大数据比对,shell脚本与hive技术结合
需求描述
从主机中获取加密数据内容,解密数据内容(可能会存在json解析)插入到另一个库中,比对原始库和新库的相同表数据的数据一致性内容。
数据一致性比对实现
上亿条数据,如何比对并发现两个表数据差异
相关流程
从其他主机获取大批量数据内容文件(zip格式)–>针对大批量数据文件进行解密、解压输出–>在新库里创建对应的比对表–>将解压、解密的文件内容直接入到hdfs路径上,并刷新分区–>写出比对脚本–>参考多进程跑多个脚本内容输出相关多个日志
相关脚本内容
获取批量数据文件内容
#!/bin/bash
# https://blog.csdn.net/axing2015/article/details/89313460
# SFTP:10.230.105.47/48/49,用户密码线下提供
# 存量数据: /data1/etl/csv/省拼音/批次/表名.csv
# 增量数据: /data1/etl/stream/省拼音/批次/表名
# 加载工具: /data1/etl/tool# 已经有人帮我下载下来了,所有没必要去下载了data_home=/data1/etl/csv/省拼音/批次/
sftp_path=/data1/etl/csv/heilongjiang/0/sftp_ip=xxxx
sftp_user=xxxx
sftp_passwd=xxx
sftp_port=22
file_name=*.csvmkdir -p ${data_home}lftp -u ${sftp_user},${sftp_passwd} sftp://${sftp_ip}:${sftp_port} <<!
#关于ftp地址切换的命令 是在本地主机目录操作的命令 把东西下载到指定的本地目录
lcd ${data_home}
cd ${sftp_path}
# 下载多个文件
mget ${file_name}
bye
!cd ${data_home}
# 创建hive表结构# 将文件入到hive中去
sh putCsvLoadHive.sh解密脚本(传输的大文件数据是加密的,需要解密)
#!/bin/bash
# 将传过来的增量文件进行解密
beginTime=$(date +%s)
if [ $# -eq 0 ]; thenecho "没有传参数进来,请输入时间参数"exit
fi
source_path="/data0/e3base/wangsw_a/js_shell/sftp_file/stock_data"
decrypt_path="/data0/e3base/wangsw_a/js_shell/sftp_file/decrypt_data"
password="e3base1"
do_tran_path="/data0/e3base/do_trans/"cd "$do_tran_path"for file in "$source_path"/*.des3; doif [ -f "$file" ]; thenfilename=$(basename "$file")filename_without_ext="${filename%.*}"decrypted_file="$decrypt_path/$filename_without_ext"./dzip -pwd "$password" -unzip "$file" "$decrypted_file"if [ -f "$decrypted_file" ]; thenecho "解密成功: $decrypted_file"elseecho "解密失败: $file"fifi
done
endTime=$(date +%s)
executionTime=$((endTime - beginTime))
echo "脚本执行时间:$executionTime秒"创建hive表
#!/bin/bash
beginTime=$(date +%s)
sql="
drop database if exists radmcsdb_restore_ah cascade;
create database radmcsdb_restore_ah;
-- ac_contract_info
create table radmcsdb_restore_ah.oracle_ac_contract_info_ah(
\`ACCOUNT_LIMIT\` string,
\`ACCOUNT_TYPE\` string,
\`CONTRACTATT_TYPE\` string,
\`CONTRACT_NAME\` string,
\`CONTRACT_NAME_ENCRYPT\` string,
\`CONTRACT_NO\` string,
\`CONTRACT_PASSWD\` string,
\`CUST_ID\` string,
\`FINISH_FLAG\` string,
\`GROUP_ID\` string,
\`LOGIN_ACCEPT\` string,
\`LOGIN_NO\` string,
\`OP_CODE\` string,
\`OP_TIME\` string,
\`PAY_CODE\` string,
\`REPRESENT_PHONE\` string,
\`STATUS_CODE\` string,
\`STATUS_TIME\` string
)
PARTITIONED BY ( \`pt_day_time\` string)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ('separatorChar' = ',', 'quoteChar' = '\\\"','escapeChar' = '\\\\'
)
stored as textfile tblproperties("skip.header.line.count"="1");
-- location 'hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/oracle_ac_contract_info_ah';--- 差异表
create table radmcsdb_restore_ah.ac_contract_info_ah_diff(
\`oracle_ah_ACCOUNT_LIMIT\` string,
\`oracle_ah_ACCOUNT_TYPE\` string,
\`oracle_ah_CONTRACTATT_TYPE\` string,
\`oracle_ah_CONTRACT_NAME\` string,
\`oracle_ah_CONTRACT_NAME_ENCRYPT\` string,
\`oracle_ah_CONTRACT_NO\` string,
\`oracle_ah_CONTRACT_PASSWD\` string,
\`oracle_ah_CUST_ID\` string,
\`oracle_ah_FINISH_FLAG\` string,
\`oracle_ah_GROUP_ID\` string,
\`oracle_ah_LOGIN_ACCEPT\` string,
\`oracle_ah_LOGIN_NO\` string,
\`oracle_ah_OP_CODE\` string,
\`oracle_ah_OP_TIME\` string,
\`oracle_ah_PAY_CODE\` string,
\`oracle_ah_REPRESENT_PHONE\` string,
\`oracle_ah_STATUS_CODE\` string,
\`oracle_ah_STATUS_TIME\` string,
\`oracle_ah_pt_day_time\` string,
\`restore_ah_ACCOUNT_LIMIT\` string,
\`restore_ah_ACCOUNT_TYPE\` string,
\`restore_ah_CONTRACTATT_TYPE\` string,
\`restore_ah_CONTRACT_NAME\` string,
\`restore_ah_CONTRACT_NAME_ENCRYPT\` string,
\`restore_ah_CONTRACT_NO\` string,
\`restore_ah_CONTRACT_PASSWD\` string,
\`restore_ah_CUST_ID\` string,
\`restore_ah_FINISH_FLAG\` string,
\`restore_ah_GROUP_ID\` string,
\`restore_ah_LOGIN_ACCEPT\` string,
\`restore_ah_LOGIN_NO\` string,
\`restore_ah_OP_CODE\` string,
\`restore_ah_OP_TIME\` string,
\`restore_ah_PAY_CODE\` string,
\`restore_ah_REPRESENT_PHONE\` string,
\`restore_ah_STATUS_CODE\` string,
\`restore_ah_STATUS_TIME\` string
)
PARTITIONED BY ( \`pt_day_time\` string)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ('separatorChar' = ',', 'quoteChar' = '\\\"','escapeChar' = '\\\\'
)
stored as textfile tblproperties("skip.header.line.count"="1");
-- location 'hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/ac_contract_info_ah_diff';-- 主键文件表
create table radmcsdb_restore_ah.ac_contract_info_ah_primary(
\`primary_key_contract_no\` string
)
partitioned by ( \`pt_day_time\` string)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ('separatorChar' = ',', 'quoteChar' = '\\\"','escapeChar' = '\\\\'
)
stored as textfile tblproperties("skip.header.line.count"="1");
-- location 'hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/ac_contract_info_ah_primary';..............
"echo "${sql}!quit" | beeline -u 'jdbc:hive2://G034:11001,G035:11001,G036:11001/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi' -n e3baseecho "结束时间 $endTimeYMD"
endTime=$(date +%s)
endTimeYMD=$(date +%Y%m%d%H%M%S)
echo "结束时间 $endTimeYMD"
echo "还原层表已创建完,请进行总共21个表核对,总共耗时:'$(($endTime - $beginTime))'秒"
解密文件入hive存储地址,并刷新分区
#!/bin/bash
# 将省端数据文件传入hive 并刷新分区。
beginTime=$(date +%s)
if [ $# -eq 0 ]; thenecho "没有传参数进来,请输入省份参数"exit
fiif [ $# -eq 1 ]; thenecho "请确认是否输入省份和时间参数"exit
fi# hive_url="beeline -u 'jdbc:hive2://G034:11001,G035:11001,G036:11001/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi' -n e3base"
# hive_url_e="$hive_url --silent=true --showHeader=false --outputformat=dsv -e"
data_home=/data1/etl/csv/$1for ((i = 0; i < 21; i++)); do{cd ${data_home}/$isql=""ls *.csv | {while read t1; do# 删除第一行# sed -i '1d' $t1# 判断是否是数字if [[ $t1 == *[0-9]* ]]; then# PD_USERPRC_INFO_00.csvname2=oracle_${t1%_*}_ah# 大写边小写name3=${name2,,}elsename2=oracle_${t1%.*}_ahname3=${name2,,}fi# partition_primary=$($hive_url_e "show partitions radmcsdb_restore_ah.$name3;" | sort | tail -n 1)# partition_primary=$($hive_url_e "show partitions radmcsdb_restore_ah.oracle_ac_contract_info_ah;" | sort | tail -n 1)# hdfs dfs -rm -f hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/$name3/$partition_primaryif [ $i == 0 ]; thenhdfs dfs -mkdir hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/$name3/pt_day_time=$2fihdfs dfs -put $t1 hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/$name3/pt_day_time=$2/ && hdfs dfs -mv hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/$name3/pt_day_time=$2/$t1 hdfs://drmcluster/apps/hive/warehouse/radmcsdb_restore_ah.db/$name3/pt_day_time=$2/${i}_${t1}# 判断其是否是最后一个文件夹if [ $i == 20 ]; thensql="alter table radmcsdb_restore_ah.$name3 add if not exists partition (pt_day_time=$2);$sql"fidoneif [ $i == 20 ]; thenecho "${sql}!quit" | beeline -u 'jdbc:hive2://G034:11001,G035:11001,G036:11001/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi' -n e3basefi}}
done
# wait关键字确保每一个子进程都执行完成
# waitendTime=$(date +%s)
echo "将数据上传hdfs,总共耗时:'$(($endTime - $beginTime))'秒"比较数据一致性
#!/bin/bash
# 逻辑:插入并生成差异文件,提取差异文件,并将差异主键进行输出到指定目录。
# diff_table_sh
# 字符串切割 https://blog.csdn.net/bandaoyu/article/details/120659630
# 获取最该目录下最新的文件的数据
# https://blog.csdn.net/sh13661847134/article/details/113757792
# 第一部分获取分区
# 预支前提
beginTime=$(date +%s)
beginTimeYMD=$(date +%Y%m%d%H%M%S)
hive_url="beeline -u 'jdbc:hive2://G034:11001,G035:11001,G036:11001/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi' -n e3base"
hive_url_e="$hive_url --silent=true --showHeader=false --outputformat=dsv -e"# 第一部分获取分区
join="full outer join"
partition_orcle=$($hive_url_e "show partitions radmcsdb_restore_ah.oracle_ac_account_rel_ah;" | sort | tail -n 1)
count_num=$($hive_url_e "select count(distinct pt_day_time) as count_num from radmcsdb_restore_ah.oracle_ac_account_rel_ah;")
if [ $count_num -gt 1 ]; thenjoin="inner join"
fi# 第二部分执行sql
sql="insert overwrite table radmcsdb_restore_ah.ac_account_rel_ah_diff partition(pt_day_time)select left_table.*,right_table.*,from_unixtime(unix_timestamp(),'yyyyMMddHHmmss') as pt_day_timefrom (select *from radmcsdb_restore_ah.oracle_ac_account_rel_ah where $partition_orcle)left_table$join (select *from restore_ah.ac_account_rel)right_tableon (left_table.CONTRACT_NO = right_table.CONTRACT_NOand left_table.ACCT_REL_TYPE = right_table.ACCT_REL_TYPEand left_table.REL_CONTRACT_NO = right_table.REL_CONTRACT_NOand left_table.ACCT_ITEMS = right_table.ACCT_ITEMS)where
COALESCE(left_table.login_accept, '0') <> COALESCE(right_table.login_accept, '0') or
COALESCE(left_table.contract_no, '0') <> COALESCE(right_table.contract_no, '0') or
COALESCE(left_table.rel_contract_no, '0') <> COALESCE(right_table.rel_contract_no, '0') or
COALESCE(left_table.acct_rel_type, '0') <> COALESCE(right_table.acct_rel_type, '0') or
COALESCE(left_table.acct_items, '0') <> COALESCE(right_table.acct_items, '0') or
COALESCE(left_table.pay_value, '0') <> COALESCE(right_table.pay_value, '0') or
COALESCE(left_table.pay_pri, '0') <> COALESCE(right_table.pay_pri, '0') or
-- COALESCE(left_table.eff_date, '0') <> COALESCE(right_table.eff_date, '0') or
-- COALESCE(left_table.exp_date, '0') <> COALESCE(right_table.exp_date, '0') or
COALESCE(left_table.login_no, '0') <> COALESCE(right_table.login_no, '0') or
-- COALESCE(left_table.op_time, '0') <> COALESCE(right_table.op_time, '0') or
COALESCE(left_table.remark, '0') <> COALESCE(right_table.remark, '0') or
COALESCE(left_table.busi_type, '0') <> COALESCE(right_table.busi_type, '0');insert overwrite table radmcsdb_restore_ah.ac_account_rel_ah_primary partition(pt_day_time)
select
oracle_ah_CONTRACT_NO,
oracle_ah_ACCT_REL_TYPE,
oracle_ah_REL_CONTRACT_NO,
oracle_ah_ACCT_ITEMS,
from_unixtime(unix_timestamp(),'yyyyMMddHHmmss') as pt_day_time
from (
select
oracle_ah_CONTRACT_NO,
oracle_ah_ACCT_REL_TYPE,
oracle_ah_REL_CONTRACT_NO,
oracle_ah_ACCT_ITEMS
from radmcsdb_restore_ah.ac_account_rel_ah_diff
where
oracle_ah_CONTRACT_NO is not null
and oracle_ah_ACCT_REL_TYPE is not null
and oracle_ah_REL_CONTRACT_NO is not null
and oracle_ah_ACCT_ITEMS is not null
and pt_day_time=(select max(pt_day_time) from radmcsdb_restore_ah.ac_account_rel_ah_diff) unionselect
restore_ah_CONTRACT_NO,
restore_ah_ACCT_REL_TYPE,
restore_ah_REL_CONTRACT_NO,
restore_ah_ACCT_ITEMS
from radmcsdb_restore_ah.ac_account_rel_ah_diff
where
restore_ah_SERV_ACCT_ID is not null
and restore_ah_ACCT_REL_TYPE is not null
and restore_ah_REL_CONTRACT_NO is not null
and restore_ah_ACCT_ITEMS is not null
and pt_day_time=(select max(pt_day_time) from radmcsdb_restore_ah.ac_account_rel_ah_diff)) a;
"echo "${sql}!quit" | $hive_url# 第三部分获取主键文件
partition_primary=$($hive_url_e "show partitions radmcsdb_restore_ah.ac_account_rel_ah_primary;" | sort | tail -n 1)
pt_day_time=${partition_primary:12}
$hive_url_e "set hive.cli.print.header=true; select * from radmcsdb_restore_ah.ac_account_rel_ah_primary where $partition_primary;" | grep -v "WARN" >ac_account_rel_ah_primary_$pt_day_time.csv
# 针对主键文件进行传输到指定位置# 第四部分输出主键数量
count_primary=$($hive_url_e "select count(1) from radmcsdb_restore_ah.ac_account_rel_ah_primary where $partition_primary;")
echo "差异主键数量还剩:$count_primary"# 第五部分输出比对数据
sql="select left_table.pv,right_table.pv as pv_difffrom (select count(1) as pvfrom radmcsdb_restore_ah.oracle_ac_account_rel_ah)left_tableleft outer join (select count(1) as pvfrom restore_ah.ac_account_rel)right_tableon 1=1;"
# 将换行转换层空格,方面sql美观度
sql_text="$(echo $sql | tr '\n' ' ')"
count_compare=$($hive_url_e "$sql_text")# 第六部分输出主键数量
count_primary=$($hive_url_e "select count(1) from radmcsdb_restore_ah.ac_account_rel_ah_primary where $partition_primary;")# 结束标语
endTime=$(date +%s)
endTimeYMD=$(date +%Y%m%d%H%M%S)
echo "打印开始时间:$beginTimeYMD"
echo "ac_account_rel比较量级自己省端和还原层:$count_compare"
echo "差异主键数量还剩:$count_primary"
echo "打印结束时间:$endTimeYMD"
echo "ac_account_rel_ah_diff 异常表执行完成 ,开始时间:$beginTimeYMD,结束时间:$endTimeYMD,总共耗时:'$(($endTime - $beginTime))'秒"
echo "ac_account_rel_ah_diff 异常表执行完成"多进程跑脚本输出日志
运行就nohup 这个主脚本即可
#!/bin/bash
if [ $# -eq 0 ]; thenecho "没有传参数进来,请输入时间参数"exit
fihive_url="beeline -u 'jdbc:hive2://G034:11001,G035:11001,G036:11001/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi' -n e3base"
hive_url_e="$hive_url --silent=true --showHeader=false --outputformat=dsv -e"beginTime=$(date +%s)
beginTimeYMD=$(date +%Y%m%d%H%M%S)mkdir ./finalLog# 第一张表
partition_orcle=$($hive_url_e "show partitions radmcsdb.oracle_cs_conuserrel_info_hlj;" | sort | tail -n 1)
count_orcle=$($hive_url_e "select count(1) from radmcsdb.oracle_cs_conuserrel_info where $partition_orcle;")partition_primary=$($hive_url_e "show partitions radmcsdb.cs_conuserrel_info_primary;" | sort | tail -n 1)
count_primary=$($hive_url_e "select count(1) from radmcsdb.cs_conuserrel_info_primary where $partition_primary;")
echo "cs_conuserrel_info 表数量:$count_orcle,差异主键数量还剩:$count_primary"# 第二十一张表
partition_orcle=$($hive_url_e "show partitions radmcsdb.oracle_ep_organization_hlj;" | sort | tail -n 1)
count_orcle=$($hive_url_e "select count(1) from radmcsdb.oracle_ct_custcontact_info_hlj where $partition_orcle;")partition_primary=$($hive_url_e "show partitions radmcsdb.ep_organization_hlj_primary;" | sort | tail -n 1)
count_primary=$($hive_url_e "select count(1) from radmcsdb.ep_organization_hlj_primary where $partition_primary;")
echo "ep_organization 数量:$count_orcle,差异主键数量还剩:$count_primary"endTime=$(date +%s)
endTimeYMD=$(date +%Y%m%d%H%M%S)
echo "结束时间 $endTimeYMD"
echo "多个表执行完成,总共耗时:'$(($endTime - $beginTime))'秒"可能存在将json 数据解析 重新输出成 csv文件
#!/bin/bash
# 将json 数据 解析成 csv文件
# 遍历该下面的所有文件# https://blog.csdn.net/qq_36836950/article/details/131063485
# https://blog.csdn.net/weixin_45842494/article/details/123943756
# https://blog.csdn.net/qq_38250124/article/details/86554834
# https://www.cnblogs.com/bymo/p/7601519.html
# https://blog.csdn.net/weixin_44056331/article/details/102411008# 预支前提
beginTime=$(date +%s)
beginTimeYMD=$(date +%Y%m%d%H%M%S)
hive_url="beeline -u 'jdbc:hive2://iot-e3base06:11001,iot-e3base07:11001,iot-e3base08:11001/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk' -n dwdapp"
hive_url_e="$hive_url --silent=true --showHeader=false --outputformat=dsv -e"# 从文件里面获取所有需要的表名 赋值一个数组
# 根据数组进行循环遍历# 第一步根据表名获取列名
partition_stock=$($hive_url_e "desc dwdb.ods_soa_mft_bill_d;")
# $0 是指文本中的第一列 print arr[1] 输出第一列中的所有值 for(i in arr) print arr[i] 输出每一列的分割的值
partition_stock1=$(echo "$partition_stock" | awk '{split($0, arr, "|"); print arr[1]}')
# 这里是将列转行 并输出为数组的形式
arr=(${partition_stock1//\\n/})
# 变量拼接值
data_txt=''# 读取文件的每一行
while read -r line; do# jq -r 是英文字符串输出出来会有双引号,-r 可以消除# 用jq 插件的对象的方式去获取for s in ${arr[@]}; doif [[ $s != 'pt_day' ]]; then# 字符拼接if [[ $data_txt == '' ]]; thendata_txt="$(echo $line | jq -r ".COLUMNINFO.$s")"elsedata_txt="$data_txt,$(echo $line | jq -r ".COLUMNINFO.$s")"fielse# 输出内容到指定路径echo $data_txt >>'AC_CONTRACTADD_INFO_JSON.csv'breakfidone# 需要解析的文件
done <ods_soa_mft_bill_d.csv
其他-scp脚本解密
#/user/bin/expect
# Expect是一个免费的编程工具语言,用来实现自动和交互式任务进行通信,而无需人的干预。
# 首行/usr/bin/expect,声明使用except组件,类似/bin/sh用法
# spawn: spawn + 需要执行的shell命令
# expect: 只有spawn执行的命令结果才会被expect捕捉到,因为spawn会启动一个进程,只有这个进程的相关信息才会被捕捉到,主要包括:标准输入的提示信息,eof和timeout。
# send和send_user:send会将expect脚本中需要的信息发送给spawn启动的那个进程,而send_user只是回显用户发出的信息,类似于shell中的echo而已。
spawn scp -r /data0/e3base/wangsw_a/sftp_file/hlj/ e3base@G030:/data1/hlj/stock_data/
expect "*password:"
send "E3base_12#34\n"
expect eof
相关文章:

大数据比对,shell脚本与hive技术结合
需求描述 从主机中获取加密数据内容,解密数据内容(可能会存在json解析)插入到另一个库中,比对原始库和新库的相同表数据的数据一致性内容。 数据一致性比对实现 上亿条数据,如何比对并发现两个表数据差异 相关流程…...

【Linux安全基线】- CentOS 7/8安全配置指南
在企业业务的生产环境中,Linux服务器的安全性至关重要,尤其是对于具有超级用户权限的root账号。滥用或被入侵后,可能会造成数据泄露、系统损坏等严重安全问题。为了减少这种风险,本文将详细介绍如何通过一系列安全措施来增强CentO…...

PDF.js的使用及其跨域问题解决
目录 一、PDF.js 简介 二、使用配置和步骤 1.引入PDF.js 2.加载PDF文件 3.渲染PDF页面 三、在Vue中使用PDF.js示例 1.安装PDF.js 2.在Vue组件中使用 四、在原生js中使用PDF.js示例 1.加载PDF文件并渲染页面 五、解决跨域问题 1.服务器配置 2.使用代理服务器 下面介…...

Linux Redis查询key与移除日常操作
维护老项目Express node 编写的后端程序、有这么一个方法、没有设置redis过期时间(建议设置过期时间,毕竟登录生产服务器并不是每个人都有权限登录的!!!)。如果变动只能通过登录生产服务器、手动修改… 于…...

开源两个月,antflow后端项目全网获近100星
从六月初开源,转眼间AntFlow已经开源将近四个月了(前端比后端早了大约2个月,后端于8.18开源).(其实准备是重构以前开源版本.前年的时候我们已经将Vue2版的流程设计器开源了.后来由于疫情原因,没有再继续持续开发.)后来有一天再打开仓库的时候,发现虽然很久没有更新了,但是不断有…...
抽象工厂模式(3))
设计模式——工厂方法模式(2)抽象工厂模式(3)
一、写在前面 创建型模式 单例模式工厂方法模式抽象工厂模式原型模式建造者模式 结构型模式行为型模式工厂方法模式和抽象工厂模式都属于工厂模式,所以放在一起介绍了 二、介绍 为什么要工厂模式?工厂就像一个黑盒一样,所以用工厂模式来创…...
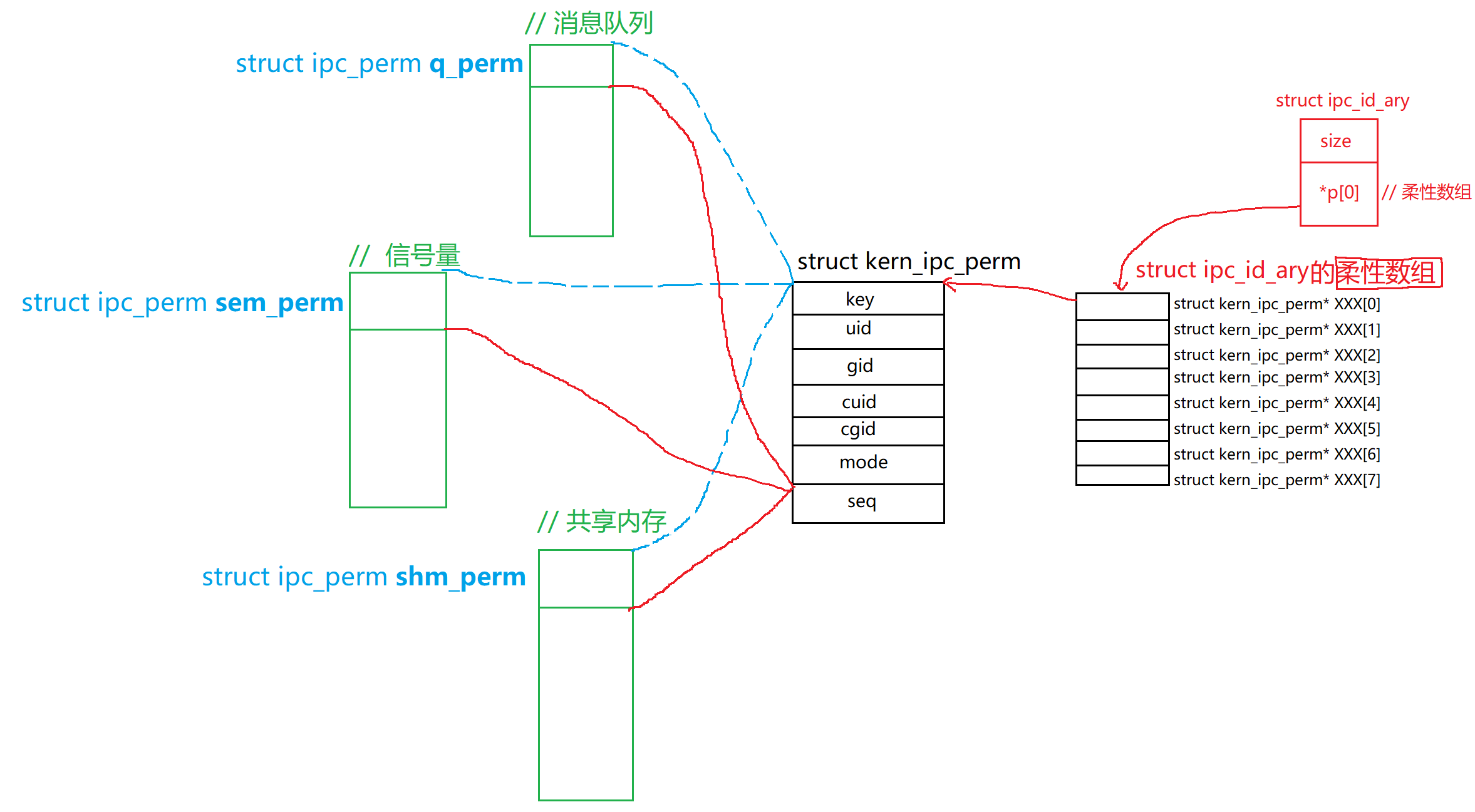
简单聊聊System V下的IPC + 内核是如何管理该IPC
文章目录 前言:🎃消息队列:1. **消息队列的基本概念**2. **消息队列的特点**3. **常见的消息队列操作(Linux IPC)****1) msgget:创建或获取消息队列****2) msgsnd:发送消息****3) msgrcv&#x…...

【WRF工具】服务器上安装convert_geotiff
【WRF工具】服务器上安装convert_geotiff convert_geotiff简介方法1:下载安装包后下载convert_geotiff依赖库安装库1:libtiff库2:sqlite库3:curl库4:projcmake更新(可选)库5:geotiff…...

RPC通讯基础原理
1.RPC(Remote Procedure Call)概述 RPC是一种通过网络从远程计算机上调用程序的技术,使得构建分布式计算更加容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性,提供一种透明调用机制,让使用者不…...

JavaScript 第18章:安全性
在JavaScript开发中,确保应用的安全性是非常重要的。下面我将根据你提到的几个方面来讲解如何增强Web应用程序的安全性。 XSS(跨站脚本)攻击防御 示例代码: function escapeHTML(unsafe) {return unsafe.replace(/&/g, &qu…...

基于workbox实现PWA预缓存能力
引言 Service Worker 是一项流行的技术,尽管在许多项目中尚未得到充分利用。基于本次项目首页加载优化的机会,决定尝试使用 Google 出品的 Workbox,以观察其优化效果。 开始 安装 项目使用 Webpack 打包,而 Workbox 提供了 We…...

探索Web3生态系统:社区、协议与参与者的角色
Web3代表着互联网的下一个演变阶段,旨在通过去中心化技术赋予用户更大的控制权和参与感。在这个新兴生态系统中,社区、协议和参与者扮演着不可或缺的角色,共同推动着Web3的建设与发展。 社区的核心作用 在Web3中,社区通过提供反馈…...

无人机电机故障率骤降:创新设计与六西格玛方法论双赢
项目背景 TBR-100是消费级无人机头部企业推出的主打消费级无人机,凭借其出色的续航能力和卓越的操控性,在市场上获得了广泛认可。在产品运行过程,用户反馈电机故障率偏高,尤其是在飞行一段时间后出现电机过热、损坏以及运行不稳定…...

samba禁用时拷贝服务器文件到本地的脚本
Android系统开发一般在ubuntu服务器上,我们办公电脑一般是windows。在将编译出来的模块push到板子上时,一般采用adb push 方式。 有时由于种种原因会出现服务器禁用了samba,导致无法直接用adb push 的情况。 下面介绍用winscp 走ssh 拷贝服…...

C#代码 串口通信晋中A2板,控制直流电机
1,在电脑中给晋中板中下载编译好的程序。 0x39 :开启电机的标识 代码: /********************************************************************************** **** 实验名称:串口通信实验 接线说明: 实验现象&…...

3 机器学习之假设空间
归纳(induction)与演绎(deduction)是科学推理的两大基本手段。前者是从特殊到一般的“泛化”(generalization)过程,即从具体的事实归结出一般性规律;后者则是从一般到特殊的“特化”(specialization)过程,即从基础原理推演出具体状况。例如&a…...

基于STM32的风速风向传感器设计
引言 本项目设计了一个基于STM32的风速和风向传感器系统,能够通过组合使用旋转式风速传感器和电子罗盘,实时测量风速和风向,并将数据通过显示屏或无线模块发送给用户。该系统适用于气象监测、环境监控、农业自动化等场景,具有准确…...
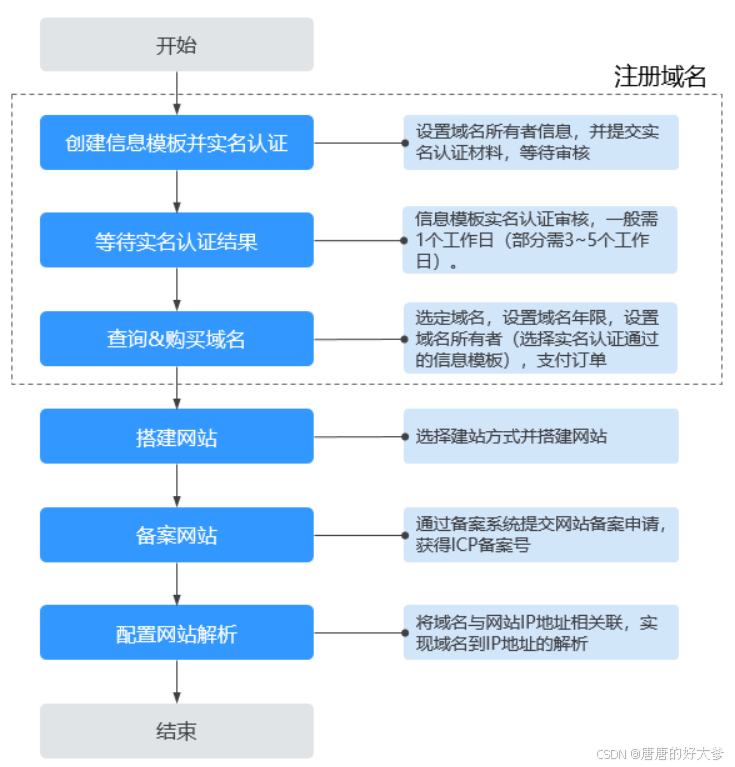
域名申请.
操作场景 Internet上有成千上万台主机,每一台主机都对应一个唯一的IP地址。IP地址因不具备实际意义,非常难于记忆,于是就产生了域名。 域名(Domain Name)是一串用点分隔的字符串组成的名称(例如huaweiclo…...

mysql5.7与mysql8.0身份认证插件的区别
MySQL 5.7 和 MySQL 8.0 在身份认证插件方面有一些重要的区别。这些变化主要集中在默认的身份验证插件、密码管理和安全性增强上。 默认身份验证插件 MySQL 5.7 默认插件: mysql_native_password mysql_native_password 是 MySQL 5.7 及更早版本中的默认身份验证插件。它使用…...

进化吧!原始人
如果你想体验一下人类的进化过程~ 如果你有一颗充满探索的好奇心~ 千万不要错过博主新开发的小游戏哦! 点击链接,立即体验! 🙋 欢迎来到冒险互动游戏《进化吧原始人》! 🦍 在这里,你将扮演一…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...