文档太大LLM处理不过来?这10种LangChain分割技术帮你搞定!
前言
RAG(检索增强生成)是一种创建基于大语言模型(LLM)应用的高效方式。它有助于生成对用户查询的准确回答。为了创建一个基于 RAG 的应用程序,我们需要执行一些操作,例如文档加载、将大文档拆分为多个小块、嵌入、嵌入索引,并将它们存储在向量数据库中。然后根据用户查询,系统从向量数据库中提取相关上下文并传递给提示词以及用户查询。然后 LLM 将用户查询和内容结合起来,生成适当的响应。这是 RAG 系统的整体流程。
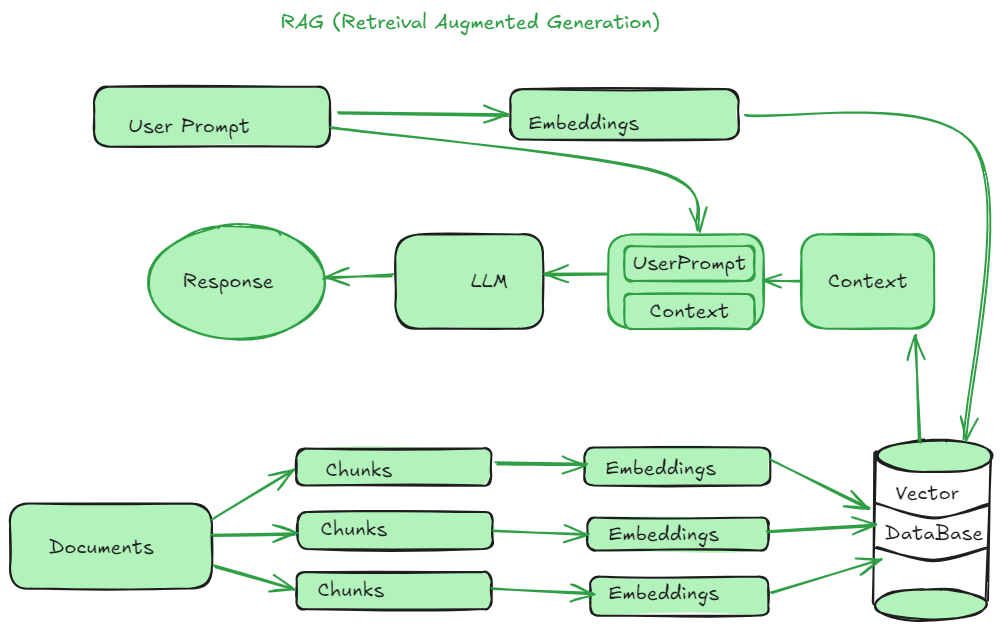
文本分割器 在 LangChain 中有助于将大文档分解为较小的块。在大文档或文本中,很难根据用户查询找到相关的上下文。此外,我们无法将整个大文档传递给 LLM 模型。每个 LLM 模型能处理的 Token 是有限的,因此必须将大文本拆分为较小部分。这样我们就可以轻松地从这些小块中找到相关的上下文,并将其作为输入传递给 LLM,确保输入量低于模型的最大输入大小。因此,文本分割器的 关键使用场景 如下:
-
• 处理超过 LLM 模型 Token 限制的大文档,文本分割技术有助于将文档划分为较小的部分,以便模型处理。
-
• 在问答任务中,较小的文本块在查询、索引和检索方面更有效,而大文档则效率较低。
-
• 它通过在适当的点拆分段落或句子数量,帮助将上下文保留在较小的部分中。这样每个块都包含适当的知识。
-
• LLM 在上下文窗口大小上有 Token 数量限制。即使上下文大小是无限的,更多的输入 Token 也会导致更高的成本,而金钱不是 无限的。
LangChain 中的文本分割技术
LangChain 提供了许多文本分割技术来适应不同类型的数据。今天我们将探索不同的文本分割技术,例如字符文本分割器、递归字符文本分割器、Token 文本分割器、Markdown 标题文本分割器、Python 代码文本分割器、HTML 文本分割器、Spacy 文本分割器、Latex 文本分割器、递归 JSON 文本分割器。如果你有兴趣探索更多的分割技术,请访问这个 LangChain 页面。建议你在自己的系统上运行代码,深入理解这些概念。
首先,安装执行分割技术所需的库。打开命令提示符或终端并运行以下命令。
pip install langchain spacy langchain_text_splitter langchain_core
字符文本分割器
这是最基本的文本分割技术,它根据特定的字符数来划分文本。它适用于简单且统一的文本分割任务。参数 separator 表示文本将只在换行符处拆分,因为使用了 “\n” 作为分隔符。它避免在段落中间拆分。我们可以使用其他分隔符,如空格。块大小表示每个块中的最大字符数,而块重叠表示从前一个块中取多少字符到下一个块中。我们要注意,每个块应该包含有用的知识。
from langchain.text_splitter importCharacterTextSplittertext ="你的长文档文本在这里..."splitter =CharacterTextSplitter(separator="\n\n",chunk_size=10,chunk_overlap=2
)chunks = splitter.split_text(text)
print(chunks)递归字符文本分割器
它使用字符分隔符将大文档分解为较小的块。它递归地尝试使用分隔符层次结构(如段落 \n\n、句子 \n 和字符 .、,)来拆分文本。它优先进行较高级别的拆分(如段落),如果需要则向下移动层次结构。当你需要灵活且分层的方法时,可以尝试这种技术。
from langchain.text_splitter importRecursiveCharacterTextSplittertext ="你的长文档文本在这里..."splitter =RecursiveCharacterTextSplitter(separators=["\n\n","\n"," ",""],chunk_size=1000,chunk_overlap=200,length_function=len
)chunks = splitter.split_text(text)
print(chunks)
Token 文本分割器
它根据 Token 而不是字符或单词来拆分文本。对于有 Token 限制的语言模型来说,这是必要的。它使用模型的 Token 化方法将大文档分割成块。这里我们使用了 OpenAI 的编码来对文档进行 Token 化。
from langchain.text_splitter import TokenTextSplittertext = "你的长文档文本在这里..."splitter = TokenTextSplitter(encoding_name="cl100k_base", chunk_size=100,chunk_overlap=20
)chunks = splitter.split_text(text)
print(chunks)
Markdown 标题文本分割器
这种方法用于根据标题级别(如 #、##、### 等)拆分 Markdown 文档。它使用分层方法,例如将特定标题及其子标题下的文本分开。当你想组织 Markdown 文件中的内容(如技术文档)时,可以尝试这种分割方法。
from langchain.text_splitter importMarkdownHeaderTextSplittermarkdown_text ="""
# 标题
## 部分 1
部分 1 的内容
## 部分 2
部分 2 的内容
### 子部分 2.1
子部分 2.1 的内容
"""headers_to_split_on =[
("#","Header 1"),
("##","Header 2"),
("###","Header 3"),
]splitter =MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
chunks = splitter.split_text(markdown_text)
print(chunks)
Python 代码文本分割器
当你想将 Python 代码分解为较小的逻辑块时,这种技术非常有用。它基于 Python 特定的分隔符(如函数、类等)来拆分代码。
from langchain.text_splitter importPythonCodeTextSplitterpython_code ="""
def function1():print("Hello,World!")class MyClass:def __init__(self):self.value = 42def method1(self):return self.value
"""splitter =PythonCodeTextSplitter(chunk_size=100,chunk_overlap=20
)chunks = splitter.split_text(python_code)
print(chunks)
HTML 文本分割器
当你处理网页时,想要基于 HTML 层次结构进行分割而不破坏文档结构。你可以使用这种技术,它根据文档的结构来拆分 HTML 内容。它识别常见的 HTML 标签,如 <p>、<div>、<h1>等,并根据文档结构拆分文本。
from langchain_text_splitters importHTMLSectionSplitterhtml_text ="""
<html>
<body>
<h1>主标题</h1>
<p>这是一个段落。</p>
<div><h2>子部分</h2><p>另一个段落。</p>
</div>
</body>
</html>
"""headers_to_split_on =[("h1","Header 1"),("h2","Header 2")]
splitter =HTMLSectionSplitter(headers_to_split_on=headers_to_split_on,chunk_size=100,chunk_overlap=20
)chunks = splitter.split_text(html_text)
chunks
Spacy 文本分割器
它使用 Spacy NLP 管道来分割文本,利用 Spacy 的 Token 化和句子分割能力,基于语言规则来拆分文本。当语言细微差别(如句子边界)很重要时,可以尝试这种方法。
from langchain.text_splitter import SpacyTextSplittertext = "你的长文档文本在这里。它可以是多种语言的。SpaCy 将处理语言的细微差别。"splitter = SpacyTextSplitter(chunk_size=100,chunk_overlap=20
)chunks = splitter.split_text(text)
chunks
Latex 文本分割器
当你处理科学论文、数学文档或任何 LaTex 格式的文本时,可以使用这种技术,它在保留其结构的同时拆分文本。它使用 latex 特定的分隔符,如 \\documentclass{}、\\begin{}等,将文本拆分为块。
from langchain.text_splitter importLatexTextSplitterlatex_text = r"""
\documentclass{article}
\begin{document}
\section{引言}
这是引言部分。
\section{方法}
这是方法部分。
\end{document}
"""splitter =LatexTextSplitter(chunk_size=100,chunk_overlap=20
)chunks = splitter.split_text(latex_text)
chunks
递归 JSON 文本分割器
你可以使用它将大型或嵌套的 JSON 对象分割为较小的可管理部分。它递归地拆分 JSON,并通过遍历键和值保持层次结构的顺序。
from langchain_text_splitters importRecursiveJsonSplitterjson_data ={
"company":{
"name":"TechCorp",
"location":{
"city":"Metropolis",
"state":"NY"
},
"departments":[
{
"name":"Research",
"employees":[
{"name":"Alice","age":30,"role":"Scientist"},
{"name":"Bob","age":25,"role":"Technician"}
]
},
{
"name":"Development",
"employees":[
{"name":"Charlie","age":35,"role":"Engineer"},
{"name":"David","age":28,"role":"Developer"}
]
}
]
},
"financials":{
"year":2023,
"revenue":1000000,
"expenses":750000
}
}splitter =RecursiveJsonSplitter(max_chunk_size=200, min_chunk_size=20)chunks = splitter.split_text(json_data, convert_lists=True)for chunk in chunks:
print(len(chunk))
print(chunk)
选择合适的文本分割器
我们之前讨论过递归字符文本分割技术。你也可以使用这种技术递归地分割编程语言。编程语言的结构不同于纯文本,我们可以根据特定语言的语法来拆分代码。
from langchain_text_splitters importRecursiveCharacterTextSplitter,LanguagePYTHON_CODE ="""
def add(a, b):return a + bclass Calculator:def __init__(self):self.result = 0def add(self, value):self.result += valuereturn self.resultdef subtract(self, value):self.result -= valuereturn self.result# 调用函数
def main():calc = Calculator()print(calc.add(5))print(calc.subtract(2))if __name__ == "__main__":main()
"""python_splitter =RecursiveCharacterTextSplitter.from_language(language=Language.PYTHON, chunk_size=100, chunk_overlap=0)python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
如果你不确定哪种分割技术最适合你的 RAG 应用程序,可以选择递归字符文本分割器技术。它作为通用的默认选项,也可以执行专门的分割器,如 MarkdownHeaderTextSplitter、PythonCodeTextSplitter 等,它们为特定的文档格式提供解决方案。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相关文章:
文档太大LLM处理不过来?这10种LangChain分割技术帮你搞定!
前言 RAG(检索增强生成)是一种创建基于大语言模型(LLM)应用的高效方式。它有助于生成对用户查询的准确回答。为了创建一个基于 RAG 的应用程序,我们需要执行一些操作,例如文档加载、将大文档拆分为多个小块…...

TikTok广告账号被封?常见原因及解决方法分享
TikTok广告投放往往会给我们的账号带来高效曝光和精准流量,但同时许多用户也面临着一个困扰——广告账号被封禁的问题。将在此文一起商讨TikTok广告账号被封禁的原因,分析平台的具体规定,提供解决问题的应对策略,帮助大家有效规避…...
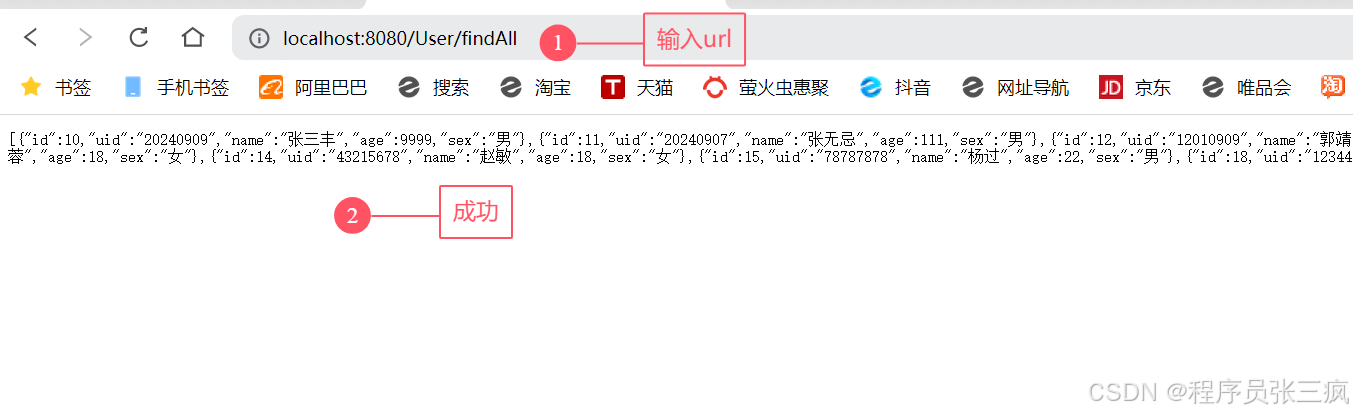
maven聚合ssm
如果没有写过ssm项目请移步SSM后端框架搭建(有图有真相)-CSDN博客 数据库准备 create table user (id int (11),uid varchar (60),name varchar (60),age int (11),sex varchar (12) ); insert into user (id, uid, name, age, sex) values(10,202409…...

网络通信与并发编程(二)基于tcp的套接字、基于udp的套接字、粘包现象
基于tcp的套接字 文章目录 基于tcp的套接字一、套接字的工作流程二、基于tcp的套接字通信三、基于udp的套接字通信四、粘包现象 一、套接字的工作流程 Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个…...

400行程序写一个实时操作系统(十):用面向对象思想构建抢占式内核
前言 通过前几章的学习,我们学会了如何为RTOS设计一个合理的内存管理算法。现在,是时候学习设计RTOS内核了。 关于RTOS内核的文章也有很多,但都有一点先射箭再化靶子的意味。要么是代码连篇解释却寥寥无几,要么是要先怎么样再怎么…...

C#学习笔记(九)
C#学习笔记(九) 第六章 面向对象编程(一)类与对象、字段与属性一、类与对象正确的理解1. 什么是类?2.什么是对象?3. 类与对象的区别 二、类的基本规范和对象使用1. 类的规范 三、类的访问修饰符(…...
意外发现!AI写作这样用,热点文章轻松超越同行90%!
做自媒体,写热点文章很重要。 热点自带流量,能很快吸引不少读者。 可很多自媒体新手很犯愁。 干货文还能勉强写出来,碰到热点文就不知咋办了。 为啥写热点文章这么难呢? 关键是得找个新颖角度切入。 要是只在网上反复复制粘贴那些…...

WPF常见容器全方位介绍
Windows Presentation Foundation (WPF) 是微软的一种用于构建Windows桌面应用程序的UI框架。WPF的布局系统基于容器,帮助开发者以灵活、响应的方式组织用户界面 (UI) 元素。本篇文章将详细介绍WPF中几种常见的容器,包括Grid、StackPanel、WrapPanel、Do…...

重置时把el-tree树节点选中状态取消
要重置 Element UI 的 el-tree 组件并取消所有节点的选中状态,可以通过以下几种方法: 使用 setCheckedKeys 方法: 如果你的树配置了 node-key 属性,可以使用 setCheckedKeys 方法来清空所有选中的节点。 this.$refs.tree.setCheck…...

服务器系统克隆技术
工作任务:克隆对象是Windows server2019 和2022的datacenter版本 条件:在已经完成安装的虚拟机上做克隆 图1-1 用两个服务器的母盘准备进行克隆 第一步:新建一个文件目录用于安放克隆好的服务器 图1-2 创建两个目录用于安放即将克隆好的服务…...

【Java】多线程 Start() 与 run() (简洁实操)
Java系列文章目录 补充内容 Windows通过SSH连接Linux 第一章 Linux基本命令的学习与Linux历史 文章目录 Java系列文章目录一、前言二、学习内容:三、问题描述start() 方法run() 方法 四、解决方案:4.1 重复调用 .run()4.2 重复调用 start()4.3 正常调用…...

基于微信小程序的购物系统【附源码、文档】
博主介绍:✌IT徐师兄、7年大厂程序员经历。全网粉丝15W、csdn博客专家、掘金/华为云//InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇dz…...

AI绘画:24最新Stable Diffusion 终极炼丹宝典:从入门到精通!
前言 我是咪咪酱,以浅显易懂的方式,与大家分享那些实实在在可行之宝藏。 历经耗时数十个小时,总算将这份Stable Diffusion的使用教程整理妥当。 从最初的安装与配置,细至界面功能的详解,再至实战案例的制作…...

线性可分支持向量机的原理推导【补充知识部分】拉格朗日函数 公式解析
本文是将文章《线性可分支持向量机的原理推导》中的公式单独拿出来做一个详细的解析,便于初学者更好的理解。在主文章中,有一个部分是关于补充拉格朗日对偶性的相关知识,此公式即为这部分内容。 公式 9-9 是关于拉格朗日函数 L ( x , α , β…...
csdn(最新交流群)
SEOI Chathttps://seoi.net/room/10122?kwe7cp45v此网站开放性较强,小心诈骗...

新手maven入门学习教程
MAVEN基础入门 提示:java新人的学习之路记录 学习内容: 提示:了解并会初步使用maven构建管理java项目 Maven 是一个非常流行的 Java 项目管理和构建工具。它通过提供一套标准的构建生命周期和一组预定义的目标来简化 Java 应用程序的构建过…...

React 中级阶段学习计划
React 中级阶段学习计划 目标 掌握状态管理和路由。能够调用API并处理异步数据。学会使用CSS-in-JS和CSS Modules进行样式处理。 学习内容 状态管理 React Context API Context API:用于在组件树中传递数据,避免多层props传递。示例:im…...
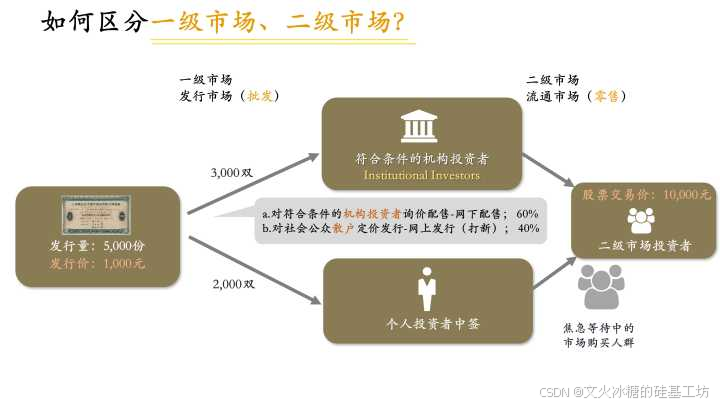
[产品管理-47]:产品市场调研 - 一级市场、二级市场、次级市场?
目录 一、产品销售环节的一级二级市场 1、一级市场 2、二级市场 3、一级市场与二级市场的互动关系 二、金融中的一级二级市场 1、一级市场(Primary Market)- 新股发行、定向发行 2、二级市场(Secondary Market)- 普通投资者…...

Linux零基础教程学习(黑马)
1.初识Linux 1.2远程连接Linux系统 图形化、命令行 对于操作系统的使用,有2种使用形式: 图形化页面使用操作系统 以命令的形式使用操作系统 不论是Windows还是Linux亦或是MacOS系统,都是支持这两种使用形式。 图形化:使用操作…...

一款零依赖、跨平台的流媒体协议处理工具,支持 RTSP、WebRTC、RTMP 等视频流协议的处理
大家好,今天给大家分享一款功能强大的流媒体协议处理工具go2rtc,支持多种协议和操作系统,具有零依赖、零配置、低延迟等特点。 项目介绍 go2rtc可以从各种来源获取流,包括 RTSP、WebRTC、HomeKit、FFmpeg、RTMP 等,并…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境
告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境 当现代Linux系统已全面拥抱Python3的时代,突然需要维护一个仅支持Python2.7的遗留项目,这种场景对开发者而言无异于一场噩梦。本文将带你用工程化的思维,在Deb…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...