Spark的安装配置及集群搭建
Spark的本地安装配置:
我们用scala语言编写和操作spark,所以先要完成scala的环境配置
1、先完成Scala的环境搭建
下载Scala插件,创建一个Maven项目,导入Scala依赖和插件

scala依赖
<dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.12</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>2.11.12</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>2.11.12</version></dependency>scala插件
<build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build>2、导入spark-core依赖
<!--导入spark-core依赖--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.5</version></dependency>3、使用spark-->(代码操作)
以下是用spark处理单词统计任务
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Demo1WordCount {def main(args: Array[String]): Unit = {//1、创建spark的执行环境val conf = new SparkConf()//设置运行模式conf.setMaster("local")conf.setAppName("wc")val sc = new SparkContext(conf)//2、读取数据//RDD:弹性的分布式数据集(相当于List)val linesRDD: RDD[String] = sc.textFile("data/lines.txt")//一行转换多行val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(","))val kvRD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))//统计单词的数量val countRDD: RDD[(String, Int)] = kvRD.reduceByKey((x, y) => x + y)//保存结果countRDD.saveAsTextFile("data/word_count")}
}搭建Spark独立集群:
## 1、独立集群> Spark自己搭建一个资源管理框架,不依赖yarn### 1、上传解压配置环境变量```shell
# 家业安装包
tar -xvf spark-3.1.3-bin-hadoop3.2.tgz -C /usr/local/soft
# 重命名解压目录
mv spark-3.1.3-bin-hadoop3.2/ spark-3.1.3# 配置环境变量
vim /etc/profileexport SPARK_HOME=/usr/local/soft/spark-3.1.3
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile
```### 2、修改配置文件```shell
# 1、修改spark-env.sh
cd /usr/local/soft/spark-3.1.3/conf/
mv spark-env.sh.template spark-env.sh
# 在spark-env.sh中增加配置
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.1/etc/hadoop
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=4G
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171# 2、修改workers
mv workers.template workers# 增加配置
node1
node2# 3、同步到所有节点
cd /usr/local/soft/
scp -r spark-3.1.3/ node1:`pwd`
scp -r spark-3.1.3/ node2:`pwd`
```### 3、启动集群```shell
# 启动集群
cd /usr/local/soft/spark-3.1.3/sbin
./start-all.sh # spark webUI
http://master:8080
```### 4、提交任务```shell
# 进入样例代码所在的目录
/usr/local/soft/spark-3.1.3/examples/jars# 提交任务
spark-submit --master spark://master:7077 --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.3.jar 100# 代码提交到集群运行方式
#1、注释local
#2、修改数据路径,改成HDFS的路径,输入输出目录都需要修改i
#3、将代码打包上传到服务器运行
# 提交任务
spark-submit --master spark://master:7077 --class com.company.core.Demo15Submit spark-1.0-SNAPSHOT.jar
```## 2、Spark on Yarn> yarn是一个分布式资源管理管家,负责管理集群的CPU和内存### 1、关闭独立集群```shell
# 进入spark脚本目录
cd /usr/local/soft/spark-3.1.3/sbin
./stop-all.sh
```### 2、启动hadoop```shell
start-all.sh
```### 3、提交任务```shell
# --num-executors 2: 指定Executor的数量
# --executor-cores 1 : 指定executor的核数
# --executor-memory 2G :指定executoe的内存# yarn client模式
# 1、会在本地打印详细的执行日志,可以看到全部执行错误日志
# 2、一般用于测试使用,如果大量的任务都使用client模式去提交,会导致本地节点压力大
# 3、client模式Driver、在本地启动,所以再本地可以看详细日志
spark-submit --master yarn --deploy-mode client --num-executors 2 --executor-cores 1 --executor-memory 2G --class com.company.core.Demo15Submit spark-1.0-SNAPSHOT.jar# yarn cluster模式
# 1、在本地不打印详细的执行日志,只能看到部分错误日志
# 2、任务执行报错会重试一次
# 3、一般用于上线使用,Driver是随机节点,不会导致某一个系欸但压力大
# 4、Driver不在本地启动,所在再本地看不到详细日志
spark-submit --master yarn --deploy-mode cluster --num-executors 2 --executor-cores 1 --executor-memory 2G --class com.company.core.Demo15Submit spark-1.0-SNAPSHOT.jar# 获取yarn任务的详细日志
yarn logs -applicationId [appid]spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.3.jar 100
```相关文章:
Spark的安装配置及集群搭建
Spark的本地安装配置: 我们用scala语言编写和操作spark,所以先要完成scala的环境配置 1、先完成Scala的环境搭建 下载Scala插件,创建一个Maven项目,导入Scala依赖和插件 scala依赖 <dependency><groupId>org.scal…...

网络编程基础-IO模型深入理解
一、IO的基本概念 什么是IO? I/O就是计算机内存与外部设备之间拷贝数据的过程 什么是网络IO? 网络IO是指在计算机网络环境中进行的输入和输出操作,涉及数据在网络设备之间的传输。 网络IO操作可以是发送请求、接收响应、下载文件、传输数…...

go 语言学习路线图(一)
1. Go语言简介 Go语言的历史背景和设计理念Go的优势:简洁、高效、并发支持强Go的应用场景:微服务、云计算、系统编程 2. 开发环境设置 安装Go语言开发环境 在Windows、macOS、Linux系统上的安装方法 配置环境变量:GOROOT 和 GOPATH验证安装…...

前端自动化部署,Netlify免费满足你
1 Netlify 介绍 为什么推荐 Netliy , 主要还是穷,Netlify 免费太香了 Netlify you优势100GB 内免费 ,满足个人日常 需求,操作,兼容性绑定代码仓库,提交代码自动部署 支持 github , gitlab 等 大多常用代码仓库易操作只…...

Linux的开发工具gcc Makefile gdb的学习
一:gcc/g 1. 1 背景知识 1. 预处理(进行宏替换) 预处理 ( 进行宏替换 ) 预处理功能主要包括宏定义,文件包含,条件编译,去注释等。 预处理指令是以#号开头的代码行。 实例: gcc –E hello.c –o hello.i 选项“-E”,该选项的作用是让 gcc 在预处理结…...
基于SSM出租车管理系统的设计
管理员账户功能包括:系统首页,个人中心,车辆管理,驾驶员管理,基础数据管理,公告管理 驾驶员账号功能包括:系统首页,学生管理,车辆管理,公告管理 开发系统&a…...

iPhone照片内存怎么清理,参考这些方法
随着拍摄数量的增加,许多iPhone用户常常发现自己的手机存储空间不足,而照片无疑是占用空间的罪魁祸首之一。清理这些照片不仅能释放存储空间,还能提升设备的运行速度。小编将分享一些iPhone照片内存怎么清理的高效策略,助你告别冗…...

【Triton教程】向量相加
Triton 是一种用于并行编程的语言和编译器。它旨在提供一个基于 Python 的编程环境,以高效编写自定义 DNN 计算内核,并能够在现代 GPU 硬件上以最大吞吐量运行。 更多 Triton 中文文档可访问 →https://triton.hyper.ai/ 在本教程中,你将使…...

关于CSS中毛玻璃和滤镜使用总结
【1】毛玻璃 毛玻璃效果(也称为磨砂玻璃效果)可以通过 CSS 的 backdrop-filter 属性来实现。这个属性允许你在背景上应用各种滤镜效果,从而创建出类似磨砂玻璃的效果。这种效果通常用于创建半透明背景下的模糊效果,使得背景图像或…...

陷入产出危机的我聊聊近况
文章目录 前言我的多重身份作为IT网管作为运维人员作为Web开发人员作为游戏开发人员 总结 前言 在总结文章时,我把自己当做一个内容产出者,当这样一个身份进入每天按部就班的平稳状态时会陷入一种焦虑,产生一种居然没有什么可写的感觉&#…...

HarmonyOS 开发知识总结
1. HarmonyOS 开发知识总结 1.1. resources->base->media中不可以新建文件夹? 项目图片路径resources->base->media中不可以新建文件夹,图片全平级放里面,查找图片不方便,有没有什么其他的办法解决这个难点ÿ…...

[WPF初学到大神] 1. 什么是WPF, MVVM框架, XAML?
什么是WPF? WPF(Windows Presentation Foundation) 包含XAML标记语言和后端代码来开发桌面应用程序的. 用VS新建项目有WPF(.Net Framework和.Net应用程序), 该怎么选? 首选 .NET 应用程序(.NET Core 或 .NET 5/6/7/8新版本)拥有更好的性能、跨平台Windows, Linux, Mac支…...

matlab怎样自动搜索文件夹中的所有txt文件,并将每个txt文件中的数据存放到一个cell数组中——MATLAB批量处理数据
在使用MATLAB批量处理数据时,有时候需要自动搜索文件夹中的所有txt文件,并将每个txt文件中的数据存放到一个以一定规律命名的变量中,以便于后续通过循环处理每个变量数据。 然而,MATLAB并不支持在变量名中直接使用i来动态生成变量…...
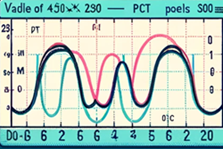
LabVIEW智能可变温循环PCT测试系统
随着全球能源危机的加剧和环境保护需求的提升,开发和利用清洁能源已成为全球必然趋势。氢能作为一种高效的替代能源,正逐步受到关注。然而,储氢技术的研究至关重要,尤其是储氢材料的PCT(Pressure-Composition-Temperat…...

SparkSQL整合Hive
spark-sql可以直接使用hive的元数据 1、环境搭建如下: ## 1、启动hive的元数据服务shell # 1、修改hive的配置文件 cd /usr/local/soft/hive-3.1.3/conf# 2、增加配置 vim hive-site.xml<property> <name>hive.metastore.uris</name> <value…...

Vue 3 和 Vue 2区别
Vue 3 是 Vue 2 的全新升级版本,引入了诸多新的特性,并在性能、开发体验、响应式系统等多个方面进行了改进。以下是 Vue 2 和 Vue 3 的详细对比: 1. 生命周期钩子差异 Vue 3 保留了大部分 Vue 2 的生命周期钩子,但部分名称有所调…...

React.memo和useMemo
React.memo和usememo React.memo React.memo是一个高阶组件,对组件进行性能优化,主要用于优化函数组件的性能,如果一个组件在相同的props下渲染出相同的结果,但是又不需要在组件更新的时候重新渲染,就可以使用react.…...

Android中实现网络请求的方式有哪些?
在Android开发中,实现网络请求是开发过程中不可避免的一部分。随着技术的不断发展,Android中出现了多种实现网络请求的方式,每种方式都有其独特的优缺点。 一、HttpURLConnection HttpURLConnection是Java提供的用于发送HTTP请求的标准类&a…...

安卓13usb触摸唤醒系统 android13触摸唤醒
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.问题分析3.代码分析4.代码修改5.编译6.彩蛋1.前言 android13在待机后,需要能够使用触摸屏去唤醒我们的系统,这就需要我们修改系统的相关配置了。 2.问题分析 对于这个问题,我们需要知道安卓的事件分发,通过事件分发,…...

c++常用库函数
一.sort排序 快排的改进算法,评价复杂度为(nlogn). 1.用法 sort(起始地址,结束地址下一位,*比较函数) [起始地址,结束地址) (左开右闭) #include<bits/stdc.h> using namespace std; int main() {//sortvector<int&g…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...