Numpy基础02
目录
1.数组操作
1.1改变维度
1.2遍历数组
1.2.1nditer(array,order)
1.2.1.1flags 参数
1.2.1.2op_flags 参数
1.3平展数组
1.3.1flatten(order='C')
1.3.2ravel()
1.4数组转置
1.4.1transpose()
1.4.2T
1.5分割数组
1.5.1hsplit(arr,indices_or_section)
1.5.2vsplit(arr,indices_or_section))
1.6连接数组
1.6.1hstack()
1.6.2vstack()
1.7删除维度
1.8增加维度
2.数组元素的增删改查
2.1resize(arr, new_shape)
2.2append(arr, values, axis=None)
2.3insert(arr, obj, values, axis)
2.4delete(arr, obj, axis)
2.5argwhere(arr)
2.6unique
3.统计函数
3.1amin(arr,axis=None)和amax(arr,axis=None)
3.2ptp(arr,axis=None)
3.3median(arr,axis=None)
3.4mean(arr,axis=None)
3.5average(arr,weights,axis=None)
3.6var(arr,ddof=0,axis=None)
3.6.1var(arr,axis=None)
3.6.2var(arr,ddof=1,axis=None)
3.7std(arr,axis=None,ddof=0)
1.数组操作
1.1改变维度
reshape()
1.2遍历数组
flat:数组属性,是迭代器,用于遍历所有元素。
arr = np.arange(0,10).reshape(2,5)
for i in arr.flat:print(i,end=" ")1.2.1nditer(array,order)
nditer 是 NumPy 中的迭代器对象,用于高效地遍历多维数组。
arr = np.array([[1, 2, 3], [4, 5, 6]])for item in np.nditer(arr,order="F"):print(item)
print("-----")
for item in np.nditer(arr,order="C"):print(item)1.2.1.1flags 参数
用于指定迭代器的额外行为。
multi_index:返回每个元素的索引
external__loop:返回一维数组,减少函数调用的次数。
arr = np.array([[1, 2, 3], [4, 5, 6]])
item = np.nditer(arr,flags=['multi_index'])
for i in item:print(i,item.multi_index)# print(f"Element: {i}, Index: {i.multi_index}")item2 = np.nditer(arr,flags=['external_loop'],order="F")
for i in item2:print(i)item3 = np.nditer(arr,flags=['external_loop'],order="C")
for i in item3:print(i)注意:flags的参数是列表或元组

1.2.1.2op_flags 参数
用于指定操作数
- readonly:只读操作数
- readwrite:读写操作数
- writeonly:只写操作数
arr = np.array([[1, 2, 3], [4, 5, 6]])
for x in np.nditer(arr, op_flags=['readwrite']):x[...] = 2 * x
print(arr)
1.3平展数组
1.3.1flatten(order='C')
数组属性,返回数组以一维形式的副本
参数
order: 指定数组的展开顺序。
-
'C':按行优先顺序展开(默认)。 -
'F':按列优先顺序展开。 -
'A':如果原数组是 Fortran 连续的,则按列优先顺序展开;否则按行优先顺序展开。 -
'K':按元素在内存中的顺序展开。
arr = np.arange(0,10).reshape(2,5)
print(arr.flatten(order="F"))
print(arr.flatten(order="C"))1.3.2ravel()
返回原数组的一个视图(view)(浅拷贝)
arr = np.arange(0,6).reshape(2,3)
x=arr.ravel()
x[-1]=100
print(arr)1.4数组转置
1.4.1transpose()
arr = np.arange(0,6).reshape(2,3)
print(arr.transpose())1.4.2T
数组属性
arr = np.arange(0,6).reshape(2,3)
print(arr.transpose())1.5分割数组
1.5.1hsplit(arr,indices_or_section)
列分割
arr = np.arange(0,9).reshape(3,3)
print(arr)
print('列分割1:',np.hsplit(arr,[1,2]))
print('列分割2:',np.hsplit(arr,[2]))
1.5.2vsplit(arr,indices_or_section))
行分割
arr = np.arange(0,9).reshape(3,3)
print(arr)
print('行分割1:',np.vsplit(arr,[1,2]))
print('行分割2:',np.vsplit(arr,[2]))1.6连接数组
1.6.1hstack()
元组,列表,或者numpy数组,返回numpy的数组
按水平顺序堆叠序列中数组(列方向)
注意:参与连接的数组,行数一致
arr = np.arange(0, 6).reshape(2,3)
arr2 = np.arange(6.1, 10.1).reshape(2,2)
print(np.hstack((arr,arr2)))lt1=[1,2,3]
lt2=[4,5,6]
print(np.hstack((lt1,lt2)))arr2=np.arange(8, 10).reshape(1,2)
arr3 = np.arange(0, 6).reshape(1,6)
tup_arr2=tuple(arr2)
tup_arr3=tuple(arr3)
print(np.hstack((tup_arr2,tup_arr3)))1.6.2vstack()
元组,列表,或者numpy数组,返回numpy的数组
按垂直方向堆叠序列中数组(行方向)
注意:参与连接的数组,列数一致
arr = np.arange(0, 6).reshape(3,2)
arr2 = np.arange(6.1, 10.1).reshape(2,2)
print(np.vstack((arr,arr2)))1.7删除维度
squeez(arr,axis)
删除的指定维度的维度值必须为1
arr = np.arange(0,20).reshape(4,5,1)
print('原数组:\n', arr)
arr1 = np.squeeze(arr,axis=2)
print('删除后:\n',arr1)1.8增加维度
expand_dims(arr, axis)
axis:新轴插入的位置
arr = np.arange(0, 6).reshape(2,3)
print(arr)
print(np.expand_dims(arr,axis=0))2.数组元素的增删改查
2.1resize(arr, new_shape)
返回的修改后的数组
new_shape:在二维数组中,[cow,col],元素数量:cow*col
若元素数量不够,重复数组元素来填充新的形状
若元素数量超出范围,截断范围外数组元素
arr = np.arange(0,9).reshape(3,3)
print('',np.resize(arr,[3,4]))
print(np.resize(arr,[2,2]))2.2append(arr, values, axis=None)
values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致(局限)
axis:默认为 None,返回的是一维数组;
当 axis =0 时,追加的值会被添加到行,而列数保持不变,axis=1 与其相反
arr = np.arange(0,6).reshape(2,3)
value1=np.array([10])
value2=np.array([[10,11,12],[13,14,15]])
value3=np.array([100,110,120])
print("axis=None时",np.append(arr,value1),sep="\n")
print("axis=0时",np.append(arr,value2,axis=0),sep="\n")
print("axis=1时",np.append(arr,value2,axis=1),sep="\n")2.3insert(arr, obj, values, axis)
obj:表示索引值,在该索引值之前插入 values 值;
value:插入的元素,可广播
axis:默认为 None,返回的是一维数组;
当 axis =0 时,追加的值会被添加到行,而列数保持不变,axis=1 与其相反
arr = np.arange(0,6).reshape(2,3)
value1=np.array([10,11,12])
value2=np.array([20,21])
value3=np.array([20])
print(np.insert(arr,1,value1,axis=0))
print(np.insert(arr,2,value2,axis=1))
print(np.insert(arr,2,value3,axis=1))


2.4delete(arr, obj, axis)
obj:表示索引值,在该索引值之前删除 values 值
axis:默认为 None,返回的是一维数组;
当 axis =0 时,删除指定的行,若 axis=1,删除指定的列
arr = np.arange(0,12).reshape(3,4)
print("原二维数组:",arr,sep="\n")
print("删除行:",np.delete(arr,[2],axis=0),sep="\n")
print("删除列:",np.delete(arr,[1],axis=1),sep="\n")2.5argwhere(arr)
返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成非 0 元素的索引坐标
arr=np.array([[1,2,3],[0,4,5]])
print(np.argwhere(arr))2.6unique
unique(arr, return_index=False, return_inverse=False, return_counts=False, axis=None)
return_index:如果为 True,则返回新数组元素在原数组中的位置(索引)
return_inverse:如果为 True,则返回原数组元素在新数组中的位置(逆索引)
return_counts:如果为 True,则返回去重后的数组元素在原数组中出现的次数
功能:删掉某个轴上的子数组,并返回删除后的新数组
用途:词频统计
arr = np.array([[1, 2], [2, 3], [1, 2]])
arr_new, index, inverse, count = np.unique(arr, return_index=True, return_inverse=True, return_counts=True)
print("去重后:", arr_new, sep="\n")
print("出现次数统计:", count, sep="\n")
print("新数组元素在原数组的首次出现的索引:", index, sep="\n")
print("原数组此位置元素在新数组中的索引:", inverse, sep="\n")3.统计函数
3.1amin(arr,axis=None)和amax(arr,axis=None)
计算数组沿指定轴的最小值与最大值,并以数组形式返回
对于二维数组来说,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向,axis默认值为None,amin,amax求整体的最值

arr = np.array([[1, 2, 3], [0, 4, 5], [2, 5, 6], [4, 2, 4]])
print(arr)
print('数组中最小值\n',np.amin(arr))
print('列最小值\n',np.amin(arr,axis=0))
print('行最小值\n',np.amin(arr,axis=1))
print('数组中最大值\n',np.amax(arr))
print('列最大值\n',np.amax(arr,axis=0))
print('行最大值\n',np.amax(arr,axis=1))3.2ptp(arr,axis=None)
计算数组元素中最值之差值,即最大值 - 最小值
对于二维数组来说,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向,axis默认值为None,求整体的差值
arr = np.array([[1, 2, 3], [0, 4, 5], [2, 5, 6], [4, 2, 4]])
print(arr)
print(np.ptp(arr))
print(np.ptp(arr,axis=0))
print(np.ptp(arr,axis=1))3.3median(arr,axis=None)
用于计算中位数,中位数是指将数组中的数据按从小到大的顺序排列后,位于中间位置的值。如果数组的长度是偶数,则中位数是中间两个数的平均值。
arr = np.array([[1, 2, 3], [0, 4, 5], [2, 5, 6], [4, 2, 4]])
print(arr)
print(np.median(arr))
print(np.median(arr,axis=0))
print(np.median(arr,axis=1))3.4mean(arr,axis=None)
沿指定的轴,求数组中元素的算术平均值
arr = np.array([[1, 2, 3], [0, 4, 5], [2, 5, 6], [4, 2, 4]])
print(arr)
print(np.mean(arr))
print(np.mean(arr,axis=0))
print(np.mean(arr,axis=1))3.5average(arr,weights,axis=None)
加权平均值是将数组中各数值乘以相应的权数,然后再对权重值求总和,最后以权重的总和除以总的单位数(即因子个数);根据在数组中给出的权重,计算数组元素的加权平均值。

arr = np.array([[1, 2], [3, 4],[5,6]])
weights = np.array([[0.4, 0.3], [0.2, 0.2],[0.8,0.57]])
print(np.average(arr, weights=weights))
print(np.average(arr, weights=weights,axis=0))
print(np.average(arr, weights=weights,axis=1))
3.6var(arr,ddof=0,axis=None)
在 NumPy 中,计算方差时使用的是统计学中的方差公式,而不是概率论中的方差公式,主要是因为 NumPy 的设计目标是处理实际数据集,而不是概率分布。
np.var 函数默认计算的是总体方差(Population Variance),而不是样本方差(Sample Variance)。
总体方差:
对于一个总体数据集 X={x1,x2,…,xN},总体方差的计算公式为:
N是总体数据点的总数。
μ是总体的均值。

3.6.1var(arr,axis=None)
arr = np.array([[1, 2], [3, 4],[5,6]])
print(np.var(arr))
print(np.var(arr,axis=0))
print(np.var(arr,axis=1))样本方差:
对于一个样本数据集 X={x1,x2,…,xn},样本方差 的计算公式为:
其中:
n是样本数据点的总数。
xˉ是样本的均值。
在样本数据中,样本均值的估计会引入一定的偏差。通过使用 n−1作为分母,可以校正这种偏差,得到更准确的总体方差估计。
3.6.2var(arr,ddof=1,axis=None)
arr = np.array([[1, 2], [3, 4],[5,6]])
print(np.var(arr,ddof=1))
print(np.var(arr,ddof=1,axis=0))
print(np.var(arr,ddof=1,axis=1))3.7std(arr,axis=None,ddof=0)
标准差是方差的算术平方根,用来描述一组数据平均值的分散程度。若一组数据的标准差较大,说明大部分的数值和其平均值之间差异较大;若标准差较小,则代表这组数值比较接近平均值。
arr = np.array([[1, 2], [3, 4],[5,6]])
print(np.std(arr))
print(np.std(arr,axis=0))
print(np.std(arr,axis=1))相关文章:

Numpy基础02
目录 1.数组操作 1.1改变维度 1.2遍历数组 1.2.1nditer(array,order) 1.2.1.1flags 参数 1.2.1.2op_flags 参数 1.3平展数组 1.3.1flatten(orderC) 1.3.2ravel() 1.4数组转置 1.4.1transpose() 1.4.2T 1.5分割数组 1.5.1hsplit(arr,indices_or_section) 1.5.2vsp…...

Elasticsearch是做什么的?
初识elasticsearch 官方网站:Elasticsearch:官方分布式搜索和分析引擎 | Elastic Elasticsearch是做什么的? Elasticsearch 是一个分布式搜索和分析引擎,专门用于处理大规模数据的实时搜索、分析和存储。它基于 Apache Lucene …...

Java中消息队列
MQ是Message Queue的缩写,也就是消息队列的意思,它是一种应用程序对应用程序的通信方法,使得应用程序能够通过读写出入列队的消息来进行通信,而无需要使用专用的连接来链接它们。消息队列中间件是分布式系统中重要的组件ÿ…...

高频面试手撕
手撕高频结构 前言 以下内容,都是博主在秋招面试中,遇到的面试手撕代码题目,不同于算法题目,更多考察的是基础知识,包含常见的数据结构比如线性表、哈希表、优先级队列等,还有多线程以及数据库连接池等内…...

Spring Boot 3.3 【八】整合实现高可用 Redis 集群
一、引言 在当今快速发展的软件开发领域,系统的性能和可靠性至关重要。Springboot 3 整合 Redis 7 集群具有多方面的重大意义。 首先,随着业务的不断发展,数据量呈爆炸式增长,单个 Redis 服务器往往难以满足存储和处理需求。Red…...

循环控制结构穷举 同构数
说明 同构数是会出现在它的平方的右边的数。例如,5就是1个同构数。5的平方是25,25最右边的这个数是5自己。25也是一个同构数,比如25的平方是625,而625右边的数是25. 请编程输出1000以内正整数中所有的同构数。每行一个答案。 输…...

主机本地IP与公网IP以及虚拟机的适配器和WSL发行版的IP
在局域网内,如果你想要连接到同一网络中的另一台设备,建议使用 本地 IP 地址(也称为局域网 IP 地址)。这是因为本地 IP 地址是在局域网内分配给设备的,用于在同一网络中的设备之间进行通信。 使用本地 IP 地址的好处 …...

@MassageMapping和@SendTo注解详解
MessageMapping注解是Spring Framework中用于WebSocket消息处理的注解,它用于将特定的消息路径映射到处理器方法上。SendTo注解指定了相应消息应该被发送到的目的地路径。 一、WebSocket配置类: Configuration EnableWebSocketMessageBroker public cl…...

2.1_Linux发展与基础
Linux基础知识 Shell 命令执行环境: 命令提示符的组成:(用户名主机名)-[当前路径]权限提示符,例:(kali㉿kali)-[~]$ ~ 表示所在目录为家目录:其中root用户的家目录是/root,普通用户的家目录在/home下 # 表示用户的权…...

c#子控件拖动父控件方法及父控件限在窗体内拖动
一、效果 拖放位置不超过窗体四边,超出后自动靠边停靠支持多子控件拖动指定控件拖放(含父控件或窗体)点击左上角logo弹出消息窗口(默认位置右下角)1.1 效果展示 1.2 关于MQTTnet(最新版v4.3.7.1207)实现在线客服功能,见下篇博文 https://github.com/dotnet/MQTTnet 网上…...

Redis --- 第八讲 --- 关于主从复制哨兵
主从复制的补充问题 从节点和主节点之间断开连接,有两种情况: 1、从节点和主节点断开连接 slaveof no one 命令。这个时候,从节点就能能够晋升成主节点。意味着我们程序员要主动修改redis的组成结构。, 2、主节点挂了 这个时…...
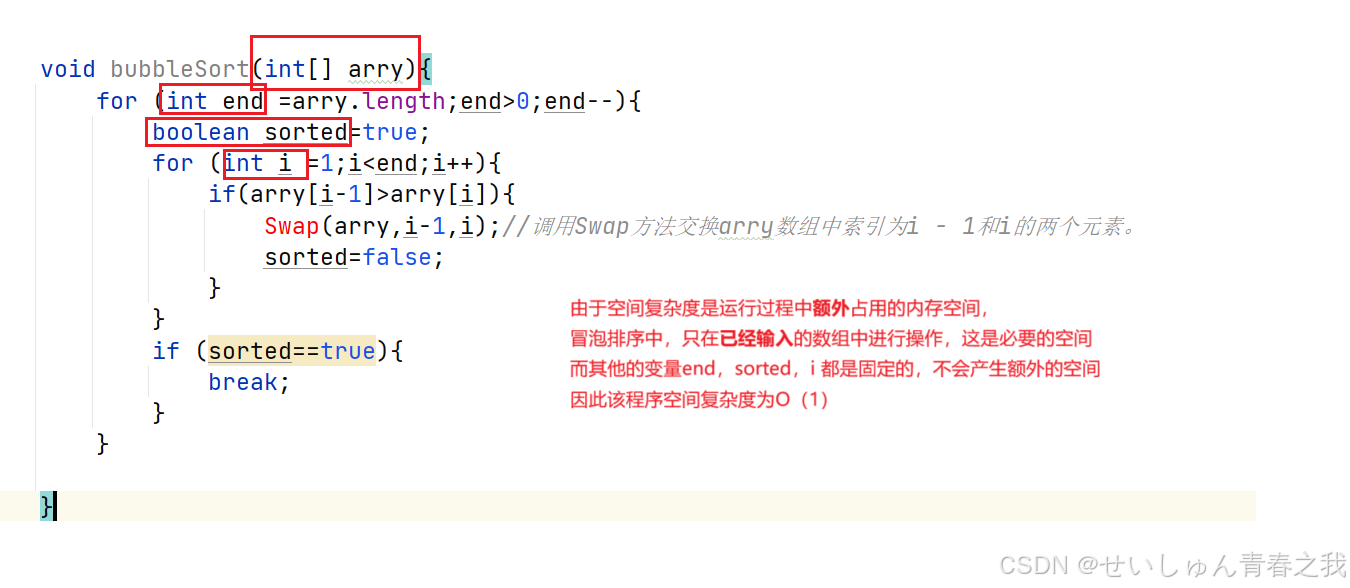
【数据结构】时间和空间复杂度-Java
如何衡量算法的好坏 根据时间复杂度和空间复杂度来判断 比较项目时间复杂度空间复杂度定义衡量算法执行时间与问题规模之间的关系衡量算法在运行过程中所占用的额外存储空间与问题规模之间的关系表达方式通常用大O符号表示,如O(n)、O(n^2&am…...

tensorRT安装详解(linux与windows)
目录 tensorRT介绍 前置准备 安装cuda与cudnn linux windows cuda版本查看 下载安装包 linux安装 安装 安装验证 windows安装 安装 环境变量配置 安装验证 tensorRT介绍 有关tensorRT的介绍见 TensorRT简介-CSDN博客 前置准备 安装cuda与cudnn linux Linux下…...

MYSQL OPTIMIZE TABLE 命令重建表和索引
在 MySQL 中,OPTIMIZE TABLE 命令用于重建表和相关索引,以及回收未使用的空间。这个命令对于维护和优化数据库表的性能非常有用,特别是在进行了大量的数据删除操作之后。OPTIMIZE TABLE 可以减少数据文件的碎片化,确保数据存储更加…...

开发指南075-各种动画效果
方法一、使用动画GIF图标 方法二、使用vue-count-to import CountTo from vue-count-to components: { CountTo }, <count-to :start-val"0" :end-val"num" :duration"num>0?num:1" class"card-panel-num" /> 方法…...

使用 el-upload 如何做到发送一次请求上传多个文件
在使用 Element UI 的 el-upload 组件时,默认情况下每次选择文件都会触发一次上传请求。如果你需要一次性上传多个文件,而不是每个文件都触发一次请求,可以通过一些配置和代码处理来实现。 方法一:通过配置file-list(…...

GEE引擎架设好之后进游戏时白屏的解决方法——gee引擎白屏修复
这两天测试GeeM2引擎的服务端,最常见的问题就是点击开始游戏出现白屏,最早还以为是服务端问题,结果是因为升级了引擎,而没有升级NewUI这份文件导致的。解决方法如下: 下载GEE引擎包最新版,(可以…...

Linux LVS 通用命令行
LVS(Linux Virtual Server)是一种基于Linux操作系统的负载均衡技术,它通过网络负载均衡技术将客户端请求分发到多台实际服务器上,以提高系统的性能和可靠性。在LVS中,常用的命令行工具主要是ipvsadm,以及一…...

laravel .env环境变量原理
介绍 对于应用程序运行的环境来说,不同的环境有不同的配置通常是很有用的。Laravel 利用 Vance Lucas 的 PHP 库 DotEnv 使得此项功能的实现变得非常简单。当应用程序收到请求时,.env 文件中列出的所有变量将被加载到 PHP 的超级全局变量 $_ENV 中。 使…...

Nuxt.js 应用中的 app:templatesGenerated 事件钩子详解
title: Nuxt.js 应用中的 app:templatesGenerated 事件钩子详解 date: 2024/10/19 updated: 2024/10/19 author: cmdragon excerpt: app:templatesGenerated 是 Nuxt.js 的一个生命周期钩子,在模板编译到虚拟文件系统(Virtual File System, VFS)之后被调用。这个钩子允许…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...

怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程
怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的旧Mac重新焕发活力吗…...

线程化笔记工具:重塑深度思考与知识管理的技术实践
1. 项目概述:一个为线程化思考而生的笔记工具最近在折腾个人知识管理工具时,发现了一个挺有意思的开源项目:alishobeiri/thread-notebook。乍一看名字,可能会以为是又一个普通的Markdown笔记本应用。但深入使用后,我发…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十三)用户指引自助教学源码—东方仙盟
代码<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" content"IEedge,chrome1"> <title>你的导师-未来之窗</title> <style>*…...

【最新v2.7.1 版本安装包】OpenClaw 小白入门必看,零基础无需命令零代码保姆级教学
OpenClaw v2.7.1 一键安装部署教程|可视化傻瓜式搭建 ✨适配系统:Windows10/11 64 位 ✨当前版本:v2.7.1 版本(虾壳云版) ✨安装包大小:58.7MB 【点击下载最新安装包】https://xiake.yun/api/download/…...

从零解析开源API网关fiGate:架构设计与生产实践
1. 项目概述:从零解析一个开源API网关最近在梳理团队内部微服务治理方案时,我又重新审视了市面上各类API网关的实现。除了大家耳熟能详的Kong、APISIX、Tyk这些“明星产品”,其实在GitHub的海洋里,还藏着不少设计精巧、思路独特的…...

用Git和Markdown构建个人知识库:Wandercode项目实践指南
1. 项目概述:从“漫游代码”到个人知识管理系统的蜕变最近在GitHub上看到一个挺有意思的项目,叫“Wandercode”,直译过来就是“漫游代码”。乍一看这个标题,可能会让人联想到某种代码生成器或者自动化脚本工具。但当我深入探究其仓…...

MCP2221+Blinka+Jupyter:桌面Python直连I2C传感器实时可视化
1. 项目概述:当桌面电脑“学会”与传感器对话作为一名在嵌入式开发和数据可视化领域摸爬滚打了十多年的老手,我见过太多为了读取一个温度传感器的数据,而不得不先折腾Arduino固件、再折腾串口通信、最后还要自己写个上位机软件的复杂流程。整…...

大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核?!
【大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核】快速阅读:大学正面临一场名为“僵尸化”的危机。当学生和教授都开始将 AI 用于替代思考、替代教学、甚至替代沟通时,高等教育正在从知识的殿堂退化为一种由算法驱动的、高度标准化的凭证工…...