Spark动态资源释放机制 详解
Apache Spark 是一个分布式数据处理框架,其动态资源分配(或称为动态资源释放)机制,是为了更高效地利用集群资源,尤其是在执行具有不同工作负载的作业时。Spark 的动态资源释放机制允许它根据作业的需求自动分配和释放集群资源,从而提高资源利用率,降低空闲资源占用时间。
1. Spark 动态资源分配概述
动态资源分配(Dynamic Resource Allocation, DRA)机制主要解决以下问题:
- 资源浪费:在传统的静态分配模式中,Spark 作业启动时会为其分配固定数量的执行器(Executor),即使任务执行过程中部分执行器处于空闲状态,这些资源也不会被释放。
- 作业负载波动:Spark 作业的负载可能随时间变化,不同阶段所需资源不同,动态资源分配允许作业根据任务负载的变化自动调整资源数量。
Spark 通过动态调整**执行器(Executor)**的数量,根据作业的负载来增加或减少资源。核心目标是:
- 自动扩展资源:当作业需要更多资源时,可以动态增加执行器。
- 释放空闲资源:当作业不再需要过多的资源时,自动释放空闲的执行器以减少资源占用。
2. Spark 动态资源分配的触发条件
Spark 的动态资源释放机制主要根据两个方面触发:
- 作业的负载:如果作业在运行过程中,发现有更多的任务需要执行,但当前的执行器数量不足,那么 Spark 可以请求新的执行器。
- 执行器的空闲状态:如果发现某些执行器长时间处于空闲状态(没有任务运行),Spark 可以将这些执行器释放掉,归还集群资源。
具体地,Spark 会监控每个执行器的任务分配和运行状态,并根据以下参数做出资源释放或扩展的决定:
spark.dynamicAllocation.enabled:启用或禁用动态资源分配机制。spark.dynamicAllocation.minExecutors:设置最小执行器数量,即使资源空闲,Spark 也不会低于这个数量。spark.dynamicAllocation.maxExecutors:设置最大执行器数量,限制作业可以使用的资源上限。spark.dynamicAllocation.executorIdleTimeout:执行器空闲的最大时间,超过该时间后将被释放。
3. 底层原理
Spark 的动态资源释放机制依赖于集群管理器(如 YARN、Kubernetes、Mesos)以及 Spark 自身的调度逻辑来实现资源的动态增减。其核心思想是通过监控任务的状态和资源使用情况,决定是否需要增加或者减少执行器。
3.1 动态资源分配的组件
以下是动态资源分配机制涉及的关键组件:
-
ExecutorAllocationManager:这是 Spark 动态资源分配的核心管理类,负责监控执行器的任务负载,决定是否要扩展或释放执行器。 -
ClusterManager:这是 Spark 的集群管理层,如 YARN 或 Kubernetes,负责实际的资源分配和管理。ExecutorAllocationManager向集群管理器请求资源,集群管理器则实际分配或释放执行器。 -
TaskSchedulerImpl:任务调度器,用于调度任务给执行器,并与ExecutorAllocationManager协作,判断当前的资源使用状况。 -
BlockManager:负责 Spark 的存储管理,缓存数据块(RDD partitions 等),影响执行器是否可以释放。
3.2 执行器动态扩展的原理
-
任务提交与资源不足检测:
- 当一个 Spark 作业开始执行时,
ExecutorAllocationManager会根据当前待执行的任务数量和现有执行器的任务处理能力,判断是否需要更多执行器。 - 如果发现待执行的任务远多于当前执行器能够处理的任务,
ExecutorAllocationManager就会向集群管理器(如 YARN 或 Kubernetes)请求更多的执行器。
- 当一个 Spark 作业开始执行时,
-
扩展执行器:
ExecutorAllocationManager通过TaskSchedulerImpl检查当前的任务负载。- 它会根据
spark.dynamicAllocation.initialExecutors参数指定的初始执行器数量和当前任务队列长度,计算需要的执行器数量。 - 然后向集群管理器发起请求,增加执行器数量,直到达到
spark.dynamicAllocation.maxExecutors限制的最大值。
class ExecutorAllocationManager(scheduler: TaskSchedulerImpl) {def schedule(): Unit = {// 根据任务负载计算需要的执行器数量val numExecutorsNeeded = computeNumExecutorsNeeded()if (numExecutorsNeeded > currentExecutors) {// 请求集群管理器分配更多执行器requestExecutors(numExecutorsNeeded - currentExecutors)}}
}
3.执行器分配与任务调度:
1. 集群管理器响应后,分配新的执行器,并将它们添加到集群中。
2. 新的执行器加入后,TaskSchedulerImpl 会为其分配待处理的任务,新的任务开始执行。
3.3 执行器动态释放的原理
-
监控空闲执行器:
ExecutorAllocationManager也会持续监控执行器的使用情况,判断执行器是否空闲。每个执行器的状态(空闲或繁忙)会定期被更新。- 如果某个执行器超过
spark.dynamicAllocation.executorIdleTimeout的空闲时间(默认为 60 秒),并且集群中运行的执行器数量大于spark.dynamicAllocation.minExecutors,则该执行器会被标记为可释放状态。
-
释放执行器:
- 一旦发现执行器空闲时间超时,
ExecutorAllocationManager会通知集群管理器释放这些空闲的执行器。 - 在执行器释放之前,
BlockManager会确保该执行器上没有需要保留的缓存数据。如果缓存的数据重要(如被其他执行器所依赖),它会将这些数据复制到其他执行器上。
- 一旦发现执行器空闲时间超时,
class ExecutorAllocationManager(scheduler: TaskSchedulerImpl) {def schedule(): Unit = {val idleExecutors = getIdleExecutors()if (idleExecutors.nonEmpty) {// 如果有空闲的执行器,且空闲时间超过阈值,则释放这些执行器removeExecutors(idleExecutors)}}
}
3.任务完成后的资源释放:
1.当 Spark 作业进入尾声,待执行的任务逐渐减少,执行器处于空闲状态。
2.ExecutorAllocationManager 会根据 spark.dynamicAllocation.executorIdleTimeout 来判断哪些执行器可以释放,并逐步将这些空闲执行器释放回集群管理器,从而避免浪费资源。
4. 源码解析:ExecutorAllocationManager 的工作流程
ExecutorAllocationManager 是 Spark 动态资源分配的核心类。它通过定期检查任务队列和执行器状态来判断是否需要扩展或释放资源。其主要逻辑分为两个部分:执行器扩展和执行器释放。
4.1 执行器扩展逻辑
扩展逻辑通过 schedule() 方法进行资源检查和调整。它会定期运行,检查是否有新的任务提交,如果有未分配的任务,且当前的执行器数量不足以处理这些任务,就会请求新的执行器:
private def schedule(): Unit = {// 计算需要的执行器数量val numExecutorsNeeded = computeNumExecutorsNeeded()if (numExecutorsNeeded > currentExecutors) {// 请求新的执行器requestExecutors(numExecutorsNeeded - currentExecutors)}
}
4.2 执行器释放逻辑
释放逻辑通过 schedule() 方法中的 removeExecutors() 进行资源释放。在每次调度周期内,ExecutorAllocationManager 会检查哪些执行器处于空闲状态,并判断它们是否可以被释放。
private def removeExecutors(executors: Seq[String]): Unit = {for (executor <- executors) {if (canBeRemoved(executor)) {// 通知集群管理器释放执行器releaseExecutor(executor)}}
}
4.3 主要调度参数与其作用
spark.dynamicAllocation.enabled:是否启用动态资源分配。spark.dynamicAllocation.minExecutors:最小执行器数量。spark.dynamicAllocation.maxExecutors:最大执行器数量。spark.dynamicAllocation.executorIdleTimeout:执行器空闲时间,超过该时间的空闲执行器会被释放。
5. 总结
Spark 的动态资源释放机制旨在提高资源利用效率,避免资源浪费。它通过以下步骤实现:
- 执行器动态扩展:根据任务负载,自动增加执行器。
- 执行器动态释放:当执行器空闲时自动释放,减少资源占用。
- 与集群管理器的协同工作:Spark 的资源扩展和释放都依赖于集群管理器(如 YARN 或 Kubernetes)来实现实际的资源管理。
通过 ExecutorAllocationManager 和集群管理器的紧密协作,Spark 动态资源分配机制能有效地调度资源,保证作业执行的同时,最大限度地节省资源。
相关文章:

Spark动态资源释放机制 详解
Apache Spark 是一个分布式数据处理框架,其动态资源分配(或称为动态资源释放)机制,是为了更高效地利用集群资源,尤其是在执行具有不同工作负载的作业时。Spark 的动态资源释放机制允许它根据作业的需求自动分配和释放集…...
基于径向基神经网络(RBF)的构网型VSG自适应惯量控制MATLAB仿真模型
微❤关注“电气仔推送”获得资料(专享优惠) 模型简介 逆变器虚拟同步发电机控制和核心控制参数就是虚拟惯量与虚拟阻尼,目前的文献中已有众多论文对VSG的虚拟参数展开了研究,但是百分之90都是采用构造函数的方法,使用…...

简单汇编教程9 字符串与字符串指令
目录 字符串的指令 movs 字符串传送 lods, stos使用 cmpsb的使用 SCASB的使用 字符串你很熟悉了,我们定义了无数次了! %macro ANNOUNCE_STRING 2%1 db %2%1_LEN equ $ - %1 %endmacro 当然,我们现在来学习一个比较新的定义方式…...

Taro构建的H5页面路由切换返回上一页存在白屏页面过渡
目录 项目背景:Taro与Hybrid开发问题描述:白屏现象可能的原因包括: 解决方案解决后的效果图 其他优化方案可参考: 项目背景:Taro与Hybrid开发 项目使用Taro框架同时开发微信小程序和H5页面,其中H5页面被嵌…...

【学习笔记】网络设备(华为交换机)基础知识 9 —— 堆叠配置
提示:学习华为交换机堆叠配置,含堆叠的概念、功能、角色、ID和优先级;堆叠的建立过程以及注意事项;包含堆叠的配置命令,以及堆叠的配置案例 一、前期准备 1.已经可以正常访问交换机的命令行接口 Console口本地访问教…...

jeston编译配置cuda加速版opencv
1.源码下载连接 opencv:Releases - OpenCV opencv-contrib: https://github.com/opencv/opencv_contrib 建议不要下最新版本 一般我会下4.5.4 // 4.5.6 // 4.6.0 opencv和opencv-contrib版本要对齐 将下好的opencv和opencv-contrib解压 将opencv-c…...
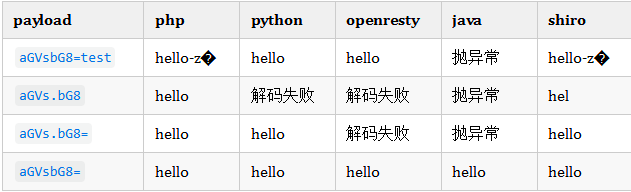
ApacheShiro反序列化 550 721漏洞
Apache Shiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理个漏洞被称为 Shiro550 是因为在Apache Shiro的GitHub问题跟踪器中,该漏洞最初被标记为第550个问题,721漏洞名称也是由此而来 Shiro-550 CVE-2016-4437 Shiro反序列化Docker复现 …...
Github + 自定义域名搭建个人静态站点
Github 自定义域名搭建个人静态站点 使用 Github 部署一个自己的免费站点给你的站点添加上自定义域名 本文基于腾讯云基于二级域名, 作用于 Github 实现自定义域名站点 使用 Github 部署一个自己的免费站点 首先你得有一个 Github 账号, 没有就去注册一个,网上有教程,本文跳…...

使用OpenCV进行视频边缘检测:案例Python版江南style
1. 引言 本文将演示如何使用OpenCV库对视频中的每一帧进行边缘检测,并将结果保存为新的视频文件。边缘检测是一种图像处理技术,它可以帮助我们识别出图像中不同区域之间的边界。在计算机视觉领域,这项技术有着广泛的应用,比如物体…...

DataWhale10月动手实践——Bot应用开发task04学习笔记
一、图像流 1. 什么是图像流? 图像流是一种直观的图像处理流程工具,用户可以灵活组合各类图像处理模块。该系统将不同的图像处理工具模块化,并通过可视化界面,将这些模块以拖拽方式组合,构建完整的处理流程。用户可以…...

关于 IntelliJ IDEA 2024 安装使用
补丁文件...

React是如何工作的?
从编写组件到最后屏幕生成界面,如上图所示,我们现在需要知道的就是后面几步是如何运行的。 概述 这张图解释了 React 渲染过程的几个阶段: 渲染触发:通过更新某处的状态来触发渲染。渲染阶段:React 调用组件函数&…...

llama.cpp 去掉打印,只显示推理结果
llama.cpp 去掉打印,只显示推理结果 1 llama.cpp/common/log.h #define LOG_INF(...) LOG_TMPL(GGML_LOG_LEVEL_INFO, 0, __VA_ARGS__) #define LOG_WRN(...) LOG_TMPL(GGML_LOG_LEVEL_WARN, 0, __VA_ARGS__) #define LOG_ERR(…...

Word、PDF转换为图片Java
Word、PDF转换为图片Java 需求要在小程序端展示文档内容,所以将文档每页转换为图片后显示 参考和其他等方案: https://blog.csdn.net/strggle_bin/article/details/140599514 https://www.modb.pro/db/566986 https://blog.csdn.net/spring_is_comin…...
iOS IPA上传到App Store Connect的三种方案详解
引言 在iOS应用开发中,完成开发后的重要一步就是将IPA文件上传到App Store Connect以便进行测试或发布到App Store。无论是使用Xcode进行原生开发,还是通过uni-app、Flutter等跨平台工具生成的IPA文件,上传到App Store的流程都是类似的。苹果…...

Java中的Arrays类
java.util.Arrays是一个非常实用的类,提供了许多静态方法来操作数组,如排序、查找、复制和填充等。 1. toString - 将数组转换为字符串 // 导入java.util.Arrays类 import java.util.Arrays;public class ArraysExample {public static void main(Stri…...

GUI编程
GUI编程 【Java从0到架构师课程】笔记 GUI简介 GUI:图形用户界面,在计算机中采用图形的方式显示用户界面 java的GUI开发 AWT:java最早推出的GUI编程开发包,界面风格跟随操作系统SWT:eclipse就是java使用SWT开发的Sw…...
map和set--C++)
(multi)map和set--C++
文章目录 一、序列式容器和关联式容器二、set系列的使用1、set和multiset参考文档2、set类的介绍3、set的构造和迭代器4、set的增删查5、insert和迭代器遍历使用样例:6、find和erase使用样例:7、multiset和set的差异 三、map系列的使用1、map和multimap参…...

jmeter响应断言放进csv文件遇到的问题
用Jmeter的json 断言去测试http请求响应结果,发现遇到中文时出现乱码,导致无法正常进行响应断言,很影响工作。于是,察看了其他测试人员的解决方案,发现是jmeter本身对编码格式的设置导致了这一问题。解决方案是在jmete…...

复旦大学全球供应链研究中心揭牌,合合信息共话大数据赋能
10月13日,复旦大学全球供应链研究中心(以下简称“中心”)揭牌仪式在复旦大学管理学院政立院区隆重举行。我国的供应链体系庞大复杂,在百年未有之大变局下,保障产业链供应链安全已成为我国的重要战略目标。中心的设立旨…...

破解“局部合格、整体偏差”困局:三维扫描如何实现精密机械零部件微米级精准检测?
汽车结构支撑件(如转向系统壳体、底盘集成支架)作为整车安全与操控性能的核心载体,承担着定位、承载、减振与部件集成的关键使命。其安装面平面度、关键孔位位置度与同轴度、复杂筋条轮廓度等精度指标,直接决定了转向系统的响应精…...

iOS App Clips实战:从开发限制到场景化触发全解析
1. App Clips到底是什么?为什么开发者需要关注它? 想象一下这样的场景:你走进一家咖啡店想用手机点单,但发现必须下载一个200MB的App才能完成操作。这时候如果店员说"扫这个二维码就能直接点单",10秒后你已经…...

从电压模到COT:DC-DC降压转换器控制模式演进与选型指南
1. DC-DC降压转换器控制模式概述 第一次接触电源设计时,我被各种控制模式搞得晕头转向。电压模、电流模、迟滞控制、COT...这些专业名词就像天书一样。后来在实际项目中摸爬滚打多年,才发现理解这些控制模式的关键在于抓住它们的"性格特点"——…...

<数据集>yolo 易拉罐识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92882375数据集格式:VOCYOLO格式 图片数量:3253张 标注数量(xml文件个数):3253 标注数量(txt文件个数):3253 标注类别数:1 标注类别名称ÿ…...

Display Driver Uninstaller:显卡驱动清理的终极解决方案
Display Driver Uninstaller:显卡驱动清理的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstall…...

告别预编译包!手把手教你为Qt6项目定制编译OpenCV,解锁WITH_QT支持
告别预编译包!手把手教你为Qt6项目定制编译OpenCV,解锁WITH_QT支持 在计算机视觉开发领域,OpenCV无疑是使用最广泛的库之一。然而,许多开发者可能没有意识到,直接从官网下载的预编译版本OpenCV可能无法充分发挥其与Qt框…...

基于DS18B20与WipperSnapper的无代码物联网温度监测方案
1. 项目概述:当经典传感器遇上无代码物联网 在物联网和智能硬件的世界里,温度监测是一个永恒的基础需求。无论是想监控家里的温室环境、记录鱼缸水温,还是追踪服务器机柜的热量变化,你都需要一个可靠、精确且易于集成的温度传感器…...
)
SolidWorks插件开发避坑指南:手把手教你搞定工具栏图标乱跑和注册表清理(C#版)
SolidWorks插件开发实战:彻底解决工具栏图标错乱与注册表残留问题 1. 问题现象与根源分析 当你在SolidWorks插件开发过程中修改插件名称或反复调试时,是否遇到过这些令人抓狂的场景? 工具栏上出现多个重复的功能按钮图标位置随机错位…...

[技术解析]图卷积网络在半监督节点分类中的实战与优化
1. 图卷积网络入门:从传统CNN到GCN的思维跃迁 第一次接触图卷积网络(GCN)时,我习惯性地用传统CNN的思维去理解它,结果踩了不少坑。传统卷积在规整的网格数据上滑动滤波器的操作,在图数据中完全行不通——因为图的拓扑结构是不规则…...

抖音本地生活运营4大核心秘籍
最近参加了一场 抖音本地生活全域运营实战特训营,两天一夜,从理论到实操。把最核心的 4 个模块整理出来,分享给想做本地生活的技术/运营同学。一、账号主页:让抖音自动帮你获客抖音主页就是你的线上门头。很多商家挂个风景图&…...