TensorRT推理端到端
TensorRT推理端到端
- 1.参考链接
- 2.宿主机上安装CUDA 12.4.1
- 3.安装nvidia-container-toolkit
- 4.创建ghcr.io/intel/llvm/ubuntu2204_base容器
- 5.容器内安装CUDA 12.4.1 + TensorRT10.1.0
- 6.安装依赖
- 7.准备resnet50模型
- 8.准备bert模型
- 9.准备yolov5m模型
- 10.编译TensorRT推理程序
- 11.onnx模型CPU推理,生成输出、输出数据对照数据
- 12.TensorRT C++推理跟CPU输出对比MSE
- 13.清理
本文演示TensorRT推理端到端
主要内容
- 生成onnx模型
- onnxruntime cpu推理,保存输入、输出做为对照参考文件
- TensorRT C++ API推理,跟对照文件计算MSE
1.参考链接
- TensorRT 10.5.0 Installation Guide
2.宿主机上安装CUDA 12.4.1
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda_12.4.1_550.54.15_linux.run
sudo apt-get --purge -y remove 'nvidia*'
bash cuda_12.4.1_550.54.15_linux.run
3.安装nvidia-container-toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
4.创建ghcr.io/intel/llvm/ubuntu2204_base容器
docker stop ai_model_dev
docker rm ai_model_dev
docker run --gpus all --shm-size=32g -ti -e NVIDIA_VISIBLE_DEVICES=all --privileged --net=host --name ai_model_dev -it -v $PWD:/home -w /home ghcr.io/intel/llvm/ubuntu2204_base /bin/bash
docker start ai_model_dev
docker exec -ti ai_model_dev /bin/bash
设置代理[可选]
export proxy="http://192.168.30.26:808"
export http_proxy=$proxy
export https_proxy=$proxy
5.容器内安装CUDA 12.4.1 + TensorRT10.1.0
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-4wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/10.1.0/local_repo/nv-tensorrt-local-repo-ubuntu2204-10.1.0-cuda-12.4_1.0-1_amd64.deb
dpkg -i nv-tensorrt-local-repo-ubuntu2204-10.1.0-cuda-12.4_1.0-1_amd64.deb
dpkg -i /var/nv-tensorrt-local-repo-ubuntu2204-10.1.0-cuda-12.4/*.deb
6.安装依赖
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
pip install requests pillow onnx transformers onnxruntime
wget https://download.pytorch.org/whl/cpu/torch-2.3.1%2Bcpu-cp310-cp310-linux_x86_64.whl
pip install torch-2.3.1+cpu-cp310-cp310-linux_x86_64.whl
wget https://download.pytorch.org/whl/cpu/torchvision-0.18.1%2Bcpu-cp310-cp310-linux_x86_64.whl
pip install torchvision-0.18.1+cpu-cp310-cp310-linux_x86_64.whl# 编译支持cuda的opencv【可选】
git clone -b 4.x https://github.com/opencv/opencv_contrib
git clone -b 4.x https://github.com/opencv/opencvcd opencv
rm build -rf
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=Release \-D CMAKE_INSTALL_PREFIX=/usr/local \-D OPENCV_EXTRA_MODULES_PATH=/home/opencv_contrib/modules/ \-D WITH_CUDA=ON \-D CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda \-D OPENCV_ENABLE_NONFREE=ON \-D BUILD_opencv_python3=ON \-D WITH_TBB=ON \-D BUILD_NEWP=ON \-D BUILD_EXAMPLES=OFF ..
make -j
7.准备resnet50模型
import requests
from PIL import Image
from io import BytesIO
import torchvision.transforms as transforms
import torch
import torchvision.models as models# 读取图片
image = Image.open("YellowLabradorLooking_new.jpg")# 定义预处理流程
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])# 应用预处理
img_t = preprocess(image)
input_tensor = torch.unsqueeze(img_t, 0)
print("Image downloaded and preprocessed successfully.")#with open('resnet50_input.bin', 'wb') as f:
# f.write(input_tensor.numpy().tobytes())# 加载预训练的ResNet50模型
model = models.resnet50(pretrained=True)
model.eval() # 将模型设为评估模式# 执行前向推理
with torch.no_grad():output = model(input_tensor)#with open('resnet50_output.bin', 'wb') as f:
# f.write(output.numpy().tobytes())# 获取预测结果
predicted = torch.argmax(output, 1)# 加载ImageNet的类别索引
with open("imagenet_classes.txt") as f:idx_to_class = [line.strip() for line in f.readlines()]# 输出预测的类别名
predicted_class = idx_to_class[predicted]
print(f"Index:{predicted} Predicted class: {predicted_class}")input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model, input_tensor, "resnet50.onnx", verbose=False, input_names=input_names, output_names=output_names)
python resnet50.py
8.准备bert模型
import torch
from transformers import BertTokenizer, BertModel# 1. 定义仅返回 pooler_output 的自定义模型
class BertPoolerOutputModel(torch.nn.Module):def __init__(self):super(BertPoolerOutputModel, self).__init__()self.bert = BertModel.from_pretrained('bert-base-uncased')def forward(self, input_ids, attention_mask=None, token_type_ids=None):# 获取 BERT 模型的输出outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)# 仅返回 pooler_outputpooler_output = outputs.pooler_output # [batch_size, hidden_size]return pooler_output# 2. 实例化自定义模型和分词器
model = BertPoolerOutputModel()# 加载模型和 tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertPoolerOutputModel()
model.eval()# 准备输入数据
text = "Hello, my dog is cute"
inputs = tokenizer(text, return_tensors="pt",max_length=512, truncation=True, padding='max_length')
print(inputs['input_ids'].shape)'''
with open('bert-base-uncased-input_ids.bin', 'wb') as f:f.write(inputs['input_ids'].numpy().tobytes())with open('bert-base-uncased-attention_mask.bin', 'wb') as f:f.write(inputs['attention_mask'].numpy().tobytes())
'''output=model(inputs['input_ids'], inputs['attention_mask'])
print(output.shape)
'''
with open('bert-base-uncased-output.bin', 'wb') as f:f.write(output.detach().numpy().tobytes())
'''
# 导出为 ONNX 格式
torch.onnx.export(model,(inputs['input_ids'], inputs['attention_mask']),"bert-base.onnx",export_params=True,opset_version=14,do_constant_folding=True,input_names=['input_ids', 'attention_mask'],output_names=['pooler_output']
)
python bert_base.py
9.准备yolov5m模型
rm yolov5 -rf
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
wget https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt
python export.py --weights yolov5m.pt --include onnx --img 640
mv yolov5m.onnx ../
cd ..
10.编译TensorRT推理程序
#include <iostream>
#include <fstream>
#include <cassert>
#include <string>
#include <vector>
#include <map>
#include <functional>
#include <cuda_runtime.h>
#include <NvInfer.h>
#include <NvOnnxParser.h>/*** @brief 自定义日志器类,用于记录 TensorRT 的日志信息*/
class Logger : public nvinfer1::ILogger {
public:/*** @brief 实现日志记录函数* @param severity 日志级别* @param msg 日志信息*/void log(Severity severity, const char* msg) noexcept override {// 只记录警告及以上级别的日志if (severity <= Severity::kWARNING) {std::cout << msg << std::endl;}}
};// 全局日志器实例
static Logger gLogger;/*** @brief 计算数据的哈希值,用于缓存模型* @param data 数据指针* @param size 数据大小* @return size_t 哈希值*/
size_t computeHash(const void* data, std::size_t si相关文章:

TensorRT推理端到端
TensorRT推理端到端 1.参考链接2.宿主机上安装CUDA 12.4.13.安装nvidia-container-toolkit4.创建ghcr.io/intel/llvm/ubuntu2204_base容器5.容器内安装CUDA 12.4.1 + TensorRT10.1.06.安装依赖7.准备resnet50模型8.准备bert模型9.准备yolov5m模型10.编译TensorRT推理程序11.onn…...

获取历史的天气预报数据的网站
要获取从2019年到现在某个中国城市的天气数据,您可以通过以下方法实现: 1. 使用第三方天气数据API 许多天气服务提供商提供了历史天气数据的API接口,您可以通过这些API获取所需的数据。以下是一些常用的天气数据API提供商: 1.1…...

【VUE】Vue中常用的修饰符
事件修饰符 .stop:阻止事件冒泡。.prevent:阻止默认事件。.capture:使用事件捕获模式。.self:只当事件在该元素本身(比如不是子元素)触发时触发回调。.once:只触发一次事件。 按键修饰符 .en…...

数据分箱:如何确定分箱的最优数量?
选择最优分箱可以考虑以下几种方法: 一、基于业务理解 分析业务背景:从业务角度出发,某些特征可能有自然的分组或区间划分。例如,年龄可以根据不同的人生阶段进行分箱,收入可以根据常见的收入等级划分。 优点&#x…...

机器学习核心功能:分类、回归、聚类与降维
机器学习核心功能:分类、回归、聚类与降维 机器学习领域的基本功能类型通常按照学习模式、预测目标和算法适用性来分类。这些类型包括监督学习、无监督学习、半监督学习和强化学习,它们可以进一步细化为特定的任务,如分类、回归、聚类和降维…...

Python爬虫-eBay商品排名数据
前言 本文是该专栏的第39篇,后面会持续分享python爬虫干货知识,记得关注。 本文以eBay为例,通过搜索目标”关键词“,获取相关搜索”关键词“的商品排名数据。废话不多说,具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。接下来,跟着笔者直接往下看正文详…...
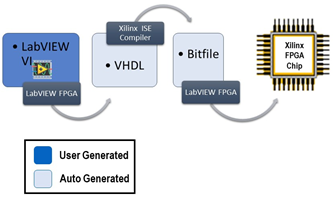
LabVIEW提高开发效率技巧----图像处理加速
在现代工业和科研中,图像处理技术被广泛应用于质量检测、自动化控制、机器人导航等领域。然而,随着图像数据量的增加,传统的CPU处理方式可能难以满足实时性和高效处理的需求。LabVIEW通过结合NI Vision模块和FPGA硬件平台,可以显著…...
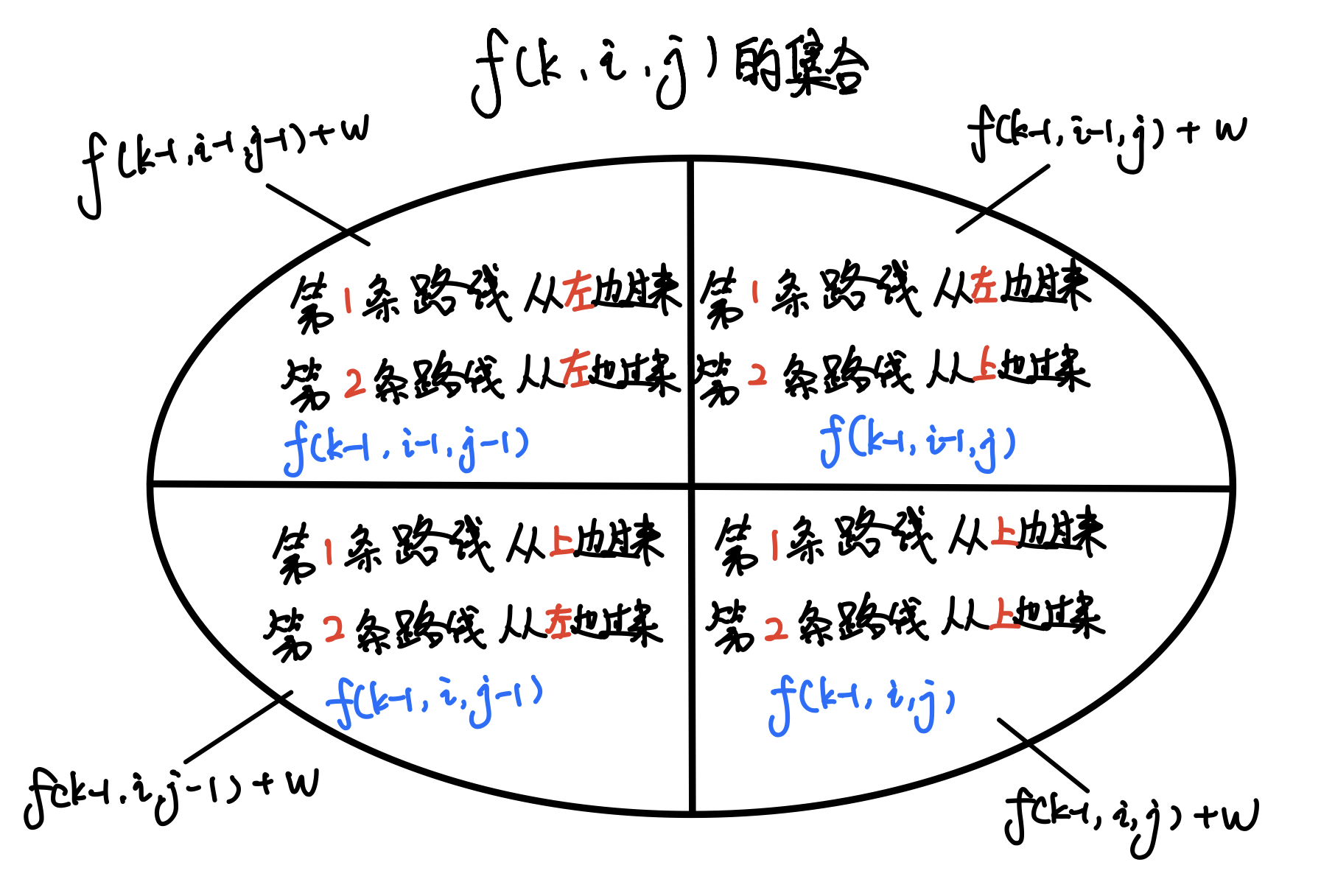
AcWing1027
题目重述: 题目的核心是找到一条路径的最大权值总和,但路径要从起点 (1, 1) 走到终点 (n, n)。由于两条路径分别经过不同的格子,我们可以巧妙地将问题简化为两次同时出发的路径问题。这种映射的设计让我们能够更方便地处理两条路径重叠在同一…...

23 Shell Script服务脚本
Linux 服务脚本 一、Linux 开机自动启动服务 linux开机服务原理: ①linux系统启动首先加载kernel ②初始操作系统 ③login验证程序等待用户登陆 初始化操作系统 kernel加载/sbin/init创建用户空间的第一个程序 该程序完成操作系统的初…...

三周精通FastAPI:3 查询参数
查询参数 FastAPI官网手册:https://fastapi.tiangolo.com/zh/tutorial/query-params/ 上节内容:https://skywalk.blog.csdn.net/article/details/143046422 声明的参数不是路径参数时,路径操作函数会把该参数自动解释为**查询**参数。 from…...

大语言模型学习指南:入门、应用与深入
0x00 学习路径概述 本文将学习路径划分为三个部分:入门篇、应用篇、深入篇。每个章节针对不同的学习需求,帮助你从基础知识入手,逐步掌握大语言模型(LLM)的使用、应用开发以及技术原理等内容。 学习目标 入门篇&…...

【Linux-进程间通信】匿名管道+4种情况+5种特征
匿名管道 匿名管道(Anonymous Pipes)是Unix和类Unix操作系统中的一种通信机制,用于在两个进程之间传递数据。匿名管道通常用于命令行工具之间的数据传递; 匿名管道的工作原理是创建一个临时文件,该文件被称为管道文件…...

Perl打印9x9乘法口诀
本章教程主要介绍如何用Perl打印9x9乘法口诀。 一、程序代码 1、写法① use strict; # 启用严格模式,帮助捕捉变量声明等错误 use warnings; # 启用警告,帮助发现潜在问题# 遍历 1 到 9 的数字 for my $i (1..9) {# 对于每个 $i,遍历 1…...

Android--第一个android程序
写在前边 ※安卓开发工具常用模拟器汇总Android开发者必备工具-常见Android模拟器(MuMu、夜神、蓝叠、逍遥、雷电、Genymotion...)_安卓模拟器-CSDN博客 ※一般游戏模拟器运行速度相对较快,本文选择逍遥模拟器_以下是Android Studio连接模拟器实现(先从以上博文中…...

MySQL的并行复制原理
1. 并行复制的概念 并行复制(Parallel Replication)是一种通过同时处理多个复制任务来加速数据复制的技术。它与并发复制的区别在于,并行复制更多关注的是数据块或事务之间的并行执行,而不是单纯的任务并发。在数据库主从复制中&…...

2023年五一杯数学建模C题双碳目标下低碳建筑研究求解全过程论文及程序
2023年五一杯数学建模 C题 双碳目标下低碳建筑研究 原题再现: “双碳”即碳达峰与碳中和的简称,我国力争2030年前实现碳达峰,2060年前实现碳中和。“双碳”战略倡导绿色、环保、低碳的生活方式。我国加快降低碳排放步伐,大力推进…...

信息安全工程师(57)网络安全漏洞扫描技术与应用
一、网络安全漏洞扫描技术概述 网络安全漏洞扫描技术是一种可以自动检测计算机系统和网络设备中存在的漏洞和弱点的技术。它通过使用特定的方法和工具,模拟攻击者的攻击方式,从而检测存在的漏洞和弱点。这种技术可以帮助组织及时发现并修补漏洞ÿ…...

练习题 - Scrapy爬虫框架 Spider Middleware 爬虫页中间件
在 web 爬虫开发中,Scrapy 是一个非常强大且灵活的框架,它可以帮助开发者轻松地从网页中提取数据。Scrapy 的下载器中间件(Downloader Middleware)是 Scrapy 处理下载请求和响应的一个重要组件。通过使用和编写下载器中间件,开发者可以自定义请求的处理过程,增加请求头信…...
)
探索C++的工具箱:双向链表容器类list(1)
引言 在C中,std::list 是一个标准库提供的容器类,属于C STL(标准模板库)。std::list 是一种独特而强大的容器,它使用双向链表结构来管理元素。无论是在处理动态数据集合,还是在需要频繁进行插入和删除操作时…...

大厂高频算法考点--单调栈
什么是单调栈: 单调栈就是借助一个栈,在仅仅使用当前栈的条件下,时间复杂度是N(n),将每个节点最有离这他最近的大于或者是小于的数据返回,将已知数组的元素放到栈里。再自我实现的代码里面我们使用数组实现…...

3种方式轻松搞定地理数据处理:Mapshaper免费开源工具完全指南
3种方式轻松搞定地理数据处理:Mapshaper免费开源工具完全指南 【免费下载链接】mapshaper Tools for editing Shapefile, GeoJSON, TopoJSON and CSV files 项目地址: https://gitcode.com/gh_mirrors/ma/mapshaper 你是否曾经面对庞大的地理数据文件感到束手…...

突破VMware限制:Unlocker工具实现macOS虚拟机的完整指南
突破VMware限制:Unlocker工具实现macOS虚拟机的完整指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 在虚拟化技术广泛应用的今天,许多开发者和技术爱好者需要在非苹果硬件上…...

OpenClaw版本升级:无缝迁移Kimi-VL-A3B-Thinking服务的实践
OpenClaw版本升级:无缝迁移Kimi-VL-A3B-Thinking服务的实践 1. 升级前的准备工作 上周五晚上,当我正准备下班时,收到了OpenClaw团队发来的新版本发布邮件。作为一个重度依赖OpenClawKimi-VL-A3B-Thinking组合的开发者,我既期待新…...

tao-8k镜像免配置部署教程:开箱即用的Xinference Embedding服务
tao-8k镜像免配置部署教程:开箱即用的Xinference Embedding服务 你是不是也遇到过这样的烦恼:想用个强大的文本嵌入模型,结果光是环境配置、依赖安装、模型下载就折腾了大半天,最后还可能因为版本冲突、路径不对而失败࿱…...

OpenSC2K终极问题解决指南:20个典型开发和使用问题及快速解决方案
OpenSC2K终极问题解决指南:20个典型开发和使用问题及快速解决方案 【免费下载链接】OpenSC2K OpenSC2K - An Open Source remake of Sim City 2000 by Maxis 项目地址: https://gitcode.com/gh_mirrors/op/OpenSC2K OpenSC2K是一款基于JavaScript和WebGL Can…...
)
Halcon 9点标定保姆级教程:从螺丝批头点到机械手精准定位(附源码)
Halcon 9点标定实战指南:从硬件准备到误差优化的全流程解析 在工业自动化领域,视觉引导的机械手定位精度直接影响生产质量。许多工程师第一次接触Halcon标定时,往往被理论公式和算法流程所困扰,却忽略了现场实施中最关键的实操细节…...

利用MT5进行文案润色:输入原始文案,AI输出优化后的多种版本
利用MT5进行文案润色:输入原始文案,AI输出优化后的多种版本 1. 为什么需要文案自动润色工具 在日常工作中,我们经常遇到这样的场景: 写了一篇产品介绍,但总觉得表达方式单一,缺乏吸引力需要为同一内容生…...
)
【2026年最新600套毕设项目分享】校园水电费管理微信小程序(30004)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

Qwen-Audio歌唱语音识别效果展示
Qwen-Audio歌唱语音识别效果展示 1. 歌唱语音识别的独特挑战与突破 当我们在听一首歌时,大脑会自动分离出旋律、节奏、歌词和情感表达。但对AI模型来说,这却是个复杂得多的任务——它需要同时处理音高变化、节奏韵律、人声谐波特征,还要准确…...

氧化镓高体积热容的特性,集成高介电常数界面的结侧冷却架构
速览:技术背景与挑战背景: 虽然宽禁带(WBG)半导体(如SiC、GaN)已取得进展,但超宽禁带(UWBG)材料如氧化镓(Ga₂O₃)具有更高的理论极限。痛点&…...