open-cd中的changerformer网络结构分析
open-cd
目录
- open-cd
- 1.安装
- 2.源码结构分析
- 主干网络
- 1.1 主干网络类
- 2.neck
- 2.Decoder
- 3.测试模型
- 6. changer主干网络
- 总结

该开源库基于:
mmcv
mmseg
mmdet
mmengine
1.安装
在安装过程中遇到的问题:
1.pytorch版本问题,open-cd采用的mmcv版本比较低,建议安装2.3以下版本pytorch,太高了mmcv可能不太适配,先安装pytorch,在安装mmcv,我在安装时用的版本
pytorch 2.1.2 py3.9_cuda12.1_cudnn8_0 pytorch
mmcv 2.1.0 pypi_0 pypi
mmcv安装方式

该方式同样适用于解决:
note: This error originates from a subprocess, and is likely not a problem with pip.ERROR: Failed building wheel for mmcvRunning setup.py clean for mmcv
Failed to build mmcv
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (mmcv)
参考
之后参照博主的的安装步骤安装opencd的开原文件即可(建议安装源文件,直接 opencd第三方包形式后期不方便调试):
# Install OpenMMLab Toolkits as Python packages
pip install -U openmim
mim install mmengine
mim install "mmpretrain>=1.0.0rc7"
pip install "mmsegmentation>=1.2.2"
pip install "mmdet>=3.0.0"# Install Opencd
git clone https://github.com/likyoo/open-cd.git
cd open-cd
pip install -v -e .
2.源码结构分析

该库主要的文件时1.config参数文件,2.opencd模型架构文件,3.训练推理分析工具,4.mmlab
这里主要介绍2.opencd模型框架文件,文件下包含:

其中,model文件夹下包含模型结构基础文件:

变化检测大致遵循语义分割的编码结构、neck结构、以及解码结构。
如果使用过mmsegmentation机会发现,backbone中存放着雨参数文件对应的主干网络,相应的是neck,decoder,这里changer_detector里面是主要的模型架构如Encoder-Decoder。
open-cd与mmseg这类参数化的文件非常适合进行模型复现或者进行工程化应用;但对一些科研小白,特别是非计算机专业的科研小白需要改进网络就不太友好;这里直观的作用下模型架构的组合使用,方便大家理解和魔改(~~别越看越迷糊就行)
这里以changerformer-mitb0为例:
前提是已完成open-cd的安装官方issue
下面内容摘自opencd/model/
删除每个类前面的注册表装饰器 @MODELS.register_module(),报错提示类已注册
主干网络
# Copyright (c) OpenMMLab. All rights reserved.
import math
import warningsimport torch
import torch.nn as nn
import torch.utils.checkpoint as cp
from mmcv.cnn import Conv2d, build_activation_layer, build_norm_layer
from mmcv.cnn.bricks.drop import build_dropout
from mmcv.cnn.bricks.transformer import MultiheadAttention
from mmengine.model import BaseModule, ModuleList, Sequential
from mmengine.model.weight_init import (constant_init, normal_init,trunc_normal_init)from mmseg.registry import MODELS
## 下面两个依赖在opencd/model/utils中可以找到
from .embed import PatchEmbed
from .shape_convert import nchw_to_nlc, nlc_to_nchwclass MixFFN(BaseModule):"""An implementation of MixFFN of Segformer.The differences between MixFFN & FFN:1. Use 1X1 Conv to replace Linear layer.2. Introduce 3X3 Conv to encode positional information.Args:embed_dims (int): The feature dimension. Same as`MultiheadAttention`. Defaults: 256.feedforward_channels (int): The hidden dimension of FFNs.Defaults: 1024.act_cfg (dict, optional): The activation config for FFNs.Default: dict(type='ReLU')ffn_drop (float, optional): Probability of an element to bezeroed in FFN. Default 0.0.dropout_layer (obj:`ConfigDict`): The dropout_layer usedwhen adding the shortcut.init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.Default: None."""def __init__(self,embed_dims,feedforward_channels,act_cfg=dict(type='GELU'),ffn_drop=0.,dropout_layer=None,init_cfg=None):super().__init__(init_cfg)self.embed_dims = embed_dimsself.feedforward_channels = feedforward_channelsself.act_cfg = act_cfgself.activate = build_activation_layer(act_cfg)in_channels = embed_dimsfc1 = Conv2d(in_channels=in_channels,out_channels=feedforward_channels,kernel_size=1,stride=1,bias=True)# 3x3 depth wise conv to provide positional encode informationpe_conv = Conv2d(in_channels=feedforward_channels,out_channels=feedforward_channels,kernel_size=3,stride=1,padding=(3 - 1) // 2,bias=True,groups=feedforward_channels)fc2 = Conv2d(in_channels=feedforward_channels,out_channels=in_channels,kernel_size=1,stride=1,bias=True)drop = nn.Dropout(ffn_drop)layers = [fc1, pe_conv, self.activate, drop, fc2, drop]self.layers = Sequential(*layers)self.dropout_layer = build_dropout(dropout_layer) if dropout_layer else torch.nn.Identity()def forward(self, x, hw_shape, identity=None):out = nlc_to_nchw(x, hw_shape)out = self.layers(out)out = nchw_to_nlc(out)if identity is None:identity = xreturn identity + self.dropout_layer(out)class EfficientMultiheadAttention(MultiheadAttention):"""An implementation of Efficient Multi-head Attention of Segformer.This module is modified from MultiheadAttention which is a module frommmcv.cnn.bricks.transformer.Args:embed_dims (int): The embedding dimension.num_heads (int): Parallel attention heads.attn_drop (float): A Dropout layer on attn_output_weights.Default: 0.0.proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.Default: 0.0.dropout_layer (obj:`ConfigDict`): The dropout_layer usedwhen adding the shortcut. Default: None.init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.Default: None.batch_first (bool): Key, Query and Value are shape of(batch, n, embed_dim)or (n, batch, embed_dim). Default: False.qkv_bias (bool): enable bias for qkv if True. Default True.norm_cfg (dict): Config dict for normalization layer.Default: dict(type='LN').sr_ratio (int): The ratio of spatial reduction of Efficient Multi-headAttention of Segformer. Default: 1."""def __init__(self,embed_dims,num_heads,attn_drop=0.,proj_drop=0.,dropout_layer=None,init_cfg=None,batch_first=True,qkv_bias=False,norm_cfg=dict(type='LN'),sr_ratio=1):super().__init__(embed_dims,num_heads,attn_drop,proj_drop,dropout_layer=dropout_layer,init_cfg=init_cfg,batch_first=batch_first,bias=qkv_bias)self.sr_ratio = sr_ratioif sr_ratio > 1:self.sr = Conv2d(in_channels=embed_dims,out_channels=embed_dims,kernel_size=sr_ratio,stride=sr_ratio)# The ret[0] of build_norm_layer is norm name.self.norm = build_norm_layer(norm_cfg, embed_dims)[1]# handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqafrom mmseg import digit_version, mmcv_versionif mmcv_version < digit_version('1.3.17'):warnings.warn('The legacy version of forward function in''EfficientMultiheadAttention is deprecated in''mmcv>=1.3.17 and will no longer support in the''future. Please upgrade your mmcv.')self.forward = self.legacy_forwarddef forward(self, x, hw_shape, identity=None):x_q = xif self.sr_ratio > 1:x_kv = nlc_to_nchw(x, hw_shape)x_kv = self.sr(x_kv)x_kv = nchw_to_nlc(x_kv)x_kv = self.norm(x_kv)else:x_kv = xif identity is None:identity = x_q# Because the dataflow('key', 'query', 'value') of# ``torch.nn.MultiheadAttention`` is (num_query, batch,# embed_dims), We should adjust the shape of dataflow from# batch_first (batch, num_query, embed_dims) to num_query_first# (num_query ,batch, embed_dims), and recover ``attn_output``# from num_query_first to batch_first.if self.batch_first:x_q = x_q.transpose(0, 1)x_kv = x_kv.transpose(0, 1)out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]if self.batch_first:out = out.transpose(0, 1)return identity + self.dropout_layer(self.proj_drop(out))def legacy_forward(self, x, hw_shape, identity=None):"""multi head attention forward in mmcv version < 1.3.17."""x_q = xif self.sr_ratio > 1:x_kv = nlc_to_nchw(x, hw_shape)x_kv = self.sr(x_kv)x_kv = nchw_to_nlc(x_kv)x_kv = self.norm(x_kv)else:x_kv = xif identity is None:identity = x_q# `need_weights=True` will let nn.MultiHeadAttention# `return attn_output, attn_output_weights.sum(dim=1) / num_heads`# The `attn_output_weights.sum(dim=1)` may cause cuda error. So, we set# `need_weights=False` to ignore `attn_output_weights.sum(dim=1)`.# This issue - `https://github.com/pytorch/pytorch/issues/37583` report# the error that large scale tensor sum operation may cause cuda error.out = self.attn(query=x_q, key=x_kv, value=x_kv, need_weights=False)[0]return identity + self.dropout_layer(self.proj_drop(out))class TransformerEncoderLayer(BaseModule):"""Implements one encoder layer in Segformer.Args:embed_dims (int): The feature dimension.num_heads (int): Parallel attention heads.feedforward_channels (int): The hidden dimension for FFNs.drop_rate (float): Probability of an element to be zeroed.after the feed forward layer. Default 0.0.attn_drop_rate (float): The drop out rate for attention layer.Default 0.0.drop_path_rate (float): stochastic depth rate. Default 0.0.qkv_bias (bool): enable bias for qkv if True.Default: True.act_cfg (dict): The activation config for FFNs.Default: dict(type='GELU').norm_cfg (dict): Config dict for normalization layer.Default: dict(type='LN').batch_first (bool): Key, Query and Value are shape of(batch, n, embed_dim)or (n, batch, embed_dim). Default: False.init_cfg (dict, optional): Initialization config dict.Default:None.sr_ratio (int): The ratio of spatial reduction of Efficient Multi-headAttention of Segformer. Default: 1.with_cp (bool): Use checkpoint or not. Using checkpoint will savesome memory while slowing down the training speed. Default: False."""def __init__(self,embed_dims,num_heads,feedforward_channels,drop_rate=0.,attn_drop_rate=0.,drop_path_rate=0.,qkv_bias=True,act_cfg=dict(type='GELU'),norm_cfg=dict(type='LN'),batch_first=True,sr_ratio=1,with_cp=False):super().__init__()# The ret[0] of build_norm_layer is norm name.self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]self.attn = EfficientMultiheadAttention(embed_dims=embed_dims,num_heads=num_heads,attn_drop=attn_drop_rate,proj_drop=drop_rate,dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),batch_first=batch_first,qkv_bias=qkv_bias,norm_cfg=norm_cfg,sr_ratio=sr_ratio)# The ret[0] of build_norm_layer is norm name.self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]self.ffn = MixFFN(embed_dims=embed_dims,feedforward_channels=feedforward_channels,ffn_drop=drop_rate,dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),act_cfg=act_cfg)self.with_cp = with_cpdef forward(self, x, hw_shape):def _inner_forward(x):x = self.attn(self.norm1(x), hw_shape, identity=x)x = self.ffn(self.norm2(x), hw_shape, identity=x)return xif self.with_cp and x.requires_grad:x = cp.checkpoint(_inner_forward, x)else:x = _inner_forward(x)return x# @MODELS.register_module()
class MixVisionTransformer(BaseModule):"""The backbone of Segformer.This backbone is the implementation of `SegFormer: Simple andEfficient Design for Semantic Segmentation withTransformers <https://arxiv.org/abs/2105.15203>`_.Args:in_channels (int): Number of input channels. Default: 3.embed_dims (int): Embedding dimension. Default: 768.num_stags (int): The num of stages. Default: 4.num_layers (Sequence[int]): The layer number of each transformer encodelayer. Default: [3, 4, 6, 3].num_heads (Sequence[int]): The attention heads of each transformerencode layer. Default: [1, 2, 4, 8].patch_sizes (Sequence[int]): The patch_size of each overlapped patchembedding. Default: [7, 3, 3, 3].strides (Sequence[int]): The stride of each overlapped patch embedding.Default: [4, 2, 2, 2].sr_ratios (Sequence[int]): The spatial reduction rate of eachtransformer encode layer. Default: [8, 4, 2, 1].out_indices (Sequence[int] | int): Output from which stages.Default: (0, 1, 2, 3).mlp_ratio (int): ratio of mlp hidden dim to embedding dim.Default: 4.qkv_bias (bool): Enable bias for qkv if True. Default: True.drop_rate (float): Probability of an element to be zeroed.Default 0.0attn_drop_rate (float): The drop out rate for attention layer.Default 0.0drop_path_rate (float): stochastic depth rate. Default 0.0norm_cfg (dict): Config dict for normalization layer.Default: dict(type='LN')act_cfg (dict): The activation config for FFNs.Default: dict(type='GELU').pretrained (str, optional): model pretrained path. Default: None.init_cfg (dict or list[dict], optional): Initialization config dict.Default: None.with_cp (bool): Use checkpoint or not. Using checkpoint will savesome memory while slowing down the training speed. Default: False."""def __init__(self,in_channels=3,embed_dims=64,num_stages=4,num_layers=[3, 4, 6, 3],num_heads=[1, 2, 4, 8],patch_sizes=[7, 3, 3, 3],strides=[4, 2, 2, 2],sr_ratios=[8, 4, 2, 1],out_indices=(0, 1, 2, 3),mlp_ratio=4,qkv_bias=True,drop_rate=0.,attn_drop_rate=0.,drop_path_rate=0.,act_cfg=dict(type='GELU'),norm_cfg=dict(type='LN', eps=1e-6),pretrained=None,init_cfg=None,with_cp=False):super().__init__(init_cfg=init_cfg)assert not (init_cfg and pretrained), \'init_cfg and pretrained cannot be set at the same time'if isinstance(pretrained, str):warnings.warn('DeprecationWarning: pretrained is deprecated, ''please use "init_cfg" instead')self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)elif pretrained is not None:raise TypeError('pretrained must be a str or None')self.embed_dims = embed_dimsself.num_stages = num_stagesself.num_layers = num_layersself.num_heads = num_headsself.patch_sizes = patch_sizesself.strides = stridesself.sr_ratios = sr_ratiosself.with_cp = with_cpassert num_stages == len(num_layers) == len(num_heads) \== len(patch_sizes) == len(strides) == len(sr_ratios)self.out_indices = out_indicesassert max(out_indices) < self.num_stages# transformer encoderdpr = [x.item()for x in torch.linspace(0, drop_path_rate, sum(num_layers))] # stochastic num_layer decay rulecur = 0self.layers = ModuleList()for i, num_layer in enumerate(num_layers):embed_dims_i = embed_dims * num_heads[i]patch_embed = PatchEmbed(in_channels=in_channels,embed_dims=embed_dims_i,kernel_size=patch_sizes[i],stride=strides[i],padding=patch_sizes[i] // 2,norm_cfg=norm_cfg)layer = ModuleList([TransformerEncoderLayer(embed_dims=embed_dims_i,num_heads=num_heads[i],feedforward_channels=mlp_ratio * embed_dims_i,drop_rate=drop_rate,attn_drop_rate=attn_drop_rate,drop_path_rate=dpr[cur + idx],qkv_bias=qkv_bias,act_cfg=act_cfg,norm_cfg=norm_cfg,with_cp=with_cp,sr_ratio=sr_ratios[i]) for idx in range(num_layer)])in_channels = embed_dims_i# The ret[0] of build_norm_layer is norm name.norm = build_norm_layer(norm_cfg, embed_dims_i)[1]self.layers.append(ModuleList([patch_embed, layer, norm]))cur += num_layerdef init_weights(self):if self.init_cfg is None:for m in self.modules():if isinstance(m, nn.Linear):trunc_normal_init(m, std=.02, bias=0.)elif isinstance(m, nn.LayerNorm):constant_init(m, val=1.0, bias=0.)elif isinstance(m, nn.Conv2d):fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsfan_out //= m.groupsnormal_init(m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)else:super().init_weights()def forward(self, x):outs = []for i, layer in enumerate(self.layers):x, hw_shape = layer[0](x)for block in layer[1]:x = block(x, hw_shape)x = layer[2](x)x = nlc_to_nchw(x, hw_shape)if i in self.out_indices:outs.append(x)return outs1.1 主干网络类
from torch import nn
from CDmodel.ly_utils.MixVisionTransformer import MixVisionTransformerclass backbone(nn.Module):def __init__(self):super(backbone,self).__init__()self.model = MixVisionTransformer(in_channels=3,embed_dims=32,num_stages=4,num_layers=[2, 2, 2, 2],num_heads=[1, 2, 5, 8],patch_sizes=[7, 3, 3, 3],sr_ratios=[8, 4, 2, 1],out_indices=(0, 1, 2, 3),mlp_ratio=4,qkv_bias=True,drop_rate=0.0,attn_drop_rate=0.0,drop_path_rate=0.1)def forward(self,x1):return self.model.forward(x1)
2.neck
# Copyright (c) Open-CD. All rights reserved.
import torch
from torch import nn
from opencd.registry import MODELSclass FeatureFusionNeck(nn.Module):"""Feature Fusion Neck.Args:policy (str): The operation to fuse features. candidatesare `concat`, `sum`, `diff` and `Lp_distance`.in_channels (Sequence(int)): Input channels.channels (int): Channels after modules, before conv_seg.out_indices (tuple[int]): Output from which layer."""def __init__(self,policy = 'concat',in_channels=None,channels=None,out_indices=(0, 1, 2, 3)):super(FeatureFusionNeck,self).__init__()self.policy = policyself.in_channels = in_channelsself.channels = channelsself.out_indices = out_indices@staticmethoddef fusion(x1, x2, policy):"""Specify the form of feature fusion"""_fusion_policies = ['concat', 'sum', 'diff', 'abs_diff']assert policy in _fusion_policies, 'The fusion policies {} are ' \'supported'.format(_fusion_policies)if policy == 'concat':x = torch.cat([x1, x2], dim=1)elif policy == 'sum':x = x1 + x2elif policy == 'diff':x = x2 - x1elif policy == 'abs_diff':x = torch.abs(x1 - x2)return xdef forward(self, x1, x2):"""Forward function."""assert len(x1) == len(x2), "The features x1 and x2 from the" \"backbone should be of equal length"outs = []for i in range(len(x1)):out = self.fusion(x1[i], x2[i], self.policy)outs.append(out)outs = [outs[i] for i in self.out_indices]return tuple(outs)
2.Decoder
changerformer解码头采用的是’mmseg.SegformerHead’
这个得在mmsegmentation/mmseg/model/head里面找
找到后,删除损失函数、预测推理保留下面部分内容
# Copyright (c) OpenMMLab. All rights reserved.
import warnings
from abc import ABCMeta, abstractmethod
from typing import List, Tuple
from mmcv.cnn import ConvModule
import torch
import torch.nn as nn
from mmengine.model import BaseModule
from torch import Tensorfrom mmseg.registry import MODELS
from mmseg.structures import build_pixel_sampler
from mmseg.utils import ConfigType, SampleList
# from ..losses import accuracy
from layer.resize import resizeclass BaseDecodeHead(nn.Module):"""Base class for BaseDecodeHead.1. The ``init_weights`` method is used to initialize decode_head'smodel parameters. After segmentor initialization, ``init_weights``is triggered when ``segmentor.init_weights()`` is called externally.2. The ``loss`` method is used to calculate the loss of decode_head,which includes two steps: (1) the decode_head model performs forwardpropagation to obtain the feature maps (2) The ``loss_by_feat`` methodis called based on the feature maps to calculate the loss... code:: textloss(): forward() -> loss_by_feat()3. The ``predict`` method is used to predict segmentation results,which includes two steps: (1) the decode_head model performs forwardpropagation to obtain the feature maps (2) The ``predict_by_feat`` methodis called based on the feature maps to predict segmentation resultsincluding post-processing... code:: textpredict(): forward() -> predict_by_feat()Args:in_channels (int|Sequence[int]): Input channels.channels (int): Channels after modules, before conv_seg.num_classes (int): Number of classes.out_channels (int): Output channels of conv_seg. Default: None.threshold (float): Threshold for binary segmentation in the case of`num_classes==1`. Default: None.dropout_ratio (float): Ratio of dropout layer. Default: 0.1.conv_cfg (dict|None): Config of conv layers. Default: None.norm_cfg (dict|None): Config of norm layers. Default: None.act_cfg (dict): Config of activation layers.Default: dict(type='ReLU')in_index (int|Sequence[int]): Input feature index. Default: -1ignore_index (int | None): The label index to be ignored. When usingmasked BCE loss, ignore_index should be set to None. Default: 255.align_corners (bool): align_corners argument of F.interpolate.Default: False.The all mlp Head of segformer.This head is the implementation of`Segformer <https://arxiv.org/abs/2105.15203>` _.Args:interpolate_mode: The interpolate mode of MLP head upsample operation.Default: 'bilinear'."""def __init__(self,in_channels = [v * 2 for v in [32, 64, 160, 256]],channels = 256,num_classes = 2,out_channels=None,threshold=None,dropout_ratio=0.1,conv_cfg=None,norm_cfg=dict(type='SyncBN', requires_grad=True),act_cfg=dict(type='ReLU'),in_index=[0, 1, 2, 3],input_transform='multiple_select',ignore_index=255,interpolate_mode='bilinear',align_corners=False,):super(BaseDecodeHead,self).__init__()# self._init_inputs(in_channels, in_index, input_transform)self.in_channels = in_channelsself.channels = channelsself.dropout_ratio = dropout_ratioself.conv_cfg = conv_cfgself.norm_cfg = norm_cfgself.act_cfg = act_cfgself.in_index = in_indexself.input_transform = input_transformself.ignore_index = ignore_indexself.align_corners = align_cornersself.interpolate_mode = interpolate_modenum_inputs = len(self.in_channels)assert num_inputs == len(self.in_index)self.convs = nn.ModuleList()self.convs = nn.ModuleList()for i in range(num_inputs):self.convs.append(ConvModule(in_channels=self.in_channels[i],out_channels=self.channels,kernel_size=1,stride=1,norm_cfg=self.norm_cfg,act_cfg=self.act_cfg))self.fusion_conv = ConvModule(in_channels=self.channels * num_inputs,out_channels=self.channels,kernel_size=1,norm_cfg=self.norm_cfg)if out_channels is None:if num_classes == 2:warnings.warn('For binary segmentation, we suggest using''`out_channels = 1` to define the output''channels of segmentor, and use `threshold`''to convert `seg_logits` into a prediction''applying a threshold')out_channels = num_classesif out_channels != num_classes and out_channels != 1:raise ValueError('out_channels should be equal to num_classes,''except binary segmentation set out_channels == 1 and'f'num_classes == 2, but got out_channels={out_channels}'f'and num_classes={num_classes}')if out_channels == 1 and threshold is None:threshold = 0.3warnings.warn('threshold is not defined for binary, and defaults''to 0.3')self.num_classes = num_classesself.out_channels = out_channelsself.threshold = thresholdself.conv_seg = nn.Conv2d(channels, self.out_channels, kernel_size=1)if dropout_ratio > 0:self.dropout = nn.Dropout2d(dropout_ratio)else:self.dropout = Nonedef _transform_inputs(self, inputs):"""Transform inputs for decoder.Args:inputs (list[Tensor]): List of multi-level img features.Returns:Tensor: The transformed inputs"""if self.input_transform == 'resize_concat':inputs = [inputs[i] for i in self.in_index]upsampled_inputs = [resize(input=x,size=inputs[0].shape[2:],mode='bilinear',align_corners=self.align_corners) for x in inputs]inputs = torch.cat(upsampled_inputs, dim=1)elif self.input_transform == 'multiple_select':inputs = [inputs[i] for i in self.in_index]else:inputs = inputs[self.in_index]return inputs@abstractmethoddef forward(self, inputs):"""Placeholder of forward function."""# Receive 4 stage backbone feature map: 1/4, 1/8, 1/16, 1/32inputs = self._transform_inputs(inputs)outs = []for idx in range(len(inputs)):x = inputs[idx]conv = self.convs[idx]outs.append(resize(input=conv(x),size=inputs[0].shape[2:],mode=self.interpolate_mode,align_corners=self.align_corners))out = self.fusion_conv(torch.cat(outs, dim=1))out = self.cls_seg(out)return outdef cls_seg(self, feat):"""Classify each pixel."""if self.dropout is not None:feat = self.dropout(feat)output = self.conv_seg(feat)return output3.测试模型
import torch
from torch import nn
# from torchsummary import summary
from torchinfo import summaryfrom backbone1 import backbone
from neck import FeatureFusionNeck
from head import BaseDecodeHeadclass siamencoderdecoder(nn.Module):def __init__(self):super(siamencoderdecoder, self).__init__()self.backbone = backbone()# self.backbone2 = backbone()self.neck = FeatureFusionNeck()self.head = BaseDecodeHead()def backboneforward(self,x1,x2):# 孪生主干网络特征提取x1,x2 = self.backbone(x1),self.backbone(x2)return x1,x2def forward(self,x1,x2):x1,x2 = self.backboneforward(x1,x2)x = self.neck(x1,x2)logit = self.head(x)return logitif __name__ == "__main__":inputs = torch.rand(3, 224, 224)model = siamencoderdecoder()device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)summary(model,input_size=[(1,3,256,256),(1,3,256,256)])summary
========================================================================================================================
Layer (type:depth-idx) Output Shape Param #
========================================================================================================================
siamencoderdecoder [1, 2, 64, 64] --
├─backbone: 1-1 -- (recursive)
│ └─MixVisionTransformer: 2-2 -- (recursive)
│ │ └─ModuleList: 3-2 -- (recursive)
├─backbone: 1-2 [1, 32, 64, 64] 3,319,392
│ └─MixVisionTransformer: 2-2 -- (recursive)
│ │ └─ModuleList: 3-2 -- (recursive)
├─FeatureFusionNeck: 1-3 [1, 64, 64, 64] --
├─BaseDecodeHead: 1-4 [1, 2, 64, 64] --
│ └─ModuleList: 2-3 -- --
│ │ └─ConvModule: 3-3 [1, 256, 64, 64] 16,896
│ │ └─ConvModule: 3-4 [1, 256, 32, 32] 33,280
│ │ └─ConvModule: 3-5 [1, 256, 16, 16] 82,432
│ │ └─ConvModule: 3-6 [1, 256, 8, 8] 131,584
│ └─ConvModule: 2-4 [1, 256, 64, 64] --
│ │ └─Conv2d: 3-7 [1, 256, 64, 64] 262,144
│ │ └─SyncBatchNorm: 3-8 [1, 256, 64, 64] 512
│ │ └─ReLU: 3-9 [1, 256, 64, 64] --
│ └─Dropout2d: 2-5 [1, 256, 64, 64] --
│ └─Conv2d: 2-6 [1, 2, 64, 64] 514
========================================================================================================================
Total params: 7,166,146
Trainable params: 7,166,146
Non-trainable params: 0
Total mult-adds (G): 2.09
========================================================================================================================
Input size (MB): 1.57
Forward/backward pass size (MB): 141.75
Params size (MB): 12.29
Estimated Total Size (MB): 155.62
========================================================================================================================Process finished with exit code 0
6. changer主干网络
opencd作者提了一个主干网络特征交换的idea,通过继承ResNet实现的网络结构,并在主网络中给出了使用实例:
Example:
# >>> from opencd.models import IA_ResNet
# >>> import torch
# >>> self = IA_ResNet(depth=18)
# >>> self.eval()
# >>> inputs = torch.rand(1, 3, 32, 32)
# >>> level_outputs = self.forward(inputs, inputs)
# >>> for level_out in level_outputs:
# … print(tuple(level_out.shape))
(1, 128, 8, 8)
(1, 256, 4, 4)
(1, 512, 2, 2)
(1, 1024, 1, 1)
“”"
# Copyright (c) Open-CD. All rights reserved.
import torch
import torch.nn as nnfrom mmseg.models.backbones import ResNet
from opencd.registry import MODELS# @MODELS.register_module()
class IA_ResNet(ResNet):"""Interaction ResNet backbone.Args:interaction_cfg (Sequence[dict]): Interaction strategies for the stages.The length should be the same as `num_stages`. The details can befound in `opencd/models/ly_utils/interaction_layer.py`.Default: (None, None, None, None).depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.in_channels (int): Number of input image channels. Default: 3.stem_channels (int): Number of stem channels. Default: 64.base_channels (int): Number of base channels of res layer. Default: 64.num_stages (int): Resnet stages, normally 4. Default: 4.strides (Sequence[int]): Strides of the first block of each stage.Default: (1, 2, 2, 2).dilations (Sequence[int]): Dilation of each stage.Default: (1, 1, 1, 1).out_indices (Sequence[int]): Output from which stages.Default: (0, 1, 2, 3).style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-twolayer is the 3x3 conv layer, otherwise the stride-two layer isthe first 1x1 conv layer. Default: 'pytorch'.deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.Default: False.avg_down (bool): Use AvgPool instead of stride conv whendownsampling in the bottleneck. Default: False.frozen_stages (int): Stages to be frozen (stop grad and set eval mode).-1 means not freezing any parameters. Default: -1.conv_cfg (dict | None): Dictionary to construct and config conv layer.When conv_cfg is None, cfg will be set to dict(type='Conv2d').Default: None.norm_cfg (dict): Dictionary to construct and config norm layer.Default: dict(type='BN', requires_grad=True).norm_eval (bool): Whether to set norm layers to eval mode, namely,freeze running stats (mean and var). Note: Effect on Batch Normand its variants only. Default: False.dcn (dict | None): Dictionary to construct and config DCN conv layer.When dcn is not None, conv_cfg must be None. Default: None.stage_with_dcn (Sequence[bool]): Whether to set DCN conv for eachstage. The length of stage_with_dcn is equal to num_stages.Default: (False, False, False, False).plugins (list[dict]): List of plugins for stages, each dict contains:- cfg (dict, required): Cfg dict to build plugin.- position (str, required): Position inside block to insert plugin,options: 'after_conv1', 'after_conv2', 'after_conv3'.- stages (tuple[bool], optional): Stages to apply plugin, lengthshould be same as 'num_stages'.Default: None.multi_grid (Sequence[int]|None): Multi grid dilation rates of laststage. Default: None.contract_dilation (bool): Whether contract first dilation of each layerDefault: False.with_cp (bool): Use checkpoint or not. Using checkpoint will save somememory while slowing down the training speed. Default: False.zero_init_residual (bool): Whether to use zero init for last norm layerin resblocks to let them behave as identity. Default: True.pretrained (str, optional): model pretrained path. Default: None.init_cfg (dict or list[dict], optional): Initialization config dict.Default: None.Example:# >>> from opencd.models import IA_ResNet# >>> import torch# >>> self = IA_ResNet(depth=18)# >>> self.eval()# >>> inputs = torch.rand(1, 3, 32, 32)# >>> level_outputs = self.forward(inputs, inputs)# >>> for level_out in level_outputs:# ... print(tuple(level_out.shape))(1, 128, 8, 8)(1, 256, 4, 4)(1, 512, 2, 2)(1, 1024, 1, 1)"""def __init__(self,interaction_cfg=(None, None, None, None),**kwargs):super().__init__(**kwargs)assert self.num_stages == len(interaction_cfg), \'The length of the `interaction_cfg` should be same as the `num_stages`.'# cross-correlationself.ccs = []for ia_cfg in interaction_cfg:if ia_cfg is None:ia_cfg = dict(type='TwoIdentity')self.ccs.append(MODELS.build(ia_cfg))self.ccs = nn.ModuleList(self.ccs)def forward(self, x1, x2):"""Forward function."""def _stem_forward(x):if self.deep_stem:x = self.stem(x)else:x = self.conv1(x)x = self.norm1(x)x = self.relu(x)x = self.maxpool(x)return xx1 = _stem_forward(x1)x2 = _stem_forward(x2)outs = []for i, layer_name in enumerate(self.res_layers):res_layer = getattr(self, layer_name)x1 = res_layer(x1)x2 = res_layer(x2)x1, x2 = self.ccs[i](x1, x2)if i in self.out_indices:outs.append(torch.cat([x1, x2], dim=1))return tuple(outs)# @MODELS.register_module()
class IA_ResNetV1c(IA_ResNet):"""ResNetV1c variant described in [1]_.Compared with default ResNet(ResNetV1b), ResNetV1c replaces the 7x7 conv inthe input stem with three 3x3 convs. For more details please refer to `Bagof Tricks for Image Classification with Convolutional Neural Networks<https://arxiv.org/abs/1812.01187>`_."""def __init__(self, **kwargs):super(IA_ResNetV1c, self).__init__(deep_stem=True, avg_down=False, **kwargs)# @MODELS.register_module()
class IA_ResNetV1d(IA_ResNet):"""ResNetV1d variant described in [1]_.Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv inthe input stem with three 3x3 convs. And in the downsampling block, a 2x2avg_pool with stride 2 is added before conv, whose stride is changed to 1."""def __init__(self, **kwargs):super(IA_ResNetV1d, self).__init__(deep_stem=True, avg_down=True, **kwargs)
下面在上述环境下我们来调用一下
import torch
from IA_ResNet import IA_ResNetV1c
backbone = IA_ResNetV1c(depth=18)
backbone.eval()
inputs = torch.rand(1, 3, 256, 256)
level_outputs = backbone.forward(inputs, inputs)
for level_out in level_outputs:print(tuple(level_out.shape))
# output:
(1, 128, 64, 64)
(1, 256, 32, 32)
(1, 512, 16, 16)
(1, 1024, 8, 8)
总结
通过上述内容,我们可以根据参数文件中的内容提取opencd中任意网络结构,或采用timm来设置主干网络结构,或添加到自己的训练框架中如pytorch_segmentation中进行训练。相应的,我们可以进一步去学习mmalb的框架结构
相关文章:
open-cd中的changerformer网络结构分析
open-cd 目录 open-cd1.安装2.源码结构分析主干网络1.1 主干网络类2.neck2.Decoder3.测试模型6. changer主干网络 总结 该开源库基于: mmcv mmseg mmdet mmengine 1.安装 在安装过程中遇到的问题: 1.pytorch版本问题,open-cd采用的mmcv版本比…...
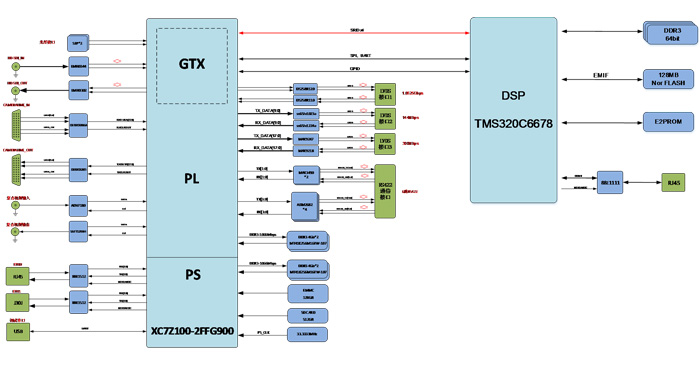
太速科技-426-基于XC7Z100+TMS320C6678的图像处理板卡
基于XC7Z100TMS320C6678的图像处理板卡 一、板卡概述 板卡基于独立的结构,实现ZYNQ XC7Z100DSP TMS320C6678的多路图像输入输出接口的综合图像处理,包含1路Camera link输入输出、1路HD-SDI输入输出、1路复合视频输入输出、2路光纤等视频接口,…...

asp.net Core 自定义中间件
内联中间件 中间件转移到类中 推荐中间件通过IApplicationBuilder 公开中间件 使用扩展方法 调用中间件 含有依赖项的 》》》中间件 参考资料...

掌握 C# 设计模式:从基础到依赖注入
设计模式是一种可以在开发中重复使用的解决方案,能够提高代码的可维护性、扩展性和复用性。C# 中常见的设计模式包括单例模式、工厂模式、观察者模式、策略模式等。本文将介绍这些常见的设计模式,并探讨 SOLID 原则和依赖注入(Dependency Inj…...

根据json转HttpClient脚本
String json “{\n” " “paths”: {\n" " “/dev-api/system/subjectResult/exportUserList”: {\n" " “post”: {\n" " “tags”: [\n" " “bd-subject-result-controller”\n" " ],\n" " “summ…...
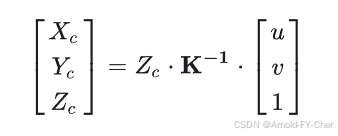
如何将LiDAR坐标系下的3D点投影到相机2D图像上
将激光雷达点云投影到相机图像上做数据层的前融合,或者把激光雷达坐标系下标注的物体点云的3d bbox投影到相机图像上画出来,都需要做点云3D点坐标到图像像素坐标的转换计算,也就是LiDAR 3D坐标转像素坐标。 看了网上一些文章都存在有错误或者…...

JAVA就业笔记6——第二阶段(3)
课程须知 A类知识:工作和面试常用,代码必须要手敲,需要掌握。 B类知识:面试会问道,工作不常用,代码不需要手敲,理解能正确表达即可。 C类知识:工作和面试不常用,代码不…...

02.04、分割链表
02.04、[中等] 分割链表 1、题目描述 给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你不需要 保留 每个分区中各节点的初始相对位置。 2、解题思路 本题要求将链表分隔…...

Excel 中根据患者的就诊时间标记病例为“初诊”或“复诊”
1. 假设: 患者表:包含患者的基本信息,如患者 ID 和患者姓名。 病例表:包含病例信息,如患者 ID、就诊时间和就诊状态。 2. 操作步骤: 合并数据: 确保病例表中有一列包含患者 ID,以…...

遇到“mfc100u.dll丢失”的系统错误要怎么处理?科学修复mfc100u.dll
遇到“mfc100u.dll丢失”的系统错误会非常麻烦,因为mfc100u.dll是Microsoft Visual C 2010 Redistributable Package的重要部分,许多应用程序和游戏在运行时都需要调用这个文件。如果这个文件缺失,可能会导致相关软件或游戏启动失败。面对这种…...

[Linux] 逐层深入理解文件系统 (1)—— 进程操作文件
标题:[Linux] 文件系统 (1)—— 进程操作文件 个人主页水墨不写bug (图片来源于网络) 目录 一、进程与打开的文件 二、文件的系统调用与库函数的关系 1.系统调用open() 三、内存中的文件描述符表 四、缓冲区…...

RT-Thread 互斥量的概念
目录 概述 1 互斥量定义 1.1 概念介绍 1.2 线程优先级翻转问题 2 互斥量管理 2.1 结构体定义 2.2 函数接口介绍 2.2.1 rt_mutex_create函数 2.2.2 rt_mutex_delete 函数 2.2.3 初始化和脱离互斥量 概述 本文主要介绍互斥量的概念,实现原理。还介绍RT-Thre…...

6.计算机网络_UDP
UDP的主要特点: 无连接,发送数据之前不需要建立连接。不保证可靠交付。面向报文。应用层给UDP报文后,UDP并不会抽象为一个一个的字节,而是整个报文一起发送。没有拥塞控制。网络拥堵时,发送端并不会降低发送速率。可以…...

Windows应急响蓝安服面试
Windows应急响应 蓝队溯源流程 学习Windows应急首先要站在攻击者的角度去学习一些权限维持和权限提升的方法.,文章中的方法其实和内网攻防笔记有类似l红队教你怎么利用 蓝队教你怎么排查 攻防一体,应急响应排查这些项目就可以 端口/服务/进程/后门文件都是为了权限维持,得到s…...

PCL 点云配准-4PCS算法(粗配准)
目录 一、概述 1.1原理 1.2实现步骤 1.3应用场景 二、代码实现 2.1关键函数 2.1.1 加载点云数据 2.1.2 执行4PCS粗配准 2.1.3 可视化源点云、目标点云和配准结果 2.2完整代码 三、实现效果 3.1原始点云 3.2配准后点云 PCL点云算法汇总及实战案例汇总的目录地址链接…...

12、论文阅读:利用生成对抗网络实现无监督深度图像增强
Towards Unsupervised Deep Image Enhancement With Generative Adversarial Network 摘要介绍相关工作传统图像增强基于学习的图像增强 论文中提出的方法动机和目标网络架构损失函数1) 质量损失2) 保真损失3)身份损失4)Total Loss 实验 摘要 提高图像的…...

Axure重要元件三——中继器表单制作
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 本节课:中继器表单制作 课程内容:利用中继器制作表单 应用场景:台账、表单 案例展示: 步骤一:建立一个背景区…...

DMAIC赋能智能家居:解锁未来生活新篇章!
从清晨自动拉开的窗帘,到夜晚自动调暗的灯光,每一处细节都透露着科技的温度与智慧的光芒。而在这场智能革命的浪潮中,DMAIC(定义Define、测量Measure、分析Analyze、改进Improve、控制Control)作为六西格玛管理的核心方…...

代码随想录算法训练营第二天| 209.长度最小的子数组 59.螺旋矩阵II 区间和 开发商购买土地
209. 长度最小的子数组 题目: 给定一个包含正整数的数组 nums 和一个正整数 target ,找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 ,并返回其长度。如果不存在符合条件的子数组,返回 0。 示例: 示例 1…...

mysql隐藏索引
1. 什么是隐藏索引? 在 MySQL 8 中,隐藏索引(Invisible Indexes)是指一种特殊类型的索引,它并不真正被删除,而是被标记为“不可见”。当索引被标记为不可见时,查询优化器在生成查询计划时将忽略…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

Charles弱网测试六维参数实战:从丢包率到DNS延迟的精准复现
1. 为什么弱网测试不能只靠“模拟3G”按钮点一下就完事做移动端或Web前端的同学,大概率都听过这句话:“上线前跑一遍Charles,切个2G网络测下加载。”——听起来很专业,实际一查日志,发现90%的团队连Charles的Throttlin…...

GetStoreApp核心功能解析:离线部署Microsoft Store应用的5大优势
GetStoreApp核心功能解析:离线部署Microsoft Store应用的5大优势 【免费下载链接】GetStoreApp 离线下载 Microsoft Store 商店应用 项目地址: https://gitcode.com/gh_mirrors/ge/GetStoreApp GetStoreApp是一款专为Windows用户设计的离线下载工具ÿ…...

10分钟掌握D3KeyHelper:告别手酸,暗黑3游戏效率翻倍的终极指南
10分钟掌握D3KeyHelper:告别手酸,暗黑3游戏效率翻倍的终极指南 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗…...