STL源码剖析:Hashtable
hashtable 概述
哈希表是一种数据结构,它提供了快速的数据插入、删除和查找功能。它通过使用哈希函数将键(key)映射到表中的一个位置来实现这一点,这个位置称为哈希值或索引。哈希表使得这些操作的平均时间复杂度为常数时间,即O(1)。
哈希表使用哈希函数将键映射到一个固定大小的数组上。
碰撞
两个不同的键通过哈希函数得到了相同的索引。由于哈希表的大小是有限的,而键的数量可能非常多,所以碰撞是不可避免的。
(1)线性探测:当发生碰撞时,线性探测会在哈希表中按线性顺序搜索下一个空闲位置。
(2)二次探测:与线性探测类似,但是搜索下一个空闲位置时,使用的是二次函数而不是线性函数。
(3)开链:每个哈希表的槽位不直接存储元素,而是存储一个链表。当发生碰撞时,新元素会被添加到对应槽位的链表中。
hashtable实现
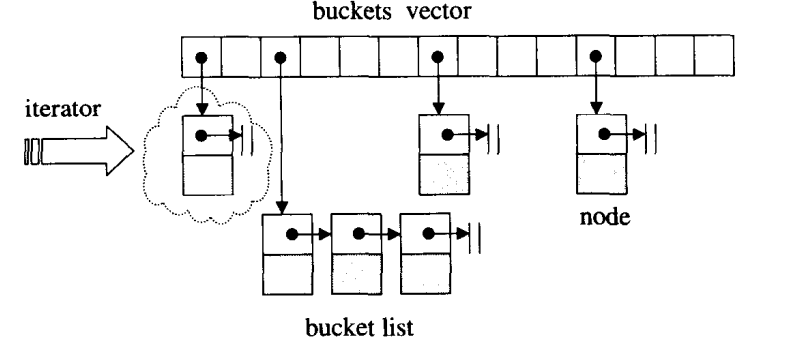
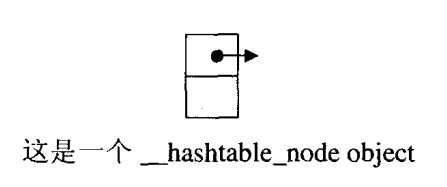
hash_table node
template <class Value>
struct hashtable_node
{_hashtable_node* next; Value val;
};
hashtable 的迭代器
// 定义哈希表迭代器模板结构体
template <class Value, class Key, class HashFcn, class ExtractKey, class EqualKey, class Alloc
>
struct hashtable_iterator {// 使用typedef定义相关类型别名,以简化代码typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> hashtable_type;typedef hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> iterator_type;typedef __hashtable_const_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> const_iterator_type;typedef __hashtable_node<Value> node_type;typedef std::forward_iterator_tag iterator_category;typedef Value value_type;typedef ptrdiff_t difference_type;typedef std::size_t size_type;typedef Value& reference;typedef Value* pointer;// 成员变量node_type* cur; // 当前节点指针hashtable_type* ht; // 指向哈希表的指针// 构造函数hashtable_iterator(node_type* n = nullptr, hashtable_type* tab = nullptr) : cur(n), ht(tab) {}// 解引用操作符,返回当前节点的值reference operator*() const { return cur->val; }// 成员访问操作符,返回当前节点值的指针pointer operator->() const { return &(operator*()); }// 前置++iterator_type& operator++() {// 此处应有逻辑来移动迭代器到下一个节点// ...return *this;}// 后置++iterator_type operator++(int) {iterator_type temp = *this;++(*this); // 使用前置++来实现return temp;}// 相等比较操作符bool operator==(const iterator_type& it) const { return cur == it.cur; }// 不等比较操作符bool operator!=(const iterator_type& it) const { return !(*this == it); }
};hashtable的数据结构
#include <vector> // For std::vector
#include <cstddef> // For size_t// 定义哈希表类模板
template <class Value,class Key,class HashFcn,class ExtractKey,class EqualKey,class Alloc = Alloc // 注意:这里应该是具体的分配器类名,例如 std::allocator
>
class hashtable {
public:// 为模板型别参数重新定义一个名称typedef HashFcn hasher;typedef EqualKey key_equal;typedef size_t size_type;
private:// 以下三者都是 function objectshasher hash; // 哈希函数对象key_equal equalg; // 键值比较函数对象ExtractKey get_key; // 键提取函数对象typedef hashtable_node<Value> node; // 节点类型定义typedef simple_alloc<node, Alloc> node_allocator; // 节点分配器定义std::vector<node*, Alloc> buckets; // 桶数组,使用 vector 完成size_type num_elements; // 元素数量
public:// 构造函数hashtable():num_elements(0){}// bucket 个数即 buckets vector 的大小size_type bucket_count() const { return buckets.size(); }// 其他成员函数声明...
};// 注意:hashtable_node, simple_alloc 需要被定义
// 注意:Alloc 应该是一个具体的分配器类,例如 std::allocator虽然开链法(separate chaining)并不要求表格大小必须为质数,但 SGI STL 仍然以质数来设计表格大小,并且先将28 个质数(逐渐呈现大约两倍的关系)计算好,以备随时访问,同时提供一个函数,用来查询在这 28 个质数之中,"最接近某数并大于某数"的质数。
hashtable 的构造,插入,内存分配,拷贝和回收
hashtable类中定义了一个node_allocator类型
typedef simple_alloc<node, Alloc> node_allocator;
node* new_node(const value_type& obj) {node* n = node_allocator::allocate();n->next = 0;STL_TRY{construct(&n->val, obj); return n;}STL_UNWIND(node_allocator::deallocate(n));
}
void delete_node(node* n) {destroy(&n->val);node_allocator::deallocate(n);
}new_node函数分配内存并构造一个新节点,若构造失败则释放内存。
delete_node函数销毁节点的值并释放内存。
哈希表构造
hashtable<int, int, hash<int>, identity<int>, equal_to<int>, alloc>
iht(50, hash<int>(), equal_to<int>());创建一个哈希表iht,初始容量为50,使用默认的哈希函数和比较函数。
初始化桶
void initialize_buckets(size_type n) {const size_type n_buckets = next_size(n);buckets.reserve(n_buckets);buckets.insert(buckets.end(), n_buckets, (node*)0);num_elements = 0;
}initialize_buckets函数根据给定的大小n计算下一个质数作为桶的数量,并初始化桶为null指针。
插入元素 和 重建 hash table
pair<iterator, bool> insert_unique(const value_type& obj) {resize(num_elements + 1);return insert_unique_noresize(obj);
}insert_unique调用resize检查是否需要扩展哈希表的容量。
void resize(size_type num_elements_hi) {const size_type old_n = buckets.size();if (num_elements_hint > old_n) {const size_type n = next_size(num_elements_hint);if (n > old_n) {vector<node*, A> tmp(n, (node*)0);STL_TRY {for (size_type bucket = 0; bucket < old_n; ++bucket) {node* first = buckets[bucket];while (first) {size_type new_bucket = bkt_num(first->val, n);buckets[bucket] = first->next;first->next = tmp[new_bucket];tmp[new_bucket] = first;first = buckets[bucket];}}}buckets.swap(tmp);}}
}resize函数决定是否需要扩展哈希表,如果当前元素数量超过桶的数量,则重新配置桶并将现有节点转移到新桶中。
插入不重建
template<class V, class K, class HF, class Ex, class Eq, class A>
typename hashtable<V, K, HF, Ex, Eq, A>::iterator
hashtable<V, K, HF, Ex, Eq, A>::insert_equal_noresize(const value_type& obj) {const size_type n = bkt_num(obj); // 确定 obj 应位于 #n 桶node* first = buckets[n]; // 指向桶对应的链表头部
//遍历链表,查找重复的键值for(node* cur = first;cur;cur=cur->next) {if (equals(get_key(cur->val), get_key(obj))) {// 如果找到重复键值,插入新节点node* tmp = new_node(obj); // 产生新节点tmp->next = cur->next; // 新节点指向当前节点的下一个节点cur->next = tmp; // 将新节点插入到当前节点后面++num_elements; // 节点个数累加1return iterator(tmp, this); // 返回指向新节点的迭代器}}
//若没有找到重复的键值,插入到链表头部node* tmp = new_node(obj); // 产生新节点tmp->next = first; // 新节点指向当前链表的头部buckets[n] = tmp; // 更新桶指向新节点++num_elements; // 节点个数累加1return iterator(tmp, this); // 返回指向新节点的迭代器
}bkt_num函数的功能
bkt_num系列函数负责将元素映射到哈希表的桶中,确保即使是无法直接对哈希表大小进行模运算的类型(如const char*),也能正确处理。
版本 1:接受实值和桶的数量
size_type bkt_num(const value_type& obj, size_t n) const {return bkt_num_key(get_key(obj), n); // 调用版本 4
}接收一个元素值和桶的数量,首先提取键值(get_key),然后调用bkt_num_key来计算桶的位置。
版本 2:只接受实值
size_type bkt_num(const value_type& obj) const {return bkt_num_key(get_key(obj)); // 调用版本 3
}只接受元素值,调用bkt_num_key,不需要提供桶的数量,默认为当前桶的大小。
版本 3: 只接受键值
size_type bkt_num_key(const key_type& key) const {return bkt_num_key(key, buckets.size()); // 调用版本 4
}版本 4: 接受键值和桶的数量
size_type bkt_num_key(const key_type& key,size_t n) const {return hash(key)%n;//调用哈希函数并取模
}最基础的版本,接受键值和桶的数量,通过哈希函数计算出键值的哈希值,并对桶的数量进行取模运算,得出最终的桶索引。
哈希表的复制(copy_from)和整体删除(clear)
由于哈希表由向量和链表组成,这两个操作都涉及内存管理。
整体删除 clear
遍历每个桶,逐个删除桶中的所有节点,确保调用delete_node来释放内存。最后将桶的内容设置为null指针,并将节点总数设置为0。注意向量buckets本身并没有释放空间,只是清空了其内容。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::clear() {// 针对每一个 bucketfor (size_type i = 0; i < buckets.size(); ++i) {node* cur = buckets[i];// 删除 bucket list 中的每一个节点while (cur != 0) {node* next = cur->next;delete_node(cur); // 删除当前节点cur = next; // 移动到下一个节点}// 令 bucket 内容为 null 指针buckets[i] = 0;}num_elements = 0; // 令总节点个数为0// 注意,buckets vector 并未释放掉空间,仍保有原来大小
}复制 copy_from
复制另一个哈希表的内容。首先清空当前哈希表的buckets向量。预留空间以匹配目标哈希表ht的桶数量。向buckets中插入null指针,初始化每个桶。使用STL_TRY块来处理复制过程,确保在发生异常时能够安全清理。遍历目标哈希表的每个桶,将节点的值复制到新创建的节点中,保持链表结构。最后,更新当前哈希表的节点总数为目标哈希表的节点数量。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::copy_from(const hashtable& ht) {// 先清除己方的 buckets vectorbuckets.clear(); // 清空当前哈希表的内容// 为己方的 buckets vector 保留空间,使与对方相同buckets.reserve(ht.buckets.size());// 插入 n 个 null 指针buckets.insert(buckets.end(), ht.buckets.size(), (node*)0);STL_TRY {// 针对 buckets vectorfor (size_type i = 0; i < ht.buckets.size(); ++i) {if (const node* cur = ht.buckets[i]) {node* copy = new_node(cur->val); // 复制第一个节点buckets[i] = copy; // 设置当前桶的头节点// 针对同一个 bucket list 复制每一个节点for (node* next = cur->next; next; cur = next, next = cur->next) {copy->next = new_node(next->val); // 复制后续节点copy = copy->next; // 移动到新节点}}}}num_elements = ht.num_elements; // 重新登录节点个数STL_UNWIND(clear()); // 异常时清理资源
}hashtable 运用实例
// file: hashtable-test.cpp
// 注意:客户端程序不能直接包含 <stl_hashtable.h>,
// 应该包含有用到 hashtable 的容器头文件,例如 <hash_set.h> 或 <hash_map.h>
#include <hash_set> // for hashtable
#include <iostream>
using namespace std;
int main() {// 创建哈希表// <value, key, hash-func, extract-key, equal-key, allocator>// 注意:哈希表没有默认构造函数hashtable<int, int, hash<int>, identity<int>, equal_to<int>, alloc> iht(50, hash<int>(), equal_to<int>());// 输出哈希表的信息cout << iht.size() << endl; // 输出当前元素数量,初始为0cout << iht.bucket_count() << endl; // 输出桶数量,应该是53(第一个质数)cout << iht.max_bucket_count() << endl; // 输出最大桶数量,4294967291// 插入元素iht.insert_unique(59);iht.insert_unique(63);iht.insert_unique(108);iht.insert_unique(2);iht.insert_unique(53);iht.insert_unique(55);// 输出当前元素数量cout << iht.size() << endl; // 应为6// 声明一个哈希表迭代器hashtable<int, int, hash<int>, identity<int>, equal_to<int>, alloc>::iterator ite = iht.begin();// 以迭代器遍历哈希表,输出所有节点的值for (int i = 0; i < iht.size(); ++i, ++ite) {cout << *ite << ' '; // 输出所有节点的值}cout << endl;// 遍历所有桶,输出每个桶的节点个数for (int i = 0; i < iht.bucket_count(); ++i) {int n = iht.elems_in_bucket(i);if (n != 0) {cout << "bucket [" << i << "] has " << n << " elems." << endl;}}// 测试表格重建(rehashing)for (int i = 0; i <= 47; i++) {iht.insert_equal(i); // 插入54个元素}// 输出节点数量和新的桶数量cout << iht.size() << endl; // 应为54cout << iht.bucket_count() << endl; // 应为97// 再次遍历所有桶,输出节点个数for (int i = 0; i < iht.bucket_count(); ++i) {int n = iht.elems_in_bucket(i);if (n != 0) {cout << "bucket [" << i << "] has " << n << " elems." << endl;}}// 再次以迭代器遍历哈希表,输出所有节点的值ite = iht.begin();for (int i = 0; i < iht.size(); ++i, ++ite) {cout << *ite << ';'; // 输出所有节点的值}cout << endl;// 查找元素cout << *(iht.find(2)) << endl; // 查找并输出值为2的节点cout << iht.count(2) << endl; // 输出值为2的节点个数return 0;
}find函数 和 count函数
find函数
函数用于查找具有特定键值的元素,并返回一个迭代器指向该元素。首先,通过bkt_num_key(key)确定该元素应位于哪个桶(bucket)。接着从该桶的头节点开始循环遍历链表,使用equals函数比较每个节点的键值与目标键值。一旦找到匹配的键值,循环结束,返回一个指向该节点的迭代器。如果未找到匹配,返回的迭代器将指向空。
count函数:
函数用于计算特定键值在哈希表中的出现次数。同样地,首先通过bkt_num_key(key)确定该元素应位于哪个桶。然后,从该桶的头节点开始,循环遍历链表。对于每个节点,使用equals函数判断键值是否与目标键值相同。如果匹配,result计数器加1。最后返回result,即该键值的总出现次数。
//查找元素的迭代器
iterator find(const key_type& key) {size_type n = bkt_num_key(key); // 首先找到元素应该落在哪一个桶内node* first;// 从桶的头部开始,依次比较每个元素的键值for (first = buckets[n]; first && !equals(get_key(first->val), key); first = first->next) {// 循环直到找到匹配的键值,或到达链表末尾}return iterator(first, this); // 返回迭代器,指向找到的节点或为空
}
//计算特定键值的出现次数
size_type count(const key_type& key) const {const size_type n = bkt_num_key(key); // 首先找到元素应该落在哪一个桶内size_type result = 0;// 从桶的头部开始,依次比较每个元素的键值for (const node* cur = buckets[n]; cur; cur = cur->next) {if (equals(get_key(cur->val), key)) {++result; // 如果找到匹配,累加计数}}return result; // 返回特定键值的出现次数
}hash functions
//hash function 基础定义
template <class Key> struct hash { };
//字符串的哈希计算函数
inline size_t stl_hash_string(const char* s) {unsigned long h = 0;for (; *s; ++s) {h = 5 * h + *s; // 计算哈希值}return size_t(h);
}
//针对不同类型的哈希函数实现,对于char*类型的哈希函数
STL_TEMPLATE_NULL struct hash<char*> {size_t operator()(const char* s) const { return stl_hash_string(s); }
};
//对于 const char* 类型的哈希函数
STL_TEMPLATE_NULL struct hash<const char*> {size_t operator()(const char* s) const { return stl_hash_string(s); }
};
//对于单字符类型的哈希函数
STL_TEMPLATE_NULL struct hash<char> {size_t operator()(char x) const { return x; }
};
//对于无符号字符类型的哈希函数
STL_TEMPLATE_NULL struct hash<unsigned char> {size_t operator()(unsigned char x) const { return x; }
};
//对于有符号字符类型的哈希函数
STL_TEMPLATE_NULL struct hash<signed char> {size_t operator()(signed char x) const { return x; }
};
//对于短整型的哈希函数
STL_TEMPLATE_NULL struct hash<short> {size_t operator()(short x) const { return x; }
};
//对于无符号短整型的哈希函数
STL_TEMPLATE_NULL struct hash<unsigned short> {size_t operator()(unsigned short x) const { return x; }
};
//对于整型的哈希函数
STL_TEMPLATE_NULL struct hash<int> {size_t operator()(int x) const { return x; }
};
//对于无符号整型的哈希函数
STL_TEMPLATE_NULL struct hash<unsigned int> {size_t operator()(unsigned int x) const { return x; }
};
//对于长整型的哈希函数
STL_TEMPLATE_NULL struct hash<long> {size_t operator()(long x) const { return x; }
};
//对于无符号长整型的哈希函数
STL_TEMPLATE_NULL struct hash<unsigned long> {size_t operator()(unsigned long x) const { return x; }
};对于整型和字符型数据,哈希函数通常直接返回原值。
对于字符串,调用 stl_hash_string 函数以计算哈希值(每位的ascii码值然后乘以5)。
SGI hashtable 无法处理上述所列各项型别以外的元素,例如string,double,float。欲处理这些型别,用户必须自行为它们定义 hash function。
相关文章:
STL源码剖析:Hashtable
hashtable 概述 哈希表是一种数据结构,它提供了快速的数据插入、删除和查找功能。它通过使用哈希函数将键(key)映射到表中的一个位置来实现这一点,这个位置称为哈希值或索引。哈希表使得这些操作的平均时间复杂度为常数时间&…...

spring-boot学习(2)
上次学习截止到拦截器 1.构建RESfun服务 PathVariable通过url路径获取url传递过来的信息 2.MyBatisPlus 第三行的mydb要改为自己的数据库名 第四,五行的账号密码改成自己的 MaooerScan告诉项目自己的这个MyBatisPlus是使用在哪里的,包名 实体类的定义…...

《案例》—— OpenCV 实现2B铅笔填涂的答题卡答案识别
文章目录 一、案例介绍二、代码解析 一、案例介绍 下面是一张使用2B铅笔填涂选项后的答题卡 使用OpenCV 中的各种方法进行真确答案识别,最终将正确填涂的答案用绿色圈出,错误的答案不圈出,用红色圈出错误题目的正确答案最终统计正确的题目数…...
新员工入职流程指南_完整入职流程解析
文章介绍了新员工入职流程的重要性、步骤及持续时间,并推荐ZohoPeople软件自动化管理入职流程,提升新员工入职体验,减少离职率,确保合规性,提升公司品牌形象。 一、新员工入职流程是怎样的? 入职流程是指一…...

mysql查看和修改默认配置
1.查看最大连接数 SELECT max_connections; 或者 SHOW VARIABLES LIKE max_connections;2.查看当前连接的客户端 SHOW PROCESSLIST;2.临时设置最大连接数 SET GLOBAL max_connections 500;3.临时设置连接客户端交互超时时间 SET GLOBAL interactive_timeout 1800;4.永久生…...

海外云手机:出海电商养号智能化方案
随着出海电商的迅猛发展,使用海外云手机进行养号已经成为越来越多商家的新选择。尤其在社交电商推广和短视频引流方面,海外云手机不仅提高了流量的精准度,还助力商家实现业务的快速增长。本文将探讨海外云手机养号相较于传统模式的优势&#…...
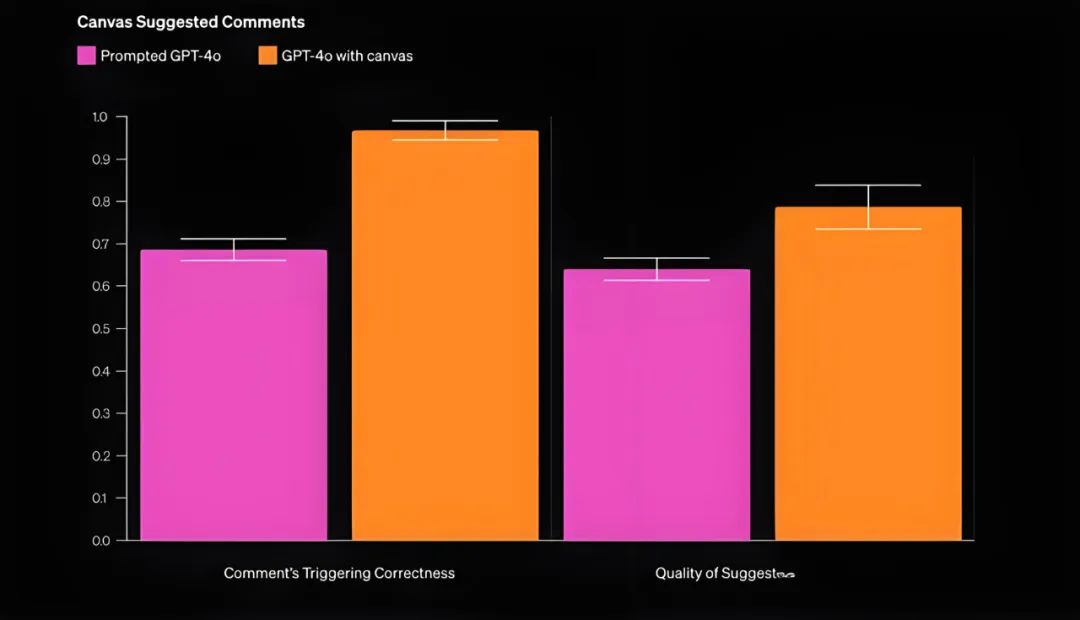
OpenAI Canvas用户反馈:并不如外界传言般“炸裂”,更不是“AGI的终极交互形态” | LeetTalk Daily...
“LeetTalk Daily”,每日科技前沿,由LeetTools AI精心筛选,为您带来最新鲜、最具洞察力的科技新闻。 Canvas作为一个独立的界面,通过与ChatGPT的结合来提升用户的协作能力和创作效率。尽管用户对其独立性与现有工具的整合存在不同…...

RiproV9.0主题wordpress主题免扩展可二开PJ版/WordPress博客主题Ripro全解密无后门版本
🔥🎉 全新RiPro9.0开源版发布 —— 探索无限可能🚀🌐 今天,我很高兴能与大家分享一个重磅资源——RiPro9.0开源版!这不是一个普通的版本,而是一个经过精心打磨、全面解密的力作。🔍…...

[LeetCode] 515. 在每个树行中找最大值
题目描述: 给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。 示例1: 输入: root [1,3,2,5,3,null,9] 输出: [1,3,9]示例2: 输入: root [1,2,3] 输出: [1,3]提示: 二叉树的节点个数的范围是 [0,10…...

【分布式微服务云原生】《微服务架构大揭秘:流行框架与服务治理攻略》
标题:《微服务架构大揭秘:流行框架与服务治理攻略》 摘要:本文深入探讨了流行的微服务架构框架,包括 Spring Cloud、Docker Kubernetes、Dubbo、Service Mesh 和 Serverless 架构,详细介绍了它们的关键组件和服务治理…...

uniapp uni.uploadFile errMsg: “uploadFile:fail
uniapp 上传后一直显示加载中 1.检查前后端上传有无问题 2.检查失败信息 await uni.uploadFile({url,filePath,name,formData,header,timeout: 30000000, // 自定义上传超时时间fail: async function(err) {$util.hideAll()// 失败// err 返回 {errMsg: "uploadFile:fai…...

一个常见问题:TCP和UDP是否可以使用一个端口
TCP(传输控制协议)和UDP(用户数据报协议)做为两种被广泛使用的协议,它们在处理数据时采用不同的机制,那么有一个问题,在同一系统内,TCP和UDP的服务是否可以使用同一个端口呢…...
)
前端报错:‘vue-cli-service‘ 不是内部或外部命令,也不是可运行的程序(node_modules下载不下来)
原因:Vue CLI 没有被正确安装,或者其安装路径没有被添加到你的系统环境变量中。 一、确认 Vue CLI 是否已安装: 打开命令行工具(例如 CMD、PowerShell、Terminal),输入以下命令来检查 Vue CLI 是否已安装…...

白日门【鬼服无限刀】win服务端+安卓客户端+教程+GM后台
演示系统:Windows Server 2012 -------------------------------------------------------------------------------------------------------------------------- 把服务端上传解压缩到服务器D盘根目录:D:\【解压完成后检查路径是否正确:D:\】 安装基础运行环境&…...

如何迅速的了解一个人
目录 社会经济背景 生活满意度 爱心和同情心 如果你想迅速地了解一个人,问他问题是最快捷的方法。不论你是相亲、工作、而试、看医生还是为孩子找个学校,事先设计好你想提出的问题,想好你究竟要搜罗对方哪一方面的信息这样做会实现许多目…...

Window和Linux远程调度kettle
在windows和linux分别安装kettle,我的是pdi-ce-8.2.0.0-342版本,在windows中配置好之后,直接放到虚拟机的目录下 在cmd窗口中到kettle根目录下执行 (carte ip 端口 ),出现如下提示即启动成功 在远程端…...

设定义结构变量
在C语言中,可以使用struct关键字来定义结构变量。结构变量是由多个不同类型的成员变量组成的数据类型,可以在一个变量中存储多个相关的数据。 定义结构变量的语法如下: struct 结构名 {数据类型 成员1;数据类型 成员2;... };例如࿰…...

SSD |(七)FTL详解(中)
文章目录 📚垃圾回收🐇垃圾回收原理🐇写放大🐇垃圾回收实现🐇垃圾回收时机 📚解除映射关系📚磨损均衡 📚垃圾回收 🐇垃圾回收原理 ✋设定一个迷你SSD空间: 假…...

Swift 协议:深入解析与高级应用
Swift 协议:深入解析与高级应用 Swift 协议是 Swift 编程语言中的一项核心特性,它提供了一种定义接口和实现多态的强大方式。本文将深入探讨 Swift 协议的概念、用法和高级应用,帮助读者更好地理解和运用这一特性。 什么是 Swift 协议&…...

API项目3:API签名认证
问题引入 我们为开发者提供了接口,却对调用者一无所知 假设我们的服务器只能允许 100 个人同时调用接口。如果有攻击者疯狂地请求这个接口,那是很危险的。一方面这可能会损害安全性,另一方面耗尽服务器性能,影响正常用户的使用。…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...

从无人机到自动驾驶:一文读懂ROS中ENU、NED、相机坐标系到底怎么用
从无人机到自动驾驶:ROS中ENU、NED与相机坐标系实战指南 当你在无人机上安装Realsense相机时,是否遇到过相机数据与飞控数据"对不上"的情况?或者在自动驾驶项目中,GPS的北东地坐标如何与激光雷达的东北天坐标对齐&#…...