【动手学深度学习】7.5 批量规范化(个人向笔记)
- 训练深层神经网络是十分困难的,特别是在较短的时间内使它们收敛更加棘手。而本节的批量规范化(batch normalization) 可以持续加速深层网络的收敛速度
- 结合下节会介绍道德残差块,批量规范化使得研究人员能够训练100层以上的网络
1. 训练深层网络
- 为什么要批量规范化层呢?下面回顾一下训练神经网络时出现的实际挑战
- 首先,数据的预处理方式通常会对最终结果产生巨大影响。在前面我们预测房价实战中,我们第一步是标准化输入特征,使其均值为 0,方差为 1。这种标准化可以很好地配合我们的优化器,因为它可以将参数的量级进行同一
- 对于 MLP 或 CNN。当我们训练时,中间层的变量可能有更广的变化范围:无论是沿着从输入到输出的层,跨同一层中的单元,或是随着时间的推移,模型参数随着训练更新变幻莫测
- 批量规范化的发明者非正式地假设,这些变量分布中的这种偏移可能会阻碍网络收敛。如果一个层的可变值是另一个层的100倍,这可能需要学习率进行补偿
- 更深层的网络很复杂,容易过拟合,这意味着正则化变得更加重要
- 批量规范化可以应用于单个可选层,也可以应用到所有层。原理如下:在每次训练迭代中,我们首先规范化输入,即通过减去均值并除以标准差,其中两者均基于当前小批量处理。接下来我们应用比例系数和比例偏移。由于是基于批量统计的标准化,所以i叫批量规范化
- 如果我们尝试使用大小为1的小批量应用批量规范化,我们将无法学到任何东西。这是因为在减去均值之后,每个隐藏单元将为0。 所以,只有使用足够大的小批量,批量规范化这种方法才是有效且稳定的。 请注意,在应用批量规范化时,批量大小的选择可能比没有批量规范化时更重要。

- 在训练过程中,中间层的变化幅度不能过于剧烈,而批量规范化将每一层主动居中,并将它们重新调整为给定的平均值和大小

- 由于某些尚未被明确的原因,优化中各种噪声源通常会导致更快的训练和较少的过拟合,这种变化似乎是正则化的一种形式
- 另外,批量规范化层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范化)中的功能不同。 在训练过程中,我们无法得知使用整个数据集来估计平均值和方差,所以只能根据每个小批次的平均值和方差不断训练模型。 而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和方差。
- 下面来看是如何在实践中工作的
2. 批量规范化层
- 回想一下,批量规范化和其他层之间的一个关键区别是批量规范化在完整的小批量上运行,因此我们不能像以前在引入其他层时那样忽略批量大小。
- 我们在下面讨论这两种情况:全连接层和卷积层,他们的批量规范化实现略有不同。
2.1 全连接层

2.2 卷积层
- 对于卷积层,可以在卷积层之后和非线性激活函数之前进行批量规范化,每个通道都有自己的拉伸和偏移参数,两个参数都是标量
- 假设我们的小批量包含 m 个样本,并且对于每个通道,卷积的输出具有高度 p和宽度 q。 那么对于卷积层,我们在每个输出通道的 mpq 个元素上同时执行每个批量规范化。 因此,在计算平均值和方差时,我们会收集所有空间位置的值,然后在给定通道内应用相同的均值和方差,以便在每个空间位置对值进行规范化。
2.3 预测过程中的批量规范化
- 批量规范化在训练模式和预测模式下的行为通常不同
- 将训练好的模型用于预测时,我们不再需要样本均值中的噪声以及在微批次上估计每个小批次产生的样本方差了
- 我们可能需要使用我们的模型对逐个样本进行预测。 一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出
- 和暂退法一样,批量规范化层在训练模式和预测模式下的计算结果也是不一样的
3. 从零开始实现
- 下面是实现代码



- 我们现在可以创建一个正确的BatchNorm层。 这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新
- 我们的层将保存均值和方差的移动平均值,以便在模型预测期间随后使用

4. 使用批量规范化层的LeNet
- 为了更好地理解BatchNorm,下面我们将其应用于LeNet模型。批量规范化是在卷积层或全连接层之后、相应的激活函数之前应用的。

- 我们再在Fashion-MNIST数据集上训练网络,但不同的是学习率大得多,下面的补充内容会提到为什么可以上更大的学习率

5. 简明实现
- 我们可以直接使用深度学习框架中定义的BatchNorm。 代码看起来几乎与我们上面的代码相同。

6. 补充
- 下面是我在b站上看的一个视频的笔记,看了之后感觉清晰了很多:https://www.bilibili.com/video/BV12d4y1f74C/?spm_id_from=333.880.my_history.page.click&vd_source=bab99a4bc7d540abf82733d55fa02cca
- 在网络学习的过程中,全一层的输出就是后一层的输入,因此由于参数的更新,每层的输入分布都在发生变化,这会导致网络很难收敛

- 而为了能够收敛,那么就需要:① 学习率不能太高。 ② 参数初始化准确。 ③ 网络层数不能太多。
- 而神经网络的研究人员发现,这个现象是由于每层分布的差异过大,且无法预测而导致的。那么如果让每一个batch在每一层中都服从类似的分布,就可以解决这一的问题了

- 加上伽马和贝塔是因为我们不想每层输入的分布都相同

- 在加上了Batch Normalization,那么我们就可以:① 使用较大的学习率。 ② 参数初始化不敏感。 ③ 加快网络训练。
- 在测试推理阶段,我们仍然可以使用训练得到的伽马和贝塔两个参数。但是训练集和测试集的样本分布不完全一致,并且我们可能只使用一个样本进行测试,无法计算均值和标准差。因此我们需要保存并使用训练过程中的结果来辅助运算
- 假设我们有30个样本,每五个样本构成一个batch进行训练,完整遍历一次训练集就需要六个batch,那么对于第一层神经网络来说我们会得到六个均值的历史数值,那么接下来通过指数加权,获得这六个均值的平均值,下面的m可以看作是对历史的保留,非常类似于随机梯度下降中动量的概念,在torch框架中也直接将这个变量命名为 momentum,默认值为0.1
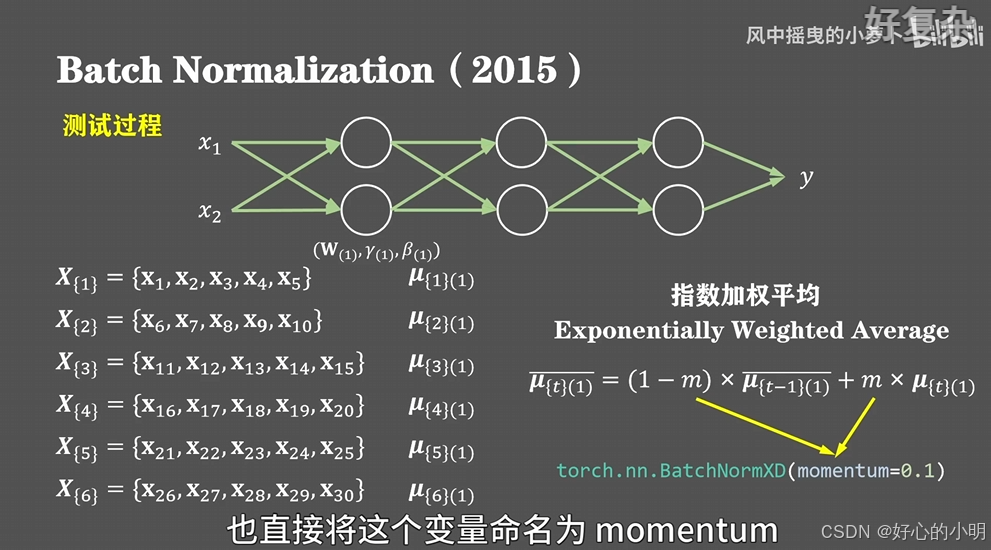
- Batch Normalization可以加速神经网络收敛。但是①仅在样本数量较多时有效。② 对RNN或序列数据性能较差。 ③ 分布式运算时影响效率
相关文章:
【动手学深度学习】7.5 批量规范化(个人向笔记)
训练深层神经网络是十分困难的,特别是在较短的时间内使它们收敛更加棘手。而本节的批量规范化(batch normalization) 可以持续加速深层网络的收敛速度结合下节会介绍道德残差块,批量规范化使得研究人员能够训练100层以上的网络 1.…...

111 - exercise 5
一 public class Dummy {private static int a 3;private static int b 5;private static int c 7;public static void main(String... arguments) {int a 1, b 2;System.out.println("" a (a - b) c);} }这个Java程序中有两个a和b变量,一个是类…...
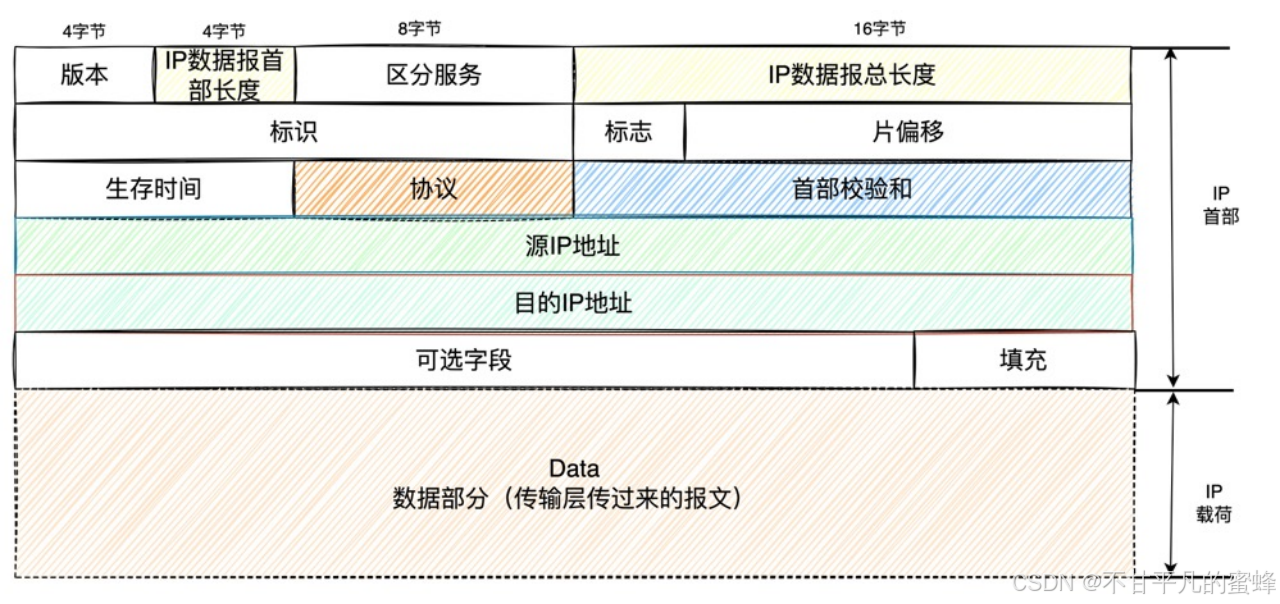
第二十五:IP网络层的数据,IP数据报
在数据链路层传输的数据叫帧,帧是数据链路层的传输单元。 那么在IP网络层的数据也有一个叫法IP数据报。 IP数据报 IP数据报首部 数据。 数据是传输层传递过来的报文;IP数据报首部格式如下: IP 报头的最小长度为 20 字节,上图…...

三菱FX3UPLC机械原点回归- DSZR/ZRN指令
机械原点回归用指令的种类 产生正转脉冲或者反转脉冲后,增减当前值寄存器的内容。可编程控制器的定位指令,可编程控制器的电源0FF后,当前值寄存器清零,因此上电后,请务必使机械位置和当前值寄存器的位置相吻合…...
粘包现象解决方案、socketserver实现并发)
网络通信与并发编程(三)粘包现象解决方案、socketserver实现并发
粘包现象解决方案、socketserver实现并发 文章目录 粘包现象解决方案、socketserver实现并发一、粘包现象解决方案1.发送数据大小2.发送数据信息 二、socketserver实现并发1.tcp版的socketserver并发2.udp版的socketserver并发 一、粘包现象解决方案 1.发送数据大小 有了上一…...

使用Uniapp开发微信小程序实现一个自定义的首页顶部轮播图效果?
在Uniapp中开发微信小程序,并实现自定义首页顶部轮播图的效果,可以通过使用Uniapp的组件如swiper和swiper-item来完成。这是一个常见的需求,下面是一个完整的示例代码,展示如何实现一个简单的自定义轮播图效果。 创建页面结构 首…...

软硬连接及动静态库
目录 一、理解文件系统在磁盘中的存储 (1)inode是什么 (2)硬链接 (3)软链接 二、动静态库 (1)静态库 二、动态库 三、在链接动静态库的时候如何不用指定路径 一、理解文件系统…...
vue3.0 + vite:中使用 sass
1、安装依赖 npm i sass sass-loader --save-dev 在项目的src/assets文件夹下新建style/index.scss 文件 2、在 vite.config.ts 中加: resolve: {alias: {: fileURLToPath(new URL(./src, import.meta.url))} }, css: {// 配置 SCSS 支持preprocessorOptions: {s…...

搭建`mongodb`副本集-开启权限认证 mongo:7.0.5
搭建mongodb副本集-开启权限认证 mongo:7.0.5 1.5.1、创建文件 创建配置文件保存目录和数据保存目录 mkdir -p /data/mongodb/{/conf,/data,/logs}生成和设置权限 这个文件一定要在一个服务里面生成然后复制到其它服务器,所有服务器的这个key一定是相同的。 op…...

智能工厂的软件设计 由“原力“篇引发的思考: 回顾、展望和本位 之2 修订稿之2
Q15、《“工厂”篇》其前的《“公共逻辑”》篇 提出的三个专门工厂(抽象/项目/产品)以及 再之前 讨论的各自的“专项运作逻辑”(辩证/数理/形式)之间协作的“整体概念运作”“概念模式”给出一个标准的“公共逻辑”的“语言模板”…...

2025选题推荐|基于SpringBoot的幼儿园智能管理与监控系统的设计与实现
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,…...

mqtt客户端订阅一直重复连接?
文章 前言错误场景问题分析解决方案后言 前言 ✨✨ 他们是天生勇敢的开发者,我们创造bug,传播bug,毫不留情地消灭bug,在这个过程中我们创造了很多bug以供娱乐。 前端bug这里是博主总结的一些前端的bug以及解决方案,感兴…...

SegFormer: 一个基于Transformer的高效视觉图像分割算法
今天我分享一篇关于 Transformer 架构在图像视觉分割中的应用的文章,主题是 SegFormer。SegFormer 是一种新颖的语义分割方法,它结合了无位置编码的层次化 Transformer 编码器和轻量级 All-MLP 解码器,避免了传统方法中的复杂设计,…...

SoC芯片中Clock Gen和Reset Gen的时钟树综合
社区目前已经开设了下面列举的前四大数字后端实战课程,均为直播课,且均是小编本人亲自授课!遇到项目问题,都可以远程一对一指导解决具体问题。小编本人是一线12年后端经验的数字后端工程师。想找一线IC后端技术专家亲自带你做后端…...

学习资料:电子标签拣货技术
导语 大家好,我是社长,老K。专注分享智能制造和智能仓储物流等内容。 新书《智能物流系统构成与技术实践》 完整版文件和更多学习资料,请球友到知识星球【智能仓储物流技术研习社】自行下载。 这份文件主要介绍了电子标签拣货技术,…...

Git 提交规范参考
Git 提交规范参考 feat 增加新的业务功能fix 修复业务问题/BUGperf 优化性能style 更改代码风格, 不影响运行结果refactor 重构代码revert 撤销更改test 测试相关, 不涉及业务代码的更改docs 文档和注释相关chore 更新依赖/修改脚手架配置等琐事workflow 工作流改进ci 持续集成…...

【前端】Matter:物体的高级控制
在 Matter.js 中,除了简单的物体创建和碰撞检测外,还可以通过高级控制实现更复杂的物理交互与模拟效果。本教程将介绍如何使用 约束 (Constraint)、复合物体 (Composite) 以及如何进行 运动与旋转控制,来实现链条、摆钟等效果,以及…...

ASP.NET Core 路由规则 MapControllerRoute、MapDefaultControllerRoute、MapController
MapControllers 来映射属性路由控制器。 资料...

linux命令之less用法
less 分屏上下翻页浏览文件内容 补充说明 less命令 的作用与more十分相似,都可以用来浏览文字档案的内容,不同的是less命令允许用户向前或向后浏览文件,而more命令只能向前浏览。用less命令显示文件时,用PageUp键向上翻页&…...

试用cursor的简单的记录
快下班时又饿了,饿了几个小时了。中午那点饭,没够顶到下班。难怪店家说饭可以随便加。 所以不编码了,本周任务也超额完成了,这种状态再去编码调试,搞不好会写出自己不认识的代码。 本周工作中,新的事务是…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

统信UOS浏览器书签同步难题?一招搞定所有新用户默认书签配置
统信UOS浏览器书签批量配置:系统管理员的高效部署指南在企业或教育机构的IT运维工作中,统信UOS作为国产操作系统的代表,其浏览器书签的统一管理常常成为系统管理员面临的挑战。想象一下,每当有新员工入职或学生入学,都…...

昇腾CANN cmake 实战:CANN CMake 构建系统——跨平台编译配置与模块化管理
8 个 CANN 仓库各需独立构建(ops-transformer/ops-nn/hccl/ge/…)→ 手写 8 套 CMakeLists.txt(CANN 路径判断、跨 NPU 型号编译、第三方库兼容)。cmake 仓库提供统一的 FindCANN.cmake CANNConfig.cmake 模板——任何仓库只需 f…...

国产大模型新王登基?Qwen3.7-Max全球第五、编程Agent登顶,千问APP免费体验全攻略
AI前线观察 | 2026.05.25 就在刚刚过去的阿里云峰会上,通义千问甩出了一张“王炸”。万亿参数MoE架构的旗舰模型Qwen3.7-Max正式接入千问APP、PC端及网页端。这不仅仅是一次版本更新,更是国产大模型在权威第三方榜单中首次稳居全球前五、国产第一的里程碑…...

3步搞定B站缓存视频转换:m4s转MP4的终极解决方案
3步搞定B站缓存视频转换:m4s转MP4的终极解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的视频&a…...