python 日志库loguru
python 日志库loguru
安装
pip install loguru
最简单的基本使用
from loguru import loggerlogger.success("Hello from success!")
logger.info("Hello from info!")
logger.debug("Hello from debug!")
logger.warning("Hello from warning!")
logger.error("Hello from error!")
# 严重错误
logger.critical("Hello from critical!")
输出结果
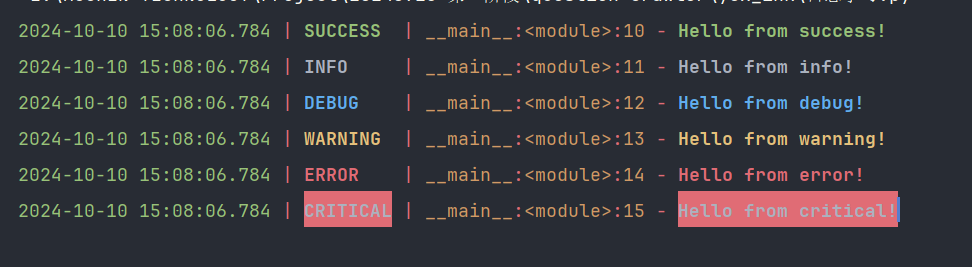
自定义日志处理器(输出样式, 显示日志等级, 输出方式等)
import sysfrom loguru import logger# 移除默认的日志处理器, 否则会重复输出
logger.remove()
# 添加一个自定义日志处理器
logger.add(sys.stdout,format="<green>{time:YYYYMMDD HH:mm:ss}</green> | " # 颜色>时间"{process.name} | " # 进程名"{thread.name} | " # 进程名"<level>{module}</level>.<cyan>{function}</cyan>" # 模块名.方法名":<cyan>{line}</cyan> | " # 行号"<level>{level}</level>: " # 等级"<level>{message}</level>", # 日志内容# 可选值: TRACE, DEBUG, INFO, SUCCESS, WARNING, ERROR, CRITICAL# 越后的值, 显示的日志越少level='TRACE')def main():logger.success("Hello from success!")logger.info("Hello from info!")logger.debug("Hello from debug!")logger.warning("Hello from warning!")logger.error("Hello from error!")logger.critical("Hello from critical!")if __name__ == '__main__':main()
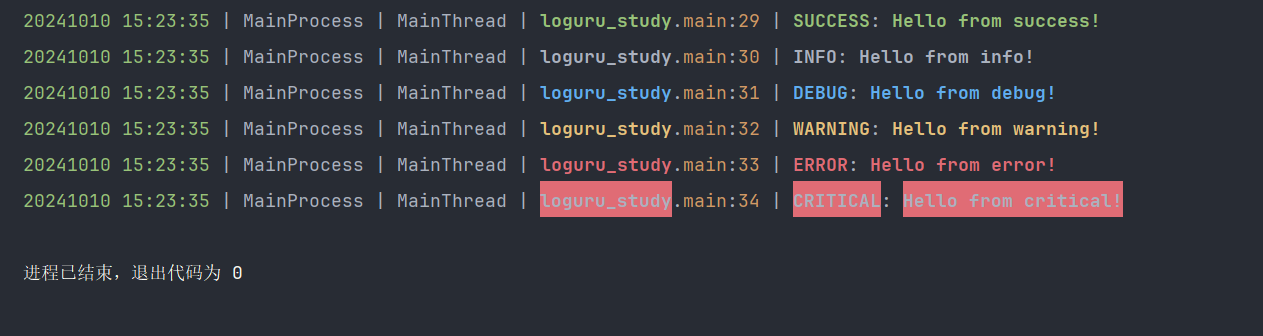
使用配置方式定义
import sysfrom loguru import loggerconfig = {"handlers": [{"sink": sys.stdout,"format": "<green>{time:YYYYMMDD HH:mm:ss}</green> | " # 颜色>时间"{process.name} | " # 进程名"{thread.name} | " # 进程名"<level>{module}</level>.<cyan>{function}</cyan>" # 模块名.方法名":<cyan>{line}</cyan> | " # 行号"<level>{level}</level>: " # 等级"<level>{message}</level>", # 日志内容"level": 'TRACE'},{"sink": "loguru.log", # 日志文件名"rotation": "1 week", # 按周滚动"retention": "10 days", # 保留10天"enqueue": True, # 异步写入"compression": "zip", # 压缩格式"serialize": True # 序列化日志为json格式},],"extra": {"user": "Tiam"}
}
logger.configure(**config)保存日志文件
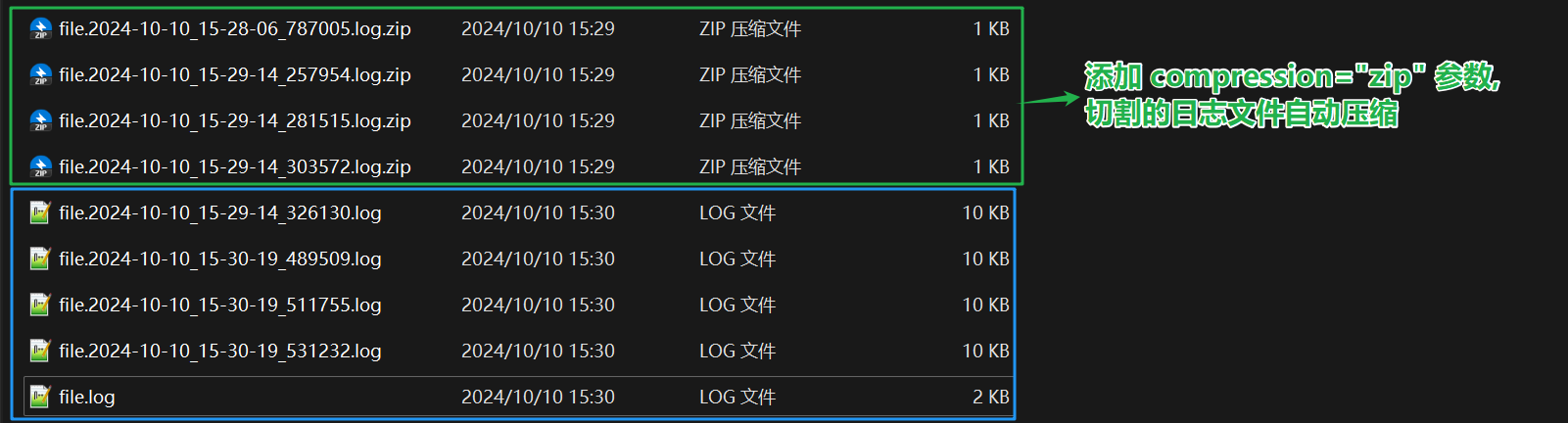
from loguru import logger# 添加一个文件日志处理器, 指定日志等级, 日志文件名, 日志文件大小, 日志文件数量, 日志文件切割方式# 添加 compression="zip" 参数, 可以压缩日志文件
# logger.add("file.log", level="INFO", rotation="10 KB", compression="zip")# 日志文件每达到 10 KB 时, 会自动切割
logger.add("file.log", level="INFO", rotation="10 KB")def main():logger.success("Hello from success!")logger.info("Hello from info!")logger.debug("Hello from debug!")logger.warning("Hello from warning!")logger.error("Hello from error!")logger.critical("Hello from critical!")if __name__ == '__main__':for i in range(100):main()
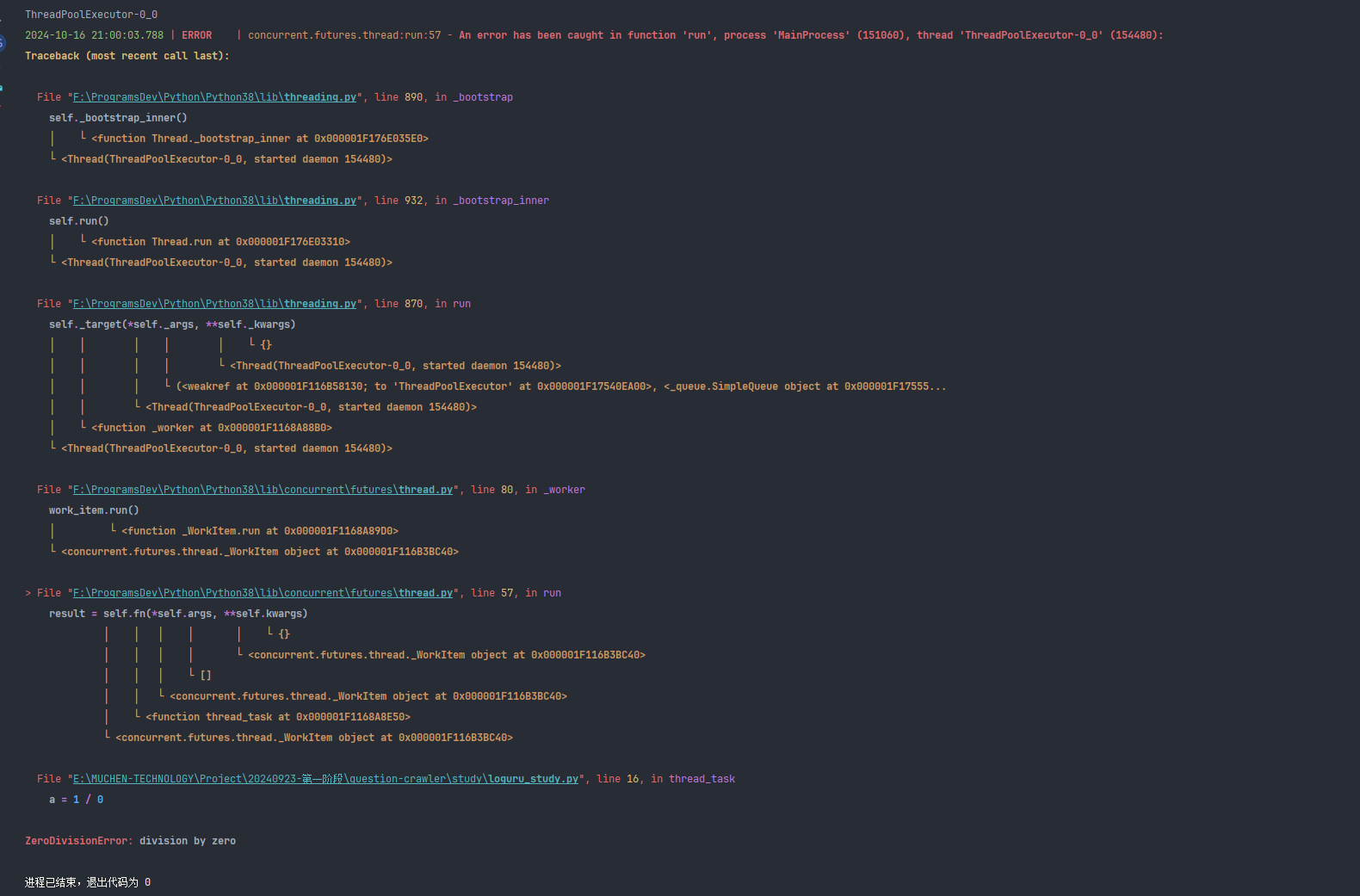
线程异常捕获
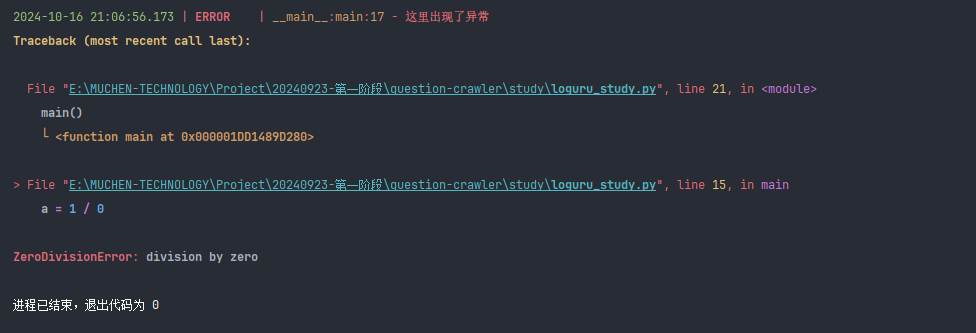
import threading
from concurrent.futures import ThreadPoolExecutorfrom loguru import logger@logger.catch
def thread_task():print(threading.current_thread().name)a = 1 / 0if __name__ == '__main__':with ThreadPoolExecutor(max_workers=1) as executor:executor.submit(thread_task)
@logger.catch 会捕获打印完整的异常信息以及堆栈信息,
如果没有@logger.catch 注解将不会抛出任何错误, 因为没有调用未来对象的返回结果(退出代码返回0)
使用logger.exception()方法,可以打印出异常的堆栈信息, logger.error 只能记录信息
def main():try:a = 1 / 0except:# 使用logger.exception()方法,可以打印出异常的堆栈信息logger.exception("这里出现了异常")
多任务/多线程日志
多任务时, 分任务写入不同文件
from loguru import loggerlogger.add("file_A.log", filter=lambda record: record["extra"]["task"] == "A")
logger.add("file_B.log", filter=lambda record: record["extra"]["task"] == "B")def task_a():logger_a = logger.bind(task="A")logger_a.info("Task A")def task_b():logger_b = logger.bind(task="B")logger_b.info("Task B")task_a()
task_b()
多线程, 为每个线程分配一个日志文件
import copy
import time
from concurrent.futures import ThreadPoolExecutorfrom loguru import loggerlogger.remove()def task(task_id, logger):logger.info("Starting task {}", task_id)# do somethingtime.sleep(3)logger.success("End of task {}", task_id)tasks = ["A", "B", "C", "D", "E"]
with ThreadPoolExecutor(max_workers=len(tasks)) as executor:for task_id in tasks:# 深拷贝一个新的logger对象logger_ = copy.deepcopy(logger)# 给新的logger对象添加一个文件输出logger_.add("file_%s.log" % task_id)# 后续使用新的logger进行日志记录executor.submit(task, task_id, logger_)
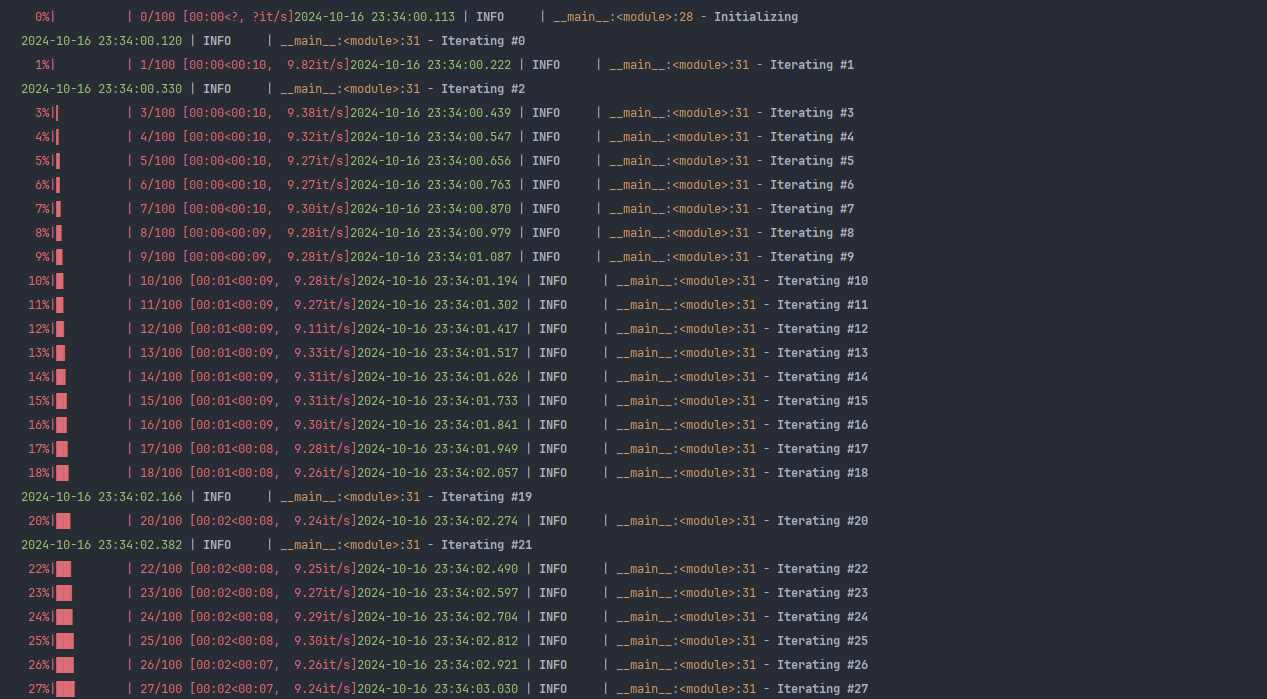
与进度条tqdm
这里配置使用 tqdm.write作为日志输出
from tqdm import tqdm
from loguru import logger
import timelogger.remove()
logger.add(lambda msg: tqdm.write(msg, end=""), colorize=True)logger.info("Initializing")for x in tqdm(range(100)):logger.info("Iterating #{}", x)time.sleep(0.1)
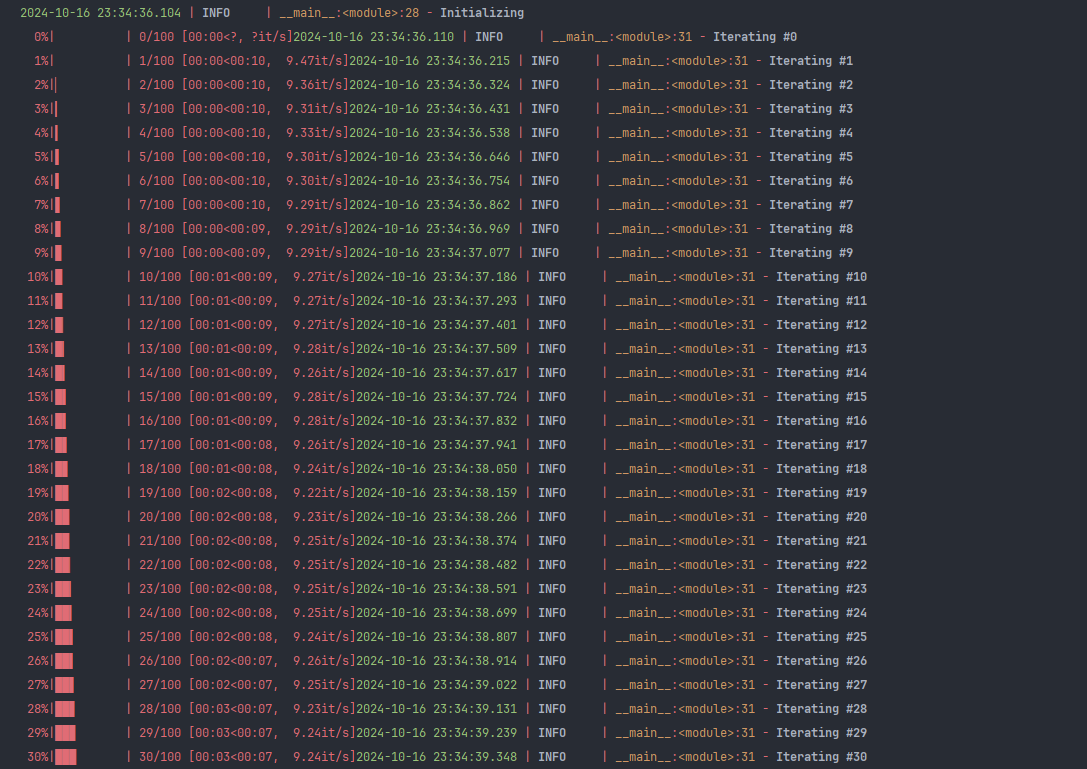
这是不使用tqdm.write的输出效果, em…没体会到作用…
参考:
- 与tqDM一起使用· 议题 #135 · Delgan/loguru — Usage with tqdm · 议题 #135 · Delgan/loguru (github.com)
- loguru的代码片段和食谱- loguru文档 — Code snippets and recipes for loguru — loguru documentation
自定义日志等级
from loguru import logger
from functools import partialmethodlogger.level("simple", no=33, icon="🤖", color="<fg #b168f2>")logger.__class__.simple = partialmethod(logger.__class__.log, "simple")
logger.log("simple", "A message")
logger.simple("A message")
更多颜色可选值: loguru.logger — loguru documentation
icon=“🤖”, color=“<fg #b168f2>”)
logger.class.simple = partialmethod(logger.class.log, “simple”)
logger.log(“simple”, “A message”)
logger.simple(“A message”)
更多颜色可选值: [loguru.logger — loguru documentation](https://loguru.readthedocs.io/en/stable/api/logger.html#color)更多: [Overview — loguru documentation](https://loguru.readthedocs.io/en/stable/overview.html)
相关文章:
python 日志库loguru
python 日志库loguru 安装 pip install loguru最简单的基本使用 from loguru import loggerlogger.success("Hello from success!") logger.info("Hello from info!") logger.debug("Hello from debug!") logger.warning("Hello from wa…...
基于SpringBoot+Vue+uniapp的在线招聘平台的详细设计和实现
详细视频演示 请联系我获取更详细的演示视频 项目运行截图 技术框架 后端采用SpringBoot框架 Spring Boot 是一个用于快速开发基于 Spring 框架的应用程序的开源框架。它采用约定大于配置的理念,提供了一套默认的配置,让开发者可以更专注于业务逻辑而不…...

Chrome谷歌浏览器加载ActiveX控件之JT2Go控件
背景 JT2Go是一款西门子公司出品的三维图形轻量化预览解决工具,包含精确3D测量、基本3D剖面、PMI显示和改进的选项过滤器等强大的功能。JT2Go控件是一个标准的ActiveX控件,曾经主要在IE浏览器使用,由于微软禁用IE浏览器,导致JT2Go…...
)
Java基础概览和常用知识(七)
什么是自动装箱和自动拆箱,原理是什么? 自动装箱和自动拆箱是Java编程语言中的两个重要概念,它们涉及到基本数据类型与其对应包装类之间的自动转换。 一、定义 自动装箱:是指Java编译器在需要将基本数据类型转换为对应的包装类…...

STL-string
STL的六大组件: string // string constructor #include <iostream> #include <string> using namespace std; int main() {// 构造std::string s0("Initial string");std::string s1; //nullptrstd::string s2("A character sequenc…...

数据库基础-学习版
目录 数据库巡检清理表空间高水位处理重建索引扩展字段异常恢复处置常见命令汇总 数据库巡检 数据库巡检的主要目的是确保数据库的健康状态、性能和安全,及时发现潜在的问题。 一 数据库状态检查 查看数据库列表:SHOW DATABASES; 检查当前数据库SELECT DATABASE(); 检查数据…...

【Gin】Gin框架介绍和使用
一、简单使用Gin框架搭建一个服务器 package mainimport ("github.com/gin-gonic/gin" )func main() {// 创建一个默认的路由引擎r : gin.Default()// GET 请求方法r.GET("/hello", func(c *gin.Context) {// c.JSON 返回的是JSON格式的数据c.JSON(200, g…...

AI大模型带来哪些创业机遇?
AI 大模型的快速发展带来了许多创新和创业机遇,涵盖了从行业应用到基础设施优化的方方面面。以下是一些具体的创业机会: 1、垂直行业应用 大模型可以根据不同行业的需求进行定制和优化,提供高度专业化的 AI 解决方案。 医疗领域:…...

[Linux] 层层深入理解文件系统——(3)磁盘组织存储的文件
标题:[Linux] 层层深入理解文件系统——(3)磁盘组织组织存储的文件 个人主页水墨不写bug 目录 一、磁盘中的文件 1)磁盘的物理结构 2)磁盘的CHS寻址法 3)磁盘的空间管理 二、磁盘如何组织存储文件 三…...

Apache Cordova学习计划
Apache Cordova(之前称为 PhoneGap): 1. PhoneGap的起源:2008年8月,PhoneGap在旧金山的iPhoneDevCamp上首次亮相,由Nitobe公司开发,目的是“为跨越Web技术和iPhone之间的鸿沟牵线搭桥”。 2. Ph…...

Unity学习日志-API
Untiy基本API 角度旋转自转相对于某一个轴 转多少度相对于某一个点转练习 角度 this.transform.rotation(四元数)界面上的xyz(相对于世界坐标) this.transform.eulerAngles;相对于父对象 this.transform.localEulerAngles;设置角度和设置位置一样,不能单独设置xz…...

Java基础常见面试题总结(上)
基础概念与常识 Java 语言有哪些特点? 简单易学(语法简单,上手容易);面向对象(封装,继承,多态);平台无关性( Java 虚拟机实现平台无关性)&…...

4 -《本地部署开源大模型》在Ubuntu 22.04系统下部署运行ChatGLM3-6B模型
在Ubuntu 22.04系统下部署运行ChatGLM3-6B模型 大模型部署整体来看并不复杂,且官方一般都会提供标准的模型部署流程,但很多人在部署过程中会遇到各种各样的问题,很难成功部署,主要是因为这个过程会涉及非常多依赖库的安装和更新及…...
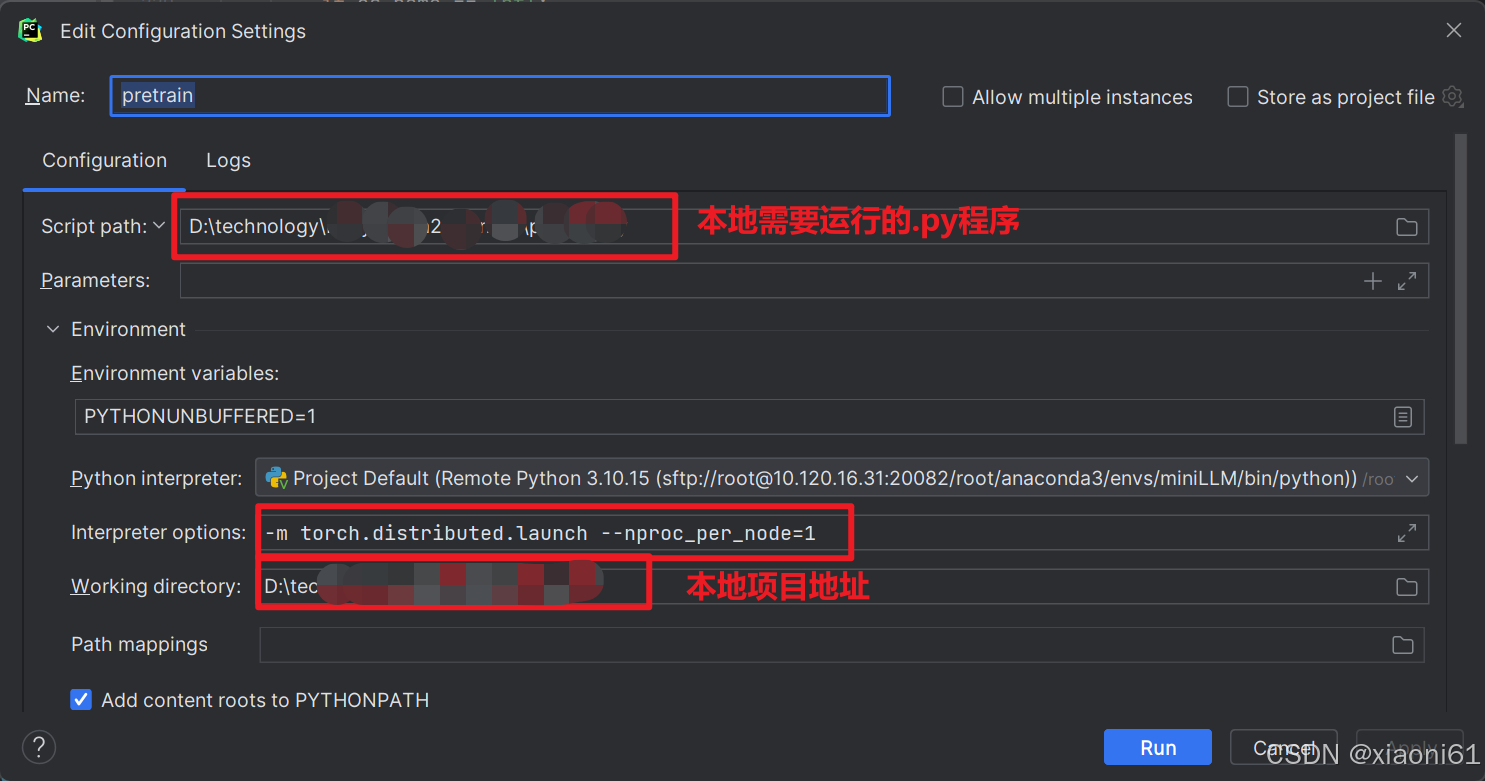
本地如何使用Pycharm连接远程服务器调试torchrun
pycharm 远程连接服务器并且debug, 支持torch.distributed.launch debug_pycharm远程debug-CSDN博客 上面这个博客写的真的非常好,记录一下,需要注意该博主的主机为mac 本人可调试版本为: 可直接运行版本为:...

Visual Studio 2022常用快捷键
1. 基本编辑快捷键 Ctrl X:剪切选中内容Ctrl C:复制选中内容Ctrl V:粘贴内容Ctrl Z:撤销Ctrl Y:重做Ctrl Shift L:删除当前行Ctrl K, Ctrl C:注释选中的代码Ctrl K, Ctrl U…...
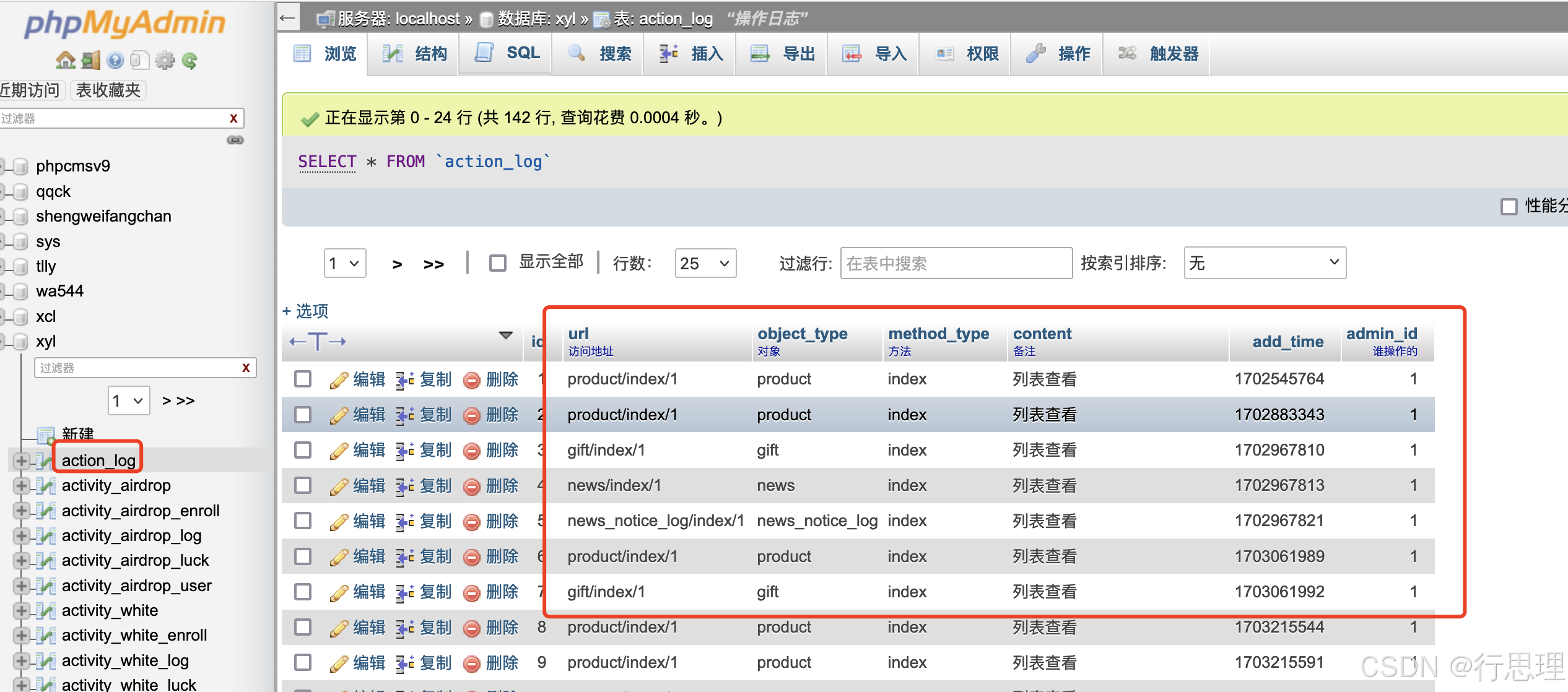
mysql innodb 引擎如何直接复制数据库文件?
mysql innodb 引擎如何直接复制数据库文件?介绍如下: 1、首先找到数据库文件所在位置 一般可以看my.conf/my.ini配置的文件的“datadir” 看示例: “MAMP”在Macos下的数据库文件位置: /Library/Application Support/appsolu…...

python中的global和nonlocal关键字以及闭包和模块
global i 这样的用法在于 Python 中,但需要在一个函数内部使用,以便将变量 i 声明为全局变量。让我们来详细讲解一下它的用法。 什么是全局变量? 全局变量是指在函数外部定义的变量,可以在任何函数中访问和修改。如果你需要在函数…...
LabVIEW风机滚动轴承监测系统
矿井主通风机作为矿井中最重要的通风设备,一旦出现故障,不仅会影响矿井内的空气质量,还可能引发安全事故。研究表明,通风机中约30%的故障是由轴承问题引起的。因此,能够实时监控矿井主通风机轴承状态的系统,…...

第1节 什么是鸿蒙系统
鸿蒙系统(HarmonyOS)是华为公司发布的一款基于微内核的面向全场景的分布式操作系统。以下是对它的具体介绍: 1. 核心特点: • 分布式能力:这是鸿蒙系统的核心优势之一。它能够将多种不同类型的智能终端设备连接起来&a…...

CentOS 7 将 YUM 源更改为国内镜像源
在 CentOS 7 中,将 YUM 源更改为国内的阿里云镜像源可以提高软件包的下载速度。以下是具体的步骤: 1. 备份原有 YUM 源配置 首先,建议你备份当前的 YUM 源配置,以防后续需要恢复: sudo cp -r /etc/yum.repos.d /etc…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...

DLA功耗优化验证:tegrastats实战指南
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...

DSP、FPGA、STM32大对决:谁才是嵌入式开发的“天选之子”?
在嵌入式开发的广阔天地里,DSP、FPGA 和 STM32(作为通用 MCU 的典型代表)可以说是三款绕不开的核心处理器。很多初学者甚至有一定经验的工程师在选择时都会陷入纠结:我的项目到底该选哪一个?为了帮你彻底理清思路&…...

3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能
3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元
HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器的缓慢加载和频繁卡顿而烦恼吗?你…...

终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误
终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/r…...