基于Python的自然语言处理系列(39):Huggingface中的解码策略

在自然语言生成任务中,如何选择下一步的单词或者词语对生成的文本质量影响巨大。Huggingface 提供了多种解码策略,可以在不同的场景下平衡流畅度、创造力以及生成效率。在这篇文章中,我们将逐步介绍 Huggingface 中的几种常见解码策略,包括贪婪搜索、Beam Search(束搜索)、采样、Top-K 采样以及 Top-p(核采样)。通过具体代码示例,我们将对比这些策略的效果,并讨论它们在实际应用中的利弊。
加载GPT-2模型
我们首先加载 GPT-2 模型和对应的分词器。为了避免警告信息,我们将 EOS(End of Sequence,序列结束符)设置为 PAD(填充符)。
from transformers import GPT2LMHeadModel, GPT2Tokenizertokenizer = GPT2Tokenizer.from_pretrained("gpt2")# 将 EOS token 设置为 PAD token
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
贪婪搜索(Greedy Search)
贪婪搜索是一种最简单的解码方法。在每一步,贪婪搜索直接选择具有最高概率的下一个词语,直到达到设定的最大长度。这种策略虽然简单高效,但往往会导致模型重复生成相同的词组。
让我们通过 GPT-2 模型来生成一段文本,给定的上下文是 I enjoy walking with my cute dog。
# 编码输入
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='pt')# 使用贪婪搜索生成文本,最大长度设为50
greedy_output = model.generate(input_ids, max_length=50)print("输出:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
虽然生成的文本看似合理,但贪婪搜索容易出现重复生成的情况。这个问题在对话生成、故事生成等开放式任务中尤为突出。
Beam Search(束搜索)
Beam Search 能够缓解贪婪搜索的局限性,通过在每个时间步跟踪 num_beams 个最有可能的候选词序列,直到所有序列都到达 EOS 标记为止。这种方法比贪婪搜索更有可能找到更优的词序列。
# 激活束搜索,设定 beam 数量为 5
beam_output = model.generate(input_ids, max_length=50, num_beams=5, early_stopping=True
)print("输出:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
尽管 Beam Search 生成的文本更连贯,但它仍然可能出现重复现象。为了进一步提升生成质量,我们可以通过引入 n-gram 惩罚机制来减少重复的出现。
# 设置 no_repeat_ngram_size 参数为 2,避免重复生成二元组
beam_output = model.generate(input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, early_stopping=True
)print("输出:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
我们还可以通过设置 num_return_sequences 参数,生成多个不同的候选序列。
# 生成多个候选序列
beam_outputs = model.generate(input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, num_return_sequences=3, early_stopping=True
)print("输出:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):print(f"{i}: {tokenizer.decode(beam_output, skip_special_tokens=True)}")
虽然 Beam Search 能够生成更连贯的文本,但在开放式生成任务中,它的表现往往不如其他解码方法。
采样(Sampling)
采样策略不再像贪婪搜索或束搜索那样总是选择概率最高的词语,而是从词汇表中根据每个词的概率随机选取下一个词。采样的多样性较高,但可能会生成不连贯的句子。
import torchtorch.manual_seed(0)# 激活采样,关闭 Top-K 采样
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=0
)print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
由于采样的随机性,生成的文本可能会包含一些不连贯或不自然的句子。我们可以通过调整 temperature 参数来让生成更加连贯。
# 使用 temperature 减少不合理单词的生成
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=0, temperature=0.7
)print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Top-K 采样
Top-K 采样是采样的改进版,它限制每次采样只从 K 个概率最高的单词中选择,能够有效避免生成一些低概率的单词。
# 设置 top_k 为 50
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=50
)print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Top-p 采样(核采样)
Top-p 采样根据概率阈值 p 选择最小数量的词汇,使其累积概率超过 p,然后在这些词中进行采样。这种动态的选择方法更具弹性,能够适应不同的词汇分布。
# 设置 top_p 为 0.92
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_p=0.92, top_k=0
)print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
最后,我们还可以结合 Top-K 和 Top-p 采样,生成多个候选序列。
# 结合 top_k 和 top_p 并生成多个候选序列
sample_outputs = model.generate(input_ids,do_sample=True, max_length=50, top_k=50, top_p=0.95, num_return_sequences=3
)print("输出:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):print(f"{i}: {tokenizer.decode(sample_output, skip_special_tokens=True)}")
结语
通过这篇文章,我们深入了解了 Huggingface 提供的各种解码策略。从最简单的贪婪搜索到更为复杂的 Top-K 和 Top-p 采样,每种方法在不同的场景下都有其独特的优势。贪婪搜索和束搜索在生成固定长度输出的任务中表现较好,而 Top-p 和 Top-K 采样在开放式生成任务(如对话和故事生成)中更具表现力。根据具体应用场景选择合适的解码策略,能够显著提升文本生成的质量。
如果你觉得这篇博文对你有帮助,请点赞、收藏、关注我,并且可以打赏支持我!
欢迎关注我的后续博文,我将分享更多关于人工智能、自然语言处理和计算机视觉的精彩内容。
谢谢大家的支持!
相关文章:
基于Python的自然语言处理系列(39):Huggingface中的解码策略
在自然语言生成任务中,如何选择下一步的单词或者词语对生成的文本质量影响巨大。Huggingface 提供了多种解码策略,可以在不同的场景下平衡流畅度、创造力以及生成效率。在这篇文章中,我们将逐步介绍 Huggingface 中的几种常见解码策略&#x…...
如何将视频格式转为mp4?好好看看下面这几个方法
如何将视频格式转为mp4?在数字化时代,视频已成为信息传播与娱乐消遣的重要载体。无论是学习、工作还是日常生活,我们几乎每天都会接触到各式各样的视频内容。然而,不同设备、平台或软件生成的视频文件往往采用不同的编码格式&…...

景区智慧公厕系统,监测公厕异味,自动清洁除臭
随着旅游业的快速发展,景区的公共厕所管理成为提升游客体验的重要环节。传统的公厕管理方式存在诸多不足,如卫生条件差、异味严重等问题。为了改善这些问题,许多景区开始采用智慧公厕系统。这种系统能够实时监测公厕内的异味,并自…...

GitLab CVE-2024-6389、CVE-2024-4472 漏洞解决方案
极狐GitLab 近日发布安全补丁版本17.3.2, 17.2.5, 17.1.7,修复了17个安全漏洞,本分分享其中两个漏洞 CVE-2024-6389、CVE-2024-4472 两个漏洞详情及解决方案。 极狐GitLab 正式推出面向 GitLab 老旧版本免费用户的专业升级服务,为 GitLab 老…...

hashCode的底层原理
HashCode是计算机科学中一个广泛使用的概念,特别是在Java等编程语言中,它扮演着重要的角色。为了详细解释hashCode的底层原理,以下从几个方面进行阐述: 一、hashCode的基本概念 HashCode,即哈希码,是一个将…...

hadoop_hdfs详解
HDFS秒懂 HDFS定义HDFS优缺点优点缺点 HDFS组成架构NameNodeDataNodeSecondary NameNodeClient NameNode工作机制元数据的存储启动流程工作流程 Secondary NameNode工作机制checkpoint工作流程 DataNode工作机制工作流程数据完整性 文件块大小块太小的缺点块太大的缺点 文件写入…...

【Linux】Linux命令行与环境变量
1.命令行 前⾯写C语⾔时,很少关注过 main 函数的参数,也没有考虑过 main 为什么会有参 数。 实际上在C语⾔中, main 函数⼀共有三个参数,在命令⾏部分先关注前两个参数: 1. argc:表示 main 函数接收到参…...

改变函数调用上下文:apply与call方法详解及实例
目录 改变函数调用上下文:apply与call方法详解及实例 一、什么是 apply 方法? 1、apply 语法 2、apply 示例 二、什么是 call 方法? 1、call 语法 2、call 示例 三、apply 和 call 的共同与差异 1、apply 和 call 的共同点 2、apply…...

k8s中的微服务
一、什么是微服务 用控制器来完成集群的工作负载,那么应用如何暴漏出去?需要通过微服务暴漏出去后才能被访问 Service是一组提供相同服务的Pod对外开放的接口。 借助Service,应用可以实现服务发现和负载均衡。 service默认只支持4层负载均…...
树莓派--AI视觉小车智能机器人--1.树莓派系统烧入及WiFi设置并进入jupyterlab
一、Raspberry Pi 系统烧入 使用树莓派,我们是需要有操作系统的。默认情况下,树莓派会在插入的SD卡上查找操作系统。这需要一台电脑将存储设备映像为引导设备,并将存储设备插入该电脑。大多数树莓派用户选择microSD卡作为引导设备。 1.1 下载…...
MacOS安装BurpSuite
文章目录 一、下载地址二、下载注册机三、安装教程四、启动burpsuit五、免责声明 一、下载地址 https://portswigger-cdn.net/burp/releases/download?productpro&version2024.7.1&typeMacOsx二、下载注册机 https://github.com/NepoloHebo/BurpSuite-BurpLoaderKey…...

【AI工具大全】《史上最全的AI工具合集》
一.AI编程类工具 1.CodeArts Snap CodeArts Snap是华为云研发的智能开发助手,覆盖软件开发全生命周期,提供代码生成、研发知识问答、智能协同等功能。通过自然语言编程,它能自动生成代码、解释代码逻辑、提供调试与检查,提升开发效率和软件质量。 2.ModelArts ModelArt…...

qt继承结构
一、 继承结构 所有的窗口类均继承自QWidget类,因此QWidget类本身包含窗口的特性。QWidget对象本身既可以作为独立窗口,又可以作为组件(子窗口)。 通过构造函数可以创建以上两种形态的QWidget: // 参数1:使…...
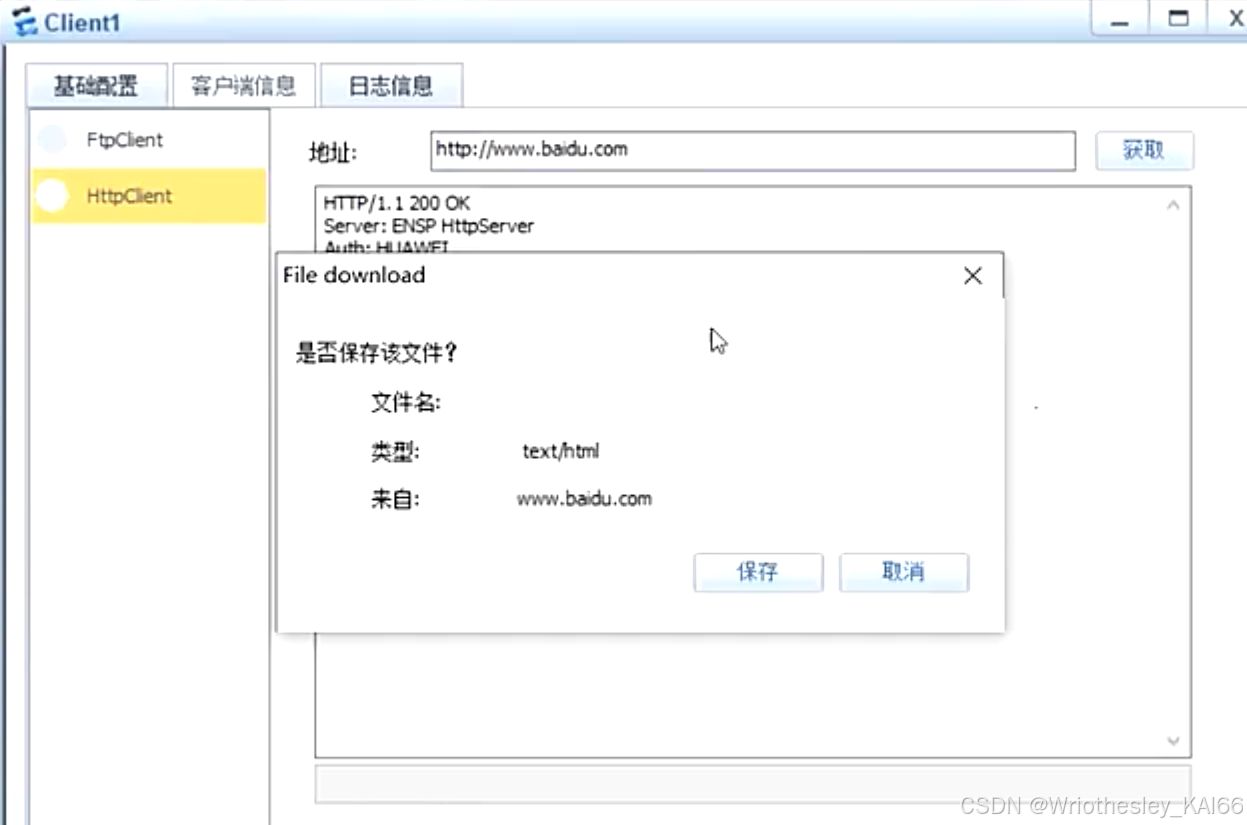
【HCIA复习作业】综合拓扑实验(已施工完)
一、实验要求 1.学校内部的HTTP客户端可以正常通过域名www.baidu.com访问到百度网络中的HTTP服务器 2.学校网络内部网段基于192.168.1.0/24划分,PC1可以正常访问3.3.3.0/24网段,但是Pc2不允许 3.学校内部路由使用静态路由,R1和R2之间两条链路…...

网络基础知识:交换机关键知识解析
了解交换机的关键知识对网络工程师至关重要。 以下是交换机的基础知识解析,包括其基本概念、工作原理和关键技术点: 01-交换机的基本概念 交换机是一种网络设备,用于在局域网(LAN)中连接多个设备,如计算机…...
基于System.js的微前端实现(插件化)
目录 写在前面 一、微前端相关知识 (一)概念 (二) 优势 (三) 缺点 (四)应用场景 (五)现有框架 1. qiankun 2. single-spa 3. SystemJ…...

MedSAM2调试安装与使用记录
目录 前言一、环境准备多版本cuda切换切换cuda版本二 安装CUDNN2.1 检查cudnn 二、使用步骤1.安装虚拟环境2.测试Gradio3.推理 总结 前言 我们在解读完MedSAM之后,迫不及待想尝尝这个技术带来的福音,因此验证下是否真的那么6。这不,新鲜的使…...

Linux 进程终止和进程等待
目录 0.前言 1. 进程终止 1.1 进程退出的场景 1.2 进程常见退出方法 1.2.1 正常退出 1.2.2 异常退出 2. 进程等待 2.1 进程等待的重要性 2.2 进程等待的方法 2.2.1 wait() 方法 2.2.2 waitpid() 方法 2.3 获取子进程 status 2.4 阻塞等待和非阻塞等待 2.4.1 阻塞等待 2.4.2 非阻…...
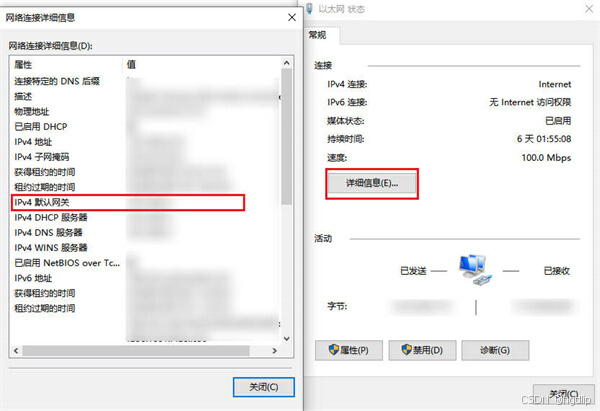
如何查看默认网关地址:详细步骤
在日常的网络配置与故障排查中,了解并正确查看默认网关地址是一项基础且至关重要的技能。默认网关是连接本地网络与外部网络(如互联网)的关键节点,它扮演着数据包转发的重要角色。无论是家庭网络、办公室网络还是更复杂的网络环境…...

什么是方法的返回值?方法有哪几种类型?静态方法为什么不能调用非静态成员?静态方法和实例方法有何不同?
什么是方法的返回值?方法有哪几种类型? 方法的返回值 是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用是接收出结果,使得它可以用于其他的操作! 我们可以…...

离子阱量子计算机与SIMD编译优化技术解析
1. 离子阱量子计算机与SIMD的奇妙结合在量子计算领域,离子阱系统因其独特的物理特性而备受关注。与传统超导量子比特不同,离子阱量子计算机通过电磁场将带电原子(通常是镱或钙离子)悬浮在真空中,利用激光操控这些离子的…...

ARMv9 CPYEN指令:内存拷贝优化技术详解
1. ARM内存拷贝指令CPYEN深度解析 在ARMv9架构中,内存拷贝操作通过专门的硬件指令得到了显著优化。CPYEN指令作为FEAT_MOPS特性的一部分,采用创新的三阶段流水线设计来提升数据传输效率。对于需要频繁处理内存块操作的系统开发者来说,理解这条…...

ARM指令集架构与安全指令解析:APAS、ASR与AUT
1. ARM指令集架构概述在处理器设计领域,指令集架构(Instruction Set Architecture, ISA)定义了处理器与软件之间的契约。作为RISC(精简指令集计算机)架构的代表,ARM指令集以其高效能和低功耗特性࿰…...

Talkyard管理员入门:10个必备设置打造完美的社区环境
Talkyard管理员入门:10个必备设置打造完美的社区环境 【免费下载链接】talkyard A community discussion platform: Brings together the main features from StackOverflow, Slack, Discourse, Reddit, and Disqus blog comments. 项目地址: https://gitcode.com…...

SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅
SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾想过,一张普通的图片如何能变成一个会思考、会对话、…...

2026年AI工程化的5大发展趋势:从模型到产品的必经之路
2026年AI工程化的5大发展趋势:从模型到产品的必经之路 导读: AI模型越来越强大,但如何将其稳定、高效地部署到生产环境?本文结合我过去3年的MLOps实战经验,深度剖析2026年AI工程化的核心趋势,助你从“会调参…...
并优化代码)
别再为OpenMV串口传图卡顿发愁了!手把手教你选对硬件(STM32 SWD vs TTL)并优化代码
OpenMV串口传图性能优化实战:从硬件选型到代码调优 当你在实验室调试OpenMV串口传图项目时,是否经历过这样的场景:图像传输像老式拨号上网一样缓慢,帧率低得让人怀疑人生,调试界面卡成PPT?这背后往往隐藏着…...

别再手动折腾了!用Docker Compose 5分钟搞定Kamailio + MySQL + RTPproxy完整SIP服务栈
5分钟极速搭建Kamailio SIP服务栈:Docker Compose实战指南 在VoIP开发领域,快速搭建可靠的SIP服务环境是每个开发者都会遇到的基础需求。传统的手动部署方式往往需要数小时甚至更长时间,涉及复杂的依赖安装、配置文件修改和服务调优。而今天&…...

告别手动标注!R语言ggplot2+ggannotate高效绘制组间差异柱状图保姆级教程
R语言科研绘图革命:ggplot2ggannotate自动化差异标注全攻略 科研图表的美观程度直接影响论文的第一印象,而统计显著性标注更是数据可视化的灵魂所在。传统手动添加p值和星号的方式不仅效率低下,还容易出错——标注位置偏移、字体大小不一、连…...

别再手动写上传了!用Layui Upload组件+PHP后端,10分钟搞定带进度条的文件上传功能
10分钟极速集成:Layui UploadPHP打造高体验文件上传模块 每次看到项目里又需要实现文件上传功能时,你是不是已经开始头疼那些重复的代码和调试过程?从进度条显示到文件类型校验,再到后端安全处理,每个环节都可能藏着意…...