Spark数据源的读取与写入、自定义函数
1. 数据源的读取与写入
1.1 数据读取
- 读文件
read.jsonread.csv- csv文件由两个部分组成:头部数据(也就是字段数据)、行数据。
read.orc
- 读数据库
read.jdbc(jdbc连接地址,table=‘表名’,properties={‘user’=用户名,‘password’=密码,‘driver’=‘驱动信息’})
数据库创建测试数据:
create database itcast charset=utf8;create table itcast.tb_user(id int,name varchar(20),age int,gender varchar(20)
);insert into itcast.tb_user values (1,'张三',20,'男');
表查看:

读取数据库数据:
# 读取数据源,将数据转为DF
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()# read读取数据库数据
# 使用jdbc方法通过jdbc读取数据库数据,在读取数据库之前,需要现将数据库连接驱动放入spark的jars目录下
#
df = ss.read.jdbc('jdbc:mysql://192.168.88.100:3306/itcast',table='tb_user',properties={'user':'root','password':'123456','driver':'com.mysql.jdbc.Driver'})
df.show()
运行结果:

1.2 数据写入
因为数据是在df中存储,所以使用DataFrame进行数据写入
使用DataFrame的的write方法
写入文件有个模式,覆盖和追加两种方式,用mode参数指定
覆盖 overwrite
追加 append
- 写入文件
- write.json
- write.csv
- write.orc
- 写入数据库
- write.jdbc(jdbc连接地址,table=‘表名’,properties={‘user’=用户名,‘password’=密码,‘driver’=‘驱动信息’},mode=‘写入方式’)
# 数据写入
from pyspark.sql import SparkSession,Row
ss = SparkSession.builder.getOrCreate()df = ss.createDataFrame([Row(id=1,name='张三',age=20),Row(id=2,name='李四',age=20),Row(id=3,name='王五',age=20)],schema='id int,name string,age int'
)# 将df数据写入hdfs文件中 mode='overwrite' 覆盖写入 append 追加写入
df.write.json('hdfs://node1:8020/data_json',mode='overwrite')# 写入数据库
# create table itcast.tb_stu(
# id int,
# name varchar(20),
# age int
# );
# 在jdbc连接中指定编码字符集为utf-8
df.write.jdbc('jdbc:mysql://192.168.88.100:3306/itcast?characterEncoding=utf8',table='tb_stu',mode='overwrite',properties={'user':'root','password':'123456','driver':'com.mysql.jdbc.Driver'})
运行结果:

2. 自定义函数

2.1 函数分类
- udf
- 自定义
- 一进一出
- udaf
- 聚合
- 自定义
- 多进一出
- udtf
- 爆炸
- 一进多出
2.2 UDF函数
对每一行数据依次进行计算,返回每一行的结果。
#UDF函数
from pyspark.sql import SparkSession,functions as F
from pyspark.sql.types import *ss = SparkSession.builder.getOrCreate()#读取文件数据转为df
df = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',')df.show()#自定义字符串长度计算函数
def len_func(field):if field is None:return 0else:data = len(field)return data
#将自定义的函数注册到spark中使用
len_func = ss.udf.register('len_func', len_func,returnType=IntegerType())#在spark中使用
df2 = df.select('id','name','gender',len_func('name'))
df2.show()#sql语句中使用
df.createTempView('stu')
df3= ss.sql('select *,len_func(name) from stu')
df3.show()
2.3 UDAF函数
多进一出 主要是聚合
使用pandas中的series实现,可以读取一列数据存储在pandas的series中进行数据的聚合。
#UDAF函数
from pyspark.sql import SparkSession,functions as F
from pyspark.sql.types import *
import pandas as pdss = SparkSession.builder.getOrCreate()#读取文件数据转为df
df = ss.read.csv('hdfs://node1:8020/data/students.csv', header=True,sep=',',schema = 'id int,name string,age int,gender string,cls string')df.show()#对某个字段的整列数据进行计算,自定义udaf函数
# 第一步,装饰器注册
@F.pandas_udf(returnType=IntegerType())
def sub(field:pd.Series) -> int:n=field[0] #取出第一个值作为初始值for i in field[1::]:n-=ireturn n
#第二步,register方法注册
sub = ss.udf.register('sub', sub)df2 = df.select(sub('age'))
df2.show()
相关文章:
Spark数据源的读取与写入、自定义函数
1. 数据源的读取与写入 1.1 数据读取 读文件 read.jsonread.csv csv文件由两个部分组成:头部数据(也就是字段数据)、行数据。 read.orc 读数据库 read.jdbc(jdbc连接地址,table‘表名’,properties{‘user’用户名,‘password’密码,‘driv…...

LeetCode 每日一题 2024/10/14-2024/10/20
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 10/14 887. 鸡蛋掉落10/15 3200. 三角形的最大高度10/16 3194. 最小元素和最大元素的最小平均值10/17 3193. 统计逆序对的数目10/18 3191. 使二进制数组全部等于 1 的最少操…...

接口测试(六)jmeter——参数化(配置元件 --> 用户定义的变量)
一、jmeter——参数化(配置元件 --> 用户定义的变量) 注:示例仅供参考 1. 参数化格式:${变量名} 2. 配置元件:用户定义的变量 3. 添加【用户定义的变量】,【线程组】–>【添加】–>【配置元件】–…...

【学习笔记】网络流
背景 马上ICPC了,很惊奇的发现自己没整理网络流的板子。 最大流 dinic 这里选用的是二分图最大匹配的板子:飞行员配对方案问题 #include<bits/stdc.h> #define int long long using namespace std; const int N1e67,inf1e18; struct E {int to…...
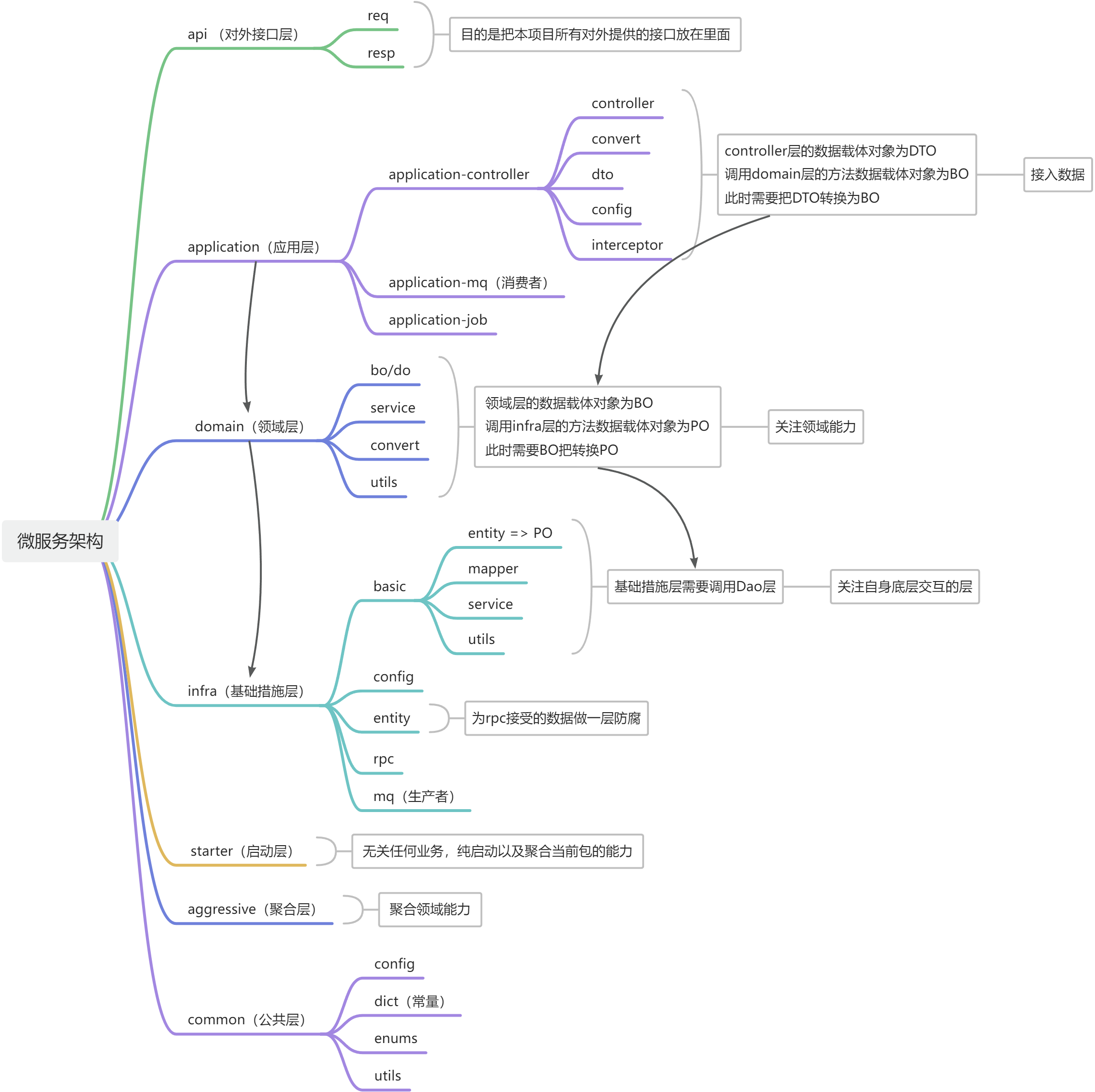
【鸡翅Club】项目启动
一、项目背景 这是一个 C端的社区项目,有博客、交流,面试学习,练题等模块。 项目的背景主要是我们想要通过面试题的分类,难度,打标,来评估员工的技术能力。同时在我们公司招聘季的时候,极大的…...

python+大数据+基于热门视频的数据分析研究【内含源码+文档+部署教程】
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...

【电子电力】基于PMU相量测量单元的电力系统状态评估
摘要 相量测量单元(PMU)作为一种精确且快速的实时监控设备,在电力系统状态评估中发挥了重要作用。本文研究了在没有PMU和部署PMU情况下,电力系统的电压角度和电压幅值估计误差的差异。通过比较实验结果,发现PMU的应用…...
)
ubuntu修改默认开机模式(图形/终端)
将 Ubuntu 16 系统设置为开机进入终端模式: 打开终端。编辑 Grub 配置文件:sudo nano /etc/default/grub。找到 GRUB_CMDLINE_LINUX_DEFAULT 行,将其修改为 GRUB_CMDLINE_LINUX_DEFAULT"text"。保存并退出编辑器(Ctrl …...

LaMI-DETR:基于GPT丰富优化的开放词汇目标检测 | ECCV‘24
现有的方法通过利用视觉-语言模型(VLMs)(如CLIP)强大的开放词汇识别能力来增强开放词汇目标检测,然而出现了两个主要挑战:(1)概念表示不足,CLIP文本空间中的类别名称缺乏…...

AI大模型是否有助于攻克重大疾病?
AI大模型在攻克重大疾病方面展现出了巨大的潜力,特别是在疾病预测、药物研发、个性化医疗等领域有着广泛应用。具体来说,AI大模型能够帮助以下几方面: 1、疾病预测与诊断:AI大模型通过分析海量的医学数据,可以提高重大…...

【渗透测试】-红日靶场-获取web服务器权限
拓扑图: 前置环境配置: Win 7 默认密码:hongrisec201 内网ip:192.168.52.143 打开虚拟网络编辑器 添加网络->VMent1->仅主机模式->子网ip:192.168.145.0 添加网卡: 虚拟机->设置-> 添加->网络适配器 保存&a…...

python 深度学习 项目调试 图像分割 segment-anything
起因, 目的: 项目来源: https://github.com/facebookresearch/segment-anything项目目的: 图像分割。 提前图片中的某个目标。facebook 出品, 居然有 47.3k star! 思考一些问题 我可以用这个项目来做什么?给一个图片, 进行分割࿰…...
:支付和订单处理)
【GO实战课】第六讲:电子商务网站(6):支付和订单处理
1. 简介 本课程将探讨电子商务网站的支付和订单处理功能,以及使用GO语言实现。在本课程中,我们将介绍如何设计一个可扩展、可靠和高性能的支付和订单处理系统,并演示如何使用GO语言编写相关代码。 本课程的目标是帮助学生理解电子商务网站的支付和订单处理功能,并提供一个…...

专题十三_记忆化搜索_算法专题详细总结
目录 1. 斐波那契数(easy) 那么这里就画出它的决策树 : 解法一:递归暴搜 解法二:记忆化搜索 解法三:动态规划 1.暴力解法(暴搜) 2.对优化解法的优化:把已经计算过的…...
)
已发布金融国家标准目录(截止2024年3月)
已发布金融国家标准目录2024年3月序号标准编号标准名称...

【论文#快速算法】Fast Intermode Decision in H.264/AVC Video Coding
目录 摘要1.前言2.帧间模式决策概览2.1 H.264/AVC中的帧间模式决策2.2 发现和动机 3.同质性和平稳性的确定3.1 同质性区域的确定3.2 稳定性区域的决定3.3 整体算法 4.实验结果4.1 IPPP序列的测试4.2 IBBP序列测试 5.结论 《Fast Intermode Decision in H.264/AVC Video Coding》…...

Git核心概念图例与最常用内容操作(reset、diff、restore、stash、reflog、cherry-pick)
文章目录 简介前置概念.git目录objects目录refs目录HEAD文件 resetreflog 与 reset --hardrevert(撤销指定提交)stashdiff工作区与暂存区差异暂存区与HEAD差异工作区与HEAD差异其他比较 restore、checkout(代码撤回)merge、rebase、cherry-pick 简介 本文将介绍Git几个核心概念…...

【人工智能在医疗企业个人中的应用】
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

IPv4头部和IPv6头部
IPv4和IPv6是互联网协议(IP)中的两个主要版本,它们在数据包头部(Header)结构上存在显著差异。以下是IPv4头部和IPv6头部的主要结构和区别: IPv4头部结构 IPv4(Internet Protocol Version 4&…...

从零开始手把手带你训练LLM保姆级教程,草履虫都能学会!零基础看完这篇就足够了~
导读 ChatGPT面世以来,各种大模型相继出现。那么大模型到底是如何训练的呢,在这篇文章中,我们将尽可能详细地梳理一个完整的 LLM 训练流程,包括模型预训练(Pretrain)、Tokenizer 训练、指令微调࿰…...
核心原理、MATLAB/Python实现与工程应用全解析)
离散时间傅里叶变换(DTFT)核心原理、MATLAB/Python实现与工程应用全解析
1. 项目概述:从连续到离散的信号分析桥梁信号处理领域里,我们常常需要分析一个信号的频率成分。对于连续时间信号,我们有强大的工具——连续时间傅里叶变换。但现实世界中的计算机和数字系统处理的都是离散的、一串串的数字序列,比…...

城通网盘解析工具:3步获取高速直连下载地址的终极方案
城通网盘解析工具:3步获取高速直连下载地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否还在为城通网盘的蜗牛下载速度而烦恼?每次下载大文件都要经历漫长的…...

对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值 在开发依赖大模型能力的应用时,服务的连续性与稳定性是保障用…...

QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制
QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了心爱的歌曲࿰…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

飞书自动化开发实战:从脚本编写到事件驱动架构设计
1. 项目概述:飞书自动化,从“手动挡”到“自动驾驶”的进化 如果你每天的工作,有超过30%的时间是在飞书里重复着“点击-填写-发送”的枯燥操作,比如手动拉取数据生成日报、定时向群聊推送消息、或者根据特定条件审批流程…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

轻量级配置管理框架zcf:多环境配置、敏感信息加密与云原生集成实践
1. 项目概述:一个面向开发者的轻量级配置管理框架最近在梳理团队内部工具链时,发现一个挺普遍的问题:不同项目、不同环境(开发、测试、生产)的配置管理总是乱糟糟的。.env文件满天飞,敏感信息一不小心就提交…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

CFD工程师必看:TVD格式选型指南——从SUPERBEE到UMIST,哪个才是你的菜?
CFD工程师必看:TVD格式选型实战指南——从工程场景到最优解 在计算流体力学(CFD)的世界里,TVD格式就像赛车手的轮胎选择——没有绝对的好坏,只有场景的适配。当你在汽车外气动分析中遇到激波振荡,或在燃烧模拟中面临虚假扩散时&am…...