Spring集成Redisson及存取几种基本类型数据
目录
一.什么是Redisson
二.为什么要使用Redisson
三.Spring集成Redisson
1.添加依赖
2.添加配置信息
3.添加redisson配置类
四.Redisson存取各种类型数据
1.字符串(String类型)
存储
获取
2.object对象类型
1.实体类信息
2.存储
3.获取
3.List集合类型
第一种: 需要对象实体类实现序列化
1.实体类信息
2.存储
3.获取
第二种: 不需要对象实体类实现序列化
1.实体类信息
2.存储
3.获取
五.为什么要实现序列化
六.实现序列化会导致哪些问题
一.什么是Redisson
Redisson 是一个用于 Redis 的 Java 客户端,它不仅提供了对 Redis 命令的访问,还提供了一套丰富且易于使用的分布式对象和服务。通过 Redisson,开发者可以轻松地在 Java 应用程序中使用 Redis 作为缓存、消息中间件或数据存储解决方案。
查看官方网站查看具体介绍 : Redisson官方介绍文档
主要特点
- 分布式对象:Redisson 提供了多种常用的 Java 对象的分布式版本,如 Map、Set、List、Queue 等等,这些对象可以在多个 JVM 实例间共享,从而支持高可用性和可扩展性。
- 分布式集合:除了基本的数据结构外,Redisson 还支持更高级的数据结构,例如 BitSets, Blooms Filters, HyperLogLogs 等,这些都是特别设计来处理大数据量和高并发场景的。
- 分布式锁:Redisson 提供了多种类型的分布式锁(如 RedLock、公平锁、联锁等),这些锁可以用来协调不同应用程序实例之间的操作,确保线程安全。
- 发布/订阅模式:支持消息的发布与订阅功能,允许不同的服务之间通过频道进行通信。
- 服务发现:Redisson 可以作为服务发现机制的一部分,帮助应用程序动态查找和连接其他服务。
- 性能优化:通过使用 Netty 框架,Redisson 能够实现高性能的异步非阻塞 I/O 操作,同时支持连接池管理和自动重连机制。
- 配置灵活:支持单机模式、主从模式、哨兵模式以及集群模式等多种部署方式,可以根据实际需求选择最适合的配置方案。
- 易于集成:Redisson 提供了 Spring、Spring Boot 等框架的支持,使得将其集成到现有项目中变得非常简单。
总之,Redisson 是一个功能强大且灵活的 Redis Java 客户端,适用于需要高性能、高可用性和易于使用的分布式应用开发。
二.为什么要使用Redisson
- 简化开发:Redisson 封装了大量的复杂逻辑,如分布式锁、分布式集合等,使得开发者可以更加专注于业务逻辑的实现,而无需深入研究底层实现细节。这大大降低了开发难度和维护成本。
- 提高效率:通过提供丰富的分布式数据结构和工具,Redisson 让开发者能够快速构建高效的应用程序。例如,使用 Redisson 的 RMap 可以很容易地创建一个分布式的哈希表,这对于需要跨多个节点共享状态的应用来说非常有用。
- 增强功能:Redisson 不仅实现了 Redis 原生命令的支持,还额外提供了许多高级特性,比如分布式锁、分布式计数器、分布式集合等,这些都是标准 Redis 客户端所不具备的功能。
- 提高可靠性:Redisson 支持多种 Redis 部署模式(单机、主从、哨兵、集群等),并且具有自动故障转移和重连机制,这有助于提高系统的稳定性和可靠性。此外,它的连接池管理功能也有助于优化资源利用,减少网络延迟。
- 易于集成:Redisson 与主流的 Java 框架(如 Spring、Spring Boot)有良好的兼容性,可以通过简单的配置就能完成集成,方便快速上手。
- 社区支持:作为一个成熟的开源项目,Redisson 拥有一个活跃的社区,这意味着用户可以获得及时的帮助和支持,同时也意味着该库会持续得到更新和完善。
- 性能优势:基于 Netty 框架构建,Redisson 在处理大量并发请求时表现出色,能够有效地提升应用的整体性能。
综上所述,如果你正在寻找一种强大、灵活且易于使用的 Redis Java 客户端,Redisson 是一个非常好的选择。无论是为了简化开发流程、提高应用性能还是增强系统稳定性,Redisson 都能为你提供强有力的支持。
三.Spring集成Redisson
1.添加依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.17.4</version>
</dependency><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.17.4</version>
</dependency>2.添加配置信息
spring:redis:#这里是自己redis的ip地址host: 192.168.169.129#redis的端口号 默认6379port: 63793.添加redisson配置类
/*** Redisson 配置类,用于创建和配置 Redisson 客户端。*/
@Configuration
public class RedissonConfig {/*** 创建并配置 Redisson 客户端。** @return 配置好的 Redisson 客户端实例*/@Bean(destroyMethod = "shutdown")public RedissonClient redissonClient() {// 创建 Redisson 配置对象Config config = new Config();// 配置单节点 Redis 服务器地址// 这里使用的是单节点模式,地址为 "redis://192.168.169.129:6379" 使用自己的redis配置即可config.useSingleServer().setAddress("redis://192.168.169.129:6379");// 创建 Jackson ObjectMapper 实例// ObjectMapper 是 Jackson 库提供的用于 JSON 序列化和反序列化的工具ObjectMapper objectMapper = new ObjectMapper();// 设置 Redisson 的编解码器为 JsonJacksonCodec// JsonJacksonCodec 使用 Jackson 的 ObjectMapper 进行对象的序列化和反序列化config.setCodec(new JsonJacksonCodec(objectMapper));// 创建并返回 Redisson 客户端实例return Redisson.create(config);}
}注解详解:
1.使用 @Bean 注解将该方法返回的对象注册为 Spring 容器中的 Bean。
2.使用 destroyMethod = "shutdown" 确保在 Spring 容器关闭时调用 shutdown() 方法,释放所有相关资源。
四.Redisson存取各种类型数据
在业务类注入Redisson核心接口 继续完成以下指定操作
@Autowired
private RedissonClient redisson;1.字符串(String类型)
存储
public void setStringRedisson() {// 获取一个名为 "stringRedisson" 的 RBucket 对象// RBucket 是 Redisson 提供的一个接口,用于操作 Redis 中的键值对RBucket<String> bucket = redisson.getBucket("stringRedisson");// 设置键 "stringRedisson" 的值为 "Hello! Story"bucket.set("Hello! Story");
}获取
public void getStringRedisson() {// 获取一个名为 "stringRedisson" 的 RBucket 对象// RBucket 是 Redisson 提供的一个接口,用于操作 Redis 中的键值对RBucket<String> bucket = redisson.getBucket("stringRedisson");// 获取键 "stringRedisson" 的值String stringRedisson = bucket.get();// 打印获取到的值System.out.println(stringRedisson);
}2.object对象类型
确保项目中包含以下依赖
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version>
</dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.83_noneautotype</version>
</dependency>1.实体类信息
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {/*** id*/private Integer id;/*** 用户名*/private String username;/*** 密码*/private String password;
}2.存储
public void setObjectJsonRedisson() {// 创建一个User对象User user = new User(1, "张三", "123456");// 获取Redis中的Bucket对象,指定键名为"ObjectRedisson"RBucket<String> bucket = redisson.getBucket("ObjectJsonRedisson");// 将User对象转换为JSON字符串,并设置到Bucket中// 注意这里使用了JSON.toJSONString方法来完成对象到字符串的转换bucket.set(JSON.toJSONString(user));
}3.获取
/*** 从Redis中获取并反序列化User对象* 使用了阿里巴巴的Fastjson将JSON字符串转换为User对象* 通过Redisson的Bucket接口从Redis中获取JSON字符串* @return 反序列化后的User对象*/
public User getObjectJsonRedisson() {// 获取Redis中的Bucket对象,指定键名为"ObjectRedisson"RBucket<String> bucket = redisson.getBucket("ObjectJsonRedisson");// 从Bucket中获取JSON字符串String objectJsonString = bucket.get();// 将JSON字符串转换为User对象// 注意这里使用了JSON.parseObject方法来完成字符串到对象的转换User user = JSON.parseObject(objectJsonString, User.class);// 返回反序列化后的User对象return user;
}3.List集合类型
注: 存取List集合类型包括两种方法
第一种是需要对象实体类实现序列化(Serializable)
第二种是不需要对象实体类实现序列化(Serializable)
为什么要实现序列化以及实现序列化会出现的问题,在文章最后有详细讲解
第一种: 需要对象实体类实现序列化
确保项目中拥有以下依赖
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version>
</dependency>1.实体类信息
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {/*** id*/private Integer id;/*** 用户名*/private String username;/*** 密码*/private String password;
}2.存储
/*** 将User对象列表存入Redis中* 在每次调用时,先清空列表,再添加新的用户信息*/public void setUserListRedisson() {// 创建两个User对象User user1 = new User(1, "张三", "12345");User user2 = new User(2, "李四", "12345");// 创建一个User对象列表List<User> users = new ArrayList<>();users.add(user1);users.add(user2);// 获取Redis中的RList对象,指定键名为"userListRedisson"RList<User> list = redisson.getList("userListRedisson");// 清空列表list.clear();// 将User对象列表添加到RList中list.addAll(users);}注: 使用list.clear() 方法会先清空列表,再实现添加操作,相当于会覆盖掉之前的数据,而不使用这个方法它会在原来的基础上添加信息,根据自己需求添加即可
3.获取
/*** 从Redis中获取User对象列表* 直接从Redis中的RList读取所有User对象并返回* @return 反序列化后的User对象列表*/public List<User> getUserListRedisson() {// 获取Redis中的RList对象,指定键名为"userListRedisson"RList<User> list = redisson.getList("userListRedisson");// 从RList中读取所有User对象List<User> users = list.readAll();// 返回读取到的User对象列表return users;}第二种: 不需要对象实体类实现序列化
确保项目中包含以下依赖
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version>
</dependency><!-- Jackson库用于JSON处理,包括对象与JSON之间的序列化和反序列化 -->
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.13.3</version> <!-- 请检查是否有更新的版本 -->
</dependency><!-- Apache Commons Lang库提供了许多常用的工具方法,简化了字符串处理、日期操作等任务 -->
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.12.0</version>
</dependency>1.实体类信息
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {/*** id*/private Integer id;/*** 用户名*/private String username;/*** 密码*/private String password;
}2.存储
@Autowired
private ObjectMapper objectMapper;/*** 将User对象列表序列化后存入Redis中* 在每次调用时,先清空列表,再添加新的用户信息*/
public void setUserListRedisson() {// 创建两个User对象User user1 = new User(1, "张三", "12345");User user2 = new User(2, "李四", "12345");// 创建一个User对象列表List<User> users = new ArrayList<>();users.add(user1);users.add(user2);// 获取Redis中的RList对象,指定键名为"userListRedisson"RList<String> list = redisson.getList("userListRedisson");// 清空列表list.clear();// 将User对象序列化并添加到列表中for (User user : users) {try {String userJson = objectMapper.writeValueAsString(user);list.add(userJson);} catch (JsonProcessingException e) {throw new RuntimeException("Failed to serialize User object to JSON", e);}}
}注: 使用list.clear() 方法会先清空列表,再实现添加操作,相当于会覆盖掉之前的数据,而不使用这个方法它会在原来的基础上添加信息,根据自己需求添加即可
3.获取
/*** 从Redis中获取并反序列化User对象列表* 使用了Apache Commons Lang库进行字符串处理,以及Jackson库进行JSON解析* @return 反序列化后的User对象列表*/
public List<User> getUserListRedisson() {// 创建一个User对象列表,用于存储反序列化后的User对象List<User> users = new ArrayList<>();// 获取Redis中的RList对象,指定键名为"userListRedisson"RList<String> userList = redisson.getList("userListRedisson");// 从RList中读取所有JSON字符串List<String> userJsons = userList.readAll();// 遍历每个JSON字符串,进行反序列化并添加到用户列表中for (String userJson : userJsons) {try {// 使用Apache Commons Lang库的StringUtils.normalizeSpace方法去除字符串中的多余空格String cleanedUserJson = StringUtils.normalizeSpace(userJson);// 使用Jackson的ObjectMapper将JSON字符串转换为User对象User user = objectMapper.readValue(cleanedUserJson, User.class);// 将反序列化后的User对象添加到列表中users.add(user);} catch (JsonProcessingException e) {// 捕获JSON处理异常,并将其包装为运行时异常抛出throw new RuntimeException("Failed to parse JSON string to User object", e);}}// 返回反序列化后的User对象列表return users;
}五.为什么要实现序列化
实现序列化(Serialization)是编程中一个非常重要的概念,尤其是在分布式系统、持久化存储和网络通信中。序列化的主要目的是将对象的状态转换为一种可以存储或传输的格式。以下是实现序列化的一些主要原因:
1.持久化存储
保存对象状态:将对象的状态保存到磁盘或其他持久化存储介质中,以便在程序重启后可以恢复这些对象的状态。
备份和恢复:在系统出现故障时,可以通过序列化和反序列化来备份和恢复数据。
历史记录:保存对象的历史状态,以便进行审计或回溯。
2. 网络传输
跨进程通信:在分布式系统中,不同进程或机器之间的通信需要将对象转换为字节流,以便通过网络传输。
远程方法调用(RMI):在 Java 中,RMI 依赖于序列化来传递对象参数和返回值。
微服务架构:在微服务架构中,服务之间通过网络进行通信,需要将对象序列化为字节流进行传输。
3. 缓存
对象缓存:将对象序列化后存储在缓存中,可以提高系统的性能和响应速度。
分布式缓存:在分布式缓存系统中,对象需要被序列化以便在不同的节点之间共享。
4. 数据交换
文件传输:将对象序列化为文件,可以在不同的系统之间进行数据交换。
消息队列:在消息队列中,消息体通常是序列化后的对象,以便在生产者和消费者之间传递。
5. 安全性和加密
数据保护:在传输或存储敏感数据时,可以先将对象序列化,然后对字节流进行加密,以保护数据的安全性。
签名和验证:序列化后的数据可以进行数字签名,确保数据的完整性和来源的可靠性。
6. 版本控制
兼容性:通过序列化和反序列化,可以确保不同版本的软件之间能够正确地交换数据。
迁移:在系统升级或迁移过程中,可以通过序列化和反序列化来确保数据的一致性和完整性。
7. 性能优化
减少内存占用:将对象序列化后存储在磁盘上,可以减少内存占用,特别是在内存资源有限的情况下。
批量处理:将多个对象序列化为一个字节流,可以减少网络传输的次数,提高性能。
8. 调试和测试
日志记录:将对象序列化后记录到日志文件中,便于调试和分析。
单元测试:在单元测试中,可以将对象序列化后保存,以便在不同的测试环境中复现问题。
六.实现序列化会导致哪些问题
实现序列化虽然带来了许多好处,但也可能导致一些问题。这些问题包括但不限于性能问题、安全问题、版本兼容性问题和内存管理问题。以下是一些常见的问题及其详细解释:
1.性能问题
序列化和反序列化的开销:序列化和反序列化过程会消耗 CPU 和内存资源,特别是对于复杂的对象图或大量数据,性能开销可能较大。
网络传输延迟:序列化后的数据量可能较大,导致网络传输延迟增加,特别是在高并发场景下。
2. 安全问题
敏感信息泄露:序列化数据可能包含敏感信息,如果这些数据被截获,可能会导致安全问题。
反序列化攻击:恶意用户可以构造特定的序列化数据,导致反序列化时执行任意代码或触发其他安全漏洞。这被称为反序列化攻击(Deserialization Attack)。
3. 版本兼容性问题
字段变更:添加、删除或修改类的字段可能会影响序列化和反序列化的过程,导致数据不一致或异常。
类结构变化:类的结构发生变化(如继承关系、方法签名等)可能影响序列化的兼容性。
serialVersionUID 管理:如果没有正确管理 serialVersionUID,可能会导致不同版本的类无法正确反序列化。
4. 内存管理问题
内存泄漏:如果序列化对象引用了大量其他对象,这些对象可能会被保留,导致内存泄漏。
临时对象:序列化和反序列化过程中可能会创建大量的临时对象,增加垃圾回收的压力。
5. 数据一致性问题
部分序列化:如果序列化过程中发生错误,可能会导致部分数据被序列化,而另一部分没有,从而导致数据不一致。
并发访问:在多线程环境下,如果多个线程同时对同一个对象进行序列化和反序列化操作,可能会导致数据不一致或竞态条件。
6. 可读性和调试困难
二进制格式:默认的序列化格式(如 Java 的二进制格式)难以阅读和调试,不利于手动检查和修改。
复杂对象图:对于复杂的对象图,序列化和反序列化的过程可能变得非常复杂,难以跟踪和调试。
7. 依赖管理问题
外部依赖:使用第三方库进行序列化(如 Jackson、Gson)时,需要确保这些依赖的版本是最新的,以避免潜在的安全漏洞和性能问题。
总结:实现序列化虽然会方便代码实现,但会造成一些性能及安全方面的问题,建议大家尽量不要序列化
相关文章:

Spring集成Redisson及存取几种基本类型数据
目录 一.什么是Redisson 二.为什么要使用Redisson 三.Spring集成Redisson 1.添加依赖 2.添加配置信息 3.添加redisson配置类 四.Redisson存取各种类型数据 1.字符串(String类型) 存储 获取 2.object对象类型 1.实体类信息 2.存储 3.获取 3.List集合类型 第一种…...

Maplibre-gl\Mapbox-gl改造支持对矢量瓦片加密
Maplibre-gl是Mapbox-gl剔除自带地图服务之后的一个分支,代码很相似。Maplibre-gl\Mapbox-gl使用的pbf格式的矢量瓦片,数据量小,渲染效果好。但也存在着信息泄露的风险。但如果想使用这个开发框架的前端渲染效果,还必须要使用这个格式。最近研究了一下如何对矢量瓦片进行加…...
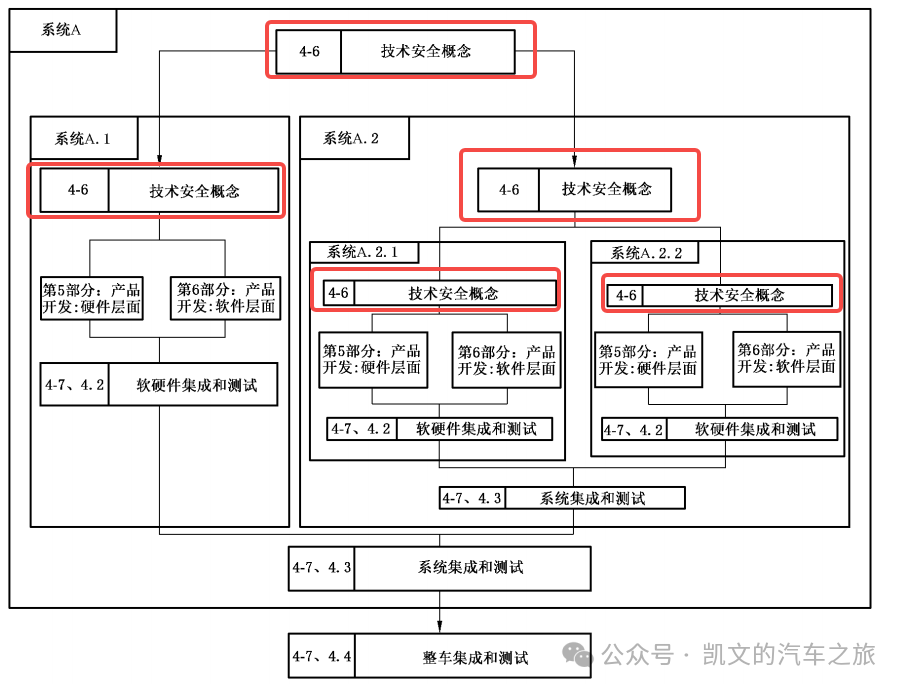
【功能安全】技术安全概念TSC
目录 01 TSC定义 02 TSC注意事项 03 TSC案例 📖 推荐阅读 01 TSC定义 所处位置 TSC:Technical safety concept技术安全概念 TSR:Technical safety requirement技术安全需求 在系统开发阶段属于安全活动4-6 系统层产品开发示例 TSC目的...

Spark数据源的读取与写入、自定义函数
1. 数据源的读取与写入 1.1 数据读取 读文件 read.jsonread.csv csv文件由两个部分组成:头部数据(也就是字段数据)、行数据。 read.orc 读数据库 read.jdbc(jdbc连接地址,table‘表名’,properties{‘user’用户名,‘password’密码,‘driv…...

LeetCode 每日一题 2024/10/14-2024/10/20
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 10/14 887. 鸡蛋掉落10/15 3200. 三角形的最大高度10/16 3194. 最小元素和最大元素的最小平均值10/17 3193. 统计逆序对的数目10/18 3191. 使二进制数组全部等于 1 的最少操…...

接口测试(六)jmeter——参数化(配置元件 --> 用户定义的变量)
一、jmeter——参数化(配置元件 --> 用户定义的变量) 注:示例仅供参考 1. 参数化格式:${变量名} 2. 配置元件:用户定义的变量 3. 添加【用户定义的变量】,【线程组】–>【添加】–>【配置元件】–…...

【学习笔记】网络流
背景 马上ICPC了,很惊奇的发现自己没整理网络流的板子。 最大流 dinic 这里选用的是二分图最大匹配的板子:飞行员配对方案问题 #include<bits/stdc.h> #define int long long using namespace std; const int N1e67,inf1e18; struct E {int to…...
【鸡翅Club】项目启动
一、项目背景 这是一个 C端的社区项目,有博客、交流,面试学习,练题等模块。 项目的背景主要是我们想要通过面试题的分类,难度,打标,来评估员工的技术能力。同时在我们公司招聘季的时候,极大的…...

python+大数据+基于热门视频的数据分析研究【内含源码+文档+部署教程】
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...

【电子电力】基于PMU相量测量单元的电力系统状态评估
摘要 相量测量单元(PMU)作为一种精确且快速的实时监控设备,在电力系统状态评估中发挥了重要作用。本文研究了在没有PMU和部署PMU情况下,电力系统的电压角度和电压幅值估计误差的差异。通过比较实验结果,发现PMU的应用…...
)
ubuntu修改默认开机模式(图形/终端)
将 Ubuntu 16 系统设置为开机进入终端模式: 打开终端。编辑 Grub 配置文件:sudo nano /etc/default/grub。找到 GRUB_CMDLINE_LINUX_DEFAULT 行,将其修改为 GRUB_CMDLINE_LINUX_DEFAULT"text"。保存并退出编辑器(Ctrl …...

LaMI-DETR:基于GPT丰富优化的开放词汇目标检测 | ECCV‘24
现有的方法通过利用视觉-语言模型(VLMs)(如CLIP)强大的开放词汇识别能力来增强开放词汇目标检测,然而出现了两个主要挑战:(1)概念表示不足,CLIP文本空间中的类别名称缺乏…...

AI大模型是否有助于攻克重大疾病?
AI大模型在攻克重大疾病方面展现出了巨大的潜力,特别是在疾病预测、药物研发、个性化医疗等领域有着广泛应用。具体来说,AI大模型能够帮助以下几方面: 1、疾病预测与诊断:AI大模型通过分析海量的医学数据,可以提高重大…...

【渗透测试】-红日靶场-获取web服务器权限
拓扑图: 前置环境配置: Win 7 默认密码:hongrisec201 内网ip:192.168.52.143 打开虚拟网络编辑器 添加网络->VMent1->仅主机模式->子网ip:192.168.145.0 添加网卡: 虚拟机->设置-> 添加->网络适配器 保存&a…...

python 深度学习 项目调试 图像分割 segment-anything
起因, 目的: 项目来源: https://github.com/facebookresearch/segment-anything项目目的: 图像分割。 提前图片中的某个目标。facebook 出品, 居然有 47.3k star! 思考一些问题 我可以用这个项目来做什么?给一个图片, 进行分割࿰…...
:支付和订单处理)
【GO实战课】第六讲:电子商务网站(6):支付和订单处理
1. 简介 本课程将探讨电子商务网站的支付和订单处理功能,以及使用GO语言实现。在本课程中,我们将介绍如何设计一个可扩展、可靠和高性能的支付和订单处理系统,并演示如何使用GO语言编写相关代码。 本课程的目标是帮助学生理解电子商务网站的支付和订单处理功能,并提供一个…...

专题十三_记忆化搜索_算法专题详细总结
目录 1. 斐波那契数(easy) 那么这里就画出它的决策树 : 解法一:递归暴搜 解法二:记忆化搜索 解法三:动态规划 1.暴力解法(暴搜) 2.对优化解法的优化:把已经计算过的…...
)
已发布金融国家标准目录(截止2024年3月)
已发布金融国家标准目录2024年3月序号标准编号标准名称...

【论文#快速算法】Fast Intermode Decision in H.264/AVC Video Coding
目录 摘要1.前言2.帧间模式决策概览2.1 H.264/AVC中的帧间模式决策2.2 发现和动机 3.同质性和平稳性的确定3.1 同质性区域的确定3.2 稳定性区域的决定3.3 整体算法 4.实验结果4.1 IPPP序列的测试4.2 IBBP序列测试 5.结论 《Fast Intermode Decision in H.264/AVC Video Coding》…...

Git核心概念图例与最常用内容操作(reset、diff、restore、stash、reflog、cherry-pick)
文章目录 简介前置概念.git目录objects目录refs目录HEAD文件 resetreflog 与 reset --hardrevert(撤销指定提交)stashdiff工作区与暂存区差异暂存区与HEAD差异工作区与HEAD差异其他比较 restore、checkout(代码撤回)merge、rebase、cherry-pick 简介 本文将介绍Git几个核心概念…...

Codesys ST语言PID调参避坑指南:从仿真到实战,手把手教你搞定温控/电机项目
Codesys ST语言PID调参避坑指南:从仿真到实战的工程化解决方案 在工业自动化领域,PID控制算法占据着核心地位。无论是恒温控制、电机调速还是压力调节,一个精心调校的PID控制器往往能决定整个系统的性能表现。然而,许多工程师在掌…...

Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复“变砖“设备
Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复"变砖"设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器因固件升级失败、意外断电或系统崩…...
在Windows下的详细评测与实战技巧)
Kafka运维新选择:Offset Explorer(Kafka Tool)在Windows下的详细评测与实战技巧
Kafka运维新选择:Offset Explorer在Windows下的深度评测与高阶实战 当Kafka集群规模从几个节点扩展到数十甚至上百个Broker时,命令行工具kafka-topics.sh和kafka-console-consumer.sh开始显得力不从心。这时,一个得力的可视化工具就像黑暗中的…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

Go语言AI编程助手SDK:提升Cursor代码理解与生成精准度
1. 项目概述:一个为AI编程而生的Go语言SDK如果你是一名Go语言开发者,同时又在深度使用Cursor这样的AI辅助编程工具,那么你很可能已经感受到了一个痛点:如何让AI更精准、更高效地理解你的代码库,并在此基础上进行智能操…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈
Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈 【免费下载链接】Qwen2.5-14B 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/Qwen2.5-14B 当开发者面对复杂的代码生成任务或技术文档分析需求时,往往会受限于云端API的延迟和…...
)
【限时解密】ElevenLabs未文档化的/v1/text-to-speech/{voice_id}/with-timing接口:获取逐词时间戳+音素级对齐数据(仅剩3个Beta白名单通道)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音生成的核心能力与技术定位 ElevenLabs 是当前业界领先的 AI 语音合成平台,其英文语音生成能力建立在自研的端到端神经声学模型(如 ElevenMultilingualV2&…...

桌面自动化技能库:基于PyAutoGUI与Selenium的工程化实践
1. 项目概述:一个桌面操作员的技能库最近在GitHub上看到一个挺有意思的项目,叫Marways7/cua_desktop_operator_skill。光看这个名字,可能有点摸不着头脑,但作为一个在自动化运维和桌面支持领域摸爬滚打多年的老手,我立…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...