Elasticsearch字段数据类型
1. 前言
ES文档的每个字段都至少有一个数据类型,此类型决定了字段值如何被存储以及检索。例如,字符串类型可以定义为text或者keyword,前者用于全文检索,会经过分词后索引;后者用于精准匹配,值会保持原样被索引。
ES字段类型按族分组,同一族中的类型具有完全相同的搜索行为,但可能具有不同的空间使用或性能特征。
2. 基本数据类型
2.1 binary
二进制数据类型,接受以Base64编码的二进制数据作为输入,默认不可索引和搜索。
// 创建索引
PUT files
{"mappings": {"properties": {"title":{"type": "text"},"blob":{"type": "binary"}}}
}
// 索引文档
POST files/_doc
{"title":"hello.txt","blob":"aGVsbG8gd29ybGQ="
}
//获取文档
GET files/_search{"took": 30,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "files","_id": "7-tinY4BODFb3LbQRHQD","_score": 1,"_source": {"title": "hello.txt","blob": "aGVsbG8gd29ybGQ="}}]}
}
二进制数据类型字段不会被索引,固无法被搜索,否则会报错
{"error": {"root_cause": [{"type": "query_shard_exception","reason": "failed to create query: Binary fields do not support searching","index_uuid": "IM89dUaXTuqYCgnmMlb9VQ","index": "files"}],"type": "search_phase_execution_exception","reason": "all shards failed","phase": "query","grouped": true,"failed_shards": [{"shard": 0,"index": "files","node": "X6yldsn_RMuokM0m_Q5Z1g","reason": {"type": "query_shard_exception","reason": "failed to create query: Binary fields do not support searching","index_uuid": "IM89dUaXTuqYCgnmMlb9VQ","index": "files","caused_by": {"type": "illegal_argument_exception","reason": "Binary fields do not support searching"}}}]},"status": 400
}
2.2 boolean
布尔类型,接受JSON的 true 或 false值,也可以接受对应字符串格式作为输入。
PUT users
{"mappings": {"properties": {"name":{"type": "keyword"},"deleted":{"type": "boolean"}}}
}POST users/_doc
{"name":"Lisa","deleted":false
}
2.3 Keywords
关键字类型族,包括:keyword、constant_keyword和wildcard。
2.3.1 keyword
关键字类型,用于存储结构化内容,如id、电子邮件地址、主机名、状态码、邮政编码或标签。用于精准匹配、聚合、以及排序。
PUT users
{"mappings": {"properties": {"user_id":{"type": "keyword"}}}
}
2.3.2 constant_keyword
常量关键字类型,它的目的是让文档中的字段具有相同的值,什么意思呢?
举个例子,创建一个logs索引,其中level字段定义为constant_keyword类型,值是”debug“
PUT logs
{"mappings": {"properties": {"content":{"type": "text"},"level":{"type": "constant_keyword","value":"debug"}}}
}
下面两个索引请求是等价的,level最终都是“debug”
POST logs/_doc
{"content":"haha","level":"debug"
}POST logs/_doc
{"content":"haha"
}
但是,如果索引一个非法的level值,就会得到一个异常
POST logs/_doc
{"content":"haha","level":"info"
}{"error": {"root_cause": [{"type": "document_parsing_exception","reason": "[3:11] failed to parse field [level] of type [constant_keyword] in document with id '9ut5nY4BODFb3LbQtHRG'. Preview of field's value: 'info'"}],"type": "document_parsing_exception","reason": "[3:11] failed to parse field [level] of type [constant_keyword] in document with id '9ut5nY4BODFb3LbQtHRG'. Preview of field's value: 'info'","caused_by": {"type": "illegal_argument_exception","reason": "[constant_keyword] field [level] only accepts values that are equal to the value defined in the mappings [debug], but got [info]"}},"status": 400
}
总结一下,constant_keyword目的是让索引内的文档字段具有相同的值,如果映射没有定义默认值,则以第一个索引到的不为空的字段值作为默认值,如果再索引到不同的值,ES会抛出异常。
2.3.3 wildcard
通配符字段类型,可以在字符串中实现通配符的模式查找。
如下示例,创建books索引并索引文档
PUT books
{"mappings": {"properties": {"title":{"type": "wildcard"}}}
}POST books/_doc
{"title":"C语言程序设计"
}
使用通配符查找书名
GET books/_search
{"query": {"wildcard": {"title": {"value": "*语言*设计"}}}
}{"took": 11,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "books","_id": "9-uInY4BODFb3LbQW3Sn","_score": 1,"_source": {"title": "C语言程序设计"}}]}
}
2.4 Numbers
数字类型族,包括:long、integer、short、byte、double、float、half_float、scaled_float、unsigned_long。
除了整型和浮点数的区别外,其它就是长度不一样导致表示的数值范围不同。在数据类型的选择上,建议在满足需求的基础上选择占用空间最小的数据类型以节省存储空间和检索性能。
2.5 Dates
日期类型,包括:date和date_nanos。因为JSON并没有日期类型,所以ES可以接收的日期输入是:格式化的日期字符串和时间戳。
2.5.1 date
日期类型,可以通过format指定日期的格式。如下示例,接受格式化的日期字符串或时间戳作为输入值
PUT dates
{"mappings": {"properties": {"date":{"type": "date","format": "yyyy-MM-dd HH:mm:ss||epoch_millis"}}}
}
以下两种索引请求均支持
POST dates/_doc
{"date":"2024-01-01 00:00:00"
}POST dates/_doc
{"date":1618321898000
}
2.5.2 date_nanos
纳秒级的时间类型,是对日期数据类型的补充。区别是:date使用毫秒精度存储日期、date_nanos使用纳秒精度存储日期,date_nanos日期范围被限制在大约1970到2262之间,它存储的是自epoch依赖的纳秒时长。
如下示例,接收格式化的日期字符串或时间戳作为输入
PUT date-nanos
{"mappings": {"properties": {"date_nanos":{"type": "date_nanos","format": "strict_date_optional_time_nanos||epoch_millis"}}}
}
索引文档请求
POST date-nanos/_doc
{"date_nanos":"2024-01-01T12:00:00.123456789Z"
}
2.6 alias
别名类型,它可以用来给索引中的字段定义别名。
如下示例,我们给field_a定义一个别名字段
PUT alias-index
{"mappings": {"properties": {"field_a":{"type": "keyword"},"field_a_alias":{"type": "alias","path":"field_a"}}}
}
如此一来,下面两个搜索请求是等价的:
GET alias-index/_search
{"query": {"term": {"field_a": {"value": "haha"}}}
}GET alias-index/_search
{"query": {"term": {"field_a_alias": {"value": "haha"}}}
}
3. 对象和关系类型
3.1 object
JSON文档是分层的,文档可能还会包含内部对象,如下索引文档请求示例:
POST users/_doc
{"name":"张三","address":{"province":"浙江省","city":"杭州市"}
}
在ES内部,该文档会被索引为简单的键值对列表:
{"name":"张三","address.province":"浙江省","address.city":"杭州市"
}
索引映射看起来是下面这样的,address包含province和city两个子字段,address并没有显式的指定type=object,这是默认值。
{"users": {"mappings": {"properties": {"address": {"properties": {"city": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"province": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}},"name": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}
}
3.2 flattened
默认情况下,ES的配置dynamic:true,即允许动态映射添加新字段,如果不加约束,可能会导致索引映射字段激增,最终超过索引字段数限制index.mapping.total_fields.limit:1000 ,这种非预期的字段数激增被称作”字段膨胀“。
尤其是索引结构复杂的文档,如下示例,会导致索引的字段结构变得混乱:
POST logs/_doc
{"project":"user-server","content":{"field_a":{"a":{"a1":{"a1_1":{},"a1_2":{},"a1_3":{}},"a2":{},"a3":{}},"b":{},"c":{}...},"field_b":{......}}
}
在这种情况下,当面临索引包含大量不可预测字段的文档时,可以将字段类型设置为”flattened“来避免字段膨胀的问题。”flattened“译为”扁平“,它会将整个嵌套的JSON对象索引为单个keyword类型,以减少字段总数。
如下示例,将用户地址设为flattened类型,无论address对象结构如何复杂,索引字段数都不会变。
PUT users
{"mappings": {"properties": {"name":{"type": "keyword"},"address":{"type": "flattened"}}}
}
索引如下文档请求:
POST users/_doc
{"name":"张三","address":{"province":"浙江省","city":"杭州市","region":"西湖区","street":"文一西路","detail":"某某小区1幢1号"}
}
查看索引映射,依旧只有俩字段
GET users/_mapping{"users": {"mappings": {"properties": {"address": {"type": "flattened"},"name": {"type": "keyword"}}}}
}
索引字段更新具备额外的开销,ES必须为每个字段更新集群状态,跨节点的集群状态传输是单线程操作的,需要更新的字段越多,所需的时间就越长,甚至导致整个集群宕机。
3.3 nested
嵌套数据类型,它和object类似也被用来存储JSON对象或数组,它允许以一种可以彼此独立查询的方式对对象数组进行索引。什么意思呢?
看一个例子,创建users索引,并索引文档,lisa有男性Jack和女性Ruth两位朋友。
PUT usersPOST users/_doc
{"name":"lisa","friends":[{"name":"Jack","gender":"男"},{"name":"Ruth","gender":"女"}]
}
接下来,我们执行bool查询,搜索具有女性Jack朋友的用户,按照正常的业务逻辑不应该召回任何文档,但是结果出乎意料地返回了lisa
GET users/_search
{"query": {"bool": {"must": [{"match": {"friends.name": "Jack"}},{"match": {"friends.gender": "女"}}]}}
}{"took": 3,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.5753642,"hits": [{"_index": "users","_id": "COvanY4BODFb3LbQgXW-","_score": 0.5753642,"_source": {"name": "lisa","friends": [{"name": "Jack","gender": "男"},{"name": "Ruth","gender": "女"}]}}]}
}
出现这种情况的原因是:ES文档没有内部对象的概念,它会将对象层次结构扁平化为一个简单的键值对列表,值使用数组存储,就像这样:
{"name":"lisa","friends.name":["Jack","Ruth"],"friends.gender":["男","女"]
}
单个friend的关系已经丢失,示例中的搜索条件是:(“Jack” in friends.name) and (“女” in friends.gender) ,所以lisa被召回就可以理解了。
要解决这个问题,本质上是要索引对象数组并维护数组中每个对象的独立性,此时可以使用ES提供的“nested”数据类型,如下所示:
PUT users
{"mappings": {"properties": {"name": {"type": "keyword"},"friends": {"type": "nested","properties": {"name": {"type": "keyword"},"gender": {"type": "keyword"}}}}}
}
搜索方式改为nested,如下所示,将不会再找回任何文档
GET users/_search
{"query": {"bool": {"must": [{"nested": {"path": "friends","query": {"bool": {"must": [{"match": {"friends.name": "Jack"}},{"match": {"friends.gender": "女"}}]}}}}]}}
}
nested类型将嵌套对象索引为单独的隐藏文档,使其可以独立于其它对象而查询每个对象。上述示例中,lisa.friends的存储结构就变成了下面这样,每个friend都单独存储为内部的隐藏文档。
{{"friends.name":["Jack"],"friends.gender":["男"]},{"friends.name":["Ruth"],"friends.gender":["女"]}
}
3.4 join
join数据类型用来给同一索引中的文档创建父子关系,有点类似于关系数据库中的表连接。
如下示例,创建一个问答索引用于搜索问题和答案:
PUT question-answer-index
{"mappings": {"properties": {"content": {"type": "text"},"join_field": {"type": "join","relations": {"question": "answer"}}}}
}
分别索引父文档和子文档,其中索引子文档时路由值routing是必须的,因为ES必须保证父子文档索引在同一个分片里。
// 父文档
POST question-answer-index/_doc/1
{"content": "Elasticsearch是什么?","join_field": {"name": "question"}
}// 子文档
POST question-answer-index/_doc/2?routing=1
{"content": "Elasticsearch是位于Elastic Stack 核心的分布式搜索和分析引擎。","join_field": {"name": "answer","parent": "1"}
}
根据父文档搜索子文档:
GET question-answer-index/_search
{"query": {"has_parent": {"parent_type": "question","query": {"match": {"content": "Elasticsearch"}}}}
}{"took": 4,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "question-answer-index","_id": "2","_score": 1,"_routing": "1","_source": {"content": "Elasticsearch是位于Elastic Stack 核心的分布式搜索和分析引擎。","join_field": {"name": "answer","parent": "1"}}}]}
}
根据子文档搜索父文档:
GET question-answer-index/_search
{"query": {"has_child": {"type": "answer","query": {"match": {"content": "Elasticsearch"}}}}
}{"took": 5,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "question-answer-index","_id": "1","_score": 1,"_source": {"content": "Elasticsearch是什么?","join_field": {"name": "question"}}}]}
}
除了示例中的一对一的关系,join也支持定义一对多的关联关系,join本身支持纵向的层级结构,除了定义父子关系,还可以定义子孙关系,但是都必须保证有关系的文档索引在同一分片里。
join类型的一些限制需要注意:
- 每个索引,仅允许定义一个join类型的字段
- 父子文档必须索引在同一个分片里
- 一个父文档可以有多个子文档,一个子文档只能有一个父文档
4. 结构化数据类型
4.1 Range
范围字段类型表示一个连续的值范围,由上边界和下边界组成。ES目前支持的范围类型有:整型范围、浮点数范围、日期范围和ip范围。
如下示例,我们创建一个meetings索引,其中会议的持续时间duration字段就是一个日期范围类型
PUT meetings
{"mappings": {"properties": {"title":{"type": "text"},"duration":{"type": "date_range","format": "yyyy-MM-dd HH:mm:ss"}}}
}
接下来索引文档
POST meetings/_doc
{"title":"需求评审会","duration":{"gte":"2024-01-01 12:00:00","lte":"2024-01-01 12:30:00"}
}
使用term查询即可,只要查询的值在给定的时间范围内就可以召回文档
GET meetings/_search
{"query": {"term": {"duration": {"value": "2024-01-01 12:10:00"}}}
}{"took": 4,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "meetings","_id": "CuuRoY4BODFb3LbQk3WN","_score": 1,"_source": {"title": "需求评审会","duration": {"gte": "2024-01-01 12:00:00","lte": "2024-01-01 12:30:00"}}}]}
}
4.2 ip
ip类型字段可以用来存储IPv4和IPv6地址。
如下示例,创建一个computers索引
PUT computers
{"mappings": {"properties": {"name":{"type": "keyword"},"ip":{"type": "ip"}}}
}
索引文档
POST computers/_doc
{"name":"C01","ip":"192.168.0.1"
}
POST computers/_doc
{"name":"C02","ip":"192.168.0.2"
}
可以根据ip精确匹配
GET computers/_search
{"query": {"term": {"ip": {"value": "192.168.0.1"}}}
}{"took": 0,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "computers","_id": "DeuloY4BODFb3LbQV3UG","_score": 1,"_source": {"name": "C01","ip": "192.168.0.1"}}]}
}
也可以用CIDR表示法根据前缀查询
GET computers/_search
{"query": {"term": {"ip": {"value": "192.168.0.0/24"}}}
}{"took": 0,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 1,"hits": [{"_index": "computers","_id": "DeuloY4BODFb3LbQV3UG","_score": 1,"_source": {"name": "C01","ip": "192.168.0.1"}},{"_index": "computers","_id": "DuuloY4BODFb3LbQW3XF","_score": 1,"_source": {"name": "C02","ip": "192.168.0.2"}}]}
}
5. 文本搜索类型
5.1 Text
文本类型族,包含text和match_only_text,经过分析的非结构化文本数据。
5.1.1 text
索引全文值的字段,例如新闻内容、商品介绍等,ES在索引之前会先经过分析器将字符串转换成单个词列表再存储,默认不存储原始全文值,所以无法通过精准匹配来检索text类型,也不可用于排序和聚合,text适合存储非结构化但人类可阅读的文本内容。
如下示例,创建一个news索引,用于索引新闻数据
PUT news
{"mappings": {"properties": {"title":{"type": "text"},"content":{"type": "text"}}}
}
索引两篇新闻文档
POST news/_doc
{"title":"美国苹果公司发布新款iPhone","content":"新iPhone发布!美国苹果公司震撼发布最新款iPhone。精致设计,强劲性能,和先进功能的完美结合。期待它带来的创新体验!"
}POST news/_doc
{"title":"今年苹果预计将推迟上市","content":"据报道,今年水果市场上备受期待的苹果预计将推迟上市。这可能是由于天气等因素导致苹果的生长和成熟过程延迟。消费者需稍作等待,相信在不久的将来将能品尝到新鲜甜蜜的苹果。"
}
最后通过multi_match来检索文档,检索的字段包括title和content,其中title具备更高的权重,文档得分会更高
GET news/_search
{"query": {"multi_match": {"query": "苹果","fields": ["title^2","content"]}}
}{"took": 11,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 0.72928625,"hits": [{"_index": "news","_id": "meQwuI4BPIYet_3flP8X","_score": 0.72928625,"_source": {"title": "美国苹果公司发布新款iPhone","content": "新iPhone发布!美国苹果公司震撼发布最新款iPhone。精致设计,强劲性能,和先进功能的完美结合。期待它带来的创新体验!"}},{"_index": "news","_id": "muQwuI4BPIYet_3fl_9V","_score": 0.72928625,"_source": {"title": "今年苹果预计将推迟上市","content": "据报道,今年水果市场上备受期待的苹果预计将推迟上市。这可能是由于天气等因素导致苹果的生长和成熟过程延迟。消费者需稍作等待,相信在不久的将来将能品尝到新鲜甜蜜的苹果。"}}]}
}
5.1.2 match_only_text
Elasticsearch7.14推出的全新文本类型,它和text的区别是:match_only_text不存储长度归一化因子、词频数据、位置数据,所以match_only_text不支持文档评分,带来的好处就是比text更节省存储空间,非常适合用于存储日志。
如下示例,创建logs索引,用于索引日志数据,其中text字段类型是match_only_text
PUT logs
{"mappings": {"properties": {"level":{"type": "keyword"},"text":{"type": "match_only_text"}}}
}
索引一些日志
POST logs/_doc
{"level":"info","text":"This is the first log"
}POST logs/_doc
{"level":"info","text":"This is the second log log"
}
最后,通过match检索日志,第二条日志因为有两个”log“所以评分理论上会更高,但是match_only_text不记录词频,所以也就不参与评分,所以两条日志的评分结果都是1
GET logs/_search
{"query": {"match": {"text": "log"}}
}{"took": 12,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 1,"hits": [{"_index": "logs","_id": "m-Q5uI4BPIYet_3f4P8H","_score": 1,"_source": {"level": "info","text": "This is the first log"}},{"_index": "logs","_id": "nOQ5uI4BPIYet_3f5f8j","_score": 1,"_source": {"level": "info","text": "This is the second log log"}}]}
}
5.2 completion
completion类型主要用于搜索建议和自动补全,如果你要做一个类似百度搜索的联想提示功能,那么就可以使用ES的completion类型。completion类型的suggest性能非常高,ES使用了一种特殊的结构用于前缀搜索,并且数据会缓存在内存中。
如下示例,创建一个webpages索引,用于索引网页,其中suggest字段使用completion类型,数据来源是title
PUT webpages
{"mappings": {"properties": {"title": {"type": "text","copy_to": "suggest"},"suggest": {"type": "completion"},"url": {"type": "keyword"}}}
}
接下来,我们索引几篇文档
POST webpages/_doc
{"title":"Java-百度百科","url":"https://baike.baidu.com/item/Java/85979"
}POST webpages/_doc
{"title":"java能做什么","url":"https://baijiahao.baidu.com/s?id=1765494775400937848"
}POST webpages/_doc
{"title":"python编程从入门到精通","url":"https://baijiahao.baidu.com/s?id=1764847625088362688"
}
最后,通过suggest检索自动补全的数据
GET webpages/_search
{"suggest": {"title-suggestion": {"text": "java","completion": {"field": "suggest"}}}
}{"took": 0,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 0,"relation": "eq"},"max_score": null,"hits": []},"suggest": {"title-suggestion": [{"text": "java","offset": 0,"length": 4,"options": [{"text": "Java-百度百科","_index": "webpages","_id": "neRCuI4BPIYet_3f8v8w","_score": 1,"_source": {"title": "Java-百度百科","url": "https://baike.baidu.com/item/Java/85979"}},{"text": "java能做什么","_index": "webpages","_id": "nuRCuI4BPIYet_3f9f9k","_score": 1,"_source": {"title": "java能做什么","url": "https://baijiahao.baidu.com/s?id=1765494775400937848"}}]}]}
}
6. 空间数据类型
ES支持的空间数据类型比较丰富,包括:geo_point、geo_shape、point、shape。
6.1 geo_point
geo_point类型用来存储地址位置经纬度坐标,用于地址位置的搜索和聚合分析,例如实现:附近的人、附近的店铺等功能。
如下示例,创建hotels索引,索引酒店信息,其中location字段使用geo_point类型
PUT hotels
{"mappings": {"properties": {"name": {"type": "keyword"},"location":{"type": "geo_point"}}}
}
再索引两个文档
POST hotels/_doc
{"name":"如家酒店","location":{"lat":10.1,"lon":10.1}
}POST hotels/_doc
{"name":"亚朵酒店","location":{"lat":10.2,"lon":10.2}
}
最后,给定一个圆心坐标查询附近10km的酒店
GET hotels/_search
{"query": {"bool": {"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 10.15,"lon": 10.15}}}]}}
}{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 0,"hits": [{"_index": "hotels","_id": "puRxuI4BPIYet_3fT__u","_score": 0,"_source": {"name": "如家酒店","location": {"lat": 10.1,"lon": 10.1}}},{"_index": "hotels","_id": "p-RxuI4BPIYet_3fUv_f","_score": 0,"_source": {"name": "亚朵酒店","location": {"lat": 10.2,"lon": 10.2}}}]}
}
还可以使用geo_bounding_box矩形搜索,给定矩形的左上方和右下方坐标即可
GET hotels/_search
{"query": {"bool": {"filter": [{"geo_bounding_box": {"location": {"top_left": {"lat": 10.175,"lon": 10},"bottom_right": {"lat": 10,"lon": 10.175}}}}]}}
}{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0,"hits": [{"_index": "hotels","_id": "puRxuI4BPIYet_3fT__u","_score": 0,"_source": {"name": "如家酒店","location": {"lat": 10.1,"lon": 10.1}}}]}
}
6.2 geo_shape
geo_point用来在空间里定义一个点,geo_shape则可以用来定义一个形状,支持:点、线、圆、矩形、多边形。例如可以用geo_shape来表示一个景点的区域、一个停车场的范围等。
如下示例,创建scenic-spots索引用于索引景点信息,其中location_shape字段使用geo_shape类型
PUT scenic-spots
{"mappings": {"properties": {"name": {"type": "keyword"},"location_shape":{"type": "geo_shape"}}}
}
我们使用polygon多边形来索引杭州西湖和西溪湿地两个景点
POST scenic-spots/_doc
{"name":"杭州西湖","location_shape":{"type":"polygon","coordinates":[[[120.13,30.25],[120.16,30.26],[120.16,30.25],[120.15,30.23],[120.14,30.23],[120.13,30.25]]]}
}POST scenic-spots/_doc
{"name":"杭州西溪湿地","location_shape":{"type":"polygon","coordinates":[[[120.05,30.28],[120.09,30.28],[120.09,30.26],[120.04,30.25],[120.05,30.28]]]}
}
最后通过形状搜索,我们使用within即搜索形状必须包含在索引形状内,我们搜索西湖内的三潭印月区域,结果返回西湖
GET scenic-spots/_search
{"query": {"bool": {"filter": [{"geo_shape": {"location_shape": {"shape": {"type": "polygon","relation": "within","coordinates": [[[120.14,30.24],[120.145,30.245],[120.135,30.235],[120.14,30.24]]]}}}}]}}
}{"took": 6,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0,"hits": [{"_index": "scenic-spots","_id": "xeQ7vI4BPIYet_3fHP81","_score": 0,"_source": {"name": "杭州西湖","location_shape": {"type": "polygon","coordinates": [[[120.13,30.25],[120.16,30.26],[120.16,30.25],[120.15,30.23],[120.14,30.23],[120.13,30.25]]]}}}]}
}
除了within,还支持disjoint 搜索形状和索引形状不重叠、intersects 搜索形状和索引形状有重叠部分。
相关文章:

Elasticsearch字段数据类型
1. 前言 ES文档的每个字段都至少有一个数据类型,此类型决定了字段值如何被存储以及检索。例如,字符串类型可以定义为text或者keyword,前者用于全文检索,会经过分词后索引;后者用于精准匹配,值会保持原样被…...

简述RESTFul风格的API接口
目录 传统的风格API REST风格 谓词规范 URL命令规范 避免多级URL 幂等 CURD的接口设计 REST响应 响应成功返回的状态码 重定向 错误代码 客户端 服务器 RESTful的返回格式 返回格式 从上一篇文章我们已经初步知道了怎么在VS中创建一个webapi项目。这篇文章来探讨一…...

探索光耦:光耦——不间断电源(UPS)系统中的安全高效卫士
在现代社会,不间断电源(UPS)系统已成为保障关键设备和数据安全的关键设施,广泛应用于企业数据中心、家庭电子设备等场景。UPS能在电力中断或波动时提供稳定电力,确保设备持续运行。而在这套系统中,光耦&…...
at命令和cron命令
第一章 例行性工作 1、单一执行的例行性工作 单一执行的例行性工作:仅处理执行一次就结束了 . 1.1 at命令的工作过程 /etc/at.allow:里面的用户是可以使用at命令的 --- 但实际上这个allow文件不存在,所以指全部的人都可以使用该命令&#…...

搜维尔科技:使用Manus Primel Xsens数据手套直接在Xsens及其插件中捕获手指数据
使用Manus Primel Xsens数据手套直接在Xsens及其插件中捕获手指数据 搜维尔科技:使用Manus Primel Xsens数据手套直接在Xsens及其插件中捕获手指数据...

Avalonia UI获取Popup显示位置,可解决异常显示其他应用程序的左上角
1.通过 PlacementTarget 获取位置 如果 Popup 是相对于某个控件(PlacementTarget)显示的,你也可以获取该控件的位置,然后计算 Popup 的相对位置。 // 假设 popup 是你的 Popup,target 是你的目标控件(Pla…...

新版Win32高级编程教程-学习笔记01:应用程序分类
互联网行业 算法研发工程师 目录 新版Win32高级编程教程-学习笔记01:应用程序分类 控制台程序 强烈注意 窗口程序 启动项 程序入口函数 库程序 静态库 动态库程序 几种应用程序的区别 控制台程序 本身没有窗口,其中的doc窗口,是管…...
无需编程知识 如何用自适应建站系统创建专业网站 带完整的安装代码包以及搭建部署教程
系统概述 自适应建站系统是一款功能强大、易于使用的建站工具。它采用了先进的技术和设计理念,旨在为用户提供一个简单、高效的建站平台。该系统支持多种语言和多种设备,能够自动适应不同屏幕尺寸和分辨率,确保网站在各种终端上都能呈现出最…...
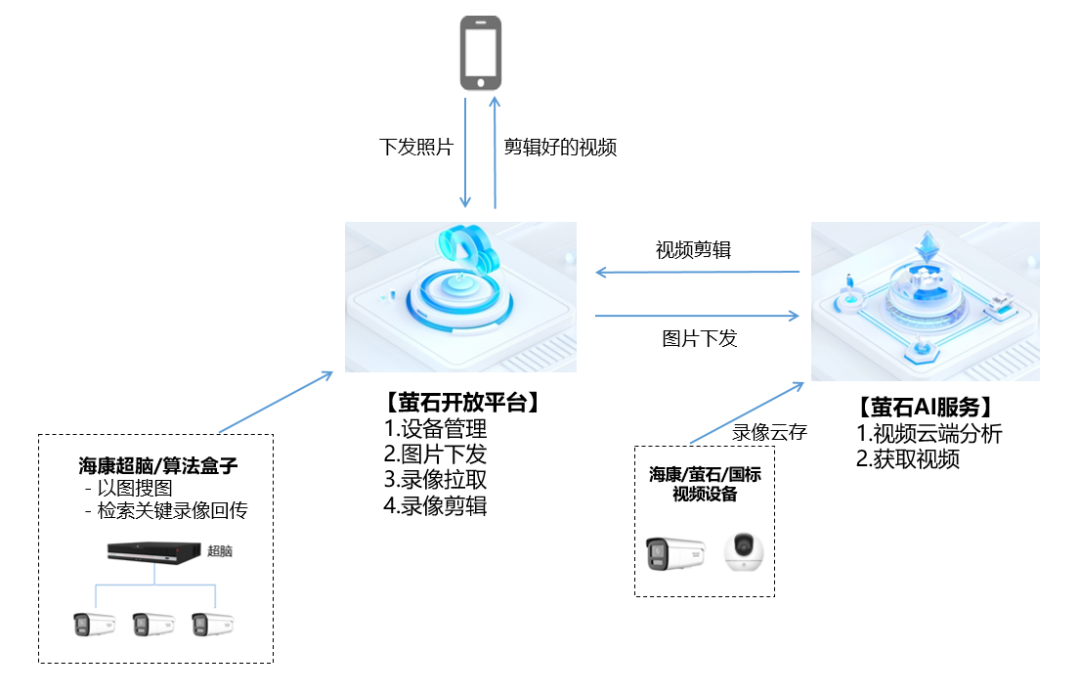
萤石云服务支持云端视频AI自动剪辑生成
萤石视频云存储及媒体处理服务是围绕IoT设备云端存储场景下的音视频采集、媒体管理、视频剪辑和分发能力的一站式、专业云服务,并可面向广大开发者提供复杂设备存储场景下的完整技术方案。目前该服务新增了视频剪辑功能,支持将视频片段在云端进行裁剪并拼…...

Flink移除器Evictor
前言 在 Flink 窗口计算模型中,数据被 WindowAssigner 划分到对应的窗口后,再经过触发器 Trigger 判断窗口是否要 fire 计算,如果窗口要计算,会把数据丢给移除器 Evictor,Evictor 可以先移除部分元素再交给 ProcessFu…...

R语言实现多元线性回归高杠杠点,离群点分析
14a set.seed(1) x1 = runif(100) x2 = 0.5 * x1 + rnorm(100)/...

overfrp内网穿透:使用域名将内网http/https服务暴露到公网
项目地址:https://github.com/sometiny/overfrp 使用overfrp部署穿透服务器,绑定域名后,可使用域名访问内网的http/https服务。 用例中穿透服务器和内网机器之间的访问全链路加密,具有ssh2相当的安全级别。!…...

springboot034在线商城系统设计与开发-代码(论文+源码)_kaic
毕 业 设 计(论 文) 题目:ONLY在线商城系统设计与实现 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本ONLY在线商城系统…...
?为什么要遵守第三范式?)
什么是第三范式(3NF)?为什么要遵守第三范式?
第三范式(Third Normal Form, 3NF)是数据库设计中的一个重要概念,它是对关系型数据库规范化的一种标准。 在数据库设计中,通过将数据表按照一定的规则进行分解,可以减少数据冗余和提高数据的一致性。 3NF 是建立在第…...

大数据比对,shell脚本与hive技术结合
需求描述 从主机中获取加密数据内容,解密数据内容(可能会存在json解析)插入到另一个库中,比对原始库和新库的相同表数据的数据一致性内容。 数据一致性比对实现 上亿条数据,如何比对并发现两个表数据差异 相关流程…...

【Linux安全基线】- CentOS 7/8安全配置指南
在企业业务的生产环境中,Linux服务器的安全性至关重要,尤其是对于具有超级用户权限的root账号。滥用或被入侵后,可能会造成数据泄露、系统损坏等严重安全问题。为了减少这种风险,本文将详细介绍如何通过一系列安全措施来增强CentO…...

PDF.js的使用及其跨域问题解决
目录 一、PDF.js 简介 二、使用配置和步骤 1.引入PDF.js 2.加载PDF文件 3.渲染PDF页面 三、在Vue中使用PDF.js示例 1.安装PDF.js 2.在Vue组件中使用 四、在原生js中使用PDF.js示例 1.加载PDF文件并渲染页面 五、解决跨域问题 1.服务器配置 2.使用代理服务器 下面介…...

Linux Redis查询key与移除日常操作
维护老项目Express node 编写的后端程序、有这么一个方法、没有设置redis过期时间(建议设置过期时间,毕竟登录生产服务器并不是每个人都有权限登录的!!!)。如果变动只能通过登录生产服务器、手动修改… 于…...

开源两个月,antflow后端项目全网获近100星
从六月初开源,转眼间AntFlow已经开源将近四个月了(前端比后端早了大约2个月,后端于8.18开源).(其实准备是重构以前开源版本.前年的时候我们已经将Vue2版的流程设计器开源了.后来由于疫情原因,没有再继续持续开发.)后来有一天再打开仓库的时候,发现虽然很久没有更新了,但是不断有…...
抽象工厂模式(3))
设计模式——工厂方法模式(2)抽象工厂模式(3)
一、写在前面 创建型模式 单例模式工厂方法模式抽象工厂模式原型模式建造者模式 结构型模式行为型模式工厂方法模式和抽象工厂模式都属于工厂模式,所以放在一起介绍了 二、介绍 为什么要工厂模式?工厂就像一个黑盒一样,所以用工厂模式来创…...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...