YOLOv8改进 - 注意力篇 - 引入ShuffleAttention注意力机制
一、本文介绍
作为入门性篇章,这里介绍了ShuffleAttention注意力在YOLOv8中的使用。包含ShuffleAttention原理分析,ShuffleAttention的代码、ShuffleAttention的使用方法、以及添加以后的yaml文件及运行记录。
二、ShuffleAttention原理分析
ShuffleAttention官方论文地址:文章
ShuffleAttention官方代码地址:官方代码

ShuffleAttention注意力机制:采用Shuffle单元有效地结合了两种类型的注意力机制。首先将通道维分组为多个子特征,然后再并行处理它们。然后,对于每个子特征,利用Shuffle Unit在空间和通道维度上描绘特征依赖性。之后,将所有子特征汇总在一起,并采用“channel shuffle”运算符来启用不同子特征之间的信息通信。

三、相关代码:
ShuffleAttention注意力的代码,如下。
class ShuffleAttention(nn.Module):def __init__(self, channel=512, reduction=16, G=8):super().__init__()self.G = Gself.channel = channelself.avg_pool = nn.AdaptiveAvgPool2d(1)self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))self.sigmoid = nn.Sigmoid()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)@staticmethoddef channel_shuffle(x, groups):b, c, h, w = x.shapex = x.reshape(b, groups, -1, h, w)x = x.permute(0, 2, 1, 3, 4)# flattenx = x.reshape(b, -1, h, w)return xdef forward(self, x):b, c, h, w = x.size()# group into subfeaturesx = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w# channel_splitx_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w# channel attentionx_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1x_channel = x_0 * self.sigmoid(x_channel)# spatial attentionx_spatial = self.gn(x_1) # bs*G,c//(2*G),h,wx_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,wx_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w# concatenate along channel axisout = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,wout = out.contiguous().view(b, -1, h, w)# channel shuffleout = self.channel_shuffle(out, 2)return out
四、YOLOv8中ShuffleAttention使用方法
1.YOLOv8中添加ShuffleAttention模块:
首先在ultralytics/nn/modules/conv.py最后添加ShuffleAttention模块的代码。
2.在conv.py的开头__all__ = 内添加ShuffleAttention模块的类别名:
3.在同级文件夹下的__init__.py内添加SimAM的相关内容:(分别是from .conv import ShuffleAttention ;以及在__all__内添加ShuffleAttention)
4.在ultralytics/nn/tasks.py进行ShuffleAttention注意力机制的注册,以及在YOLOv8的yaml配置文件中添加ShuffleAttention即可。
首先打开task.py文件,按住Ctrl+F,输入parse_model进行搜索。找到parse_model函数。在其最后一个else前面添加以下注册代码:
elif m in {CBAM,ECA,ShuffleAttention}:#添加注意力模块,没有CBAM、eca的,M删除即可c1, c2 = ch[f], args[0]if c2 != nc:c2 = make_divisible(min(c2, max_channels) * width, 8)args = [c1, *args[1:]]然后,就是新建一个名为YOLOv8_ShuffleAttention.yaml的配置文件:(路径:ultralytics/cfg/models/v8/YOLOv8_ShuffleAttention.yaml)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call CPAM-yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, ShuffleAttention, [1024]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
其中参数中nc,由自己的数据集决定。本文测试,采用的coco8数据集,有80个类别。
在根目录新建一个train.py文件,内容如下:
from ultralytics import YOLO
import warningswith warnings.catch_warnings():warnings.simplefilter("ignore")model = YOLO('ultralytics/cfg/models/v8/YOLOv8_ShuffleAttention.yaml') # 从YAML建立一个新模型results = model.train(data='ultralytics/cfg/datasets/coco8.yaml', epochs=1,imgsz=640,optimizer="SGD")训练输出:


五、总结
以上就是ShuffleAttention的原理及使用方式,但具体ShuffleAttention注意力机制的具体位置放哪里,效果更好。需要根据不同的数据集做相应的实验验证。希望本文能够帮助你入门YOLO中注意力机制的使用。
相关文章:
YOLOv8改进 - 注意力篇 - 引入ShuffleAttention注意力机制
一、本文介绍 作为入门性篇章,这里介绍了ShuffleAttention注意力在YOLOv8中的使用。包含ShuffleAttention原理分析,ShuffleAttention的代码、ShuffleAttention的使用方法、以及添加以后的yaml文件及运行记录。 二、ShuffleAttention原理分析 ShuffleA…...
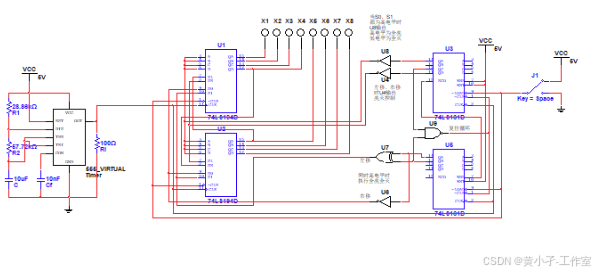
基于Multisim的8路彩灯循环控制电路设计与仿真
1)由八个彩灯LED的明暗构成各种彩灯图形; 2)彩灯依次显示的图形: 彩灯从左至右渐亮至全亮(8个CP) 彩灯从左至右渐灭至全灭(8个CP) 彩灯从右至左渐亮至全亮(8个CP) 彩灯从右至左渐灭至全灭(8个CP) 彩灯全亮(1个CP) 彩灯全灭(1个CP) 彩灯全亮(1个CP) 彩灯全灭(1个CP) 3)彩灯图形循…...

完整的模型训练套路 pytorch
**前置知识: 1、 (1).train():将模型设置为训练模式 (2).eval():将模型设置为评估模式 不写也可以(只对特定网络模型有作用,如含有Dropout的) 2、 with…...
2024年十大前沿图像分割模型汇总:工作机制、优点和缺点介绍
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...
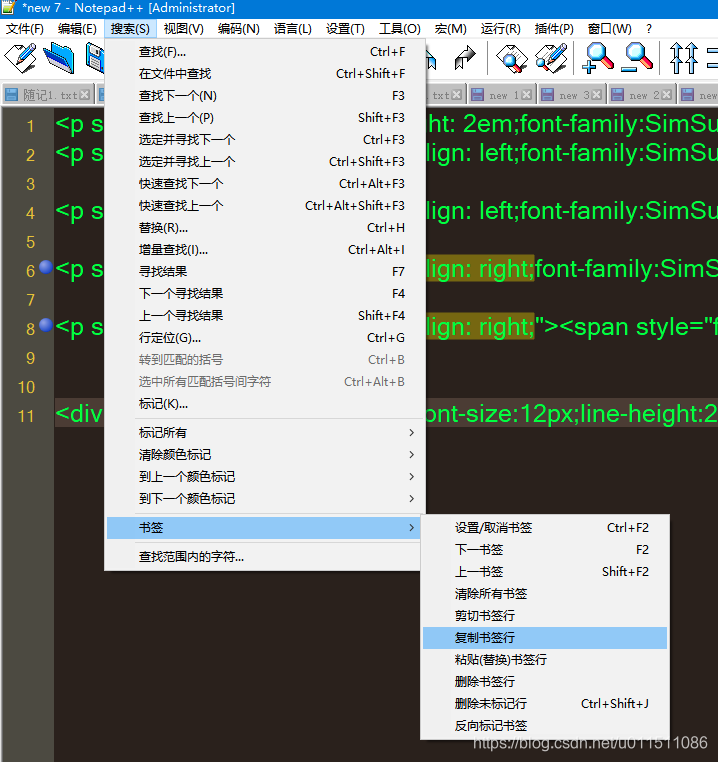
Notepad++将搜索内容所在行选中,并进行复制等操作
背景 Notepad在非常多的数据行内容中,按照指定内容检索,并定位到具体行,而后对内容行的数据进行复制、剪切、删除等处理动作。 操作说明 检索并标记所在行 弹出搜索框:按下 Ctrl F。 输入查找字符串:在搜索框中输入要…...

[Java EE] IP 协议 | NAT 机制 | 路由选择 | MAC 地址 | 域名解析服务
Author:MTingle major:人工智能 Build your hopes like a tower! 目录 一. 初识 IP 协议 IP 协议报头: 二. IP 协议如何管理地址 NAT机制 路由选择 三. 数据链路层(以太网): MAC地址 四. 域名解析系统 一. 初识 IP 协议 IP 协议工作在网络层,其目标是为了在复…...
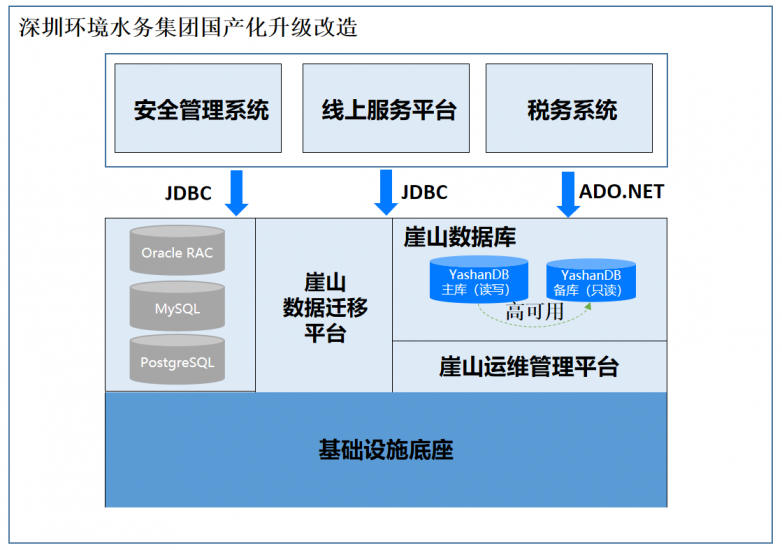
赋能特大城市水务数据安全高速运算,深圳计算科学研究院YashanDB数据库系统斩获“鼎新杯”二等奖
第三届“鼎新杯”数字化转型应用优秀案例评选结果日前正式公布,深圳计算科学研究院联合深圳市环境水务集团有限公司申报的《深圳环境水务国产数据库YashanDB,赋能特大城市水务数据安全高速运转》案例,经过5个多月的评审,从4000申报…...

RAYDATA链接PGSQL做图表
1.拖一个脚本进去 2.拖一个柱状图进去 3.双击脚本写代码 using System; using System.Collections; using System.Collections.Generic; using System.Linq; using Ventuz.Kernel; using Npgsql; using System.Threading; using System.Threading.Tasks;public class Script…...

UE5里的TObjectPtr TSharedPtr TWeakPtr有什么区别
在 Unreal Engine(UE)编程中,TObjectPtr、TSharedPtr 和 TWeakPtr 都是 指针类型,但它们在生命周期管理和使用场景上有不同的特点。让我们详细分析这些指针的区别和用途。 TObjectPtr TObjectPtr 是 UE5 中引入的新智能指针类型…...

前端--深入理解HTTP协议
HTTP 协议简介 HTTP(HyperText Transfer Protocol,超文本传输协议)是一个应用层协议,用于在客户端(通常是浏览器)和服务器之间传输超文本数据(如 HTML、CSS、JavaScript 等)。它是万…...
线性代数 向量
一、定义 几何定义:向量是一个有方向和大小的量,通常用箭头表示。向量的起点称为原点,终点称为向量的端点。 代数定义:向量是一个有序的数组,通常表示为列向量或行向量。 行向量就是 1*n的形式(行展开&…...

go中阶乘实现时递归及迭代方式的比较
package mainimport ("fmt""time""math/big" )// 使用递归和 big.Int 计算阶乘 func FactorialRecursive(n *big.Int) *big.Int {if n.Cmp(big.NewInt(0)) 0 {return big.NewInt(1)}return new(big.Int).Mul(n, FactorialRecursive(new(big.Int…...

Jupyter notebook中更改字体大小
文章目录 方法一:局部修改方法二:全局修改 Jupyter notebook提供了一个非常方便的跨平台交互代码编译环境,但是单元格的内的代码字体往往显示较小,不利于观看。本人查了很多方法来调整字体,后来发现既不需要更改jupyte…...

关于Ubuntu服务器的时间同步设置以及Linux什么时候开始使用swap虚拟内存
一、关于Ubuntu服务器的时间同步设置 首先我们检查一下服务器的时区设置和当前时间值,获取/etc/timezone 配置以及使用date命令查看当前时间。 rootiZ2ze7n2ynw18p6bs92fziZ:~# cat /etc/timezone Asia/Shanghai rootiZ2ze7n2ynw18p6bs92fziZ:~# date Wed Dec 21 …...

Java Stream API 详解
Java Stream API 详解 1. 什么是 Stream API? Stream API 是 Java 8 引入的一种用于处理集合(如数组、列表)的强大工具。它提供了一种声明性方式处理数据,可以简化代码并提高可读性。Stream 不是数据结构,它只是一种…...

一文了解大模型中的SDK和API
大白话聊SDK和API-知乎 1.智谱AI的SDK和API 以智谱AI为例,智谱AI的SDK是名为zhipuai的Python包,其中包含了用于访问API的接口(如api-key)。在这个框架中,API是SDK的一部分,用于实现与智谱AI服务的交互。 …...

element plus的el-select分页
摘要: el-select的数据比较多的时候,必须要分页,处理方案有全部数据回来,或者添加搜索功能,但是就有个问题就是编辑的时候回显问题,必须要保证select的数据有对应的id与name匹配回显! <el-fo…...

STM32CubeMX【串口收发USART】
第一步,配置cubemx 配置好点右上角生成 第二步,串口方式 阻塞式发送 英文、中文正常、浮点有口 /* Initialize all configured peripherals */MX_GPIO_Init();MX_USART1_UART_Init();//配置完自动生成的 发送到串口助手上 while (1){/* USER CODE…...

【学术会议投稿】Java Web开发实战:从零到一构建动态网站
【会后3-4个月检索|IEEE出版】第五届人工智能与计算机工程国际学术会议(ICAICE 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看: https://ais.cn/u/nuyAF3 目录 引言 一、Java Web开发基础 1. Java Web开发简介 2. 开发环境搭建 …...

[Unity]内存优化
参考: Unity 内存优化 | 新诸子Unity内存优化(来自uwa) - weigang - 博客园Unity游戏内存优化——以TileMatch为例https://github.com/wechat-miniprogram/minigame-unity-webgl-transform/blob/main/Design/OptimizationMemory.mdunity内存…...

STM32F103 + TM1628实战:如何用31个LED做一个可调亮度的简易仪表盘?
STM32F103 TM1628实战:如何用31个LED打造智能动态仪表盘 在嵌入式开发领域,将基础硬件模块转化为实用创意项目的能力,往往是区分普通开发者和资深工程师的关键。STM32F103作为经典的ARM Cortex-M3内核微控制器,以其出色的性价比和…...

第11篇 安全配置实战:SASL_SSL + SCRAM-SHA-512
第11篇:安全配置实战 —— SASL_SSL + SCRAM-SHA-512 生产落地 系列:Kafka Spring Boot:参数精讲与生产落地实战 本篇关键词:security.protocol SASL SCRAM-SHA-512 SSL TrustStore 生产安全配置 📌 本篇导读 内网开发环境用 PLAINTEXT 完全没问题。但一旦涉及: 云…...
)
YOLOv8铁轨轨道缺陷识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 针对铁轨表面缺陷自动化检测需求,本研究构建了基于YOLOv8的实时检测系统,涵盖Spalling(剥落)、Wheel Burn(车轮烧伤)、Squat(轨头压溃)和Corrugation(波浪磨耗&…...

汤姆供应链
1. 自营中泰专线渠道,泰国曼谷设有清关公司与海外仓,本地团队 24 小时响应;2. 与多家船公司签订特种柜舱位协议,旺季舱位有保障;3. 服务过机械制造、建材、跨境电商等行业客户,累计运输超 1000 票大件设备&…...

NoSleep:彻底告别电脑自动休眠的终极解决方案
NoSleep:彻底告别电脑自动休眠的终极解决方案 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否经历过这些令人沮丧的时刻?在线会议进行到关键演示…...

基于Arduino与V-USB打造低成本红外无线抢答器:从信号解码到HID模拟
1. 项目概述与核心思路拆解如果你是一位老师,或者经常组织一些需要快速抢答的互动活动,肯定对市面上那些动辄上千元的专业无线抢答系统望而却步。它们功能强大,但价格也足够“劝退”。几年前,我在为一所学校的科技节活动寻找低成本…...

研究助理/项目经理/内容编辑:Hermes Agent 3 类人格模板的 SOUL.md 配置要点
1. 三类人格不是“角色扮演”,而是上下文锚点的工程化切片 大多数人第一次看到 Hermes Agent 的 SOUL.md 配置时,会下意识把它当成一个“AI人设说明书”:研究助理要严谨、项目经理要干练、内容编辑要文雅。这种理解在小规模单次交互中勉强能用,但一旦进入真实研发流程——…...

Serverless冷启动优化全攻略:从原理到实战的性能提升方案
1. 项目概述:直面Serverless的“阿喀琉斯之踵”在Serverless架构的实践中,有一个问题几乎每个深度使用者都绕不开,那就是“冷启动”。想象一下,你精心设计的函数,在无人访问时安静地“休眠”以节省资源。当第一个请求突…...

Artisan烘焙软件终极指南:5步解决咖啡烘焙品质不稳定难题
Artisan烘焙软件终极指南:5步解决咖啡烘焙品质不稳定难题 【免费下载链接】artisan artisan: the worlds most trusted roasting software 项目地址: https://gitcode.com/gh_mirrors/ar/artisan 你是否曾为咖啡烘焙结果的不稳定性而烦恼?同一款咖…...

实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s
实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s 当Meta开源Llama3大模型的消息席卷AI社区时,一个更实际的问题浮出水面:如何让这个性能怪兽在边缘设备上真正跑起来?我们拿到搭载算丰SG2300x芯片的Radx…...