【c++】c++11多线程开发
2 C++多线程
本文是参考爱编程的大丙c++多线程部分内容,按照自己的理解对其进行整理的一篇学习笔记,具体一些APi的详细说明请参考大丙老师教程。
代码性能的问题主要包括两部分的内容,一个是前面提到资源的获取和释放,另外一个就是多任务处理能力,通俗来理解,程序能够多个任务同时处理相对于一次只处理一个任务的情况,性能是要更优的。多线程技术就是用于处理多任务同时处理的问题。在具体展开多线程内容之前,我们先做一些扩展,了解一些进程和多任务处理相关的概念。
2.1 进程
程序是我们磁盘上的可执行文件,占用的是磁盘上的空间,当程序被启动后就被叫做进程,进程不占用磁盘,而是消耗系统的内存和CPU资源。进程是操作系统进行资源分配和调度的一个独立单位,它是应用程序运行的实例,每个运行的进程都有一个属于自己的虚拟地址空间。
虚拟地址空间是内存管理的一种技术,相当于介于程序和物理内存之间的一个中间层,用于建立程序和物理内存之间的映射关系,分为内核区和用户区。内核区由操作系统管理,用于存储操作系统核心代码和数据,受到严格保护,用户程序不可访问;用户区包括代码段、数据段、堆、栈、内存映射区等,用于存储用户程序的数据和代码。这种划分是为了提供隔离和保护,提高了操作系统的稳定性和安全性。

2.1.1 并发和并行
并发和并行是多任务同时处理的两种方式:
并发: 指针对某个硬件资源,多个任务通过获取时间片的方式,交替处理,在微观上是顺序执行,宏观上同时处理;
**并行:**指多个任务分别在不同的硬件资源上,同时进行处理。

2.1.2 进程创建和退出
进程创建和退出这部分主要以概念性描述为主,旨在阐明内容。
在Linux系统上,在一个启动的进程中调用fork()函数即可完成一个子进程的创建。子进程在创建的过程中会基于父进程的虚拟地址空间拷贝出一份属于自己的虚拟地址空间(可理解为深拷贝)。父子进程之间各自的虚拟地址空间是相互独立的,父子进程间的内核区不同,用户区相同。父子进程虚拟地址空间中代码区代码虽然相同,但父子进程执行的代码逻辑可能是不同的,由于执行逻辑的不同,在完成地址空间拷贝后,用户区的全局数据区、堆区、栈区和内存映射区的数据可能会发生变换,但由于地址空间相互独立,父子进程不会相互覆盖数据。

进程的退出可以通过调用exit()函数实现,eixt()函数会通知操作系统进程进程退出请求,关闭打开的文件描述符、释放用户区内存资源,注销进程控制块,如果父进程需要知道子进程的退出状态,可以通过wait()函数系统调用来获取子进程的退出状态。进程的退出会有两种特殊的情况,子进程先于父进程退出和父进程先于子进程退出,子进程先于父进程退出的情况称为僵尸进程,父进程先于子进程的情况称为孤儿进程。
孤儿进程: 在启动的进程中创建子进程,这时父子进程同时运行,但父进程由于某种原因先退出了,子进程还在运行。在子进程退出时,子进程的用户区资源可以被释放,但内核区的进程控制块自己无法释放,必须由父进程释放子进程的进程控制块,这时系统的固定进程会将孤儿进程领养,替父进程完成进程控制块的释放。
僵尸进程: 在启动的进程中创建子进程,这时父子进程同时运行,而子进程先于父进程结束,子进程的进程控制块无法释放,但是如果父进程也不管,这时候的子进程就是一个僵尸进程。僵尸进程不是一个正常的进程,其用户区资源已经释放,只是进程控制块还在占用系统内核。解决僵尸进程的办法是杀死这个僵尸进程的父进程,这样僵尸进程的资源就会被系统回收(kill -9不能杀死僵尸进程,这个命令只对活着的进程有效)。
2.1.3 进程间通信方式
进程间通信主要有:管道、共享内存、本地套接字、内存映射区,信号量、消息队列等方式。
管道: 管道是存储在一个环形队列中的内核缓冲区,分为读端和写端两部分,读端用于读取数据,相当于出队,写端用于写入数据,相当于入队。管道中没有数据是,读端被阻塞,管道写满时,写端被阻塞;管道中的数据只能单向流动,数据从写端流向读端(即通信的两个进程中,只能是一个进程读,一个进程写,同一个进程不能同时进行读写操作)。管道分为匿名管道和有名管道,匿名管道用于有血缘关系的进程间通信,有名管道可以用于任意两个进程通信。

内存映射: 管道通信的内存空间是内核区,而内存映射则是在用户区,通信的进程都持有自己的内存映射区,由于地址空间都是独立的,内存映射之间没法直接通信,需要各个内存映射和同一个磁盘文件进行映射实现。当一个进程的内存映射区数据被修改,数据会被同步到磁盘文件,同时和磁盘文件建立银蛇关系的其他进程内存映射区中的数据也会和磁盘文件进行同步,这种同步机制保证了各个进程之间的数据共享。
共享内存: 共享内存不属于进程,不受进程生命周期的影响。通过系统函数调用可以获得共享内存,使用之前需将共享内存和进程之间进行关联,得到共享内存的起始地址就可以直接进行读写操作,进程也可以解除和共享内存的关联,解除进程无法再操作这块共享内存。共享内存操作默认不阻塞,多个进程同时进行读写时,要进行数据同步操作。功效内存是进程通信方式中效率最高的。
2.1.4 多进程和多线程的区别
将这部分放再前面,目的是想在多线程主要内容前,先对两者有个宏观认识,更利于理解多线程的一些技术细节,这也是介绍上述内容的出发点。
进程是资源分配的最小单位,线程是操作系统调度执行的最小单位。
进程有自己独立的虚拟地址空间,多个线程共用同一个地址空间。
在一个地址空间(进程)中多个线程独享: 每个线程都有属于自己的栈区,寄存器(内核中管理)
1.子线程栈上的数据无法传递到主线程,因为当子线程退出时,子线程栈会被释放,资源无法传递出来;
2.通过主线程的栈,可以将子线程栈上数据传递到主线程,将主线程栈区数据以函数参数的形式传递给子线程执行函数,在子线程执行函数内将子线程栈数据指向主线程栈,则可以实现将子线程数据传递到主线程的功能。
在同一个地址空间(进程)中多个线程共享: 代码段、堆区、全局数据区,打开的文件(文件描述符表)
2.2 多线程开发
做了一堆铺垫,终于到正文了。c++11引入了对多线程编程的原生支持。它解决了跨平台的问题,提供了管理线程、保护共享数据、线程同步和原子操作等类。
2.2.1 线程创建、控制和this_thread()
2.2.1.1 线程创建
线程创建的时候需提供线程函数或函数对象。c++11提供的线程类为std::thread,std::thread的构造函数要求必须只能一个可调用实体作为线程的入口点,否则程序无法编译。
#include<iostream>
#include<thread>void work_func1(int num){std::cout<<"num: "<<num<<std::endl;
}
void work_func2(){std::cout<<"work func2"<<std::endl;
}int main(){std::cout<<"主线程ID: "<<this_thread::get_id()<<std::endl;std::thread th1(work_func1,10);std::thread th2(work_func2);std::cout<<"线程th1的ID: "<<th1.get_id()<<std::endl;std::cout<<"线程th2的ID: "<<th2.get_id()<<std::endl;return 0;
}
上述代码中,主线程销毁时会将其子线程一并销毁,但这时有可能子线程还没执行完**(主线程和子线程共享一个地址空间,子线程被创建后需抢cpu时间片,抢不到则不能运行,如果子线程退出,地址空间就会被释放,子线程也就一并被销毁了,但如果子线程先退出,主线程仍可运行,虚拟地址空间依旧存在)**,这就会有问题。解决这个问题有两个思路,一是让主线程等待子线程结束再销毁,一是让子线程和主线程脱离。基于上述两个思路,c++11了线程控制的两个重要操作:join和detach。
2.2.1.2 join()和joinable()
join()的功能是让主线程等待(阻塞)子线程的终止后再释放。在某个线程中通过子线程对象调用join()函数,调用这个函数的线程被阻塞,但子线程的任务函数还在执行,当任务函数执行完毕后,join()会清理当前子线程资源并返回,同时调用join()函数的线程解除阻塞向下执行。
int main(){std::cout<<"主线程ID: "<<this_thread::get_id()<<std::endl;std::thread th1(work_func1,10);std::thread th2(work_func2);std::cout<<"线程th1的ID: "<<th1.get_id()<<std::endl;std::cout<<"线程th2的ID: "<<th2.get_id()<<std::endl;th1.join();th2.join();return 0;
}
joinable()函数可以理解为join()函数的一个辅助函数,用于判断线程是否已经被启动且尚未执行完,如果线程已经启动且尚未执行完,则返回true,这是需要join(),若线程尚未启动或已经被join,则返回false。因此,joinable()通常和join()一起使用。
int main(){std::cout<<"主线程ID: "<<this_thread::get_id()<<std::endl;std::thread th1(work_func1,10);std::thread th2(work_func2);std::cout<<"线程th1的ID: "<<th1.get_id()<<std::endl;std::cout<<"线程th2的ID: "<<th2.get_id()<<std::endl;if(th1.joinable()){th1.join();}if(th2.joinable()){th2.join();}return 0;
}
2.2.1.3 detach()
detach()用于线程分离,即分类主线程和其子线程。在主线程退出前,detach()函数会使子线程脱离子线程继续独立的运行,当子线程退出时。其占用的内核资源会被系统的其他线程接管并进行回收。
int main(){std::cout<<"主线程ID: "<<this_thread::get_id()<<std::endl;std::thread th1(work_func1,10);std::thread th2(work_func2);std::cout<<"线程th1的ID: "<<th1.get_id()<<std::endl;std::cout<<"线程th2的ID: "<<th2.get_id()<<std::endl;th1.detach();th2.detach();return 0;
}
2.2.1.4 this_thread命名空间
this_thread命名空间提供了获取线程ID和控制线程状态的几个API。
| 序号 | API | 用途 |
|---|---|---|
| 1 | std::this_thread::get_id() | 用于获取当前线程的ID |
| 2 | std::this_thread::sleep_for() | 将调用线程从运行态切换到阻塞态,知道休眠完成,重新抢cpu时间片 |
| 3 | std::this_thread::sleep_until() | 和sleep_for()功能一样,不同之处是前者是时间段,后者是时间点 |
| 4 | std::this_thread::yield() | 将调用线程从运行态切换到就绪态,即放弃cpu资源后马上参与下一轮抢时间片活动 |
2.2.2 线程同步
同样在说明线程同步之前,先做个铺垫,说一下共享资源,没有多个线程对共享资源的操作,也就没有线程同步的概念了。
-
共享资源: 即多个线程共同访问操作的变量,这些变量通常为全局数据区变量或堆区变量,这些变量对应的共享资源也被称为临界资源。
-
线程同步: 即多个线程按照先后顺序依次操作共享资源。确保程序的正确性和性能,避免数据不一致和竞态条件。
线程同步的目的是让多个线程按照顺序一次执行临界区代码,这样做线程对共享资源的访问就从并行访问变成了线性访问,访问效率降低了,但保证了数据的正确性。
线程不同步会导致的问题:当两个线程同时操作共享资源的时候,A线程获取内存资源进行操作,完成操作需将结果写入到内存,但在写入的这个过程中,A线程阻塞丢掉时间片;此时,B线程进入运行态,进行内存数据获取,操作完成后,将数据更新到内存,此时,A线程又获得时间片,完成数据写入内存的操作,将B线程的操作结果进行覆盖。从而导致共享资源操作错乱的问题(两线程数数)。
常见的线程同步方式有四种:互斥锁、读写锁、条件变量和信号量。
2.2.2.1 互斥锁
互斥锁是一种同步原语,确保了任何时候只有一个线程可以执行临界区代码段。C++的mutex类提供了相关的API函数。注意,线程加锁的逻辑是,获取到互斥量后加锁,互斥量和临界区一一对应,只有抢到资源的线程才能操作。
使用互斥锁进行线程同步的基本流程如下:
- 找到多线程操作的共享资源(全局变量、堆区数据,类成员变量等),即临界资源;
- 找到和共享资源有关的上下文代码,即临界区;
- 在临界区上边调用互斥锁进行加锁(lock()函数);
- 在临界区下班调用互斥锁进行解锁(unlock()函数)。
在使用的时候有一下两点需注意:
-
在所有线程任务函数执行完毕之前,互斥锁对象是不能被析构的,一定要在程序中保证这个对象的可用性;
这句话描述了互斥锁的生命周期管理的重要。简单来说就是,互斥锁对象创建、初始化要做线程创建之前,线程结束之前互斥锁对象不能被销毁。为了保证互斥锁对象的可用性,通常需遵循以下准则:
- 全局或静态分配:将互斥锁对象定义为全局变量或静态变量,这样可以确保其在整个程序的生命周期内都是有效的。
- 作用域管理:确保互斥锁对象的作用域覆盖了所有可能使用它的线程。例如,如果互斥锁是某个类成员,确保该类的对象的生命周期覆盖了所有线程的执行。
- 线程同步:在所有线程结束执行之前,避免销毁互斥锁对象。通常可以通过使用
std::thread::join()来等待线程结束,确保互斥锁不再被使用后再销毁。
-
互斥锁的个数和共享资源的个数相同,一个共享资源对应一个互斥锁对象,互斥锁对象个数和线程个数无关。
上述两点我认为在使用互斥锁时时非常重要的,要深刻体会,下面来说以下API
- lock()函数
lock()函数用于给临界区加锁,并且只能由一个线程获得锁的所有权,独占互斥锁对象有两种状态:锁定和未锁定。如果互斥锁是打开的(临界区没有线程操作),调用lock()函数的线程会得到互斥锁的所有权(即获得临界区的操作权),并将其上锁,其他线程再调用该函数的时候由于得不到互斥锁的所有权,就会被lock()函数阻塞。当拥有互斥锁所有权的线程将互斥锁解锁,此时lock()阻塞的线程解除阻塞,抢到互斥锁所有权的线程加锁并继续执行,没有抢到互斥锁所有权的线程继续阻塞。
- try_lock()函数
lock()是一个阻塞的锁,而try_lock()是一个非阻塞的锁。当一个线程尝试通过try_lock()获取互斥锁时,如果互斥锁未锁定,则得到互斥锁并加锁成功,返回true,如果互斥锁锁定,则无法获得锁加锁失败,返回false。
try_lock()通常和lock()组合使用,实现非阻塞的线程同步。
#include <iostream>
#include <thread>
#include <mutex>
#include <vector>// 全局互斥锁
std::mutex mtx;// 全局计数器
int counter = 0;// 使用 lock() 的函数
void increment_with_lock() {mtx.lock(); // 阻塞直到获取锁counter++;std::cout << "Incremented: " << counter << std::endl;mtx.unlock(); // 释放锁
}// 使用 try_lock() 的函数
void increment_with_try_lock() {if (mtx.try_lock()) { // 尝试获取锁,不阻塞counter++;std::cout << "Incremented: " << counter << std::endl;mtx.unlock(); // 释放锁} else {std::cout << "Could not acquire lock" << std::endl;}
}// 使用 try_lock() 和 lock() 组合的函数
void increment_with_try_lock_and_lock() {if (mtx.try_lock()) { // 尝试获取锁,不阻塞counter++;std::cout << "Incremented: " << counter << std::endl;mtx.unlock(); // 释放锁} else {std::cout << "Could not acquire lock, trying again..." << std::endl;mtx.lock(); // 阻塞直到获取锁counter++;std::cout << "Incremented: " << counter << std::endl;mtx.unlock(); // 释放锁}
}int main() {std::vector<std::thread> threads;// 创建使用 lock() 的线程for (int i = 0; i < 5; ++i) {threads.emplace_back(increment_with_lock);}// 创建使用 try_lock() 的线程for (int i = 0; i < 5; ++i) {threads.emplace_back(increment_with_try_lock);}// 创建使用 try_lock() 和 lock() 组合的线程for (int i = 0; i < 5; ++i) {threads.emplace_back(increment_with_try_lock_and_lock);}// 等待所有线程完成for (auto& thr : threads) {thr.join();}std::cout << "Final counter value: " << counter << std::endl;return 0;
}
- std::lock_guard
lock_guard时一个模板类,可以简化互斥锁加锁和解锁的写法,也更加安全。lock_guard的构造函数会自动锁定互斥锁,退出作用域后进行析构时会自动解锁,使用了RALL技术,在构造函数中分配资源,在析构函数中释放资源,保证资源出了作用域就释放,从而保证了互斥锁的正确操作。
#include <iostream>
#include <thread>
#include <mutex>
#include <vector>std::mutex mtx; // 全局互斥锁
int shared_data = 0; // 共享资源void increment(int n) {for (int i = 0; i < n; ++i) {std::lock_guard<std::mutex> lock(mtx);shared_data++; // 安全地修改共享资源}
}int main() {std::vector<std::thread> threads;int num_threads = 5;int increments_per_thread = 100;// 创建线程for (int i = 0; i < num_threads; ++i) {threads.emplace_back(increment, increments_per_thread);}// 等待所有线程完成for (auto& thr : threads) {thr.join();}std::cout << "Final value of shared_data: " << shared_data << std::endl;return 0;
}
lock_guard有一个弊端,上述代码中的整个for循环都被当成了临界区,临界区越大,程序效率越低,可以通过加{}的方式限定其作用域来处理。
- 其他
c++11提供了四种互斥锁:
std::mutex:前面主要提到的,独占互斥锁,不能递归使用;std::timed_mutex:带超时的独占互斥锁,不能递归使用。在获取锁时,会根据设定的阻塞时间或时间点,超时后线程解除阻塞去处理其他任务;std::recursive_mutex:递归互斥锁,不带超时功能,用于解决同一个线程需多次获得锁的情况,不建议使用,易出现Bug,使用递归互斥锁的场景往往都可以简化;std::recursive_timed_mutex:带超时的递归互斥锁,上述锁的组合版本。
2.2.2.2 条件变量
条件变量能阻塞一个或多个线程,直到收到另外一个线程发出的通知或超时时,才会唤醒当前阻塞的线程。条件变量需和互斥量配合起来使用。
互斥锁用于保护共享资源,确保在任何时刻只要一个线程可以访问共享资源。条件变量用于特定条件发行前进行线程阻塞。二者区别如下:
- 多个线程共同访问一把互斥锁,如果其中一个加锁成功,那么其他线程访问互斥锁都会阻塞,所有线程只能顺序访问临界区;
- 条件变量变量只要在满足特定条件下才会阻塞线程,如果条件不满足,多个可以同时访问临界区,同时读写临界资源,这种情况会出现共享资源中的数据混乱。
条件变量在流程上只有两个操作阻塞线程和唤醒线程,条件满足时,阻塞当前线程,等待其他线程通知,其他线程执行到一定流程,唤醒被当前条件量阻塞的线程,因此,同一个条件变量,唤醒和通知操作通常会在两个线程里的不同任务函数中执行。
c++11提供了两种条件变量,condition_variable和condition_variable_any
- condition_variable
condition_variable需配合std::unique_lock<std::mutex>一起使用(只能和独占非递归互斥锁配合使用),这样能够确保解锁后重更新锁定。
-
等待函数
等待函数用于阻塞线程,其基本流程如下:
(1)线程先通过
std::unique_lock<std::mutex>获取到互斥锁所有权;(2)调用条件变量
wait()函数阻塞线程并释放互斥锁所有权;(3)条件满足时,唤醒线程并重新获取互斥锁所有权继续执行。
condition_variable提供了三个等待函数API:序号 API 用途 1 wait()阻塞线程,有一个重载版本,第二个参数可以接受返回值为 bool的函数,可简化代码2 wait_for()阻塞线程到指定时长,时间到达后解除阻塞 3 wait_until()阻塞线程到指定时间点,时间点到达后解除阻塞 -
通知函数
condition_variable提供的通知函数API如下:序号 API 用途 1 notify_one()唤醒一个被当前条件变量阻塞的线程 2 notify_all()唤醒全部被当前条件变量阻塞的线程
条件变量的一个典型应用就是生成-消费者模型。以下是基于条件变量的一个模型demo。
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>std::mutex mtx;
std::condition_variable data_cond;
std::condition_variable space_cond;
std::queue<int> data_queue;
const unsigned int MAX_QUEUE_SIZE = 10;// 生产者函数
void producer(int start) {for (int i = start; i < start + 100; ++i) {std::unique_lock<std::mutex> lock(mtx);space_cond.wait(lock, []{ return data_queue.size() < MAX_QUEUE_SIZE; });data_queue.push(i);std::cout << "Produced: " << i << std::endl;data_cond.notify_one();//lock.unlock(); // 可选的,unique_lock会自动解锁std::this_thread::sleep_for(std::chrono::milliseconds(100));}
}// 消费者函数
void consumer() {while (true) {std::unique_lock<std::mutex> lock(mtx);data_cond.wait(lock, []{ return !data_queue.empty(); });int data = data_queue.front();data_queue.pop();std::cout << "Consumed: " << data << std::endl;space_cond.notify_one();//lock.unlock(); // 可选的,unique_lock会自动解锁std::this_thread::sleep_for(std::chrono::milliseconds(100));}
}int main() {std::thread producers[2];std::thread consumers[2];// 创建生产者线程for (int i = 0; i < 2; ++i) {producers[i] = std::thread(producer, i * 100);}// 创建消费者线程for (int i = 0; i < 2; ++i) {consumers[i] = std::thread(consumer);}// 等待生产者线程结束for (auto& prod : producers) {prod.join();}// 等待消费者线程结束for (auto& cons : consumers) {cons.join(); }return 0;
}
- condition_variable_any
condition_variable_any可以和任意带锁的互斥量配合使用,使用流程和上述一样,提供了类似的等待和通知函数,这里不再赘述。
2.2.2.3 读写锁
读锁:允许多个线程同时读取共享资源;
写锁: 同一时间只允许一个线程对共享资源进行写操作;
c++14之前,没有提供读写锁的的实现,下面是配合条件变量实现的读写锁。
#include <mutex>
#include <condition_variable>
#include <thread>
#include <iostream>class ReadWriteMutex {
public:ReadWriteMutex() : read_count_(0), write_count_(0) {}void lock_read() {reader_mutex_.lock();++read_count_;if (write_count_ > 0) {cond_.wait(reader_mutex_, [this] { return write_count_ == 0; });}reader_mutex_.unlock();}void unlock_read() {reader_mutex_.lock();--read_count_;reader_mutex_.unlock();cond_.notify_one();}void lock_write() {writer_mutex_.lock();++write_count_;while (read_count_ > 0 || write_count_ > 1) {cond_.wait(writer_mutex_, [this] { return read_count_ == 0 && write_count_ == 1; });}}void unlock_write() {writer_mutex_.lock();--write_count_;cond_.notify_all();writer_mutex_.unlock();}private:std::mutex reader_mutex_;std::mutex writer_mutex_;std::condition_variable cond_;int read_count_;int write_count_;
};ReadWriteMutex rw_mutex;void reader(int id) {rw_mutex.lock_read();std::cout << "Reader " << id << " is reading" << std::endl;// simulate readingstd::this_thread::sleep_for(std::chrono::seconds(1));rw_mutex.unlock_read();
}void writer(int id) {rw_mutex.lock_write();std::cout << "Writer " << id << " is writing" << std::endl;// simulate writingstd::this_thread::sleep_for(std::chrono::seconds(2));rw_mutex.unlock_write();
}int main() {std::thread writers[2];std::thread readers[3];// Start writersfor (int i = 0; i < 2; ++i) {writers[i] = std::thread(writer, i + 1);}// Start readersfor (int i = 0; i < 3; ++i) {readers[i] = std::thread(reader, i + 1);}// Join writersfor (int i = 0; i < 2; ++i) {writers[i].join();}// Join readersfor (int i = 0; i < 3; ++i) {readers[i].join();}return 0;
}
2.2.2.4 原子变量
原子变量(Atomic Variables)是一类特殊的变量,它们提供了无锁的线程安全操作。在多线程环境中,原子变量可以保证对它们的操作是原子性的,即操作要么全部执行,要么全部不执行,不会出现中间状态。
原子操作对于实现无锁编程、提高性能以及避免使用同步机制(如互斥锁)非常有用。C++11 引入了 std::atomic 类模板,它支持对各种数据类型的原子操作。
通过原子变量可以避免互斥锁的使用,提高代码性能。互斥锁主要用于保护复杂数据和复杂操作的访问一致性,原子变量主要用于简单的单个数据的同步,是轻量级的同步机制。
#include <atomic>
#include <thread>std::atomic<int> count(0); // 原子变量初始化为0void increment() {count.fetch_add(1, std::memory_order_relaxed); // 原子递增
}int main() {std::thread t1(increment);std::thread t2(increment);t1.join();t2.join();return 0;
}
2.2.2.5 线程同步的死锁问题
当多个线程访问共享资源,需要加锁,如果锁使用不当,就会造成死锁,死锁会导致所有线程被阻塞,当前线程无法释放。
发生死锁主要有以下三种情况:
- 加锁后忘记解锁
- 对同一共享资源重复加锁
- 多个线程请求多个共享资源,形成环形应用,如线程A持有资源1并请求资源2,线程B持有资源2并请求资源1;
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>std::mutex mtx1;
std::mutex mtx2;void threadA() {mtx1.lock();std::cout << "Thread A acquired mutex 1" << std::endl;// 模拟工作std::this_thread::sleep_for(std::chrono::seconds(1));mtx2.lock();std::cout << "Thread A acquired mutex 2" << std::endl;mtx1.unlock();mtx2.unlock();
}void threadB() {mtx2.lock();std::cout << "Thread B acquired mutex 2" << std::endl;// 模拟工作std::this_thread::sleep_for(std::chrono::seconds(1));mtx1.lock();std::cout << "Thread B acquired mutex 1" << std::endl;mtx1.unlock();mtx2.unlock();
}int main() {std::thread tA(threadA);std::thread tB(threadB);tA.join();tB.join;return 0;
}
解决死锁的方案:
- 对共享资源操作完毕后,一定要解锁,或加锁使用
try_lock; - 避免对同一共享资源重复加锁
- 对于环形引用的情况,可以通过破坏循环等待条件(所有线程必须先请求资源1,再请求资源2)或超时机制(为资源请求设置超时时间。如果一个线程在超时时间内无法获取所有需要的资源,它将释放已持有的资源,并在一段时间后重试)来处理。
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>std::mutex mtx1;
std::mutex mtx2;bool try_lock_with_timeout(std::mutex& m, int timeout_ms) {std::unique_lock<std::mutex> lock(m, std::defer_lock);if (lock.try_lock_for(std::chrono::milliseconds(timeout_ms))) {return true;}return false;
}void threadA() {if (try_lock_with_timeout(mtx1, 100)) {std::cout << "Thread A acquired mutex 1" << std::endl;// 模拟工作std::this_thread::sleep_for(std::chrono::seconds(1));if (try_lock_with_timeout(mtx2, 100)) {std::cout << "Thread A acquired mutex 2" << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));mtx2.unlock();} else {std::cout << "Thread A failed to acquire mutex 2" << std::endl;}mtx1.unlock();} else {std::cout << "Thread A failed to acquire mutex 1" << std::endl;}
}void threadB() {if (try_lock_with_timeout(mtx2, 100)) {std::cout << "Thread B acquired mutex 2" << std::endl;// 模拟工作std::this_thread::sleep_for(std::chrono::seconds(1));if (try_lock_with_timeout(mtx1, 100)) {std::cout << "Thread B acquired mutex 1" << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));mtx1.unlock();} else {std::cout << "Thread B failed to acquire mutex 1" << std::endl;}mtx2.unlock();} else {std::cout << "Thread B failed to acquire mutex 2" << std::endl;}
}int main() {std::thread tA(threadA);std::thread tB(threadB);tA.join();tB.join();return 0;
}
2.2.3 线程异步
线程同步主要解决的是共享资源访问同步的问题,而线程异步则处理的是线程或任务函数执行顺序的问题。
在一般情况下,函数中调用的其他函数都是线性执行的,即一个函数执行完并返回,再执行下一个函数。如再main()函数中,被调用的函数依次按照顺序执行,完成对数据的操作,这种个过程就是同步。而在多线程的情况下,主线程创建出子线程后,各个子线程的任务函数从创建即开始执行,各个子线程之间不会阻塞等待前一个线程的任务完成后再开始执行后面的线程任务,而是继续向下去创建线程或执行主线程任务,即程序的执行顺序和任务的排列顺序不一致,这就是异步的概念。
**同步:**发出一个调用时,在没有得到结果之前,调用不会返回,调用者会阻塞等待这个调用的返回结果;
**异步:**调用发出之后,这个调用就直接返回了,调用者不会阻塞但这个调用不会返回结果。要获取这个调用的结果,则需通过状态,通知或回调函数来通知调用者
在多线程的情况下,主线程和子线程分别执行不同的任务,主线程想要获得子线程任务函数的返回结果,可以通过定义全局变量,子线程任务函数操作全局变量,主线程读取这个全局变量的方式实现,但这种方式存在很多潜在问题,如线程安全、数据竞争和难以维护等,而c++11为了处理这样的问题,为我们提供了更安全且易于管理的std::future、std::promise和std::async来更高效的解决线程间的数据传递问题。
- std::future
std::future是一个模板类,可以存储任意指定类型的数据,std::futrue提供了get()和wait()函数。在异步任务中,通过future对象存储异步线程任务执行结果,通过get()获取future对象内部保存的数据,通过wait()来阻塞当前线程,直到异步线程任务执行完毕解除当前线程阻塞。
| 序号 | API | 用途 | 说明 |
|---|---|---|---|
| 1 | get() | 获取future内部存储的数据 | 该函数是一个阻塞函数,当子线程数据就绪后解除阻塞,得到传出的数据 |
| 2 | wait() | 阻塞当前线程等着子线程任务函数执行完毕 | futrue对象内部存储的是异步线程任务执行完毕的结果,是在调用之后的将来得到的,因此调用wait()会阻塞当前线程,等待子线程执行完毕后解除对当前线程的阻塞 |
- std::promise
std::promise是一个协助线程赋值的类,能够将数据和future对象绑定,为获取线程函数的值提供便利。promise通过set_value()函数存储要传出的值,通过get_future()函数获得future对象。promise的使用流程如下:
- 在主线程中创建
std::promise对象; - 将这个
std::promise对象通过引用的方式传递给子线程的任务函数; - 在子线程任务函数中给
std::promise对象赋值; - 在主线程中通过
std::promise对象去除绑定的future实例对象; - 通过得到的
future对象去除子任务函数的返回结果。
#include <iostream>
#include <thread>
#include <future>// 一个简单的计算函数,将结果存储在 promise 中
void doCalculation(std::promise<int>&& p) {int result = 42; // 假设这是一些计算的结果p.set_value(result); // 设置 promise 的值,它将被 future 获取
}int main() {std::promise<int> promise; // 创建一个 promise 对象std::future<int> future = promise.get_future(); // 获取与 promise 相关联的 future// 创建一个线程来执行计算std::thread t(doCalculation, std::move(promise));// 在主线程中,我们可以通过 future 获取计算结果int result = future.get(); // 等待计算完成并获取结果std::cout << "The result is " << result << std::endl;t.join(); // 等待线程完成return 0;
}
- std::async
std::async是c++11标准库中的一个函数模板,用于启动一个异步任务,该任务在后台线程中执行。即通过这个函数可以直接启动一个子线程并在这个子线程中执行对应的任务函数,异步任务执行完成返回的结果也是存储到一个future对象中,当需要获取异步任务的结果时,只需调用future类的get()方法即可,如果不关注异步任务的解析,只要等待任务完成,则可调用future类的wait()或wait_for()方法。
c++11提供的std::saync函数有两种调用方式:
-
直接调用传递到
std::saync函数体内部的可调用对象,返回一个future对象; -
通过指定调用策略用传递到
std::saync函数内部的可调用调用,返回一个future对象。std::saync可设置调用策略的重载版本有以下调用策略:序号 调用策略 说明 1 std::launch::async调用 saync函数时,创建新的线程并执行任务函数2 std::launch::deferred调用 saync函数时不执行任务函数,直到调用future的get()或wait()时才执行任务(这种方式不会创建新的线程)下面给出两种使用方式的示例代码:
#include <iostream> #include <future> #include <thread> #include <chrono>//不指定调用策略int compute(int x, int y) {std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时操作return x + y; }int main() {// 使用 std::async 启动异步任务,不指定调用策略std::future<int> result = std::async(compute, 5, 3);// 在主线程中继续执行其他任务...std::cout << "Doing other work in the main thread..." << std::endl;// 获取异步操作的结果int sum = result.get(); // 这将阻塞,直到异步任务完成std::cout << "The result is " << sum << std::endl;return 0; }#include <iostream> #include <future> #include <thread> #include <chrono>//指定调用策略int compute(int x, int y) {std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时操作return x + y; }int main() {// 使用 std::async 启动异步任务,并指定调用策略std::future<int> result = std::async(std::launch::async, compute, 5, 3);// 在主线程中继续执行其他任务...std::cout << "Doing other work in the main thread..." << std::endl;// 获取异步操作的结果int sum = result.get(); // 这将阻塞,直到异步任务完成std::cout << "The result is " << sum << std::endl;return 0; }
2.3 线程池
线程池是一种用于管理和重用线程的技术,广泛用于需要大量短生命周期的应用场景,如并发处理、网络服务和高性能计算等。
线程池的基本思想是预先创建一定数量的线程,并将他们放入一个池中。线程池负责管理线程的生命周期,并将任务分配给空闲线程执行,这样可以避免每次任务执行时都创建和销毁线程的开销。其基本组成如下:
线程池管理器:负责创建、销毁线程,维护线程池状态;
任务队列:用于存储执行的任务函数,任务通常以函数对象(如std::function)的形式存储;
工作线程:线程池中实际线程,它们从任务队列中取出任务并执行。
同步机制:用于保护任务队列和线程池状态的线程安全操作,通常使用互斥量和条件变量。
#include <thread>
#include <mutex>
#include <atomic>
#include <condition_variable>
#include <functional>
#include <future>
#include <chrono>
#include <iostream>
#include <vector>
#include <queue>
#include <map>class ThreadPool
{
private:std::shared_ptr<std::thread> manager_;std::map<std::thread::id, std::thread> workers_;std::vector<std::thread::id> vec_ids_;int min_threads_num_;int max_htreads_num_;std::atomic<bool> stop_;std::atomic<int> cur_threads_; // 当前线程数量std::atomic<int> idle_threads_; // 空闲线程std::atomic<int> exit_threads_; // 需要退出的线程std::queue<std::function<void()>> tasks_;std::mutex id_mutex_;std::mutex queue_mutex_;std::condition_variable condition_;public:ThreadPool(int min_num = 4, int max_num = std::thread::hardware_concurrency());~ThreadPool();void add_task(std::function<void()> func);private:void manager();void worker();
};ThreadPool::ThreadPool(int min_num, int max_num) : min_threads_num_(min_num), max_htreads_num_(max_num), exit_threads_(0), stop_(false)
{idle_threads_ = cur_threads_ = min_num;std::cout << "The number of threads is " << std::endl;manager_ = std::make_shared<std::thread>(&ThreadPool::manager, this);for (int i = 0; i < cur_threads_; ++i){std::thread worker(&ThreadPool::worker, this);workers_.insert(std::make_pair(worker.get_id(), std::move(worker)));}
}ThreadPool::~ThreadPool()
{stop_ = true;condition_.notify_all();for (auto &worker : workers_){std::thread &th = worker.second;if (th.joinable()){std::cout << "The thread " << worker.first << " will exit..." << std::endl;th.join();}}if (manager_->joinable()){manager_->join();}
}void ThreadPool::manager()
{while (!stop_.load()){std::this_thread::sleep_for(std::chrono::seconds(1));int idle = idle_threads_.load();int cur = cur_threads_.load();// 当空闲线程数是当前线程数的一半且当前线程数量大于最小线程数量,退出两个线程if (idle > cur / 2 && cur > min_threads_num_){exit_threads_.store(2);condition_.notify_all();std::unique_lock<std::mutex> lock(id_mutex_);int count = 0; // 已退出线程数量for (auto it = vec_ids_.begin(); it != vec_ids_.end() && count < exit_threads_.load();){auto id = *it; // vector中的线程索引auto worker_it = workers_.find(id);if (worker_it != workers_.end()){std::cout << "The thread " << (*worker_it).first << " will exit..." << std::endl;(*worker_it).second.join();workers_.erase(worker_it);it = vec_ids_.erase(it);count++;}else{++it; // 如果线程ID不在workers_中,继续查找下一个ID}}}else if (idle == 0 && cur < max_htreads_num_){// 如果没有空闲线程,且当前线程数小于最大线程数,则创建新的工作线程std::thread worker(&ThreadPool::worker, this);std::cout << "Add a thread, id " << worker.get_id() << std::endl;workers_.insert(std::make_pair(worker.get_id(), std::move(worker)));cur_threads_++;idle_threads_++;}}
}void ThreadPool::worker()
{while (!stop_.load()){std::function<void()> task = nullptr;{std::unique_lock<std::mutex> lock(queue_mutex_);while (!stop_.load() && tasks_.empty()){condition_.wait(lock);// 如果有需要退出的线程,则将其退出if (exit_threads_.load() > 0){std::unique_lock<std::mutex> lock(id_mutex_);if (vec_ids_.empty() || workers_.find(std::this_thread::get_id()) == workers_.end()){return; // 若没有当前线程,则返回}vec_ids_.erase(std::remove(vec_ids_.begin(), vec_ids_.end(), std::this_thread::get_id()), vec_ids_.end());std::cout << "Thread task ended, id " << std::this_thread::get_id() << std::endl;exit_threads_--;cur_threads_--;return;}}if (!tasks_.empty()){std::cout << "Thread task ended..." << std::endl;task = std::move(tasks_.front());tasks_.pop();}}if (task){idle_threads_--;task(); //执行任务idle_threads_++;}}
}void ThreadPool::add_task(std::function<void()> func)
{{std::lock_guard<std::mutex> lock(queue_mutex_);tasks_.emplace(func);}condition_.notify_one();
}void add(int x,int y){int res=x+y;std::cout<<"res is "<<std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));
}int main(){ThreadPool th_pool(5);for(int i=0;i<50;++i){auto func=std::bind(add,i,i+10);th_pool.add_task(func);}std::getchar();return 0;
}
异步版本
#include <thread>
#include <mutex>
#include <atomic>
#include <condition_variable>
#include <functional>
#include <future>
#include <chrono>
#include <iostream>
#include <vector>
#include <queue>
#include <map>class ThreadPool
{
private:std::shared_ptr<std::thread> manager_;std::map<std::thread::id, std::thread> workers_;std::vector<std::thread::id> vec_ids_;int min_threads_num_;int max_htreads_num_;std::atomic<bool> stop_;std::atomic<int> cur_threads_; // 当前线程数量std::atomic<int> idle_threads_; // 空闲线程std::atomic<int> exit_threads_; // 需要退出的线程std::queue<std::function<void()>> tasks_;std::mutex id_mutex_;std::mutex queue_mutex_;std::condition_variable condition_;public:ThreadPool(int min_num = 4, int max_num = std::thread::hardware_concurrency());~ThreadPool();template <typename F, typename... Args>auto add_task(F&& func, Args &&...args) -> std::future<typename std::result_of<F(Args...)>::type>{using returnType = typename std::result_of<F(Args...)>::type;auto task = std::make_shared<std::packaged_task<returnType()>>(std::bind(std::forward<F>(func), std::forward<Args>(args)...));std::future<returnType> res = task->get_future();{std::unique_lock<std::mutex>(queue_mutex_);tasks_.emplace([task](){ (*task)(); });}condition_.notify_one();return res;}private:void manager();void worker();
};ThreadPool::ThreadPool(int min_num, int max_num) : min_threads_num_(min_num), max_htreads_num_(max_num), exit_threads_(0), stop_(false)
{idle_threads_ = cur_threads_ = min_num;std::cout << "The number of threads is " << std::endl;manager_ = std::make_shared<std::thread>(&ThreadPool::manager, this);for (int i = 0; i < cur_threads_; ++i){std::thread worker(&ThreadPool::worker, this);workers_.insert(std::make_pair(worker.get_id(), std::move(worker)));}
}ThreadPool::~ThreadPool()
{stop_ = true;condition_.notify_all();for (auto& worker : workers_){std::thread& th = worker.second;if (th.joinable()){std::cout << "The thread " << worker.first << " will exit..." << std::endl;th.join();}}if (manager_->joinable()){manager_->join();}
}void ThreadPool::manager()
{while (!stop_.load()){std::this_thread::sleep_for(std::chrono::seconds(1));int idle = idle_threads_.load();int cur = cur_threads_.load();// 当空闲线程数是当前线程数的一半且当前线程数量大于最小线程数量,退出两个线程if (idle > cur / 2 && cur > min_threads_num_){exit_threads_.store(2);condition_.notify_all();std::unique_lock<std::mutex> lock(id_mutex_);int count = 0; // 已退出线程数量for (auto it = vec_ids_.begin(); it != vec_ids_.end() && count < exit_threads_.load();){auto id = *it; // vector中的线程索引auto worker_it = workers_.find(id);if (worker_it != workers_.end()){std::cout << "The thread " << (*worker_it).first << " will exit..." << std::endl;(*worker_it).second.join();workers_.erase(worker_it);it = vec_ids_.erase(it);count++;}else{++it; // 如果线程ID不在workers_中,继续查找下一个ID}}}else if (idle == 0 && cur < max_htreads_num_){// 如果没有空闲线程,且当前线程数小于最大线程数,则创建新的工作线程std::thread worker(&ThreadPool::worker, this);std::cout << "Add a thread, id " << worker.get_id() << std::endl;workers_.insert(std::make_pair(worker.get_id(), std::move(worker)));cur_threads_++;idle_threads_++;}}
}void ThreadPool::worker()
{while (!stop_.load()){std::function<void()> task = nullptr;{std::unique_lock<std::mutex> lock(queue_mutex_);while (!stop_.load() && tasks_.empty()){condition_.wait(lock);// 如果有需要退出的线程,则将其退出if (exit_threads_.load() > 0){std::unique_lock<std::mutex> lock(id_mutex_);if (vec_ids_.empty() || workers_.find(std::this_thread::get_id()) == workers_.end()){return; // 若没有当前线程,则返回}vec_ids_.erase(std::remove(vec_ids_.begin(), vec_ids_.end(), std::this_thread::get_id()), vec_ids_.end());std::cout << "Thread task ended, id " << std::this_thread::get_id() << std::endl;exit_threads_--;cur_threads_--;return;}}if (!tasks_.empty()){std::cout << "Thread task ended..." << std::endl;task = std::move(tasks_.front());tasks_.pop();}}if (task){idle_threads_--;task(); // 执行任务idle_threads_++;}}
}int add(int x, int y)
{int res = x + y;// std::cout << "res is " << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));return res;
}int main()
{ThreadPool th_pool(5);std::vector<std::future<int>> results;for (int i = 0; i < 50; ++i){results.emplace_back(th_pool.add_task(add, i, i + 10));}//等待结果for (auto&& res : results) {std::cout << "res is " << res.get() << std::endl;}return 0;
}
参考资料:
1.爱编程的大丙 - 知识分享 (subingwen.cn)
2.C++多线程详解(全网最全)-CSDN博客
3.C++多线程并发(四)—异步编程_c++ 异步 同步-CSDN博客
相关文章:
【c++】c++11多线程开发
2 C多线程 本文是参考爱编程的大丙c多线程部分内容,按照自己的理解对其进行整理的一篇学习笔记,具体一些APi的详细说明请参考大丙老师教程。 代码性能的问题主要包括两部分的内容,一个是前面提到资源的获取和释放,另外一个就是多…...

PW37R_V1 产品规格书
概述 PW37R_V1是一款采用3.7英寸黑白红三色电子纸显示的电子标签,采用一种先进的无线自动更新系统,实现无线传输。 通过http,mqtt协议更新数据和控制该款电子标签的显示等操作,显示内容可自定义。内置电池供电,可Typ…...

android11 usb摄像头添加多分辨率支持
部分借鉴于:https://blog.csdn.net/weixin_45639314/article/details/142210634 目录 一、需求介绍 二、UVC介绍 三、解析 四、补丁修改 1、预览的限制主要存在于hal层和framework层 2、添加所需要的分辨率: 3、hal层修改 4、frameworks 5、备…...

【开源免费】基于SpringBoot+Vue.JS房屋租赁系统(JAVA毕业设计)
本文项目编号 T 020 ,文末自助获取源码 \color{red}{T020,文末自助获取源码} T020,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 查…...

JavaScript全面指南(二)
🌈个人主页:前端青山 🔥系列专栏:Javascript篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来JavaScript篇专栏内容:JavaScript全面指南(二) 目录 21、说明如何使用JavaScript提交表单? 2…...
Nginx:Linux配置Nginx
目录 一、环境安装1.1 GCC编译器1.2 PCRE1.3 Zlib1.4 OpenSSL1.5 快速下载 二、Nginx源码简单安装2.1 下载安装包2.2 解压2.3 进入资源文件中2.4 编译、安装 三、Yum安装四、Nginx源码复杂安装4.1 参数介绍4.2 参数配置 五、卸载Nginx5.1 关闭Nginx进程5.2 将安装的Nginx删除5.…...

WebRTC音频 04 - 关键类
WebRTC音频01 - 设备管理 WebRTC音频 02 - Windows平台设备管理 WebRTC音频 03 - 实时通信框架 WebRTC音频 04 - 关键类(本文) 一、前言: 在WebRTC音频代码阅读过程中,我们发现有很多关键的类比较抽象,搞不清楚会导致代码阅读一脸懵逼。比如…...

Elasticsearch:Redact(编辑) processor
Redact 处理器使用 Grok 规则引擎来隐藏输入文档中与给定 Grok 模式匹配的文本。该处理器可用于隐藏个人身份信息 (Personal Identifying Information - PII),方法是将其配置为检测已知模式,例如电子邮件或 IP 地址。与 Grok 模式匹配的文本将被替换为可…...

O2OA结合备份脚本和定时任务进行数据库的备份,我们以MySQL数据库为例
概述 系统运行一段时间后,可能发生各种情况导致数据丢失,如硬件故障、人为错误、软件错误、病毒攻击等。定期备份可以帮助您保护数据免受这些风险的影响,以便在需要时能够恢复数据。 O2OA应用本身可以通过dump配置每天自定备份数据ÿ…...

Python自动化办公:批量提取PDF中的表格到Excel
在现代办公环境中,处理大量的PDF文件并提取其中的表格数据是一项常见而繁琐的任务。手动复制粘贴不仅耗时耗力,还容易出错。Python作为一种功能强大的编程语言,提供了丰富的工具包,可以高效地解决这一问题。本文将介绍如何使用Pyt…...
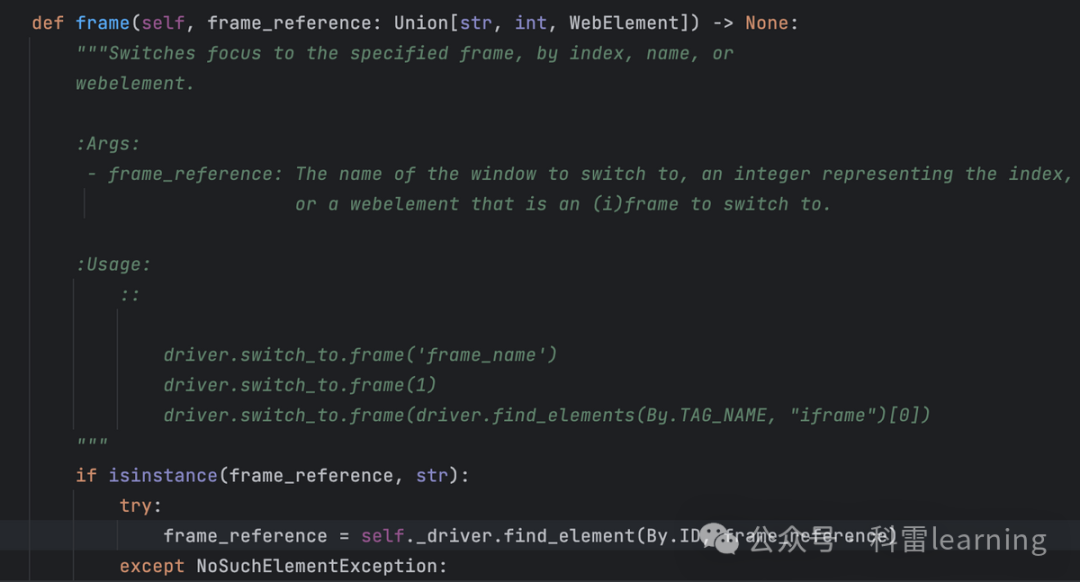
selenium有多个frame页时的操作方法(5)
之前文章我们提到,在webdriver.WebDriver类有一个switch_to方法,通过switch_to.frame()可以切换到不同的frame页然后才再定位某个元素做一些输入/点击等操作。 比如下面这个测试网站有2个frame页:http://www.sahitest.com/demo/framesTest.h…...
谷歌外链的周期性维护!
外链建设不是一次性的工作,它需要长期的维护和更新,才能持续为网站带来稳定的流量和SEO提升。很多网站在初期通过短期内大规模获取外链的方式,确实能看到排名的提升,但这种方法往往难以维持长期的效果。谷歌更喜欢自然、持续增长的…...

CATIA软件许可管理最佳实践
在当今的工程设计领域,CATIA软件已成为众多企业不可或缺的工具。然而,随着软件使用的广泛普及,许可管理变得尤为关键。本文将为您探讨CATIA软件许可管理的最佳实践,助您在确保合规性的同时,实现成本效益的最大化。 一、…...

大华智能云网关注册管理平台 SQL注入漏洞复现(CNVD-2024-38747)
0x01 产品简介 大华智能云网关注册管理平台是一款专为解决社会面视频资源接入问题而设计的高效、便捷的管理工具,平台凭借其高效接入、灵活部署、安全保障、兼容性和便捷管理等特点,成为了解决社会面视频资源接入问题的优选方案。该平台不仅提高了联网效率,降低了联网成本,…...
什么是思维导图,手把手教你做经典思维导图
在信息爆炸的时代,如何高效整理思绪、激发创意、提升学习效率成为了我们共同面临的挑战。思维导图,这一源自脑科学的思维工具,以其直观、灵活的特点,成为了众多学习者、管理者和创意人士的得力助手。今天,就让我们一起…...
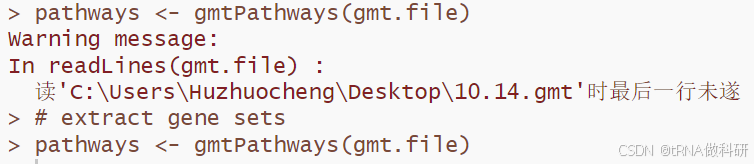
使用GSEA读‘gmt文件‘时最后一行未遂问题解决
最近工作中,使用GSEA网站自定义库下载的gmt文件用函数读取的时候报错: 这种问题在文本文件读取中经常出现,往往因为最后一行未留出/n,也就是最后一行没有换行留出空行。 可以使用notepad打开gmt文件: 发现果然最后一行…...

C++中vector常用函数总结
一,vector vector可以理解为一个边长数组,可以存储不同的类型,int ,double,char,结构体等。 也可以才能出STL标准容器,如set,string,vector等 二,构造函数 vector(size_t n,T val) …...

手撕数据结构 —— 队列(C语言讲解)
目录 1.什么是队列 2.如何实现队列 3.队列的实现 Queue.h中接口总览 具体实现 结构的定义 初始化 销毁 入队列 出队列 取队头元素 取队尾元素 判断是否为空 获取队列的大小 4.完整代码附录 Queue.h Queue.c 1.什么是队列 队列是一种特殊的线性表࿰…...

Java知识巩固(五)
目录 基本数据类型 基本类型和包装类型的区别? 自动装箱与拆箱了解吗?原理是什么? 为什么浮点数运算的时候回邮精度丢失的风险? 如何解决浮点数运算的精度丢失问题? 超过 long 整型的数据应该如何表示? 基本数据…...

C# 中 yield关键字的使用
yield return有以下优点: 每次迭代时生成一个值,并且在下次迭代时继续从上次离开的地方开始。 延迟执行:只有在实际需要时才会生成下一个值,这对于处理大量数据非常有用。 节省内存:不需要一次性将所有数据加载到内存中…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

三步破解百度网盘限速:免费获取真实下载链接的终极指南
三步破解百度网盘限速:免费获取真实下载链接的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而苦恼吗?想要彻…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...