完整的模型训练套路 pytorch
**前置知识:
1、
(1).train():将模型设置为训练模式
(2).eval():将模型设置为评估模式
不写也可以(只对特定网络模型有作用,如含有Dropout的)
2、
with torch.no_grad()::主要用于评估和推理,确保不会计算梯度,从而节省内存和加速计算。
3、
.item()的作用:将tensor型转为普通数值型
当你有一个只有一个元素的张量时,可以使用 .item() 来提取这个值。
a=torch.tensor(5) print(a) #tensor(5) print((a.item())) #5
4、
如何由分类得分来计算正确率:
outputs=torch.tensor([[0.1,0.2],[0.3,0.4]
]) #两个样本的二分类得分preds=outputs.argmax(1) #1是横向对比,0是纵向对比,得到预测的分类:[1,1]targets=torch.tensor([0,1]) #正确的分类print(preds==targets) #tensor([False, True])
print((preds==targets).sum()) #tensor(1)
print((preds==targets).sum().item()/2) #正确率=分类正确的样本数/总样本数,得0.5
**代码:
import torch.optim
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom model import * #引入模型类文件一、准备数据集:
#准备数据集
train_set=torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_set=torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)train_set_size=len(train_set)
test_set_size=len(test_set)
print(f"训练数据集的长度为:{train_set_size}")
print(f"测试数据集的长度为:{test_set_size}")train_dataloader=DataLoader(train_set,batch_size=64)
test_dataloader=DataLoader(test_set,batch_size=64)二、创建网络模型:
模型类的定义单独写在一个文件夹里
import torch
from torch import nn#搭建神经网络
class Classification_CIFAR10(nn.Module):def __init__(self):super().__init__()self.model=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding="same"), #stride默认等于1,padding没有设置则是0nn.MaxPool2d(kernel_size=2), #stride默认等于kernel_size,padding没有设置则是0nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding="same"),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding="same"),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,x):x=self.model(x)return x#测试模型的正确性:设一个input,看output的尺寸是否正确
if __name__ == '__main__':model=Classification_CIFAR10()input=torch.ones((64,3,32,32))output=model(input)print(output.shape)#[ 0.0308, -0.0105, -0.0186, 0.2409, -0.0044, 0.0182, 0.1824, -0.0557, -0.1188, 0.0300]#输入:一张3通道的图像(大小为32*32)——>64通道(大小为4*4)——>全连接后linear成64通道——>最后linnear成10通道(即十个类别的得分)
#(1,3,32,32)——>(1,10)同理,(64,3,32,32)——>(64,10)#创建网络模型
model_classification=Classification_CIFAR10()三、参数和辅助工具的设置:
(损失函数,优化器;训练、测试的次数记录;tensorboard)
#损失函数
loss_func=nn.CrossEntropyLoss() #optional表示参数是可选的#优化器
learning_rate=1e-2 #相当于(0.01)
optimizer=torch.optim.SGD(model_classification.parameters(),lr=learning_rate) #随机梯度下降#设置训练网络的一些参数
total_train_step=0 #记录训练的次数
total_test_step=0 #记录测试的次数
epoch=2 #训练、测试的轮数(一轮有多次,次数=imgs总数/每次处理的图片数)#添加tensorboard来监控数据的变化
writer=SummaryWriter("E:\DLearning\Learning\logs") #路径问题,换成绝对路径试一试四、开始训练和测试:
for i in range(epoch):print(f"——————————————第{i+1}轮训练开始——————————————")#训练步骤开始for data in train_dataloader:imgs,targets=dataoutputs=model_classification(imgs)#计算损失loss=loss_func(outputs,targets)#优化optimizer.zero_grad() #梯度清零loss.backward() #计算梯度并反向传播optimizer.step() #梯度优化(跳跃式)total_train_step=total_train_step+1if total_train_step%100==0: #逢百才打印、记录(更节省、更清晰)print(f"训练次数:{total_train_step},Loss:{loss.item()}")writer.add_scalar("train_loss",loss.item(),total_train_step)#每训练完一轮后,用验证集来测试,看看训练的效果如何print(f"——————————————第{i + 1}轮测试开始——————————————")#测试步骤开始total_test_loss=0total_accuracy=0with torch.no_grad(): #不需要调优了,利用现有模型——>with里面的代码就没有了梯度,能保证不会对它进行调优(即使不调用也会累计梯度,会使进程变慢)for data in test_dataloader:imgs,targets=dataoutputs=model_classification(imgs)#求损失loss=loss_func(outputs,targets)total_test_loss+=loss.item()#求正确数(分类特有的)accuracy=(outputs.argmax(1)==targets).sum()total_accuracy+=accuracyprint(f"整体测试集的Loss:{total_test_loss}")print(f"整体测试集的正确率:{total_accuracy/test_set_size}")writer.add_scalar("test_total_loss",total_test_loss,i+1)writer.add_scalar("test_total_accuracy",total_accuracy/test_set_size,i+1)#保存每一轮的模型训练结果torch.save(model_classification,f"model{i+1}.pth")print("模型已保存")writer.close()相关文章:

完整的模型训练套路 pytorch
**前置知识: 1、 (1).train():将模型设置为训练模式 (2).eval():将模型设置为评估模式 不写也可以(只对特定网络模型有作用,如含有Dropout的) 2、 with…...
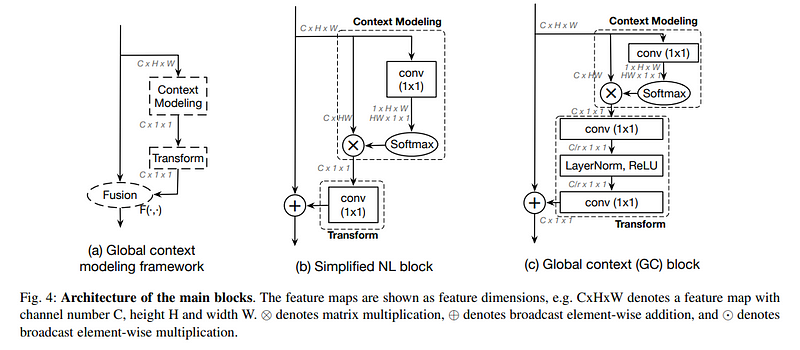
2024年十大前沿图像分割模型汇总:工作机制、优点和缺点介绍
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...
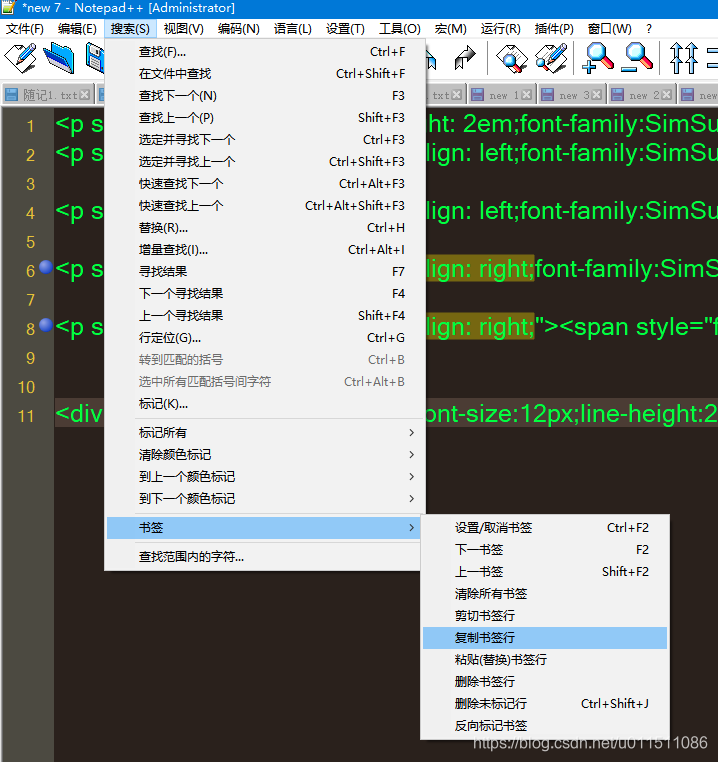
Notepad++将搜索内容所在行选中,并进行复制等操作
背景 Notepad在非常多的数据行内容中,按照指定内容检索,并定位到具体行,而后对内容行的数据进行复制、剪切、删除等处理动作。 操作说明 检索并标记所在行 弹出搜索框:按下 Ctrl F。 输入查找字符串:在搜索框中输入要…...

[Java EE] IP 协议 | NAT 机制 | 路由选择 | MAC 地址 | 域名解析服务
Author:MTingle major:人工智能 Build your hopes like a tower! 目录 一. 初识 IP 协议 IP 协议报头: 二. IP 协议如何管理地址 NAT机制 路由选择 三. 数据链路层(以太网): MAC地址 四. 域名解析系统 一. 初识 IP 协议 IP 协议工作在网络层,其目标是为了在复…...
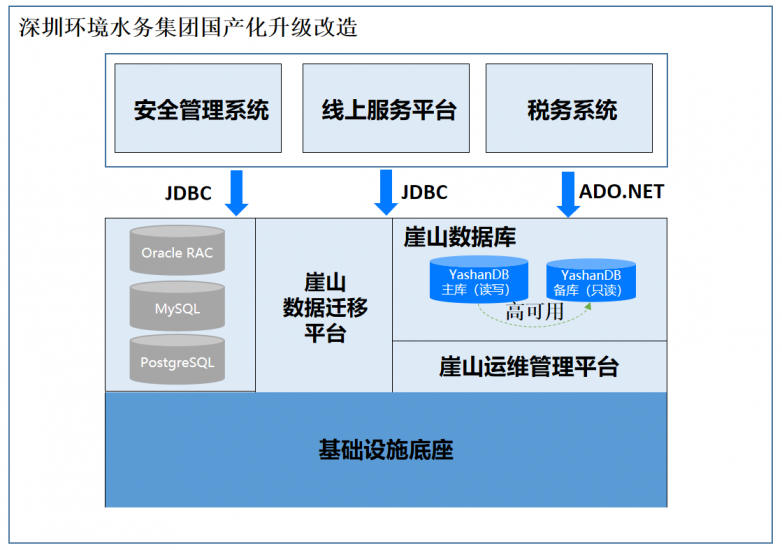
赋能特大城市水务数据安全高速运算,深圳计算科学研究院YashanDB数据库系统斩获“鼎新杯”二等奖
第三届“鼎新杯”数字化转型应用优秀案例评选结果日前正式公布,深圳计算科学研究院联合深圳市环境水务集团有限公司申报的《深圳环境水务国产数据库YashanDB,赋能特大城市水务数据安全高速运转》案例,经过5个多月的评审,从4000申报…...

RAYDATA链接PGSQL做图表
1.拖一个脚本进去 2.拖一个柱状图进去 3.双击脚本写代码 using System; using System.Collections; using System.Collections.Generic; using System.Linq; using Ventuz.Kernel; using Npgsql; using System.Threading; using System.Threading.Tasks;public class Script…...

UE5里的TObjectPtr TSharedPtr TWeakPtr有什么区别
在 Unreal Engine(UE)编程中,TObjectPtr、TSharedPtr 和 TWeakPtr 都是 指针类型,但它们在生命周期管理和使用场景上有不同的特点。让我们详细分析这些指针的区别和用途。 TObjectPtr TObjectPtr 是 UE5 中引入的新智能指针类型…...

前端--深入理解HTTP协议
HTTP 协议简介 HTTP(HyperText Transfer Protocol,超文本传输协议)是一个应用层协议,用于在客户端(通常是浏览器)和服务器之间传输超文本数据(如 HTML、CSS、JavaScript 等)。它是万…...
线性代数 向量
一、定义 几何定义:向量是一个有方向和大小的量,通常用箭头表示。向量的起点称为原点,终点称为向量的端点。 代数定义:向量是一个有序的数组,通常表示为列向量或行向量。 行向量就是 1*n的形式(行展开&…...

go中阶乘实现时递归及迭代方式的比较
package mainimport ("fmt""time""math/big" )// 使用递归和 big.Int 计算阶乘 func FactorialRecursive(n *big.Int) *big.Int {if n.Cmp(big.NewInt(0)) 0 {return big.NewInt(1)}return new(big.Int).Mul(n, FactorialRecursive(new(big.Int…...

Jupyter notebook中更改字体大小
文章目录 方法一:局部修改方法二:全局修改 Jupyter notebook提供了一个非常方便的跨平台交互代码编译环境,但是单元格的内的代码字体往往显示较小,不利于观看。本人查了很多方法来调整字体,后来发现既不需要更改jupyte…...

关于Ubuntu服务器的时间同步设置以及Linux什么时候开始使用swap虚拟内存
一、关于Ubuntu服务器的时间同步设置 首先我们检查一下服务器的时区设置和当前时间值,获取/etc/timezone 配置以及使用date命令查看当前时间。 rootiZ2ze7n2ynw18p6bs92fziZ:~# cat /etc/timezone Asia/Shanghai rootiZ2ze7n2ynw18p6bs92fziZ:~# date Wed Dec 21 …...

Java Stream API 详解
Java Stream API 详解 1. 什么是 Stream API? Stream API 是 Java 8 引入的一种用于处理集合(如数组、列表)的强大工具。它提供了一种声明性方式处理数据,可以简化代码并提高可读性。Stream 不是数据结构,它只是一种…...

一文了解大模型中的SDK和API
大白话聊SDK和API-知乎 1.智谱AI的SDK和API 以智谱AI为例,智谱AI的SDK是名为zhipuai的Python包,其中包含了用于访问API的接口(如api-key)。在这个框架中,API是SDK的一部分,用于实现与智谱AI服务的交互。 …...

element plus的el-select分页
摘要: el-select的数据比较多的时候,必须要分页,处理方案有全部数据回来,或者添加搜索功能,但是就有个问题就是编辑的时候回显问题,必须要保证select的数据有对应的id与name匹配回显! <el-fo…...

STM32CubeMX【串口收发USART】
第一步,配置cubemx 配置好点右上角生成 第二步,串口方式 阻塞式发送 英文、中文正常、浮点有口 /* Initialize all configured peripherals */MX_GPIO_Init();MX_USART1_UART_Init();//配置完自动生成的 发送到串口助手上 while (1){/* USER CODE…...

【学术会议投稿】Java Web开发实战:从零到一构建动态网站
【会后3-4个月检索|IEEE出版】第五届人工智能与计算机工程国际学术会议(ICAICE 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看: https://ais.cn/u/nuyAF3 目录 引言 一、Java Web开发基础 1. Java Web开发简介 2. 开发环境搭建 …...

[Unity]内存优化
参考: Unity 内存优化 | 新诸子Unity内存优化(来自uwa) - weigang - 博客园Unity游戏内存优化——以TileMatch为例https://github.com/wechat-miniprogram/minigame-unity-webgl-transform/blob/main/Design/OptimizationMemory.mdunity内存…...

FreeRTOS工程创建,创建多任务程序,基于汇编对ARM架构的简单理解
FreeRTOS工程创建 下载STM32CubeMX尽量找网盘下载(只是建议,没有说官网不行) 1.创建 STM32CubeMX 工程 (1)双击运行 STM32CubeMX,在首页面选择“Access to MCU Selector”,如下图所示࿱…...

C++STL--------list
文章目录 一、list链表的使用1、迭代器2、头插、头删3、insert任意位置插入4、erase任意位置删除5、push_back 和 pop_back()6、emplace_back尾插7、swap交换链表8、reverse逆置9、merge归并10、unique去重11、remove删除指定的值12、splice把一个链表的结点转移个另一个链表13…...

第11篇 安全配置实战:SASL_SSL + SCRAM-SHA-512
第11篇:安全配置实战 —— SASL_SSL + SCRAM-SHA-512 生产落地 系列:Kafka Spring Boot:参数精讲与生产落地实战 本篇关键词:security.protocol SASL SCRAM-SHA-512 SSL TrustStore 生产安全配置 📌 本篇导读 内网开发环境用 PLAINTEXT 完全没问题。但一旦涉及: 云…...

保姆级教程:解决PyTorchViz安装报错,手把手教你用AlexNet模型可视化
PyTorch模型可视化实战:从安装报错到AlexNet结构解析全指南 在深度学习模型开发过程中,可视化工具如同开发者的"第二双眼睛"。PyTorchViz作为PyTorch生态中轻量级但功能强大的可视化工具,能直观展示模型的计算图结构,帮…...

城市生活垃圾焚烧过程参数的智能自主设定方法【附程序】
✨ 长期致力于城市生活垃圾、焚烧过程、智能自主、参数设定、设定方法软件研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于学习型伪度量方法的焚烧…...

如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南
如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾面对电脑里杂乱无章的图片库感到束…...

主从结合,安全互联:Anybus工业通信解决方案全栈升级
HMS亮相2026 PROFINET技术路演杭州站,展出全新Anybus SoM及全栈PROFINET方案,助力设备商应对CRA与机械法规双重合规挑战。 5月14日,由PI China主办的2026 PROFINET技术路演(杭州站)在西玥酒店圆满举行。HMS华东区OEM销…...

告别玄学调试:用示波器‘看透’开关电源的十大常见故障波形
告别玄学调试:用示波器‘看透’开关电源的十大常见故障波形 实验室里,工程师们常把开关电源调试戏称为"玄学"——参数微调、元件更换、反复试错,往往耗费数小时仍找不到问题根源。这种低效的调试方式即将成为历史。本文将彻底改变你…...
与独立HSM如何协作)
从芯片到系统:手把手拆解汽车MCU里的安全硬件(SHE/HSE)与独立HSM如何协作
汽车MCU安全架构实战:SHE/HSE与独立HSM的协同设计指南 当一辆现代汽车启动时,从车门解锁到发动机控制,超过1亿行代码在数百个微控制器(MCU)上同时运行。这些代码中包含着价值连城的数字资产——车主的生物特征数据、自…...
)
【JPCS出版、EI检索稳定】2026年航空航天工程与空天信息国际学术会议(ICAEAI 2026)
2026年航空航天工程与空天信息国际学术会议(ICAEAI 2026)将于2026年6月26-28日在哈尔滨召开。会议旨在为从事航空航天工程与空天信息领域研究的专家学者、工程技术人员、技术研发人员提供一个共享科研成果和前沿技术,加强学术研究和探讨&…...

XNBCLI终极指南:如何轻松解包打包星露谷物语XNB文件
XNBCLI终极指南:如何轻松解包打包星露谷物语XNB文件 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli 想要深度定制星露谷物语游戏体验吗?…...

Ahk2Exe:3步实现AutoHotkey脚本到EXE的专业编译方案
Ahk2Exe:3步实现AutoHotkey脚本到EXE的专业编译方案 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe Ahk2Exe是AutoHotkey官方推出的脚本编译器&#x…...