ITarget {//...public void function1() {super.staticFunction1();}public void function2() {super.uglyNamingFucntion2();}public void function3(ParamsWrapperDefinition paramsWrapper) {super.tooManyParamsFunction3(paramsWrapper.getParamA(), ...);}public void function4() {//...reimplement it...}
}
2. 统一多个类的接口设计
某个功能的实现依赖多个外部系统(或者说类)。通过适配器模式,将它们的接口适配为统一的接口定义,然后我们就可以使用多态的特性来复用代码逻辑。具体我还是举个例子来解释一下。
假设我们的系统要对用户输入的文本内容做敏感词过滤,为了提高过滤的召回率,我们引入了多款第三方敏感词过滤系统,依次对用户输入的内容进行过滤,过滤掉尽可能多的敏感词。但是,每个系统提供的过滤接口都是不同的。这就意味着我们没法复用一套逻辑来调用各个系统。这个时候,我们就可以使用适配器模式,将所有系统的接口适配为统一的接口定义,这样我们可以复用调用敏感词过滤的代码。
你可以配合着下面的代码示例,来理解我刚才举的这个例子。
public class ASensitiveWordsFilter { // A敏感词过滤系统提供的接口//text是原始文本,函数输出用***替换敏感词之后的文本public String filterSexyWords(String text) {// ...}public String filterPoliticalWords(String text) {// ...}
}public class BSensitiveWordsFilter { // B敏感词过滤系统提供的接口public String filter(String text) {//...}
}public class CSensitiveWordsFilter { // C敏感词过滤系统提供的接口public String filter(String text, String mask) {//...}
}// 未使用适配器模式之前的代码:代码的可测试性、扩展性不好
public class RiskManagement {private ASensitiveWordsFilter aFilter = new ASensitiveWordsFilter();private BSensitiveWordsFilter bFilter = new BSensitiveWordsFilter();private CSensitiveWordsFilter cFilter = new CSensitiveWordsFilter();public String filterSensitiveWords(String text) {String maskedText = aFilter.filterSexyWords(text);maskedText = aFilter.filterPoliticalWords(maskedText);maskedText = bFilter.filter(maskedText);maskedText = cFilter.filter(maskedText, "***");return maskedText;}
}// 使用适配器模式进行改造
public interface ISensitiveWordsFilter { // 统一接口定义String filter(String text);
}public class ASensitiveWordsFilterAdaptor implements ISensitiveWordsFilter {private ASensitiveWordsFilter aFilter;public String filter(String text) {String maskedText = aFilter.filterSexyWords(text);maskedText = aFilter.filterPoliticalWords(maskedText);return maskedText;}
}
//...省略BSensitiveWordsFilterAdaptor、CSensitiveWordsFilterAdaptor...// 扩展性更好,更加符合开闭原则,如果添加一个新的敏感词过滤系统,
// 这个类完全不需要改动;而且基于接口而非实现编程,代码的可测试性更好。
public class RiskManagement { private List<ISensitiveWordsFilter> filters = new ArrayList<>();public void addSensitiveWordsFilter(ISensitiveWordsFilter filter) {filters.add(filter);}public String filterSensitiveWords(String text) {String maskedText = text;for (ISensitiveWordsFilter filter : filters) {maskedText = filter.filter(maskedText);}return maskedText;}
}
3. 替换依赖的外部系统
当我们把项目中依赖的一个外部系统替换为另一个外部系统的时候,利用适配器模式,可以减少对代码的改动。具体的代码示例如下所示:
// 外部系统A
public interface IA {//...void fa();
}
public class A implements IA {//...public void fa() { //... }
}
// 在我们的项目中,外部系统A的使用示例
public class Demo {private IA a;public Demo(IA a) {this.a = a;}//...
}
Demo d = new Demo(new A());// 将外部系统A替换成外部系统B
public class BAdaptor implemnts IA {private B b;public BAdaptor(B b) {this.b= b;}public void fa() {//...b.fb();}
}
// 借助BAdaptor,Demo的代码中,调用IA接口的地方都无需改动,
// 只需要将BAdaptor如下注入到Demo即可。
Demo d = new Demo(new BAdaptor(new B()));
4. 兼容老版本接口
在做版本升级的时候,对于一些要废弃的接口,我们不直接将其删除,而是暂时保留,并且标注为 deprecated,并将内部实现逻辑委托为新的接口实现。这样做的好处是,让使用它的项目有个过渡期,而不是强制进行代码修改。这也可以粗略地看作适配器模式的一个应用场景。同样,我还是通过一个例子,来进一步解释一下。
JDK1.0 中包含一个遍历集合容器的类 Enumeration。JDK2.0 对这个类进行了重构,将它改名为 Iterator 类,并且对它的代码实现做了优化。但是考虑到如果将 Enumeration 直接从 JDK2.0 中删除,那使用 JDK1.0 的项目如果切换到 JDK2.0,代码就会编译不通过。为了避免这种情况的发生,我们必须把项目中所有使用到 Enumeration 的地方,都修改为使用 Iterator 才行。
单独一个项目做 Enumeration 到 Iterator 的替换,勉强还能接受。但是,使用 Java 开发的项目太多了,一次 JDK 的升级,导致所有的项目不做代码修改就会编译报错,这显然是不合理的。这就是我们经常所说的不兼容升级。为了做到兼容使用低版本 JDK 的老代码,我们可以暂时保留 Enumeration 类,并将其实现替换为直接调用 Itertor。代码示例如下所示:
public class Collections {public static Emueration emumeration(final Collection c) {return new Enumeration() {Iterator i = c.iterator();public boolean hasMoreElments() {return i.hashNext();}public Object nextElement() {return i.next():}}}
}
5. 适配不同格式的数据
前面我们讲到,适配器模式主要用于接口的适配,实际上,它还可以用在不同格式的数据之间的适配。比如,把从不同征信系统拉取的不同格式的征信数据,统一为相同的格式,以方便存储和使用。再比如,Java 中的 Arrays.asList() 也可以看作一种数据适配器,将数组类型的数据转化为集合容器类型。
List<String> stooges = Arrays.asList("Larry", "Moe", "Curly");
剖析适配器模式在 Java 日志中的应用
Java 中有很多日志框架,在项目开发中,我们常常用它们来打印日志信息。其中,比较常用的有 log4j、logback,以及 JDK 提供的 JUL(java.util.logging) 和 Apache 的 JCL(Jakarta Commons Logging) 等。
大部分日志框架都提供了相似的功能,比如按照不同级别(debug、info、warn、erro……)打印日志等,但它们却并没有实现统一的接口。这主要可能是历史的原因,它不像 JDBC 那样,一开始就制定了数据库操作的接口规范。
如果我们只是开发一个自己用的项目,那用什么日志框架都可以,log4j、logback 随便选一个就好。但是,如果我们开发的是一个集成到其他系统的组件、框架、类库等,那日志框架的选择就没那么随意了。
比如,项目中用到的某个组件使用 log4j 来打印日志,而我们项目本身使用的是 logback。将组件引入到项目之后,我们的项目就相当于有了两套日志打印框架。每种日志框架都有自己特有的配置方式。所以,我们要针对每种日志框架编写不同的配置文件(比如,日志存储的文件地址、打印日志的格式)。如果引入多个组件,每个组件使用的日志框架都不一样,那日志本身的管理工作就变得非常复杂。所以,为了解决这个问题,我们需要统一日志打印框架。
如果你是做 Java 开发的,那 Slf4j 这个日志框架你肯定不陌生,它相当于 JDBC 规范,提供了一套打印日志的统一接口规范。不过,它只定义了接口,并没有提供具体的实现,需要配合其他日志框架(log4j、logback……)来使用。
不仅如此,Slf4j 的出现晚于 JUL、JCL、log4j 等日志框架,所以,这些日志框架也不可能牺牲掉版本兼容性,将接口改造成符合 Slf4j 接口规范。Slf4j 也事先考虑到了这个问题,所以,它不仅仅提供了统一的接口定义,还提供了针对不同日志框架的适配器。对不同日志框架的接口进行二次封装,适配成统一的 Slf4j 接口定义。具体的代码示例如下所示:
// slf4j统一的接口定义
package org.slf4j;
public interface Logger {public boolean isTraceEnabled();public void trace(String msg);public void trace(String format, Object arg);public void trace(String format, Object arg1, Object arg2);public void trace(String format, Object[] argArray);public void trace(String msg, Throwable t);public boolean isDebugEnabled();public void debug(String msg);public void debug(String format, Object arg);public void debug(String format, Object arg1, Object arg2)public void debug(String format, Object[] argArray)public void debug(String msg, Throwable t);//...省略info、warn、error等一堆接口
}// log4j日志框架的适配器
// Log4jLoggerAdapter实现了LocationAwareLogger接口,
// 其中LocationAwareLogger继承自Logger接口,
// 也就相当于Log4jLoggerAdapter实现了Logger接口。
package org.slf4j.impl;
public final class Log4jLoggerAdapter extends MarkerIgnoringBaseimplements LocationAwareLogger, Serializable {final transient org.apache.log4j.Logger logger; // log4jpublic boolean isDebugEnabled() {return logger.isDebugEnabled();}public void debug(String msg) {logger.log(FQCN, Level.DEBUG, msg, null);}public void debug(String format, Object arg) {if (logger.isDebugEnabled()) {FormattingTuple ft = MessageFormatter.format(format, arg);logger.log(FQCN, Level.DEBUG, ft.getMessage(), ft.getThrowable());}}public void debug(String format, Object arg1, Object arg2) {if (logger.isDebugEnabled()) {FormattingTuple ft = MessageFormatter.format(format, arg1, arg2);logger.log(FQCN, Level.DEBUG, ft.getMessage(), ft.getThrowable());}}public void debug(String format, Object[] argArray) {if (logger.isDebugEnabled()) {FormattingTuple ft = MessageFormatter.arrayFormat(format, argArray);logger.log(FQCN, Level.DEBUG, ft.getMessage(), ft.getThrowable());}}public void debug(String msg, Throwable t) {logger.log(FQCN, Level.DEBUG, msg, t);}//...省略一堆接口的实现...
}
所以,在开发业务系统或者开发框架、组件的时候,我们统一使用 Slf4j 提供的接口来编写打印日志的代码,具体使用哪种日志框架实现(log4j、logback……),是可以动态地指定的(使用 Java 的 SPI 技术,这里我不多解释,你自行研究吧),只需要将相应的 SDK 导入到项目中即可。
不过,你可能会说,如果一些老的项目没有使用 Slf4j,而是直接使用比如 JCL 来打印日志,那如果想要替换成其他日志框架,比如 log4j,该怎么办呢?实际上,Slf4j 不仅仅提供了从其他日志框架到 Slf4j 的适配器,还提供了反向适配器,也就是从 Slf4j 到其他日志框架的适配。我们可以先将 JCL 切换为 Slf4j,然后再将 Slf4j 切换为 log4j。经过两次适配器的转换,我们就能成功将 JCL 切换为了 log4j。
代理、桥接、装饰器、适配器 4 种设计模式的区别
代理、桥接、装饰器、适配器,这 4 种模式是比较常用的结构型设计模式。它们的代码结构非常相似。笼统来说,它们都可以称为 Wrapper 模式,也就是通过 Wrapper 类二次封装原始类。
尽管代码结构相似,但这 4 种设计模式的用意完全不同,也就是说要解决的问题、应用场景不同,这也是它们的主要区别。这里我就简单说一下它们之间的区别。
代理模式:代理模式在不改变原始类接口的条件下,为原始类定义一个代理类,主要目的是控制访问,而非加强功能,这是它跟装饰器模式最大的不同。
桥接模式:桥接模式的目的是将接口部分和实现部分分离,从而让它们可以较为容易、也相对独立地加以改变。
装饰器模式:装饰者模式在不改变原始类接口的情况下,对原始类功能进行增强,并且支持多个装饰器的嵌套使用。
适配器模式:适配器模式是一种事后的补救策略。适配器提供跟原始类不同的接口,而代理模式、装饰器模式提供的都是跟原始类相同的接口。
重点回顾
好了,今天的内容到此就讲完了。让我们一块来总结回顾一下,你需要重点掌握的内容。
适配器模式是用来做适配,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作。适配器模式有两种实现方式:类适配器和对象适配器。其中,类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
一般来说,适配器模式可以看作一种“补偿模式”,用来补救设计上的缺陷。应用这种模式算是“无奈之举”,如果在设计初期,我们就能协调规避接口不兼容的问题,那这种模式就没有应用的机会了。
那在实际的开发中,什么情况下才会出现接口不兼容呢?我总结下了下面这样 5 种场景:
- 封装有缺陷的接口设计
- 统一多个类的接口设计
- 替换依赖的外部系统
- 兼容老版本接口
- 适配不同格式的数据
相关文章:

51 | 适配器模式:代理、适配器、桥接、装饰,这四个模式有何区别?
前面几篇文章我们学习了代理模式、桥接模式、装饰器模式,今天,我们再来学习一个比较常用的结构型模式:适配器模式。这个模式相对来说还是比较简单、好理解的,应用场景也很具体,总体上来讲比较好掌握。 关于适配器模式…...

ORM框架简介
什么是ORM? ORM(Object-Relational Mapping,对象关系映射)是一种编程技术,用于在关系数据库和对象程序语言之间转换数据。ORM框架允许开发者以面向对象的方式来操作数据库,而不需要编写复杂的SQL语句。简单…...

Windows系统上根据端口号查找对应进程
“开始”-“运行”,输入cmd,打开命令行窗口,输入netstat和findstr的组合,找出占用了4118的端口的进程 根据上述PID,使用tasklist和findstr的组合,找出对应进程是dsa.exe 要想kill此进程,可以打开…...
一文通透OpenAI o1:从CoT、Quiet-STaR、Self-Correct、Self-play RL、MCST等技术细节到工程复现
前言 注意,本文自10.12日起,正在每天更新的过程中,包括已写的部分也在不断修改(以增加更多技术细节、更加通俗易懂) 预计10.20完成第一版,10月底修订到第二版——具体修订记录详见本文文末.. 可能是去年写或讲的关于ChatGPT原理的…...

如何解决与kernel32.dll相关的常见错误:详细指南解析kernel32.dll文件缺失、损坏或错误加载问题
当你的电脑中出现错误kernel32.dll丢失的问题,会导致电脑不能出现正常运行,希望能够有效的帮助你有效的将丢失的kernel32.dll文件进行修复同时也给大家介绍一些关于kernel32.dll文件的相关介绍,希望能够有效的帮助你快速修复错误。 kernel32.…...
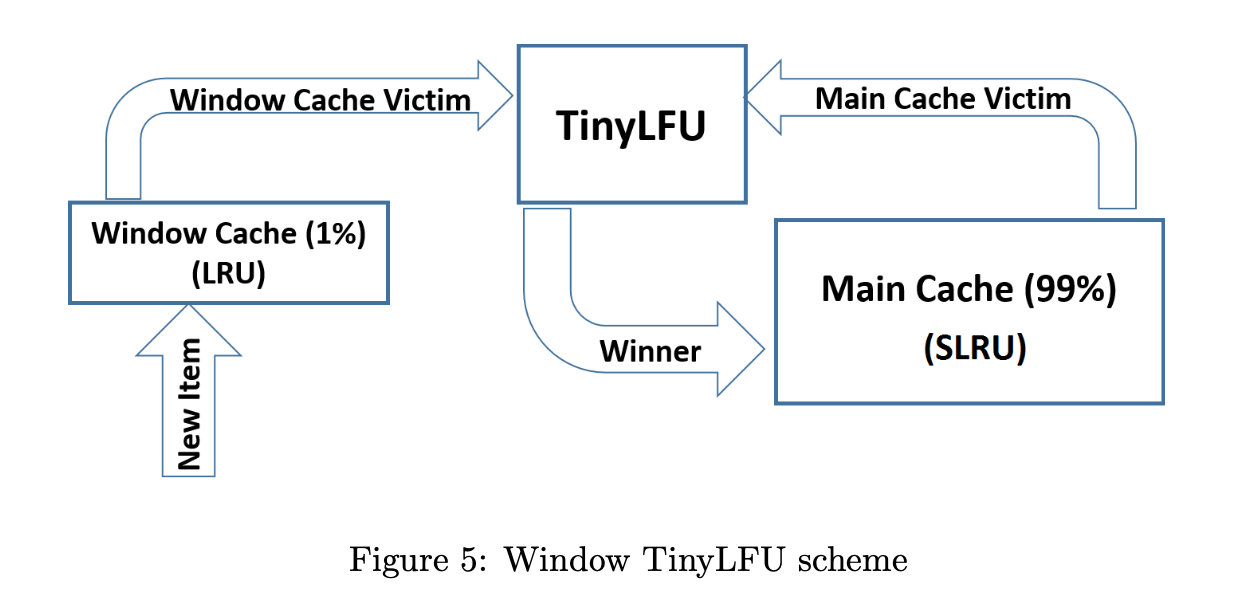
Caffeine Cache解析(一):接口设计与TinyLFU
Caffeine is a high performance Java caching library providing a near optimal hit rate. 自动加载value, 支持异步加载基于size的eviction:frequency and recency基于时间的过期策略:last access or last write异步更新valuekey支持weak referenceva…...

深入探索LINUX中AWK命令:强大的文本处理工具
深入探索LINUX中AWK命令:强大的文本处理工具 AWK 是一种编程语言,专为文本和数据处理设计,它以其强大的文本处理能力和简洁的语法在 Unix/Linux 系统中占据了重要地位。AWK 程序由一系列的模式(pattern)和动作(action)组成,对于输…...

数字化转型:解决项目管理困境的新路径
在当今这个飞速发展的数字化时代,企业如同在汹涌波涛中航行的船只,承受着前所未有的变革压力。而作为企业运作核心环节之一的项目管理,同样面临着巨大的挑战。 传统项目管理模式中的种种问题,犹如顽固的礁石,阻碍着项目…...

Arthas常用的命令(三)--monitor、jad 、stack
monitor:监控方法的执行情况 监控指定类中方法的执行情况 用来监视一个时间段中指定方法的执行次数,成功次数,失败次数,耗时等这些信息 参数说明 方法拥有一个命名参数 [c:],意思是统计周期(cycle of ou…...

Power BI之常用DAX函数使用介绍——提供数据源练习
前述: 本次使用数据是包含产品表、客户表、区域表、销售订单表的一份销售订单数据,数据源链接如下: 链接:https://pan.baidu.com/s/1micl_09hFrgz2aUBERkeZg 提取码:y17e 一、CALCULATE 1.语法结构 语法结构CALCUL…...
的详解以及代码演示)
SQL-触发器(trigger)的详解以及代码演示
一、触发器的概念 触发器是一种特殊的存储过程,但是触发器不存在输入和输出参数,所以不能被显式的去调用,而是与特定的表相关联,当表中的数据发生变化时,触发器被激活并执行其定义的SQL代码。触发器可以是行级触发器&…...

【devops】x-ui 实现一键安装 x-ray 打造高速国际冲浪 | xray管理平台
一、部署X-UI篇 1、Github 地址&说明 github地址如下: https://github.com/FranzKafkaYu/x-ui?tabreadme-ov-file 2、一键部署 2.1、更新并安装curl #Ubuntu、Deibian系统 apt update && apt upgrade -y apt install curl -y #CentOS7 系统 yum…...

Linux系统编程——进程标识、进程创建
一、进程标识(pid) 每个进程都有一个非负整数形式的唯一编号,即 PID。PID 在任何时刻都是唯一的,但是可以重用,当进程终止并被回收以后,其 PID 就可以为其它进程所用。进程的 PID 由系统内核根据延迟重用算…...

【超级福利】openMind开源实习来袭,奖励高达万元,解锁你的AI实践新篇章!
亲爱的小伙伴们,是不是梦想着能在真实的项目中大展拳脚,却又苦于找不到合适的舞台?别担心,OpenI启智社区携手openMind Library工具链,为你量身打造了一场开源实习盛宴,保证让你的学习不再无聊,技…...

React JSX 使用条件语句渲染UI的两种写法
只针对函数组件 1. 第一种写法: function App({ id }) {return id1? <h1>hello</h1> : <h1>world</h1>; } 或者: function App({ id }) {return (<h1>{id1 && "hello" || id2 && "wo…...

谷歌-BERT-第四步:模型部署
1 需求 需求1:基于gradio实现大模型的WEB UI交互界面 2 接口 3 示例 import gradio as gr from transformers import *classifier pipeline("text-classification", model"./model", tokenizer"./model")gr.Interface.from_pipel…...

猫咪化身蒲公英,浮毛满屋乱飞,有哪些宠物空气净化器值得购买?
不掉毛的猫咪究竟是谁在养? 当初去朋友家玩,被猫咪捕获芳心,没多久自己也领养了一只。没想到啊,这就意味着要和猫毛纠缠一辈子了。平时白天上班不在家,它就在一边跑动一边掉毛,回到家我都能推断它的行动路…...
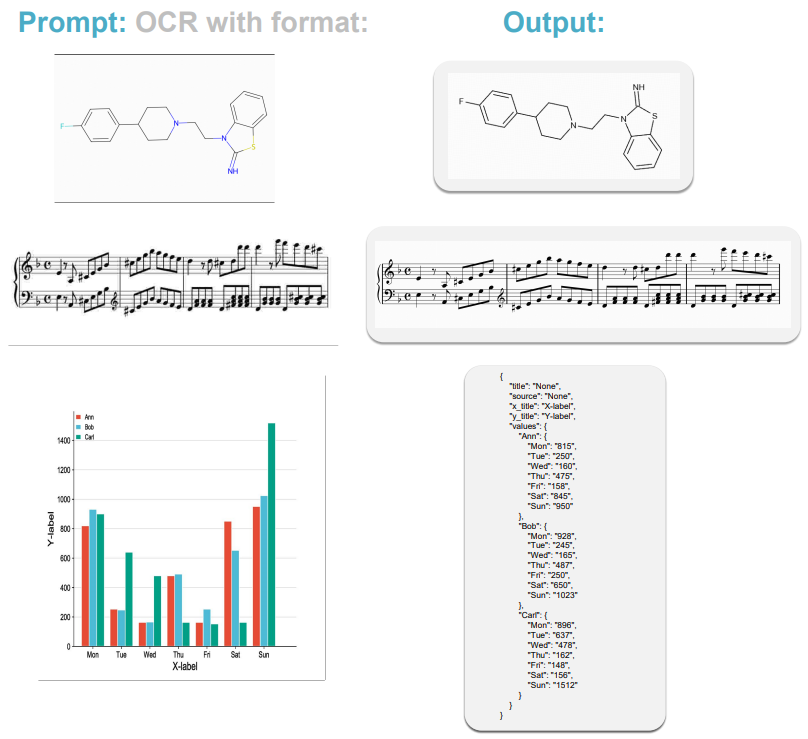
端到端的开源OCR模型:GOT-OCR-2.0,支持场景文本、文档、乐谱、图表、数学公式等内容识别!
今天给大家分享一个端到端的开源 OCR 模型,号称 OCR 2.0! 支持场景文本、文档、乐谱、图表、数学公式等内容识别,拿到了 BLEU 0.972 高分。 从给出的演示图来看,一些非常复杂的数学公式都能正确的识别,颇为强大。模型…...

自注意力机制self-attention中QKV矩阵的含义
自注意力机制(Self-Attention)是Transformer模型的核心组件,其中Q、K、V矩阵分别代表查询(Query)、键(Key)、值(Value)。它们的作用和含义可以通过信息匹配过程来理解。在…...
)
【前端】Bootstrap:栅格系统 (Grid System)
Bootstrap的栅格系统是该框架的核心部分之一,能够让开发者轻松创建响应式网页布局,适配各种屏幕尺寸和设备。栅格系统通过将页面划分为12列的布局结构,开发者可以根据内容的重要性和设计需求灵活控制元素的宽度和排列。 在这篇文章中&#x…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

NanaZip:现代Windows文件压缩问题的终极解决方案
NanaZip:现代Windows文件压缩问题的终极解决方案 【免费下载链接】NanaZip The 7-Zip derivative intended for the modern Windows experience 项目地址: https://gitcode.com/gh_mirrors/na/NanaZip 还在为Windows文件压缩工具界面老旧、功能单一而烦恼吗&…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

三步破解百度网盘限速:免费获取真实下载链接的终极指南
三步破解百度网盘限速:免费获取真实下载链接的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而苦恼吗?想要彻…...

服务器数据下载安全:实时加密与动态访问控制实战
1. 这不是又一个“加个密码”的方案,而是服务器数据流动的实时安检闸机IP-guard安全网关——这个名字在企业IT运维圈里,常被误读为“桌面端U盘管控工具”或“员工上网行为审计系统”。但真正用过它来守服务器的人,会立刻意识到:它…...