Java IO 基础知识
IO 流简介
IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流
字节流
InputStream(字节输入流)
InputStream用于从源头(通常是文件)读取数据(字节信息)到内存中,java.io.InputStream抽象类是所有字节输入流的父类。
InputStream 常用方法:
read():返回输入流中下一个字节的数据。返回的值介于 0 到 255 之间。如果未读取任何字节,则代码返回-1,表示文件结束。
read(byte b[ ]): 从输入流中读取一些字节存储到数组b中。如果数组b的长度为零,则不读取。如果没有可用字节读取,返回-1。如果有可用字节读取,则最多读取的字节数最多等于b.length, 返回读取的字节数。这个方法等价于read(b, 0, b.length)。read(byte b[], int off, int len):在read(byte b[ ])方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字节数)。skip(long n):忽略输入流中的 n 个字节 ,返回实际忽略的字节数。available():返回输入流中可以读取的字节数。close():关闭输入流释放相关的系统资源。
从 Java 9 开始,InputStream 新增加了多个实用的方法:
readAllBytes():读取输入流中的所有字节,返回字节数组。readNBytes(byte[] b, int off, int len):阻塞直到读取len个字节。transferTo(OutputStream out):将所有字节从一个输入流传递到一个输出流。
FileInputStream 是一个比较常用的字节输入流对象,可直接指定文件路径,可以直接读取单字节数据,也可以读取至字节数组中。
FileInputStream 代码示例:
try (InputStream fis = new FileInputStream("input.txt")) {System.out.println("Number of remaining bytes:"+ fis.available());int content;long skip = fis.skip(2);System.out.println("The actual number of bytes skipped:" + skip);System.out.print("The content read from file:");while ((content = fis.read()) != -1) {System.out.print((char) content);}
} catch (IOException e) {e.printStackTrace();
}
输出:
Number of remaining bytes:11
The actual number of bytes skipped:2
The content read from file:JavaGuide不过,一般我们是不会直接单独使用 FileInputStream ,通常会配合 BufferedInputStream(字节缓冲输入流,后文会讲到)来使用。
像下面这段代码在我们的项目中就比较常见,我们通过 readAllBytes() 读取输入流所有字节并将其直接赋值给一个 String 对象。
// 新建一个 BufferedInputStream 对象
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("input.txt"));
// 读取文件的内容并复制到 String 对象中
String result = new String(bufferedInputStream.readAllBytes());
System.out.println(result);DataInputStream 用于读取指定类型数据,不能单独使用,必须结合其它流,比如 FileInputStream 。
FileInputStream fileInputStream = new FileInputStream("input.txt");
//必须将fileInputStream作为构造参数才能使用
DataInputStream dataInputStream = new DataInputStream(fileInputStream);
//可以读取任意具体的类型数据
dataInputStream.readBoolean();
dataInputStream.readInt();
dataInputStream.readUTF();
------
著作权归JavaGuide(javaguide.cn)所有
基于MIT协议
原文链接:https://javaguide.cn/java/io/io-basis.htmlObjectInputStream 用于从输入流中读取 Java 对象(反序列化),ObjectOutputStream 用于将对象写入到输出流(序列化)。
ObjectInputStream input = new ObjectInputStream(new FileInputStream("object.data"));
MyClass object = (MyClass) input.readObject();
input.close();另外,用于序列化和反序列化的类必须实现 Serializable 接口,对象中如果有属性不想被序列化,使用 transient 修饰。
OutputStream(字节输出流)
OutputStream用于将数据(字节信息)写入到目的地(通常是文件),java.io.OutputStream抽象类是所有字节输出流的父类。
OutputStream 常用方法:
write(int b):将特定字节写入输出流。write(byte b[ ]): 将数组b写入到输出流,等价于write(b, 0, b.length)。write(byte[] b, int off, int len): 在write(byte b[ ])方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字节数)。flush():刷新此输出流并强制写出所有缓冲的输出字节。close():关闭输出流释放相关的系统资源。
FileOutputStream 是最常用的字节输出流对象,可直接指定文件路径,可以直接输出单字节数据,也可以输出指定的字节数组。
FileOutputStream 代码示例:
try (FileOutputStream output = new FileOutputStream("output.txt")) {byte[] array = "JavaGuide".getBytes();output.write(array);
} catch (IOException e) {e.printStackTrace();
}运行结果:
// 输出流
FileOutputStream fileOutputStream = new FileOutputStream("out.txt");
DataOutputStream dataOutputStream = new DataOutputStream(fileOutputStream);
// 输出任意数据类型
dataOutputStream.writeBoolean(true);
dataOutputStream.writeByte(1);
类似于 FileInputStream,FileOutputStream 通常也会配合 BufferedOutputStream(字节缓冲输出流,后文会讲到)来使用。
FileOutputStream fileOutputStream = new FileOutputStream("output.txt");
BufferedOutputStream bos = new BufferedOutputStream(fileOutputStream)DataOutputStream 用于写入指定类型数据,不能单独使用,必须结合其它流,比如 FileOutputStream 。
ObjectInputStream 用于从输入流中读取 Java 对象(ObjectInputStream,反序列化),ObjectOutputStream将对象写入到输出流(ObjectOutputStream,序列化)。
ObjectOutputStream output = new ObjectOutputStream(new FileOutputStream("file.txt")
Person person = new Person("Guide哥", "JavaGuide作者");
output.writeObject(person);
字符流
不管是文件读写还是网络发送接收,信息的最小存储单元都是字节。 那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
个人认为主要有两点原因:
- 字符流是由 Java 虚拟机将字节转换得到的,这个过程还算是比较耗时。
- 如果我们不知道编码类型就很容易出现乱码问题。
乱码问题这个很容易就可以复现,我们只需要将上面提到的 FileInputStream 代码示例中的 input.txt 文件内容改为中文即可,原代码不需要改动。

输出:
Number of remaining bytes:9
The actual number of bytes skipped:2
The content read from file:§å®¶å¥½
可以很明显地看到读取出来的内容已经变成了乱码。
因此,I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
字符流默认采用的是 Unicode 编码,我们可以通过构造方法自定义编码。
Unicode 本身只是一种字符集,它为每个字符分配一个唯一的数字编号,并没有规定具体的存储方式。UTF-8、UTF-16、UTF-32 都是 Unicode 的编码方式,它们使用不同的字节数来表示 Unicode 字符。例如,UTF-8 :英文占 1 字节,中文占 3 字节。
Reader(字符输入流)
Reader用于从源头(通常是文件)读取数据(字符信息)到内存中,java.io.Reader抽象类是所有字符输入流的父类。
Reader 用于读取文本, InputStream 用于读取原始字节。
Reader 常用方法:
read(): 从输入流读取一个字符。read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组cbuf中,等价于read(cbuf, 0, cbuf.length)。read(char[] cbuf, int off, int len):在read(char[] cbuf)方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字符数)。skip(long n):忽略输入流中的 n 个字符 ,返回实际忽略的字符数。close(): 关闭输入流并释放相关的系统资源。
InputStreamReader 是字节流转换为字符流的桥梁,其子类 FileReader 是基于该基础上的封装,可以直接操作字符文件。
// 字节流转换为字符流的桥梁
public class InputStreamReader extends Reader {
}
// 用于读取字符文件
public class FileReader extends InputStreamReader {
}FileReader 代码示例:
try (FileReader fileReader = new FileReader("input.txt");) {int content;long skip = fileReader.skip(3);System.out.println("The actual number of bytes skipped:" + skip);System.out.print("The content read from file:");while ((content = fileReader.read()) != -1) {System.out.print((char) content);}
} catch (IOException e) {e.printStackTrace();
}
input.txt 文件内容:

输出:
The actual number of bytes skipped:3
The content read from file:我是Guide。
Writer(字符输出流)
Writer用于将数据(字符信息)写入到目的地(通常是文件),java.io.Writer抽象类是所有字符输出流的父类。
Writer 常用方法:
write(int c): 写入单个字符。write(char[] cbuf):写入字符数组cbuf,等价于write(cbuf, 0, cbuf.length)。write(char[] cbuf, int off, int len):在write(char[] cbuf)方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字符数)。write(String str):写入字符串,等价于write(str, 0, str.length())。write(String str, int off, int len):在write(String str)方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字符数)。append(CharSequence csq):将指定的字符序列附加到指定的Writer对象并返回该Writer对象。append(char c):将指定的字符附加到指定的Writer对象并返回该Writer对象。flush():刷新此输出流并强制写出所有缓冲的输出字符。close():关闭输出流释放相关的系统资源。
OutputStreamWriter 是字符流转换为字节流的桥梁,其子类 FileWriter 是基于该基础上的封装,可以直接将字符写入到文件。
// 字符流转换为字节流的桥梁 public class OutputStreamWriter extends Writer { } // 用于写入字符到文件 public class FileWriter extends OutputStreamWriter { }
字节缓冲流
IO 操作是很消耗性能的,缓冲流将数据加载至缓冲区,一次性读取/写入多个字节,从而避免频繁的 IO 操作,提高流的传输效率。
字节缓冲流这里采用了装饰器模式来增强 InputStream 和OutputStream子类对象的功能。
举个例子,我们可以通过 BufferedInputStream(字节缓冲输入流)来增强 FileInputStream 的功能。
// 新建一个 BufferedInputStream 对象
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("input.txt"));
字节流和字节缓冲流的性能差别主要体现在我们使用两者的时候都是调用 write(int b) 和 read() 这两个一次只读取一个字节的方法的时候。由于字节缓冲流内部有缓冲区(字节数组),因此,字节缓冲流会先将读取到的字节存放在缓存区,大幅减少 IO 次数,提高读取效率。
我使用 write(int b) 和 read() 方法,分别通过字节流和字节缓冲流复制一个 524.9 mb 的 PDF 文件耗时对比如下
使用缓冲流复制PDF文件总耗时:15428 毫秒
使用普通字节流复制PDF文件总耗时:2555062 毫秒两者耗时差别非常大,缓冲流耗费的时间是字节流的 1/165。
测试代码如下:
@Test
void copy_pdf_to_another_pdf_buffer_stream() {// 记录开始时间long start = System.currentTimeMillis();try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("深入理解计算机操作系统.pdf"));BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("深入理解计算机操作系统-副本.pdf"))) {int content;while ((content = bis.read()) != -1) {bos.write(content);}} catch (IOException e) {e.printStackTrace();}// 记录结束时间long end = System.currentTimeMillis();System.out.println("使用缓冲流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}@Test
void copy_pdf_to_another_pdf_stream() {// 记录开始时间long start = System.currentTimeMillis();try (FileInputStream fis = new FileInputStream("深入理解计算机操作系统.pdf");FileOutputStream fos = new FileOutputStream("深入理解计算机操作系统-副本.pdf")) {int content;while ((content = fis.read()) != -1) {fos.write(content);}} catch (IOException e) {e.printStackTrace();}// 记录结束时间long end = System.currentTimeMillis();System.out.println("使用普通流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
如果是调用 read(byte b[]) 和 write(byte b[], int off, int len) 这两个写入一个字节数组的方法的话,只要字节数组的大小合适,两者的性能差距其实不大,基本可以忽略。
这次我们使用 read(byte b[]) 和 write(byte b[], int off, int len) 方法,分别通过字节流和字节缓冲流复制一个 524.9 mb 的 PDF 文件耗时对比如下:
使用缓冲流复制PDF文件总耗时:695 毫秒
使用普通字节流复制PDF文件总耗时:989 毫秒两者耗时差别不是很大,缓冲流的性能要略微好一点点。
测试代码如下
@Test
void copy_pdf_to_another_pdf_with_byte_array_buffer_stream() {// 记录开始时间long start = System.currentTimeMillis();try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("深入理解计算机操作系统.pdf"));BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("深入理解计算机操作系统-副本.pdf"))) {int len;byte[] bytes = new byte[4 * 1024];while ((len = bis.read(bytes)) != -1) {bos.write(bytes, 0, len);}} catch (IOException e) {e.printStackTrace();}// 记录结束时间long end = System.currentTimeMillis();System.out.println("使用缓冲流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}@Test
void copy_pdf_to_another_pdf_with_byte_array_stream() {// 记录开始时间long start = System.currentTimeMillis();try (FileInputStream fis = new FileInputStream("深入理解计算机操作系统.pdf");FileOutputStream fos = new FileOutputStream("深入理解计算机操作系统-副本.pdf")) {int len;byte[] bytes = new byte[4 * 1024];while ((len = fis.read(bytes)) != -1) {fos.write(bytes, 0, len);}} catch (IOException e) {e.printStackTrace();}// 记录结束时间long end = System.currentTimeMillis();System.out.println("使用普通流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
BufferedInputStream(字节缓冲输入流)
BufferedInputStream 从源头(通常是文件)读取数据(字节信息)到内存的过程中不会一个字节一个字节的读取,而是会先将读取到的字节存放在缓存区,并从内部缓冲区中单独读取字节。这样大幅减少了 IO 次数,提高了读取效率。
BufferedInputStream 内部维护了一个缓冲区,这个缓冲区实际就是一个字节数组,通过阅读 BufferedInputStream 源码即可得到这个结论。
public
class BufferedInputStream extends FilterInputStream {// 内部缓冲区数组protected volatile byte buf[];// 缓冲区的默认大小private static int DEFAULT_BUFFER_SIZE = 8192;// 使用默认的缓冲区大小public BufferedInputStream(InputStream in) {this(in, DEFAULT_BUFFER_SIZE);}// 自定义缓冲区大小public BufferedInputStream(InputStream in, int size) {super(in);if (size <= 0) {throw new IllegalArgumentException("Buffer size <= 0");}buf = new byte[size];}
}缓冲区的大小默认为 8192 字节,当然了,你也可以通过 BufferedInputStream(InputStream in, int size) 这个构造方法来指定缓冲区的大小。
BufferedOutputStream(字节缓冲输出流)
BufferedOutputStream 将数据(字节信息)写入到目的地(通常是文件)的过程中不会一个字节一个字节的写入,而是会先将要写入的字节存放在缓存区,并从内部缓冲区中单独写入字节。这样大幅减少了 IO 次数,提高了读取效率
try (BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("output.txt"))) {byte[] array = "JavaGuide".getBytes();bos.write(array);
} catch (IOException e) {e.printStackTrace();
}类似于 BufferedInputStream ,BufferedOutputStream 内部也维护了一个缓冲区,并且,这个缓存区的大小也是 8192 字节。
字符缓冲流
BufferedReader (字符缓冲输入流)和 BufferedWriter(字符缓冲输出流)类似于 BufferedInputStream(字节缓冲输入流)和BufferedOutputStream(字节缓冲输入流),内部都维护了一个字节数组作为缓冲区。不过,前者主要是用来操作字符信息。
打印流
下面这段代码大家经常使用吧?
System.out.print("Hello!");
System.out.println("Hello!");System.out 实际是用于获取一个 PrintStream 对象,print方法实际调用的是 PrintStream 对象的 write 方法。
PrintStream 属于字节打印流,与之对应的是 PrintWriter (字符打印流)。PrintStream 是 OutputStream 的子类,PrintWriter 是 Writer 的子类。
public class PrintStream extends FilterOutputStreamimplements Appendable, Closeable {
}
public class PrintWriter extends Writer {
}
随机访问流
这里要介绍的随机访问流指的是支持随意跳转到文件的任意位置进行读写的 RandomAccessFile 。
RandomAccessFile 的构造方法如下,我们可以指定 mode(读写模式)。
// openAndDelete 参数默认为 false 表示打开文件并且这个文件不会被删除
public RandomAccessFile(File file, String mode)throws FileNotFoundException {this(file, mode, false);
}
// 私有方法
private RandomAccessFile(File file, String mode, boolean openAndDelete) throws FileNotFoundException{// 省略大部分代码
}读写模式主要有下面四种:
r: 只读模式。rw: 读写模式rws: 相对于rw,rws同步更新对“文件的内容”或“元数据”的修改到外部存储设备。rwd: 相对于rw,rwd同步更新对“文件的内容”的修改到外部存储设备。
文件内容指的是文件中实际保存的数据,元数据则是用来描述文件属性比如文件的大小信息、创建和修改时间。
RandomAccessFile 中有一个文件指针用来表示下一个将要被写入或者读取的字节所处的位置。我们可以通过 RandomAccessFile 的 seek(long pos) 方法来设置文件指针的偏移量(距文件开头 pos 个字节处)。如果想要获取文件指针当前的位置的话,可以使用 getFilePointer() 方法。
那 字节流和字符流的主要区别是什么呢?什么时候用哪个?
一.字节流在操作时不会用到缓冲区(内存),是直接对文件本身进行操作的。而字符流在操作时使用了缓冲区,通过缓冲区再操作文件。
二.在硬盘上的所有文件都是以字节形式存在的(图片,声音,视频),而字符值在内存中才会形成。
简单的说就是在你需要对文件进行操作的时候(比如读写文件,下载,移动各种)用字节流。但是在需要对文件的内容进行操作,读取的时候就要用字符流。
那为什么要用缓冲流?
如果是边读边写,就会很慢,也伤硬盘。缓冲区就是内存里的一块区域,把数据先存内存里,然后一次性写入,类似数据库的批量操作,这样效率比较高。就好我们要把一堆文件从一个磁盘移入到另外一个磁盘里,是一个一个移还是把所有文件放到一个文件夹再移比较快,这个文件夹就相当于一个缓冲区,提高速度。
相关文章:
Java IO 基础知识
IO 流简介 IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在…...

【报错处理】MR/Spark 使用 BulkLoad 方式传输到 HBase 发生报错: NullPointerException
博主希望能够得到大家的点赞收藏支持!非常感谢 点赞,收藏是情分,不点是本分。祝你身体健康,事事顺心! Spark 通过 BulkLoad 方式传输到 HBase,我发现会出现空指针异常。简单写下如何解决的。 原理…...

域7:安全运营 第17章 事件的预防和响应
第七域包括 16、17、18、19 章。 事件的预防和响应是安全运营管理的核心环节,对于组织有效识别、评估、控制和减轻网络安全威胁至关重要。这一过程是循环往复的,要求组织不断总结经验,优化策略,提升整体防护能力。通过持续的监测、…...

Linux常见基本指令 +外壳shell + 权限的理解
下面这篇文章主要介绍了一些Linux的基本指令及其周边知识, 以及shell的简单理解和权限的理解. 目录 前言1.基本指令及其周边知识1.1 ADD类touch [file]文件的时间mkdir [directory]cp [file/directory]echo [file]输出重定向Linux中, 一切皆文件 1.2 DELETE类rmdirrm通配符关机…...

Android Framework AMS(07)service组件启动分析-1(APP到AMS流程解读)
该系列文章总纲链接:专题总纲目录 Android Framework 总纲 本章关键点总结 & 说明: 说明:本章节主要解读应用层service组件启动的2种方式startService和bindService,以及从APP层到AMS调用之间的打通。关注思维导图中左侧部分即…...
详解)
深度学习:领域适应(Domain Adaptation)详解
领域适应(Domain Adaptation)详解 领域适应是机器学习中的一个重要研究领域,它解决的问题是模型在一个领域(源域)上训练得到的知识如何迁移到另一个有所差异的领域(目标域)上。领域适应特别重要…...

华三服务器R4900 G5在图形界面使用PMC阵列卡(P460-B4)创建RAID,并安装系统(中文教程)
环境以用户需求安装Centos7.9,服务器使用9块900G硬盘,创建RAID1和RAID6,留一块作为热备盘。 使用笔记本通过HDM管理口()登录 使用VGA()线连接显示器和使用usb线连接键盘鼠标,进行窗…...
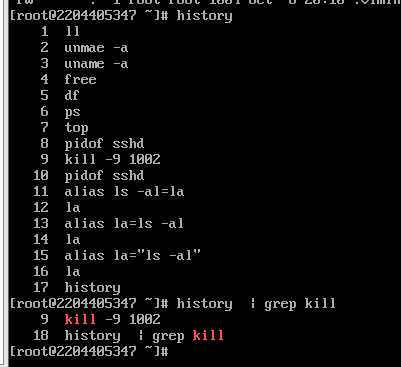
Linux实验三
Linux实验三 实验步骤: 一、登录进入 CentOS7 系统,打开并进入终端,使用 su root 切换到 root 用户 ; 二、将主机名称修改为 个人学号,并完成以下操作: 1、使用 uname -a 查看系统内核信息&#x…...

Vue预渲染:深入探索prerender-spa-plugin与vue-meta-info的联合应用
在前端开发的浪潮中,Vue.js凭借其轻量级、易上手和高效的特点,赢得了广大开发者的青睐。然而,单页面应用(SPA)在SEO方面的短板一直是开发者们需要面对的挑战。为了优化SEO,预渲染技术应运而生,而…...

使用`ThreadLocal`来优化鉴权逻辑并不能直接解决Web应用中session共享的问题
使用ThreadLocal来优化鉴权逻辑并不能直接解决Web应用中session共享的问题。实际上,ThreadLocal和session共享是两个不同的概念,它们解决的问题也不同。 ThreadLocal的作用 ThreadLocal是Java中提供的一个线程局部变量类,它可以让每个线程都拥有一个独立的变量副本,这样线…...

Python implement for PID
Python,serves as language for calculation of any domain 待更 Reference PID pythonPID git...

C++中的initializer_list类
目录 initializer_list类 介绍 基本使用 常见函数 initializer_list类 介绍 initializer_list类是C11新增的类,其原型如下: template<class T> class initializer_list; 有了initializer_list,一些容器也可以实现列表初始化&am…...

持续科技创新 高德亮相2024中国测绘地理信息科技年会
图为博览会期间, 自然资源部党组成员、副部长刘国洪前往高德企业展台参观。 10月15日,2024中国测绘地理信息科学技术年会暨中国测绘地理信息技术装备博览会在郑州召开。作为国内领先的地图厂商,高德地图凭借高精度高动态导航地图技术应用受邀参会。 本…...

深入理解HTTP Cookie
🍑个人主页:Jupiter. 🚀 所属专栏:Linux从入门到进阶 欢迎大家点赞收藏评论😊 目录 HTTP Cookie定义工作原理分类安全性用途 认识 cookie基本格式实验测试 cookie 当我们登录了B站过后,为什么下次访问B站就…...

Python多进程编程:使用`multiprocessing.Queue`进行进程间通信
Python多进程编程:使用multiprocessing.Queue进行进程间通信 1. 什么是multiprocessing.Queue?2. 为什么需要multiprocessing.Queue?3. 如何使用multiprocessing.Queue?3.1 基本用法3.2 队列的其他操作3.3 队列的阻塞与超时 4. 适…...

Docker 常见命令
命令库:docker ps | Docker Docs 安装docker apt install docker.io docker ps -a 作用:显示所有容器 docker logs -f frps 作用:持续输出容器名称为frps的日志信息(监控) docker restart frps 作用:重…...
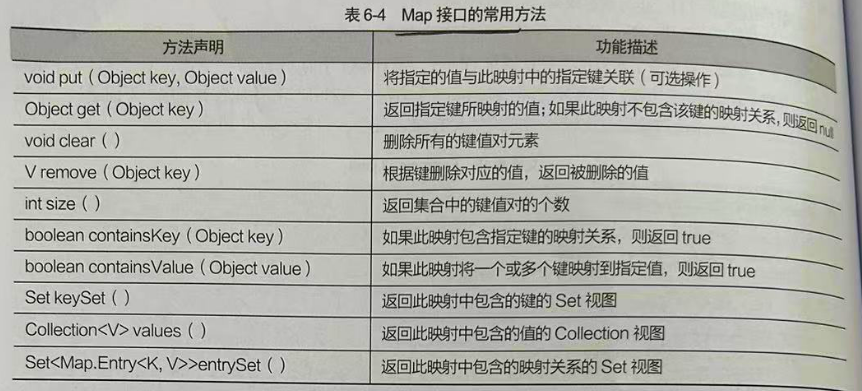
Map 双列集合根接口 HashMap TreeMap
Map接口是一种双列集合,它的每一个元素都包含一个键对象Key和值Value 键和值直接存在一种对应关系 称为映射 从Map集中中访问元素, 只要指定了Key 就是找到对应的Value 常用方法 HashMap实现类无重复键无序 它是Map 接口的一个实现类,用于存储键值映射关系,并且HashMap 集合没…...
相关总结)
Pip源设置(清华源)相关总结
1、临时使用 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package 2、永久更改pip源 升级 pip 到最新的版本 (>10.0.0) 后进行配置: pip install pip -U pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 如…...

编程入门攻略
编程小白如何成为大神?大学新生的最佳入门攻略 编程已成为当代大学生的必备技能,但面对众多编程语言和学习资源,新生们常常感到迷茫。如何选择适合自己的编程语言?如何制定有效的学习计划?如何避免常见的学习陷阱&…...

C++核心编程和桌面应用开发 第十一天(静态转换 动态转换 常量转换 重新解释转换)
目录 1.静态类型转换 1.1语法 1.2用法 2.动态类型转换 2.1语法 2.2用法 3.常量类型转换 3.1语法 3.2用法 4.重新解释转换 4.1语法 1.静态类型转换 1.1语法 static_cast<目标转换类型>(待转换变量) 1.2用法 可用于基本数据类型之间的转换。比如int和char之…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

告别虚频困扰:用VASP+DynaPhoPy搞定高温材料声子谱的保姆级教程
高温材料声子谱计算实战:从虚频困境到非谐解决方案 引言:虚频问题的根源与突破路径 在计算材料学领域,声子谱分析是理解材料动力学稳定性和热力学性质的核心手段。然而许多研究者都遭遇过这样的困境:对实验合成的材料进行简谐近似…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

13456
12356...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

AI 如何改变软件工程:Martin Fowler 视角 + 实战洞见
AI 如何改变软件工程:Martin Fowler 视角 实战洞见 AI(尤其是 LLM)是软件工程自高级语言(从汇编到 C/Fortran)以来最大的转变。它引入了非确定性(Non-deterministic)编程,改变了从编…...

基于ESP8266与RGBDigit的Wi-Fi网络时钟:硬件设计、物联网集成与DIY实践
1. 项目概述:一个能感知环境的网络时钟如果你和我一样,对复古又带点科技感的显示设备没有抵抗力,同时又是个喜欢动手折腾的极客,那么这个项目绝对能让你在工作室或家里多一个既实用又炫酷的玩意儿。我说的就是这款基于RGBDigit数码…...

地理空间机器学习库全解析:从TorchGeo到Raster Vision的实战指南
1. 项目概述:为什么我们需要专门的地理空间机器学习库?如果你尝试过用标准的PyTorch或TensorFlow去处理一张卫星影像,大概率会在第一步就卡住。不是模型写不出来,而是数据根本读不进去,或者读进去了却对不上位置。一张…...