《深度学习》【项目】自然语言处理——情感分析 <上>
目录
一、项目介绍
1、项目任务
2、评论信息内容
3、待思考问题
1)目标
2)输入字词格式
3)每一次传入的词/字的个数是否就是评论的长度
4)一条评论如果超过32个词/字怎么处理?
5)一条评论如果没有32个词/字怎么处理?
6)如果语料库中的词/字太多是否可以压缩?
7)被压缩的词/字如何处理?
二、项目实施
1、读取文件,建立词表
1)代码内容
2)部分内容拆分解析
3)代码运行结果
4)调试模式
2、评论删除、填充,切分数据集
1)代码内容
2)运行结果
3)调试模式
一、项目介绍
1、项目任务
对微博评论信息的情感分析,建立模型,自动识别评论信息的情绪状态。
2、评论信息内容
![]()

3、待思考问题
1)目标
将每条评论内容转换为词向量。
2)输入字词格式
每个词/字转换为词向量长度(维度)200,使用腾讯训练好的词向量模型有4960个维度,需要这个模型或者文件可私信发送。
3)每一次传入的词/字的个数是否就是评论的长度
应该是固定长度,如何固定长度接着看,固定长度每次传入数据与图像相似,例如输入评论长度为32,那么传入的数据为32*200的矩阵,表示这一批词的独热编码,200表示维度
4)一条评论如果超过32个词/字怎么处理?
超出的直接删除后面的内容
5)一条评论如果没有32个词/字怎么处理?
缺少的内容,统一使用一个数字(非词/字的数字)替代,项目中使用<PAD>填充
6)如果语料库中的词/字太多是否可以压缩?
可以,某些词/字出现的频率比较低,可能训练不出特征。因此可以选择频率比较高的词来训练,项目中选择4760个。
7)被压缩的词/字如何处理?
可以统一使用一个数字(非词/字的数字)替代,即选择了评论固定长度的文字后,这段文字内可能有频率低的字,将其用一个数字替代,项目内使用<UNK>替代
二、项目实施
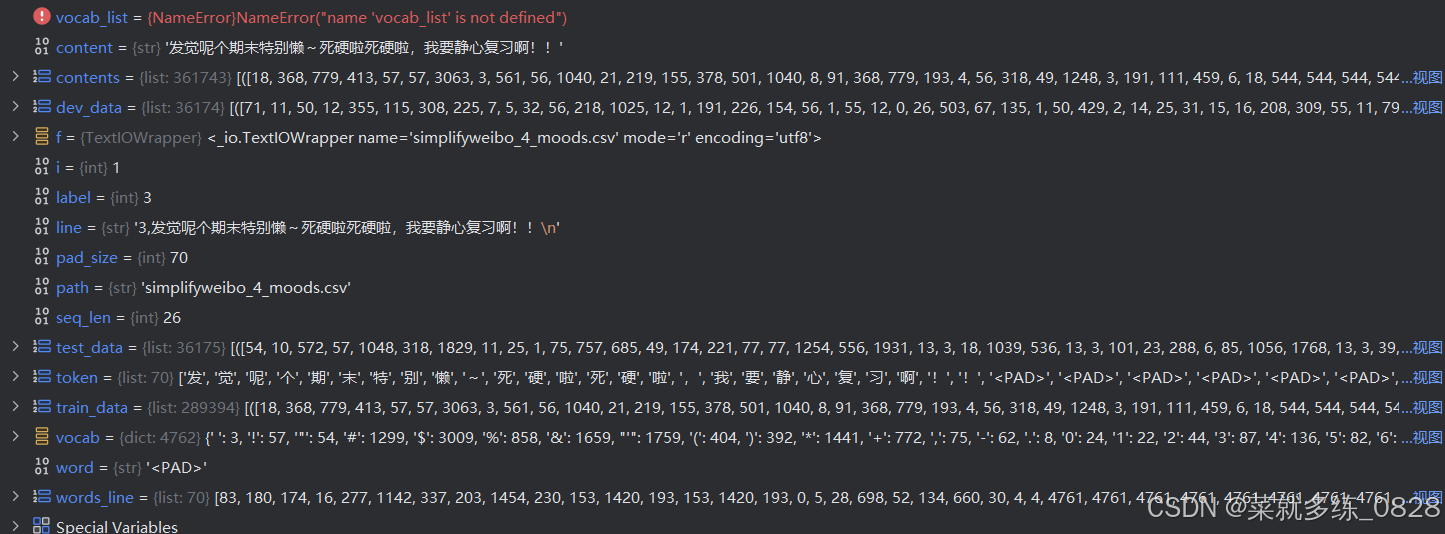
1、读取文件,建立词表
1)代码内容
将下列代码写入命名为vocab_create.py的文件内,方便见名知义及调用内部函数
from tqdm import tqdm # 导入进度条函数
import pickle as pkl # 将序列化对象保存为一个二进制字节流文件MAX_VOCAB_SIZE = 4760 # 词表长度限制长度,总共10000+个无重复的字
UNK,PAD = '<UNK>','<PAD>' # 未知字,padding符号 今天天气真好,我咁要去打球->今天天气真好,我<UNK>要去打球<PAD><PAD><PAD><PAD><PAD>def build_vocab(file_path,max_size,min_freq): # 参数分别表示,文件地址、词表最大长度、剔除的最小词频数"""函数功能:基于文本内容建立词表vocab,vocab中包含语料库中的字”"""tokenizer = lambda x: [y for y in x] # 定义了一个函数tokenizer,功能为分字,返回一个列表,存放每一个字vocab_dic = {} # 用于保存字的字典,键值对,键为词,值为索引号with open(file_path,'r',encoding='UTF-8') as f: # 打开评论文件i = 0for line in tqdm(f): # 逐行读取文件内容,并显示循环的进度条if i == 0: # 跳过文件中的第1行表头无用内容,然后使用continue跳过当前当次循环i += 1continuelin = line[2:].strip() # 使用字符串切片,获取评论内容,剔除标签和逗号,不用split分割,因为评论内容中可能会存在逗号。if not lin: # 如果lin中没有内容则continue,表示没有内容,跳过这一行continuefor word in tokenizer(lin): # 遍历列表里的每一个元素,tokenizer(lin)将每一行的评论中的每个字符分成单独的一个,然后存入列表vocab_dic[word] = vocab_dic.get(word,0)+1 # 统计每个字出现的次数,并以字典保存,字典的get用法,读取键word对应的值,如果没有读取到则将其值表示为0,这里的值表示出现次数,因为这里每出现一次值都加1,键独一无二,值可以相同# 筛选词频大于1的,并排序字典中每个字的值的大小,降序排列,(拆分见下一条代码块)vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq],key=lambda x:x[1],reverse=True)[:max_size] # 先通过for循环加if条件语句筛选出字典的值大于传入参数min_freq的键值对列表,然后对其排序,最后取出前max_size个元素# 建立新的字典vocab_dic = {word_count[0]:idx for idx,word_count in enumerate(vocab_list)} # 列表中存放每个元素是一个元组,元组里存放的是键值对的信息,将每个元组遍历出来,给予索引0的值一个索引,以此给每个字符打上索引值,返回一个字典vocab_dic.update({UNK:len(vocab_dic),PAD:len(vocab_dic)+1}) # 在字典中更新键值对 {'<UNK>':4760,'<PAD>':4761}print(vocab_dic) # 打印全新的字典# 保存字典,方便直接使用pkl.dump(vocab_dic,open('simplifyweibo_4_moods.pkl','wb')) # 此时统计了所有的文字,并将每一个独一无二的文字都赋予了独热编码,将上述的字典保存为一个字节流文件print(f'Vocab size:{len(vocab_dic)}') # 将评论的内容,根据你现在词表vocab_dic,转换为词向量return vocab_dic # 输入文件地址,对内部文件进行处理,设定最大长度,返回该文件里的所有独一无二的字符及其对应的索引的字典,其中包含两个填充字符及其索引,一个是填充未知字,一个是填充符号"""词库的创建"""
# 此处设置下列判断语句来执行的目的是为了防止外部函数调用本文件时运行下列代码
if __name__ == '__main__': # 当自己直接执行本文件代码,会运行main,中的代码vocab = build_vocab('simplifyweibo_4_moods.csv',MAX_VOCAB_SIZE,1)print('vocab')# 如果是调用本代码,则不会执行main中的代码2)部分内容拆分解析
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq],key=lambda x:x[1],reverse=True)[:max_size]vocab_list = [] # 空列表,存放元组形式的空列表
for a in vocab_dic.items(): # 遍历出来字典中的键值对,用a表示if a[1] > min_freq: # 判断键值对的值是否大于min_freqvocab_list.append(a)
vocab_list = sorted(vocab_list,key=lambda x:x[1],reverse=True) # 使用sorted函数排序,key表示排序的依据,使用匿名函数,并索引键值对的值排序,reverse为布尔值,是否降序
vocab_list = vocab_list[ : max_size] # 索引前max_size个值3)代码运行结果

4)调试模式


2、评论删除、填充,切分数据集
1)代码内容
将下列代码放入创建的文件名为load_dataset.py的文件中,后面还有代码需要往里增加
from tqdm import tqdm
import pickle as pkl
import random
import torchUNK,PAD = '<UNK>','<PAD>' # 未知字,padding符号
def load_dataset(path,pad_size=70): # path为文件地址,pad_size为单条评论字符的最大长度contents = [] # 用来存储转换为数值标号的句子,元祖类型,里面存放每一行每一个字的对应词库的索引、每一行对应的标签、每一行的实际长度70及以内vocab = pkl.load(open('simplifyweibo_4_moods.pkl','rb')) # 读取vocab词表文件,rb二进制只读tokenizer = lambda x:[y for y in x] # 自定义函数用来将字符串分隔成单个字符并存入列表with open(path,'r',encoding='utf8') as f: # 打开评论文件i = 0for line in tqdm(f): # 遍历文件内容的每一行,同时展示进度条if i == 0: # 此处循环目的为了跳过第一行的无用内容i += 1continueif not line: # 筛选是不是空行,空行则跳过continuelabel = int(line[0]) # 返回当前行的标签,整型content = line[2:].strip('\n') # 取出标签和逗号后的所有内容,同时去除前后的换行符words_line = [] # 用于存放每一行评论的每一个字对应词库的索引值token = tokenizer(content) # 将每一行的内容进行分字,返回一个列表seq_len = len(token) # 获取一行实际内容的长度if pad_size: # 非0即Trueif len(token) < pad_size: # 如果一行的字符数少于70,则填充字符<PAD>,填充个数为少于的部分的个数token.extend([PAD]*(pad_size-len(token)))else: # 如果一行的字大于70,则只取前70个字token = token[:pad_size] # 如果一条评论种的宁大于或等于70个字,索引的切分seq_len = pad_size # 当前评论的长度# word to idfor word in token: # 遍历实际内容的每一个字符words_line.append(vocab.get(word,vocab.get(UNK))) # vocab为词库,其中为字典形式,使用get去获取遍历出来的字符的值,值可表示索引值,如果该字符不在词库中则将其值增加为字典中键UNK对应的值,words_line中存放的是每一行的每一个字符对应的索引值contents.append((words_line,int(label),seq_len)) # 将每一行评论的字符对应的索引以及这一行评论的类别,还有当前评论的实际内容的长度,以元组的形式存入列表random.shuffle(contents) # 随机打乱每一行内容的顺序"""切分80%训练集、10%验证集、10%测试集"""train_data = contents[ : int(len(contents)*0.8)] # 前80%的评论数据作为训练集dev_data = contents[int(len(contents)*0.8):int(len(contents)*0.9)] # 把80%~90%的评论数据集作为验证数热test_data = contents[int(len(contents)*0.9):] # 90%~最后的数据作为测试数据集return vocab,train_data,dev_data,test_data # 返回词库、训练集、验证集、测试集,数据集为列表中的元组形式if __name__ == '__main__':vocab,train_data,dev_data,test_data = load_dataset('simplifyweibo_4_moods.csv')print(train_data,dev_data,test_data)print('结束')
2)运行结果

3)调试模式
相关文章:
《深度学习》【项目】自然语言处理——情感分析 <上>
目录 一、项目介绍 1、项目任务 2、评论信息内容 3、待思考问题 1)目标 2)输入字词格式 3)每一次传入的词/字的个数是否就是评论的长度 4)一条评论如果超过32个词/字怎么处理? 5)一条评论如果…...
)
RU19.25 Standalone (GI和DB分开打)
参考文档:Patch 36916690 - GI Release Update 19.25.0.0.241015 2.1.1.1 OPatch Utility Information 12.2.0.1.42 or later 2.1.1.2 Validation of Oracle Inventory 分别在GI和Oracle Home下执行 $ <ORACLE_HOME>/OPatch/opatch lsinventory -detail -o…...

探索 Jupyter 核心:nbformat 库的神秘力量
文章目录 探索 Jupyter 核心:nbformat 库的神秘力量1. 背景介绍:为何选择 nbformat?2. nbformat 是什么?3. 如何安装 nbformat?4. 简单的库函数使用方法4.1 读取 Notebook 文件4.2 修改 Notebook 中的单元格4.3 添加 M…...

python+大数据+基于spark的短视频推荐系统【内含源码+文档+部署教程】
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...

Elasticsearch字段数据类型
1. 前言 ES文档的每个字段都至少有一个数据类型,此类型决定了字段值如何被存储以及检索。例如,字符串类型可以定义为text或者keyword,前者用于全文检索,会经过分词后索引;后者用于精准匹配,值会保持原样被…...

简述RESTFul风格的API接口
目录 传统的风格API REST风格 谓词规范 URL命令规范 避免多级URL 幂等 CURD的接口设计 REST响应 响应成功返回的状态码 重定向 错误代码 客户端 服务器 RESTful的返回格式 返回格式 从上一篇文章我们已经初步知道了怎么在VS中创建一个webapi项目。这篇文章来探讨一…...

探索光耦:光耦——不间断电源(UPS)系统中的安全高效卫士
在现代社会,不间断电源(UPS)系统已成为保障关键设备和数据安全的关键设施,广泛应用于企业数据中心、家庭电子设备等场景。UPS能在电力中断或波动时提供稳定电力,确保设备持续运行。而在这套系统中,光耦&…...
at命令和cron命令
第一章 例行性工作 1、单一执行的例行性工作 单一执行的例行性工作:仅处理执行一次就结束了 . 1.1 at命令的工作过程 /etc/at.allow:里面的用户是可以使用at命令的 --- 但实际上这个allow文件不存在,所以指全部的人都可以使用该命令&#…...

搜维尔科技:使用Manus Primel Xsens数据手套直接在Xsens及其插件中捕获手指数据
使用Manus Primel Xsens数据手套直接在Xsens及其插件中捕获手指数据 搜维尔科技:使用Manus Primel Xsens数据手套直接在Xsens及其插件中捕获手指数据...

Avalonia UI获取Popup显示位置,可解决异常显示其他应用程序的左上角
1.通过 PlacementTarget 获取位置 如果 Popup 是相对于某个控件(PlacementTarget)显示的,你也可以获取该控件的位置,然后计算 Popup 的相对位置。 // 假设 popup 是你的 Popup,target 是你的目标控件(Pla…...

新版Win32高级编程教程-学习笔记01:应用程序分类
互联网行业 算法研发工程师 目录 新版Win32高级编程教程-学习笔记01:应用程序分类 控制台程序 强烈注意 窗口程序 启动项 程序入口函数 库程序 静态库 动态库程序 几种应用程序的区别 控制台程序 本身没有窗口,其中的doc窗口,是管…...
无需编程知识 如何用自适应建站系统创建专业网站 带完整的安装代码包以及搭建部署教程
系统概述 自适应建站系统是一款功能强大、易于使用的建站工具。它采用了先进的技术和设计理念,旨在为用户提供一个简单、高效的建站平台。该系统支持多种语言和多种设备,能够自动适应不同屏幕尺寸和分辨率,确保网站在各种终端上都能呈现出最…...
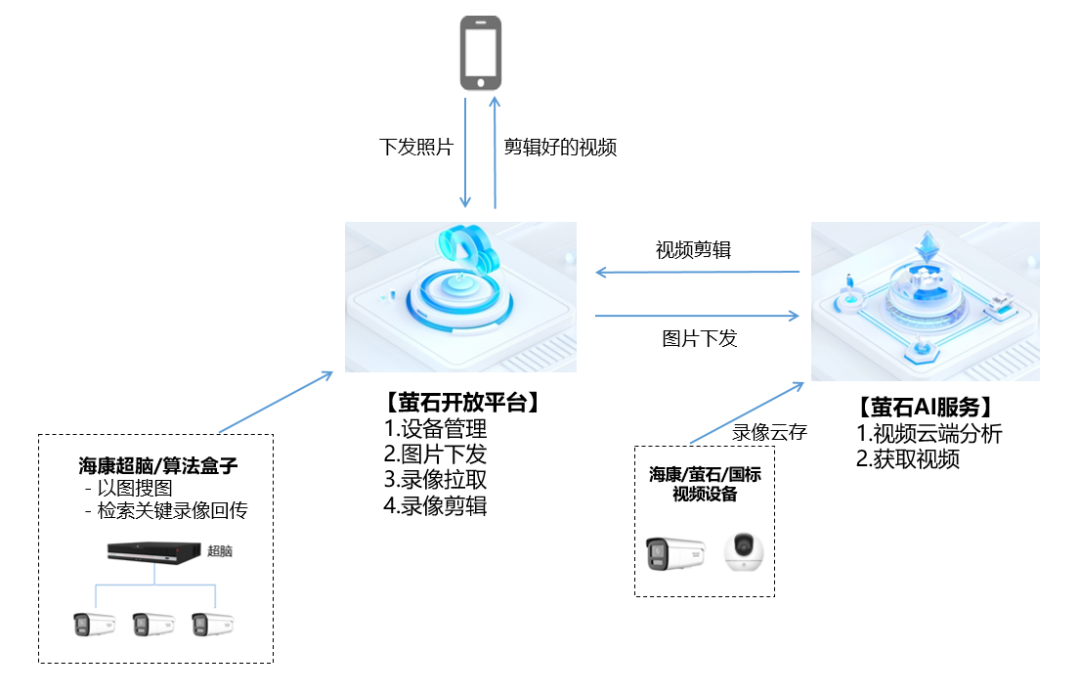
萤石云服务支持云端视频AI自动剪辑生成
萤石视频云存储及媒体处理服务是围绕IoT设备云端存储场景下的音视频采集、媒体管理、视频剪辑和分发能力的一站式、专业云服务,并可面向广大开发者提供复杂设备存储场景下的完整技术方案。目前该服务新增了视频剪辑功能,支持将视频片段在云端进行裁剪并拼…...

Flink移除器Evictor
前言 在 Flink 窗口计算模型中,数据被 WindowAssigner 划分到对应的窗口后,再经过触发器 Trigger 判断窗口是否要 fire 计算,如果窗口要计算,会把数据丢给移除器 Evictor,Evictor 可以先移除部分元素再交给 ProcessFu…...

R语言实现多元线性回归高杠杠点,离群点分析
14a set.seed(1) x1 = runif(100) x2 = 0.5 * x1 + rnorm(100)/...

overfrp内网穿透:使用域名将内网http/https服务暴露到公网
项目地址:https://github.com/sometiny/overfrp 使用overfrp部署穿透服务器,绑定域名后,可使用域名访问内网的http/https服务。 用例中穿透服务器和内网机器之间的访问全链路加密,具有ssh2相当的安全级别。!…...

springboot034在线商城系统设计与开发-代码(论文+源码)_kaic
毕 业 设 计(论 文) 题目:ONLY在线商城系统设计与实现 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本ONLY在线商城系统…...
?为什么要遵守第三范式?)
什么是第三范式(3NF)?为什么要遵守第三范式?
第三范式(Third Normal Form, 3NF)是数据库设计中的一个重要概念,它是对关系型数据库规范化的一种标准。 在数据库设计中,通过将数据表按照一定的规则进行分解,可以减少数据冗余和提高数据的一致性。 3NF 是建立在第…...

大数据比对,shell脚本与hive技术结合
需求描述 从主机中获取加密数据内容,解密数据内容(可能会存在json解析)插入到另一个库中,比对原始库和新库的相同表数据的数据一致性内容。 数据一致性比对实现 上亿条数据,如何比对并发现两个表数据差异 相关流程…...

【Linux安全基线】- CentOS 7/8安全配置指南
在企业业务的生产环境中,Linux服务器的安全性至关重要,尤其是对于具有超级用户权限的root账号。滥用或被入侵后,可能会造成数据泄露、系统损坏等严重安全问题。为了减少这种风险,本文将详细介绍如何通过一系列安全措施来增强CentO…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

AB包相关知识
Lua与AB包/Addressables以及YooAsset 摘自千问: Lua 是菜谱(逻辑):决定了菜怎么做,味道如何。因为你需要随时换菜谱(热更新),所以菜谱不能死板地印在墙上(编译进主包&a…...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...

Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能
Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

洛谷-【动态规划1】动态规划的引入4
P1077 [NOIP 2012 普及组] 摆花题目描述小明的花店新开张,为了吸引顾客,他想在花店的门口摆上一排花,共 m 盆。通过调查顾客的喜好,小明列出了顾客最喜欢的 n 种花,从 1 到 n 标号。为了在门口展出更多种花,…...

量子计算中的随机基准测试与Grover算法实现
1. 量子计算中的随机基准测试原理与应用随机基准测试(Randomized Benchmarking, RB)是量子计算领域评估量子门操作保真度的黄金标准方法。与传统直接测量单个量子门误差不同,RB通过随机量子门序列的统计特性来提取平均门保真度,这种方法对状态制备和测量…...