docker安装elasticsearch和ik分词器
目录
ElasticSearch
了解ElasticSearch
ELK技术栈
编辑 ElasticSearch与lucene的关系
总结
倒排索引
正向索引
倒排索引
正向和倒排
elasticSearch特定的一些概念
文档和字段
索引和映射
mysql与elasticsearch对比
安装elasticSeacher并部署单例es
创建网络
加载es镜像和kibana镜像
运行es镜像
部署kibana
查看kibana
安装IK分词器
下载压缩包
查询到es-plugins数据卷存在的实际位置
cd到这个实际位置,并把ik文件夹拉到这个目录中
重启es容器
测试:
扩展IK分词器
进入ik的config目录
在IKAnalyzer.cfg.xml配置文件内容添加:ext.dic
这里没有配置ext.dic的文件路径,说明和IKAnalyzer.cfg.xml在同一个目录下
然后重启es
测试,可以发现我勒个豆已经成为一个最小单元的词条
编辑 停用词词典
1)IKAnalyzer.cfg.xml配置文件内容添加:
2)打开stopword.dic(config中已经存在,不用重新创建)
3)重启es
4)测试
编辑 总结:分词器的作用
IK分词器有几种模式
ElasticSearch
了解ElasticSearch
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
ELK技术栈
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域:
而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
 ElasticSearch与lucene的关系
ElasticSearch与lucene的关系
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。
总结
什么是elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
- 是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
正向索引
什么是正向索引呢

如果根据id值直接查询,那么直接走主键索引,查询速度比较快
如果是根据title进行模糊查询
- 用户进行搜索数据时,条件为%手机%
- 那么就一行一行的获取数据,然后再判断title字段值是否符合条件
- 符合条件就放入结果集,不符合条件就丢弃,继续下一行获取数据进行比对
这就是所谓的逐行扫描,也就是全表扫描,随着数据量的增多,其查询效率会越来越低
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息。也就是数据库中的一行数据 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条。词条就是把文档数据根据某种规则进行拆分成几个词
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引

倒排索引的搜索流程如下(以搜索"华为手机"为例):
当用户输入华为手机时,进行词条分割,得到华为,手机两个词条,然后再倒排索引的表中获得对应的文档id(1,2,3)然后拿着文档id去数据库表中进行查找具体的信息(因为根据的是主键Id,走索引,查询速率比较快)
 虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引(可以建立联合唯一索引),查询速度非常快!无需全表扫描。
虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引(可以建立联合唯一索引),查询速度非常快!无需全表扫描。
正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条(再倒排索引表中)先得到词条的文档的id,然后再根据获得的id去数据表中获取对应的文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
elasticSearch特定的一些概念
文档和字段
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
 可以看见数据库的每一行数据都被序列化成了json数据,每一个json数据对应的key就是字段名
可以看见数据库的每一行数据都被序列化成了json数据,每一个json数据对应的key就是字段名
每一个json数据就是叫做文档(document),json数据里面的key值就是字段(Field)
索引和映射
索引(Index),就是相同类型的文档的集合。一个索引就是相当于数据库中的一张数据表
也就是说一个索引包含了很多相同类型的文档
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql与elasticsearch对比
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性

安装elasticSeacher并部署单例es
创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
创建网络的原因是在同一网络中的容器(即kibana)可以直接通过容器的名字(es)来获取 es的ip地址
docker network create es-net 创建成功
加载es镜像和kibana镜像
docker pull ...
加载压缩包
docker load -i es.tar
运行es镜像
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录(如果没有这个数据卷,可以自动创建)-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置,http访问的入口- -p 9300:9300:tcp协议端口,用于集群模式下节点与节点之间的心跳检查的
在浏览器中输入:http://192.168.230.100:9200 即可看到elasticsearch的响应结果:

部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:

查看kibana
192.168.230.100:5601,里面的dev tools


这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
DSL就是elasticsearch提供的特殊语法,基本格式如下:
[请求方式] /[请求路径]
{[请求参数key1]: [请求参数value1],[请求参数key2]: [请求参数value2]
}例如
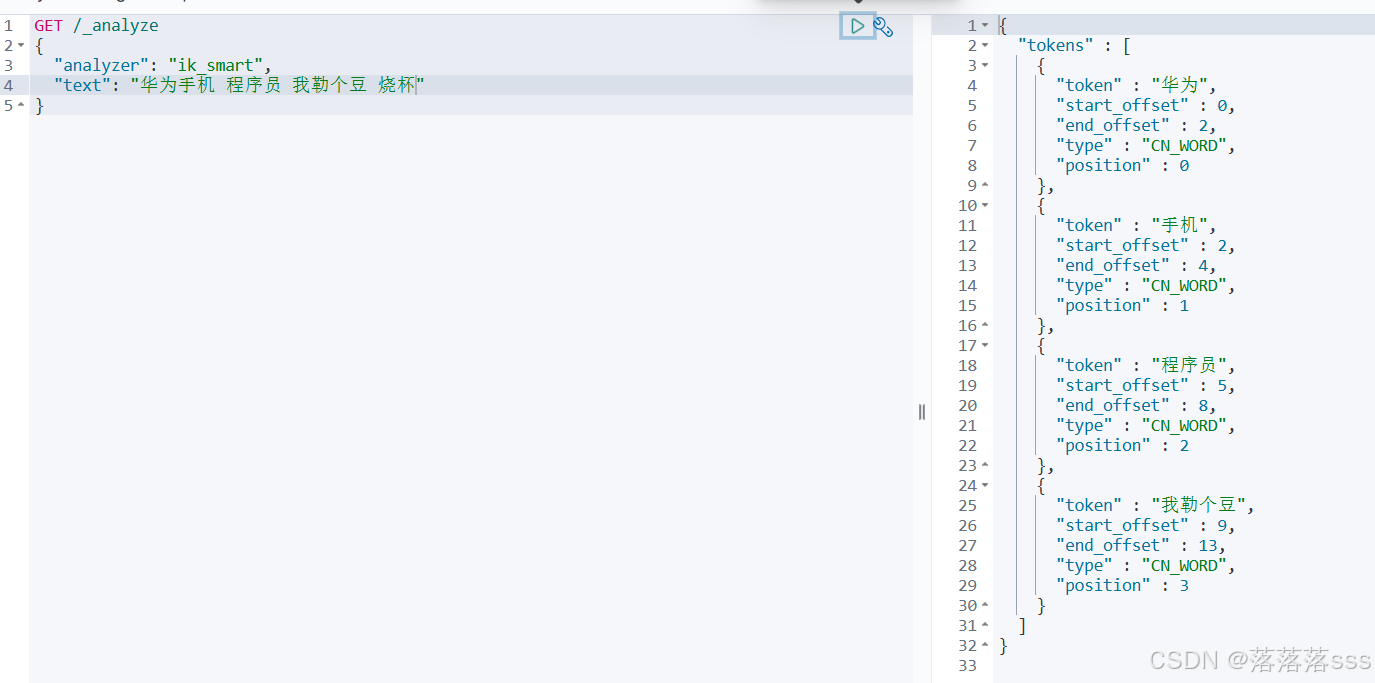
GET /_analyze
{"analyzer": "standard","text": "华为手机"
}运行结果后默认是把文档拆成一个一个字的词条

安装IK分词器
因为默认的行为是把文档拆成一个一个字的词条,不符合我们的习惯,所以需要安装国内的开源的IK分词器
下载压缩包
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip解压这个压缩包得到ik文件夹
查询到es-plugins数据卷存在的实际位置

cd到这个实际位置,并把ik文件夹拉到这个目录中

重启es容器
docker restart es测试:
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
使用最少切分的模式可以把华为,手机分割出来,但是对于网络热词无法切分
 使用ik_max_word模式进行分词,可以发现分出来的词更加细腻,把"程序员"还分成了"程序"和"员"
使用ik_max_word模式进行分词,可以发现分出来的词更加细腻,把"程序员"还分成了"程序"和"员"

扩展IK分词器
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“我了个豆”等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。我们可以自己进行配置
进入ik的config目录
cd ik/config

在IKAnalyzer.cfg.xml配置文件内容添加:ext.dic
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
这里没有配置ext.dic的文件路径,说明和IKAnalyzer.cfg.xml在同一个目录下
vim ext.dic
在这个文件中添加词汇

然后重启es
docker restart es
测试,可以发现我勒个豆已经成为一个最小单元的词条
 停用词词典
停用词词典
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典--><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--><entry key="ext_stopwords">stopword.dic</entry>
</properties>2)打开stopword.dic(config中已经存在,不用重新创建)
添加屏蔽词汇

3)重启es
docker restart es
4)测试
直接把不显示屏蔽词
 总结:
总结:
分词器的作用
- 创建倒排索引时对文档进行分词
- 用户搜索时,对输入的内容进行分词
IK分词器有几种模式
- ik_smart:智能切片,粗粒度
- ik_max_word:最细分片,细粒度
相关文章:
docker安装elasticsearch和ik分词器
目录 ElasticSearch 了解ElasticSearch ELK技术栈 编辑 ElasticSearch与lucene的关系 总结 倒排索引 正向索引 倒排索引 正向和倒排 elasticSearch特定的一些概念 文档和字段 索引和映射 mysql与elasticsearch对比 安装elasticSeacher并部署单例es 创建网络 加…...

|智能门票|008_django基于Python的智能门票设计与实现2024_i16z2v70
目录 系统展示 设计步骤 代码实现 项目案例 获取源码 博主介绍:CodeMentor毕业设计领航者、全网关注者30W群落,InfoQ特邀专栏作家、技术博客领航者、InfoQ新星培育计划导师、Web开发领域杰出贡献者,博客领航之星、开发者头条/腾讯云/AW…...
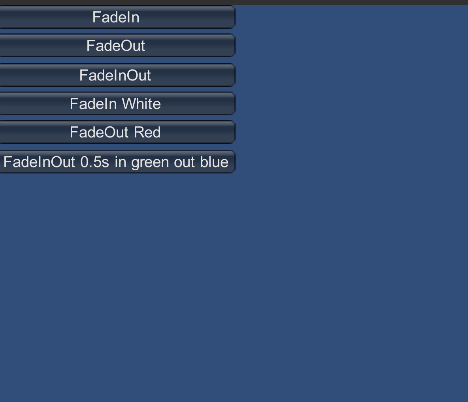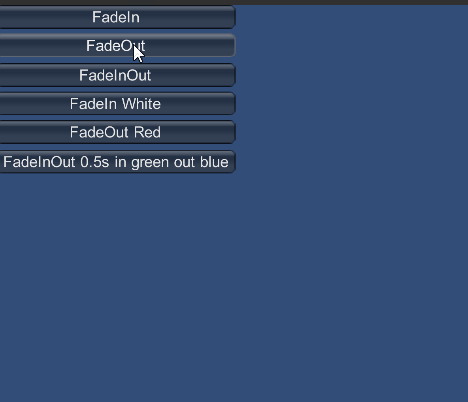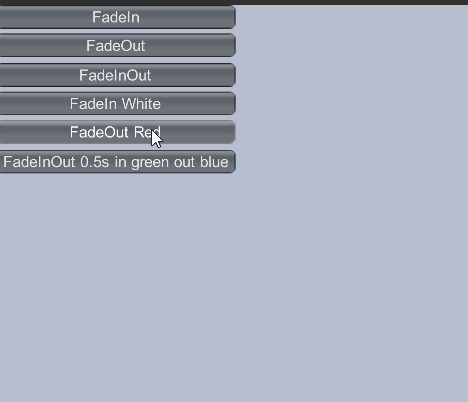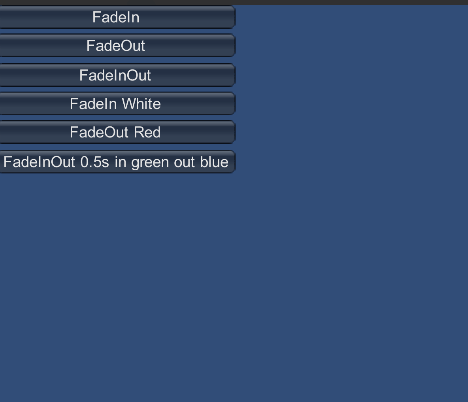
QFramework v1.0 使用指南 更新篇:20240919. 新增 BindableDictionary
增加了三个比较常用的屏幕过渡:FadeIn,FadeOut,FadeInOut。 示例代码如下: using UnityEngine;namespace QFramework.Example {public class ScreenTransitionsExample : MonoBehaviour{private void OnGUI(){IMGUIHelper.SetDesignResolut…...
vue实现文件预览和文件上传、下载、预览——多图、模型、dwg图纸、文档(word、excel、ppt、pdf)
整体思路(模型特殊不考虑,别人封装不具备参考性) 图片上传采用单独的组件,其他三种类型采用一个上传组件(仅仅文件格式不同)文件上传采用前端直接上传阿里云的方式图片预览使用elementUI自带的image预览dw…...
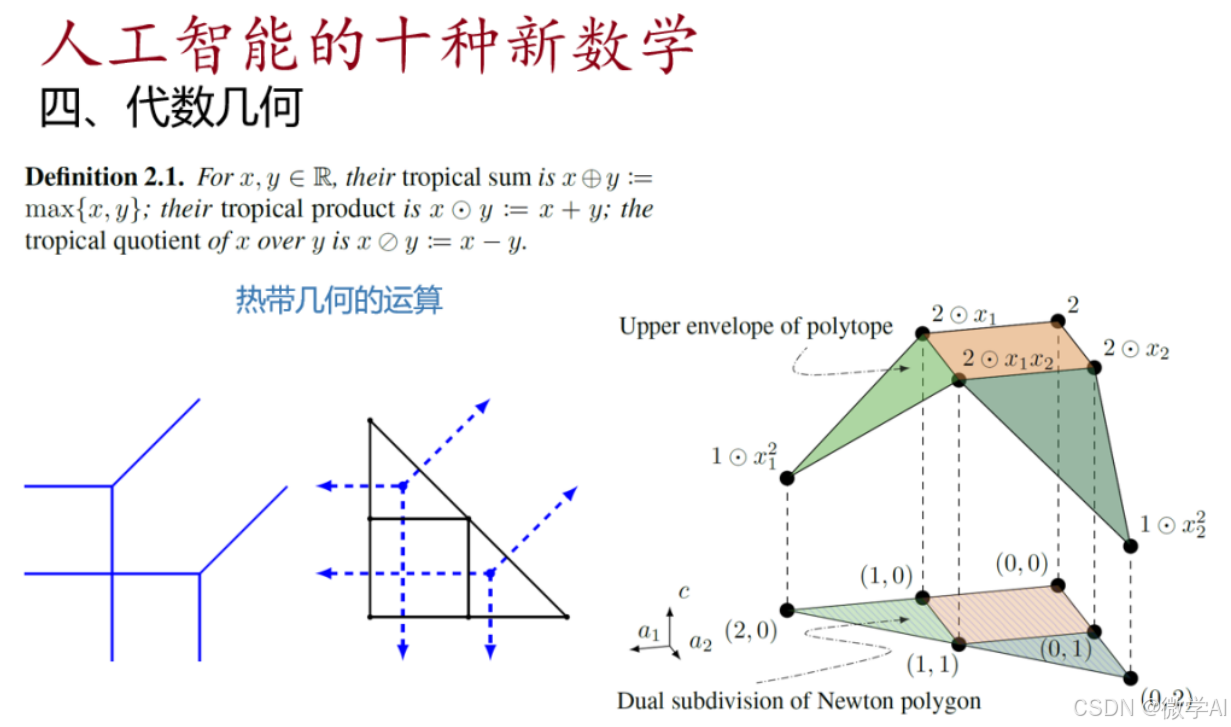
探讨人工智能领域所需学习的高等数学知识及其应用场景,涵盖了微积分、线性代数、概率论等多个数学分支。
大家好,我是微学AI,今天给大家介绍一下本文主要探讨了人工智能领域所需学习的高等数学知识及其应用场景。文章详细列出了人工智能中涉及的数学公式,涵盖了微积分、线性代数、概率论等多个数学分支。同时,本文深入介绍了这些数学知…...

详解安卓和IOS的唤起APP的机制,包括第三方平台的唤起方法比如微信
网页唤起APP是一种常见的跨平台交互方式,它允许用户从网页直接跳转到移动应用程序。 这种技术广泛应用于各种场景,比如让用户在浏览器中点击链接后直接打开某个应用,或者从网页引导用户下载安装应用。实现这一功能主要依赖于URL Scheme、Univ…...

服务器数据恢复—raid5阵列中多块硬盘离线导致崩溃的数据恢复案例
服务器数据恢复环境: 三台V7000存储,共有64块SAS硬盘(其中有三块热备盘,其中一块已启用)组建了数组raid5阵列。分配若干LUN,上层安装Windows server操作系统,数据分区格式化为NTFS文件系统。 服…...

《深度学习》OpenCV FisherFaces算法人脸识别 原理及案例解析
目录 一、FisherFaces算法 1、什么是FisherFaces算法 2、原理 3、特点 4、算法步骤 1)数据预处理 2)特征提取 3)LDA降维 4)特征投影 5)人脸识别 二、案例解析 1、完整代码 运行结果: 一、Fish…...

基于Python+Flask的天气预报数据可视化分析系统(源码+文档)
简介: 本系统是一个集数据收集、处理、分析和可视化于一体的天气预报数据平台。通过Python和Flask框架的结合,我们能够高效地构建出一个用户友好的Web界面,让用户能够轻松访问并理解复杂的天气数据。系统不仅能够实时获取最新的天气信息&…...

深入解析 Flutter兼容鸿蒙next全体生态的横竖屏适配与多屏协作兼容架构
目录 写在前面 1. Flutter 的基本适配机制 1.1 响应式布局 1.2 逻辑像素 2. 横屏与竖屏的适配 2.1 方向感知 2.2 针对方向的布局优化 3. 多屏协作的实现 3.1 适配多屏显示 3.2 使用 StreamBuilder 和 Provider 3.3 多设备协作的挑战 4. 实践中的应用场景 4.1 移动办…...
【Spring】Spring实现加法计算器和用户登录
加法计算器 准备工作 创建 SpringBoot 项目:引入 Spring Web 依赖,把前端的页面放入项目中 **<!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport"…...

电脑d盘不见了怎么恢复?
在使用电脑的时候,我们可能会遇到这样一个问题,电脑里的D盘突然不见了,在“此电脑”中看不到D盘了。这这个情况可能会让人感到非常困惑甚至是头疼,因为D盘里面可能存放着非常重要的文件。今天的内容要和大家分析一下D盘不见的原因…...

电子商务网站维护技巧:保持WordPress、主题和插件的更新
在这个快节奏的数字时代,维护一个电子商务网站的首要任务之一是保持WordPress、主题和插件的最新状态。过时的软件不仅可能导致功能故障,还可能带来安全风险。本文将深入探讨如何有效地更新和维护您的WordPress网站,以确保其安全性和性能。 …...

交叉编译--目标平台aarch64 ubuntu 22.04
开发宿主机: ubuntu22.04虚拟机(PC) 目标平台: 地平线x3派/x3 Module , ubuntu22.04, ros2 humble 基于地平线x3开发板 5核 4G的内存的有限的资源,直接在目标机上编译虽然也可以,但耗时太长&a…...

【pytorch】昇思大模型配置python的conda版本
首先,切换conda的源,可以参考这篇文章,如果python的版本比较老的话不推荐使用清华源。 比如算子开发文档中推荐的python版本是3.7.5,比较老,使用清华源无法安装。 之后就是比较重要的,修改~/.bashrc。 把…...

nodejs的卸载和nvm安装
由于项目需求,需要多版本控制的nodejs,所以要把原来的nodejs卸载干净,然后再装nvm 常见问题 1.在安装nvm的时候没有卸载node,导致使用nvm安装完之后,node和npm都不可用。 2.在第一次使用nvm安装node后,要…...

网络七层架构
目录标题 网络七层架构从正确认识网络七层架构开始 网络七层架构 简介: 网络七层架构是指ISO/OSI模型,它是国际标准化组织(ISO)制定的一种用于计算机网络体系结构的参考模型。该模型将计算机网络的功能划分为七个层次,…...
)
2024年华为OD机试真题-敏感字段加密-Java-OD统一考试(E卷)
最新华为OD机试考点合集:华为OD机试2024年真题题库(E卷+D卷+C卷)_华为od机试题库-CSDN博客 每一题都含有详细的解题思路和代码注释,精编c++、JAVA、Python三种语言解法。帮助每一位考生轻松、高效刷题。订阅后永久可看,发现新题及时跟新。 题目描述 给定一个由多个…...

图神经网络黑书笔记--术语
一、图的基本概念 图由节点集合和边集合组成。节点代表实体,边代表实体之间的关系。节点、边、整个图都可以与丰富的信息相关联,这些信息被表征为节点/边/图的特征。 中心度:是度量节点的重要性。如果许多其他重要的节点也连接到该节点&a…...

原型基于颜色的图像检索与MATLAB
原型基于颜色的图像检索与MATLAB 摘要 基于内容的检索数据库(图像)已经变得越来越受欢迎。为了达到这一目的,需要发展算法检测/模拟工具,但市场上没有合适的商业工具。 本文介绍了一个模拟环境,能够从数据库中检索图像直方图的相似之处。该…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...

终极音乐解锁指南:3步让加密音乐在任何设备自由播放
终极音乐解锁指南:3步让加密音乐在任何设备自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

鼎讯AM-601光纤熔接机:交通通信建设与维护的可靠伙伴
在铁路、高速公路等交通基础设施的智能化建设中,稳定高效的光纤网络是指挥调度、安全监控等核心系统运行的生命线。鼎讯AM-601光纤熔接机,作为一款专为严苛环境设计的六马达便携式熔接设备,正成为保障这些关键通信链路畅通无阻的可靠选择。无…...