YOLO11改进 | 注意力机制 | 正确的 Self-Attention 与 CNN 融合范式,性能速度全面提升【独家创新】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
卷积和自注意力是两种强大的表征学习技术,它们通常被认为是彼此不同的两种平行方法。ACmix模型通过结合卷积和自注意力的优势,旨在解决卷积神经网络和自注意力模型在表征学习中的各自局限性,提高模型性能。通过这种方式,ACmix在图像识别和下游任务上实现了性能提升。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLO11入门 + 改进涨点——点击即可跳转 欢迎订阅
目录
1. 论文
2. ACmix代码实现
2.1 将ACmix添加到YOLO11中
2.2 更改init.py文件
2.3 添加yaml文件
2.4 在task.py中进行注册
2.5 执行程序
3.修改后的网络结构图
4. 完整代码分享
5. GFLOPs
6. 进阶
7.总结
1. 论文

论文链接:https://arxiv.org/pdf/2111.14556.pdf
代码链接:https://github.com/Panxuran/ACmix
预训练模型:models: Models of MindSpore
2. ACmix代码实现
2.1 将ACmix添加到YOLO11中
关键步骤一: 将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/conv.py中
import torch.nn.functional as F
import timedef position(H, W, is_cuda=True):if is_cuda:loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)else:loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)return locdef stride(x, stride):b, c, h, w = x.shapereturn x[:, :, ::stride, ::stride]def init_rate_half(tensor):if tensor is not None:tensor.data.fill_(0.5)def init_rate_0(tensor):if tensor is not None:tensor.data.fill_(0.)class ACmix(nn.Module):def __init__(self, in_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):super(ACmix, self).__init__()self.in_planes = in_planesself.out_planes = in_planesself.head = headself.kernel_att = kernel_attself.kernel_conv = kernel_convself.stride = strideself.dilation = dilationself.rate1 = torch.nn.Parameter(torch.Tensor(1))self.rate2 = torch.nn.Parameter(torch.Tensor(1))self.head_dim = self.out_planes // self.headself.conv1 = nn.Conv2d(in_planes, self.out_planes, kernel_size=1)self.conv2 = nn.Conv2d(in_planes, self.out_planes, kernel_size=1)self.conv3 = nn.Conv2d(in_planes, self.out_planes, kernel_size=1)self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)self.softmax = torch.nn.Softmax(dim=1)self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, self.out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)self.reset_parameters()def reset_parameters(self):init_rate_half(self.rate1)init_rate_half(self.rate2)kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)for i in range(self.kernel_conv * self.kernel_conv):kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)self.dep_conv.bias = init_rate_0(self.dep_conv.bias)def forward(self, x):q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)scaling = float(self.head_dim) ** -0.5b, c, h, w = q.shapeh_out, w_out = h//self.stride, w//self.stride# ### att# ## positional encoding https://github.com/iscyy/yoloairpe = self.conv_p(position(h, w, x.is_cuda))q_att = q.view(b*self.head, self.head_dim, h, w) * scalingk_att = k.view(b*self.head, self.head_dim, h, w)v_att = v.view(b*self.head, self.head_dim, h, w)if self.stride > 1:q_att = stride(q_att, self.stride)q_pe = stride(pe, self.stride)else:q_pe = peunfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_outunfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_outatt = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)att = self.softmax(att)out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)## convf_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])out_conv = self.dep_conv(f_conv)return self.rate1 * out_att + self.rate2 * out_conv2.2 更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数

然后在下面的__all__中声明函数

2.3 添加yaml文件
关键步骤三:在/ultralytics/ultralytics/cfg/models/11下面新建文件yolo11_ACmix.yaml文件,粘贴下面的内容
- 目标检测
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, ACmix, [1024]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 11], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
- 语义分割
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, ACmix, [1024]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 11], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[17, 20, 23], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
- 旋转目标检测
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, ACmix, [1024]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 11], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[17, 20, 23], 1, OBB, [nc, 1]] # Detect(P3, P4, P5)温馨提示:本文只是对yolo11基础上添加模块,如果要对yolo11n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple
# YOLO11n
depth_multiple: 0.50 # model depth multiple
width_multiple: 0.25 # layer channel multiple
max_channel:1024# YOLO11s
depth_multiple: 0.50 # model depth multiple
width_multiple: 0.50 # layer channel multiple
max_channel:1024# YOLO11m
depth_multiple: 0.50 # model depth multiple
width_multiple: 1.00 # layer channel multiple
max_channel:512# YOLO11l
depth_multiple: 1.00 # model depth multiple
width_multiple: 1.00 # layer channel multiple
max_channel:512 # YOLO11x
depth_multiple: 1.00 # model depth multiple
width_multiple: 1.50 # layer channel multiple
max_channel:5122.4 在task.py中进行注册
关键步骤四:在parse_model函数中进行注册,添加ACmix,
先在task.py导入函数

然后在task.py文件下找到parse_model这个函数,如下图,添加ACmix

elif m in [ACmix,]:c1, c2 = ch[f], args[0]if c2 != nc: # if not outputc2 = make_divisible(c2 * width, 8)args = [c1, *args[1:]]2.5 执行程序
关键步骤五: 在ultralytics文件中新建train.py,将model的参数路径设置为yolo11_ACmix.yaml的路径即可
from ultralytics import YOLO
import warnings
warnings.filterwarnings('ignore')
from pathlib import Pathif __name__ == '__main__':# 加载模型model = YOLO("ultralytics/cfg/11/yolo11.yaml") # 你要选择的模型yaml文件地址# Use the modelresults = model.train(data=r"你的数据集的yaml文件地址",epochs=100, batch=16, imgsz=640, workers=4, name=Path(model.cfg).stem) # 训练模型🚀运行程序,如果出现下面的内容则说明添加成功🚀
from n params module arguments0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]10 -1 1 218414 ultralytics.nn.modules.block.ACmix [256]11 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']13 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]14 -1 1 111296 ultralytics.nn.modules.block.C3k2 [384, 128, 1, False]15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']16 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]17 -1 1 32096 ultralytics.nn.modules.block.C3k2 [256, 64, 1, False]18 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]19 [-1, 14] 1 0 ultralytics.nn.modules.conv.Concat [1]20 -1 1 86720 ultralytics.nn.modules.block.C3k2 [192, 128, 1, False]21 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]22 [-1, 11] 1 0 ultralytics.nn.modules.conv.Concat [1]23 -1 1 378880 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True]24 [17, 20, 23] 1 464912 ultralytics.nn.modules.head.Detect [80, [64, 128, 256]]
YOLO11_ACmix summary: 329 layers, 2,842,494 parameters, 2,842,478 gradients, 6.8 GFLOPs报错解决指南:
RuntimeError: Input type (float) and bias type (c10::Half) should be the same在/ultralytics/ultralytics/engine/validator.py中的116行处添加下面代码即可
self.args.half = False
3.修改后的网络结构图

4. 完整代码分享
这个后期补充吧~,先按照步骤来即可
5. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的YOLO11n GFLOPs

改进后的GFLOPs

6. 进阶
可以与其他的注意力机制或者损失函数等结合,进一步提升检测效果
7.总结
通过以上的改进方法,我们成功提升了模型的表现。这只是一个开始,未来还有更多优化和技术深挖的空间。在这里,我想隆重向大家推荐我的专栏——《YOLO11改进有效涨点》。这个专栏专注于前沿的深度学习技术,特别是目标检测领域的最新进展,不仅包含对YOLO11的深入解析和改进策略,还会定期更新来自各大顶会(如CVPR、NeurIPS等)的论文复现和实战分享。
为什么订阅我的专栏? ——《YOLO11改进有效涨点》
-
前沿技术解读:专栏不仅限于YOLO系列的改进,还会涵盖各类主流与新兴网络的最新研究成果,帮助你紧跟技术潮流。
-
详尽的实践分享:所有内容实践性也极强。每次更新都会附带代码和具体的改进步骤,保证每位读者都能迅速上手。
-
问题互动与答疑:订阅我的专栏后,你将可以随时向我提问,获取及时的答疑。
-
实时更新,紧跟行业动态:不定期发布来自全球顶会的最新研究方向和复现实验报告,让你时刻走在技术前沿。
专栏适合人群:
-
对目标检测、YOLO系列网络有深厚兴趣的同学
-
希望在用YOLO算法写论文的同学
-
对YOLO算法感兴趣的同学等

相关文章:
YOLO11改进 | 注意力机制 | 正确的 Self-Attention 与 CNN 融合范式,性能速度全面提升【独家创新】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 卷积和自注意力是两种强大的表征学习技术…...

0基础学java之Day11
二维数组 静态二位数组 理解:二维数组中包含了多个一维数组 声明: 数据类型 变量名;--推荐 数据类型 变量名; //静态初始化1//String[][] names new String[][]{{"小红","小绿","小蓝"},{"小黄","小紫…...

python主流框架Django:ORM框架关联查询与管理器
目录 注意 使用前要调用之前的模型类 F对象 Q对象 聚合函数 排序 关联查询(连表查询) 修改 删除 查询集 QuerySet 注意 使用前要调用之前的模型类 F对象 之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用 "F对象&quo…...

如何有效维护您的WordPress在线商店内容:提高客户参与度与转化率的实用技巧
在电子商务领域,内容为王。新鲜、相关且有吸引力的内容能显著提升客户参与度和转化率。本文将探讨如何有效更新和维护您的在线商店内容,确保客户始终获得最佳体验。 定期更新产品信息 产品描述 产品描述是吸引客户和促成销售的关键。定期检查并更新产…...

【Java】认识异常
1.异常概念与体系结构 1.1异常的概念 在我们日常开发中,代码都是尽可能完善,但是难免会出现一些奇奇怪怪的问题。而这些奇奇怪怪的问题可能很难通过代码去控制,比如格式不对会报错,网络不好也会报错等。 在Java中,将…...

20 Shell Script输入与输出
标出输入、标准输出、错误输出 一、程序的基本三个IO流 一)文件描述符 任何程序在Linux系统中都有3个基本的文件描述符 比如: cd/proc/$$/fd 进入当前shell程序对于内核在文件系统的映射目录中: [rootlocalhost ~]# cd /proc/$$/fd [rootlocalhos…...

HCIP-HarmonyOS Application Developer 习题(十六)
(判断)1、HiLink通过分布式软总线的方式连接所有设备,强能力设备可对弱能力设备进行设备虚拟化,将弱设备当做本机设备直接调用。 答案:错误 分析:HiLink 主要针对的是应用开发者与第三方设备开发者…...

没有什么可以抵达乌托邦,包括AI
本文为《智人之上:从石器时代到AI时代的信息网络简史》书评 可以说,尤瓦尔赫拉利又一次让我们获得了理解人类文明的新视角。 这是他一直以来都在做的:构建理解人类文明史的新知识框架。从此前的《人类简史》《未来简史》《今日简史》,到今天的新书《智人之上》,他一直保…...

家庭事务管理系统|基于java和vue的家庭事务管理系统设计与实现(源码+数据库+文档)
家庭事务管理系统 目录 基于java和vue的家庭事务管理系统 一、前言 二、系统功能设计 三、系统实现 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,阿里云…...
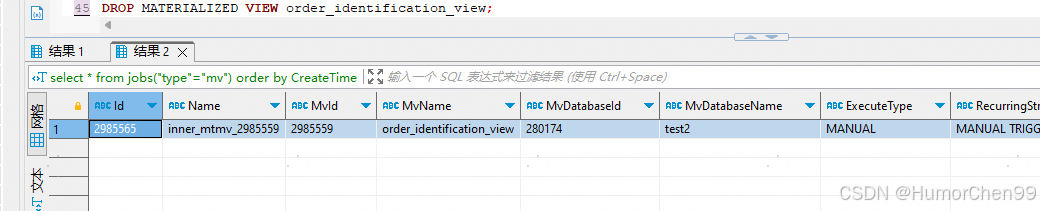
doris创建异步物化视图(加速数据低频变更的复杂实时计算)
异步物化视图,可以把那些每次实时计算非常耗时的,而需要计算的数据变更比较低频的这些计算创建对应的异步物化视图,当相关数据变化的时候触发异步任务去更新计算结果,或者定时计算也可以。例如该处示范为计算订单的订单标识&#…...

PhpSpreadsheet创建带复杂表头的excel数据
目录 一:背景 二:excel表头数据实现 三:excel渲染数据实现: 四:最终效果如下: 一:背景 最近需要统计一些数据,导出到excel,主要是一些区域的人员销售统计数据,涉及到复杂的表头和…...

BurpSuite渗透工具的简单使用
BurpSuite渗透工具 用Burp Suite修改请求 step1: 安装Burp Suite。官网链接:Burp Suite官网 step2: 设置代理 step3: 如果要拦截https请求,还需要在客户端安装证书 step4: 拦截到请求可以在Proxy ->…...

洞察云上风险,主机安全尽在掌握
在实战攻防演练中,主机一直是攻击方的最终目标。作为网络架构中的重要组成部分,主机包含了大量的敏感数据、关键服务和系统资源。同时主机拥有网络资源的访问权限,攻击者通过入侵主机获得权限,进而控制整个网络或系统。因此做好主…...

使用kimi编辑助手,开始搭建一个微信小程序!第一天
为什么开源?因为不开源,一个人开发小程序,一点突如其来的变故就会导致自己整体处于一个不舒服的状态,同时自己从0开始1开始搭建小程序,也是自己个体之间能力的验证! 目前小程序版本:2.5.2 目前…...

【已解决】libev not found
学习韦东山老师的Linux应用开发实验班的JSON部分,在编译JSON包的过程中 报错命令: ./configure --hostarm-buildroot-linux-gnueabihf -prefix$PWD/tmp 错误信息: checking for libev support... checking for arm-buildroot-linux-gnue…...

qt QVariant详解
QVariant是Qt框架中一个功能强大的变体类,它提供了一种通用的方式来存储Qt对象及其他类的值,能够以类似于指针的方式存储任意类型的值。 一、 主要特性 通用性:QVariant可以存储几乎所有数据类型,包括基本数据类型(如…...

再获殊荣!通付盾当选信息技术应用创新工作委员会技术活动单位称号
近日,通付盾凭借其在信息技术应用创新领域的卓越贡献和突出表现,荣获“信息技术应用创新工作委员会技术活动单位”称号。这一荣誉不仅是对通付盾在技术创新和信息安全领域努力的肯定,更是对其在推动国家信息技术应用创新发展中发挥重要作用的…...

PostgreSQL模板数据库template0和template1的异同点
PostgreSQL模板数据库 PostgreSQL有两个模板数据库:template0和template1,template0是不可修改的,而template1是可以修改的。 那模板数据库有什么作用呢?顾名思义,当做模板。 其实我们创建数据库 CREATE DATABASE 其…...

手机ip切换成全局模式怎么弄
在当今数字化时代,智能手机已成为我们日常生活中不可或缺的一部分,无论是工作、学习还是娱乐,都离不开它的陪伴。随着网络技术的不断发展,手机IP地址的切换技术也逐渐走进大众视野,中,“全局模式” 作为IP切…...

前端学习笔记(1.0)
在开发项目时,需要使用符号来代替书写./和../等麻烦的路径书写,所以就遇到了下面的问题。 输入没有路径提示 我们都知道,设置是通过配置vite等脚手架工具的配置文件,设置别名即可。 但是如果需要在使用的时候需要出现路径提示&…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备
Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器在固件升级过程中意外断电,或者刷入错误固件导致…...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

通达信数据解析终极指南:mootdx让金融数据获取变得如此简单
通达信数据解析终极指南:mootdx让金融数据获取变得如此简单 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易的世界里,获取准确、完整的市场数据是…...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...

3分钟掌握Seraphine:英雄联盟智能助手完全指南
3分钟掌握Seraphine:英雄联盟智能助手完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,通过自动BP系统和实时战绩查…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

轻量级服务器监控面板:从原理到部署实战
1. 项目概述:一个开源监控面板的诞生最近在折腾服务器和容器化应用,发现一个挺普遍的需求:当你手头有几台服务器,上面跑着几个Docker容器,或者一些自己写的服务,你总想知道它们现在“活”得怎么样。CPU是不…...

AI驱动工作流自动化:从原理到实践,构建智能效率引擎
1. 项目概述:当AI遇上工作流,一场效率革命正在发生最近在GitHub上看到一个名为“WorkflowAI/WorkflowAI”的项目,这个名字本身就充满了想象空间。作为一个长期与各种自动化工具和效率方法论打交道的人,我立刻意识到,这…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...