【AIGC视频生成】视频扩散模型(综述+最新进展)

文章目录
- 一、综述
- 1.1 扩散模型
- 1.1.1 Denoising Diffusion Probabilistic Models (DDPMs)
- 1.1.2 Score-Based Generative Models (SGMs)
- 1.1.3 Stochastic Differential Equations (Score SDEs)
- 1.2 相关任务
- 1.3 数据集
- 1.4 评价指标
- 二、年度进展
- 1.runway gen
- 2.1 Gen-1:对现有的3D动画和手机视频进行AI编辑
- 2.2 Gen-2获得了史诗级的升级——可以从头开始生成视频
- 2.Emu Video(Meta发布)
- 2.1 Emu Edit :精确的图像编辑
- 2.2 Emu Video:先生成图像,再通过图像和文本生成视频
- 2.3 如何延长生成视频的时长
- 3.Stable Video Diffusion (SVD:Stability AI发布)
- SVD的训练三步骤:图像预训练、视频预训练、视频微调
- 4.Pika 1.0:电影特效级视频生成模型
- 1.1 Pika 1.0原理:DreamPropeller通过基于分数蒸馏,加速文本到3D的生成过程
- 5.阿里I2VGEN-XL
- 6.腾讯DynamiCrafter :让图像动起来
- 三*、预备知识:Text-to-image
- 四、SORA原理解析
- 1. 被突破的认知
- 2. 数据的定义也决定了问题的定义
- 3. 核心信仰:scale up
- 4.Sora 的学习 – 网络结构
- 拓展
- 一、基于分数的生成模型(Score-based Generative Model )
一、综述
最新综述《A Survey on Video Diffusion Models》来自于复旦大学,论文地址为:https://arxiv.org/abs/2310.10647
人工智能生成内容(AIGC)目前是计算机视觉和人工智能领域最杰出的研究领域之一。它不仅引起了广泛的关注和学术研究,还在各行各业和其他应用领域产生了深远的影响,例如计算机图形学、艺术和设计、医学成像等。在这些努力中,一系列以扩散模型为代表的方法已经取得了特别成功,迅速取代了基于生成对抗网络(GANs)和自回归变换器的方法,成为图像生成的主导方法。由于其强大的可控性、逼真的生成和出色的多样性,基于扩散的方法也在广泛的计算机视觉任务中蓬勃发展,包括图像编辑、密集预测以及视频合成和3D生成等各种领域。
作为最重要的媒介之一,视频在互联网上崭露头角,成为了一个强大的力量。与纯文本和静态图像相比,视频提供了大量的动态信息,为用户提供更全面和沉浸式的视觉体验。基于扩散模型的视频任务研究逐渐引起了关注。如图1所示,自2022年以来,基于扩散模型的视频研究论文数量显著增加,可以分为三个主要类别: 视频生成、视频编辑和视频理解 。

1.1 扩散模型
扩散模型是一类概率生成模型,它们学习逆转一个逐渐破坏训练数据结构的过程,已经成为深度生成模型的新领域的最新技术。它们在各种具有挑战性的任务中打破了长期以来生成对抗网络(GANs)的统治地位,这些任务包括 图像生成、图像超分辨率和图像编辑 。目前,有关扩散模型的研究主要基于三种主要的表达方式: 去噪扩散概率模型(DDPMs)、基于分数的生成模型(SGMs)和随机微分方程(Score SDEs) 。
1.1.1 Denoising Diffusion Probabilistic Models (DDPMs)
去噪扩散概率模型(DDPM)涉及两个马尔可夫链:一个前向链,将数据转化成噪声,和一个反向链,将噪声转化回数据。前者旨在将任何数据转化为简单的先验分布,而后者学习了反转前者过程的转移核。新的数据点可以通过首先从先验分布中抽样一个随机向量,然后通过反向马尔可夫链进行衍生抽样来生成。这个抽样过程的关键在于训练反向马尔可夫链以匹配前向马尔可夫链的实际时间反转。

1.1.2 Score-Based Generative Models (SGMs)
基于得分的生成模型(SGMs)的关键思想是使用不同程度的噪声扰动数据,并同时通过训练单个条件得分网络来估计对应于所有噪声水平的得分。样本是通过将得分函数在逐渐降低的噪声水平上进行链接,并结合基于得分的采样方法生成的。在 SGMs 的定义中,训练和采样是完全解耦的。

1.1.3 Stochastic Differential Equations (Score SDEs)
用多个噪声尺度扰动数据对于上述方法的成功至关重要。Score SDEs 将这一思想进一步推广到无限数量的噪声尺度。扩散过程可以被建模为以下随机微分方程(SDE)的解:

1.2 相关任务
视频扩散模型的应用范围包括广泛的视频分析任务,包括视频生成、视频编辑以及各种形式的视频理解任务。这些任务的方法论具有相似性,通常将问题制定为扩散生成任务或者利用扩散模型的强大控制生成能力用于下游任务。在这份综述中,主要关注的任务包括文本到视频生成、无条件视频生成以及文本引导的视频编辑等。
文本到视频生成旨在基于文本描述自动生成相应的视频。通常涉及理解文本描述中的场景、物体和动作,将其翻译成一系列连贯的视觉帧,从而生成一个在逻辑和视觉上一致的视频。文本到视频生成具有广泛的应用,包括自动生成电影、动画、虚拟现实内容、教育演示视频等。

提示:详细内容见最后
无条件视频生成是一个生成建模任务,其目标是从随机噪声或固定的初始状态开始生成一系列连续而视觉一致的视频,而无需依赖特定的输入条件。与有条件视频生成不同,无条件视频生成不需要任何外部指导或先验信息。生成模型需要自主学习如何在没有明确输入的情况下捕捉时间动态、行动和视觉一致性,以产生既真实又多样的视频内容。这对于探索生成模型从无监督数据中学习视频内容的能力和展示多样性至关重要。
文本引导视频编辑是一种利用文本描述来引导视频内容编辑过程的技术。在这个任务中,将自然语言描述作为输入,描述对视频要应用的期望更改或修改。然后,系统分析文本输入,提取相关信息,如对象、动作或场景,并使用这些信息来指导编辑过程。文本引导视频编辑通过允许编辑者使用自然语言传达其意图,为实现高效和直观的编辑提供了一种方式,潜在地减少了逐帧手动和耗时的编辑需求。

提示:详细内容见最后
1.3 数据集
视频理解任务的演进通常与视频数据集的发展保持一致,对视频生成任务也是如此。视频生成的数据集主要可分为标题级别(caption-level)和类别级别(category-level)。
标题级别(caption-level)数据集 包括与描述性文本标题配对的视频,为训练模型基于文本描述生成视频提供了必要的数据。下图左列出了几个常见的标题级别数据集,在规模和领域上各不相同。早期的标题级别视频数据集主要用于视频文本检索任务 [84–86],规模较小(不超过12万)且主要关注特定领域(如电影 [86]、动作 [87, 92]、烹饪 [88])。随着 通用领域 WebVid-10M [94] 数据集 的引入,文本到视频(T2V)生成任务获得了动力,研究人员开始关注通用领域的 T2V 生成任务。尽管它是 T2V 任务的主要基准数据集,但仍存在分辨率较低(360P)和带有水印内容等问题。随后,为增强通用文本到视频(T2V)任务中视频的分辨率和广泛覆盖,VideoFactory [30] 和 InternVid [99] 引入了更大规模 (130M 和 234M)和高清晰度(720P)的通用领域数据集。

类别级别(category-level)数据集 包括根据特定类别分组的视频,每个视频都带有类别标签。这些数据集通常用于无条件视频生成或类别条件视频生成任务。上图右总结了常用数据集。其中有几个数据集也用于其他任务。例如,UCF101 [101]、Kinetics [103, 107] 和 Something-Something [106] 是动作识别的典型基准数据集。DAVIS [105] 最初是为视频对象分割任务提出的,后来成为视频编辑的常用基准数据集。在这些数据集中,UCF-101 [101] 最为广泛用于视频生成,作为无条件视频生成、基于类别的有条件生成和视频预测的基准。它包含来自 YouTube [110] 的样本,包括101个动作类别,包括人类运动、乐器演奏和互动动作。与 UCF 类似,Kinetics-400 [103] 和 Kinetics-600 [107] 是两个包含更复杂的动作类别和更大数据规模的数据集,但仍保持与 UCF-101 [101] 相同的应用范围。另一方面,Something-Something [106] 数据集既具有类别级别标签,也具有标题级别标签,因此特别适用于文本条件视频预测任务。值得注意的是,这些最初在动作识别领域起到关键作用的大规模数据集具有较小的规模(不超过5万)和单一类别 [82, 83]、单一领域属性(数字 [81]、驾驶风景 [35, 102, 109]、机器人 [108]),因此不足以生成高质量的视频。因此,近年来提出了专门为视频生成任务设计的数据集,通常具有独特属性,如高分辨率(1080P)[35] 或较长持续时间 [109, 112]。例如,Long Video GAN [109] 提出了马背数据集,其中包含 66 个视频,每个视频的平均持续时间为 30fps 的 6504 帧。Video LDM [35] 收集了包含 683,060 个 8 秒长度的真实驾驶视频,分辨率为 1080P 的 RDS 数据集。
1.4 评价指标
视频生成的评估指标通常分为定量和定性度量。 对于定性度量,一些研究中已经使用了人类主观评估,在这种情况下,评估者通常会被呈现两个或多个生成的视频,以与其他竞争性模型合成的视频进行比较。观察者通常进行基于投票的评估,评估视频的逼真程度、自然一致性以及文本对齐(T2V任务)。然而,人工评估既昂贵又有可能无法反映模型的全部能力。因此,接下来主要探讨图像级别和视频级别评估的定量评估标准。
图像级别指标:视频由一系列图像帧组成,因此图像级别的评估指标可以提供对生成的视频帧质量的一定了解。常用的图像级别指标包括 Fréchet Inception Distance (FID) 、峰值信噪比 (PSNR) 、结构相似性指数 (SSIM) 和 CLIPSIM。FID 通过比较合成的视频帧与真实视频帧来评估生成视频的质量。它涉及将图像进行归一化以获得一致的尺度,利用 InceptionV3 从真实和合成视频中提取特征,并计算均值和协方差矩阵。然后将这些统计数据结合起来计算 FID 分数。SSIM 和 PSNR 都是像素级别的指标。SSIM 评估原始和生成图像的亮度、对比度和结构特征,而 PSNR 是代表峰值信号与均方误差(MSE)之比的系数。这两个指标通常用于评估重建图像帧的质量,并应用于超分辨率和修复等任务。CLIPSIM 是一种用于测量图像文本相关性的方法。基于 CLIP 模型,它提取图像和文本特征,然后计算它们之间的相似性。这个指标通常用于文本条件的视频生成或编辑任务。
视频级别指标:虽然图像级别的评估指标代表了生成视频帧的质量,但它们主要关注单个帧,忽略了视频的时间一致性。另一方面,视频级别的指标会提供更全面的视频生成评估。Fréchet Video Distance (FVD) 是一种基于 FID 的视频质量评估指标。 与图像级别方法不同,图像级别方法使用 Inception 网络从单帧图像中提取特征,FVD 利用在 Kinetics 上预训练的 Inflated-3D Convnets (I3D) 从视频片段中提取特征。随后,通过均值和协方差矩阵的组合来计算 FVD 分数。与 FVD 类似,Kernel Video Distance (KVD) 也基于 I3D 特征,但它通过利用基于核的方法最大均值差异 (MMD) 来评估生成视频的质量。Video IS (Inception Score) 使用由 3D-Convnets (C3D) 提取的特征来计算生成视频的 Inception 分数,通常用于 UCF-101 上的评估。高质量的视频具有低熵概率,表示为 P ( y ∣ x ) P(y|x) P(y∣x)
,而多样性是通过检查所有视频的边缘分布来评估,这应该表现出高水平的熵。Frame Consistency CLIP Score 通常用于视频编辑任务,用于测量编辑后视频的一致性。其计算包括为所有编辑后视频的帧计算 CLIP 图像嵌入,并报告所有视频帧对之间的平均余弦相似度。
二、年度进展

视频生成面临的挑战:
- 1.视频生成的内容一致性难以保证,在生成长视频时画面抖动通常变得更为明显

Stable Video Diffusion从一张图片生成视频的两个例子,动作连贯性存在明显的问题。
- 2.视频生成模型的训练与推理都需要消耗极大的计算资源,高清视频和长视频会明显加重资源的消耗

相同环境下,SD1.5生成一张512512图片耗时1秒,SVD生成一段5761024*14视频耗时30秒
- 3.相对于图像可控生成,视频可控生成的难度要大得多,需要额外考虑更多的要素(精细运镜、复杂角色动作)

视频生成的两种范式

1.runway gen
2.1 Gen-1:对现有的3D动画和手机视频进行AI编辑
2023年2月,开发stable diffusion最初版本的Runway提出了首个AI编辑模型Gen-1,可以在原视频的基础上,编辑出想要的视频。无论是粗糙的3D动画,还是用手机拍出来的摇摇晃晃的视频,Gen-1都可以升级出一个不可思议的效果(当然,其背后原因是Gen1 trained jointly on images and videos)
比如用几个包装盒,Gen-1就可以生成一个工厂的视频:

摘要:Gen-1:给图像模型增加时间线,且对图像和视频做联合训练
Gen-1对应的论文为:Structure and Content-Guided Video Synthesis with Diffusion Models,runway只对外发布了Gen-1的论文,2的论文在23年年底之前还没对外发。
如下图,可以基于潜在视频扩散模型(latent video diffusion models),通过给定原始输入图像,既可以通过如「左上角」的文字引导生成视频,也可以通过如「左下角」的图像引导生成视频:

- 首先,需要text-to-image一系列前置工作(比如 DALL-E2 ,Stable Diffusiont)。潜在扩散模型提供了“在感知压缩空间高效合成图像”的方法
- 其次,通过引入带有时间线的预训练图像模型(temporal layers into a pre-trained image model),且在图像和视频上做联合训练「即在一个大规模的无字幕视频,和配对的“文本-图像”的数据集上进行训练( trained on a large-scale dataset of uncaptioned videos and paired text-image data)」,从而将潜在扩散模型扩展到视频生成
Gen1提出了一个 可控的结构和内容感知的 视频扩散模型(controllable structure and content-aware video diffusion model),同时, 在推理阶段可以修改由图像或文本引导的视频 (意味着编辑视频的操作完全在推理阶段中执行,无需额外的针对每个视频的训练或预处理,即Editing is performed entirely at inference time without additional per-video training or pre-processing)
且选择用单眼深度估计的技术来表示结构,且由预先训练的神经网络预测嵌入表示内容(We opt to represent structure with monocular depth estimates and content with embeddings predicted by a pre-trained neural network)
在视频生成的过程中提供了几种控制模式
首先,类似于image synthesis models,训练模型,使得其可以推断视频的内容,例如他们的外观或风格,及匹配用户提供的图像或文本提示
第二,受到扩散过程的启发,将information obscuring process应用到structure representation,以选择模型对给定结构的坚持程度(we apply an information obscuring process to the structure representation to enable selecting of how strongly the model adheres to the given structure)
最后,还对推理过程进行了调整,通过自定义指导方法,以及受classifier-free guidance的启发,以控制生成的剪辑的时间一致性(to enable control over temporal consistency in generated clips),相当于做到了时间、内容、结构三者在一致上的统一对齐
Gen1的训练过程、推理过程的详解
为了保留视频结构 (结构一般指视频的几何、动力学的特征,比如对象的形状、位置以及他们的时间变化) 的同时,编辑视频的内容,需要 基于结构表示s和内容表示c的基础上学习视频x的生成模型 p ( x ∣ s , c ) p(x| s, c) p(x∣s,c) ,从而通过输入的视频推断出其结构表示s,然后根据编辑视频的描述文本c进行修改(modify it based on a text prompt c describing the edit),如下图:

- 上图左侧的训练过程中,输入的视频x用一个固定的编码器 E E E编码到 z 0 z_0 z0,并扩散到 z t z_t zt;另一边,通过对“使用MiDaS获得的depth maps”进行编码,来提取一个结构表示 S S S,并通过使用CLIP对其中一个帧进行编码,来提取内容表示 C C C ,然后,在 S S S、 z t z_t zt、以及通过交叉注意块提供的 C C C的帮助下,模型学习在潜在空间中逆转扩散过程
- 上图右侧的推理过程中,输入视频的结构 S S S以同样的方式提供。为了通过文本指定内容,将CLIP文本嵌入转换为图像嵌入。
训练的最终目标为(原理见DDPM):

时空潜在扩散(Spatio-temporal Latent Diffusion)
为了可以正确的对视频帧的分布进行建模,需要做以下工作
-
1.引入时间层来扩展图像架构,且时间层仅对视频输入有效,另自动编码器保持固定并独立处理视频中的每一帧
-
2.UNet主要由两个模块组成:残差块和transformer块,通过添加跨时间的一维卷积和跨时间的一维自注意力将它们扩展到视频。

在每个残差块中,每个2D卷积之后引入一个时间卷积(如上图左侧);同样在每个2D transformer块后,都包含一个temporal 1D transformer block(which mimics its spatial counterpart along the time axis,,如上图右侧),且将learnable positional encodings of the frame index输入到temporal transformer blocks中。相当于:
在每个空间卷积之后添加一个一维时间卷积(注意,是空间卷积 VS 时间卷积); 在每个空间注意力层之后添加一个一维时间注意力层(注意,是空间注意力 VS 时间注意力)
结构与内容的表示(Representing Content and Structure)
扩散模型非常适合对 p ( x ∣ s , c ) p(x| s, c) p(x∣s,c) 等条件分布进行建模,由于大规模配对的视频-文本数据集比较缺乏,所以只能限制在无字幕的视频数据上进行训练
- 1.我们的目标是根据用户提供的编辑视频的文本提示来编辑视频,但是:我们没有视频三元组的训练数据、编辑prompt、和生成的输出,也没有成对的视频和文本字幕(Thus, while our goal is to edit an input video based on a text prompt describing the desired edited video, we have neither training data of triplets with a video, its edit prompt and the resulting output, nor even pairs of videos and text captions)
- 2.因此,我们必须从训练视频本身导出结构和内容的表示,即 S = S ( x ) , C = C ( x ) S=S(x), C=C(x) S=S(x),C=C(x),训练损失为:

- 3.推理过程中,结构 S S S和内容 C C C 分别来自输入视频 y y y和文本提示 t t t,
z z z~ p θ ( z ∣ s ( y ) , c ( t ) ) , x = D ( z ) p_θ(z|s(y),c(t)), x=D(z) pθ(z∣s(y),c(t)),x=D(z)
2.2 Gen-2获得了史诗级的升级——可以从头开始生成视频
2023年3月份,runway推出了Gen-2的内测版本,并于6月份正式对外发布(Gen-2主页:https://research.runwayml.com/gen2),相比Gen-1,Gen-2获得了史诗级的升级——可以从头开始生成视频。
8月份,Gen-2生成视频的最大长度便从4s提升到了18s;9月,新增导演模式,可以控制镜头的位置和移动速度;11月3日,支持4K超逼真的清晰度作品
基于Gen-2生成视频的8种模式:
1.Text to Video
2.Text + Image to Video

3.Image to Video
4.Stylization
5.Storyboard
6.Mask
7.Render
8.Customization

2.Emu Video(Meta发布)
23年11月16日,Meta发布文生视频模型Emu Video,该模型既支持灵活的图像编辑(例如把「兔子」变成「吹小号的兔子」,再变成「吹彩虹色小号的兔子」),也支持根据文本和图像生成高分辨率视频(例如让「吹小号的兔子」欢快地跳舞)

其中涉及两项工作:灵活的图像编辑由一个叫「Emu Edit」的模型来完成。它支持通过文字对图像进行自由编辑,包括本地和全局编辑、删除和添加背景、颜色和几何转换、检测和分割等等。此外,它还能精确遵循指令,确保输入图像中与指令无关的像素保持不变。高分辨率的视频则由一个名叫「Emu Video」的模型来生成,能够基于文本生成 512x512 的 4 秒高分辨率视频。且有人工评估表明,与 Runway 的 Gen-2 以及 Pika Labs 的生成效果相比,Emu Video 在生成质量和文本忠实度方面的得分可能更高。以下是它的生成效果:

2.1 Emu Edit :精确的图像编辑
相比InstructPix2Pix的优势:更准确的执行指令
论文:《Emu Edit: Precise Image Editing via Recognition and Generation Tasks》
项目地址:https://emu-edit.metademolab.com/
基于指令的图像编辑(Instruction-based image editing)试图让用户使用自然语言指令来解决这些限制。例如,用户可以向模型提供图像并指示其「给鸸鹋穿上消防员服装」这样的指令:

instruct- pix2pix引入了一个可指导的图像编辑模型,他们通过同时利用GPT-3和Prompt-to-Prompt来开发这个模型,以生成一个用于基于指令的图像编辑的大型合成数据集,并利用该数据集来训练一个可遵循指令的图像编辑模型。与使用合成数据集的InstructPix2Pix不同,Mag-icBrush通过要求人类使用在线图像编辑工具,开发了一个人工标注的指令引导的图像编辑数据集,然后在此数据集上微调instructable - pix2pix可以提高图像编辑能力。这些模型的泛化能力有限,通常无法完成与训练时略有不同的任务,例如下图,当让小兔子吹彩虹色的小号,其他模型要么把兔子染成彩虹色,要么是直接生成彩虹色的小号

Emu Edit基于 Meta 开发的包含 16个不同的任务 和 1000 万个合成样本的数据集,每个样本都包含一个输入图像、对要执行任务的描述(即文本指令),以及目标输出图像、任务索引 而成的图像编辑模型,如前所述,Emu Edit 可以根据指令进行自由形式的编辑,包括本地和全局编辑、删除和添加背景、颜色改变和几何变换、检测和分割等任务。可以精确遵循指令,确保输入图像中与指令无关的像素保持不变。

2.2 Emu Video:先生成图像,再通过图像和文本生成视频
T2I到T2V的挑战:
虽然这些模型可以通过使用视频-文本对进一步适用于文本 - 视频(T2V)生成,但视频生成在质量和多样性方面仍然落后于图像生成与图像生成相比,视频生成更具挑战性,因为它需要建模更高维度的时空输出空间,而能依据的仍然只是文本提示。此外,市面上现有的视频-文本数据集的规模通常比图像 - 文本数据集小一个数量级
视频生成的主流模式是使用扩散模型一次生成所有视频帧。与此形成鲜明对比的是,在 NLP 中,长序列生成被表述为一个自回归问题:以先前预测的单词为条件预测下一个单词
因此,后续预测的条件信号(conditioning signal)会逐渐变强。研究者假设,加强条件信号对高质量视频生成也很重要,因为视频生成本身就是一个时间序列
然而,使用扩散模型进行自回归解码具有挑战性,因为借助此类模型生成单帧图像本身就需要多次迭代
因此,Meta 提出了 EMU VIDEO,论文为《EMU VIDEO:Factorizing Text-to-Video Generation by Explicit Image Conditioning》,项目地址为https://emu-video.metademolab.com/,通过显式的中间图像生成步骤来增强基于扩散的文本到视频生成的条件
具体来说,将文生视频问题分解为两个子问题:
- 1.根据输入的文本提示p,生成图像I;
- 2.然后使用更强的条件:生成的图像和文本来生成视频v(模型只需预测图像在未来将如何演变即可)

为了用图像约束模型 ,时对图像进行补零,并将其与一个二进制掩码(指示哪些帧是被补零的)以及带噪声的输入连接起来
由于视频 - 文本数据集比图像 - 文本数据集要小得多,使用冻结的预训练文本 - 图像(T2I)模型初始化文本 - 视频模型,关键的设计决策为—— 改变扩散噪声调度和多阶段训练(adjusted noises chedules for diffusion, and multi-stage training) —— 该方法支持直接生成 512px 分辨率视频,不需要先前方法中使用的一些深度级联模型(without requiring a deep cascade of models as inprior work)。该模型同时使用冻结的T5-XL和冻结的CLIP文本编码器从文本提示符中提取特征。U-Net中单独的cross-attention层负责每个文本特征。在初始化之后,模型包含2.7B被冻结的空间参数,以及1.7B被学习的时间参数
更多细节:
- 1.用预训练的Text2Img模型初始化F,这种初始化保留了从大型图像-文本数据集中学习到的概念和风格多样性,并使用它来生成 I I I。这不需要额外的训练成本,而不像Imagen video那样对图像和视频数据进行联合微调以保持这种风格。当然,许多直接的T2V方法[比如Align your latents: High-resolution video synthesis with latent diffusion models,再比如Make-a-video: Text-to-video generation without text-video data]也从预训练的T2I模型初始化,并保持空间层冻结。然而,它们没有采用我们基于图像的因子分解,因此不能保留T2I模型的质量和多样性
- 2.使用潜在扩散模型,首先按帧使用图像自动编码器,将视频V转为潜在空间 X ∈ R T × C × H × W X∈R^{T×C×H×W} X∈RT×C×H×W,降低了空间维度;再利用解码器转换回像素空间。
T个帧被独立加噪,扩散模型被训练去噪。- 3.我们使用预训练的T2I模型初始化潜在扩散模型F,像「上文1.1.2.2 时空潜在扩散(Spatio-temporal Latent Diffusion)」所述的一样,我们添加了新的可学习的时间参数:
– 在每个空间卷积之后添加一个一维时间卷积
– 在每个空间注意力层之后添加一个一维时间注意力层
原始的空间卷积层和注意力层被独立应用到每个T帧上,并保持冻结
与直接用文本生成视频的方法不同,他们的分解方法在推理时会显式地生成一张图像,这使得他们能够轻松保留文生图模型的视觉多样性、风格和质量,如下图所示(这使得 EMU VIDEO 即使在训练数据、计算量和可训练参数相同的情况下,也能超越直接 T2V 方法):



2.3 如何延长生成视频的时长
从展示的 demo 中可以看到,EMU VIDEO 已经可以支持 4 秒的视频生成。在论文中,他们还探讨了增加视频时长的方法。作者表示,通过一个小的架构修改,他们可以在 T 帧上约束模型并扩展视频。因此,他们训练 EMU VIDEO 的一个变体,以「过去」16 帧为条件生成未来 16 帧。在扩展视频时,他们使用与原始视频不同的未来文本提示,效果如图 7 所示。他们发现,扩展视频既遵循原始视频,也遵循未来文本提示。

3.Stable Video Diffusion (SVD:Stability AI发布)
23年11月21日,开发并维护stable diffusion的Stability AI终于发布了他们自家的生成式视频模型Stable Video Diffusion(SVD),支持文本到视频、图像到视频生成,并且还支持物体从单一视角到多视角的转化,也就是3D合成:


SVD的训练三步骤:图像预训练、视频预训练、视频微调
SVD对应的论文为:《Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets》,包括训练SVD的三个步骤:
- 1.文本到图像的图像预训练(image pretraining),即2D文本到图像扩散模型,比如SDXL的工作:Improving Latent Diffusion Models for High-Resolution Image Synthesis
- 2.规模比较大但低分辨率的视频数据集上的视频预训练(video pretraining on a large dataset at low resolu-tion)
我们收集了一个长视频的初始数据集,它构成了我们的视频预训练阶段的基础数据。然后To avoid cuts andfades leaking into synthesized videos, we apply a cut detec-tion pipeline1 in a cascaded manner at three different FPSlevels. Figure 2, left, provides evidence for the need for cutdetection: After applying our cut-detection pipeline, we ob-tain a significantly higher number (∼4×) of clips, indicat-ing that many video clips in the unprocessed dataset containcuts beyond those obtained from metadata.
4.Pika 1.0:电影特效级视频生成模型
地址:https://midjourney.wxmyxz.com/home/#/pika?from=PK360
斯坦福博士生郭文景(Demi Guo) 曾在去年参加Runway的首届AI电影节,发现Runway和Adobe Photoshop的工具并不好用,自己所在团队的作品也并未获奖。
23年4月,郭文景决定从斯坦福退学,开发更好用的AI视频工具,Pika由此诞生(官网地址:https://pika.art),很快联合创始人Chenlin Meng加入。他俩,一个曾参与AlphaFold2的研究,一个则是DDIM论文的二作
Pika成立后,到现在为止已经有了50万用户,他们每周都会制作数百万个视频。硅谷投资人在三轮融资到了5500万美元(前两轮融资由前 GitHub 首席执行官CEO Nat Friedman领投,而最新一轮的3500万美元A轮融资由Lightspeed Venture Partners领投)。且让人颇受鼓舞的是,仅4人团队估值已超2亿美元
23年11月29日,正式发布Pika 1.0, 打开了制作3D动画、动漫、卡通、电影等无限想象空间。能根据 文字图片,流畅地生成视频 ,动静转换就在一瞬间:

而且可编辑性还特别强,指定视频中的任意元素, 一句话就能实现快速“换装”:

Pika 1.0功能包括:
1.文本生成视频/图像生成视频:输入几行文本或上传图像,就可以通过AI创建简短、高质量的视频
2.视频-视频不同风格转换:将现有视频转换为不同的风格,包括不同的角色和对象,同时保持视频的结构
3.扩展(expand):扩展视频的画布或宽高比,将视频从TikTok 9:16格式更改为宽屏16:9格式,AI模型将预测超出原始视频边界的内容,相当于先预测 后补全或填充所需的内容
4.更改:使用 AI 编辑视频内容,比如更换衣服、添加另一个角色、更改环境或添加道具
5.扩展(Extend):使用 AI 扩展现有视频剪辑的长度
6.全新Web界面:Pika 将在Discord和Web上提供
1.1 Pika 1.0原理:DreamPropeller通过基于分数蒸馏,加速文本到3D的生成过程
分数蒸馏,比如DreamFusion、ProlificDreamer等模型,进行文本到3D的生成质量虽高,但运行时间可能长达10个小时。论文《DreamPropeller: Supercharge Text-to-3D Generation with Parallel Sampling》的提出,实现了一种基于分数蒸馏的加速方法——DreamPropeller,能够将现有方法的速度提高4.7倍。整体架构如下图:

-
1.在每次迭代(k次)的开始,初始化一个由3D形状(用绿色表示)组成的窗口,然后,这些形状被分发到p个GPU上进行并行计算,在GPU上并行计算形状的SDS/VSD梯度
-
2.然后根据下述公式收集这些梯度「which are gathered for rollout using the rule in Eq. (9)」,并使用这些梯度对形状进行更新

- 3.将迭代k + 1得到的形状(橙色)与迭代k得到的形状进行比较,窗口向前滑动,直到该时间步的误差不小于阈值e,阈值e根据窗口的平均/中值误差进行自适应更新
在VSD的情况下,研究人员会在所有GPU上保留LoRA diffusion的独立副本,这些副本会独立更新,无需额外通信;如下是与其他模型的可视化比较,可以看出,使用DreamPropeller的方法能以更短的运行时间实现同样高质量的生成

5.阿里I2VGEN-XL
代码和模型开源:https://github.com/ali-vilab/i2vgen-xl

6.腾讯DynamiCrafter :让图像动起来
论文地址:https://arxiv.org/pdf/2310.12190
模型开源:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
摘要:VideoComposer和I2VGen-XL 已经初步尝试了通过图像的视觉引导生成视频。不幸的是,由于它们的图像注入机制不全面,两者都不能适合图像动画,从而导致突然的时间变化或与输入图像的低视觉一致性。本文探索了视端域图像的动态内容的合成,并将其转换为动画视频。其关键思想是利用文本到视频扩散模型的运动先验,将图像纳入生成过程作为指导。
具体流程为:给定一个图像,我们首先通过一个特殊设计的上下文学习网络将其投影到文本对齐的丰富上下文表示空间中。具体来说,它包括一个预训练的CLIP图像编码器来提取文本对齐的图像特征和一个可学习的查询转换器,以进一步促进其对扩散模型的适应。模型通过交叉注意层使用丰富的上下文特征,然后通过门控融合将其与文本条件特征相结合。在某种程度上,学习到的上下文表示将视觉细节与文本对齐进行交换,这有助于促进对图像上下文的语义理解,从而可以合成合理和生动的动态。为了 补充更精确的视觉细节,我们通过将完整的图像与初始噪声连接起来,进一步将其输入给扩散模型。这种 双流注入范式 保证了合理的动态内容和与输入图像的视觉一致性。

前向过程 q ( x t ∣ x 0 , t ) q(x_t|x_0,t) q(xt∣x0,t)包含T个时间步长,逐渐增加噪声,通过参数化技巧产生 x t x_t xt。去噪过程 p θ ( x t − 1 ∣ x t , t ) p_θ(x_{t−1}|x_t,t) pθ(xt−1∣xt,t)通过去噪网络 ϵ θ ( x t , t ) ϵ_θ(x_t,t) ϵθ(xt,t)从噪声输入 x t x_t xt中获得噪声较小的数据 x t − 1 x_{t−1} xt−1,其目标是:

视频扩散模型:对于视频生成任务,潜在扩散模型(LDMs)常用来降低计算复杂度。本文研究基于开源的视频LDM VideoCrafter。给定一个视频 x ∈ R L × 3 × H × W x∈R^{L×3×H×W} x∈RL×3×H×W,将它逐帧编码成一个潜在表示 z = E ( x ) , z ∈ R L × C × w × h z = E(x),z∈R^{L×C×w×h} z=E(x),z∈RL×C×w×h。然后,在这个潜在空间中同时进行前向扩散过程 z t = p ( z 0 , t ) z_t = p(z_0,t) zt=p(z0,t)和后向去噪过程 z t = p θ ( z t − 1 , c , t ) z_t=p_θ(z_{t−1},c,t) zt=pθ(zt−1,c,t),其中 c c c表示可能的去噪条件,如文本提示。因此,通过解码器 x ^ = D ( z ) \hat{x}= D(z) x^=D(z)获得生成的视频。
文本对齐的上下文表示。 CLIP图像编码器的全局语义标记fcls与图像标题对齐良好,但它主要在语义层次上表示视觉内容,并不能捕获图像的全部范围。为了提取更完整的信息,使用了CLIP图像ViT的最后一层的完整的视觉token F v i s F_{vis} Fvis = { f i f^i fi} i = 1 K ^K_{i=1} i=1K(其在条件图像生成工作中显示了高保真度)。为了促进与文本嵌入的对齐,得到可以由去噪U-Net解释的上下文表示,再使用一个可学习的轻量级模型 P将 F v i s F_{vis} Fvis转换为最终的上下文表示 F c t x = P ( F v i s ) F_{ctx} = P(F_{vis}) Fctx=P(Fvis)。 P P P 使用query Transformer架构,由N个堆叠层的交叉注意和前馈网络(FFN)组成,擅长通过交叉注意机制进行跨模态表示学习。随后,利用文本嵌入 F t x t F_{txt} Ftxt和上下文嵌入 F c t x F_{ctx} Fctx,通过双交叉注意层与U-Net中间特征Fin进行交互:

该设计旨在促进模型以一个层依赖的方式吸收图像条件的能力。由于U-Net的中间层与物体形状或姿态的关联更大,而两端层与外观的关联更紧密,我们预计图像特征将主要影响视频的外观,而对形状的影响相对较小.
视觉细节引导(VDG)。信息丰富的上下文表示使视频扩散模型能够产生与输入图像非常相似的视频。然而,如图3所示,仍然可能会出现微小的差异。这主要是由于预训练过的CLIP图像编码器在完全保留输入图像信息方面的能力有限,因为它被设计为对齐视觉和语言特征。为了增强视觉一致性,我们建议为视频模型提供来自图像的额外视觉细节。具体地说,我们将条件图像与每帧的初始噪声连接起来,并将它们作为一种引导形式输入到去噪的U-Net中。因此,在我们提出的双流图像注入范式中,视频扩散模型以一种互补的方式集成了来自输入图像的全局上下文和局部细节。

三阶段的训练策略:(i) 训练图像上下文表示网络P,(ii)使P适应T2V模型,以及(iii)与VDG进行联合微调。考虑到P需要许多优化步骤收敛,我们基于一个轻量级T2I模型来训练P,而不是T2V模型,允许它专注于图像上下文学习,然后通过联合训练P和空间层(与时间层)来适应T2V模型。在为T2V建立了一个兼容的上下文调节分支后,我们将输入图像与每帧噪声连接起来,以进行联合微调,以增强视觉一致性。
三*、预备知识:Text-to-image
















四、SORA原理解析
1. 被突破的认知
• 简单的架构可以学习到复杂的视频生成,有很强的三维,时序,物理一致性

2. 数据的定义也决定了问题的定义
训练数据的不同会导致问题的定义不同,训练目标也不同

3. 核心信仰:scale up
• Diffusion Transformer block
• 多个时长、分辨率、长宽比





4.Sora 的学习 – 网络结构

Sora 是一个视频生成的基础大模型,根据 Sora 技术网站(https://openai.com/research/video-generation-models-as-world-simulators)上的描述 :
-
1.首先训练一个 Video Compression Network,它是一个 3D VAE。它有一个编码器 Encoder 能够将 pixel 表示的视频转换为 latent 表示,同时也有一个解码器 Decoder 能够将 latent 表示转变成 pixel 的视频。
-
2.结合 patchify,它可以把不同长度、不同长宽比、不同分辨率的视频都表示为时空的 patches,然后都“拉成一个序列。
-
3.将上述得到的序列,用 diffusion transformer 进行训练。




d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ
拓展
提示:这里对文章进行总结:
一、基于分数的生成模型(Score-based Generative Model )
两种生成式模型的驱动方法:基于概率似然估计的方法和生成对抗网络(Generative adversarial network,简称为GAN)。前者使用对数似然(或合适的其他损失函数)作为训练目标函数,而后者使用对抗性训练来最小化模型和数据分布之间的f-散度或积分概率度量。
(一)概念:分数匹配与朗之万动力学采样
1、生成模型思路概述
生成模型的目标是希望训练一个神经网络来表征概率分布,从而能够通过其实现采样生成。目前,主流的生成式模型主要可以归纳为两种不同的模式:一类是对数据的采样过程进行建模(不从数据分布的概率密度角度出发,而是通过其它方法达到表示概率分布的目的,因此也被称为隐式(implicit)生成模型,即以GAN为主的深度学习模型);另一类是对概率密度进行建模(直接让模型去估计概率密度,于是被称为显式(explicit)生成模型,即以VAE、DDPM为主的深度生成式模型)。GAN及其魔改结构采用“博弈”的思想,让生成器和判别器不断博弈,直到判别器无法判断到底是真实的数据样本还是由生成器生成的样本时,就可认为生成效果很棒了;以似然估计为主的思路通过极大似然(maximum likelihood)估计的方式来进行学习。这种生成式模型能够明确计算出似然函数,因此可以用统一的指标来比较分析不同模型的好坏,但由于概率必须位于之间,因此这类模型需要指定的网络架构来构建归一化(normalized)的概率模型(如自回归模型、流模型 flow models 等),另外,由于真实的概率密度无法获知,因此通常会使用代理的损失函数来进行训练(如 VAE、基于能量的模型)。
扩散模型(Diffusion Model)属于上面讨论中的第二种,即基于似然估计的生成式模型,在之前所分析的DDPM模型可以看成是级联变分自编码器(VAE)形式,其使用的训练方法也同样为极大似然法,并且它对似然函数的处理方式也类似于VAE用了变分推断(variational inference)来近似。只不过,扩散模型在扩散过程中的每一步都走得非常小(因此需要的步数比较多,导致采样生成的过程慢),“破坏性”不大,因此模型也比较容易学习,学习效果也比较好。
2、基于分数的生成模型(Score-based generative modeling)
(1)分数模型(Score-based models):其主要目标是估计与数据分布相关的梯度(即“分数”的定义,在后文中会详细介绍)并使用朗之万动力学(Langevin dynamics)的方法从估计的数据分布中进行采样来生成新的样本,整体思路框架如图:

假设有一组数据{ x 1 , x 2 , . . . , x N x_1,x_2,...,x_N x1,x2,...,xN} ~ { x i ∈ R D x_i∈R^D xi∈RD} i = 1 N _{i=1}^N i=1N,其中每个数据都是独立同分布,服从于概率密度函数 p ( x ) p(x) p(x)。对于这个数据集,生成式建模的目标是将模型拟合到数据分布中,这样我们就可以通过从分布中采样来随意合成新的数据点。
1)分数函数:通过对分数函数而不是密度函数建模,我们可以避免难以处理的常数归一化的困难。对于分布为 p ( x ) p(x) p(x) 的概率密度函数,其“分数(score)”的定义为对数概率密度函数对于输入数据的梯度,其表达式为

2)分数模型:与分数对应的一个“生成式是深度学习框架”—用来学习这个分数分布的模型—称为分数模型(score-based model),通常用 S θ ( x ) S_θ(x) Sθ(x) 来表示,其表达式可以写为

3)分数匹配(Score Matching):类似于基于似然估计的模型,可以通过最小化模型和数据分布之间的Fisher散度(简记为F-散度)来训练基于分数的模型,其表达式为

值得注意的是,直接计算F-散度是不可行的,原因是需要计算未知概率分布的分数。幸运的是, 存在一种称为分数匹配的方法,可以在不知道真实数据分数的情况下最小化F-散度。分数匹配目标可以直接在数据集上估计,并使用随机梯度下降进行优化 ,类似于训练基于似然模型的对数似然目标(具有已知的归一化常数)。我们可以通过最小化分数匹配目标来训练基于分数的模型,而不需要对抗性优化。
对分数(score)的解释:一般来说,实际场景下的数据往往是多维的。由分数的定义以及从数学的角度出发来看,它应当是一个“矢量场(vector field)”。既然是矢量,那么就有方向,这个方向就是:对于输入数据(样本)来说,其对数概率密度增长最快的方向,其可以用矢量场分布图表示,如图2。在采样过程中沿着分数的方向走,就能够走到数据分布的高概率密度区域,最终生成的样本就会符合原数据分布。

基于分数的模型已经在许多下游任务实现了先进性能,包括图像生成,音频合成,形状生成和音乐生成。此外,基于分数的模型与归一化流模型有联系,因此允许精确的似然计算和表示学习。此外,建模和估计分数有助于逆向问题的解决,应用如图像修补,图像着色,压缩感知和医学图像重建(例如,CT,MRI)。
(3)朗之万动力学(Langevin dynamics) 采样方法:当经过(2)中所述的分数匹配方法训练深度生成模型 S θ ( x ) S_θ(x) Sθ(x)≈ ∇ x \nabla_x ∇xlog p ( x ) p(x) p(x) 后,使用具有迭代过程的朗之万动力学采样方法从分布中来生成新的样本。 朗之万动力学方程,它是描述物理学中布朗运动(悬浮在液体/气体中的微小颗粒所做的无规则运动)的微分方程,借鉴到这里作为一种生成样本的方法。概括地来说,该方法首先从先验分布随机采样一个初始样本,然后利用模型估计出来的分数逐渐将样本向数据分布的高概率密度区域靠近。为保证生成结果的多样性,我们需要采样过程带有随机性。由于布朗运动就是带有随机性的,朗之万动力学方程因此也带有随机项。
假设初始数据满足先验分布 x 0 x_0 x0~ π ( x ) \pi(x) π(x), ,然后使用迭代过程:

(二)分数匹配的实现方法
1、基于分数匹配方法的分数估计
(将前面的分数匹配定义进行复述并对符号进行修正)通过最小化模型和数据分布之间的Fisher散度(简记为F-散度)来训练基于分数的模型,其表达式为:
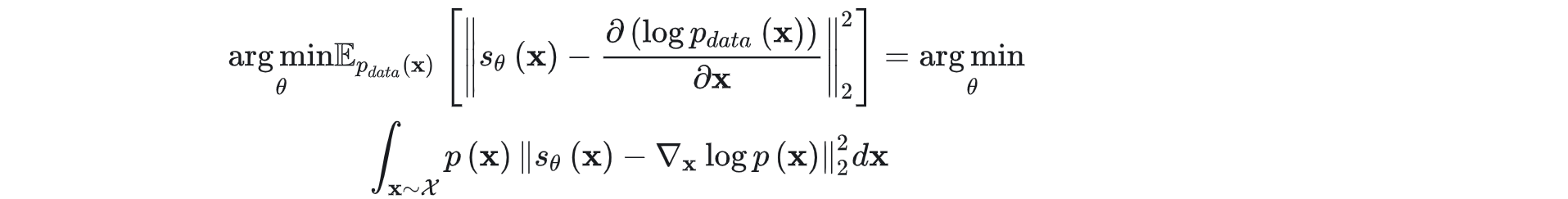
其中, s θ ( x ) s_θ(x) sθ(x)为所学习的网络模型, θ θ θ 为模型参数, E p d a t a ( x ) [ ] E_{pdata}(x)[] Epdata(x)[] 表示在整体数据中计算期望。
在前面提到过,直接计算F-散度是不可行的 (概率分布的分数未知)。基于分数匹配的思想,可以有效地绕过计算数据分布 p d a t a ( x ) p_{data}(x) pdata(x) ,直接训练一个分数网络 s θ ( x ) s_θ(x) sθ(x) 来估计 ∇ x \nabla_x ∇xlog p d a t a ( x ) p_{data}(x) pdata(x) 。使用分部积分方法(这一部分见网上的数学推导,不在此进行计算),上面的损失函数可以计算为
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ
相关文章:
【AIGC视频生成】视频扩散模型(综述+最新进展)
文章目录 一、综述1.1 扩散模型1.1.1 Denoising Diffusion Probabilistic Models (DDPMs)1.1.2 Score-Based Generative Models (SGMs)1.1.3 Stochastic Differential Equations (Score SDEs) 1.2 相关任务1.3 数据集1.4 评价指标 二、年度进展1.runway gen2.1 Gen-1࿱…...

如何下载3GPP协议?
一、进入3GPP网页 https://www.3gpp.org/ 二、点击“Specifications &Technologies” 三、点击“FTP Server” 网址: https://www.3gpp.org/specifications-technologies 四、找到“latest”,查看最新版 网址: https://www.3gpp.org/ftp…...
目标检测系统操作说明【用户使用指南】(python+pyside6界面+系统源码+可训练的数据集+也完成的训练模型)
1.100多种【基于YOLOv8/v10/v11的目标检测系统】目录(pythonpyside6界面系统源码可训练的数据集也完成的训练模型) 2.目标检测系统【环境搭建过程】(GPU版本) 3.目标检测系统【环境详细配置过程】(CPU版本࿰…...

Vue中使用路由
目录 单页应用程序:SPA - Single Page Application路由 VueRouterVueRouter使用步骤组件存放目录问题 路由模块封装声明式导航 - 导航连接两个类名自定义匹配类名 声明式导航 - 跳转传参Vue路由 - 重定向Vue路由 - 404Vue路由 - 模式设置 编程式导航 - 基本跳转编程…...
【Linux】多线程安全之道:互斥、加锁技术与底层原理
目录 1.线程的互斥 1.1.进程线程间的互斥相关背景概念 1.2.互斥量mutex的基本概念 所以多线程之间为什么要有互斥? 为什么抢票会抢到负数,无法获得正确结果? 为什么--操作不是原子性的呢? 解决方式: 2.三种加锁…...
收藏多年的四款音频剪辑工具你pick哪一个?
在这个时代,音频剪辑已经成为音乐制作、播客、自媒体等领域的必备技能。而随着网络技术的飞速发展,我们不再需要安装庞大的软件,只需一个浏览器,就能轻松完成音频剪辑工作。今天,就让我为大家推荐几款优秀的在线音频剪…...

使用Redis进行在线人数统计时,有哪些性能优化技巧?
使用Redis进行在线人数统计时,性能优化是关键,以下是一些性能优化技巧: 选择合适的数据结构: 对于在线人数统计,可以选择使用Set数据结构,因为它具有自动去重和高效的集合操作特性,非常适合用于…...
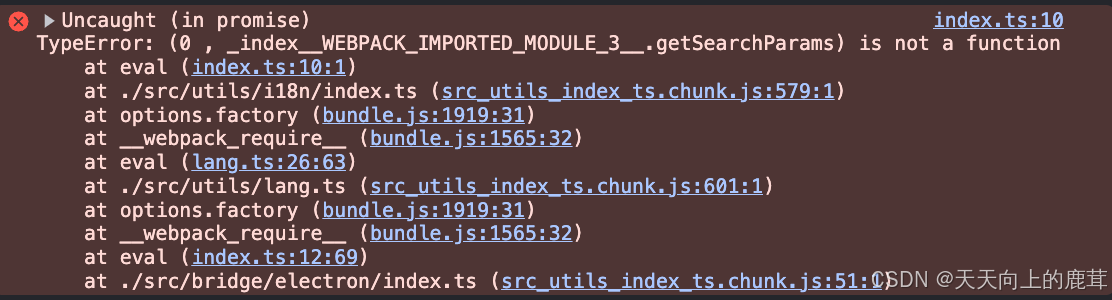
前端模块循环依赖问题
模块循环依赖问题 在项目比较小的时候可能不怎么会遇到这个问题,但项目一旦有一定的体量后就可能会遇到了。 我之前做项目时就遇到这个问题,也是总结一篇文章。 比如这种类型的报错 commonjs存在的问题 先讲一下commonjs存在的问题。 CommonJS模块采…...
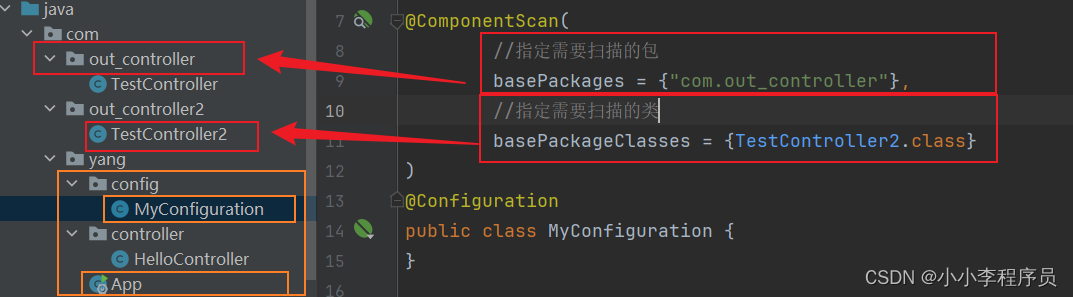
Springboot指定扫描路径
方式一:通过在启动类的SpringbootApplication中指定包扫描或类扫描 指定需要扫描的包 scanBasePackages{"待扫描包1","待扫描包2", . . . ," "} 指定需要扫描的类 scanBasePackageClasses{类1.class,类2.class,...} 方式二ÿ…...

【Flutter】Dart:环境搭建
Flutter 是一个基于 Dart 的跨平台开发框架,可以帮助我们快速构建移动应用程序。在开始 Flutter 开发之前,我们需要先搭建 Dart 的开发环境,并配置合适的编辑器,比如 VSCode。本教程将引导你一步步完成 Dart 和 Flutter 的环境搭建…...

OpenCV高级图形用户界面(10)创建一个新的窗口函数namedWindow()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 创建一个窗口。 函数 namedWindow 创建一个可以作为图像和跟踪条占位符的窗口。创建的窗口通过它们的名字来引用。 如果已经存在同名的窗口&am…...

水题四道。
我的 水题四道--题目目录 问题 A: 依次输出第k小整数 代码1 问题 B: 第k小整数(knumber) 代码2 树的统计 代码3 枪声问题 代码4 问题 A: 依次输出第k小整数 现有n个正整数,n≤10000,要求出这n个正整数中的第1小的整数,第2小的整数…...

upload-labs靶场Pass-05
upload-labs靶场Pass-05 大小写绕过 $deny_ext array(“.php”,“.php5”,“.php4”,“.php3”,“.php2”,“.html”,“.htm”,“.phtml”,“.pht”,“.pHp”,“.pHp5”,“.pHp4”,“.pHp3”,“.pHp2”,“.Html”,“.Htm”,“.pHtml”,“.jsp”,“.jspa”,“.jspx”,“.jsw”…...

【AIGC】解锁高效GPTs:ChatGPT-Builder中系统提示词Prompt的设计与应用
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | ChatGPT 文章目录 💯前言💯系统提示词系统提示词的作用与重要性系统提示词在构建GPTs中的作用结论 💯ChatGPT-Builder系统提示词的详细解读OpenAI为Builder编写的系统提示词系统提示词对…...

【JavaEE初阶】深入理解网络编程—使用UDP协议API实现回显服务器
前言 🌟🌟本期讲解关于TCP/UDP协议的原理理解~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么废话不…...

C语言复习第3章 函数
目录 一、函数介绍1.1 函数是什么1.2 C语言中函数的分类1.3 函数原型1.4 高内聚 低耦合1.5 C语言main函数的位置 二、函数的参数2.1 实参和形参2.2 函数的参数(实参)可以是表达式2.3 传值与传址(swap函数)2.4 明确形参是实参的临时拷贝2.5 void(如果不写函数返回值 默认是int)2…...

Golang | Leetcode Golang题解之第491题非递减子序列
题目: 题解: var (temp []intans [][]int )func findSubsequences(nums []int) [][]int {ans [][]int{}dfs(0, math.MinInt32, nums)return ans }func dfs(cur, last int, nums []int) {if cur len(nums) {if len(temp) > 2 {t : make([]int, len(…...

conan安装方法简介
因为conan是使用python开发的,所以使用conan需要先安装python环境,这里就不展开python的安装方法了。 conan安装有多种方法,但是比较推荐也是比较简单的一种方法是使用python的pip包管理器安装,相关方法如下(Windows和…...

Java面试指南:Java基础介绍
这是《Java面试指南》系列的第1篇,本篇主要是介绍Java的一些基础内容: 1、Java语言的起源 2、Java EE、Java SE、Java ME介绍 3、Java语言的特点 4、Java和C的区别和联系? 5、面向对象和面向过程的比较 6、Java面向对象的三大特性:…...

【mod分享】波斯王子遗忘之沙高清重置,纹理,字体,贴图全部重置,特效增强,支持光追
各位好,今天小编给大家带来一款新的高清重置MOD,本次高清重置的游戏叫《波斯王子:遗忘之沙》。 《波斯王子:遗忘之沙》是由育碧(Ubisoft)开发并发行的一款动作类游戏,于2010年5月18日发行。游戏…...
)
.prettierrc 典型配置(通用版)
文章目录一、完整版标准配置(推荐)二、极简版配置(新手够用)三、常用配置项说明(一看就懂)四、配套使用(必看)五、总结.prettierrc 典型配置(通用版)是前端项…...

终极DDrawCompat使用指南:让经典游戏在现代Windows系统完美运行
终极DDrawCompat使用指南:让经典游戏在现代Windows系统完美运行 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/…...

GEMMA-3像素级JRPG界面实测:零基础也能看懂图片的AI神器
GEMMA-3像素级JRPG界面实测:零基础也能看懂图片的AI神器 1. 复古像素风遇上AI视觉革命 当90年代JRPG的怀旧美学撞上Google最先进的多模态AI,会擦出怎样的火花?GEMMA-3像素级JRPG界面给出了惊艳答案。这款名为"Pixel Station"的工…...

阿姆智创15.6寸触摸工控一体机,工业智造终端解决方案,源头工厂ODM定制赋能自动化升级
在工业自动化与智能制造深度融合的当下,稳定可靠、适配性强、可定制化的工控终端,已成为SMT产线、MES/ESOP系统等场景高效运行的关键支撑。阿姆智创15.6寸触摸工控一体机,以硬核工业性能、丰富系统接口、灵活ODM定制服务,打造一站…...

像素极光入门指南:像插入游戏卡一样加载模型,快速生成梦幻像素风景
像素极光入门指南:像插入游戏卡一样加载模型,快速生成梦幻像素风景 1. 认识像素极光创意引擎 像素极光(Pixel Aurora Engine)是一款专为像素艺术创作设计的AI绘图工作站。它采用复古游戏机风格界面,让AI绘画变得像玩游戏一样简单有趣。与传…...

GHelper:如何用10MB工具取代臃肿的华硕控制中心?
GHelper:如何用10MB工具取代臃肿的华硕控制中心? 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Str…...

使用VS Code开发SenseVoice-Small模型应用的完整指南
使用VS Code开发SenseVoice-Small模型应用的完整指南 1. 开发环境配置 1.1 基础环境准备 在开始开发SenseVoice-Small模型应用之前,需要先确保你的开发环境准备就绪。VS Code作为轻量级但功能强大的代码编辑器,非常适合这类AI模型的开发工作。 首先确…...

如何高效实现图标自动化导入:unplugin-icons与unplugin-vue-components的完美配合指南
如何高效实现图标自动化导入:unplugin-icons与unplugin-vue-components的完美配合指南 【免费下载链接】unplugin-icons 🤹 Access thousands of icons as components on-demand universally. 项目地址: https://gitcode.com/gh_mirrors/un/unplugin-i…...

AcousticSense AI优化升级:如何提升识别准确率和响应速度
AcousticSense AI优化升级:如何提升识别准确率和响应速度 1. 从听到看:音频识别的新范式 传统音频识别技术往往受限于特征提取的局限性,而AcousticSense AI开创性地将声音转化为视觉信号进行处理。这套系统通过三个关键步骤实现音频理解&am…...

Qwen3-VL-2B场景应用:电商识图、教育答题、办公文档处理实战
Qwen3-VL-2B场景应用:电商识图、教育答题、办公文档处理实战 1. 项目概述 Qwen3-VL-2B-Instruct是一款基于视觉语言模型(Vision-Language Model)的多模态AI服务,能够同时处理图像和文本输入,实现复杂的图文交互功能。该模型针对CPU环境进行…...