端到端的开源OCR模型:GOT-OCR-2.0,支持场景文本、文档、乐谱、图表、数学公式等内容识别!
今天给大家分享一个端到端的开源 OCR 模型,号称 OCR 2.0! 支持场景文本、文档、乐谱、图表、数学公式等内容识别,拿到了 BLEU 0.972 高分。
从给出的演示图来看,一些非常复杂的数学公式都能正确的识别,颇为强大。模型大小仅 1.43GB,感兴趣的小伙伴可以试试。

OCR一直是离落地最近的研究方向之一,是AI-1.0时代的技术结晶。到了以LLM(LVLM)为核心的AI-2.0时代,OCR成了多模大模型的一项基本能力,各家模型甚至有梭哈之势。多模态大模型作为通用模型,总有种降维打击OCR模型的感觉。那么纯OCR的研究真的到头了吗?我们想说:当然没有!没准才刚刚开始。首先盘一下AI-1.0 OCR系统和LVLM OCR的缺点:
首先是AI-1.0流水线式的OCR系统,缺点不用多说,各个模块比较独立,局部最优,维护成本也大。最重要的是不通用,不同OCR任务需路由不同模型,不太方便。那么多模态大模型在pure OCR任务上有什么缺陷呢?我们认为有以下两点:
-
为Reasoning让路必然导致image token数量过多,进而导致在纯OCR任务上存在bottle-neck。Reasoning(VQA-like)能力来自LLM(decoder),要想获得更好的VQA能力(至少在刷点上),就要充分利用起LLM来,那么image token就得越像text token(至少高维上,这样就会让LLM更舒服)。试想一下,100个text token在LLM词表上能编码多少文字?那么一页PDF的文字,又需要多少token呢?不难发现,保VQA就会导致在做OCR任务上,尤其是dense OCR任务上,模型搞得比较丑陋。 例如,一页PDF图片只有A4纸大小,很多LVLM要都需要切图做OCR,切出几千个image token。单张都要切图,拿出多页PDF拼接图,阁下又当如何应对?我们认为对于OCR模型这么多token大可不必。
-
非常直观的一点就是模型太大,迭代困难。要想引入新OCR feature如支持一项新语言,不是SFT一下就能训进模型的,得打开vision encoder做pre-training或者post-training,这都是相当耗资源的。对于OCR需求来说太浪费了。有人会说,小模型能同时做好这么多OCR任务吗?我们的答案是肯定的,而且甚至还能更好。
相关链接
论文地址:https://arxiv.org/abs/2409.0170
代码地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.0/tree/main
模型下载:huggingface.co/ucaslcl/GOT-OCR2_0
GOT: Towards OCR-2.0
通用OCR模型须要够通用,体现在输入输出都要通用上。我们可以笼统地将人造的所有信号都叫字符,基于此,我们提出通用或者广义OCR(也就是OCR-2.0)的概念,并设计开源了第一个起步OCR-2.0模型GOT,该模型名字就是由General OCR Theory的首字母组成。
在输入方面,模型支持图1中全部的OCR任务;输出方面,模型同时支持plain texts输出以及可读性强、可编辑的formatted文本输出,如markdown等。
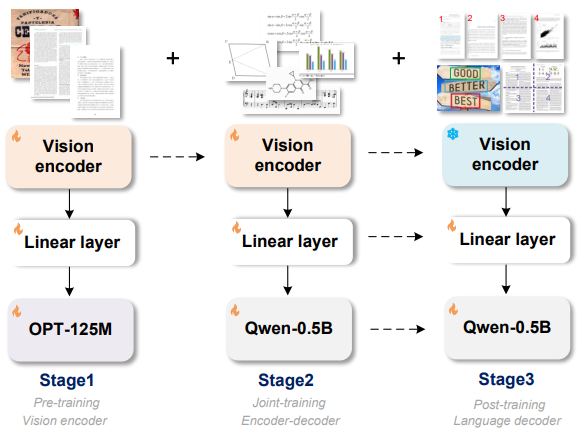
图2. GOT结构与训练流程图 模型的结构和训练方法如图2所示,采用vision encoder+input embedding layer+decoder的pipeline。Encoder主体采用带local attention的VITDet架构,这不至于CLIP方案的全程global attention在高分辨率下激活太大,炸显存。Encoder后两层采用Vary的双卷积设计方案。整个Encoder将1024×1024×3的图像压缩为256×1024的image tokens,这足以做好A4纸级别的dense OCR。
整个训练过程分为3个步骤,没有一个阶段锁LLM,也就是不会存在图像到文本的对齐阶段,进而导致损害image token的文字压缩率。3个训练阶段分别为:
-
高效预训练encoder,GOT在整个训练过程中,没有A100级别的卡,为了节省资源,该阶段使用小型OPT-125M作为decoder为encoder提供优化方向,快速灌入大量数据。
-
联合训练encoder-decoder,该阶段GOT的基本结构搭建完成,为上一阶段预训练好的encoder,以及Qwen团队预训练好的Qwen0.5B。我们稍稍加大了decoder的大小,因为该阶段需要喂入大量OCR-2.0的知识,而不少数据(如化学式的OCR)其实也是带点reasoning的,更小的decoder未敢尝试。
-
锁住encoder,加强decoder以适配更多的OCR应用场景,如支持坐标或者颜色引导的细粒度OCR(点读笔可能会用到),支持动态分辨率OCR技术(超大分辨率图可能会用到),多页OCR技术(该feature主要是为了后续follower能更好地训练Arxiv这种数据,我们的设想是多页PDF直接训练,无须再对.tex断页而苦恼!)

图3. GOT使用到的数据渲染工具
当然,整个GOT模型设计最困难的还是数据工程。为了构造各种各样的数据,我们学习了众多数据渲染工具,如图3所示,包括Latex,Mathpix-markdown-it,Matplotlib,Tikz,Verovio, Pyecharts等等。
结果可视化: 多说无用,效果才是一切,GOT的输出可视化效果如下:

例1:最常用的PDF image转markdown能力

例2:双栏文本感知能力

例3:自然场景以及细粒度OCR能力

例4:动态分辨率OCR能力

例5:多页OCR能力
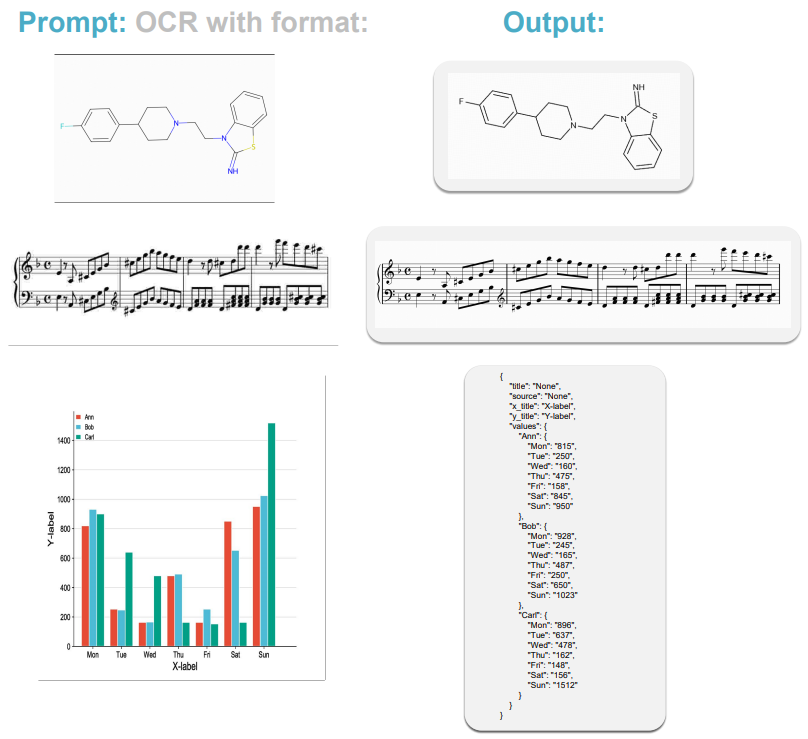
例6:更多符号的OCR能力
总结
尽管GOT模型表现不错,但也存在一些局限,如更多的语言支持,更复杂的几何图,更复杂的表格。OCR-2.0的研究还远的很,GOT也还有不小提升空间(该项目在数据和算力资源上都是非常受限的),正是因为深知GOT以及OCR-2.0的潜力,我们希望通过开源GOT吸引更多的人,放弃VQA,再次投向强感知。都说纯OCR容易背锅,但也正好说明做的不够work,不是吗?
相关文章:
端到端的开源OCR模型:GOT-OCR-2.0,支持场景文本、文档、乐谱、图表、数学公式等内容识别!
今天给大家分享一个端到端的开源 OCR 模型,号称 OCR 2.0! 支持场景文本、文档、乐谱、图表、数学公式等内容识别,拿到了 BLEU 0.972 高分。 从给出的演示图来看,一些非常复杂的数学公式都能正确的识别,颇为强大。模型…...

自注意力机制self-attention中QKV矩阵的含义
自注意力机制(Self-Attention)是Transformer模型的核心组件,其中Q、K、V矩阵分别代表查询(Query)、键(Key)、值(Value)。它们的作用和含义可以通过信息匹配过程来理解。在…...
)
【前端】Bootstrap:栅格系统 (Grid System)
Bootstrap的栅格系统是该框架的核心部分之一,能够让开发者轻松创建响应式网页布局,适配各种屏幕尺寸和设备。栅格系统通过将页面划分为12列的布局结构,开发者可以根据内容的重要性和设计需求灵活控制元素的宽度和排列。 在这篇文章中&#x…...

一文读懂,SSL证书怎么验签安装使用?
SSL证书目前已经有越来越多的企业网站开始使用,安装SSL证书后,原有的http协议将会变成安全性更好的https加密协议,这对保护用户的信息安全,保障企业及用户的利益起着重要作用。 一张SSL证书的获取,需要经历不少环节&a…...

Mysql(八) --- 视图
文章目录 前言1.什么是视图?2.创建视图3. 使用视图4. 修改数据4.1.注意事项 5. 删除视图6.视图的优点 前言 前面我们学习了索引,这次我们来学习视图 1.什么是视图? 视图是一个虚拟的表,它是基于一个或多个基本表或其他视图的查询…...

SQL注入原理、类型、危害与防御
SQL注入的原理概念 SQL注入是一种常见的网络攻击技术,攻击者通过在Web应用程序的输入字段中注入恶意构造的SQL代码,以欺骗后端数据库执行非预期的SQL命令。这种攻击可以导致数据泄露、权限提升、数据篡改甚至系统瘫痪。SQL注入可以分为多种类型…...

第2讲 数据库系统的结构抽象与演变
基本内容 数据库系统的标准结构?数据模型?数据库系统的演变与发展?重难点 一组概念的区分:三级模式两层映像,物理独立性和逻辑独立性一组概念的区分:数据→模式→数据模型几种数据模型的差异:网状/层次模型→关系模型→数据模型数据库系统的标准结构 (1)数据库系统的分…...

Git创建开发分支命名规则
git checkout -b feature/branchname 和 git checkout -b branchname 这两条命令的主要区别在于新分支的命名。 主要区别 分支命名: git checkout -b feature/branchname:新分支的名字是 feature/branchname,表示该分支属于一个特性开发&…...

【纯前端excel导出】vue2纯前端导出excel,使用xlsx插件,修改样式、合并单元格
一、使用第三方插件 1、安装 npm install xlsx-js-style 2、引入 import xlsx from xlsx-js-style xlsx插件是基础的导出,不可以修改样式,直接xlsx-style插件式修改样式的,所以这里直接用二者合体插件即可 二、页面使用 1、数据源 [{"…...

如何在极速浏览器中实现谷歌浏览器的扩展功能
在当今数字化时代,浏览器扩展功能极大地增强了我们的在线体验。尤其是谷歌浏览器,以其丰富的扩展生态而闻名。但是,如果你想在极速浏览器中使用这些谷歌浏览器的扩展功能,该怎么办呢?本文将为你详细解析如何实现这一目…...

Web安全 - 跨站点请求伪造CSRF(Cross Site Request Forgery)
文章目录 OWASP 2023 TOP 10CSRF 导图CSRF的基本概念CSRF的工作原理常见CSRF攻击模式CSRF防御策略补充建议应用场景实战防御策略选择1. CSRF Token(首选)2. SameSite Cookie属性3. 验证Referer和Origin4. 多因素认证 实现方案CSRF Token实现SameSite Coo…...

C++游戏开发完整学习路径
C游戏开发完整学习路径 引言 随着游戏行业的迅速发展,C作为主要的游戏开发语言,因其高效性和灵活性,依然受到广泛欢迎。C不仅在大型游戏开发中被广泛使用,而且在游戏引擎的构建、性能优化和复杂算法的实现中也扮演着关键角色。本…...

vue3之 shallowRef、markRaw
shallowRef 用于创建一个浅层响应式引用,只对顶层属性进行响应式处理。 markRaw 用于标记一个对象,使其完全跳过 Vue 的响应式系统。 这两者都可以用于优化性能,避免不必要的响应式开销,特别是在处理大型对象或第三方库对象时。 …...

影刀RPA实战:操作Mysql数据库
1.摘要 影刀RPA(Robotic Process Automation)是一种软件自动化工具,它可以模拟人类用户执行各种重复性任务,其中包括对数据库的操作。 我们可以使用软件自动化指令,通过获取数据库窗口对象来操作数据库,也…...

【c++】c++11多线程开发
2 C多线程 本文是参考爱编程的大丙c多线程部分内容,按照自己的理解对其进行整理的一篇学习笔记,具体一些APi的详细说明请参考大丙老师教程。 代码性能的问题主要包括两部分的内容,一个是前面提到资源的获取和释放,另外一个就是多…...

PW37R_V1 产品规格书
概述 PW37R_V1是一款采用3.7英寸黑白红三色电子纸显示的电子标签,采用一种先进的无线自动更新系统,实现无线传输。 通过http,mqtt协议更新数据和控制该款电子标签的显示等操作,显示内容可自定义。内置电池供电,可Typ…...

android11 usb摄像头添加多分辨率支持
部分借鉴于:https://blog.csdn.net/weixin_45639314/article/details/142210634 目录 一、需求介绍 二、UVC介绍 三、解析 四、补丁修改 1、预览的限制主要存在于hal层和framework层 2、添加所需要的分辨率: 3、hal层修改 4、frameworks 5、备…...

【开源免费】基于SpringBoot+Vue.JS房屋租赁系统(JAVA毕业设计)
本文项目编号 T 020 ,文末自助获取源码 \color{red}{T020,文末自助获取源码} T020,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 查…...

JavaScript全面指南(二)
🌈个人主页:前端青山 🔥系列专栏:Javascript篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来JavaScript篇专栏内容:JavaScript全面指南(二) 目录 21、说明如何使用JavaScript提交表单? 2…...
Nginx:Linux配置Nginx
目录 一、环境安装1.1 GCC编译器1.2 PCRE1.3 Zlib1.4 OpenSSL1.5 快速下载 二、Nginx源码简单安装2.1 下载安装包2.2 解压2.3 进入资源文件中2.4 编译、安装 三、Yum安装四、Nginx源码复杂安装4.1 参数介绍4.2 参数配置 五、卸载Nginx5.1 关闭Nginx进程5.2 将安装的Nginx删除5.…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...
)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理(附dpkg/apt组合拳)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理 在UOS系统日常使用中,WPS Office作为常用办公软件,有时因版本更新或功能调整需要彻底卸载。但不少用户发现,通过图形界面或简单命令卸载后,系统中仍残留配置文件、…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南
3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 面对遗忘的加密压…...
CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗?
更多请点击: https://intelliparadigm.com 第一章:CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗? 在现代CI/CD实践中,开发者常误以为 package.json 或 requirements.txt 中显式…...

HKMG工艺的“阿喀琉斯之踵”:聊聊那个无法移除的SiON界面层与未来0.3nm的挑战
HKMG工艺的隐形枷锁:SiON界面层的物理宿命与亚纳米级突围战 在半导体工艺演进的史诗中,HKMG(高K金属栅)技术曾被寄予厚望——它用金属栅极替代传统多晶硅,搭配高K介质材料HfO₂,一举解决了栅极耗尽和漏电流…...