Python无监督学习中的聚类:K均值与层次聚类实现详解
📘 Python无监督学习中的聚类:K均值与层次聚类实现详解
无监督学习是一类强大的算法,能够在没有标签的数据集中发现结构与模式。聚类作为无监督学习的重要组成部分,在各类数据分析任务中广泛应用。本文将深入讲解聚类算法中的两种常见方法:K均值聚类和层次聚类,结合Python代码详细介绍它们的实现与应用,帮助理解不同聚类方法的优劣与使用场景。
目录
- 🔗 聚类的核心思想与应用场景
- 📊 K均值聚类:快速高效的聚类方法
- 🔝 层次聚类:基于层次结构的灵活聚类
- 🆚 K均值与层次聚类的比较
- 🚀 实践:如何选择合适的聚类方法
- 🌐 拓展:结合轮廓系数评估聚类效果
1. 🔗 聚类的核心思想与应用场景
聚类是一种将数据划分为多个组(或称为簇)的技术,每个簇内的数据点具有较高的相似性,而簇间的数据点则差异较大。聚类的核心目标是寻找数据的潜在模式和结构,而不依赖于标签信息。
应用场景:
- 市场细分:根据顾客的购买行为,将其划分为不同的细分市场,便于进行精准营销。
- 图像分割:将图像分割为多个区域,用于图像处理与分析。
- 异常检测:通过聚类发现异常数据点,这些数据点通常位于簇的边界之外。
2. 📊 K均值聚类:快速高效的聚类方法
K均值聚类是最常用的聚类算法之一。它通过不断迭代来将数据集分成K个簇,并使得每个簇的中心与其成员数据点之间的距离最小化。K均值算法的主要步骤包括:
- 随机选择K个初始中心点(即质心)。
- 将每个数据点分配给距离最近的质心。
- 重新计算每个簇的质心。
- 重复步骤2和3,直到质心不再发生显著变化。
📌 实现K均值聚类
在Python中,使用KMeans类可以轻松实现K均值聚类。以下代码展示了如何应用K均值对二维数据进行聚类,并可视化结果。
# 导入相关库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs# 生成示例数据
X, y = make_blobs(n_samples=300, centers=4, random_state=42, cluster_std=0.60)# 创建K均值聚类模型,设定K=4
kmeans = KMeans(n_clusters=4)# 训练模型并获取聚类标签
kmeans.fit(X)
y_kmeans = kmeans.predict(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')# 可视化质心
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.title("K均值聚类结果")
plt.show()
🎯 K均值的特点:
- 效率高:K均值算法的时间复杂度较低,能够在较大数据集上快速运行。
- 易于实现:K均值算法简单直观,并且能够在多数任务中表现良好。
- 局限性:K均值依赖于初始质心的选择,容易陷入局部最优解;此外,K的值需要预先设定,不适用于所有数据集。
代码中,使用make_blobs生成了一个包含4个簇的模拟数据集,并通过KMeans类对数据进行聚类。最终,我们使用Matplotlib可视化了聚类结果,其中红色点表示每个簇的质心。
3. 🔝 层次聚类:基于层次结构的灵活聚类
层次聚类是一种通过创建簇的嵌套层次来进行聚类的算法,分为自底向上(凝聚型)和自顶向下(分裂型)两种方法。自底向上的层次聚类开始时将每个数据点视为一个单独的簇,逐渐合并相似簇,直到达到指定的簇数或某一停止条件。它能够生成一棵聚类树,称为树状图。
📌 实现层次聚类
在Python中,可以使用AgglomerativeClustering类实现凝聚型层次聚类,并利用dendrogram函数可视化树状图。
# 导入相关库
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs# 生成示例数据
X, y = make_blobs(n_samples=300, centers=4, random_state=42, cluster_std=0.60)# 使用凝聚层次聚类
agg_clustering = AgglomerativeClustering(n_clusters=4)
y_agg = agg_clustering.fit_predict(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_agg, cmap='viridis')
plt.title("层次聚类结果")
plt.show()# 计算层次聚类的树状图数据
linked = linkage(X, 'ward')# 绘制树状图
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title("层次聚类树状图")
plt.show()
🎯 层次聚类的特点:
- 无需预设簇数:层次聚类不需要预先设定K值,能够自动生成簇的层次结构。
- 结果直观:树状图能够清晰展示数据的聚类层次,便于理解和分析。
- 计算代价高:层次聚类的时间复杂度较高,在大数据集上表现不如K均值高效。
通过AgglomerativeClustering实现了层次聚类,代码中的dendrogram函数生成了对应的树状图,从图中可以清楚地看到聚类的层次结构。在实际应用中,层次聚类非常适合于数据点较少的场景,或需要对聚类结果进行深入分析的任务。
4. 🆚 K均值与层次聚类的比较
K均值和层次聚类在应用场景和算法特点上各具优势,以下是两者的比较:
| 特点 | K均值聚类 | 层次聚类 |
|---|---|---|
| 计算复杂度 | 低,适合大数据集 | 高,适合小数据集 |
| 需要预设簇数 | 是,需要预设K值 | 否,可生成层次结构 |
| 簇的形状 | 适用于球状簇 | 能处理复杂的簇形 |
| 对噪声和异常点的敏感性 | 对异常点敏感 | 相对不敏感 |
| 结果可解释性 | 结果较简单 | 树状图提供丰富的解释性 |
在选择聚类方法时,需要考虑数据集的大小、簇的形状、计算资源以及对聚类结果的要求等因素。K均值在大规模数据上的表现优异,而层次聚类则提供了更多分析层次和解释性。
5. 🚀 实践:如何选择合适的聚类方法
选择聚类方法时,应从以下几个维度进行考量:
- 数据规模:K均值算法适合大规模数据集,层次聚类更适合小规模数据集。
- 簇的形状:如果簇的形状复杂且非球形,层次聚类往往能给出更合理的划分结果。
- 簇数的确定:如果聚类数未知或希望获取层次结构信息,层次聚类是更好的选择;而K均值需要预设K值。
- 计算资源:K均值算法在大数据集上的速度优势明显,适合资源有限的情况。
6. 🌐 拓展:结合轮廓系数评估聚类效果
为了客观评估聚类结果的质量,可以
使用轮廓系数。轮廓系数通过比较每个数据点与簇内其他点的距离与其与最近簇的距离,给出聚类效果的度量。
📌 实现轮廓系数评估
from sklearn.metrics import silhouette_score# K均值聚类模型
kmeans = KMeans(n_clusters=4)
kmeans_labels = kmeans.fit_predict(X)# 计算K均值的轮廓系数
kmeans_silhouette = silhouette_score(X, kmeans_labels)
print(f"K均值轮廓系数: {kmeans_silhouette}")# 层次聚类模型
agg_clustering = AgglomerativeClustering(n_clusters=4)
agg_labels = agg_clustering.fit_predict(X)# 计算层次聚类的轮廓系数
agg_silhouette = silhouette_score(X, agg_labels)
print(f"层次聚类轮廓系数: {agg_silhouette}")
通过计算轮廓系数,可以量化聚类的紧密程度与分离度,从而辅助选择最佳的聚类方法。
相关文章:

Python无监督学习中的聚类:K均值与层次聚类实现详解
📘 Python无监督学习中的聚类:K均值与层次聚类实现详解 无监督学习是一类强大的算法,能够在没有标签的数据集中发现结构与模式。聚类作为无监督学习的重要组成部分,在各类数据分析任务中广泛应用。本文将深入讲解聚类算法中的两种…...

C++ 中 new 和 delete 详解,以及与 C 中 malloc 和 free 的区别
1. C 中 new 和 delete 的基本用法 在 C 中,new 和 delete 是用来动态分配和释放内存的关键字,它们是面向对象的替代方式,提供了比 C 语言更优雅的内存管理工具。 1.1 new 的使用 new 用于从堆中分配内存,并且自动调用对象的构造…...

YOLOv11来了 | 自定义目标检测
概述 YOLO11 在 2024 年 9 月 27 日的 YOLO Vision 2024 活动中宣布:https://www.youtube.com/watch?vrfI5vOo3-_A。 YOLO11 是 Ultralytics YOLO 系列的最新版本,结合了尖端的准确性、速度和效率,用于目标检测、分割、分类、定向边界框和…...
Vue3 集成Monaco Editor编辑器
Vue3 集成Monaco Editor编辑器 1. 安装依赖2. 使用3. 效果 Monaco Editor (官方链接 https://microsoft.github.io/monaco-editor/)是一个由微软开发的功能强大的在线代码编辑器,被广泛应用于各种 Web 开发场景中。以下是对 Monaco Editor 的…...

一文详解Mysql索引
背景 索引是存储引擎用于快速找到一条记录的数据结构。索引对良好的性能非常关键。尤其是当表中的数据量越来越大时,索引对性能的影响愈发重要。接下来,就来详细探索一下索引。 索引是什么 索引(Index)是帮助数据库高效获取数据的…...
基于JAVA+SpringBoot+Vue的旅游管理系统
基于JAVASpringBootVue的旅游管理系统 前言 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN[新星计划]导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末附源码下载链接🍅 哈喽兄…...

STM32_实验3_控制RGB灯
HAL_Delay 是 STM32 HAL 库中的一个函数,用于在程序中产生一个指定时间的延迟。这个函数是基于系统滴答定时器(SysTick)来实现的,因此可以实现毫秒级的延迟。 void HAL_Delay(uint32_t Delay); 配置引脚: 点击 1 到 IO…...

RISC-V笔记——Pipeline依赖
1. 前言 RISC-V的RVWMO模型主要包含了preserved program order、load value axiom、atomicity axiom、progress axiom和I/O Ordering。今天主要记录下preserved program order(保留程序顺序)中的Pipeline Dependencies(Pipeline依赖)。 2. Pipeline依赖 Pipeline依赖指的是&a…...

构建后端为etcd的CoreDNS的容器集群(六)、编写自动维护域名记录的代码脚本
本文为系列测试文章,拟基于自签名证书认证的etcd容器来构建coredns域名解析系统。 一、前置文章 构建后端为etcd的CoreDNS的容器集群(一)、生成自签名证书 构建后端为etcd的CoreDNS的容器集群(二)、下载最新的etcd容…...

Leetcode 剑指 Offer II 098.不同路径
题目难度: 中等 原题链接 今天继续更新 Leetcode 的剑指 Offer(专项突击版)系列, 大家在公众号 算法精选 里回复 剑指offer2 就能看到该系列当前连载的所有文章了, 记得关注哦~ 题目描述 一个机器人位于一个 m x n 网格的左上角 (起始点在下…...
LabVIEW智能螺杆空压机测试系统
基于LabVIEW软件开发的螺杆空压机测试系统利用虚拟仪器技术进行空压机的性能测试和监控。系统能够实现对螺杆空压机关键性能参数如压力、温度、流量、转速及功率的实时采集与分析,有效提高测试效率与准确性,同时减少人工操作,提升安全性。 项…...

在 Ubuntu 22.04 上安装 PHP 8.2
在 Ubuntu 22.04 上安装 PHP 8.2,可以按照以下步骤进行: 更新系统软件包: 首先,确保你的系统软件包是最新的。 sudo apt update sudo apt upgrade 安装 PHP PPA(Personal Package Archive): U…...

Java生死簿管理小系统(简单实现)
学习总结 1、掌握 JAVA入门到进阶知识(持续写作中……) 2、学会Oracle数据库入门到入土用法(创作中……) 3、手把手教你开发炫酷的vbs脚本制作(完善中……) 4、牛逼哄哄的 IDEA编程利器技巧(编写中……) 5、面经吐血整理的 面试技…...
【VoceChat】一个即时聊天(IM)软件,又是一个可以嵌入任何网页聊天系统
为什么要搭建私人聊天软件 在当今数字化时代,聊天软件已经成为人们日常沟通和协作的重要工具。市面上的公共聊天平台虽然方便,但也伴随着诸多隐私、安全、广告和功能限制的问题。对于那些注重数据安全、追求高效沟通的个人或团队来说,搭建一…...

【LeetCode】动态规划—96. 不同的二叉搜索树(附完整Python/C++代码)
动态规划—96. 不同的二叉搜索树 题目描述前言基本思路1. 问题定义2. 理解问题和递推关系二叉搜索树的性质:核心思路:状态定义:状态转移方程:边界条件: 3. 解决方法动态规划方法:伪代码: 4. 进一…...
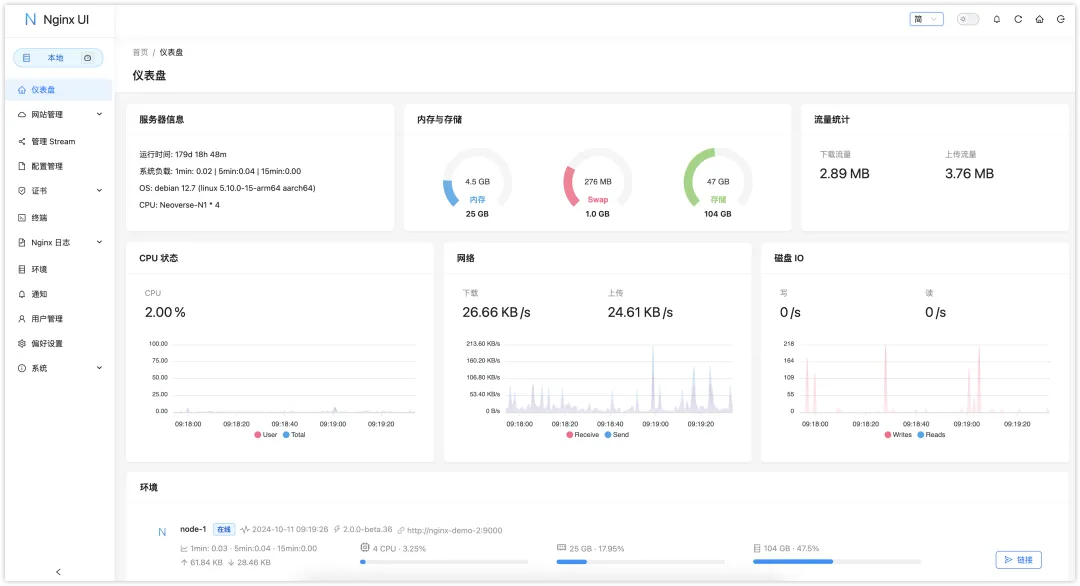
Nginx UI 一个可以管理Nginx的图形化界面工具
Nginx UI 是一个基于 Web 的图形界面管理工具,支持对 Nginx 的各项配置和状态进行直观的操作和监控。 Nginx UI 的功能非常丰富: 在线查看服务器 CPU、内存、系统负载、磁盘使用率等指标 在线 ChatGPT 助理 一键申请和自动续签 Let’s encrypt 证书 在…...

Vue向上滚动加载数据时防止内容闪动
目前的需求:当前组件向上滚动加载数据,dom加载完后,页面的元素位置不能发生变化 遇到的问题:加载完数据后,又把滚轮滚到之前记录的位置时,内容发生闪动 现在的方案: 加载数据之前记录整体滚动条…...

基于QT、ARM的智能停车管理系统+高分项目+源码
Parking-management-system 本系统基于QT、ARM开发板、Linux系统并对接百度AI 1.1 项目目的: 创建一个智能停车管理系统,能够停入车辆和取出车辆以及查询车辆停入停车场的状态并且计算车辆离开时收费情况。 1.2 项目意义: 实现停车场智能抬杆和智能收费系统&…...

1.6,unity动画Animator屏蔽某个部位,动画组合
动画组合 一边跑一边攻击 using System.Collections; using System.Collections.Generic; using UnityEngine;public class One : MonoBehaviour {private Animator anim;// Start is called before the first frame updatevoid Start(){anim GetComponent<Animator>();…...

发动机冷却系统排空气
发动机冷却系统排空气的几种常见方法 发动机冷却系统是汽车发动机的重要组成部分,它的主要作用是通过循环冷却液来吸收和散发发动机产生的热量,确保发动机在正常工作温度下运行。然而,在冷却系统的运行过程中,由于各种原因&#…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

Linux CPU性能优化:D状态和Z状态排查与处理
文章目录一、Linux进程五大基本状态1. 运行状态(R,Running / Runnable)2. 可中断睡眠状态(S,Interruptible Sleep)3. 不可中断睡眠状态(D,Uninterruptible Sleep)4. 停止…...

Linux命令:perf
perf 命令 基本介绍 perf(Performance Counters for Linux)是 Linux 系统中用于性能分析的强大工具套件。它基于内核性能计数器(PMC),可以分析 CPU 使用率、内存访问、缓存命中率、分支预测等硬件级性能指标࿰…...