【MySQL】 表的增删操作
目录
1.Create(增)
1.1.单行数据 + 全列插入
1.2.多行数据 + 指定列插入
1.3.插入否则更新
1.4.替换数据(REPLACE)
2.Delete(删)
2.1.删除表中的某个条目
2.2.删除整张表数据
2.3.截断表
1.Create(增)
在SQL中,INSERT INTO语句用于向数据库表中添加新记录。
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...// 解释: value_list: value, [, value] ...
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- SQL中的每个value_list都表示插入的一条记录,每个value_list都由若干待插入的列值组成。
- SQL中的column列表,用于指定每个value_list中的各个列值应该插入到表中的哪一列。
- INSERT [INTO] table_name:INSERT INTO是固定的SQL关键字,用于指示要执行的操作是插入新记录。table_name是您要插入数据的表的名称。在某些数据库系统中,INTO关键字是可选的,但在大多数情况下都会使用。
- [(column [, column] ...)]:这是一个可选的部分,用于指定要插入数据的列。如果您提供了列名,那么VALUES子句中的值列表必须按照相同的顺序匹配这些列。如果您省略了列名,那么VALUES子句中的值必须按照表中列的顺序提供,并且必须包含所有非空列的值。
- VALUES (value_list) [, (value_list)] ...:VALUES子句用于指定要插入的值。value_list是一个逗号分隔的值列表,这些值将插入到指定的列中。如果您要插入多行数据,可以在VALUES子句中使用多个value_list,每个value_list用逗号分隔,并且整个列表用括号括起来。每个value_list中的值数量必须与指定的列数相匹配。
注释部分:// 解释: value_list: value, [, value] ...
- 这里的注释说明了value_list的结构。每个value_list由一个或多个值组成,这些值之间用逗号分隔。这些值对应于您要插入的列的值。如果您有多个列要插入值,那么每个value_list中就会有多个值,这些值按照您在INSERT INTO语句中指定的列的顺序排列。
为了方便进行演示,下面创建一个学生表,表当中包含自增长的主键id、学号、姓名和QQ号。如下:
create table students(id int unsigned primary key auto_increment,sn int unsigned not null unique comment '学号',name varchar(20) not null comment '姓名',qq varchar(15) unique comment 'qq号码'
);desc students;
1.1.单行数据 + 全列插入
当我们在使用insert语句向学生表中插入记录,每次向表中插入一条记录,并且插入记录时不指定column列表,表示按照表中默认的列顺序进行全列插入,因此插入的每条记录中的列值需要按表列顺序依次列出。如下:
insert into students values(100, 1000, '唐玄奘', null);
insert into students values(101, 1023, '孙悟空', null);
select * from students;

1.2.多行数据 + 指定列插入
使用insert语句也可以一次向表中插入多条记录,插入的多条记录之间使用逗号隔开,并且插入记录时可以只指定某些列进行插入。如下:
insert into students(sn, name) values (123, '曹操'), (187,'刘备');
select * from students;

1.3.插入否则更新
有时候我们在向表中插入新记录时,由于 主键 或者 唯一键 对应的值已经存在而导致我们插入失败。
desc students;
select * from students;
insert into students (id,sn,name) values (100,1000,'唐僧');
这时如果我们还想插入我们的数据就可以选择性的进行同步更新操作:
您提供的INSERT ... ON DUPLICATE KEY UPDATE语法描述是正确的。这是MySQL特有的一个扩展语法,用于处理在插入记录时可能发生的键冲突(通常是主键冲突或唯一键冲突)。这个语法允许你在尝试插入一条记录时,如果因为键冲突而失败,则自动更新表中已存在的记录。
下面是该语法的详细解释:
INSERT ... ON DUPLICATE KEY UPDATE column1=value1 [, column2=value2] ...; - INSERT ...:这部分与标准的INSERT INTO语句相同,用于指定要插入的表和值。
- ON DUPLICATE KEY UPDATE:这是一个条件子句,它告诉MySQL在发生键冲突时应该执行什么操作。具体来说,如果尝试插入的记录与表中已存在的记录在主键或唯一键上冲突,则不执行插入操作,而是执行UPDATE子句指定的更新操作。
- column1=value1 [, column2=value2] ...:这部分指定了在发生键冲突时需要更新的列和对应的值。你可以指定一个或多个列进行更新,每个列和值的对之间用逗号分隔。
这个语法的作用如下:
- 如果表中没有冲突数据:则直接插入指定的记录。
- 如果表中有冲突数据:则不插入新记录,而是将表中已存在的、与插入记录冲突的记录的指定列更新为新的值。
需要注意的是,这个语法依赖于表中的主键或唯一键约束。如果没有这些约束,MySQL将无法检测到冲突,因此也就无法执行更新操作。此外,这个语法是MySQL特有的,不是SQL标准的一部分,因此在其他数据库管理系统中可能无法使用。
举个例子,假设我们有一个名为students的表,包含id(主键)、name和score三列。我们可以使用以下语句来插入新记录,或者在发生冲突时更新已有记录的score列:
INSERT INTO students (id, name, score) VALUES (1, 'Alice', 90) ON DUPLICATE KEY UPDATE score=90;在这个例子中,如果id为1的记录已经存在,那么它的score列将被更新为90(尽管这里看起来像是没有变化,但在实际应用中,你可能会根据某些条件来动态地设置这个值)。如果id为1的记录不存在,那么将插入一条新记录。
例如:这次我们继续向学生表中刚才的插入记录。如下:
select * from students;insert into students (id,sn,name) values(100, 1000, '唐僧') on duplicate key update name= '唐僧', sn= 1010;select * from students; 
可以看到在冲突的情况下我们也确实更新了数据。
说明:执行插入否则更新的SQL后,可以通过受影响的数据行数来判断本次数据的插入情况:
- 0 rows affected:表中有冲突数据,但冲突数据的值和指定更新的值相同。
- 1 row affected:表中没有冲突数据,数据直接被插入。
- 2 rows affected:表中有冲突数据,并且数据已经被更新。
1.4.替换数据(REPLACE)
REPLACE INTO语句是MySQL特有的一个语法,它用于处理数据插入时的键冲突。
与INSERT ... ON DUPLICATE KEY UPDATE不同,REPLACE INTO在遇到键冲突时不是更新已有记录,而是先删除冲突的记录,然后插入新记录。
下面是REPLACE INTO语句的详细解释:
REPLACE INTO table_name (column1, column2, ...) VALUES (value1, value2, ...); - REPLACE INTO:这是指示MySQL执行替换操作的关键字。
- table_name:要插入或替换数据的表的名称。
- (column1, column2, ...):要插入或替换数据的列的名称。
- (value1, value2, ...):与列名称相对应的值,这些值将被插入或用于替换。
当您执行REPLACE INTO语句时,MySQL会尝试将新记录插入到表中。
- 如果表中已经存在具有相同主键或唯一键值的记录,MySQL会先删除那条记录,然后插入新记录。
- 如果表中不存在冲突的记录,MySQL则直接插入新记录。
需要注意的是,REPLACE INTO可能会导致数据的丢失,因为它会删除冲突的记录。因此,在使用REPLACE INTO之前,请确保您了解这一行为,并且确实希望删除冲突的记录。
此外,REPLACE INTO语法与INSERT INTO非常相似,只需要将INSERT替换为REPLACE即可。但是,由于REPLACE INTO的潜在破坏性,建议在使用时格外小心。
举个例子,我们使用replace into来替换掉我们的孙悟空

我们可以使用以下语句来插入新记录,或者在发生冲突时替换已有记录:
REPLACE INTO students (sn, name) VALUES (1023, '孙行者'); 在这个例子中,如果sn为1023的记录已经存在,那么那条记录将被删除,然后插入一条新的记录,其sn为1023,name为'孙行者'。如果sn为1023的记录不存在,那么将插入一条新记录。

执行替换数据的SQL后,也可以通过受影响的数据行数来判断本次数据的插入情况:
- 1 row affected:表中没有冲突数据,数据直接被插入。
- 2 rows affected:表中有冲突数据,冲突数据被删除后重新插入。
2.Delete(删)
删除数据的SQL如下:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]; - SQL中大写的表示关键字,[ ]中代表的是可选项。
- 在删除数据之前需要先找到待删除的记录,delete语句中的where、order by和limit就是用来定位数据的。
- DELETE FROM table_name:这是删除操作的基本形式,指示要从哪个表中删除记录。table_name是您要删除数据的表的名称。
- [WHERE ...]:WHERE子句是可选的,但非常重要,因为它用于指定删除哪些记录。如果不使用WHERE子句,表中的所有记录都将被删除,这通常是不希望发生的情况。WHERE子句后面跟着一个条件表达式,只有满足该条件的记录才会被删除。
- [ORDER BY ...]:ORDER BY子句也是可选的,它用于指定删除记录的顺序。这在某些情况下很有用,比如当您希望按照特定的顺序删除记录时(尽管数据库引擎在删除记录时可能不会严格遵循这个顺序,因为删除操作本身通常不保证顺序)。ORDER BY子句后面跟着一个或多个列名,以及可选的排序方向(ASC升序或DESC降序)。
- [LIMIT ...]:LIMIT子句同样是可选的,它用于限制删除操作影响的记录数。这对于批量删除记录时避免一次性删除过多记录导致性能问题或事务日志过大非常有用。LIMIT子句后面跟着一个数字,表示要删除的记录的最大数量。
需要注意的是,DELETE语句是一个危险的操作,因为它会永久删除表中的记录(除非您使用了事务,并且在删除后执行了回滚操作)。因此,在执行DELETE语句之前,请务必确保您已经备份了数据,并且确实希望删除这些记录。
此外,DELETE语句通常会触发与表相关联的删除触发器(如果有的话),并且会影响与该表相关联的索引和约束。
举个例子,假设我们有一个名为students的表,包含id、name和score三列。我们可以使用以下语句来删除score小于60的记录:
DELETE FROM students WHERE score < 60;如果我们想进一步限制删除操作,只删除满足条件的记录中的前10条,我们可以使用LIMIT子句:
DELETE FROM students WHERE score < 60 LIMIT 10;在某些情况下,你可能需要按照特定的顺序删除记录,或者限制删除的记录数量。MySQL 8.0支持在DELETE语句中使用ORDER BY和LIMIT子句。
DELETE FROM students WHERE score < 60 ORDER BY score DESC LIMIT 5;上面的语句会删除students表中score字段值小于60的记录中,按score降序排列的前5条记录。
注意:虽然MySQL允许在DELETE语句中使用ORDER BY,但并非所有数据库管理系统都支持这一用法。此外,ORDER BY在DELETE语句中的行为可能因具体的数据库实现而异,有时可能不会严格按照指定的顺序删除记录。
2.1.删除表中的某个条目
我们先来准备一张测试表,表中包含一个自增长的主键id和姓名。如下:
create table test( id int primary key auto_increment, name varchar(10));desc test;insert into test(name) values ('A'),('B'),('C');select * from test;

接下来我们要删除B,删除B首先要确定B是存在的!!
select * from test where name = 'B';
好的,B确实存在,这个时候我们才可以删除。
delete from test where name = 'B';
select * from test; \
\
2.2.删除整张表数据
删除整表的操作很简单,我们只要不在delete后面加where子句,这样我们就能够删除整个表了
注意:删除整表操作要慎用!
我们先来准备一张测试表,表中包含一个自增长的主键id和姓名。如下:
create table test2( id int primary key auto_increment, name varchar(10));desc test2;insert into test2(name) values ('A'),('B'),('C');select * from test2;
这里我们顺便看一下test2表的主键值的相关信息,方便我们解释下面的截断表问题:
show create table test2 \G 
这个4就是下次的增长值。即下次插入数据的id值
delete from test2;
select * from test2;
这里我们再看一下test2表的自增长值的相关信息
show create table test2 \G
我们发现啊,这个auto_increment的值怎么没变啊!!!
我们在插入一些数据进行验证:
insert into test2(name) values ('D'), ('E'), ('F');select * from test2;

再次查看主键值的相关信息:
show create table test2 \G
到这里我们也就得出结论了:
在MySQL中,当你使用DELETE语句删除表中的所有记录时,表的AUTO_INCREMENT计数器不会被重置。这意味着,如果你随后插入一条新记录,该记录将使用被删除记录之后的下一个AUTO_INCREMENT值。
要重置AUTO_INCREMENT值,你可以使用ALTER TABLE语句。
例如,要将AUTO_INCREMENT值重置为1(或者任何你希望的起始值,只要它大于当前表中任何记录的id值,以避免冲突),你可以执行以下语句:
ALTER TABLE test2 AUTO_INCREMENT = 1; 但是,请注意,在生产环境中重置AUTO_INCREMENT值可能会导致数据完整性问题,特别是如果你有其他依赖于这些AUTO_INCREMENT值的外部系统或数据。因此,在重置之前,请确保你了解这一操作的潜在影响。
另外,如果你只是想清空表中的数据而不关心AUTO_INCREMENT值,那么使用TRUNCATE TABLE语句可能是一个更好的选择。TRUNCATE TABLE不仅会删除表中的所有记录,还会重置AUTO_INCREMENT值,并且通常比DELETE语句执行得更快,因为它不会逐行删除记录,而是直接释放整个表的数据页。但是,请注意,TRUNCATE TABLE也会删除表上的所有触发器,并且不能用于有外键约束的表(除非先删除或禁用这些约束)。
2.3.截断表
- TRUNCATE 是 SQL 中的一个命令,用于快速删除表中的所有记录,并通常重置表的自增(AUTO_INCREMENT)计数器(如果表中有这样的字段)。
- 与 DELETE 命令不同,TRUNCATE 不会逐行删除数据,而是直接释放表的数据页和索引页,这使得它在处理大表时通常比 DELETE 更快。
以下是 TRUNCATE 命令的一些关键特性和注意事项:
- 快速删除:
- TRUNCATE 通过释放整个表的数据页和索引页来删除数据,而不是像 DELETE 那样逐行删除。这使得 TRUNCATE 在处理包含大量记录的表时非常高效。
- 重置自增计数器:
- 在大多数数据库系统中,TRUNCATE 会将表的自增(AUTO_INCREMENT)计数器重置为初始值(通常是1,除非之前已经设置了其他起始值)。这意味着在 TRUNCATE 之后插入的第一条新记录将获得自增字段的下一个可用值。
- 不激活触发器:
- TRUNCATE 不会激活与表关联的 DELETE 触发器。如果你依赖于触发器来执行某些操作(如记录删除日志),那么 TRUNCATE 可能不是最佳选择。
- 外键约束:
- 如果表被其他表的外键约束所引用,那么通常不能对该表执行 TRUNCATE 操作。在这种情况下,你需要先删除或禁用这些外键约束,或者改用 DELETE 语句来删除记录。
- 权限要求:
- 执行 TRUNCATE 操作通常需要具有对表的 DROP 权限,这通常比对表执行 DELETE 操作所需的权限更高。
- 无法回滚:
- TRUNCATE 操作通常是一个 DDL(数据定义语言)命令,而不是 DML(数据操作语言)命令。因此,它通常不经过事务日志记录(或者记录方式与 DELETE 不同),并且一旦执行,就无法通过事务回滚来恢复数据。这意味着在使用 TRUNCATE 之前,必须确保你真的想要删除所有数据,并且已经做好了备份。
- 表空间:
- 在某些数据库系统中(如 MySQL 的 InnoDB 存储引擎),TRUNCATE 不会立即释放表所占用的物理存储空间,而是将其标记为可重用。要真正释放表空间,可能需要执行额外的操作,如 OPTIMIZE TABLE。然而,在其他数据库系统中(如 PostgreSQL),TRUNCATE 通常会释放表所占用的存储空间。
- 日志记录:
- 由于 TRUNCATE 通常是一个 DDL 命令,它可能会记录在数据库的DDL日志中,而不是DML日志中。这意味着它可能不会像 DELETE 那样详细地记录每行数据的删除操作。
总之,TRUNCATE 是一个强大的工具,可以快速清空表并重置自增计数器,但它也有一些重要的限制和注意事项。在使用之前,请确保你了解这些限制,并且已经做好了适当的备份和计划。如果你需要保留触发器激活、事务回滚能力或精细的日志记录,那么 DELETE 可能是更合适的选择。
截断表的SQL语法如下:
TRUNCATE [TABLE] table_name;说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- truncate只能对整表操作,不能像delete一样针对部分数据操作。
- truncate实际上不对数据操作,所以比delete更快。
- truncate在删除数据时不经过真正的事务,所以无法回滚。
- truncate会重置AUTO_INCREMENT=n字段。
为了演示truncate的效果,我们创建一张测试和原来一样表,表中包含一个自增长的主键id和姓名。如下:
create table for_truncate(id int primary key auto_increment,name varchar(10));insert into for_truncate(name) values ('A'),('B'),('C');select * from for_truncate;
我们查看一下表for_truncate自增长值的相关信息:
show create table for_truncate \G
然后我们就要通过truncate删除这张表了,在truncate语句中只指明要删除数据的表名,这时便会删除整张表的数据,但由于truncate实际不对数据操作,因此执行truncate语句后看到影响行数为0。如下:
truncate for_truncate; 
再次查看表for_truncate自增长值的相关信息
show create table for_truncate \G
我们发现auto_increment不见了
再向表中插入一些数据,在插入数据时不指明自增长字段的值,这时会发现插入数据对应的自增长id值是重新从1开始增长的。如下:
insert into for_truncate(name) values ('D'), ('E'), ('F');select * from for_truncate;

再次查看表for_truncate自增长值的相关信息
show create table for_truncate \G
注意: truncate在删除数据时不经过真正的事务,无法回滚,所以截断表操作要慎用!
相关文章:
【MySQL】 表的增删操作
目录 1.Create(增) 1.1.单行数据 全列插入 1.2.多行数据 指定列插入 1.3.插入否则更新 1.4.替换数据(REPLACE) 2.Delete(删) 2.1.删除表中的某个条目 2.2.删除整张表数据 2.3.截断表 1.Create…...

新生入门季 | 学习生物信息分析,如何解决个人电脑算力不足的问题?
随着生物信息学在科研和教育中的快速普及,越来越多的新生开始接触基因组测序、RNA分析等复杂计算任务。然而,在面对这些大规模数据时,个人电脑的算力往往显得捉襟见肘。你是否也在为自己的笔记本性能不足而苦恼? 这篇文章将为你提…...

20255 - 中医方剂学 - 考研 - 执业
第1章 总论 1.我国现存最早的记载方剂的医书是()( ) [单选] A.《太平圣惠方》 B.《黄帝内经》 C.《五十二病方》 D.《千金要方》 E.《外台秘要》 正确答案: C 2.我国最早的中医经典理论著作是()( ) [单选] A.《伤寒杂病论…...

【Vue.js设计与实现】第三篇第9章:渲染器-简单Diff算法-阅读笔记
文章目录 9.1 减少 DOM 操作的性能开销9.2 DOM 复用与 key 的作用9.3 找到需要移动的元素9.4 如何移动元素9.5 添加新元素9.6 移除不存在的元素 系列目录:【Vue.js设计与实现】阅读笔记目录 当新旧vnode 的子节点都是一组节点时,为了以最小的性能…...

服务器软件之Tomcat
服务器软件之Tomcat 服务器软件之Tomcat 服务器软件之Tomcat一、什么是Tomcat二、安装Tomcat1、前提:2、下载3、解压下载的tomcat4、tomcat启动常见错误4.1、tomcat8.0 startup报错java.util.logging.ErrorManager: 44.2、java.lang.UnsatisfiedLinkError 三、Tomca…...

Flutter包管理(三)
1、作用 在APP的实际开发过程中往往会依赖很多包,而这些包之间存在着交叉依赖、版本依赖,由开发者自己管理手动管理会非常麻烦,每种开发生态或编程官方会提供一些包的管理工具,在Flutter中我们在pubspec.yaml文件中来管理第三方依…...

CGNS资料
CGNS数据文件 资料 CFD General Notation System CGNS Converters vtkCGNSReader cgnsToFromFoam Example Computer Codes 8.1.2. CGNS Mesh Format and Multizone Interface Connectivity 8 Multizone Interface Connectivity pyvista.cgnsreader CGNS for MATLAB and Octave…...

论文阅读(十六):Deep Residual Learning for Image Recognition
文章目录 1.介绍2.基本原理3.两种残差块4.网络结构 论文:Deep Residual Learning for Image Recognition 论文链接:Deep Residual Learning for Image Recognition 代码链接:Github 1.介绍 在ResNet网络提出之前,传统的卷…...

Dubbo 序列化方式
Hession 这是dubbo的默认序列化协议,是一种二进制协议,他的特点是序列化的速度比较快,并且序列化的数据体积比较小。Hession适合于大部分场景,因此被选为dubbo的默认序列化协议。 Json Json是一种基于文本的序列化方式…...

如何替换OCP节点(二):使用 antman脚本 | OceanBase应用实践
前言: OceanBase Cloud Platform(简称OCP),是 OceanBase数据库的专属企业级数据库管理平台。 在实际生产环境中,OCP的安装通常是第一步,先搭建OCP平台,进而依赖OCP来创建、管理和监控我们的生…...

15.JVM垃圾收集算法
一、垃圾收集算法 1.分代收集理论 分代收集理论是JAVA虚拟机进行垃圾回收的一种思想,根据对象存活周期的不同将内存分成不同的几个区域;一般将JAVA堆内存分为新生代和老年代;根据每个分代特点选择不同的垃圾收集器; 在新生代中&am…...

软件工程:图书管理系统甘特图
1 实验目的 熟悉GanttProject 软件环境,能够使用GanttProject绘制甘特图,进行项目管理与规划。 2 实验内容 为小型图书管理系统项目的实施计划绘制甘特图。 小型图书管理系统项目包含登录、浏览、管理读者、管理图书资料、管理书目、登记借书、登记还书、预定图书、…...

视频的编解码格式
文章目录 视频的编解码格式概念术语视频处理流程视频封装格式视频编码格式视频编解码器,视频容器和视频文件格式之间的区别补充视频码率 参考资料 视频的编解码格式 概念术语 两大组织主导视频压缩的组织及其联合(joint)组织 ITU-T(VCEG) ITU-T的中文名称是国际电信…...
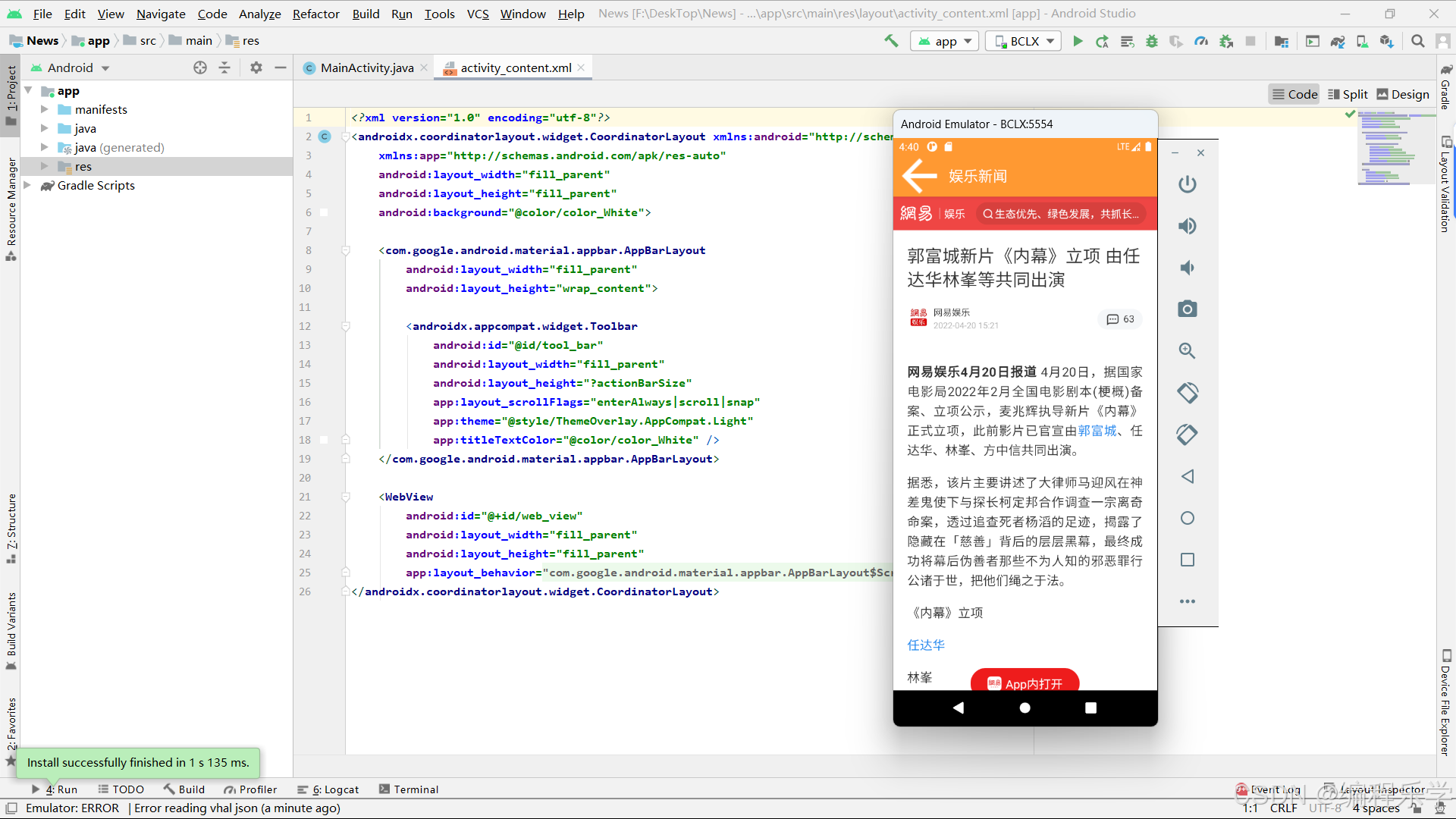
网络资源模板--Android Studio 实现简易新闻App
目录 一、项目演示 二、项目测试环境 三、项目详情 四、完整的项目源码 一、项目演示 网络资源模板--基于Android studio 实现的简易新闻App 二、项目测试环境 三、项目详情 登录页 用户输入: 提供账号和密码输入框,用户可以输入登录信息。支持“记…...
LabVIEW提高开发效率技巧----离线调试
离线调试是LabVIEW开发中一项重要的技巧,通过使用Simulate Signal Express VI生成虚拟数据,开发者能够有效减少对实际硬件的依赖,加速开发过程。这种方法不仅可以提高开发效率,还能降低成本,增强系统的灵活性。 离…...

6N137S1取反电路图
文章目录 一、前言二、6N137S1性能介绍三、应用电路图 一、前言 在硬件电路设计中需要用到隔离电路,但此引脚输出为WS2812的信号,频率有840khz,所以需要使用逻辑光耦,选用6N137S1光耦,速率能达到10Mhz,能满…...
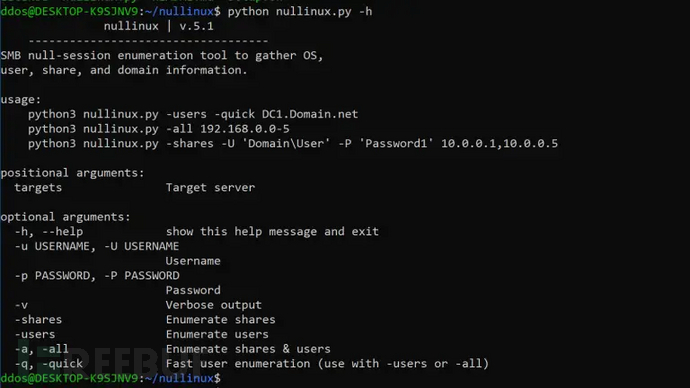
Nullinux:一款针对Linux操作系统的安全检测工具
关于Nullinux Nullinux是一款针对Linux操作系统的安全检测工具,广大研究人员可以利用该工具针对Linux目标设备执行网络侦查和安全检测。 该工具可以通过SMB枚举目标设备的安全状况信息,其中包括操作系统信息、域信息、共享信息、目录信息和用户信息。如…...

学会这 5 个 AI 神器做字体设计,保证让你私单接到爆!
最近我在浏览 AI 绘画的相关内容时,发现不少图像都是与字体相关的,而且其中一些呈现出的艺术特效很是让人眼前一亮。 放在之前,我们需要掌握一些专业技能、并花费大量时间才能设计出精致酷炫的艺术字,但是现在却可以轻松用文本直…...

《Vue3 踩坑》expose 和 defineExpose 暴露属性或方法注意事项
选项式写法 使用 选项式API - 状态选项 - expose 一定要注意: 接下来,进一步看示例说明: 设置 expose 仅显示列出的属性/方法才能被父组件调用;代码第 2 行,父组件可访问属性 a 和 方法 myFunc01,不可访…...

10.13论文阅读
通过联合学习检测和描述关键点增强可变形局部特征 摘要 局部特征提取是计算机视觉中处理图像匹配和检索等关键任务的常用方法。大多数方法的核心理念是图像经历仿射变换,忽略了诸如非刚性形变等更复杂的效果。此外,针对非刚性对应的新兴工作仍然依赖于…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...