LangGraph - Hierarchical Agent Teams
本文翻译整理自 Hierarchical Agent Teams
https://langchain-ai.github.io/langgraph/tutorials/multi_agent/hierarchical_agent_teams/
文章目录
- 一、前言
- 二、设置
- 三、创建工具
- 四、Helper Utilities
- 五、定义代理 Team
- 研究 Team
- 文档写作Team
- 六、添加图层
一、前言
在前面的示例(Agent Supervisor)中,我们引入了单个主管节点的概念,用于在不同的工作节点之间路由工作。
但是如果一个工人的工作变得太复杂怎么办?如果工人数量太多怎么办?
对于某些应用程序,如果工作按层次分布,系统可能会更有效。
您可以通过组合不同的子图并创建顶级主管以及中级主管来做到这一点。
为此,让我们构建一个简单的研究助手!该图如下所示:

AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
本笔记本的灵感来自Wu等人的论文AutoGen:通过多代理对话启用下一代LLM应用程序。在本笔记本的其余部分,您将:
- Define the agents’ tools to access the web and write files
- 定义代理访问Web和写入文件的工具
- Define some utilities to help create the graph and agents
- 定义一些实用程序来帮助创建图和代理
- Create and define each team (web research + doc writing)
- 创建和定义每个Team (网络研究+文档编写)
- Compose everything together.
- 把一切组合在一起。
二、设置
首先,让我们安装所需的包并设置API密钥
%%capture --no-stderr
%pip install -U langgraph langchain langchain_openai langchain_experimentalimport getpass
import osdef _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}")_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")
设置LangSmith用于LangGraph开发
注册LangSmith以快速发现问题并提高LangGraph项目的性能。LangSmith允许您使用跟踪数据来调试、测试和监控使用LangGraph构建的LLM应用程序 - 在此处阅读有关如何开始的更多信息。
三、创建工具
每个Team 将由一个或多个代理组成,每个代理都有一个或多个工具。下面,定义您的不同Team 要使用的所有工具。
我们将从研究Team 开始。
ResearchTeam 工具
研究Team 工具
研究Team 可以使用搜索引擎和url刮刀在网络上查找信息。请随时在下面添加其他功能以提高Team 绩效!
from typing import Annotated, Listfrom langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tooltavily_tool = TavilySearchResults(max_results=5)@tool
def scrape_webpages(urls: List[str]) -> str:"""Use requests and bs4 to scrape the provided web pages for detailed information."""loader = WebBaseLoader(urls)docs = loader.load()return "\n\n".join([f'<Document name="{doc.metadata.get("title", "")}">\n{doc.page_content}\n</Document>'for doc in docs])
API Reference: WebBaseLoaderTavilySearchResultstool
文档编写Team 工具
接下来,我们将提供一些工具供文档编写Team 使用。我们在下面定义了一些基本的文件访问工具。
请注意,这使代理可以访问您的文件系统,这可能是不安全的。我们也没有优化工具描述以提高性能。
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import Dict, Optionalfrom langchain_experimental.utilities import PythonREPL
from typing_extensions import TypedDict_TEMP_DIRECTORY = TemporaryDirectory()
WORKING_DIRECTORY = Path(_TEMP_DIRECTORY.name)@tool
def create_outline(points: Annotated[List[str], "List of main points or sections."],file_name: Annotated[str, "File path to save the outline."],
) -> Annotated[str, "Path of the saved outline file."]:"""Create and save an outline."""with (WORKING_DIRECTORY / file_name).open("w") as file:for i, point in enumerate(points):file.write(f"{i + 1}. {point}\n")return f"Outline saved to {file_name}"@tool
def read_document(file_name: Annotated[str, "File path to save the document."],start: Annotated[Optional[int], "The start line. Default is 0"] = None,end: Annotated[Optional[int], "The end line. Default is None"] = None,
) -> str:"""Read the specified document."""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()if start is not None:start = 0return "\n".join(lines[start:end])@tool
def write_document(content: Annotated[str, "Text content to be written into the document."],file_name: Annotated[str, "File path to save the document."],
) -> Annotated[str, "Path of the saved document file."]:"""Create and save a text document."""with (WORKING_DIRECTORY / file_name).open("w") as file:file.write(content)return f"Document saved to {file_name}"@tool
def edit_document(file_name: Annotated[str, "Path of the document to be edited."],inserts: Annotated[Dict[int, str],"Dictionary where key is the line number (1-indexed) and value is the text to be inserted at that line.",],
) -> Annotated[str, "Path of the edited document file."]:"""Edit a document by inserting text at specific line numbers."""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()sorted_inserts = sorted(inserts.items())for line_number, text in sorted_inserts:if 1 <= line_number <= len(lines) + 1:lines.insert(line_number - 1, text + "\n")else:return f"Error: Line number {line_number} is out of range."with (WORKING_DIRECTORY / file_name).open("w") as file:file.writelines(lines)return f"Document edited and saved to {file_name}"# Warning: This executes code locally, which can be unsafe when not sandboxedrepl = PythonREPL()@tool
def python_repl(code: Annotated[str, "The python code to execute to generate your chart."],
):"""Use this to execute python code. If you want to see the output of a value,you should print it out with `print(...)`. This is visible to the user."""try:result = repl.run(code)except BaseException as e:return f"Failed to execute. Error: {repr(e)}"return f"Successfully executed:\n\`\`\`python\n{code}\n\`\`\`\nStdout: {result}"
API Reference: PythonREPL
四、Helper Utilities
当我们想要时,我们将创建一些实用函数以使其更加简洁:
- 创建一个工作代理。
- 为子图创建主管。
这些将为我们简化最后的图形组合代码,以便更容易看到发生了什么。
from typing import List, Optional
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAIfrom langgraph.graph import END, StateGraph, START
from langchain_core.messages import HumanMessage, trim_messagesllm = ChatOpenAI(model="gpt-4o-mini")trimmer = trim_messages(max_tokens=100000,strategy="last",token_counter=llm,include_system=True,
)def agent_node(state, agent, name):result = agent.invoke(state)return {"messages": [HumanMessage(content=result["messages"][-1].content, name=name)]}def create_team_supervisor(llm: ChatOpenAI, system_prompt, members) -> str:"""An LLM-based router."""options = ["FINISH"] + membersfunction_def = {"name": "route","description": "Select the next role.","parameters": {"title": "routeSchema","type": "object","properties": {"next": {"title": "Next","anyOf": [{"enum": options},],},},"required": ["next"],},}prompt = ChatPromptTemplate.from_messages([("system", system_prompt),MessagesPlaceholder(variable_name="messages"),("system","Given the conversation above, who should act next?"" Or should we FINISH? Select one of: {options}",),]).partial(options=str(options), team_members=", ".join(members))return (prompt| trimmer| llm.bind_functions(functions=[function_def], function_call="route")| JsonOutputFunctionsParser())
API Reference: JsonOutputFunctionsParserChatPromptTemplateMessagesPlaceholderChatOpenAIHumanMessagetrim_messagesENDStateGraphSTART
五、定义代理 Team
现在我们可以定义我们的等级Team 了。“选择你的球员!”
研究 Team
研究Team 将有一个搜索代理和一个网页抓取“research_agent”作为两个工作节点。让我们创建这些,以及Team 主管。
import functools
import operatorfrom langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai.chat_models import ChatOpenAI
from langgraph.prebuilt import create_react_agent# ResearchTeam graph state
class ResearchTeamState(TypedDict):# A message is added after each team member finishesmessages: Annotated[List[BaseMessage], operator.add]# The team members are tracked so they are aware of# the others' skill-setsteam_members: List[str]# Used to route work. The supervisor calls a function# that will update this every time it makes a decisionnext: strllm = ChatOpenAI(model="gpt-4o")search_agent = create_react_agent(llm, tools=[tavily_tool])
search_node = functools.partial(agent_node, agent=search_agent, name="Search")research_agent = create_react_agent(llm, tools=[scrape_webpages])
research_node = functools.partial(agent_node, agent=research_agent, name="WebScraper")supervisor_agent = create_team_supervisor(llm,"You are a supervisor tasked with managing a conversation between the"" following workers: Search, WebScraper. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH.",["Search", "WebScraper"],
)
API Reference: BaseMessageHumanMessageChatOpenAIcreate_react_agent
现在我们已经创建了必要的组件,定义它们的交互很容易。将节点添加到团队图中,并定义确定转换标准的边。
research_graph = StateGraph(ResearchTeamState)
research_graph.add_node("Search", search_node)
research_graph.add_node("WebScraper", research_node)
research_graph.add_node("supervisor", supervisor_agent)# Define the control flow
research_graph.add_edge("Search", "supervisor")
research_graph.add_edge("WebScraper", "supervisor")
research_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"Search": "Search", "WebScraper": "WebScraper", "FINISH": END},
)research_graph.add_edge(START, "supervisor")
chain = research_graph.compile()# The following functions interoperate between the top level graph state
# and the state of the research sub-graph
# this makes it so that the states of each graph don't get intermixed
def enter_chain(message: str):results = {"messages": [HumanMessage(content=message)],}return resultsresearch_chain = enter_chain | chainfrom IPython.display import Image, displaydisplay(Image(chain.get_graph(xray=True).draw_mermaid_png()))

我们可以直接给这个团队工作。在下面试试。
for s in research_chain.stream("when is Taylor Swift's next tour?", {"recursion_limit": 100}
):if "__end__" not in s:print(s)print("---")
文档写作Team
使用类似的方法在下面创建文档编写团队。这一次,我们将授予每个代理访问不同文件编写工具的权限。
请注意,我们在这里向我们的代理提供文件系统访问权限,这在所有情况下都不安全。
import operator
from pathlib import Path# Document writing team graph state
class DocWritingState(TypedDict):# This tracks the team's conversation internallymessages: Annotated[List[BaseMessage], operator.add]# This provides each worker with context on the others' skill setsteam_members: str# This is how the supervisor tells langgraph who to work nextnext: str# This tracks the shared directory statecurrent_files: str# This will be run before each worker agent begins work
# It makes it so they are more aware of the current state
# of the working directory.
def prelude(state):written_files = []if not WORKING_DIRECTORY.exists():WORKING_DIRECTORY.mkdir()try:written_files = [f.relative_to(WORKING_DIRECTORY) for f in WORKING_DIRECTORY.rglob("*")]except Exception:passif not written_files:return {**state, "current_files": "No files written."}return {**state,"current_files": "\nBelow are files your team has written to the directory:\n"+ "\n".join([f" - {f}" for f in written_files]),}llm = ChatOpenAI(model="gpt-4o")doc_writer_agent = create_react_agent(llm, tools=[write_document, edit_document, read_document]
)
# Injects current directory working state before each call
context_aware_doc_writer_agent = prelude | doc_writer_agent
doc_writing_node = functools.partial(agent_node, agent=context_aware_doc_writer_agent, name="DocWriter"
)note_taking_agent = create_react_agent(llm, tools=[create_outline, read_document])
context_aware_note_taking_agent = prelude | note_taking_agent
note_taking_node = functools.partial(agent_node, agent=context_aware_note_taking_agent, name="NoteTaker"
)chart_generating_agent = create_react_agent(llm, tools=[read_document, python_repl])
context_aware_chart_generating_agent = prelude | chart_generating_agent
chart_generating_node = functools.partial(agent_node, agent=context_aware_note_taking_agent, name="ChartGenerator"
)doc_writing_supervisor = create_team_supervisor(llm,"You are a supervisor tasked with managing a conversation between the"" following workers: {team_members}. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH.",["DocWriter", "NoteTaker", "ChartGenerator"],
)
通过创建对象本身,我们可以形成图形。
# Create the graph here:
# Note that we have unrolled the loop for the sake of this doc
authoring_graph = StateGraph(DocWritingState)
authoring_graph.add_node("DocWriter", doc_writing_node)
authoring_graph.add_node("NoteTaker", note_taking_node)
authoring_graph.add_node("ChartGenerator", chart_generating_node)
authoring_graph.add_node("supervisor", doc_writing_supervisor)# Add the edges that always occur
authoring_graph.add_edge("DocWriter", "supervisor")
authoring_graph.add_edge("NoteTaker", "supervisor")
authoring_graph.add_edge("ChartGenerator", "supervisor")# Add the edges where routing applies
authoring_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"DocWriter": "DocWriter","NoteTaker": "NoteTaker","ChartGenerator": "ChartGenerator","FINISH": END,},
)authoring_graph.add_edge(START, "supervisor")
chain = authoring_graph.compile()# The following functions interoperate between the top level graph state
# and the state of the research sub-graph
# this makes it so that the states of each graph don't get intermixed
def enter_chain(message: str, members: List[str]):results = {"messages": [HumanMessage(content=message)],"team_members": ", ".join(members),}return results# We reuse the enter/exit functions to wrap the graph
authoring_chain = (functools.partial(enter_chain, members=authoring_graph.nodes)| authoring_graph.compile()
)from IPython.display import Image, displaydisplay(Image(chain.get_graph().draw_mermaid_png()))

for s in authoring_chain.stream("Write an outline for poem and then write the poem to disk.",{"recursion_limit": 100},
):if "__end__" not in s:print(s)print("---")
{'supervisor': {'next': 'NoteTaker'}}
---
{'NoteTaker': {'messages': [HumanMessage(content='The poem has been written and saved to "poem.txt".', name='NoteTaker')]}}
---
{'supervisor': {'next': 'FINISH'}}
---
六、添加图层
在这个设计中,我们执行了一个自上而下的规划策略。我们已经创建了两个图表,但是我们必须决定如何在两者之间分配工作。
我们将创建第三个图来协调前两个图,并添加一些连接器来定义如何在不同图之间共享这个顶级状态。
from langchain_core.messages import BaseMessage
from langchain_openai.chat_models import ChatOpenAIllm = ChatOpenAI(model="gpt-4o")supervisor_node = create_team_supervisor(llm,"You are a supervisor tasked with managing a conversation between the"" following teams: {team_members}. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH.",["ResearchTeam", "PaperWritingTeam"],
)
API Reference: BaseMessageChatOpenAI
# Top-level graph state
class State(TypedDict):messages: Annotated[List[BaseMessage], operator.add]next: strdef get_last_message(state: State) -> str:return state["messages"][-1].contentdef join_graph(response: dict):return {"messages": [response["messages"][-1]]}# Define the graph.
super_graph = StateGraph(State)
# First add the nodes, which will do the work
super_graph.add_node("ResearchTeam", get_last_message | research_chain | join_graph)
super_graph.add_node("PaperWritingTeam", get_last_message | authoring_chain | join_graph
)
super_graph.add_node("supervisor", supervisor_node)# Define the graph connections, which controls how the logic
# propagates through the program
super_graph.add_edge("ResearchTeam", "supervisor")
super_graph.add_edge("PaperWritingTeam", "supervisor")
super_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"PaperWritingTeam": "PaperWritingTeam","ResearchTeam": "ResearchTeam","FINISH": END,},
)super_graph.add_edge(START, "supervisor")
super_graph = super_graph.compile()from IPython.display import Image, displaydisplay(Image(super_graph.get_graph().draw_mermaid_png()))

for s in super_graph.stream({"messages": [HumanMessage(content="Write a brief research report on the North American sturgeon. Include a chart.")],},{"recursion_limit": 150},
):if "__end__" not in s:print(s)print("---")
{'supervisor': {'next': 'ResearchTeam'}}
---
{'ResearchTeam': {'messages': [HumanMessage(content="Unfortunately, ... documents.", name='WebScraper')]}}
---
{'supervisor': {'next': 'PaperWritingTeam'}}
2024-10-18(五)
相关文章:
LangGraph - Hierarchical Agent Teams
本文翻译整理自 Hierarchical Agent Teams https://langchain-ai.github.io/langgraph/tutorials/multi_agent/hierarchical_agent_teams/ 文章目录 一、前言二、设置三、创建工具四、Helper Utilities五、定义代理 Team研究 Team文档写作Team 六、添加图层 一、前言 在前面的…...

2021-04-14 proteus中仿真时74HC245三态双向端口扩展输出
缘由proteus中仿真时74HC245输出时电平显示灰色(不确定电平状态)是为什么?-编程语言-CSDN问答 缘由C语言翻译单片机开关检测器-编程语言-CSDN问答 参考74ls245的工作原理及作用详解 - 电子发烧友网 参考74ls245_百度百科...

解决UNSPSC商品分类的层级不足的方法
《联合国标准产品和服务守则》(UNSPSC)是一个分层框架,旨在对产品和服务进行分类。其主要目标是通过提供统一的方法来对产品和服务进行分类,从而简化采购和供应链管理。 虽然 UNSPSC 有效地将产品分为各种商品类别,但…...

Pytest基于fixture的参数化及解决乱码问题
我们知道,Pytest是Python技术栈下进行自动化测试的主流测试框架。支持灵活的测试发现、执行策略,强大的Fixture夹具和丰富的插件支持。 除了通过pytest的parametrize标签进行参数化外,我们通过fixture的param参数也可以比较方便地实现参数化…...

使用excel.js(layui-excel)进行layui多级表头导出,根据单元格内容设置背景颜色,并将导出函数添加到toolbar
本段是菜狗子的碎碎念,解决办法请直接从第二段开始看。layui多级表头的导出,弄了两天才搞定,中途一度想放弃,还好坚持下来了。一开始用的是layui的toolbar里自带的那个导出,但是多级表头没有正常导出,单元格…...

Mysql 5.7 安装与卸载(非常详细)
一、环境介绍 操作系统:CentOS 7 MySQL:5.7 二、MySQL卸载 # 查看软件 rpm -qa|grep mysql # 卸载MySQL yum remove -y mysql mysql-libs mysql-common rm -rf /var/lib/mysql rm /etc/my.cnf 继续查看是否还有 MySQL 软件,有的话继续删…...

030 elasticsearch查询、聚合
文章目录 查询聚合查询RestHighLevelClientElasticsearchRestTemplat SpringData对ES客户端的封装:ElasticsearchRestTemplate SpringData对CRUD的封装:ElasticsearchRepository 原生ES客户端:RestHighLevelClient 查询 package com.xd.cube…...

前端工程启动工具
一些思考 在公司项目中,需要启一个新的前端工程(一个基于Webpack的React工程)。因为同一个项目中有其他的前端工程,我们最开始想的是参考另外一个工程的配置重启一个新的工程,但是又因为原来的工程用的库版本都比较老…...

游戏逆向基础-跳出游戏线程发包
附加游戏后下断点 bp ws2_32.send send函数断下后,可以看到数据地址每次都一样 可以说明这个游戏是线程发包,所以直接在数据窗口中转到这个地址,然后对这个地址下硬件写入断点。 下了硬件写入断点后可以一层一层往上面跟,确定写…...

做海外网站需要准备什么
一,购买域名 在租用国外服务器之前,您需要购买域名。域名是访问网站的标志,也是网站品牌的一部分。因此,在购买域名时,需要考虑域名的可记忆性、简短性和搜索性,使网站更容易被用户记住。 二,租…...

通过OpenCV实现 Lucas-Kanade 算法
目录 简介 Lucas-Kanade 光流算法 实现步骤 1. 导入所需库 2. 视频捕捉与初始化 3. 设置特征点参数 4. 创建掩模 5. 光流估计循环 6. 释放资源 结论 简介 在计算机视觉领域,光流估计是一种追踪物体运动的技术。它通过比较连续帧之间的像素强度变化来估计图…...
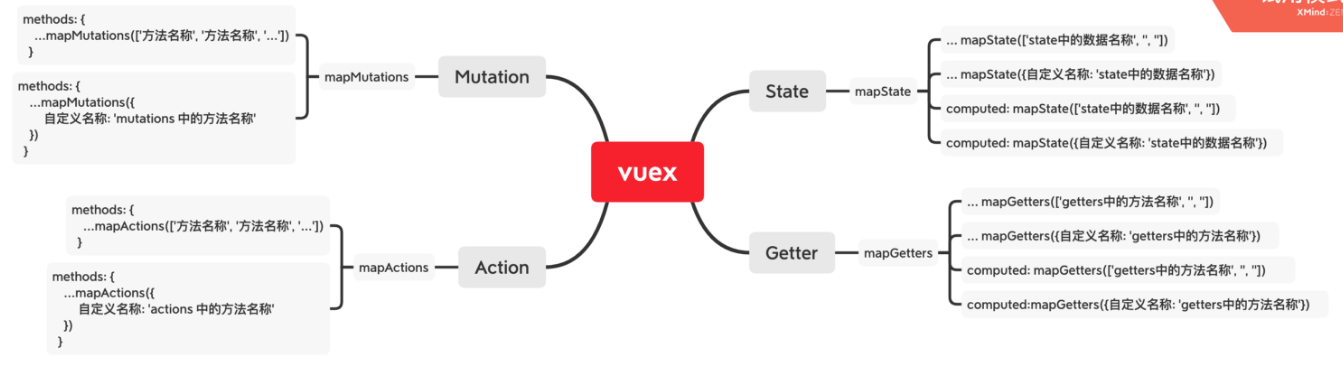
7、Vue2(二) vueRouter3+axios+Vuex3
14.vue-router 3.x 路由安装的时候不是必须的,可以等到使用的时候再装,如果之前没有安装的话,可以再单独安装。之前的终端命令行不要关闭,再重新开一个,还需要再package.json文件的依赖中添加。 如果忘记之前是否有安…...
最新PHP礼品卡回收商城 点卡回收系统源码_附教程
最新PHP礼品卡回收商城 点卡回收系统源码_附教程 各大电商平台优惠券秒杀拼团限时折扣回收商城带余额宝 1、余额宝理财 2、回收、提现、充值、新订单语音消息提醒功能 3、带在线客服 4、优惠券回收功能 源码下载:https://download.csdn.net/download/m0_66047…...

MySQL数据库和表的基本操作
文章目录 一、数据库的基础知识 背景知识数据库的基本操作二、数据类型 字符串类型数值类型日期类型三、表的基本操作 创建表查看表结构查看所有表删除表 一、数据库的基础知识 背景知识 MySQL是一个客户端服务器结构的程序 主动发送数据的这一方,客户端(client…...

SAM应用:医学图像和视频中的任何内容分割中的基准测试与部署
医学图像和视频中的任何内容分割:基准测试与部署 目录 摘要:一、引言1.1 SAM2 在医学图像和视频中的应用 二.结果2.1 数据集和评估协议2.2 二维图像分割的评估结果 三 讨论四 局限性和未来的工作五、方法5.1数据来源和预处理5.2 微调协议5.3 评估指标 总…...

Qt消息对话框
问题对话框 对应API [static] QMessageBox::StandardButton QMessageBox::question( QWidget *parent, const QString &title, const QString &text, QMessageBox::StandardButtons buttons StandardButtons(Yes | No), QMessageBox::StandardButton defaultButt…...

FreeRTOS的队列管理
“队列”提供了一种任务到任务、任务到中断和中断到任务的通信机制。 队列特性 数据存储 队列可以容纳有限数量的固定大小的数据项。队列可以容纳的最大项目数称为其“长度”。每个数据项的长度和大小都是在创建队列时设置的。 队列通常用作先进先出(FIFO…...
)
买卖股票的最佳时机(动态规划方法总结)
总结一下,买卖股票系列的动态规划思想,贪心解法或者其他解法不做描述。 总结 121. 买卖股票的最佳时机 只有一次交易机会,每天有两种状态:持有股票和不持有股票; 122. 买卖股票的最佳时机 II 有多次交易机会&#x…...

KubeSphere安装mysql8.4.0
背景 KubeSphere 是在 Kubernetes 之上构建的以应用为中心的多租户容器平台,完全开源,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。 安装组件前提&am…...

SpringBoot项目热部署-devtools
DevTools 会使用两个类加载器(一个用于加载不变的类,一个用于加载可能会变化的类),每次重启只重新加载管理变化的类的加载器,因此会快很多 1.导入依赖 <dependency> <groupId>org.springframework.boot&l…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

2026这6款神级降AIGC平台大公开,一键让AIGC率直逼绝对安全线!
步入 2026 年,学术圈的风向早已不是从前的模样。曾经大家还在为查重率发愁,如今却陷入了更棘手的困境——如何在不破坏论文专业性的前提下,彻底消除 AI 痕迹?随着 AIGC 检测技术不断进化,高校对论文的审核标准也愈发严…...

AI 应用原型开发阶段利用 Taotoken 快速进行多模型效果对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 AI 应用原型开发阶段利用 Taotoken 快速进行多模型效果对比 在构建一个 AI 应用的原型时,开发者常常面临一个核心问题&…...

收藏2026版|大模型应用开发入门全攻略,小白程序员转行AI避坑学习指南
打算踏入大模型领域、转行AI赛道的新手与程序员,正式规划学习路径前,务必先吃透AI应用开发工程师的岗位定位与工作内容。清晰认知岗位核心价值,才能规避无效学习,精准找准发力方向。2026年大模型技术全面迈入商业化落地阶段&#…...

安卓逆向实战:Frida内存砸壳提取DEX原理与技巧
1. 这不是“脱壳”,是逆向工程中一次精准的内存手术你打开一个加固过的安卓App,用常规工具解包,发现classes.dex只有几KB,里面全是混淆到面目全非的壳代码;用dex2jar反编译,报错“Not a valid dex file”&a…...

C语言--day19
第十章 内存管理当./a.out 运行起来后,系统会给a.out分配一段内存区域1、code ,存放编写好的c语言代码。 只读特性,在运行期间不能修改2、data 数据段。 存储全局变量,和被static 修改的变量细分:data 数据段ÿ…...

Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南
Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...