【Hive】2-Apache Hive概述、架构、组件、数据模型
Apache Hive概述
什么是Hive
- Apache Hive是一款建立在Hladoop之上的开源
数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。 - Hive核心是将
HQL转换为MapReduce程序,然后将程序提交到Hadoop集群执行。 - Hive由Facebook实现并开源。
为什么使用Hive
- 使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高需要掌握java语言
- MapReduce实现复杂查询逻辑开发难度太大
- 使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写MapReduce,减少开发人员的学习成本
- 支持自定义函数,功能扩展很方便
- 背靠Hadoop,擅长存储分析海量数据集
Hive和Hadoop关系
- 从功能来说,数据仓库软件,至少需要具备下述两种能力︰存储数据的能力、分析数据的能力
- Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。 - 这样突然发现Hive没啥用,不过是套壳Hladoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。

Hive的功能模拟
-
Hive能将数据文件映射成为一张表,这个
映射是指什么?答:文件和表之间的对应关系
-
Hive软件本身到底承担了什么
功能职责?答:SQL语法解析编译成为MapReduce

Apache Hive架构、组件
架构图

组件
用户接口:包括CLI、JDBC/OOBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。元数据存储:通常是存储在关系数据库如mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器:完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS 中,并在随后有执行引擎调用执行。执行引擎:Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark三种执行引擎。
Apache Hive数据模型
Data Model概念
- 数据模型∶用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。
- Hive的数据模型类似于
RDBMS库表结构,此外还有自己特有模型。 - Hive中的数据可以在粒度级别上分为三类∶
- Table 表
- Partition 分区
- Bucket 分桶

DataBases 数据库
- Hive作为一个数据仓库,在结构上积极向传统数据库看齐,也分数据库(Schema ),每个数据库下面有各自的表组成。
默认数据库default。 - Hive的数据都是
存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。 - 因此,Hive中的数据库在HDFS上的存储路径为︰${hive.metastore.warehouse.dir}/databasename.db
- 比如,名为itcast的数据库存储路径为:/user/hive/warehouse/itcast.db
Tables 表
- Hive表与关系数据库中的表相同。Hive中的表所对应的数据通常是存储在HDFPS中,而表相关的元数据是存储在RDBMS中。
- Hive中的表的数据在HDFS上的存储路径为:${hive.metastore.warehouse.dir}/databasename. db/tablename
- 比如, itcast的数据库下t_user表存储路径为:/user/hive/warehouse/itcast.db/t_user

Partitions 分区
- Partition分区是hive的一种优化手段表。分区是指根据分区列(例如“日期day”)的值将表划分为不同分区。这样可以更快地对指定分区数据进行查询。
- 分区在存储层面上的表现是:table表目录下以子文件夹形式存在。
- 一个文件夹表示一个分区。子文件命名标准:分区列=分区值
- Hive还支持分区下继续创建分区,所谓的多重分区。

Buckets 分桶
- Bucket分桶表是hive的一种优化手段表。分桶是指根据表中字段(例如“编号ID”)的值,经过hash计算规则将数据文件划分成指定的若干个小文件。
- 分桶规则:hashfunc(字段)%桶仓数,余数相同的分到同一个文件。

- 分桶的好处是可以优化join查询和方便抽样查询。
- Bucket分桶表在HDFS中表现为同一个表目录下数据根据hash散列之后变成多个文件。

Hive和MySQL对比
- Hive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都十分相似,但应用场景却完全不同。
Hive只适合用来做海量数据的离线分析。Hive的定位是数据仓库,面向分析的OLAP系统。- 因此时刻告诉自己,
Hive不是大型数据库,也不是要取代MySQL承担业务数据处理。
| Apache Hive | MySQL | |
|---|---|---|
| 定位 | 数据仓库 | 数据库 |
| 使用场景 | 离线数据分析 | 业务数据事务处理 |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Local FS |
| 执行引擎 | MR、Tez、Spark | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 常见操作 | 导入数据、查询 | 增删改查 |
Metadata、Metastore介绍
什么是元数据
- 元数据(Metadata),又称中介数据、中继数据,为
描述数据的数据( data about data ),主要是描述数据属性( property )的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata
- Hive Metadata即Hive的元数据。
- 包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
Hive Metastore
- Metastore即
元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。 - 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。

Metastore配置方式
- metastore服务配置有3种模式:
内嵌模式、本地模式、远程模式。 - 区分3种配置方式的关键是弄清楚两个问题:
- Metastore服务是否需要单独配置、单独启动?
- Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
- 本系列中使用
企业推荐模式--远程模式部署。
| 内嵌模式 | 本地模式 | 远程模式 | |
|---|---|---|---|
| Metastore是否单独配置、启动 | 否 | 否 | 是 |
| Metadata存储介质 | Derby | MySQL | MySQL |
内嵌模式
内嵌模式(Embedded Metastore)是metastore默认部署模式。- 此种模式下,元数据存储在
内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动。不需要额外起Metastore服务。 - 但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。

本地模式
本地模式( Local Metastore )下,Metastore服务与主liveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信。- 本地模式采用
外部数据库来存储元数据,推荐使用MySQL。 - hive根据hive.metastore.uris参数值来判断,如果为空,则为本地模式。
- 缺点是∶每启动一次hive服务,都内置启动了一个metastore。

远程模式
远程模式(Remote Metastore ) 下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。- 远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且
需要单独手动启动metastore服务。元数据也采用外部数据库来存储元数据,推荐使用MySQL。 - 在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。

Apache Hive安装部署
安装前准备
- 由于Apache Hive是一款基于HIadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
服务器基础环境:集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装Hadoop集群健康可用:启动Hive之前必须先启动Hadoop集群。特别要注意,需等待HDFS安全模式关闭之后再启动运行Hlive。Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
Hadoop与Hive整合
- 因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据
- 因此需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行。
- 修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效。

具体安装步骤请参考B站P19-22:https://www.bilibili.com/video/BV1L5411u7ae/
Hive命令行客户端
- Hive发展至今,总共历经了两代客户端工具。
- 第一代客户端(deprecated不推荐使用):$HIVE_HOME
/bin/hive,是一个shellUltil。主要功能:一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。 - 第二代客户端(recommended推荐使用):$HIVE_HOME
/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第—代客户端相比,性能加强安全性提高。

Hive Beeline Client
- Beeline在嵌入式模式和远程模式下均可工作。
- 在嵌入式模式下,它运行嵌入式Hive(类似于Hive Client);而远程模式下beeline通过Thrift连接到单独的HiveServer2服务上,这也是官方推荐在生产环境中使用的模式。
- 那么问题来了,HiveServer2是什么? HiveServer1哪里去了?
HiveServer、HiveServer2服务
- HiveServer、HiveServer2都是Hive自带的两种服务,允许客户端在不启动CLI(命令行)的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言如java, python等向hive提交请求,取回结果。
- 但是,HiveServer不能处理多于一个客户端的并发请求。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer已经被废弃。
HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。
Hive服务和客户端
- HiveServer2通过Metastore服务读写元数据。所以在远程模式下,
启动HiveServer2之前必须先首先启动metastore服务。 - 特别注意:远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive。而bin/hive是通过Metastore服务访问的。具体关系如下:

bin/hive 客户端
- 在hive安装包的bin目录下,有hive提供的第一代客户端 bin/hive。该客户端可以访问hive的metastore服务,从而达到操作hive的目的。
- 友情提示∶如果你是
远程模式部署,请手动启动运行metastore服务。如果是内嵌模式和本地模式,直接运行bin/hive , metastore服务会内嵌一起启动。 - 可以直接在启动Hive metastore服务的机器上使用bin/hive客户端操作,此时不需要进行任何配置。

bin/beeline 客户端
- hive经过发展,推出了第二代客户端beeline,但是beeline客户端不是直接访问metastore服务的,而是需要单独启动hiveserver2服务。
- 在hive安装的服务器上,
首先启动metastore服务,然后启动hiveserver2服务。

- 在node3上使用beeline客户端进行连接访问。需要注意
hiveserver2服务启动之后需要稍等一会才可以对外提供服务。 - Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://node1:10000

属性配置的3种方式
概述
-
Hive除了默认的属性配置之外,还支持用户使用时修改配置;
-
修改Hive配置之前,作为用户需要掌握两件事:
- 1.有哪些属性支持用户修改,属性的功能、作用是什么;
- 2.支持哪种方式进行修改,是临时生效还是永久生效的。
-
Hive配置属性是在HiveConf. Java类中管理的,可以参考文件以获取当前使用版中可用的配置属性列表;
-
从Hive 0.14.0开始,会从HiveConf.java类中直接生成配置模板文件
hive-default.xml.template; -
详细的配置参数大全可以参考Hive官网配置参数:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties

配置方式一:hive-site.xml
在$HIVE_HOME/conf路径下,可以添加一个hive-site.xml文件,把需要定义修改的配置属性添加进去,这个配置文件会影响到基于这个Hive安装包的任何一种服务启动、客户端使用方式。
比如使用MIySQL作为元数据的存储介质,把连接MySQL的相关属性配置在hive-site.xml文件中,这样不管是本地模式还是远程模式启动,不管客户端本地连接还是远程连接,都将访问同一个元数据存储介质。

配置方式二:–hiveconf命令行参数
hiveconf是一个命令行的参数,用于在使用Hive CLI或者Beeline CLI的时候指定配置参数。
这种方式的配置在整个的会话session中有效,会话结束,失效。
比如在启动hive服务的时候,为了更好的查看启动详情,可以通过hiveconf参数修改日志级别:

配置方式三:set命令
在Hive CLI或Beeline中使用set命令为set命令之后的所有SQL语句设置配置参数,这个也是会话级别的。这种方式也是用户日常开发中使用最多的一种配置参数方式。
因为Hive倡导一种:谁需要、谁配置、谁使用的一种思想,避免你的属性修改影响其他用户的修改。

配置方式四:服务特定配置文件
hivemetastore-site.xml、hiveserver2-site.xml
- Hive Metastore会加载可用的hive-site.xml以及hivemetastore-site.xml配置文件。
- HiveServer2会加载可用的hive-site.xml以及hiveserver2-site.xml。
- 如果HiveServer2以嵌入式模式使用元存储,则还将加载hivemetastore-site.xml。
总结
- 配置方式优先级:
set设置> hiveconf参数> hive-site.xml配置文件 - set参数声明会覆盖命令行参数hiveconf,命令行参数会覆盖配置文件hive-site.xml设定
- 日常开发使用中,
如果不是核心的需要全局修改的参数属性,建议使用set命令进行设置 - 另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置
相关文章:
【Hive】2-Apache Hive概述、架构、组件、数据模型
Apache Hive概述 什么是Hive Apache Hive是一款建立在Hladoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访…...

关于目前面试八股文的一些心得体会
现在是2024年10月,自22年开始,明显感觉到整个计算机行业,越来越卷了。一方面,随着信息的传播,越来越多的新人涌入了这个赛道,另一方面,众所周知的原因,不管大厂还是小厂在经历寒冬之…...

大数据-178 Elasticsearch Query - Java API 索引操作 文档操作
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

PHP(一)从入门到放弃
参考文献:https://www.php.net/manual/zh/introduction.php PHP 是什么? PHP(“PHP: Hypertext Preprocessor”,超文本预处理器的字母缩写)是一种被广泛应用的开放源代码的多用途脚本语言,它可嵌入到 HTML…...

基于深度学习的生物启发的学习系统
基于深度学习的生物启发学习系统(Biologically Inspired Learning Systems)旨在借鉴生物大脑的结构和学习机制,设计出更高效、更灵活的人工智能系统。这类系统融合了生物神经科学的研究成果,通过模仿大脑中的学习模式、记忆过程和…...

10_实现readonly
在某些时候,我们希望定义一些数据是只读的,不允许被修改,从而实现对数据的保护,即为 readonly 只读本质上也是对数据对象的代理,我们同样可以基于之前实现的 createReactiveObject 函数来实现,可以为此函数…...

简单介绍$listeners
$listeners 它可以获取父组件传递过来的所有自定义函数,如下: // 父组件 <template><div class"a"><Child abab"handleAbab" acac"handleAcac"/></div> </template><script> impor…...

架构设计笔记-20-补充知识
知识产权 我国没有专门针对知识产权制定统一的法律(知识产权法),而是在民法通则规定的原则下,根据知识产权的不同类型制定了不同的单项法律及法规,如著作权法、商标法、专利法、计算机软件保护条例等,这些法律、法规共同构成了我…...

scrapy 爬虫学习之【中医药材】爬虫
本项目纯学习使用。 1 scrapy 代码 爬取逻辑非常简单,根据url来处理翻页,然后获取到详情页面的链接,再去爬取详情页面的内容即可,最终数据落地到excel中。 经测试,总计获取 11299条中医药材数据。 import pandas as…...

PDH稳频技术粗谈
PDH(Plesiochronous Digital Hierarchy)是一种传输技术,主要用于数字通信中的传输系统。PDH稳频技术是指在PDH传输系统中,通过稳定频率来实现传输系统的稳定性和可靠性。 PDH传输系统中,时钟同步是非常重要的。传输系…...
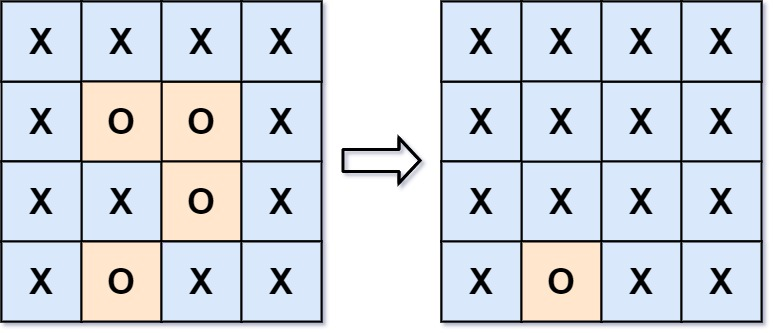
[LeetCode] 130. 被围绕的区域
题目描述: 给你一个 m x n 的矩阵 board ,由若干字符 X 和 O 组成,捕获 所有 被围绕的区域: 连接:一个单元格与水平或垂直方向上相邻的单元格连接。区域:连接所有 O 的单元格来形成一个区域。围绕&#x…...

C语言位运算
目录 1.C语言位运算符表 2.C语言移位运算符详解(配实例作业) 3.C语言&按位与运算符详解 4.C语言|按位或运算符详解 5.C语言^按位异或运算符详解 6.C语言~取反运算符详解 C语言位运算这一章主要介绍C语言位运算符表、C语言移位运算符、C语言&按…...

Go 语言中格式化动词
当然,我很乐意为你提供 Go 语言中所有的格式化动词的完整列表。Go 语言的格式化动词非常丰富,可以满足各种打印和格式化需求。以下是完整的列表: 通用: %v - 以默认格式打印值 %v - 类似 %v,但对结构体会添加字段名 %#…...

CSS3 动画相关属性实例大全(四)(font、height、left、letter-spacing、line-height 属性)
CSS3 动画相关属性实例大全(四) (font、height、left、letter-spacing、line-height 属性) 本文目录: 一、font 属性(所有字体属性) 1.1、font-size属性(指定字体的大小) 1.2、f…...

大模型涌现判定
什么是大模型? 大模型:是“规模足够大,训练足够充分,出现了涌现”的深度学习系统; 大模型技术的革命性:延申了人的器官的功能,带来了生产效率量级提升,展现了AGI的可行路径&#x…...

LeetCode 1456.定长子串中元音的最大数目
题目: 给你字符串 s 和整数 k 。 请返回字符串 s 中长度为 k 的单个子字符串中可能包含的最大元音字母数。 英文中的 元音字母 为(a, e, i, o, u)。 思路:定长滑动窗口 入 更新 出 代码: class Solution {pub…...

freeswitch-esl 三方设备实现监听功能
使用场景: A和B在通话中,C想监听A和B通话内容 方法一: 修改拨号计划<extension name="global" continue="true"><condition><action application="info"/>...

【LeetCode】123.买卖股票的最佳时间
清晰明了的思路是解决问题的至上法宝。如何把一个复杂的问题拆成简单的问题,就是我们需要考虑的。 1. 题目 2. 思想 这道题虽然是难题,但是思想比较简单。 题目要求说至多买卖两次,也就是说,也可以买卖一次,这种情况…...

elk部署安装
elk部署 前提准备1、elasticsearch2、kibana3、logstash 前提准备 1、提前装好docker docker-compose相关命令 2、替换docker仓库地址国内镜像源 cd /etc/docker vi daemon.json # 替换内容 {"registry-mirrors": [ "https://docker.1panel.dev", "ht…...

使用 JAX 进行 LLM 分布式监督微调
LLM distributed supervised fine-tuning with JAX — ROCm Blogs (amd.com) 24年1月25日,Douglas Jia 发布在AMD ROCm 博客上的文章。 在这篇文章中,我们回顾了使用 JAX 对基于双向编码器表示(BERT)的大型语言模型(LL…...

ROS2多线程调试避坑指南:用gdb同时监控3个关键线程的交互问题
ROS2多线程调试避坑指南:用gdb同时监控3个关键线程的交互问题 调试ROS2节点时,多线程问题往往是最棘手的挑战之一。上周在调试一个图像处理节点时,我遇到了三个线程相互竞争导致的数据不一致问题——主线程发布消息、回调线程处理数据、定时器…...

PyTorch Autograd实战避坑指南:从梯度消失到内存泄漏,新手常踩的5个坑
PyTorch Autograd实战避坑指南:从梯度消失到内存泄漏,新手常踩的5个坑 刚接触PyTorch时,我们往往会被其简洁的API和动态计算图的特性所吸引。然而在实际项目开发中,Autograd系统的一些"隐藏规则"常常让开发者踩坑——梯…...

浅论虚荣心
浅论虚荣心虚荣心是人性中常见的一种心理倾向,是人们为了取得荣誉和引起普遍注意而表现出来的一种社会情感和心理状态。适度的虚荣心可以给生活带来激情,给工作带来动力,在一定条件下,它也能成为自尊心、自信心建立的促进剂——但…...

如何将iCloud/iTunes备份恢复到新的iPhone?
刚买了一部新 iPhone,不知道如何恢复所有旧数据?无论您的备份存储在 iTunes 还是 iCloud,都有多种方法可以将备份恢复到新 iPhone。本指南将逐步指导您完成所有可靠的方法,以便您快速将旧设备上的所有内容传输到新设备并从上次中断…...

SparkSQL临时表实战:4种高效创建方式与应用场景解析
1. SparkSQL临时表基础与应用场景 临时表是SparkSQL中处理数据的重要工具,它允许我们在数据处理过程中暂存中间结果,避免重复计算。我在实际项目中经常遇到需要多次引用同一数据集的情况,这时候临时表就能大显身手。比如做数据清洗时…...
Matlab程序)
改进无人机三维路径规划(蜣螂优化算法)Matlab程序
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matl…...

一人干出3人活!当贝Molili在混沌学园教你用好OpenClaw
如果说2025年是AI大模型的内卷之年,2026年则是AI Agent(智能体)规模化落地的元年。3月29日,当贝Molili产品负责人唐涛受邀登上国内创新标杆混沌学园的讲坛,以《用OpenClaw打造7x24小时个人分身,一人团队如何干出3人产出》为主题&a…...

【AI】Datadog
Datadog是当前全球范围内最主流的商业可观测性平台,是一个将监控、安全与AI分析深度整合的SaaS服务。 作为业界公认的领军者,其核心价值在于提供了一个 “大一统”的中央控制台,帮助企业技术团队全面洞察其整个技术栈的运行状况。在AI快速发展…...

Web-Maker深度解析:理解多预处理器支持的实现原理
Web-Maker深度解析:理解多预处理器支持的实现原理 【免费下载链接】web-maker A blazing fast & offline frontend playground 项目地址: https://gitcode.com/gh_mirrors/we/web-maker Web-Maker是一款强大的离线前端开发工具,它支持多种CSS…...

Comsol弱形式求解三维光子晶体能带:快速而精确的模拟方法探索光子晶体的局域化光学行为
Comsol弱形式求解三维光子晶体能带。深夜两点盯着屏幕上扭曲的能带曲线,突然意识到三维光子晶体的数值模拟就像在量子迷宫里玩俄罗斯方块——每个晶格参数都可能让整个能带结构瞬间崩塌。传统界面操作总让我感觉戴着镣铐跳舞,直到某天偶然翻到COMSOL的弱…...