拓扑排序在实际开发中的应用
1. 拓扑排序说明
简单解释:针对于有向无环图(DAG),给出一个可行的节点排序,使节点之间的依赖关系不冲突。
复杂解释:自行搜索相关资料。
本次应用中的解释:给出一个可行的计算顺序,使得每个字段计算时,所需的变量已经完成了计算。
2. 业务场景
在开发的报表数据管理系统中,系统的业务流程如下:
① 先从目标数据库中抓取数据值,例如目标系统为物流系统,抓取其中物流订单的相关数据,送货地区、货物体积、数量、型号等数据。
② 对数据进行一定的运算逻辑,如计算总费用= 运费+卸货费
问题难点:
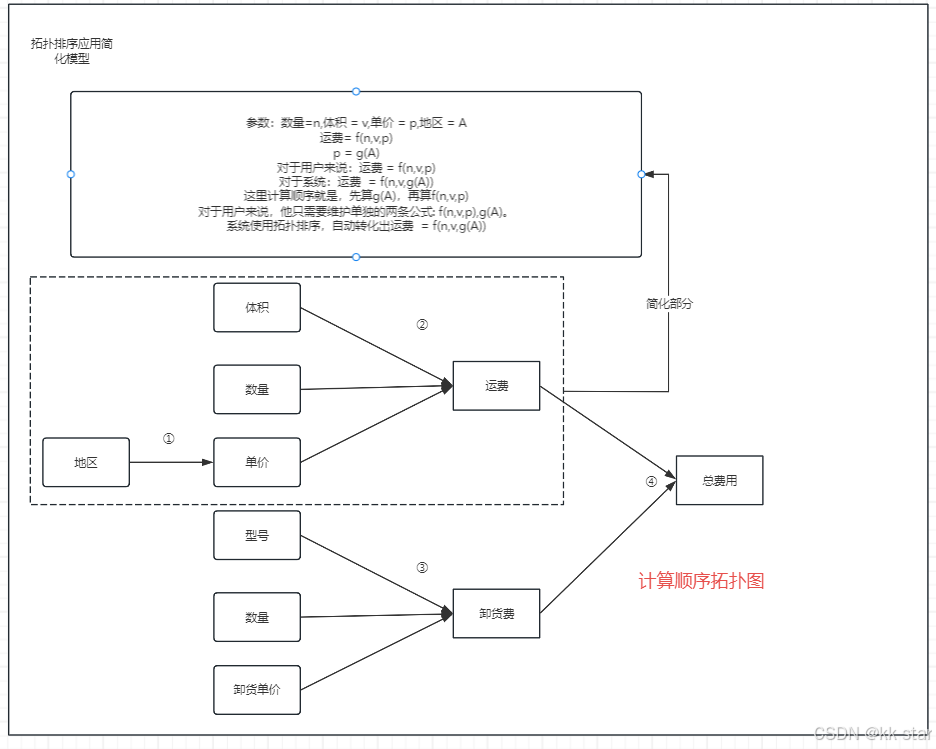
系统在计算的过程中,存在多级计算,如下图中的单价、运费、卸货费、总费用都需要进行计算,如何确定每个字段的计算顺序,保证总费用在计算时,运费已经完成计算了。即系统需要将运费的计算先排在总费用的计算前面。这个时候就可以应用到拓扑排序。
如果系统不去进行这么一个排序的话,用户在添加公式的时候,需要考虑字段之间的顺序是否符合先后顺序, 如果出现了计算总费用时,运费这个字段还没有计算完成的情况,系统会出现报错,用户需要对错误进行排查,导致用户使用体验非常差。
3. 实际应用代码
kahn算法说明:
- 维护一个入度为0的队列
- 先找到所有入度为0的点,并从图中移除,加入到入度为0的队列中,即setOfZeroIndegree
- 循环处理setOfZeroIndegree队列中的所有点,将点向外指出的边进行删除,A->B,A的入度为0 ,B的入度为1,删除掉A点和B点的边后,B点的入度为0,这个时候B点也可以加入setOfZeroIndegree队列中
- 挡setOfZeroIndegree队列为空时,判断图中是否还有边没有删除干净,如果没有删除干净,则当前图为有环图,无法得到可行解。如果删除干净了,表示给出的图是有可行解的。
拓扑排序工具类
/*** @author kstar* @date 2024/10/16* @description* 操作方法见main方法,有详细的操作流程*/import java.util.*;public class GraphUtils {// 定义点的数据结构public static class Node {public Object val;public int pathIn = 0; // 入链路数量public Node(Object val) {this.val = val;}}/*** 拓扑图类*/public static class Graph {// 图中节点的集合public Set<Node> vertexSet = new HashSet<Node>();// 相邻的节点,纪录边public Map<Node, Set<Node>> adjaNode = new HashMap<Node, Set<Node>>();// 将节点加入图中public boolean addNode(Node start, Node end) {// 判断节点集合中是否有这两个节点,没有的话就加入到节点集合if (!vertexSet.contains(start)) {vertexSet.add(start);}if (!vertexSet.contains(end)) {vertexSet.add(end);}// 如果图中已经存在该边,则不添加if (adjaNode.containsKey(start)&& adjaNode.get(start).contains(end)) {return false;}// 判断当前节点是否有边的map,有的话可以直接加入,没有的话新建一个setif (adjaNode.containsKey(start)) {adjaNode.get(start).add(end);} else {Set<Node> temp = new HashSet<Node>();temp.add(end);adjaNode.put(start, temp);}// 被指向的节点入度+1end.pathIn++;return true;}}/**Kahn算法* 0. 维护一个入度为0的队列* 1. 先找到所有入度为0的点,并从图中移除,加入到入度为0的集合中* 2. 循环处理setOfZeroIndegree集合中的所有点,*/public static class KahnTopo {private List<Node> result; // 用来存储结果集,结果数据集就是最终的排序结果private Queue<Node> setOfZeroIndegree; // 用来存储入度为0的顶点private Graph graph;//构造函数,初始化public KahnTopo(Graph di) {this.graph = di;this.result = new ArrayList<Node>();this.setOfZeroIndegree = new LinkedList<Node>();// 对入度为0的集合进行初始化for(Node iterator : this.graph.vertexSet){if(iterator.pathIn == 0){this.setOfZeroIndegree.add(iterator);}}}//拓扑排序处理过程public void process() {while (!setOfZeroIndegree.isEmpty()) {Node v = setOfZeroIndegree.poll();// 将当前顶点添加到结果集中result.add(v);if (this.graph.adjaNode.get(v)==null){this.graph.vertexSet.remove(v);continue;}if(this.graph.adjaNode.keySet().isEmpty()){return;}// 遍历由v引出的所有边for (Node w : this.graph.adjaNode.get(v) ) {// 将该边从图中移除,通过减少边的数量来表示w.pathIn--;if (0 == w.pathIn) // 如果入度为0,那么加入入度为0的集合{setOfZeroIndegree.add(w);}}this.graph.vertexSet.remove(v);this.graph.adjaNode.remove(v);}// 如果此时图中还存在边,那么说明图中含有环路if (!this.graph.vertexSet.isEmpty()) {List<String> errNode = new ArrayList<>();for (Node node : this.graph.vertexSet) {errNode.add(node.val.toString());}throw new IllegalArgumentException("当前参数存在循环依赖,请检查:"+errNode);}}//结果集public Iterable<Node> getResult() {return result;}}//测试方法public static void main(String[] args) {// 添加点Node A = new Node("A");Node B = new Node("B");Node C = new Node("C");Node D = new Node("D");Node E = new Node("E");Node F = new Node("F");// 添加边Graph graph = new Graph();graph.addNode(A, B);graph.addNode(B, C);graph.addNode(B, D);graph.addNode(D, C);graph.addNode(E, C);graph.addNode(C, F);KahnTopo topo = new KahnTopo(graph);topo.process();for(Node temp : topo.getResult()){System.out.print(temp.val.toString() + "-->");}}
}实际应用代码
// 在实际业务场景中的应用,仅做说明演示,直接复制过去无法使用,要用的话用上面的代码的main方法即可测试
// 样例方法中,需要对CollectSchemeDetail这个类中进行排序,
// 排序时根据类中的getCollectResultCode构建图,将计算时需要的字段解析出来构建图
public void calculateOrder(String collectSchemeCode){List<CollectSchemeDetail> collectSchemeDetails = listByCode(collectSchemeCode);Map<String, GraphUtils.Node> nodeMap = new HashMap<>();// 循环遍历对象数组中的值,取出其中的点和图的关系for (CollectSchemeDetail schemeDetail : collectSchemeDetails) {GraphUtils.Node node = new GraphUtils.Node(schemeDetail.getCollectResultCode());nodeMap.put(schemeDetail.getCollectResultCode(),node);}GraphUtils.Graph graph = new GraphUtils.Graph();for (CollectSchemeDetail schemeDetail : collectSchemeDetails) {if (schemeDetail.getCollectType().equals(CollectSchemeDetail.CollectTypeEnum.EQUATION)) {if (schemeDetail.getExpression()==null||!schemeDetail.getExpression().contains("$")){throw new GlobalException("公式:["+schemeDetail.getCollectResultName()+"]中没有设置表达式,请先设置表达式后再添加");}// 公式解析,expression为公式,如A+B-C,// JEPUtils.getVariables的方法可以将公式中的有效字段解析出来List<String> variableList = JEPUtils.getVariables(schemeDetail.getExpression());for (String variable : variableList) {graph.addNode(nodeMap.get(variable), nodeMap.get(schemeDetail.getCollectResultCode()));}}}// 执行拓扑排序算法GraphUtils.KahnTopo topo = new GraphUtils.KahnTopo(graph);topo.process();Map<String,List<CollectSchemeDetail>> resultCodeSchemeDetailMap = collectSchemeDetails.stream().collect(Collectors.groupingBy(CollectSchemeDetail::getCollectResultCode));int i = 1;List<CollectSchemeDetail> needUpdateList = new ArrayList<>();// 循环拓扑排序的结果,对数据的计算顺序进行更新for(GraphUtils.Node temp : topo.getResult()){for (CollectSchemeDetail collectSchemeDetail : resultCodeSchemeDetailMap.get(temp.val.toString())) {collectSchemeDetail.setCalculateOrder(i);}needUpdateList.addAll(resultCodeSchemeDetailMap.get(temp.val.toString()));i++;}updateBatchById(needUpdateList);}
4. 解决问题
处理后字段的计算顺序按照拓扑排序给出的一个可行解进行排序,如在给出的样例图中,运费的计算需要先由地区计算出单价,再由单价*数量得到运费。那么地区、数量、体积的计算顺序应该是0,运费的计算顺序是1,卸货费用的计算顺序是2,总费用的计算顺序为3,总费用= 运费+卸货费用。
至此,用户可以随意的去修改字段之间的计算公式,而不需要考虑计算顺序出现错误。只有在设定的公式存在环路时,系统会返回报错信息,告知用户哪几个字段之间存在环路,让用户重新配置公式。
用户的使用体验得到了优化。
5. 相关链接
本样例说明源码开源在:
ruoyi-reoprt gitee仓库
ruoyi-report github仓库
欢迎大家到到项目中多给点star支持,对项目有建议或者有想要了解的欢迎一起讨论
相关文章:
拓扑排序在实际开发中的应用
1. 拓扑排序说明 简单解释:针对于有向无环图(DAG),给出一个可行的节点排序,使节点之间的依赖关系不冲突。 复杂解释:自行搜索相关资料。 本次应用中的解释:给出一个可行的计算顺序࿰…...

【CTF-SHOW】Web入门 Web27-身份证日期爆破 【关于bp intruder使用--详记录】
1.点进去 是一个登录系统,有录取名单和学籍信息 发现通过姓名和身份证号可以进行录取查询,推测录取查询可能得到学生对应学号和密码,但是身份证号中的出生日期部分未知,所以可以进行爆破 2.打开bp抓包 这里注意抓的是学院录取查…...

Windows 添加右键以管理员身份运行 PowerShell
在 Windows 系统中添加一个右键菜单选项,以便可以使用管理员权限打开 PowerShell,可以通过编辑注册表来实现。 打开注册表编辑器: 按 Win R 打开运行对话框。输入 regedit 并按回车,这将打开注册表编辑器。 导航到文件夹背景键&…...

数学建模算法与应用 第15章 预测方法
目录 15.1 微分方程模型 Matlab代码示例:求解简单的微分方程 15.2 灰色预测模型(GM) Matlab代码示例:灰色预测模型 15.3 自回归模型(AR) Matlab代码示例:AR模型的预测 15.4 指数平滑法 M…...

HC32F460KETA PETB JATA 工业 自动化 电机
HC32F460 系列是基于 ARM Cortex-M4 32-bit RISC CPU,最高工作频率 200MHz 的高性能 MCU。Cortex-M4 内核集成了浮点运算单元(FPU)和 DSP,实现单精度浮点算术运算,支持 所有 ARM 单精度数据处理指令和数据类型…...

linux系统,不定时kernel bug :soft lockup的问题
这个问题困扰好久,机器经常不定时卡死,只能重启 后来检查是因为没有安装nvidia显卡驱动,或者更新到最新驱动 下载地址:驱动详情 禁止nouveau就可以了...
可移植库 - <unistd.h> 和 <sys/types.h>)
【C语言教程】【常用类库】(十四)可移植库 - <unistd.h> 和 <sys/types.h>
14. 可移植库 - <unistd.h> 和 <sys/types.h> UNIX和类UNIX系统上提供的一组头文件,其中<unistd.h>定义了POSIX操作系统API的访问点,而<sys/types.h>定义了许多基础数据类型。这些库在多种环境中增强了C程序的可移植性。 14.1…...

Java项目实战II基于Spring Boot的周边游平台设计与实现(源码+数据库+文档)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 随着人们生…...
远程控制软件哪个好用:4款主流的远程控制软件大点评,谁最给力?
战国时期,有百家争鸣,九流十家,争芳斗艳; 时至今日,科学技术突飞猛进、一日千里,各大远程控制软件更是佳丽三千、琳琅满目、各有千秋! 这时,新的问题来了:远程控制软件哪…...

基于springboot实习管理系统
作者:计算机学长阿伟 开发技术:SpringBoot、SSM、Vue、MySQL、ElementUI等,“文末源码”。 系统展示 【2024最新】基于JavaSpringBootVueMySQL的,前后端分离。 开发语言:Java数据库:MySQL技术:…...

(38)MATLAB分析带噪信号的频谱
文章目录 前言一、MATLAB仿真代码二、仿真结果画图总结 前言 本文给出带噪信号的时域和频域分析,指出频域分析在处理带噪信号时的优势。 首先使用MATLAB生成一段信号,并在信号上叠加高斯白噪声得到带噪信号,然后对带噪信号对其进行FFT变换&…...

多级缓存-案例导入说明
为了演示多级缓存,我们先导入一个商品管理的案例,其中包含商品的CRUD功能。我们将来会给查询商品添加多级缓存。 1.安装MySQL 后期做数据同步需要用到MySQL的主从功能,所以需要大家在虚拟机中,利用Docker来运行一个MySQL容器。 1.1.准备目录 为了方便后期配置MySQL,我们…...
:SpaCy + Training Neural Network)
基于Python的自然语言处理系列(31):SpaCy + Training Neural Network
1. 介绍 在自然语言处理的多个任务中,训练神经网络模型是一个至关重要的步骤,它能帮助我们实现更精准的模型预测。对于特定的任务,如命名实体识别(NER)或文本分类,使用自定义的训练数据对模型进行微调是提高模型表现的有效方式。在这篇文章中,我们将深入探讨如何从零开始…...

在 cPanel 中管理区域编辑权限
在 cPanel & WHM 60 版本中,cPanel 界面有四种不同方式编辑你的区域文件。简单 DNS 编辑器(cPanel >> 域名 >> 简单 DNS 编辑器)允许用户设置 A 记录和 CNAME 记录。高级 DNS 编辑器(cPanel >> 域名 >&g…...

web前端网页用户注册页面
源码: <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>用户注册</title> </head> <body><form action"#" metho…...

问题记录-- 在 Vue2 中动态更新 Select 组件的选项
在 Vue2 中动态更新 Select 组件的选项 在 Vue 开发中,动态更新表单组件的选项是一个常见的需求。特别是在使用 select 组件时,如何确保选项能够实时反映数据的变化是一个值得关注的问题。本文将探讨如何通过方法获取 select 的 options 来解决这一问题…...

Opencv形态学的膨胀操作、开运算与闭运算、梯度运算、礼帽与黑帽操作
文章目录 一、膨胀操作二、开运算与闭运算三、梯度运算四、礼帽与黑帽操作 一、膨胀操作 膨胀操作也就是根据图片将边缘的一些细节给丰富,处理的程度取决于卷积核的大小还有膨胀次数。也就是腐蚀操作的相反操作(腐蚀操作参考我的上一篇文章 点击跳转&am…...
keil 中添加gcc编译 stmf207
一、安装下载arm-gcc 编译器: 二、在keil中配置gcc: 三、配置工程选项 1.配置gcc编译规则: Misc Controls : -mcpucortex-m3 -mthumb -fdata-sections -ffunction-sections 注: 1.这里我用的cortex-m3,如果你是m4内核…...

BEV相关
1.deformable DETR是在DETR基础上做了什么 Deformable DETR 是对经典 DETR(Detection Transformer)进行的改进,旨在解决 DETR 训练速度慢、对大目标的定位不精确等问题。它主要在以下几个方面做了优化: 稀疏的多尺度注意力机制&a…...

nodepad++带时间段的关键字搜索筛选
10:11:[2-3][0-9].(com.asus.rogforum) 如图:冒号后面的[2-3]表示秒的十位20秒到30秒之间,如果想筛选多个则(com.asus.rogforum)中的多个关键字之间用|分隔...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...