【Python爬虫实战】从文件到数据库:全面掌握Python爬虫数据存储技巧
🌈个人主页:https://blog.csdn.net/2401_86688088?type=blog
🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html

目录
前言
一、文本文件数据存储的基础
二、如何将爬取的数据存储为.txt文件
三、如何将数据存储为.csv文件
四、如何将数据存储为.json文件
五、如何选择合适的存储格式
六、MySQL存储
(一)环境准备
(二)连接MySQL数据库
(三)创建数据库和表
(四)插入数据到MySQL
(五)查询数据
(六)更新和删除数据
(七)断开连接
(八)MySQL存储总结
七、MongoDB存储
(一)安装MongoDB和Python库
(二)连接MongoDB数据库
(三)创建集合
(四)插入数据
(五)查询数据
(六)更新数据
(七)删除数据
(八)断开连接
(九)MongoDB存储总结
八、总结
前言
在数据驱动的时代,爬虫技术已经成为获取和收集网络数据的重要工具。然而,仅仅获取数据还不够,如何高效、合理地存储这些数据,才能让其真正发挥价值。Python提供了多种数据存储方式,包括简单的文本文件(如.txt、.csv、.json),以及高级数据库(如MySQL和MongoDB)。本篇文章将深入剖析如何将爬取的数据灵活存储于不同格式和数据库中,帮助你选择最适合自己项目的存储方式。
本文将通过详细的代码示例,逐步讲解如何将数据存储在不同格式的文件中,以及如何将数据存入MySQL和MongoDB数据库中,以满足不同类型爬虫项目的需求。无论你是初学者还是开发者,相信你都会从本文中找到适合你的解决方案。
一、文本文件数据存储的基础
Python中常见的文本文件格式包括:
-
.txt:纯文本文件,适合存储不需要特定格式的内容。 -
.csv:逗号分隔文件,适合存储表格化数据。 -
.json:JavaScript Object Notation格式,适合存储结构化数据(如字典、列表)。
二、如何将爬取的数据存储为.txt文件
示例:
# 保存为 .txt 文件
data = "这是从网站爬取的内容"# 写入文本文件
with open("data.txt", "w", encoding="utf-8") as f:f.write(data)
print("数据已保存到 data.txt")
注意事项:
-
编码问题:爬取的中文或其他特殊字符内容需要指定
encoding="utf-8",避免乱码。 -
覆盖写入:使用
"w"模式会覆盖原有内容,如需追加内容,可以用"a"模式。
三、如何将数据存储为.csv文件
示例:
import csv# 模拟爬取的表格数据
data = [["标题", "链接", "日期"],["Python教程", "https://example.com", "2024-10-19"],["爬虫入门", "https://example2.com", "2024-10-18"]
]# 写入CSV文件
with open("data.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerows(data)
print("数据已保存到 data.csv")
注意事项:
-
表格数据格式:
csv文件需要结构化数据,如列表或元组。 -
newline="":防止在Windows下写入多余的空行。
四、如何将数据存储为.json文件
示例:
import json# 模拟爬取的数据
data = {"标题": "Python爬虫教程","链接": "https://example.com","日期": "2024-10-19"
}# 写入JSON文件
with open("data.json", "w", encoding="utf-8") as f:json.dump(data, f, ensure_ascii=False, indent=4)
print("数据已保存到 data.json")
注意事项:
-
ensure_ascii=False:避免中文字符在保存时被转义成Unicode编码。 -
indent=4:使生成的JSON文件格式化,易于阅读。
五、如何选择合适的存储格式
-
.txt文件:适合存储非结构化的文本数据,如文章内容、日志等。 -
.csv文件:适合存储二维表格数据,如新闻标题和日期等。 -
.json文件:适合存储层次化结构数据,如字典列表。
六、MySQL存储
使用MySQL来存储爬取的数据是非常常见且有效的做法,尤其适合管理和查询大量结构化数据。下面,我会详细介绍如何将爬取的数据存入MySQL数据库,包括准备环境、数据库连接、创建表、插入数据等关键步骤。
(一)环境准备
1.安装MySQL
-
Windows / Mac:可以从MySQL官网下载并安装。
-
Linux:使用
apt或yum安装,例如:
sudo apt update
sudo apt install mysql-server
2.安装Python的MySQL库
推荐使用mysql-connector-python或pymysql库。安装命令:
pip install mysql-connector-python
或
pip install pymysql
(二)连接MySQL数据库
示例:
import mysql.connector# 连接到MySQL数据库
db = mysql.connector.connect(host="localhost", # 数据库地址user="your_username", # 用户名password="your_password", # 密码database="your_database" # 数据库名称
)print("连接成功")
cursor = db.cursor()
注意事项:
-
MySQL服务需要启动。可以通过
sudo service mysql start(Linux)或手动启动(Windows)。 -
检查用户权限,确保该用户有权限操作对应的数据库。
(三)创建数据库和表
创建数据库:
cursor.execute("CREATE DATABASE IF NOT EXISTS your_database")
print("数据库创建成功")
创建表结构:
# 创建一个用于存储爬取数据的表
cursor.execute("""CREATE TABLE IF NOT EXISTS web_data (id INT AUTO_INCREMENT PRIMARY KEY,title VARCHAR(255),url VARCHAR(255),date DATE)
""")
print("表创建成功")
(四)插入数据到MySQL
示例:
# 模拟爬取的数据
data = [("Python教程", "https://example.com", "2024-10-19"),("爬虫入门", "https://example2.com", "2024-10-18")
]# 插入数据的SQL语句
insert_query = "INSERT INTO web_data (title, url, date) VALUES (%s, %s, %s)"# 执行批量插入
cursor.executemany(insert_query, data)
db.commit() # 提交事务
print(f"成功插入{cursor.rowcount}条数据")
注意事项:
-
事务提交:通过
db.commit()确保数据插入成功。 -
批量插入:使用
executemany()可以高效插入多条数据。
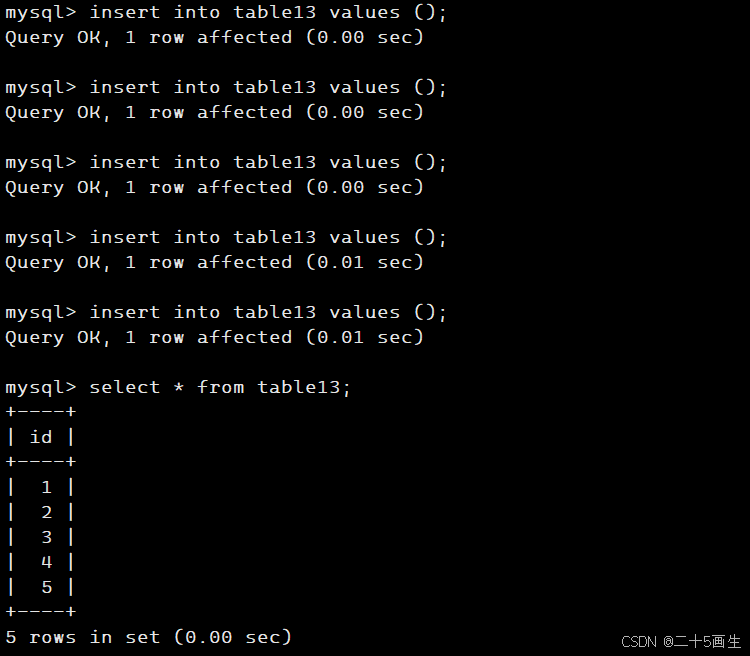
(五)查询数据
示例:
# 查询所有数据
cursor.execute("SELECT * FROM web_data")
results = cursor.fetchall()# 输出查询结果
for row in results:print(row)
结果:
(1, 'Python教程', 'https://example.com', datetime.date(2024, 10, 19))
(2, '爬虫入门', 'https://example2.com', datetime.date(2024, 10, 18))
(六)更新和删除数据
更新数据:
update_query = "UPDATE web_data SET title = %s WHERE id = %s"
cursor.execute(update_query, ("Python进阶教程", 1))
db.commit()
print("数据更新成功")
删除数据:
delete_query = "DELETE FROM web_data WHERE id = %s"
cursor.execute(delete_query, (2,))
db.commit()
print("数据删除成功")
(七)断开连接
示例:
# 关闭游标和数据库连接
cursor.close()
db.close()
print("数据库连接已关闭")
(八)MySQL存储总结
将爬取的数据存储在MySQL中具有以下优点:
-
高效查询:通过SQL语句可以快速查找和过滤数据。
-
数据管理:支持更新、删除数据,更适合大规模爬取项目。
-
结构化存储:非常适合存储结构化的数据,如文章标题和链接。
七、MongoDB存储
使用 MongoDB 存储爬取数据是非常合适的选择,尤其是当数据结构复杂或需要灵活存储时。MongoDB是一个 NoSQL 数据库,适合存储 JSON 格式的文档数据。接下来,我会详细介绍如何将爬取的数据存储在 MongoDB 中,包括安装、连接、存储、查询等操作。
(一)安装MongoDB和Python库
1.安装MongoDB
-
Windows / Mac:从 MongoDB官网 下载并安装。
-
Linux:使用以下命令安装:
sudo apt update
sudo apt install -y mongodb
sudo systemctl start mongodb # 启动MongoDB服务
2.安装Python库pymongo
MongoDB的Python客户端为pymongo。你可以通过以下命令安装:
pip install pymongo
(二)连接MongoDB数据库
示例:
from pymongo import MongoClient# 连接到MongoDB服务
client = MongoClient("mongodb://localhost:27017/")# 选择数据库(如果不存在会自动创建)
db = client["web_scraping"]print("连接成功")
(三)创建集合
在MongoDB中,数据存储在集合中,类似于关系型数据库中的表。集合会在插入数据时自动创建。
# 创建或选择集合(类似于SQL中的表)
collection = db["web_data"]
(四)插入数据
MongoDB的文档格式与JSON相同,非常适合存储嵌套数据结构。
1.插入单条数据
data = {"title": "Python爬虫教程","url": "https://example.com","date": "2024-10-19"
}# 插入数据
collection.insert_one(data)
print("单条数据插入成功")
2.插入多条数据
data_list = [{"title": "Python入门", "url": "https://example1.com", "date": "2024-10-18"},{"title": "高级爬虫", "url": "https://example2.com", "date": "2024-10-17"}
]# 批量插入数据
collection.insert_many(data_list)
print("多条数据插入成功")
(五)查询数据
1.查询所有数据
# 查询集合中的所有数据
results = collection.find()# 输出查询结果
for result in results:print(result)
结果:
{'_id': ObjectId('...'), 'title': 'Python入门', 'url': 'https://example1.com', 'date': '2024-10-18'}
{'_id': ObjectId('...'), 'title': '高级爬虫', 'url': 'https://example2.com', 'date': '2024-10-17'}
2.条件查询
# 查询特定条件的数据
result = collection.find_one({"title": "Python入门"})
print(result)
(六)更新数据
示例:
# 更新特定文档的数据
collection.update_one({"title": "Python入门"}, # 查询条件{"$set": {"title": "Python入门教程"}} # 更新内容
)
print("数据更新成功")
(七)删除数据
示例:
# 删除单条数据
collection.delete_one({"title": "高级爬虫"})
print("单条数据删除成功")# 删除多条数据
collection.delete_many({"date": {"$lt": "2024-10-18"}})
print("多条数据删除成功")
(八)断开连接
# 关闭数据库连接
client.close()
print("数据库连接已关闭")
(九)MongoDB存储总结
使用MongoDB存储爬取数据的优点:
-
灵活的数据结构:无需预定义表结构,适合存储复杂的嵌套数据。
-
高效的读写性能:支持大规模数据的高效存储和查询。
-
JSON格式支持:爬取的数据通常以JSON格式存储,直接适配MongoDB。
八、总结
数据存储的方式和格式对于爬虫项目的效率和效果至关重要。本篇文章系统地介绍了Python爬虫数据的存储方式,涵盖了从基础的TXT、CSV和JSON格式到高级的MySQL和MongoDB数据库。
-
简单数据存储:
使用TXT文件存储纯文本内容,适合日志或简单记录。CSV文件非常适合存储表格数据,方便后续数据分析和展示。而JSON格式更适合存储复杂、嵌套的结构化数据。 -
高级数据存储:
对于需要频繁查询和更新的数据,MySQL提供了稳定的关系型存储支持。而MongoDB由于其灵活的JSON格式支持,非常适合处理非结构化数据,尤其是在数据结构不固定的情况下。
通过这些不同存储方式的掌握,你可以根据项目需求选择合适的存储方案,为数据处理和分析奠定坚实基础。希望这篇文章能够帮助你在数据存储方面更上一层楼,为你的爬虫项目注入新活力。
相关文章:
【Python爬虫实战】从文件到数据库:全面掌握Python爬虫数据存储技巧
🌈个人主页:https://blog.csdn.net/2401_86688088?typeblog 🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html 目录 前言 一、文本文件数据存储的基础 二、如何将爬取的数据存储为.txt文件 三、如何…...
断其一指,无惧!ProFusion3D: 相机或者激光失效仍高效的多传感器融合3D目标检测算法
Abstract 多传感器融合在自动驾驶中的3D目标检测中至关重要,摄像头和激光雷达是最常用的传感器。然而,现有方法通常通过将两种模态的特征投影到鸟瞰视角(BEV)或透视视角(PV)来进行单视角的传感器融合&…...

CCS字体、字号更改+CCS下载官方链接
Step1、 按照图示箭头操作 step2 Step3 点击确定,点击Apply(应用),点击Apply and close(应用和关闭) 4、历代版本下载链接 CCS下载:官方链接https://www.ti.com/tool/CCSTUDIO The last but not least 如果成功的解决了你的问题&#x…...

YOLO11改进|注意力机制篇|引入SEAM注意力机制
目录 一、【SEAM】注意力机制1.1【SEAM】注意力介绍1.2【SEAM】核心代码二、添加【SEAM】注意力机制2.1STEP12.2STEP22.3STEP32.4STEP4三、yaml文件与运行3.1yaml文件3.2运行成功截图一、【SEAM】注意力机制 1.1【SEAM】注意力介绍 下图是【SEAM】的结构图,让我们简单分析一下…...

简历修订与求职经历 - Chap04
节后第一周有点山中无甲子的状况。Oct08,节后第一天几乎全天处于心流状态。上午下午很快时间就结束了。 周五,按照既有的面试频次,感觉可以做点别的。然后就联系了附近的驾校,打算把摩托车驾驶证拿了。然后几乎到了驾校ÿ…...

鸿蒙开发案例:推箱子
推箱子游戏(Sokoban)的实现。游戏由多个单元格组成,每个单元格可以是透明的、墙或可移动的区域。游戏使用Cell类定义单元格的状态,如类型(透明、墙、可移动区域)、圆角大小及坐标偏移。而MyPosition类则用于…...
mysql--表的约束
目录 理解表的约束和操作 如何理解? 1、空属性null 2、默认值default 3、列描述comment 4、自动填充zorefill 5、主键primary key (1)创建表时指定可以 (2)创建表后指定key (3)删除主…...

Ubuntu 上安装 docker 并配置 Docker Compose 详细步骤
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...
)
MySQL去除空白字符(如非标准空格、制表符等)
在 MySQL 中,需要去除 site_name 字段的空格,可以使用 TRIM() 函数。这个函数可以去掉字符串开头和结尾的空格。以下是一个示例查询,演示如何选择去除空格后的 site_name: SELECT TRIM(site_name) AS site_name FROM site_info;如…...

2063:【例1.4】牛吃牧草
【题目描述】 有一个牧场,牧场上的牧草每天都在匀速生长,这片牧场可供15头牛吃20天,或可供20头牛吃10天,那么,这片牧场每天新生的草量可供几头牛吃1天? 【输入】 (无) 【输出】 如题…...
QT开发:深入掌握 QtGui 和 QtWidgets 布局管理:QVBoxLayout、QHBoxLayout 和 QGridLayout 的高级应用
目录 引言 1. QVBoxLayout:垂直布局管理器 基本功能 创建 QVBoxLayout 添加控件 添加控件和设置对齐方式 设置对齐方式 示例代码与详解 2. QHBoxLayout:水平布局管理器 基本功能 创建 QHBoxLayout 添加控件 添加控件和设置对齐方式 设置对齐…...

Bootstrapping、Bagging 和 Boosting
bagging方法如下: bagging和boosting比较...

板块龙头公司
高通 高通(Qualcomm)是一家总部位于美国加利福尼亚州的全球领先半导体和电信设备公司。成立于1985年,高通专注于无线通信技术的研发和创新。 移动处理器: 高通开发的骁龙(Snapdragon)系列芯片广泛用于智能手机和平板电…...
Java项目-基于Springboot的招生管理系统项目(源码+说明).zip
作者:计算机学长阿伟 开发技术:SpringBoot、SSM、Vue、MySQL、ElementUI等,“文末源码”。 开发运行环境 开发语言:Java数据库:MySQL技术:SpringBoot、Vue、Mybaits Plus、ELementUI工具:IDEA/…...
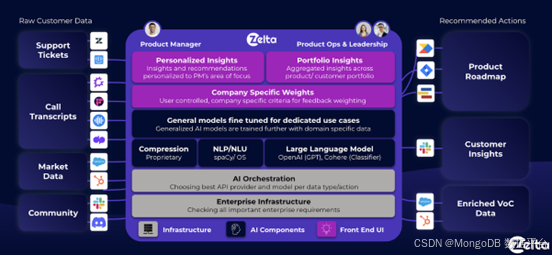
使用 MongoDB 构建 AI:利用实时客户数据优化产品生命周期
在《使用 MongoDB 构建 AI》系列博文中,我们看到越来越多的企业正在利用 AI 技术优化产品研发和用户支持流程。例如,我们介绍了以下案例: Ventecon 的 AI 助手帮助产品经理生成和优化新产品规范 Cognigy 的对话式 AI 帮助企业使用任意语言&a…...
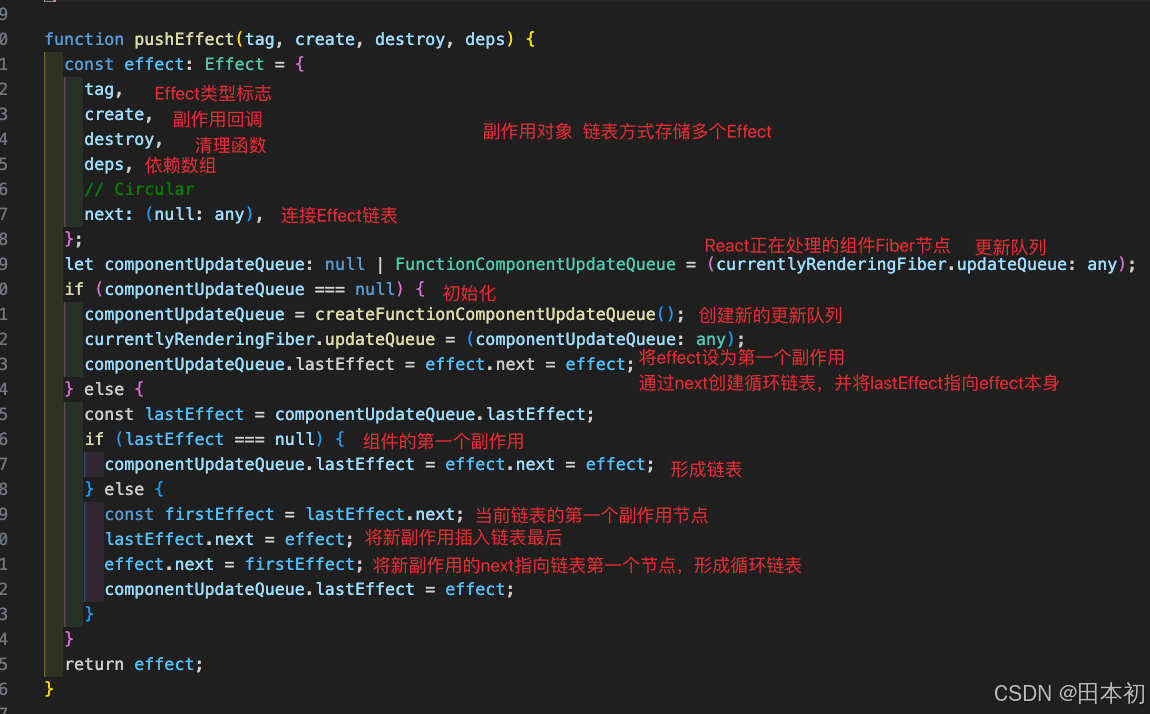
【React】React18核心源码解读
前言 本文使用 React18.2.0 的源码,如果想回退到某一版本执行git checkout tags/v18.2.0即可。如果打开源码发现js文件报ts类型错误请看本人另一篇文章:VsCode查看React源码全是类型报错如何解决。 阅读源码的过程: 下载源码 观察 package…...
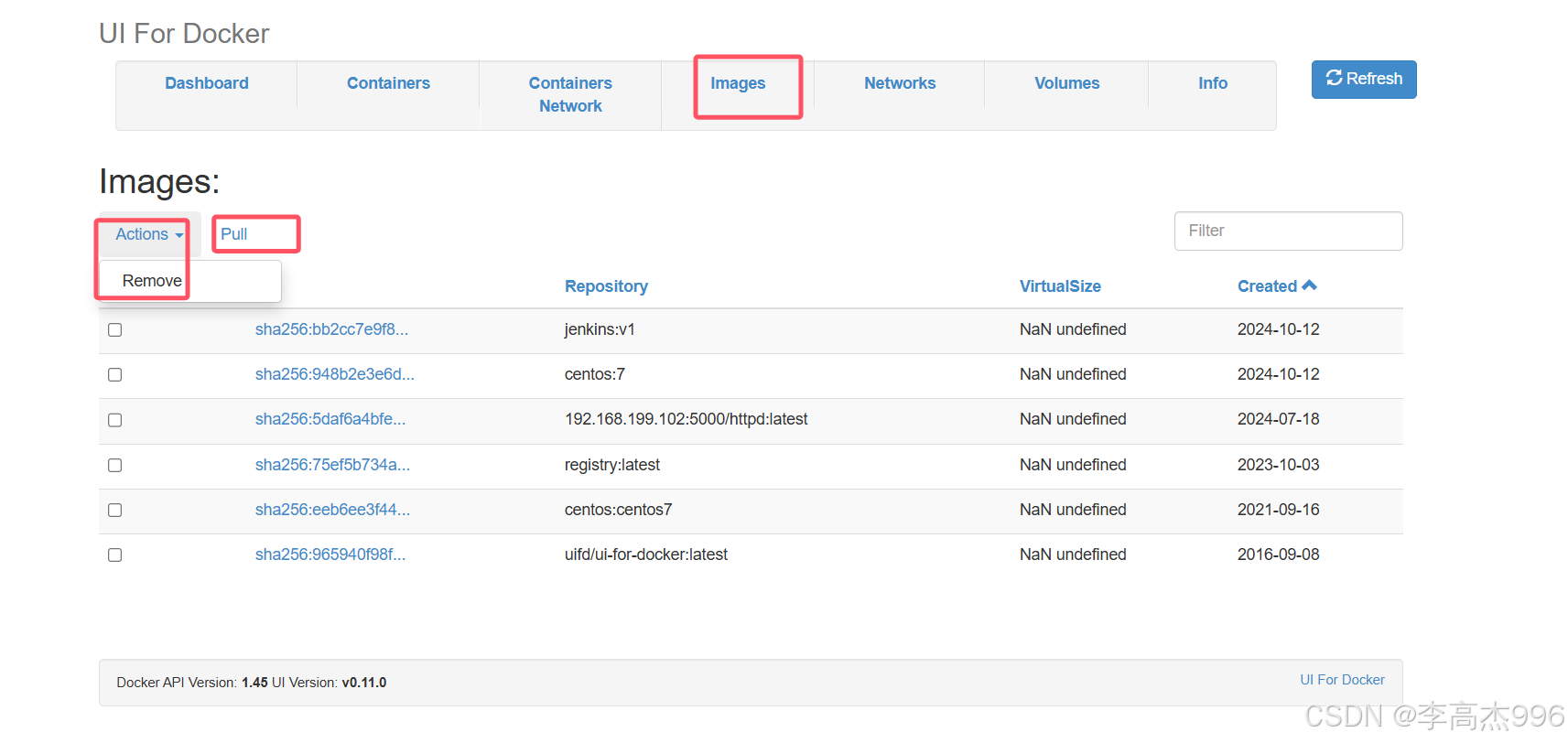
部署私有仓库以及docker web ui应用
官方地址:https://hub.docker.com/_/registry/tags 一、拉取registry私有仓库镜像 docker pull registry:latest 二、运⾏容器 docker run -itd -v /home/dockerdata/registry:/var/lib/registry --name "pri_registry1" --restartalways -p 5000:5000 …...
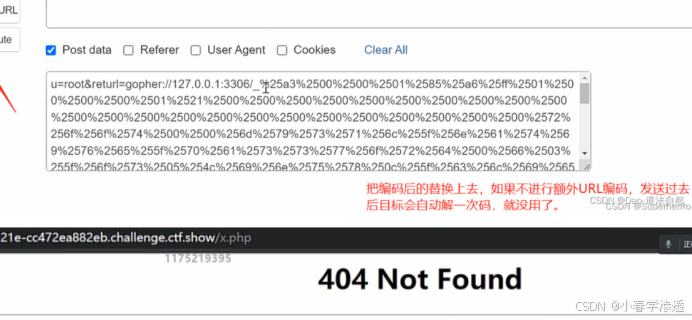
DAY57WEB 攻防-SSRF 服务端请求Gopher 伪协议无回显利用黑白盒挖掘业务功能点
知识点: 1、SSRF-原理-外部资源加载 2、SSRF-利用-伪协议&无回显 3、SSRF-挖掘-业务功能&URL参数 SSRF-原理&挖掘&利用&修复 漏洞原理:SSRF(Server-Side Request Forgery:服务器端请求伪造) ,一种由攻击者构造形成由服务…...

光盘刻录大文件时分卷操作
可以使用 split 命令来将大文件 finetune.tar 分卷为适合光盘大小的文件片段,然后在离线服务器上合并这些分卷文件。以下是具体的操作步骤: 步骤1:分卷文件 假设你的文件 finetune.tar 大小为35GB,并且你想分卷为每个4.7GB&…...

Kafka系列之:生产者性能调优
Kafka系列之:生产者性能调优 一、producer.type二、request.required.acks三、max.request.size四、batch.size五、buffer.memory一、producer.type 在Kafka中,producer.type是一个配置属性,用于指定Producer的类型。它有两个可能的值: sync:同步发送模式。当设置为sync时…...

Polr扩展指南:如何通过自定义开发打造强大的短链接生态系统
Polr扩展指南:如何通过自定义开发打造强大的短链接生态系统 【免费下载链接】polr :aerial_tramway: A modern, powerful, and robust URL shortener 项目地址: https://gitcode.com/gh_mirrors/po/polr Polr是一个现代化、功能强大且健壮的URL短链接服务&am…...

墨语灵犀完整指南:支持的语言列表+字符编码兼容性+特殊符号处理
墨语灵犀完整指南:支持的语言列表字符编码兼容性特殊符号处理 1. 产品概述 墨语灵犀(Moyu Lingxi)是一款基于腾讯混元大模型底座开发的深度翻译工具。与普通翻译软件不同,它将前沿的AI翻译技术融入"冷金笺"与"砚…...
:文件提取工具丛)
我用 AI 辅助开发了一系列小工具():文件提取工具丛
从0构建WAV文件:读懂计算机文件的本质 虽然接触计算机有一段时间了,但是我的视野一直局限于一个较小的范围之内,往往只能看到于算法竞赛相关的内容,计算机各种文件在我看来十分复杂,认为构建他们并能达到目的是一件困难…...

从零配置Livox Mid-360到Faster-LIO:一份给ROS Noetic新手的保姆级环境搭建清单
从零配置Livox Mid-360到Faster-LIO:一份给ROS Noetic新手的保姆级环境搭建清单 第一次接触Livox Mid-360激光雷达和SLAM算法时,我完全被各种依赖项和编译错误搞懵了。ROS Noetic环境下的配置过程就像走迷宫,稍有不慎就会陷入版本冲突、路径…...

2026届必备的五大AI辅助论文神器推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 依托自然语言处理跟知识图谱技术,AI开题报告工具能够针对研究领域文献开展自动解…...

Nordic主题高级配置:性能优化与多平台兼容性解决方案
Nordic主题高级配置:性能优化与多平台兼容性解决方案 【免费下载链接】Nordic :snowflake: Dark Gtk3.20 theme created using the awesome Nord color pallete. 项目地址: https://gitcode.com/gh_mirrors/no/Nordic Nordic是一款基于Nord北极蓝色彩方案的专…...

收藏!小白程序员轻松入门大模型,掌握AI领导力升职加薪必备
AI正颠覆全行业,要求原地升级AI。程序员需从执行者转变成AI领导者,提升AI领导力。未来行业可能两头重(小白AI和架构师AI),初中级工程师需提升专业能力和AI领导力。文章推荐NLP、CV、大模型算法、大模型部署等方向&…...

Limine协议参考实现:标准引导接口的设计理念与实现细节
Limine协议参考实现:标准引导接口的设计理念与实现细节 【免费下载链接】limine Modern, advanced, portable, multiprotocol bootloader and boot manager. 项目地址: https://gitcode.com/gh_mirrors/li/limine Limine是一款现代化、先进的可移植多协议引导…...

洞察AI黑盒:SHAP、LIME与Captum如何赋能软件测试
随着人工智能技术在软件产品中的深度集成,从推荐系统到自动化缺陷预测,机器学习模型正成为现代软件的核心组件。然而,这些模型,尤其是复杂的深度神经网络,其决策过程往往如同一个“黑盒”,这给软件测试工作…...
)
SVN快速入门指南:从零到团队协作(极简版)
1. SVN是什么?为什么团队开发离不开它 第一次接触SVN是在2013年参与一个跨部门协作项目时。当时团队里有5个开发人员,每个人负责不同的模块,但最终需要整合成一个完整系统。项目经理要求我们使用SVN进行代码管理,那是我第一次体会…...