机器学习核心:监督学习与无监督学习
个人主页:chian-ocean
文章专栏
监督学习与无监督学习:深度解析
机器学习是现代人工智能的核心支柱,已广泛应用于从数据挖掘到计算机视觉再到自然语言处理的诸多领域。作为机器学习最主要的两大类型,监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)构成了不同应用需求的基础。本篇文章将深度探讨这两种学习范式的理论、应用场景、以及各种常见算法的实现,并通过详细的代码实例帮助读者掌握其中的精髓。
目录
- 什么是监督学习?
- 监督学习的应用
- 监督学习的算法概述
- 什么是无监督学习?
- 无监督学习的应用
- 无监督学习的算法概述
- 监督学习的实现
- 线性回归
- 决策树
- 无监督学习的实现
- K均值聚类
- 主成分分析
- 监督学习与无监督学习的对比
- 总结与思考
什么是监督学习?

监督学习是一种基于已标记数据进行训练的学习方式。在训练过程中,算法会接受输入数据及其对应的标签(或者称为输出),以此来学习输入和输出之间的关系。其主要目的是找到一个从输入到输出的映射函数,使得模型能够对新数据进行预测。
监督学习可以进一步分为:
- 分类:将输入分配到离散的类别中,例如垃圾邮件检测。
- 回归:预测连续的数值输出,例如预测房价。
监督学习的应用
监督学习在许多领域中都有广泛的应用,包括但不限于:
- 医疗诊断:基于病患数据预测疾病种类。
- 金融预测:如股票价格、市场走势预测。
- 自然语言处理:如文本情感分析、语音识别等。
- 计算机视觉:物体识别、面部识别等。
监督学习的算法概述
监督学习的经典算法包括:
- 线性回归:适用于预测连续型变量。
- 逻辑回归:一种用于二元分类的线性模型。
- 决策树:基于树状结构的决策算法,简单直观。
- 随机森林:决策树的集成模型,用于提升模型的准确性和鲁棒性。
- 支持向量机:通过寻找最佳分隔超平面来进行分类。
接下来,我们将通过代码详细实现其中一些典型的算法。
什么是无监督学习?
与监督学习不同,无监督学习是在没有标签的数据集上进行训练的学习方式。其主要目的是发现数据中的结构、模式、或者隐藏的关系。无监督学习更加关注数据的内部相似性和聚集特征,通常用于数据探索和降维。
无监督学习主要包括:
- 聚类:将相似的数据点归为一类,例如客户细分。
- 降维:将高维数据投射到低维空间,以便于可视化和处理,例如主成分分析(PCA)。
无监督学习的应用
无监督学习的应用包括:
- 客户细分:在市场营销中,根据客户特征进行分群。
- 图像压缩:通过提取主要特征来降低图像的维度。
- 异常检测:发现数据中不寻常的模式,如信用卡欺诈检测。
无监督学习的算法概述
常见的无监督学习算法有:
- K均值聚类:将数据集分为K个簇,使得每个簇内的数据点相似度较高。
- 层次聚类:逐层构建数据的层次结构。
- 主成分分析(PCA):用于数据降维和特征提取。
- 自编码器:一种神经网络用于学习数据的有效编码。
接下来,我们通过代码实现一些无监督学习中的经典算法。
监督学习的实现
线性回归
线性回归是一种用于回归问题的简单而有效的算法。它假设输入特征和输出之间存在线性关系。以下是使用scikit-learn实现线性回归的代码。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 生成示例数据
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建线性回归模型并进行训练
model = LinearRegression()
model.fit(X_train, y_train)# 进行预测
y_pred = model.predict(X_test)# 绘制结果
plt.scatter(X_test, y_test, color='blue', label='Actual')
plt.plot(X_test, y_pred, color='red', label='Predicted')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
决策树
决策树是一种基于树状结构的监督学习算法。它通过学习数据中的规则来构建树模型,从而进行预测。以下是一个简单的决策树分类器的实现。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target# 创建决策树模型并进行训练
clf = DecisionTreeClassifier(max_depth=3)
clf.fit(X, y)# 可视化决策树
tree.plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
在上述代码中,我们利用DecisionTreeClassifier对经典的鸢尾花数据集进行了训练,并通过plot_tree()方法对生成的决策树进行可视化。
无监督学习的实现
K均值聚类
K均值聚类是一种无监督学习算法,它通过反复迭代将数据点分为K个簇。以下是K均值聚类的实现。
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 生成示例数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.6, random_state=0)# 使用K均值聚类
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)# 获取簇中心和簇标签
centroids = kmeans.cluster_centers_
labels = kmeans.labels_# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='rainbow', s=30)
plt.scatter(centroids[:, 0], centroids[:, 1], s=300, c='black', marker='X')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('K-means Clustering')
plt.show()
在此代码中,我们生成了一组二维数据,使用K均值聚类算法将数据分为4个簇,并通过图形化方式展示聚类结果。
主成分分析
**主成分分析(PCA)**是一种常用的降维方法,特别适合处理高维数据。它通过寻找数据的主要成分,将数据降到低维空间。以下是使用PCA对鸢尾花数据集进行降维的实现。
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = load_iris()
X = iris.data# 使用PCA降维到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)# 可视化降维后的数据
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iris.target, cmap='viridis', s=50)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.show()
监督学习与无监督学习的对比
| 特性 | 监督学习 | 无监督学习 |
|---|---|---|
| 数据集 | 带标签的数据 | 无标签的数据 |
| 目标 | 预测目标输出 | 发现数据内在结构 |
| 主要任务 | 分类和回归 | 聚类和降维 |
| 应用场景 | 邮件分类、图像识别 | 客户分群、特征提取 |
| 复杂性 | 需要标注大量数据 | 数据解释难度较大 |
从上述对比中可以看出,监督学习更适合有明确目标的任务,如分类和回归问题。而无监督学习更适合对数据进行探索、发现隐藏模式的场景。
总结与思考
本文详细探讨了监督学习与无监督学习的理论和应用,介绍了它们在不同任务中的适用场景,并通过代码实例演示了经典算法的实现。监督学习更适合解决需要明确预测目标的任务,如分类和回归,而无监督学习则专注于数据结构的发现,如聚类和降维。
机器学习的世界广袤而丰富,监督学习和无监督学习只是其中的两块基石。对于希望深入机器学习领域的读者来说,掌握这两类学习方式的核心思想和实践技巧是非常重要的。在实际应用中,选择合适的算法,理解其优缺点,并结合具体场景进行调优,才能真正发挥机器学习的潜力。
希望通过这篇文章,大家能对监督学习与无监督学习有更加深刻的理解,并在自己的项目中应用这些知识,解决实际问题。如果你想更深入地探讨某个算法,或者想了解更多关于其他类型机器学习(如半监督学习或强化学习)的内容,请随时联系我,一起探索更广阔的机器学习世界。
相关文章:
机器学习核心:监督学习与无监督学习
个人主页:chian-ocean 文章专栏 监督学习与无监督学习:深度解析 机器学习是现代人工智能的核心支柱,已广泛应用于从数据挖掘到计算机视觉再到自然语言处理的诸多领域。作为机器学习最主要的两大类型,监督学习(Super…...

服务器托管的优缺点有哪些?
由于数字化程度不断提高,服务器在日常业务中发挥着越来越重要的作用。在大多数情况下,服务器由公司自己维护和管理。但对于一些公司来说,托管服务器(将这些任务交给专业人员)是更好的选择。 关于服务器的优缺点,有一点是明确的&am…...

RestClient查询文档排序、分页和高亮
目录 排序、分页 高亮 高亮请求构建 高亮结果解析 排序、分页 搜索结果的排序和分页是与query同级的参数,因此同样是使用request.source()来设置。 对应的API如下: 完整代码示例: Test void testPageAndSort() throws IOException {// …...

API项目5:申请签名 在线调用接口
开发申请签名 现在用户已经能看到这个接口了,也能看到这个接口文档,接下来就要在线调用 现在我们可以给每个新注册的用户自动分配一个签名和密钥,去修改一下注册流程: backend 项目,找到 UserServiceImpl.java 中的…...

Google FabricDiffusion:开启3D虚拟试穿新篇章
随着数字化转型的步伐不断加快,时尚界也在探索如何利用最新技术为消费者带来更加沉浸式的购物体验。在这一背景下,Google 推出了一项名为 FabricDiffusion 的新技术,这项技术能够将2D服装图像中的高质量织物纹理转移到任意形状的3D服装模型上,从而为3D虚拟试穿提供了更为真…...

【开发语言】c++的发展前景
C作为一种历史悠久且功能强大的编程语言,在软件开发领域一直保持着其独特的地位和广泛的应用前景。尽管近年来出现了许多新的编程语言和技术趋势,但C由于其高性能、低层访问能力以及广泛的生态系统,在多个领域依然具有不可替代的优势。以下是…...

【机器学习】图像识别——计算机视觉在工业自动化中的应用
1. 引言 随着人工智能(AI)和机器学习(ML)的快速发展,计算机视觉已成为工业自动化中的核心技术之一。图像识别,作为计算机视觉领域的重要分支,能够通过分析和理解图像或视频数据来识别、分类或检…...

lstm基础知识
lstm前言 LSTM(Long short-term memory)通过刻意的设计来避免长期依赖问题,是一种特殊的RNN。长时间记住信息实际上是 LSTM 的默认行为,而不是需要努力学习的东西! 在标准的RNN中,这个重复模块具有非常简单的结构,例…...

Linux :at crontab简述
at命令 在指定的日期、时间点自动执行预先设置的一些命令操作,属于一次性计划任务系统服务的名称:/etc/init.d/atd存放一次性计划任务的文件:/var/spool/at/^a 依靠 /etc/at.allow(白名单)和 /etc/at.deny(…...

Python,Swift,Haskell三种语言在使用正则表达式上的方法对比
这里插入图片描述](https://i-blog.csdnimg.cn/direct/fea1494d0d0c4c9880881493929a8b91.png)在讨论 Python、Swift 和 Haskell 在正则表达式处理字符串方面的优缺点时,可以从它们对正则表达式的支持、灵活性和性能进行比较。以下通过具体的正则表达式字符串匹配例…...

leetcode力扣刷题系列——【三角形的最大高度】
题目 给你两个整数 red 和 blue,分别表示红色球和蓝色球的数量。你需要使用这些球来组成一个三角形,满足第 1 行有 1 个球,第 2 行有 2 个球,第 3 行有 3 个球,依此类推。 每一行的球必须是 相同 颜色,且相…...

工业相机解决方案
工业相机是一种特殊类型的相机,适用于恶劣条件(如高温、高压和振动)下的工作,在控制生产周期、跟踪输送机上的单元、检测超小零件等方面发挥着重要作用。针对工业相机的解决方案,朗观视觉小编认为,可以从以…...

设计一个高效的日志分析系统:自动检测错误日志的实用指南
设计一个高效的日志分析系统:自动检测错误日志的实用指南 在现代软件开发和运维中,日志分析是确保系统稳定性和性能的重要环节。通过对日志的分析,开发者和运维人员可以快速定位问题、优化性能并提高用户体验。本文将介绍如何设计一个日志分析系统,重点关注错误日志的自动…...

英语学习--如果你的父母不听你的话
所有的 Eng中文Eng中文children小孩儿们opposite…在…对面maths数学to take带走;接受;乘坐a way方法,道brave勇敢的few很少more很多more更多able能够when什么时候;…的时候to own拥有a child孩子later一会儿to feel感觉to find找…...
)
LeetCode:3258.统计满足k约束的子串数量 I(滑动窗口 Java)
目录 3258.统计满足k约束的子串数量 I 题目描述: 实现代码与解析: 滑动窗口 原理思路: 3258.统计满足k约束的子串数量 I 题目描述: 给你一个 二进制 字符串 s 和一个整数 k。 如果一个 二进制字符串 满足以下任一条件&#…...

如果用Java设计MySQL中表级锁、行级锁和间歇锁会是怎么的?
在 MySQL 中,锁机制是确保数据一致性和并发控制的重要手段。MySQL 支持多种锁类型,包括表级锁、行级锁等,每种锁的适用场景、影响范围和实现机制各不相同。我们将逐一介绍它们,并通过模拟代码展示不同锁的实现。 1. 锁类型及其影…...

GIT batch的支持中文的方法和系统建议
GIT batch是window下原生的GIT命令行终端,兼顾了GIT的命令特性,同时也支持很多UNIX的原生的bash交互方法。但是由于编码问题,在使用GIT bach的时候,用户可能会遇到中文支持的问题。这里简单介绍一下GIT batch在Windows系统下如何有…...
骑砍霸主MOD天芒传奇Ⅱ·前传-序章
基于少年包青天第一到三部的闯关夺宝MOD,故事发生在北宋仁宗年间,玩家需要代替包拯寻找天芒,最终完成统一大业.开局可尝试使用暴雨梨花针神器. MOD下载地址: 【免费】PLReminiscence资源-CSDN文库https://download.csdn.net/download/qq_35829452/89851155效果演示: 骑砍2霸…...
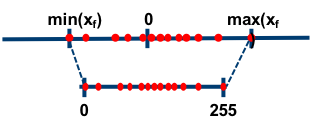
神经网络量化基础
1,模型量化概述 1.1,模型量化优点1.2,模型量化的方案 1.2.1,PTQ 理解 1.3,量化的分类 1.3.1,线性量化概述 2,量化算术 2.1,定点和浮点2.2,量化浮点2.2,量化算…...

飞机大战告尾
参考 PPO算法逐行代码详解 链接 通过网盘分享的文件:PlaneWar 链接: https://pan.baidu.com/s/1cbLKTcBxL6Aem3WkyDtPzg?pwd1234 提取码: 1234 10.17关于博客发了又改这件事 悲催的事 今天训练了一早上ppo模型,满怀期待的检测成果时发现一点长进都…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...