【数据结构与算法】栈和队列
文章目录
- 一.栈
- 1.1定义
- 顺序栈和链式栈
- 1.2基本操作
- 1.2.1表示
- 1.2.2初始化
- 1.2.3清空
- 1.2.4销毁
- 1.2.5入栈
- 1.2.6出栈
- 1.2.7取栈顶
- 1.3共享栈
- 1.3.1定义
- 1.3.2进栈出栈
- 二.队列
- 2.1定义
- 顺序队列和链式队列
- 循环队列
- 2.2基本操作
- 2.2.1初始化
- 2.2.2判空
- 2.2.3求队列长度
- 2.2.4取队头元素
- 2.2.5销毁
- 2.2.6进队
- 2.2.7出队
- 2.3双端队列
- 总结

栈和队列是两种常见的重要的数据结构
栈和队列是线性表的子集(是插入和删除位置受限的线性表)
一.栈
1.1定义
栈(Stack): 一种特殊的线性表,只允许在栈顶进行插入和删除元素操作。栈中的数据元素遵守后进先出LIFO (Last In First Out)的原则。

- 栈顶Top:允许进行插入、删除操作的一端称为栈的栈顶(top),也称为表尾。
- 栈底Base:固定不动的一端,称为栈底(bottom),也称为表头。
- 进栈PUSH(x):栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
- 出栈POP(y):栈的删除操作叫做出栈/弹栈,出数据也在栈顶。
栈满时的处理方法:
- 报错,返回操作系统
- 分配更大的空间,作为栈的存储空间,将原栈的内容移入新栈。
*进栈出栈的变化形式
看完定义,就会有同学发出质疑:那么最先进栈的元素,是不是就只能是以后出栈呢?
答案是不一定,要看是哪一种情况。栈对线性表的插入和删除的位置进行了限制,并没有对元素进出的时间进行限制,也就是说,在不是所有元素都进栈的情况下,事先进去的元素也可以出栈,只要保证是栈顶元素就可以。
举例来说,如果现在我们有3个整形数字元素1,2,3依次进栈,会有哪些出栈顺序呢?
- 第一种:1、2、3进,再3、2、1出。这是最简单、最好理解的一种,出栈次序为321。
- 第二种:1进,1出,2进,2出,3进,3出。也就是进一个出一个,出栈顺序为123。
- 第三种:1进,2进,2出,1出,3进,3出。出栈顺序为213。
- 第四种:1进,1出,2进,3进,3出,2出。出栈顺序为132。
- 第五种:1进,2进,2出,3进,3出,1出。出站顺序是231。
有没有可能是312这样的次序出栈呢?答案是肯定不会。因为3先出栈也就意味着3曾经进过栈,那既然3都进栈了,就意味着1和2已经进栈了,此时,2一定是在1的上面,就是说更接近栈顶,那么出栈顺序只能是321,不然不满足123一次进栈的要求,所以此时不会发生1比2先出栈的情况。
顺序栈和链式栈
栈也分为顺序栈和链栈(类比顺序表和链表)采用顺序存储的栈称为顺序栈,用一段物理地址连续的存储单元依次存储数据元素,通常以数组的形式实现;采用链式存储的栈称为链栈。
- 栈的顺序存储结构
既然栈是线性表的特例,那么栈的顺序存储其实也是线性表顺序存储的简化,我我们简称为顺序栈。利用一组地址连续的存储单元一次存放自栈底到栈顶的数据元素。栈底一般在低地址端。线性表是用数组来实现的。

- 附设top指针,指示栈顶元素在顺序栈中的位置,但是为了方便操作,通常top指示真正的栈顶元素之上的下标地址(top指针永远指向空)。
- 另设base指针,指示栈底元素在顺序栈中的位置,即首地址或基地址。
我们定义一个top变量来指示栈顶元素在数组中的位置,这top就如同中学物理学过的游标卡尺的游标,如下图所示,他可以来回移动,意味着栈顶的top可以变大变小,但是无论如何游标不能超出尺的长度。同理,若存储栈的长度为StackSize(最大容量),则栈顶位置top必须小于StackSize。当栈存在一个元素时,top等于0(top等于的数值的地址下标),因此通常把空栈的判定条件定为top=-1;

栈的实现一般可以使用数组作为顺序栈存储或者链表实现,相对而言数组的结构实现更优一些,因为数组尾插尾删的效率更高:简单,方便,但易产生溢出(数组大小固定)。
上溢(overflow):栈已经满,又要压入元素
下溢(underflow):栈已经空,还要弹出元素
上溢是一种错误,使问题的处理无法进行;而下溢一般认为是一种结束条件,即问题处理结束。
- 栈的链式存储结构
链式存储结构最大的好处就是没有空间的限制,可以通过指针指向将结点像以链式的形式把结点链接,我们熟悉的线性表就有链式存储结构。当然,栈同样有链式存储结构,栈的链式存储结构,简称链栈。

从图片可以看到,和单链表很像,拥有一个头指针top,又称作栈顶指针,所以此时就不再需要单链表里面的头结点了。故链栈是运算受限的单链表,只能在链表头部进行操作:因为给定链栈后,已知头结点的地址,在其后面插入一个新结点和删除首结点都十分方便,对应算法的时间复杂度均为O(1)。
对于链栈来说,基本不存在栈满的情况,除非计算机内存已经没有了可使用的空间,如果真的存在,那么计算机系统面临着即将死机崩溃的情况,而不是这个链栈是否溢出的问题了。
对于【空栈】来说,链表的定义是头指针指向NULL,而链栈是top=NULL。(top指向的结点S就是首元结点)
1.2基本操作
【顺序栈算法设计四要素】
1.栈空的条件:s->top==-1
2.栈满的条件:s->top==MaxSize-1(data数组的最大下标)
3.元素e进栈的操作:先将栈顶指针top增1,然后将元素e放在栈顶指针处
4.出栈的操作:先将栈顶指针top处的元素取出放在e中,然后将栈顶指针减1
【链栈算法设计四要素】
1.栈空的条件:s->next==NULL。
2.栈满的条件:由于只有内存溢出时才出现栈满,通常不考虑这样的情况,所以在链栈中可以看成不存在栈满。
3.元素e进栈的操作:新建一个结点存放元素e(由p指向它),将结点p插入头结点之后。
4.出栈的操作:取出首结点的data值并将其删除。
1.2.1表示
- 顺序栈的表示
动态分配利用指针来操作数组元素,静态分配利用下标来操作数组元素
//顺序栈的动态分配
typedef struct SqStack{ElemType* base;//栈底指针ElemType* top;//栈顶指针int stacksize;//栈可用最大容量
}SqStack;
//顺序栈的静态分配
typedef struct SqStack{ElemType data[Maxsize];//定长数组int top;//栈顶下标int stacksize;//栈可用最大容量
}SqStack;
/*栈的链式存储结构*/
/*构造节点*/
typedef struct StackNode{ElemType data;struct StackNode *next;
}StackNode, *LinkStackPrt;
/*构造链栈*/
typedef struct LinkStack{LinkStackPrt top;//构造链表int count;//栈可用最大容量
}LinkStack;
1.2.2初始化
【指针的偏移】两个指针相减的真正差值是要除以类型长度的,指针之间可以相减但不可以相加:两个同一类型的指针变量是可以相减的,同志们的意义表示两个指针指向的内存位置之间相隔多少个元素(注意是元素,不是字节数)。例如对于int类型指针p和p1,
p1-p的意义表示它们之间相隔多少个int类型的元素。
栈的初始化是空栈,而顺序栈空栈的条件是top==base=-1,链栈空栈的条件是s->nex=NULL;

void InitStack(SqStack *&s) //初始化顺序栈
{s=(SqStack *)malloc(sizeof(SqStack)); //分配一个顺序栈空间,首地址存放在s中s->top=-1;//或者是s->top=s->base //栈顶指针置为1
}
void InitStack(LinkStNode *&s) //初始化链栈
{s=(LinkStNode *)malloc(sizeof(LinkStNode));s->next=NULL;
}
【判断栈是否为空】
bool StackEmpty(SqStack *s) //判断顺序栈空否
{return(s->top==-1);
}
//也可以这样写
Status StackEmpty(SqStack S){if(S->top==S->base)return TRUE;elsereturn FALSE;
}
bool StackEmpty(LinkStNode *s) //判断栈空否
{return(s->next==NULL);
}
【求顺序栈的长度】
int StackLength(SqStack S){return S->top-S->base;
}
1.2.3清空
清空栈中的数据元素,栈还保留着(如同判断是否是空栈)
Status ClearStack(SqStack S){//清空顺序栈if(S->base)//如果base存在S->top=S->base;return OK;
}
1.2.4销毁
Status DestroyStack(SqStack &S){//销毁顺序栈,直接把结构回归内存if(S->base){delete S->base;S->stacksize=0;s->base=S->top=NULL;}return TRUE;
}//更简单点写
void DestroyStack(SqStack *&s) //销毁顺序栈
{free(s);
}
void DestroyStack(LinkStNode *&s) //销毁链栈
{LinkStNode *pre=s,*p=s->next; //pre指向头结点,p指向首结点while (p!=NULL) //循环到p为空{ free(pre); //释放p结点pre=p; //pre,p同步后移p=pre->next;}free(pre); //pre指向尾节点,释放其空间
}
1.2.5入栈
- 顺序栈入栈算法思路:1.判断是否栈满,若满则出错(上溢)2.元素e压入栈顶;3.栈顶指针加1
注意:每次入栈前,都需要判断栈是否已满

/*插入元素e为新的栈顶元素*/
bool Status Push(SqStack *S, ElemType e){//满栈if(S->top == MAXSIZE-1){return ERROR;}S->top++; //栈顶指针增加一S->data[S->top] = e; //将新插入元素赋值给栈顶空间//*S->top=e; 对top所指的空间进行操作return true;
}
- 链栈入栈算法思路:对于链栈的进栈push操作,不带头结点的头插,假设元素值为e的新节点是s,top为栈顶指针,S为栈顶。示意图如下:
【不带头结点的头插】因为不需要向下遍历访问,所以不要头节点更简单。不头插导致,存入顺序是3,2,1。尾插导致存入顺序是1,2,3.最终头指针都指向1.头插和尾插,他们处理的对象,有严格的逻辑先后关系,比如1,2,3。头指针要永远指向1。但是现在是栈,stack。它处理的对象只有进入的先后关系,没有逻辑先后。头插法的链表来实现栈;尾插法的链表来实现队列。

/*插入元素e为新的栈顶元素*/
bool Status Push(LinkStack *S, ElemType e){LinkStackPrt p = (LinkStackPrt)malloc(sizeof(StackNode));//生成新结点pp->data = e; //将新结点数据域设置为ep->next = S->top; //将新结点插入栈顶(原来栈的结点作为它的后继)S->top = p; //修改栈顶指针:将新的结点s赋值给栈顶指针S->count++;return true;
}
1.2.6出栈
- 顺序栈出栈算法思路:1.判断是否栈空,若满则出错(下溢)2.获取栈顶元素e;3.栈顶指针减1

bool Pop(SqStack *&s,ElemType &e) //出栈
{if (s->top==-1) //栈为空的情况,即栈下溢出return false;e=s->data[s->top]; //取栈顶元素//e=*S->top;s->top--; //栈顶指针增1return true;
}
- 链栈出栈算法思路:链栈的出栈pop操作,也是很简单的三句操作。假设变量p用来存储要删除的栈顶结点(在移动top之前需要一个指针来指向被删除结点,删除但不能让他丢失 所以用p存储),将栈顶指针下移一位,最后释放p即可,如下图所示:

bool Status Pop(LinkStack *S, ElemType &e){LinkStackPtr p;if(s->next==NULL){//栈空的情况return ERROR;}e = S->top->data;//提取首结点的值p = S->top; //p指向首结点:将栈顶结点赋值给pS->top = S->top->next; //删除首结点:使得栈顶指针下移一位,指向后一结点free(p); //释放被删除结点的存储空间S->count--;return true;
}
1.2.7取栈顶
顺序栈取栈顶

bool GetTop(SqStack *s,ElemType &e) //取栈顶元素
{if (s->top==-1) //栈为空的情况,即栈下溢出return false;*e=s->data[s->top]; //记录栈顶元素return true;
}
链栈取栈顶算法思路:头指针本来就指向栈顶元素,直接将data域的值输出

bool GetTop(LinkStNode *s,ElemType &e) //取栈顶元素
{ if (s->next==NULL) //栈空的情况return false;e=s->next->data; //提取首结点的值return true;
}
1.3共享栈
1.3.1定义
利用栈底位置相对不变的特征,可让两个顺序栈共享一个一维数组空间,将两个栈的栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸,如下图所示:

两个栈的栈顶指针都指向栈顶元素,top0=-1时0号栈为空,top1=MaxSize时1号栈为空;仅当两个栈顶指针相邻(top0+1=top1)时,判断为栈满。当0号栈进栈时top0先加1再赋值,1号栈进栈时top1先减一再赋值出栈时则刚好相反。
共享栈的空间结构
/*两栈共享空间结构*/
#define MAXSIZE 50 //定义栈中元素的最大个数
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
/*两栈共享空间结构*/
typedef struct{ElemType data[MAXSIZE];int top0; //栈0栈顶指针int top1; //栈1栈顶指针
}SqDoubleStack;
1.3.2进栈出栈
- 共享栈进栈
对于两栈共享空间的push方法,我们除了要插入元素值参数外,还需要有一个判断是栈0还是栈1的栈号参数stackNumber。
/*插入元素e为新的栈顶元素*/
Status Push(SqDoubleStack *S, Elemtype e, int stackNumber){if(S->top0+1 == S->top1){ //栈满return ERROR;}if(stackNumber == 0){ //栈0有元素进栈S->data[++S->top0] = e; //若栈0则先top0+1后给数组元素赋值}else if(satckNumber == 1){ //栈1有元素进栈S->data[--S->top1] = e; //若栈1则先top1-1后给数组元素赋值}return OK;
}
- 共享栈出栈
/*若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR*/
Status Pop(SqDoubleStack *S, ElemType *e, int stackNumber){if(stackNumber == 0){if(S->top0 == -1){return ERROR; //说明栈0已经是空栈,溢出}*e = S->data[S->top0--]; //将栈0的栈顶元素出栈,随后栈顶指针减1}else if(stackNumber == 1){if(S->top1 == MAXSIZE){return ERROR; //说明栈1是空栈,溢出}*e = S->data[S->top1++]; //将栈1的栈顶元素出栈,随后栈顶指针加1}return OK;
}
二.队列
2.1定义
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)的特点。
就像人们排队一样,讲究先来后到,先排队的人享受完服务,先离开。

- 队头:进行删除操作的一端。
- 队尾:进行插入操作的一端。
- 入队列:队列的插入操作,入数据在队尾。
- 出队列:队列的删除操作,出数据在队头。
顺序队列和链式队列
队列也可以用数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列是数组头删,效率会比较低。
队列也分为非循环队列和循环队列,可以用数组或链表实现。下面主要介绍用链表实现的普通的非循环队列。
- 队列的顺序存储结构
队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针:
队头指针 front:指向队头元素;
队尾指针 rear: 指向队尾元素的下一个位置。
队列的顺序存储类型可描述为:
//静态分配存储空间
#define MAXSIZE 50 //定义队列中元素的最大个数
typedef struct{ElemType data[MAXSIZE]; //存放队列元素int front,rear; //队头和队尾指针
}SqQueue;
//动态分配存储空间
#define MAXSIZE 50 //定义队列中元素的最大个数
typedef struct{QElemType* base; //存放队列元素int front,rear; //队头和队尾指针
}SqQueue;
溢出:当
rear=MAXQSIZE时,发生溢出;若front=0,rear=MAXQSIZE时,再入队是真溢出;若front不等于0,rear=MAXQSIZE是再入队是假溢出。
- 队列的链式存储结构
在这样的链队中只允许在单链表的表头进行删除操作(出队)和在单链表的表尾进行插入操作(进队),因此需要使用队头指针front和队尾指针rear 两个指针,用 front 指向队首结点,用rear指向队尾结点。和链栈一样,链队中也不存在队满上溢出的情况。链队的存储结构如图所示:

#define MAXSIZE 50 //定义队列中元素的最大个数
typedef struct Qnode{//链式存储队列结点QElemType data;//存放元素stuct Qnode* next;//下一个结点指针
}QNode;//链队数据结点的类型
typedef struct* QuenePtr;typedef struct {//链式队列QuenePtr front;//队头指针QuenePtr reaR;//队尾指针
}LinkQueue;
?为什么同样都需要在头部操作,链栈不需头结点,链队和单链表需要头结点
链式队列,你的头结点是要不断出队的,也就是说你的头结点是不断变化的。而单链表是需要通过头结点来访问的,所以必须有头
那我们思考下: 队列的实现使用顺序结构还是链式结构好?
其实, 选择哪种方式取决于具体的需求:
- 顺序结构(数组):优点是访问元素的时间复杂度为O(1),适合队列的插入和删除操作通常在队列的一端进行(即“先进先出”FIFO)。然而,当队列满时,添加新元素需要移动所有后续元素,空间效率较低,且不适合动态扩容。
- 链式结构(链表):链表则更灵活,能够动态地增加或减少容量,无需预先设定大小。对于频繁的插入和删除操作(尤其是中间位置),链表表现更好,因为只需要修改相邻节点的指针。但是,访问任意位置的元素时间复杂度为O(n)。
总的来说,如果队列的长度变化不大,且经常从队列前端进行操作,顺序结构可能是更好的选择;如果队列长度可能会增长并且有频繁的随机访问需求,或者频繁在队列中部插入和删除,那么链式结构会更有优势。

循环队列
循环队列是一种特殊的线性表数据结构,它在队列的一端添加元素,在另一端删除元素。与普通的队列(先进先出,FIFO)不同的是,循环队列的最后一个位置之后紧跟着第一个位置,形成了一个首尾相连的闭环。当试图从队列尾部删除元素而队列为空时,不会引发错误,而是会自动跳转到队列头部开始。相反,当试图从队列头部添加元素而队列已满时,也不会溢出,而是会替换掉队尾的第一个元素。

- 环形队列首尾相连后,当队尾指针rear=MaxSize-1后,再前进一个位置就到达0,于是就可以使用另一端的空位置存放队列元素了。实际上存储器中的地址总是连续编号的,为此采用数学上的求余运算(%)来实现:(定义和顺序队列一样)
队头指针front循环增1:front=(front+1)%MaxSize
队尾指针rear循环增1:rear=(rear+1)%MaxSize
循环队列的优势在于它能够有效地利用有限的空间,避免了普通数组在队列满时需要动态扩容的问题。但是,由于其内部逻辑相对复杂,可能会增加一些额外的操作开销,如判断队列是否满或空、元素移动等。
2.2基本操作

【顺序队列的四个要素】
- 队空的条件:q->front==q->rear。
- 队满的条件:q->rear==MaxSize-1(data数组的最大下标)。
- 元素e进队的操作:先将 rear增1,然后将元素e 放在 data数组的rear位置。
- 出队的操作:先将 front增1,然后取出 data 数组中front位置的元素。(先处理再移动指针)
【链表队列的四个要素】
- 队空的条件:q->rear == NULL(也可以为q->front==NULL)。
- 队满的条件:不考虑。
- 元素e进队的操作:新建一个结点存放元素e(由p指向它),将结点 p插入作为尾结点。
- 出队的操作:取出队首结点的 data 值并将其删除。

【循环队列的四个要素】
- 队空条件:q->rear=q->front
- 队满条件:(q->rear+1)%MaxSize=q->front
- 进队操作:队尾循环进1
- 出队操作:队头循环进1
2.2.1初始化
void InitQueue(SqQueue &q)//顺序队列初始化
{ q=(SqQueue *)malloc (sizeof(SqQueue));q->front=q->rear=-1;
}
- 链式队列初始化

void InitQueue(LinkQueue *Q){//链式队列初始化Q->front = Q->rear = (LinkNode)malloc(sizeof(LinkNode)); //建立头结点Q->front->next = NULL; //初始为空
}
bool InitQueue(SqQueue &q) //循环初始化队列q
{ q=(SqQueue *)malloc (sizeof(SqQueue));if(!Q.base)exit(OVERFLOW);//存储分配失败q->front=q->rear=0;//头指针尾指针置为0,队列为空return true;
}
2.2.2判空
bool QueueEmpty(SqQueue *q)
{return(q->front==q->rear);
}
- 链式队列的判空
链式队列有头结点,所以判空如下:
bool QueueEmpty(LinkQuNode *q)//链式队列判空
{return(q->rear==NULL);//
}
- 循环队列
区别队空和队满的其他解决方案:
- 另外设一个标志以区别队空,队满
- 另设一个变量,记录元素个数
- 少用一个元素空间

bool QueueEmpty(SqQueue *q) //判断队q是否空
{return(q->front==q->rear);
}
2.2.3求队列长度
- 顺序队列
int QueueLength(SqQueue Q){return((Q->rear-Q->front)%MAXQSIZE);
}
- 循环队列:
Q->rear-Q->front相减会出现负数,所以Q->rear-Q->front+MAXQSIZE
int QueueLength(SqQueue Q){return((Q->rear-Q->front+MAXQSIZE)%MAXQSIZE);
}
2.2.4取队头元素
- 循环队列
SElemType GetHead(SqQuere Q){if(Q->front!=Q->rear)//队列不为空return Q->base[Q->front];//返回队头指针元素的值,队头指针不变
}
- 链式队列
链式队列取头结点的下一个结点中的元素。
bool Status GetHead(LinkQueue Q,QElemType &e){if(Q->front==Q->rear)return ERROR;e=Q->front->next->data;return true;
}
2.2.5销毁
void DestroyQueue(SqQueue *&q)
{free(q);
}
- 链式队列的销毁
算法思想:从队头结点开始,依次释放所有结点

void DestroyQueue(LinkQuNode *&q) //销毁队列q
{DataNode *pre=q->front,*p; //p指向队首结点if (pre!=NULL) { p=pre->next; //p指向pre结点的后继结点while (p!=NULL) //p不空时循环{ free(pre); //释放pre结点pre=p;p=p->next; //p,pre同步后移}free(pre); //释放最后一个数据结点}free(q); //释放链队结点占用空间
}
void DestroyQueue(SqQueue *&q) //循环队列
{free(q);
}
2.2.6进队
bool enQueue(SqQueue *&q,ElemType e) //进队
{ if (q->rear==MaxSize-1) //队满上溢出return false; //返回假q->rear++; //队尾增1q->data[q->rear]=e; //rear位置插入元素ereturn true; //返回真
}
- 链式队列进队

Status EnQueue(LinkQueue *Q, ElemType e){LinkNode s = (LinkNode)malloc(sizeof(LinkNode));s->data = e;//在data域存放要插入的值s->next = NULL;Q->rear->next = s; //把拥有元素e新结点s赋值给原队尾结点的后继Q->rear = s; //把当前的s设置为新的队尾结点return OK;
}
bool enQueue(SqQueue *&q,ElemType e) //进队
{ if ((q->rear+1)%MaxSize==q->front) //队满上溢出return false;q->data[q->rear]=e;//新元素加入队尾q->rear=(q->rear+1)%MaxSize;//队尾指针+1return true;
}
2.2.7出队
bool deQueue(SqQueue *&q,ElemType &e) //出队
{ if (q->front==q->rear) //队空下溢出return false;q->front++;e=q->data[q->front];return true;
}
- 链式队列出队
出队操作时,就是头结点的后继结点出队,将头结点的后继改为它后面的结点,若链表除头结点外只剩一个元素时,则需将rear指向头结点。

/*若队列不空,删除Q的队头元素,用e返回其值,并返回OK,否则返回ERROR*/
Status DeQueue(LinkQueue *Q, Elemtype *e){LinkNode p;if(Q->front == Q->rear){//判空return ERROR;}p = Q->front->next; //将欲删除的队头结点(头结点的下溢结点)暂存给p*e = p->data; //将欲删除的队头结点的值赋值给eQ->front->next = p->next; //将原队头结点的后继赋值给头结点后继//若删除的队头是队尾,则删除后将rear指向头结点if(Q->rear == p){ //如果要删除的是尾结点Q->rear = Q->front;}free(p);return OK;
}
bool deQueue(SqQueue *&q,ElemType &e) //循环队列出队
{ if (q->front==q->rear) //队空下溢出return false;e=q->data[q->front];q->front=(q->front+1)%MaxSize;return true;
}
2.3双端队列
1、定义
双端队列是指允许两端都可以进行入队和出队操作的队列,如下图所示。其元素的逻辑结构仍是线性结构。将队列的两端分别称为前端和后端,两端都可以入队和出队。

在双端队列进队时,前端进的元素排列在队列中后端进的元素的前面,后端进的元素排列在队列中前端进的元素的后面
2、特殊的双端队列
在实际使用中,根据使用场景的不同,存在某些特殊的双端队列。
输出受限的双端队列:允许在一端进行插入和删除, 但在另一端只允许插入的双端队列称为输出受限的双端队列,如下图所示。

输入受限的双端队列:允许在一端进行插入和删除,但在另一端只允许删除的双端队列称为输入受限的双端队列,如下图所示。若限定双端队列从某个端点插入的元素只能从该端点删除,则该双端队列就蜕变为两个栈底相邻接的栈。
总结
栈和队列都是一种特殊的线性表。
- 栈的特点:后进先出,只能在表尾进行插入和删除。
- 队列的特点:先进先出,只能在表头删除,在表尾插入。
它们都可以用顺序存储和链式存储的方式。
栈常用顺序存储结构即数组的方式,因为数组的尾插尾删效率高,但可能会存在频繁开辟内存空间和内存空间浪费的问题。而栈的链式存储结构,解决了空间浪费的问题,但每个节点都存放一个指针域,也会存在一定的内存开销,并且在每次申请和释放节点的过程中也存在一定的时间开销。
队列常用链式存储结构即链表的方式,比链表多定义一个尾指针,解决尾插效率低的问题,并且不存在空间浪费。 而队列的顺序存储结构,由于插入需要挪动数据,效率低下,但循环队列可以解决这个问题,时间复杂度从O(N)变成了O(1),但仍存在内存空间浪费的问题。
相关文章:
【数据结构与算法】栈和队列
文章目录 一.栈1.1定义 顺序栈和链式栈1.2基本操作1.2.1表示1.2.2初始化1.2.3清空1.2.4销毁1.2.5入栈1.2.6出栈1.2.7取栈顶 1.3共享栈1.3.1定义1.3.2进栈出栈 二.队列2.1定义 顺序队列和链式队列循环队列2.2基本操作2.2.1初始化2.2.2判空2.2.3求队列长度2.2.4取队头元素2.2.5销…...

基于php的图书管理系统
摘 要 随着互联网的发展,许多人都热衷于在线购物,无需离开家就可以获得所需的产品,通过简单的操作,就能够获得快速、准确的配送。 科技已然渗透到进社会的方方面面,让我们的学习、交流、工作变得无比轻松自如。由于…...

k8s Node节点维护
Kubernetes (K8s) 中对 Node 节点的维护是保证集群健康和性能的重要部分。Node 节点通常是 Kubernetes 工作负载的运行环境,负责运行 Pods。当需要对节点进行维护(如升级、修复问题、调整配置等)时,可能需要将该节点标记为不可用并…...
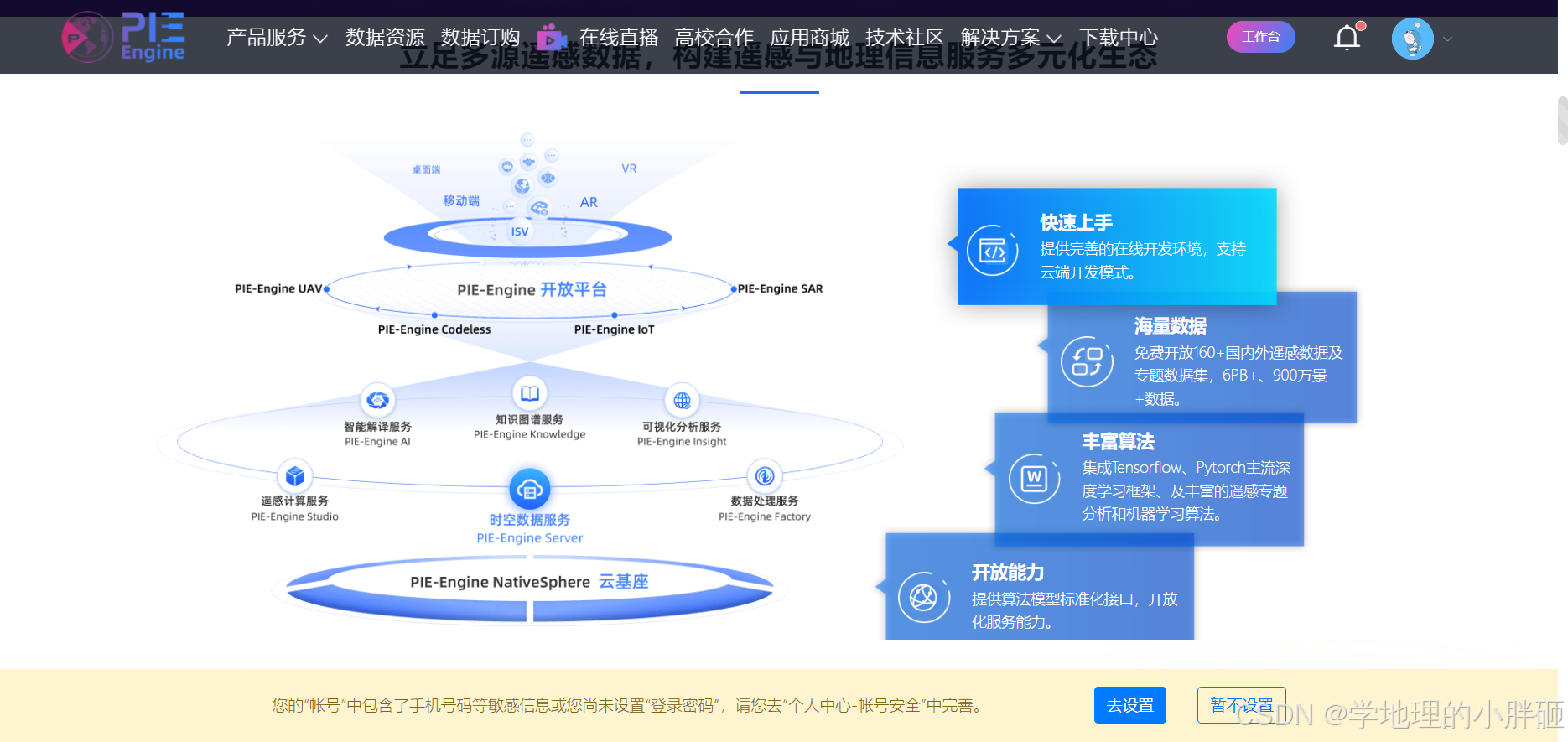
【航天宏图旗下的PIE engine】
航天宏图旗下的PIE engine是一个集实时分布式计算、交互式分析和数据可视化为一体的在线遥感云计算开放平台,以下是对其的详细介绍: 一、平台背景与定位 PIE-Engine地球科学引擎是航天宏图自主研发的一套基于容器云技术构建的面向地球科学领域的专业P…...

Python酷库之旅-第三方库Pandas(157)
目录 一、用法精讲 716、pandas.Timedelta.view方法 716-1、语法 716-2、参数 716-3、功能 716-4、返回值 716-5、说明 716-6、用法 716-6-1、数据准备 716-6-2、代码示例 716-6-3、结果输出 717、pandas.Timedelta.as_unit方法 717-1、语法 717-2、参数 717-3、…...

【原创】java+springboot+mysql校园表白墙网站设计与实现
个人主页:程序猿小小杨 个人简介:从事开发多年,Java、Php、Python、前端开发均有涉猎 博客内容:Java项目实战、项目演示、技术分享 文末有作者名片,希望和大家一起共同进步,你只管努力,剩下的交…...

CSS学习(Grid布局和flex布局比较)
grid网格布局真香,比flex方便太多了,grid-template-columns用法 文章目录 flex布局的时候网格grid布局的时候可以修改某一列的像素可以修改某一列的宽度占比自适应屏幕分列让第一个元素长宽都占2个 flex布局的时候 最后一行不够4个的时候 最下面一行无法…...

RTThread-Nano学习二-RT-Thread启动流程
一、简介 上一章,我们已经了解了如何通过MDK来移植RTT,不熟悉的可以看如下链接:RTThread-Nano学习一-基于MDK移植-CSDN博客本章我们就来继续了解一下,RTT的启动流程。 二、启动流程 官方给了一幅非常清晰的启动流程图&am…...

排查sshfs挂载失败的问题
#排查sshfs挂载失败的问题 写代码在Linux上运行,但是熟悉的IDE(比如VS code)在自己的电脑上,可以使用sshfs把linux上的目录挂载到本地,再用VScode打开即可,可以使用下面的命令: sshfs -odebug…...
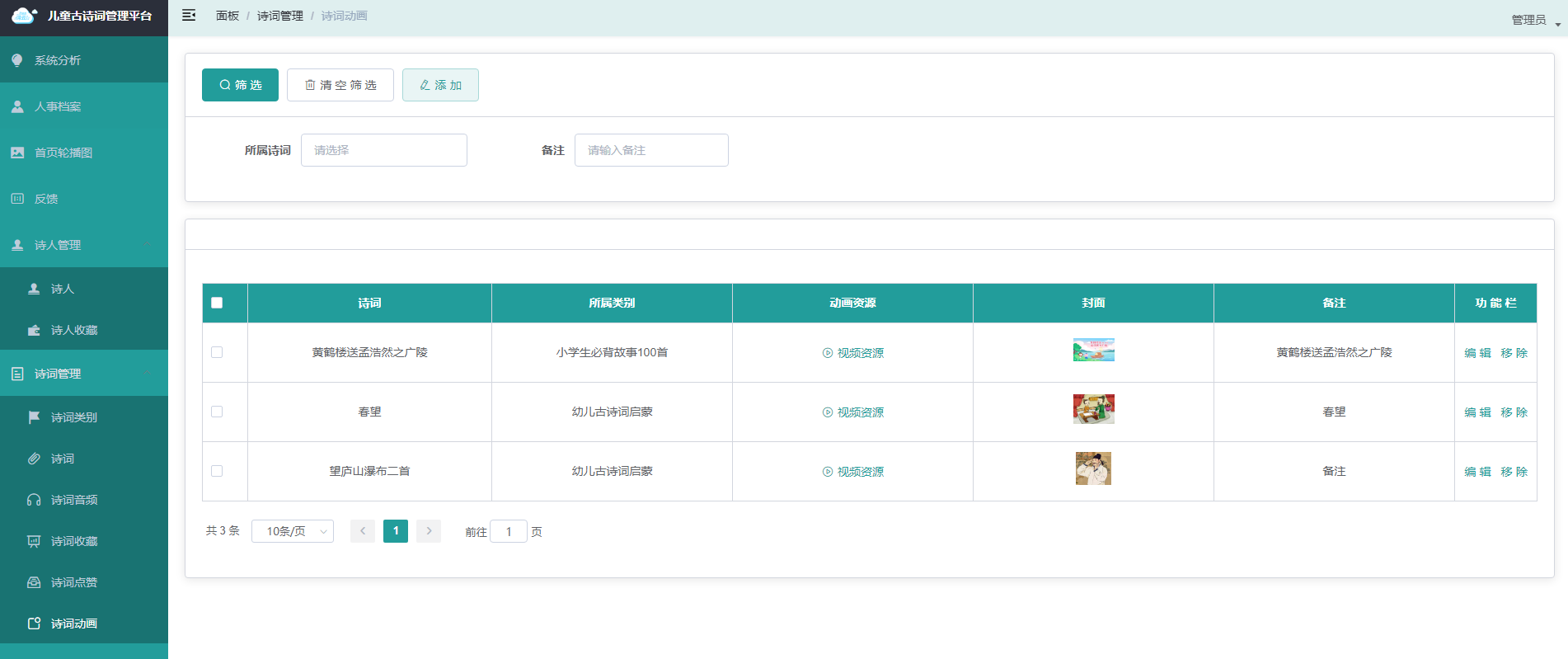
【002】基于Spring Boot+Unipp的古诗词学习小程序【原创】
一.系统开发工具与环境搭建 1.系统设计开发工具 后端使用Java编程语言的Spring boot框架 项目架构:B/S架构 运行环境:win10/win11、jdk17 前端: 技术:框架Vue.js;UI库:ElementUI; 开发工具&…...

PageHelper循环依赖问题
1. 问题 2. 原因 项目中SpringBoot的版本为2.7.18。 SpringBoot2.6.x后不推荐使用循环依赖,也就是说从2.6.x版本开始,如果项目里还存在循环依赖,SpringBoot将拒绝启动! 3. 解决 去pageHelper github看,才看到新版本…...

k8s部署Kafka集群超详细讲解
准备部署环境 Kubernetes集群信息 NAMEVERSIONk8s-masterv1.29.2k8s-node01v1.29.2k8s-node02v1.29.2 Kafka:3.7.1版本,apche版本 Zookeeper:3.6.3版本 准备StorageClass # kubectl get sc NAME PROVISIONER RECLA…...

【数据采集工具】Sqoop从入门到面试学习总结
国科大学习生活(期末复习资料、课程大作业解析、大厂实习经验心得等): 文章专栏(点击跳转) 大数据开发学习文档(分布式文件系统的实现,大数据生态圈学习文档等): 文章专栏(点击跳转&…...

Matlab绘图总结(进阶)
本文在前文的基础上进一步整理画图方法 MATLAB画动图_CSDN博客 1. 基础图形绘制 1.1 rectangle(矩形,圆形) 在前文中,讲解了如何使用rectangle,rectangle本意是用来画矩形的,其中,Curvature可…...

QExcel 保存数据 (QtXlsxWriter库 编译)
QtXlsxWriter 是一个用于在 Qt 应用程序中创建和操作 Excel XLSX 文件的库。它提供了一个简单的 API,使开发者能够轻松地生成和修改 Excel 文件,而无需依赖 Microsoft Excel 或其他外部应用程序。支持初始化、写文件、读文件、格式设置、合并单元格、加粗…...

k8s ETCD数据备份与恢复
在 Kubernetes 集群中,etcd 是一个分布式键值存储,它保存着整个集群的状态,包括节点、Pod、ConfigMap、Secrets 等关键信息。因此,定期对 etcd 进行备份是非常重要的,特别是在集群发生故障或需要恢复数据的情况下。本文…...

【C语言】循环嵌套:乘法表
循环嵌套,外层循环执行一次,内层循环执行i次。分别控制 在循环的过程中加一层循环。 多层循环属于循环嵌套、嵌套循环 #include <stdio.h> #include <math.h> /* 功能:循环嵌套 乘法表 时间:2024年10月 地点…...
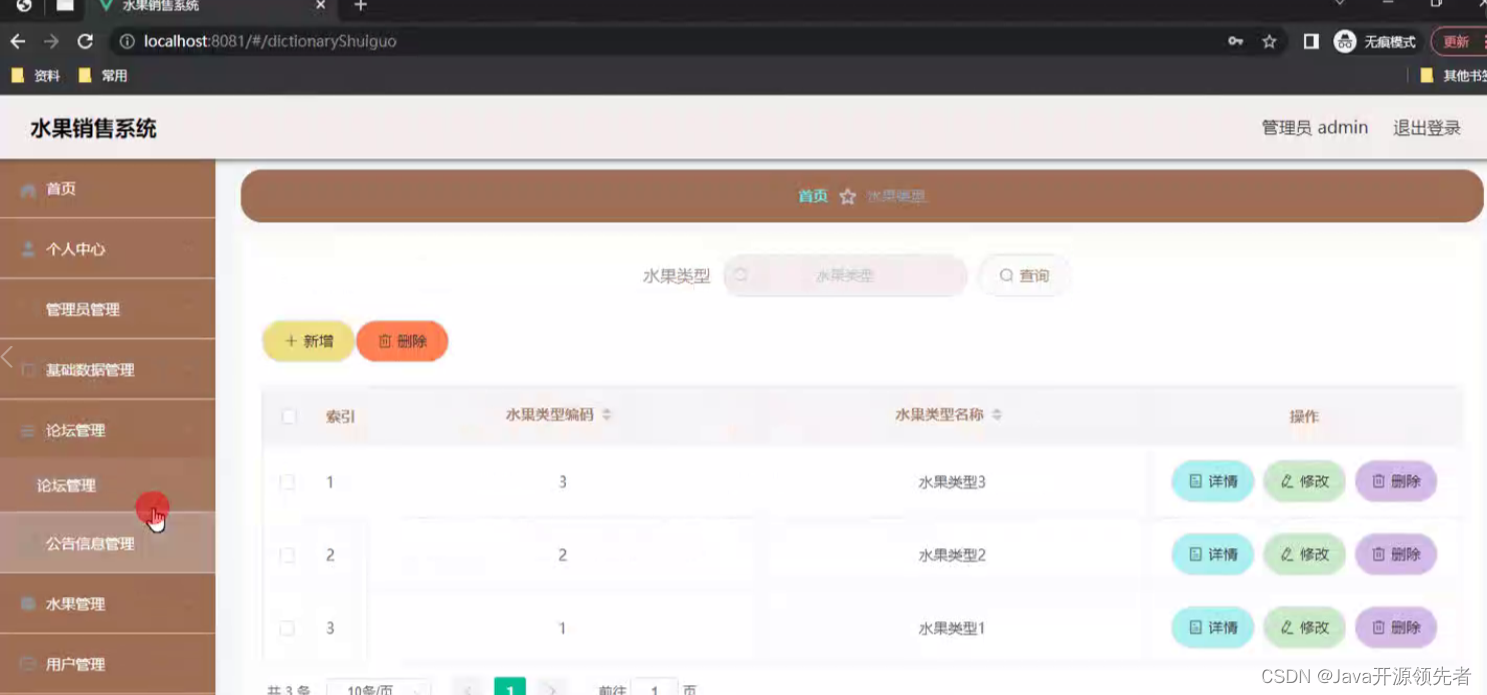
基于Java微信小程序的水果销售系统详细设计和实现(源码+lw+部署文档+讲解等)
详细视频演示 请联系我获取更详细的演示视频 项目运行截图 技术框架 后端采用SpringBoot框架 Spring Boot 是一个用于快速开发基于 Spring 框架的应用程序的开源框架。它采用约定大于配置的理念,提供了一套默认的配置,让开发者可以更专注于业务逻辑而不…...

从0开始深度学习(11)——多层感知机
前面介绍了线性神经网络,但是线性模型是有可能出错的,因为线性模型意味着是单调假设,但是现实中往往很复杂。例如,我们想要根据体温预测死亡率。 对体温高于37摄氏度的人来说,温度越高风险越大。 然而,对体…...

SQL语句查询
SQL语句查询 查询产生一个虚拟表 看到的是表形式显示的结果,但结果并不真正存储 每次执行查询只是从数据表中提取数据,并按照表的形式显示出来 查询语法 SELECT <列名> FROM <表名> [WHERE <查询条件表达式>] SELECT …...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...